Removing fences from sweep motion videos using global 3D reconstruction and fence-aware light f ield rendering
2019-05-14ChanyaLueangwattanaShoheioriandHideoSaito
Chanya Lueangwattana,Shohei M ori(),and Hideo Saito
Abstract Diminishing the appearance of a fence in an image is a challenging research area due to the characteristics of fences(thinness,lack of texture,etc.)and the need for occluded background restoration.In this paper,we describe a fence removal method for an image sequence captured by a user making a sweep motion,in which occluded background is potentially observed.To make use of geometric and appearance information such as consecutive images,we use two well-known approaches:structurefrom motion and light field rendering.Resultsusing real imagesequencesshow that our method can stably segment fencesand preserve background details for various fence and background combinations.A new video without the fence,with frame coherence,can be successfully provided.
Keywords video;fence;video repair;diminished reality (DR);structure from motion(SfM);light f ield rendering(LFR)
1 Introduction
Recovering occluded objects in a scene,also known as diminished reality(DR),is a challenging issue that has recently received increasing attention[1].Visual obstacles can appear to be seen through with a variety techniques such as image-inpainting,which is used to f ill in the occluded pixels with ones having similar features.Due to the similarity of goals,we can consider the issue of fence removal in images to be a DR problem.Fence removal requires techniques to diminish the appearance of a fence in an image to create a fence-free view.Such a technique is useful,for example,when a photographer takes a photograph of a tourist landmark but the scene is occluded by a fence(e.g.,for security reasons).
There are two challenging issues in fence removal:fence detection,and background restoration(i.e.,restoration of pixels occluded by the fence).
The dif ficulties in fence detection and segmentation lay in the characteristics of fences;they are typically thin,untextured,etc.Thus,many existing methods of segmenting fence pixels from other pixels are fully manual or semi-automated[2–4],although recent work has introduced fully automated methods[5–11].
To f ill in the detected fence pixels,we can use an existing DR method such as image-inpainting to f ill in the occluded pixels with appropriate content[7].We may also use multi-viewpoint images to observe the hidden regions[2,3].
While single shot fence removal,and fence removal using video resources,havebeen discussed for a decade,to the best of our knowledge,removal of fences in video,which introduces issues of frame coherence,has only a few examples[8,9].Furthermore,the state of the art methods are limited due to reliance on ideal regular patterns of fences[9]and depth variance in the background geometry[8].
To further assess these video related issues,in this research,we implemented several baseline methods for comparison with our algorithm which uses globally consistent data to improve frame coherence in the video results.In this paper,we combine a well-known computer vision method,structure from motion(SfM),with one from graphics,light f ield rendering(LFR).
Our contributions can be summarized as follows:•segmenting foreground and background regions based on depth information from SfM and dense reconstruction;
•recovering occluded background pixels using a modif ied LFR scheme,starting from an image sequence captured by a sweep camera motion;
•a framework for combining the above approaches for fence removal;
•comparisons of four fence removal methods combining two types of fence detection and background restoration,to validate our proposed method.
2 Related work
In this section,we review fence pixel detection and background restoration approaches used in fence removal.Table 1 summarizes the existing work and the proposed method to highlight the dif ferences.
2.1 Fence detection
Various researches have proposed methods to detect and remove fences in an image or a video.The pioneering fence removal work by Liu et al.[7]used single image foreground–background segmentation,relying on the fact that fences have almost regular patterns.Park et al.[2]improved upon Liu et al.’s method by using online learning for fence pattern detection. Nevertheless,the approach still has problems in detecting fences since actual fences are in reality ideally regularly arranged.
Yamashita et al.[10]detected fences based on dif ferences between f lash and non-f lash images.Since f lash only af fects nearby objects,the dif ference between the two images can provide a fence mask.Khasare et al.[3]and Negi et al.[4]provided semi-automated fence detection algorithms for video frames,requiring the user to identify fence pixels by means of line inputs in an image.Here,all sequential images recorded during a sweep motion are aligned temporo-spatially to detect fence pixels,which appear dif ferently to the background pixels in the space.Zhang et al.[11]used a hyperspectral camera to segment fence pixels in hyperspectral space,using concepts of signal separation.Mu et al.[8]proposed a visual parallax based method of fence removal for videos.Xue et al.[14]implemented a successful method to separate ref lections and background based on edge-based pixel motion analysis,using a set of frames captured by a user’s sweep motion.Yi et al.[9]segmented fencesin a video captured by a smart phone,using graph-cut based on gradient oriented histograms and fence geometry.
As well as color information,depth information allows us to segment fence and non-fence pixels by straightforward depth thresholding,as fences are usually closer to the camera than to the background.Jonna et al.[6]used a Kinect sensor to make a fence mask from the depth data.They also used a stereo image captured by a smart phone to compute a disparity map for the same purpose[5].
Due to their simplicity and generality,we follow the depth segmentation approaches to detect fence pixels in video frames without the need for user input.Instead of a stereo pair,we use all video frames to reconstruct the scene,including the fence,for more robust and reliable depth estimation.Ourexperiments also implemented color-based fence detection as a basis for comparison.

Table 1 Approaches used in various fence removal methods.Plain background:image methods.Grey background:video methods
2.2 Background restoration
When a single imageis used asinput for fence removal,patch-based synthesis or image inpainting are the only choices for background restoration[15].Liu et al.[7]used exemplar-based image inpainting[16]to f ill in the occluded pixels with pixels sampled from other regions.Yi et al.[9]also applied an image inpainting approach for background restoration at each frame in a video,since their main focus was to develop a fence detection method.Barnes et al.[13]presented the PatchTable method for fast pixel correspondence searching,using locality-sensitive hashing[17]for speedup.They gave occluding object removal examples as an application.
Instead of using image-inpainting approaches,multi-view images may be used since backgrounds are potentially visible from some perspectives even if occluded in others.Park et al.[2]used multi-view images to f ill fence pixels with actual observations from dif ferent perspectives in which occluded areas arevisible.For theremaining unobserved background,they used symmetry-augmented inpainting,which inpaints pixels with bilaterally symmetric patches.Zhang et al.[11]proposed use of two images for their approximate nearest neighbor f ields(ANNF).Similar patches between the fence-masked image and the image itself are found f irst,and then fence pixels are inpainted with the patch with the highest similarity.The output is then used to re-initialize a new inpainting step,and so on,until all pixels are recovered.Zhang et al.[12]proposed PlenoPatch,an interactive light f ield editing system for regularly arranged viewpoints based on a scene model of overlapped layers at dif ferent depths.
Some fenceremoval work including that of Jonna et al.[6]and Khasare et al.[3]uses image sequences(i.e.,video)and a Markov random f ield(MRF)model to fuse visible pixels from other frames with fence pixels to be replaced.Negi et al.[4]modif ied the model as a discontinuity adaptive Markov random f ield(DAMRF)for edge-preserving fence removal at higher image resolutions.
Fence pixels can also be considered as noise in an image[5,8,10].Jonna et al.[5]gave a fence removal image using a total variation(TV)denoising technique[18].Yamashita et al.[10]used multi-focus images,pictures imaged at dif ferent focal lengths,to determine background pixel colors from an image focused at the background.Mu et al.[8]suppressed fence pixels using a robust temporal median f ilter.Using optical f low analysis,a signif icant number of images are stacked temporo-spatially.Fence pixels are suppressed in this space to restore background colors with a median f ilter.
While,as noted,fence removal for a single image has been well-discussed,fence removal for video has drawn little attention apart from Refs.[8,9,14].In fact,none of these papers showed video fence removal results and therefore it lacks discussion of video visual quality issues(e.g.,frame coherence and viewpoint dependence).One of these papers notes that its algorithm can maintain frame coherence only when the background is signif icantly far away from the fence,and therefore,view-dependent properties in background restoration are out of scope[8].The other paper is mainly concerned with a fence detection algorithm,and simply uses per frame image inpainting without regard for frame coherence,as the authors note[9].
From this starting point,we modify LFR for fence removal tasks to provide frame-coherent video resultswith view-dependent propertiesin therestored backgrounds.
3 M ethod
3.1 Overview
Given a video of a scene with a fence(Section 3.2),our algorithm generates a de-fenced video.Figure 1 shows an overview of the pipeline of the proposed method.Like existing approaches,it has two phases:fence detection and background restoration.
In fence detection(Section 3.3),a 3D point cloud of the scene is generated using an SfM method(Section 3.3.1).Based on the scene reconstruction,the point cloud is separated into two clouds of points,those belonging to the fence,and other points(Section 3.3.2).A mesh is created from the points(Section 3.3.3).The fence point cloud is then used to generate mask images for every frame in the recorded video(Section 3.3.2).
In background restoration (Section 3.4),the fence pixels are f illed with fence-aware LFR results(Section 3.4.2).This rendering is based on a global reconstruction of the scene,and,therefore the resultant rendering preserves edges,and is framecoherent in the output video.

Fig.1 Overview of proposed method.
3.2 Scene capture
Following the literature[2,3],we expect that regions occluded by fences in a frame are observable in other frames in a video.To record an image sequence,we have to move the camera in a diagonal direction against the fence rectangle.Note that this diagonal sweep motion is essential for the proposed method to make the camera fully observe the background.
3.3 Fence d etection
3.3.1 Scene reconstruction
Given a video with N frames,geometric information about the captured scene is recovered as a 3D point cloud by SfM and multi-view stereo[19,20]using COLMAP,followed by separation of fence and nonfence point clouds. Figures 2(b)and 2(c)show the reconstructed 3D point cloud corresponding to a scene in Fig.2(a).The feature points in each frame are detected by SIFT and matched between consecutive frames using sequential matching.Using the obtained point correspondences,each frame is registered with its camera pose and triangulated points as a sparse point cloud.Then,depth and normal maps are computed from registered pairs,and fused to the sparse point cloud to reconstruct a dense point cloud.Note that all frames share the same intrinsic parameters given by bundle adjustment in SfM since the video is captured using a single camera.

Fig.2 Scene reconstruction from SfM:(a)a frame from a video sequence,(b)front view of a recovered 3D point cloud with color,(c)top view of the same,(d)3D background mesh.
3.3.2 Depth segmentation
After dense 3D reconstruction,we separate the 3D point cloud into fence F and non-fence¯F points.To do so,we select the T closest points(e.g.,T=40%)within the 3D point cloud in a camera coordinate system asa fencepoint cloud:see Fig.2(c).Hereafter,we use∈F anddenote a fence point and a non-fence point respectively.Consequently,reprojecting F to data cameras Di(0i 3.3.3 Mesh reconstruction In COLMAP,the fused 3D point clouds are further triangulated as a dense surface using Poisson surface be improved by using implicit depth from a focal plane[22,23,25]or explicit depth from scene geometry[26,27].We thus implemented explicit depth-based LFR to preserve view-dependent properties in the output scene.reconstruction [21]or Delaunay reconstruction.Figure 2(d)shows the reconstructed surface result for the 3D point cloud in Fig.2(b);the visible region in the scene is meshed. The dense surfaces and point cloud are combined as acquired 3D background information¯F,which can densify the depth information when ¯F is projected,and can preserve frame coherence in a video.Figures 4(a)and 4(b)show the dif ferences in background projection without and with use of the mesh respectively. However,we leave F as points since fences are thin and can be smoothed out.Instead,we dilateto densify the masked regions. 3.4.1 LFR parameterization We now recover the missing pixels in the detected fence regions,i.e.,those for which)is 1,based on LFR,which is an image-based rendering method for generating new views from arbitrary camera positions[22–25].LFR uses four parameters,r=(u,v,s,t),to represent a scene.As shown in Fig.5,a ray r represents a light ray that passes through a camera plane at(u,v)and a focal plane at(s,t)in a virtual image C.A pixel color at(s,t)in the visual view C can,therefore,be calculated by blending the corresponding colors in data cameras’images Di. 3.4.2 Fence-aware LFR To make use of the data obtained so far,we modif ied LFR[22,23]as described in the pseudo code in Algorithm 1.As noted in several papers,LFR can Fig.4 Background projection from:(a)3D point cloud,(b)3D point cloud and mesh. Fig.5 Light f ield rendering parameterization. Given a background 3D point X¯Fat a missing pixel position x,and registered data cameras Di,we render the background by blending the Diimages.The pixels to be blended in Diare calculated by projecting the 3D point to Dias described in Eq.(1).However,masked pixels in Diare given zero weight during blending and,as a result,the fence pixels are not incorporated in theblending results.Furthermore,the blending function is weighted inversely by the Euclidean distance between(u,v)’s camera position and the render frame position,giving more weight to a ray from the camera that is more closely aligned with C.Figure 6 shows the blending result for the missing pixels masked in Fig.3(b). Fig.6 Blending results using fence-aware LFR for camera data D i. In this section,wecompare the proposed method with three other alternative implementations to discuss their performance in the frame coherence and the visual quality in seven dif ferent scenes. Since implementations of published video fence removal methods[8,9]are not publicly available,instead,we implemented four video fence removal methods in combination with two fence detection and two background restorations for comprehensive tests. For fence segmentation,we implemented a method based on optical f low[28]with k-means(k=2)clustering as a baseline.Optical f low techniques have been used in image fence removal work with video resources[5,6,8,9]to estimate pixel motion between consecutiveframes.Sincefencesarenormally closer to the camera than the background,fence pixels move more than background pixels during camera translation.Therefore,we can segment pixels into two clusters.We refer to this implementation as“optical f low+binary clustering(OF+BC)”,while we denote our global depth thresholding“DT”. For background restoration,image-inpainting is one of the major approaches used in fence removal[2,7,9,11]and,therefore,we chose this as a baseline here.Given the fence mask from OF+BC or DT,we either apply our fence-aware LFR(FA-LFR)or frame-by-frame PhotoShop Content-Aware Fill(i.e.,image-inpainting)(IP);it is an exemplar-based imageinpainting based on PatchMatch[29]. These implementations were combined to provide four fence removal methods:OF+BC/IP,OF+BC/FA-LFR,DT/IP,and DT/FA-LFR(our proposed method). We recorded seven scenes with combinations of various types of background and fences including challenging irregular ones to conf irm the robustness of the proposed method in the face of real-life scene variations.Figure 7 shows stills from the seven scenes along with corresponding fence detection binary masks from OF+BC and DT respectively.The image sequencesin each scenewererecorded using an iPhone 8 Plus or an iPhone 6s(960×540 pixels at 30 Hz).The clips in Fig.7 contained 79 and 437 frames;10–20 closest(in Euclidean distance)data cameras were used for FA-LFR,depending upon the scene.Table 2 summarizes the setups.As in other video fence removal literature[8,9,14],we always assume thefencesto becloser to theuser than thebackground.The fence removal results are best seen in color,in the video in the Electronic Supplementary Material(ESM). Fig.7 Fence detection in experimental scenes. Table 2 Experimental scenes Figures 8–11 show results in three consecutive frames in four scenes to conf irm frame coherence.Figures 12–14 show results using OF+BC/IP,DT/IP,OF+BC/FA-LFR,and DT/FA-LFR to highlight dif ferences in the visual quality and frame coherence.In the paper,we only shows comparative results for Scenes 5–7,which include challenging irregular fences;supplemental material in the ESM shows all the results in pictures and video. The areas in the red squares are enlarged on the right of each image to show recovered pixels in detail.In most our experimental scenes,the DT masks more comprehensively mask the fences than OF+BC does.An examination of the visual quality and stability shows that our proposed FA-LFR method is more ef fective in restoring the missing background than IP,either for DT or OF+BC masking,throughout each entire scene. FA-LFR replaces fence pixels with background pixelsby blending view-dependent pixelsselected by a global 3D point cloud projection.Pixel color blending based on actual visible backgrounds keeps consistency between input pixels and synthesized ones,while the global 3D point projection keeps frame coherence.These features provide good restoration of object edges(see the pipes in Figs.8 and 10,rifts between two dif ferent materials in Figs.9 and 11),even in challenging scenes(see Fig.12)and for unusual object shapes(see the grass in Fig.9,the shrubs in Fig.11,and the bicycles in Fig.14). Fig.8 Background restoration for consecutive frames of Scene 1. Fig.9 Background restoration for consecutive frames of Scene 2. Fig.10 Background restoration for consecutive frames of Scene 3. Fig.11 Background restoration for consecutive frames of Scene 4. On the other hand,IP tends to lose straight lines in the background when such lines are partially occluded by the fence;in the worst case,IP removes the entire object from the background(see Fig.14).When fence pixels partially remain after OF+BC masking,IP may even recover the fence itself since IP can f ind clues of the fence in the input image(see Figs.12 and 13).Such details are normally preserved in the restoration result from FA-LFR. Fig.12 Comparison of background restoration for consecutive frames of Scene 5. Fig.13 Comparison of background restoration for consecutive frames of Scene 6. IP suf fers from signif icant frame by frame changes in appearance of the background due to its random initialization,and frame-incoherent fencedetection by OF+BC.Even with diagonal camera motion,OF+BC usually detects only one direction of fence pattern and misses the other(see the binary masks of scene 1,2,4,and 5 in Fig.7).This causes the fence to remain in the restoration results,even sometimes entirely appearing in some frames(see Fig.12).On the other hand,the DT method provides accurate and stable fence segmentation across frames due to use of global 3D reconstruction.By comparing fence masking from the two methods using FA-LFR with both,it can be seen that restoration using masking from DT producesbetter fenceremoval result:precise fence segmentation obviously leads to the better background restoration quality.If fence pixels still remain after the fence detection step,IP tends to recover the fence itself from the remaining fencepixels(see the DT/IP results in Fig.12).The proposed method recovers only the background pixels because it takes background depths into account. Fig.14 Comparison of background restoration for consecutive frames of Scene 7. While in the most cases,DT/FA-LFR achieved the most plausible results amongst all four methods,we observed failures in some frames.For example,in scenes such as Fig.15,the algorithm had dif ficulties in dif ferentiating the fence and the background since the fence’s colors are very similar to those in the background,and the backgrounds are close to the fence.The algorithm could successfully detect the horizontal fence,although mis-detects most of the vertical fence close to the tree behind.Nevertheless,the proposed method still provides acceptable results,although the fence is not removed completely. The DT/FA-LFR approach requires global 3D reconstruction of target scenes.Therefore,for frames of the beginning and the end of the sequence,the algorithm can fail to remove the fence due to a lack of image resources for both 3D reconstruction and LFR,regardless of the accuracy of fence detection.Consequently,artifacts such as black pixels and duplicated colors may be observed. In addition,pixels with no depth information are considered to have inf inite depth.Therefore,such pixels may seem blurred,although they are trivial and barely seen in the results. From the evaluations between the proposed method and the other three implementations,the inconsistent fence detection or the coherent background restoration are major issuesfor thevideo fence removal quality.Regarding these issues,the DT/FA-LFR performed more stable fence detection than OF+BC does and better background pixel recovery than IP does. Fig.15 Failure in DT fence segmentation:(a)input frame,(b)fence mask superimposed on camera data,and(c)result of our method. A f inal issue in fence removal methods,including ours,is usability. These methods require users to appropriately move their cameras to suf ficiently observe hidden background or distinguish foreground from background[2,8,9,14].User prompting may be helpful.We have found that circular motions give us better results.Many papers suggest to use straight swiping motions to provide signif icant dif ferences between foreground and background motion in the video frames.Using such approaches,circular motion isnot preferable since circular motion alwaysincludes dif ferent movements.On the other hand,our method uses a conventional SfM approach to obtain camera poses leading to our LFR scheme.As a result,users may move their cameras more carelessly,and strictly straight motions are nor required,but at the same time,users need to move their cameras relatively slowly so as not to lose correspondences between frames.An acceptable speed depends on the distance from the fence to the user. This paper has presented an automated method for fence removal from video,using a framework of a combination of SfM-based fence detection and LFR-based background restoration.Allowing use of existing libraries for SfM and LFR,our method has advantages of simplicity and preserving view-dependent appearance in the video result.A qualitative evaluation shows that fences are effectively segmented by depth thresholding in the globally reconstructed space for most experimental scenes.Missing pixels are reliably recovered and the details are preserved using the fence-aware LFR.The final output isa video sequencewhich better preservesframe coherence than the other three comparative methods.The proposed method relies on the 3D point cloud from SfM for both fence segmentation and background restoration.Asa result,theuser’smotion during video recording isimportant.Appropriateuser guidance using augmented reality visualization will solve this issue but remains for future work. Acknowledgements This work was supported in part by Grant-in-Aid from the Japan Society for the Promotion of Science,following Grant No.16J05114. Electr onic Sup p lementary M ater ial Supplementary material is available in the online version of this article at ht t ps://doi.or g/10.1007/s41095-018-0126-8.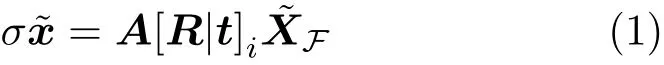
3.4 Background restoration




4 Evaluation
4.1 M ethod s for comp arison
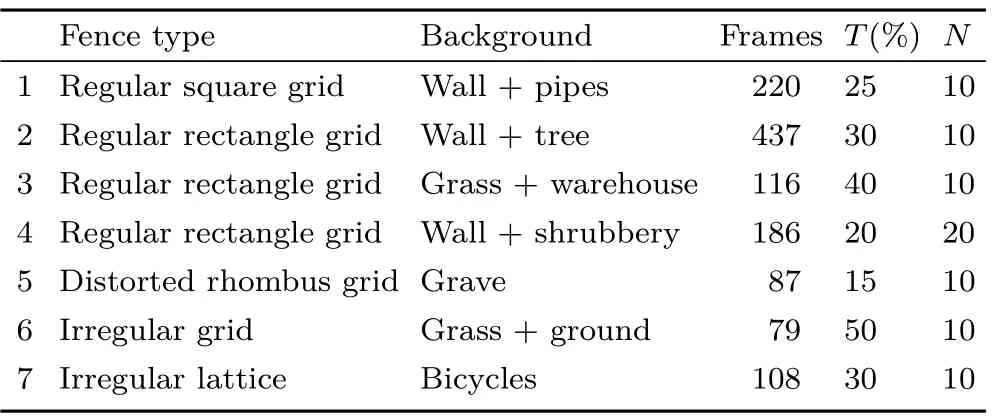
4.2 Dataset

4.3 Fence removal results and d iscussion








5 Conclusions
杂志排行

Computational Visual Media的其它文章
- BING:Binarized normed gradients for objectness estimation at 300fps
- Automated p ebble mosaic stylization of images
- Discernible image mosaic with edge-aware adaptive tiles
- Real-time stereo matching on CUDA using Fourier descriptors and dynamic programming
- Image-based app earance acquisition of ef fect coatings
- Recurrent 3D attentional networks for end-to-end active object recognition