A Multi-Feature Weighting Based K-Means Algorithm for MOOC Learner Classification
2019-05-10YuqingYangDequnZhouandXiaojiangYang
Yuqing Yang ,Dequn Zhou and Xiaojiang Yang
Abstract:Massive open online courses (MOOC) have recently gained worldwide attention in the field of education.The manner of MOOC provides a new option for learning various kinds of knowledge.A mass of data miming algorithms have been proposed to analyze the learner’s characteristics and classify the learners into different groups.However,most current algorithms mainly focus on the final grade of the learners,which may result in an improper classification.To overcome the shortages of the existing algorithms,a novel multi-feature weighting based K-means (MFWK-means) algorithm is proposed in this paper.Correlations between the widely used feature grade and other features are first investigated,and then the learners are classified based on their grades and weighted features with the proposed MFWK-means algorithm.Experimental results with the Canvas Network Person-Course (CNPC) dataset demonstrate the effectiveness of our method.Moreover,a comparison between the new MFWK-means and the traditional K-means clustering algorithm is implemented to show the superiority of the proposed method.
Keywords:Multi-feature weighting,learner classification,MOOC,clustering.
1 Introduction
The development of massive open online courses (MOOC) has been recognized as one of the most significant innovations in the field of education [Jacoby (2014)].It provides new courses at an unprecedented scale,both in terms of learner numbers and in terms of global reach [Pursel,Zhang,Jablokow et al.(2016)].Many data mining techniques have been proposed to group learners based on their learning style,approach,profile,prior knowledge,and so on [Shahir and Husain (2015); Wang,Yang,Wen et al.(2015);Papamitsiou and Economides (2014); Romero and Ventura (2017)].
Clustering techniques are the most popular techniques to group learners with similar categories allowing formulation of appropriate learning strategies for each group of learners [Dutt,Ismail and Herawan (2017); Cabedo,Tovar and Castro (2016); He,Ouyang,Wang et al.(2018); Zhang,Zheng and Xia (2018)].Using cluster analysis as a technical means can effectively identify and characterize the underlying features of MOOC learners [Cabedo,Tovar and Castro (2016)].Wang et al.[Wang and Fu (2018)]exploited the data mining tools to analyze learners’ behavior characteristics and then classify the learners into different groups.In [Gallén et al.[Gallén and Caro (2017)],a set of 26 questions was designed to investigate the learners’ motivation to study with MOOC,where the answer options of the questions were treated as cluster characteristic indexes.Yousef et al.[Yousef,Chatti,Wosnitza,et al.(2015)] adopted cluster analysis to analyze the different goals of users and establish a deeper understanding of their behavior.Gadhavi et al.[Gadhavi and Patel (2017)] utilized the data mining technology to group the MOOC learners and predict their final grade.Prabhakar et al.[Prabhakar and Zaiane (2017)] utilized a modified Particle Swarm Optimization technique to group the MOOC learners based on their grades and personal information,where the intra-group heterogeneity and inter-group homogeneity are both included to enhance the classification results.Harwati et al.[Harwati,Alfiani and Wulandari (2015)] exploited the k-means clustering algorithm to reveal the hidden pattern and classify students mainly based on their grade.
As analyzed above,most current methods exploit the learner’s final grade to judge and classify them.Note that many factors will influence the learner’s final grade in practice,thus it is difficult to obtain a comprehensive view of the state of the learner’s performance and simultaneously classify them into proper groups with the single feature.To address this challenge,we design a novel multi-feature weighting based K-means(MFWK-means) algorithm.Correlations between the grade and other features are first investigated,and then the learners are classified based on their grades and weighted features with the proposed MFWK-means.Experimental results with the Canvas Network Person-Course (CNPC) dataset demonstrate the effectiveness and superiority of our method.
2 The proposed MFWK-means clustering algorithm
2.1 Correlation analysis between the grade and other features
In this paper,we classify the MOOC learners into different categories based on their final grades and other features,such as learning hours,interactions with the course,and so on.In practice,these features are not independent and they may influence the final grade of a MOOC learner.In this part,we first analyze the correlations between them.For a more clear explanation,a widely used MOOC dataset-CNPC dataset is adopted here and in the subsequent experimental parts.This dataset is collected from the Canvas Network open courses (running January 2014-September 2015).These data include over 325000 aggregate records,and each record represents one learner's activity with 26 different features,including course ID,discipline,user ID,and so on.Among these features,some are related to the course information,and others are related to the learners study information.In this paper,we focus on the relationship between the final grade and the features corresponding to the learners.Thus,four features are selected for the analysis,including “completed”,“nevents”,“ndays” and “nforum”,where the meanings of these features are described in Tab.1.Note that in the original CNPC dataset,some records of the features are missing.After removing the invalid records,the total number of the records in our experiment is 5280.First,we analyze the correlations between the final grade and the four features by drawing a scatter plot of the feature values versus the grades,where the results are shown in Fig.1.

Table1:Feature attributes of the CNPC dataset

Figure1:Scatter plots of the feature values versus the grades.(a) Completed versus grade,(b) nevents versus grade,(c) ndays versus grade,and (d) nforum versus grade
From the scatter plots in Fig.1,we can summarize the following observations:(1) the feature “completed” greatly influence the learner’s final grade.In spite of some learners can obtain higher grade with doing less homework,but as a general trend the grade increases with a larger “complete” value.(2) The feature “nevents” slightly influence the learner’s final grade.From Fig.1(b) we can see that with the increase of the “nevents”value,the learner’s grade increase slightly.(3) The features “ndays” and “nforum” have the similar degrees of impact to the final grade.As shown in Figs.1(c) and 1(d),when the values of “ndays” and “nforum” increase,the final grade increases analogously.
By using the scatter plots,we analyze the relationship between the grade and the other features roughly.In order to quantitatively evaluate the correlations between these features,we adopt the Pearson Correlation Coefficient (PCC) measure [Zou,Zeng,Cao et al.(2016)],which can be written as:
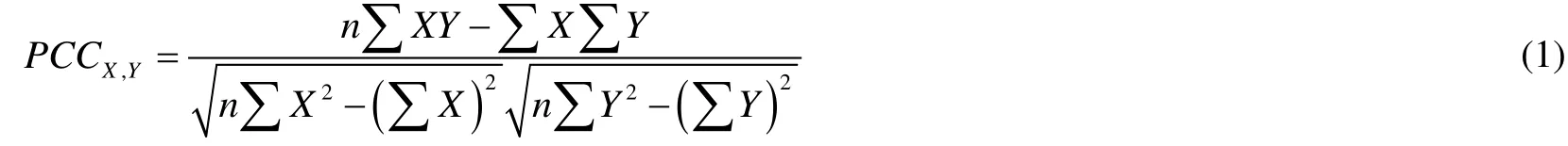
whereXandYrepresent two vectors andndenotes the number of the variables in each vector.We calculate the PCCs between the grade and the other four features by using Eq.(1),where the results are recorded in Tab.2.From the experimental results in Tab.2 we can find that the feature “completed” is more relevant to the final grade,while the feature“nevents” is less relevant to the grade,and the features “ndays” and “nforum” obtain similar PCC values.The conclusion is consistent with the scatter plot analysis.

Table2:Pearson Correlation Coefficient between the grade and other four features
2.2 The multi-feature weighting based K-means algorithm
K-means is a widely used clustering algorithm,which partitions a data set into K clusters by minimizing the sum of squared distance in each cluster.In traditional methods,the MOOC learners are usually classified based on their final grade.The using of a single feature in clustering algorithm may limit the objectivity and comprehensiveness of the classification process.To cover the shortage of the traditional clustering manner,we propose a novel multi-feature weighting based K-means algorithm in this paper.Based on the correlation analysis between the grade and other features,the proposed MFWK-means clustering algorithm can be implemented with the following four steps:
MFWK-means clustering algorithm
Step 1:initialization
Randomly select K points as initial cluster centers.
Step 2:assignment
Calculate the multi-feature weighting distance between each data point and each cluster center based on Eqs.(2) and (3),and then assign each point to the closest cluster center.
Step 3:update
Calculate the mean value of the data points for each cluster and update the cluster center,and then repeat Step 2 and Step 3.
Step 4:convergence
Stop when there is no change of the cluster centers or reaching a predefined number of iterations
In the proposed MFWK-means clustering algorithm,the multi-feature weighting distance can be formulated as:

wherec(k)represents the cluster centerk;gi(k)represents theith multi-feature weighting data point in the clusterk,which is composed of the learner’s final grade and other related features.In the proposed method,the multi-feature weighting data vectorGcan be defined as:

in whichF0represents the value of the grade,andFtdenotes the utilized related features,andTis the number of the related features.In Eq.(3),the weightwtis defined by measuring the correlation between the selected featureFtand the final gradeF0.In our method,we use the PCC defined in Eq.(1) to calculate the weights.
3 Experimental results
Equations and mathematical expressions must be inserted into the main text.Two different types of styles can be used for equations and mathematical expressions.They are:in-line style,and display style.In order to verify the effectiveness of the proposed MFWK-means clustering algorithm,the widely used CNPC dataset is utilized in our experiment.First,the MFWK-means clustering algorithm is adopted to classify the MOOC learners in to different groups.Besides the feature “grade”,another four features“completed”,“nevents”,“ndays”,and “nforum” are also used in the proposed algorithm.The weight of each feature is calculated according to Eq.(1),and the MFWK-means algorithm is implemented based on the steps described in Section 2.2.Note that due to the various scales of the utilized features,we normalize each feature to the range [0 ,1]
based on the Eq.(4):

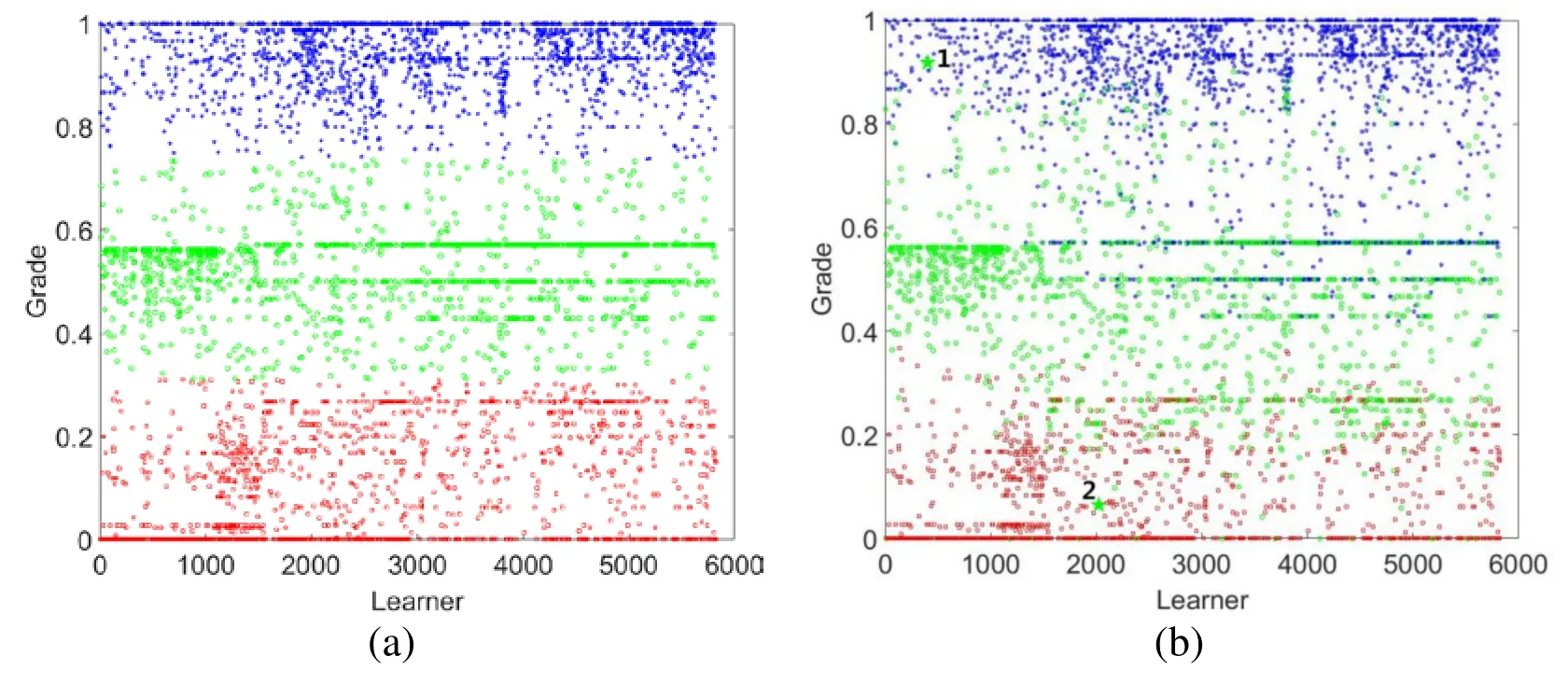
Figure2:MOOC learner classification results with different clustering algorithms.(a) K-means,(b) MFWK-means
In Figs.2(a) and 2(b),the blue points represent the “Good Learner” group,the green points corresponding to the “Ordinary Learner” group,and the red points denote the“Poor Learner” group.As shown in Fig.2(a),the traditional K-means algorithm classifies learners strictly according to their final grade.From Fig.2(b) we can see that the classification results of our algorithm is similar to Fig.2(a) in general,but some learners are classified into different groups with the following 4 cases:(1) a learner is classified into a “Ordinary Learner” group with high grade; (2) a learner is classified into a “Good Learner” group with medium grade; (3) a learner is classified into a “Poor Learner” group with medium grade; (4) a learner is classified into a “Ordinary Learner” group with low grade.This is mainly because in the proposed MFWK-means clustering algorithm,we utilize various features besides the learner’s grade,and meanwhile,each feature is assigned with a weight factor based on the correlation between the feature and the grade.To better analyze the classification results with the proposed MFWK-means algorithm,we choose two typical points in Fig.2(b) for a detailed analysis.As shown in Fig.2(b),the points 1 and 2 are denoted with green pentagon,in which point 1 is corresponding to the case (1),and point 2 is corresponding to the case (4).For a better explanation,we plot the scatter plots to show the various aspects of learner’s conditions,which are shown in Figs.3 and 4.From Fig.3 we can observe that although the learner got a high grade(0.918),the values of the related features are extremely low compared to other learners.Taking into consideration of various aspects of the learner’s study process,it is more proper to classify the learner into “Ordinary Learner” class.For the point 2 in Fig.4,the opposite is happened.In spite of the learner obtained a low grade (0.042),the other aspects of this learner are excellent,thus the learner is also classified into “Ordinary Learner” class.As analyzed above,the proposed MFWK-means clustering algorithm can obtain a more comprehensive view of the state of the MOOC learners,and further result in a more correct classification.

Figure3:Various aspects of learner’s conditions with point 1.(a) Completed,(b)nevents,(c) ndays,and (d) nforum
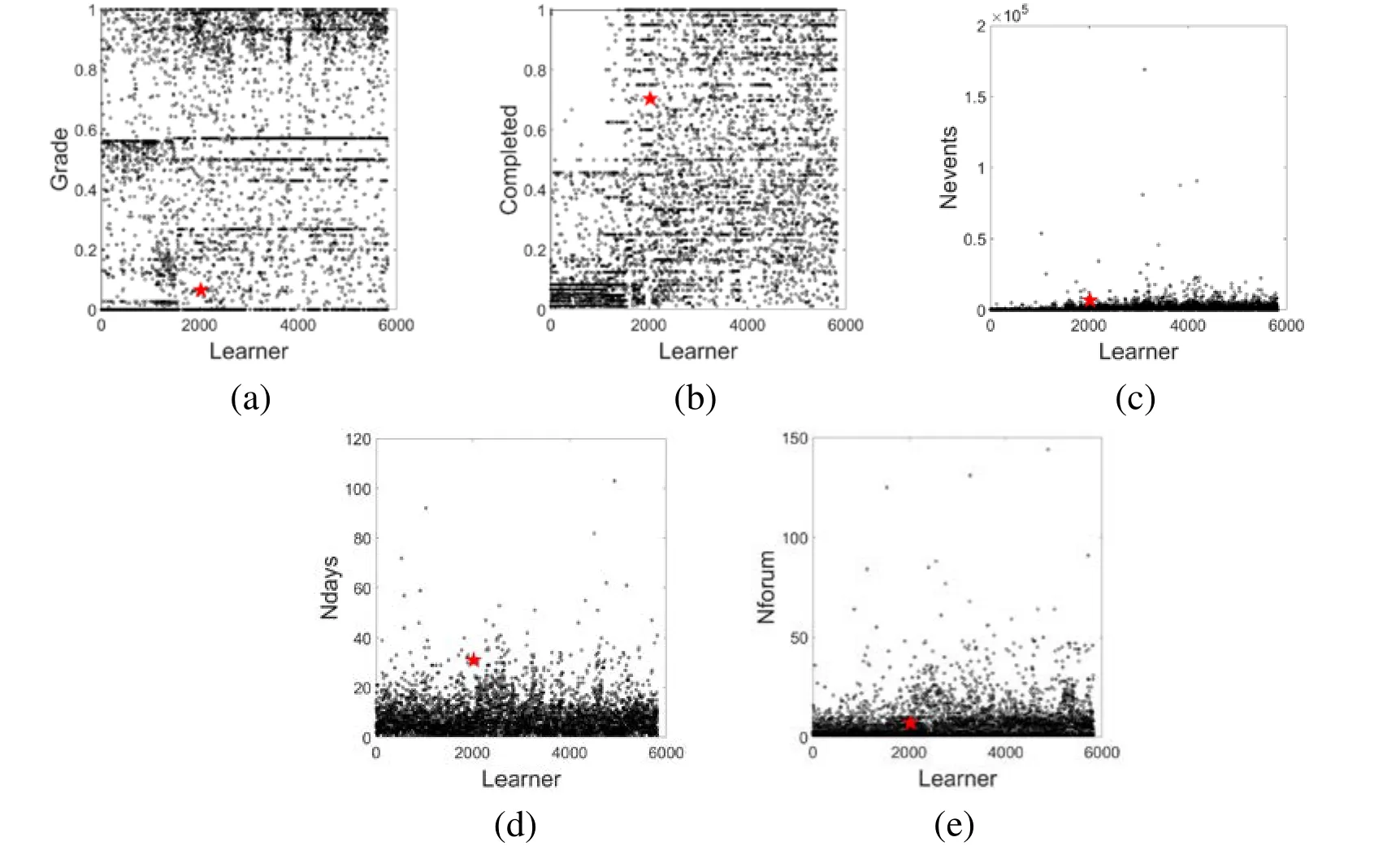
Figure4:Various aspects of learner’ conditions with point 2.(a) Completed,(b)nevents,(c) ndays,and (d) nforum
4 Conclusion
In this paper,we propose a novel multi-feature weighting based K-means algorithm to classify the MOOC learners into different groups.In order to comprehensively exploit the final grade and other various features of the learners,correlations between the grade and different features are first investigated.Then,the learners are classified based on their grades and weighted features with the proposed MFWK-means algorithm.Experimental results demonstrate the effectiveness and superiority of our method.In future works,more advanced data miming technologies can be investigated to analyze the learner’s characteristics,such as deep learning networks,which may further improve the MOOC learner classification accuracy.
杂志排行

Computers Materials&Continua的其它文章
- Security and Privacy Frameworks for Access Control Big Data Systems
- A Data Download Method from RSUs Using Fog Computing in Connected Vehicles
- Quantitative Analysis of Crime Incidents in Chicago Using Data Analytics Techniques
- A Deep Collocation Method for the Bending Analysis of Kirchhoff Plate
- Privacy-Preserving Content-Aware Search Based on Two-Level Index
- A Distributed ADMM Approach for Collaborative Regression Learning in Edge Computing