Shadow GAN:Shadow synthesis for virtual objects with conditional adversarial networks
2019-05-14ShuyangZhangRunzeLiangandiaoWang
Shuyang Zhang(),Runze Liang,and M iao Wang
Abstract We introduce ShadowGAN,a generative adversarial network(GAN)for synthesizing shadows for virtual objects inserted in images.Given a target image containing several existing objects with shadows,and an input source object with a specif ied insertion position,the network generates a realistic shadow for the source object. The shadow is synthesized by a generator;using the proposed local adversarial and global adversarial discriminators,the synthetic shadow’s appearance is locally realistic in shape,and globally consistent with other objects’shadowsin termsof shadow direction and area.To overcomethe lack of training data,weproduced training samplesbased on public 3D models and rendering technology.Experimental results from a user study show that thesynthetic shadowed resultslook natural and authentic.
Keywords shadow synthesis;deep learning;generativeadversarial networks;imagesynthesis
1 Introduction
Inserting virtual objects into scenes has a wide range of applications in visual media,from movies,advertisements,and entertainment to virtual reality.Consistency of shadows between the original scene and the inserted object contributes greatly to the naturalness of the results.If no prior scene knowledge is provided,it requires much labor and expertise to make the scene look as realistic as possible,in a tedious photo or video editing process.Even an experienced editor spends much ef fort to produce convincing results using commercial editing software such as Adobe Photoshop.The dif ficulties in this process stem from the lack of accurate estimates of illumination and scene geometry.
In this paper,we address the shadow synthesis problem for virtual objects inserted in an image.Shadow synthesis can be implemented by use of rendering techniques,which require much information,such as illumination,scene models,rendering frameworks,etc.Other methods[1–4]synthesize shadows with approximately estimated illumination and reconstructed scene geometry.Such computations either require user interaction or precise tools,and yet are time-consuming.
Wepropose to solve thisproblem using a novel deep learning-based framework without explicit knowledge of scene geometry and illumination. We use a convolutional neural network to directly predict the shadow map for a virtually inserted object,given only the target scene image and the specif ied insertion position in the image domain.Specif ically,we use a generative adversarial network(GAN)framework,where the generator G tries to produce outputs that cannot be distinguished from“real”results,while the local discriminator DLand global discriminator DGtry to detect the generator’s“fakes”from local and global perspectives,respectively.During training,the generator and discriminators compete until convergence.As a result,a real-type,single-channel shadow map is predicted,from which the edited result with a synthetic shadow can be generated by a simple pixel-wise original image multiplication.The input constraints to our ShadowGAN are few while the computational ef ficiency is high as only a simple feed-forward operation through the network is needed.

Fig.1 Input and output of ShadowGAN.(a)Given an input target scene with original objects and a virtually inserted object(here,a toy car),as well as the object mask((a)top-right),ShadowGAN predicts a shadow map(b)which can be used to synthesize the shadowed result(c)with a simple pixel-wise product operation.The ground truth result is shown in(d).
Our method works for an image of a static scene.We assume scene surfaces to be made of Lambertian materials and we do not model specular ref lection or inter-ref lections between surfaces in the scene.Despite these assumptions,we can produce plausible results.To summarize,the contributions of our work are:
•A convolutional neural network,ShadowGAN,which can synthesize shadows for virtually inserted objects in target images.
•A local–global conditional adversarial scheme for both shape and direction supervision in shadow synthesis.
•A practical dataset for shadow synthesis network training,produced using rendering techniques and public 3D models.
2 Related work
In this section,we discuss related prior work,mainly on shadow synthesis,shadow detection and removal,and image-to-image translation using generative adversarial networks.
2.1 Shadow synthesis
In image editing,knowledge of illumination and scene geometry is essential to achieving realistic shadow synthesis results.Previous methods have been proposed to recover such information from input images or videos. Intrinsic image decomposition algorithms aim to separate a single image I into a pixel-wise product of an albedo or ref lectance layer R and a shading layer S[5–8]. The ref lectance layer reveals how the material ref lects incident light,and the shading layer accounts for illumination ef fects dueto geometry,shadows,and inter-ref lections.However,approachesbased on pixel-wiseillumination and ref lectance maps are not ef fective enough to support complex editing operations such as object insertion.For visually plausibleresults,shadowsmust be carefully computed,which requires an analysis of scene geometry and lighting conf iguration in 3D space.The problem of estimating illumination from images,or inverse lighting,has been investigated.In Refs.[9,10],illumination distributionsin a scenefrom object shadows of known shapes are recovered.Khan et al.[11]proposed editing object materials in a static image.Liu et al.[4]estimated illumination and scene geometry from video for various video applications.Ge et al.[12]proposed an object-aware image editing approach to obtain consistency in structure,color,and texture in a unif ied way.
Rendering virtual objects into real scenes has been long investigated.A survey is provided by Kronander et al.[13].Various ways have been explored to solve the problems of illumination and geometry recovery.Debevec[14]proposed estimating scene radiance and global illumination using a mirrored ball to capture a high-dynamic range lighting environment,to support object insertion.Karsch et al.[1]developed an image composition system to render synthetic objects into legacy photographs.The scene structure and area light are provided by user interaction or a data-driven approach[2].Brief ly,previous methods for shadow synthesis either require user interaction and scene knowledge,or recover explicit representationsof scene geometry and illumination.Our method,in contrast,is novel in synthesizing shadows using a convolutional neural network without any requirements about the scene or the inserted object model.
2.2 Shad ow d etection and removal
The opposite problem to shadow synthesis,i.e.,
shadow detection and removal,has been studied in the computer vision community[15–20].Its goals are to separate the target image into lit and shadowed areas,and thence to remove the shadows.In early work,color[15,20],edge[18],or segmentation[19]cues was used to build high level features for shadow description.Ma et al.[21]introduced appearance harmonization that makes the appearance of a deshadowed region compatible with the rest of the image.Recently,convolutional neural networks for shadow removal have been proposed[16,17].In Ref.[17],the input image is decomposed into a shadow-free image and a shadow matte;the shadow matte is predicted using a convolutional neural network.Two stacked conditional GANs successively detect the shadow region and remove the shadow matte.
In the shadow removal problem,the objects casting shadows are commonly absent,while in the shadow synthesis problem,a virtually inserted object is present.
2.3 Image-to-image translation using generative adversarial networks
Goodfellow et al.[22]f irst introduced the concept of the generative adversarial network(GAN),consisting of two sub-networks:a generator(G)and a discriminator(D).G’s task is to generate outputs to resembletheground truth,while D tries to distinguish between fake and real inputs,i.e.,between generated output and the ground truth.G and D work against each other,and the ideal outcome is for G to produce outputs that D cannot discriminate.Since its introduction,the GAN method has been widely applied to image-to-image translation problems,such as face image synthesis[23–25],image super resolution [26],and image completion [27,28].Variations of the GAN architecture have also been developed,including conditional GAN [29,30],CycleGAN[31],StarGAN[24],etc.
Isola et al.[30]proposed a GAN network that translates an image into another domain,such as from a sketch to a photo,from architectural maps to photos,from black-and-white to color photos,etc.Their approach used a U-net structure inside the generator,enabling earlier convolutions to be concatenated with later deconvolutional layers to pass down information about the input.In an image completion task[27],the contents of an arbitrary image region conditioned on its surroundings are generated by a convolutional neural network.Later,Iizuka et al.[28]proposed an image completion network with global and local discriminators.The addition of a local discriminator helps scrutinize the details of the completed image.Portenier et al.[32]developed the Faceshop system which supports interactive face editing with user provided sketch and color information as input conditions for the GAN architecture.Wei et al.[33]proposed to learn adaptive receptive f ields instead of manually selecting dilated convolutional kernels.
Our proposed ShadowGAN is an adaption of GAN,which uses a local discriminator to guarantee shape correctness and a global discriminator to guarantee direction and area compatible with other objects’shadows.
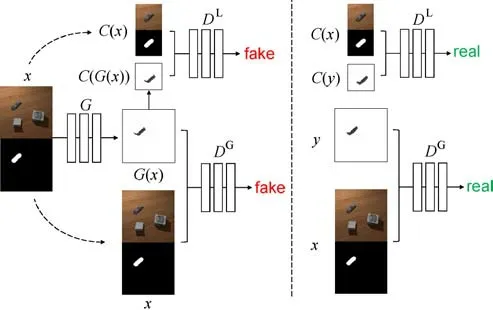
Fig.2 Training a conditional generative adversarial network to synthesize shadow maps.The local discriminator D L learns to classify between fake and real cropped tuples.The global discriminator D G learns to classify between fake and real tuples from a global view.The generator G learns to fool the discriminator.
3 M ethod
3.1 Training data
3.1.1 Approach
Our proposed ShadowGAN is trained on synthetic data,where static scene images are rendered using 3D models indexed by ShapeNet[34].Given an input target scene image Itincluding original objects with shadows and a virtually inserted object without shadow,whose position in the scene is specif ied by a mask ms,our goal is to predict a shadow map S,with which the output image Iowith a synthetic shadow can be obtained by a simple pixel-wise product operation Io=It∗S.With the scene image Itand source object mask msas inputs,the shadow map S is predicted using a generative network(see Fig.3),where a reconstruction loss and two adversarial losses are used to guarantee the synthesis produces realistic output.
As a supervised deep learning-based image synthesis method,ShadowGAN requires paired input and ground truth images as training data,where the input scene image Itcontains N objects(N3 is assumed in our work)with shadows and one virtually inserted source object without a shadow;its mask msindicating the insertion region is also provided.The ground truth shadow map S has the same size as It.Each position p of S is associated with a real number,indicating that the output synthetic image color Io(p)can be obtained by multiplying the scene image color It(p)by the coef ficient S(p),under the assumption that ambient light is present in the scene.
Such data are impossible to ef fectively collect in real life.Firstly,on one hand,scenes in which a few objects have shadows and one object is fully lit do not realistically occur in reality,while on the other hand,if the virtually inserted object is copied and pasted from other photos,the ground truth shadow map S cannot be generated ef ficiently and realistically.Secondly,a wide variety of illumination,scenes,and camera conf igurations are required for training data,which is both tedious and challenging for real-life photo capture.
Instead of using real-life photos,we use rendering technology to generate the training data.We render each target scene image Itwith N objects placed on the ground with shadows and one object with its shadow turned of f.The shadow map S is generated by rendering a scene image Itwith all the shadows turned on,then dividing it by It:S=It/It.
3.1.2 Scenes
We use a sub-set of commonly seen 3D model categories such as can,printer,bed,etc.from a publicly available dataset,ShapeNet[34].The object categories used for rendering are listed in Table 1.In total,9265 objects were selected for rendering scenes.To render realistic ground planes,we downloaded textures from Internet using key-words search for,e.g.,woollen,stone,tablecloth.A total of 110 textures

Tab le 1 ShapeNet 3D model categories used to render the target scene
wererandomly chosen for rendering theplane.In each target scene image,up to four objects were randomly selected from the model collection,one of them being the virtually inserted object,and the rest being the original objects in the scene.
We assume each of the x,y,z coordinates to be in the range[−1,1]:the ground plane is set to P={(x,y,z)|x∈[−1,1],y∈[−1,1],z=0}.The four randomly selected objects are placed at locations(0.6,0.6,0),(−0.6,0.6,0),(−0.6,−0.6,0),(0.6,−0.6,0),randomly rotated about the z-axis.
3.1.3 Camera
The camera position Pc=(xc,yc,zc)was randomly chosen in the 3D space within the range:

3.1.4 Illumination
All scenes were illuminated by a single white point light with f ixed intensity.The distance between the light and the center of the f loor was randomly chosen in a limited range:the light position Pl=(xl,yl,zl)was randomly chosen in the following range:
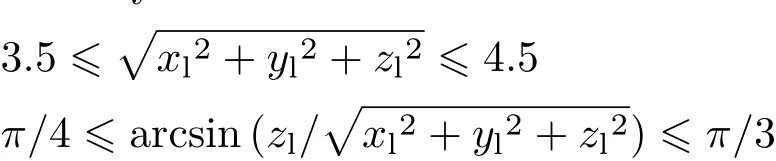
3.1.5 Rendering
We used path tracing[35]to render the scenes,with 128 samplesper pixel.To f ind themask of theinserted object,we rendered it again with its material set to pure black,and then extracted its mask from the rendered image.
3.1.6 Training data
As a result,12,400 training samples were generated,comprising a scene image It,source object mask ms,and ground truth shadow map S,rendered at resolution 256×256.
3.2 Formulation
3.2.1 Approach
Our goal is to train a generator G that learns a mapping function from domain X to domain Y,where X={xi}Ni=1are input scenes with virtually inserted object mask xi=Iit,mis,and Y={yj}Nj=1are the corresponding shadow maps yi=Si.The key requirement for learning is that the generated shadow map G(x)should reconstruct the shadow map,while not being distinguished from the ground truth shadow map data y≈pdata(y).We introduce a local discriminator DLand a global discriminator DGwhich are trained to detect the generated shadow mapsas“fakes”from aspectsof local shape and global direction and area,respectively.Our objective thus contains a reconstruction loss LL1,a local adversarial loss LLGAN,and a global adversarial loss LGGAN.
3.2.2 Reconstruction loss
Reconstruction loss is commonly used in supervised image-to-image translation problems[28,30,36],to constrain the generated result to be similar to the ground truth in an L1or L2sense.Here we use L1norm reconstruction loss to measure the error between the predicted shadow map G(x)and the ground truth shadow map y:
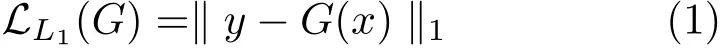
3.2.3 Local adversarial loss
The local discriminator DLtries to distinguish the generated fake results G(x)from real samples y from local considerations,so only looks at the region around the source object.Intuitively,the generated shadow G(x)for the sourceobject should beassimilar as possible to the ground truth sample y within a local region.We crop a square region centered at the source object,of side half the original image size,i.e.,128×128 pixels,and only pass the cropped region of the predicted shadow map C(G(x))or ground truth shadow map C(y),with conditional input scene image and source object mask C(x),to the local discriminator.Here,C(·)is the cropping operator.The local adversarial loss is def ined to be

G tries to minimize this objective against the local adversarial DLthat tries to maximize it.DLtakes the cropped version of either conditional real samplesx,yor generated fake samplesx,G(x)as inputs.The discriminator determines whether the samples are real or fake.
3.2.4 Global adversarial loss
The global discriminator DGtries to distinguish the generated fake results G(x)from real samples y using a global view of the whole shadow map.In particular,the generated shadow G(x)for the source object should be compatible with other objects’shadows in the original scene in terms of direction and area.
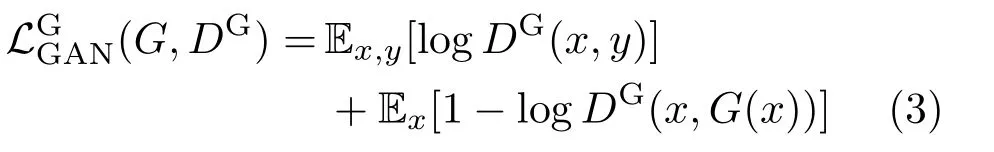
where G tries to minimize this objective against the global adversarial DLthat tries to maximize it.DGtakes either conditioned real samplesx,yor conditioned generated fake samplesx,G(x)as inputs.
3.2.5 Full objective
The overall objective is the weighted sum of the loss terms:
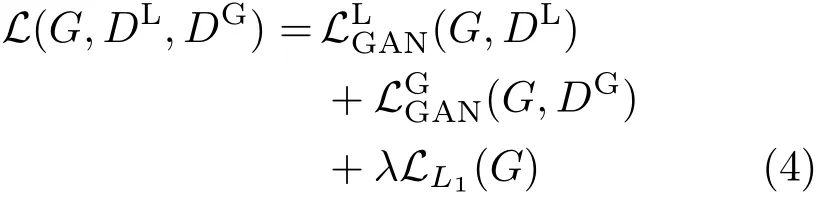
whereλ=200 controls the relative importance of the objective terms.The goal is to determine:

3.3 Imp lementation
3.3.1 Conditional shadow map generator
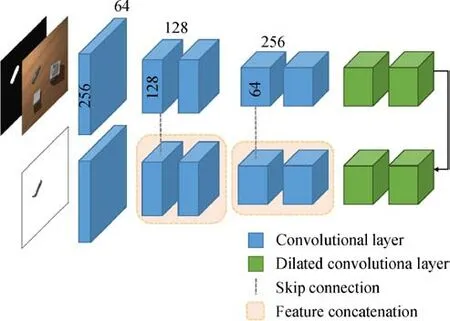
Fig.3 Conditional shadow map generator.
Figure 3 visualizes the conditional shadow map generator. The generator takes an input of size 256×256 with 4 channels;3 are RGB channels from the target scene and 1 is the source object mask ms.The output is a single channel shadow map of size 256×256.We adopt the encoder–decoder architecture proposed by Isola et al.[30],where skip connections(U-net)are set up to concatenate the corresponding layers in encoder and decoder. The generator downsamples the input using strided convolutions,followed by intermediatelayersof dilated convolutions[37]before upsampling using transposed convolutions.We use the ReLU activation function after each layer except for the output layer,which uses a tanh activation function.In total,the proposed editing network has 15 convolutional layers with up to 256 feature channels.
3.3.2 Discriminator networks
Following Iizuka et al.[28]and Portenier et al.[32],we use local and global discriminators as adversaries for generator training(see Fig.4).The input to the global discriminator is a 256×256×5 tensor:a fake shadow map sample Sfor a real shadow map sample Sr,conditional input target scene image It,and the inserted object mask ms.The local discriminator uses the same input tensor but works on a cropped region of size 128×128 centered around the inserted object position.
Both discriminators are fully-convolutional networks,with the spatial tensor dimension gradually downsampled to 1×1.Feature channels increase up to 512 channels then decrease to 1.The outputs of discriminators are predictions whether the inputs are more like real samples or fake ones.We use leaky ReLU activation functions with slope set to 0.2 everywhere in the discriminators,except for the last layer which uses a sigmoid activation function.Full network architectural details are provided in Tables 2 and 3.
3.4 Op timization and p arameters
To optimize the proposed ShadowGAN,we follow Ref.[30]in which gradient descent steps for D and G are alternately performed.We apply the Adam solver[38]with learning rate set to 0.0002,and momentum parametersβ1=0.5,β2=0.999.The training process using 100 epochs takes about 5 hours on a Titan 1080 Ti graphic card.
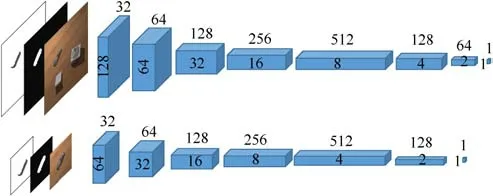
Fig.4 Discriminator architecture,comprising a global(top)and a local(bottom)network.

Tab le 2 Generator architecture.After each convolutional layer,except the last,there is a rectif ied linear unit(ReLU)layer.The output layer consists of a convolutional layer with a tanh function instead of a ReLU layer.“Outputs”gives the number of output channels for the output of the layer
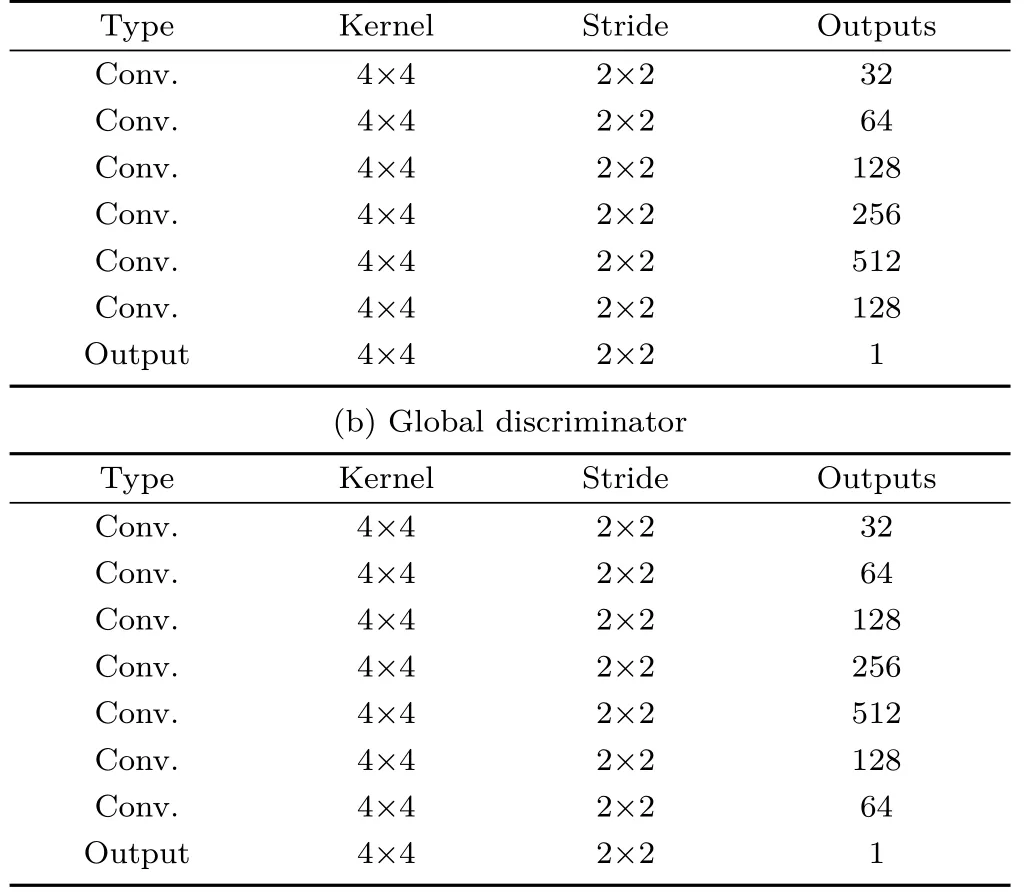
Table 3 Discriminator architectures.All Conv.layers are followed by leaky ReLU activation(slope 0.2).The output layer consists of a convolutional layer with sigmoid activation;it predicts the probability that an input shadow map is from real samples rather than the generator network(a)Local discriminator
4 Results
4.1 Initial tests
We have tested ShadowGAN on rendered synthetic scenes from the test set.The test set was rendered using the same rendering strategy as for the training set,with randomly selected models,placed object positions and orientations,illumination and camera conf igurations.Time for shadow synthesis was about 0.3 s for a 256×256 input image on a Titan 1080 Ti graphic card.A gallery of corresponding synthetic shadowed results is shown in Fig.8.Figure 5 shows synthetic resultswith thesamesceneand illumination,but viewed from randomly selected viewpoints.It can be seen that even when observed from dif ferent view points,the synthetic shadows are visually realistic.As a further test,Fig.6 shows results with the same scene and illumination,but slightly dif ferent camera poses caused by camera rotation.It can be seen that the synthetic shadows are temporally consistent during the camera movement.

Fig.5 Two examples of shadow synthesis for the same scene and illumination,with dif ferent viewing angles.In each example,top row:input scenes,bottom row:corresponding synthetic results.

Fig.6 Shadow synthesis for the same scene and illumination,with a slightly rotated camera. Top row:input scenes,bottom row:corresponding synthetic results.
ShadowGAN supports inserting virtual objects in sequence.Figure 7 shows an example of step-by-step object insertions with shadows synthesized using our method.
As ShadowGAN is the f irst deep learning-based shadow synthesis network,we next present an ablation study to demonstrate the benef its of the components of our system,followed by a user study to verify whether fake results from ShadowGAN are indistinguishable from real ones.
4.2 Ablation study
In order to evaluate the ef fectiveness of components of the proposed method,we re-evaluated ShadowGAN with alternative loss functions: with only the reconstruction loss(denoted as L1),with the reconstruction loss and the local adversarial loss(denoted as L1+Local)and with the reconstruction loss and the global adversarial loss(denoted as L1+Global).Representative visual results are shown in Fig.9. The results indicate that with some losses turned of f,using functions L1,L1+Local,and L1+Global do not generalize well to the test samples and fail to predict visually plausible shadows with correct shape,area,and direction.
We also evaluated an input variation,in which the input source object position was not explicitly provided by a mask mseither for the generator or for the discriminators.Figure 10 provides a visual comparison under input variations.The results indicate that the source object mask msis essential for ShadowGAN to obtain good results.
4.3 User study
To further assess whether the synthetic shadows for virtually inserted objects are visually natural and authentic,we conducted a user study with the task of observing and determining whether the shadows from our synthetic results look real.We also showed real scenes to the subjects and asked them to determine whether the images were real.

Fig.7 Inserting virtual objects in sequence.

Fig.8 Gallery of synthetic results.Each example,left to right:(a)input target scene with a virtual source object,(b)input source object mask,(c)predicted shadow map using Shadow GAN,(d)synthetic shadowed result,and(e)ground truth shadowed result.
We collected 20 pairs of real and fake shadowed results from the test scenes;each pair shows the same scene.We invited 20 subjects without viewing or perception issues to observe and rate the images.Each subject observed a randomly selected image from each scene pair—either the synthetic result or the real shadowed image,and assessed whether the shadows in the image were real.We collected all votes from the subjects,and summarise the results of the user study in Table 4.As a result,50.48%of our synthetic shadows were assessed to be real images.Even shadows in the real images were sometimes considered to be fake;only 57.14%were considered to be real.The summary indicates that the visual ef fectiveness of synthetic results from ShadowGAN is close to that in rendered scenes.

Fig.9 Ablation study for loss functions.Dif ferent losses lead to dif ferent qualities of results.Each column shows results trained under a dif ferent loss.

Fig.10 Ablation study for source mask.Each row shows a scene with our shadow synthesis result and the result without source mask,m s.

Table 4 User study summary
5 Limitations and conclusions
Shadow GAN has limitations.Firstly,as discussed in Section 3.1,our training set and test set were produced using rendering technology on public 3D models rather than using real-life photos.As collecting real-life photos with some objects’shadows turned of fis a challenging task,we regard collecting and testing real-life photos as requiring further work.Secondly,when testing our model,a scene with only one virtually inserted object is fed into the network.Synthesizing shadows for multiple objects is not supported by ShadowGAN.However as we have shown in the experimental results,users may iteratively perform insertion operations,one object at a time.As pioneering work that uses GAN to synthesize shadows for virtual object,we only tested our model on 256×256 images(as did Ref.[30]).
In summary,we have presented a generative adversarial network—Shadow GAN—which can synthesize shadows for virtual objects in images.Shadows are predicted from a generator which during training competes against a local discriminator and a global discriminator.To our knowledge,this is the f irst novel shadow synthesis solution using a deep learning-based framework.It benef its from being free from input constraints and is computational ef fective.For network training,we have produced a large set of rendered scenes using public 3D models in commonly seen object categories.We believe both the training data and ShadowGAN will benef it the community of computer graphics and virtual reality.
Acknowledgements
The authors would like to thank all the reviewers.This work was supported by the National Natural Science Foundation of China (Project Nos.61561146393 and 61521002),the China Postdoctoral Science Foundation(Project No.2016M601032),and a Research Grant of Beijing Higher Institution Engineering Research Center.
杂志排行

Computational Visual Media的其它文章
- Recurrent 3D attentional networks for end-to-end active object recognition
- Image-based app earance acquisition of ef fect coatings
- Real-time stereo matching on CUDA using Fourier descriptors and dynamic programming
- Discernible image mosaic with edge-aware adaptive tiles
- Automated p ebble mosaic stylization of images
- Removing fences from sweep motion videos using global 3D reconstruction and fence-aware light f ield rendering