Privacy-Preserving Content-Aware Search Based on Two-Level Index
2019-05-10ZhangjieFuLiliXiaYulingLiuandZuweiTian
Zhangjie Fu ,Lili XiaYuling Liu and Zuwei Tian
Abstract:Nowadays,cloud computing is used more and more widely,more and more people prefer to using cloud server to store data.So,how to encrypt the data efficiently is an important problem.The search efficiency of existed search schemes decreases as the index increases.For solving this problem,we build the two-level index.Simultaneously,for improving the semantic information,the central word expansion is combined.The purpose of privacy-preserving content-aware search by using the two-level index(CKESS) is that the first matching is performed by using the extended central words,then calculate the similarity between the trapdoor and the secondary index,finally return the results in turn.Through experiments and analysis,it is proved that our proposed schemes can resist multiple threat models and the schemes are secure and efficient.
Keywords:Semantic search,two-level index,expanded central-keyword.
1 Introduction
Today,heterogeneous Internet of Things is applied popularly [Qiu,Chen and Li (2018)].Zhang et al.[Zhang,Li and Dai (2018)] proposed a public verifiable outsourcing scheme based on matrix multiplication in the Internet of Things environment.Many people are preferring to storing data in the cloud.Yang et al.[Yang,Xu and Weng (2018)] provides a lightweight proof of storage for privacy protection.To utilize the data in the cloud efficient,cloud computing is widely developed.Cloud computing,not only reducing the local data maintenance costs,but also provide simple and efficient calculations.In addition,cloud computing gives a convenient way to share resources between data owners and legal data users.
Some scheme [Li,Liu and Chen (2015)] can protect the security of data search at some degree.However,cloud servers are not completely honest.Cloud servers enforce system protocols and capabilities honestly,but they guess the content of important files stored on them actively.The existing solution is to encrypt the data before uploading.However,how to effectively search encrypted data is an important issue.
At present,there are too many researches on ciphertext search by domestic and foreign experts.Song et al.[Song,Wagner and Perrig (2002)] proposed a searchable encryption method which must encrypt the data set for each query,in each query,the data set needs to be fully scanned make the computational consumption enormous.At the same time,this method cannot resist statistical analysis attacks.Dan et al.[Dan,Crescenzo and Ostrovsky(2004)] proposed a keyword search scheme based on public key encryption.This scheme is also aimed at the matching of keywords and ciphertexts,but the scope of utilization is too small.After that,Li et al.[Li,Wang and Wang (2014)] proposed a wildcard-based ciphertext search method to achieve fuzzy search to a certain degree,but it needs the support of the semantic library.A new scalable dynamic access scheme is proposed in Weng et al.[Weng,Weng,and Zhang (2018)].At present,most of the research on indexbased ciphertext search methods use tree index structure to improve the search efficiency.Fu et al.[Fu,Sun and Liu (2015)] proposed a search scheme to improve efficiency by using k-d tree.Leslie et al.[Leslie,Jain and Birdsall (1995)] proposed an efficient query scheme based on multi-dimensional B tree.Ciaccia et al.[Ciaccia,Patella and Rabitti (1997)] used M-tree to construct index metric space which improved search efficiency.Kurasawa et al.[Kurasawa,Takasu and Adachi (2008)] proposed a Peer-to-Peer (P2P) information search scheme based on Huffman distributed hash table.The index structure was changed by Huffman coding to reach the load balancing.However,the data preprocessing consumes too many computing and storage resources.Xu et al.[Xu,Li and Dai,(2019)] proposed an efficient geometric range query scheme.
In this paper,we put forward the privacy-preserving content-aware search by using the two-level index (CKESS).We build a novel two-level index framework based on the existed forward and reverse indexes,which can improve the search efficiency.Simultaneously,for improving the search precision,our program has expanded the central word of the trapdoor.The basic framework of privacy-preserving content-aware search by using the two-level index has been proposed firstly.And we propose two search schemes that can resist different threats.Followings are the main contributions of the paper.
1.We propose the privacy-preserving content-aware search by using the two-level index (CKESS) to reduce the impact of the number of files on the search time.The difference from the existed index is matching the trapdoor with the first-layer index instead of the file set,which greatly improves our search efficiency;
2.In order to be close to the user's semantic requirements,we have semantically extended the central keyword of the trapdoor based on the two-level index,thus improving the search precision.Our scheme first uses the extension of the central word of the trapdoor to match the first index.After that,the similarity between the secondary index and the trapdoor keyword is calculated,and finally the result is returned in order.
3.Through experiments and analysis,it shows that our scheme can effectively resist different threat attacks and prove the efficiency,accuracy and security of the scheme.
The following are the arrangements for the other sections of this paper.In the Section 2,we introduce the related work.We arrange the system model,threat model,and implementation goals of the program in the third section.The fourth part is mainly to describe the main content of the index construction and schemes implementation.The fifth part analyzes the security of the program.The final part is the experimental analysis and the summary of the article.
2 Relation work
2.1 Multi-keyword search
In 2011,Cao et al.[Cao,Wang and Li (2014)] first proposed a secure multi-keyword search solution (MRSE) that resisted two threat models (known ciphertexts and known backgrounds).The solution used vector space model and secure inner product to sort after the search results.In 2014,they proposed improvements and added TF / IDF algorithm to improve the search accuracy.Yang et al.[Chen,Huang and Li (2015)] proposed to use the trapdoor concept to search all encrypted documents.Fu et al.[Fu,Sun and Linge(2014)] proposed multi-keyword sorting search scheme supporting synonym query in cloud environment.These programs to achieve a multi-keyword search,expanded ciphertext search capabilities.In terms of efficiency and accuracy of multi-keyword search,Chen et al.[Liang,Huang and Guo (2016)] used sparse matrices to achieve a safe large-scale linear equation,further improving the retrieval efficiency.In 2016,Liang et al.[Li,Yang and Luan (2016)] proposed that search based on regular language is more efficient than other search schemes.In the same year,Li et al.[Wang,Li and Wang(2015)] proposed a multi-keyword search based on the fine-grained,which improved the accuracy and efficiency of the search scheme through sub-dictionaries and preference factors.To combat the Selective Chosen-Plaintext Attacks,Wang et al.[Li,Liu and Wang (2016)] proposed a SE-based range search in 2015.In 2016,Li et al.[Chuah and Hu (2011)] proposed the first range query solution that can defend against selective keyword attacks (IND-CKA).Li et al.[Li,Chen and Chow (2018)] proposed a privacyaware multi-keyword attribute encryption scheme that hides attribute information in ciphertext and allows tracking of non-honest users who have keys.Combining kNN and attribute encryption,a dynamic search symmetric encryption scheme is proposed in Li et al.[Li,Yang and Dai (2017)].Gao et al.[Gao,Cheng and He (2018)] proposed to combine the double-blind technology with the addition of homomorphic encryption to realize the privacy protection of both parties.Li et al.[Li,Liu and Dai (2018)] proposed an efficient searchable symmetric encryption scheme in mobile cloud environment.
2.2 Semantic search
Li et al.[Li,Wang and Wang (2014)] propose a single fuzzy keyword search scheme by using edit distance.Chuah et al.[Chuah and Hu (2011)] implement fuzzy search based on pre-defined word set as a whole,and propose a fuzzy search scheme to achieve secure search for multi-keywords.Kuzu et al.[Kuzu,Islam and Kantarcioglu (2012)] designed a similar search scheme using minhash based on Jaccard distance.Fu et al.[Fu,Shu and Wang (2015)] proposed similarity search scheme for encrypted documents based on simhash.Wang et al.[Wang,Yu and Zhao (2015)] proposed a fuzzy search based on multi-keywords for achieving range query using a sequence reservation encryption and two-layer Bloom.Huang et al.[Huang,Fu and Sun (2016)] combined gene sequences with secure searchable indexes to propose a secure searchable encryption scheme.Our earlier work [Fu,Wu and Guan (2016)] used a new keyword transformation to get a better accuracy.Fu et al.[Fu,Wu and Wang (2017)] improved accuracy by using center word expansion.Fu et al.[Fu,Xia and Sun (2018)] proposed the conceptual hierarchical semantic search scheme under dual servers.
3 Problem formulation
3.1 System model
Fig.1 shows that our system model is mainly composed of the following three entities.
Data owner:The data owner is the person who owns the source data.To facilitate search,they need to build efficient indexes based on the data.Finally,the source data and the index are encrypted and uploaded to the cloud server.
Cloud server:Storing and managing the encrypted data received are the main work of the cloud server.Upon receiving the user's retrieval request,the data is processed and the results are returned in turn.
Data user:The data user who received a secure authorization certificate processes the query to generate a corresponding trapdoor and uploads it to the cloud.
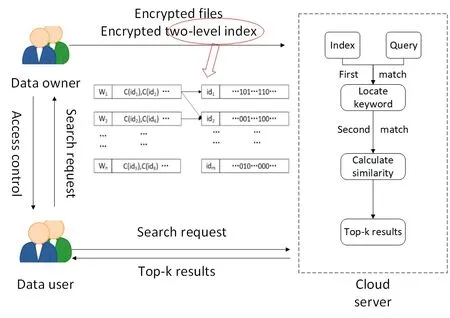
Figure1:The system model
3.2 Threat model
In the overall system model,we believe the data owner and user are honest and trustworthy,but the cloud server is not completely trusted.As the references describe[Cao,Wang and Li (2014)],the cloud server can execute programs accurately without tampering with the DO and DU instruction sets; however,it can collect keyword information and deduces the contents of the file by analyzing the relationship between trapdoor functions.Therefore,according to different privacy requirements,our threat model is as follows.
Known Ciphertext Model:The uploaded information of files,indexes,and trapdoor is easy to get for the cloud server,but it does not understand the meaning.
Known Background Model:Apart from file data,indexes,and trapdoors,the cloud also understands some background information,including file statistics,keyword frequency,and the relationship between keywords and query.With this extra information,the cloud server can speculate on some ciphertext information.
3.3 Design goal
Due to the above threat models,the design goals of this paper are as follows:
1.Scalability.We hope to implement the expansion of the central keywords,that is to say,after the user enters the search keywords,the center word can be found quickly and located accurately,and the semantic expansion of the central keyword can be achieved.The result returned must be related to the central word and its extension.
2.Efficiency.Considering the data processing of cloud servers,our approaches are designed that document size has independence.In simple terms,the relationship between the search time and fileset size should be sub-linear.
3.Privacy protection.Our schemes should provide privacy protection of data information of filesets or keywords during cloud search.
4.Results accuracy.This paper focuses on semantic search,so the accuracy of the search results is extremely important.Our solution should improve the retrieval accuracy as much as possible to achieve a higher standard.
3.4 Preliminaries
Stanford Parser.Stanford parser is basically a lexicalized probability context-free parser,and also uses dependency analysis.Different analysis results can be output according to different grammatical points.The parser uses the knowledge of the language obtained from the parsing of the sign language to get the appropriate analysis of the new sentence.
WordNet.WordNet is a huge English vocabulary database [Miller (1990)].Nouns,verbs,adjectives and adverbs are each organized into a network of synonyms.Each synonym set represents a basic semantic concept,and these sets are also connected by various relationships.The resulting meaningful vocabulary and conceptual network can be browsed through the browser.
Locality-Sensitive Hashing.The local sensitive hash(LSH)algorithm [Har-Peled,Indyk and Motwani (1998)] is mainly used to solve the nearest neighbor search problem efficiently.The basic idea of this algorithm is to map datasets to different collision buckets of multiple hash tables through a set of hash functions that meet certain constraints,then establishing multiple hash tables.So,under certain similarity measures,the points which are closer to the same conflict bucket (the higher similarity) have the greater probability,and the points which are farther to the same conflict bucket (the lower similarity) have the smaller probability.In this way,the data set is divided into multiple sub-sets.The data in each sub-set is adjacent and the number of the sub-set is small.So the problem of finding adjacent elements in a very large set is transformed to find adjacent elements within a small set.This method reduces the amount of data to be compared greatly when we do a search.We deem that a hash function familyHis (d1,d2,p1,p2)-sensitive if for random inputs ofandatisfy the following:

4 Secure search scheme
4.1 Main innovative idea
In order to achieve a secure and efficient encryption search scheme,three important design choices must be made,all of which are closely related and to some extent determine the performance of the search solution.First,the data structure used to construct the file index; second,an efficient search scheme that enables a good match between the query keywords and the file index; and finally,a secure privacy mechanism that combines with the first two design choices to protect the privacy of files and retrieving privacy.
Based on the above design choices,we propose privacy-preserving content-aware search based on two-level index.A secure two-level index for the file set is built and encrypted before uploading to the cloud.The trapdoor is constructed on the data user side and the data user provides the query keyword.We first locate the central word of the query keyword,then extend the central keyword,and upload the extended keywords to the cloud encryption.The mainly work of the cloud server is searching.When the cloud server gets the trapdoor from the user,in the first-level matching,the cloud server matches the extended keyword with the index keyword.Without loss the search accuracy,the search range is reduced.In the second-level matching,the other keywords in each file are matched with other non-central keywords in the trapdoor.Finally,the results are sorted and returned to the data user.
In this section,we detail the scenario.We first introduce the central keyword expansion algorithm in plaintext mode and the two-level index construction algorithm,and then propose the complete schemes in ciphertext mode.
4.2 Central keyword extension
In the actual situation,the user usually inputs a string of keywords to make a query,and when the user searches different targets,the weight of each keyword is different.There have been many achievements in the study of the importance of keywords.[Li,Yang and Luan (2016)] use a method of super-increasing sequence to order the keywords.In this way,getting the order of the query keywords’ importance is easily.However,this method requires the user to sort the keywords according to the user's expected value of the keyword.The disadvantage of this approach is that defaulting importance to the order of all keywords.Our early work Fu et al.[Fu,Ren and Shu (2016)] proposed to establish a unique interest model for different users,and use the grammatical relationship tree to measure the weight of keywords input by the user.In this way,a search that satisfies the needs of the user is realized.
Definition of relationship:The relationship contained in the keyword reflects the user preference information.Keywords with more semantic relationships necessarily reflect more user information,so the weight of the keyword is heavier.So,we have the definition 1.
Definition 1:For each keyword,we assign it an initial importance of 1.Assuming that the keyword has grammatical relationships with another keyword,we change its value to 1+R (relation),where R represents the total importance of the relationship between two keywords.
The semantic relationship of keywords is expressed as a connection between different words on the grammatical relationship tree.The shorter the distance of this connection,the more similar the meaning of the words.Therefore,we can quantify the importance of the grammatical relationships between keywords by using the distance between the keywords in the grammatical tree.However,the relationship is mutual,so the value of the importance should be divided into two parts.So we have the definition 2.
Definition 2:For the two keywordsand,there is a semantic relation A between them,and the interest preferences of the user included inis,whererepresents the distance of the keywords in the semantic relation tree.The increased importance ofis,andis the increased importance of,whereandare the distance between the keywords and their ancestor,and the total betweenandis.
Note that,although prepositions are often used in articles and phrases to indicate the relation between two keywords,prepositions cannot be an independent part of a sentence.Therefore,when we calculate the importance of grammatical relations,such keywords do not be included.
Definition 3:For an independent query,the total weight of the grammatical relation is,whererepresents the number of query keywords contained in this query.For a keyword,s its weight,in whichmeans the percent of the importance of the keywordin the query.So we can get the keyword weight of the keywordas follow


Figure2:The grammatical relationship tree of “black shirt made in silk”
Decision of central keyword:To represent the grammatical relations,we use the Stanford parser in this paper.The function of the Stanford parser is to transform keywords into a grammatical relationship tree.Through this tree,the grammatical relationship between words is clearly expressed.For instance,Fig.2 shows the grammatical relationship tree of“black shirt made in silk”,in which “NP” represents the noun phrase,“NN” represents the noun,and “JJ” represents an adjective or a number,and so on.
We calculate the distance d between two keywords in the grammatical tree to indicate the importance of the relation between two keywords.As the Fig.2 shown,the distance between “black” and “shirt” is 4,so.Since each relation is shared by two keywords,we divide each relationship into two parts according to the following rules:,,whereis the distance between the first keyword and the ancestors of the two keywords,as the same,the distance between the second keyword and the ancestor of the two keywords is.Since the weight of each keyword has been calculated by this way,we choose the keywords which have the highest weight as the central keywords.
Extension of central Keywords:For the same meaning,there may be many different words to express,for example,“blouse” and “shirt” mean the same thing.When the user queries one of the words,if the word is not in the server,the result will not be returned.In this case,the user needs to change a synonym and search again,which wastes the search cost.Existing solutions either increase the index build cost or extend the keyword in a small range.
Therefore,we calculate the weight of keyword to get the central keyword.Then,we expand the central keyword.In this way,we not only ensuring the results of user search,but also ensure that trapdoor generated efficiency.So,we should balance the relationship between efficiency and functionality.
We use the central word as the benchmark to calculate the weight of each extended word.The higher the weight,the closer the meaning of the extended word,and the higher the quality of the expansion.
We use Lin’s measure [Wong,Cheung and Kao (2009)] to calculate the similarity between the keywords A and B,and the calculated similarity is:
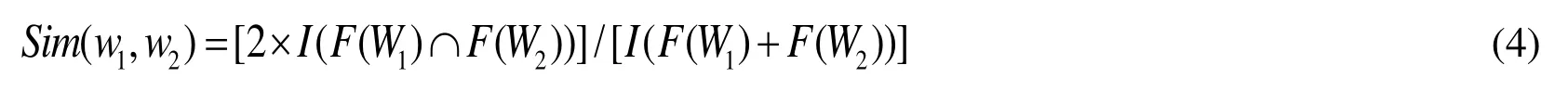
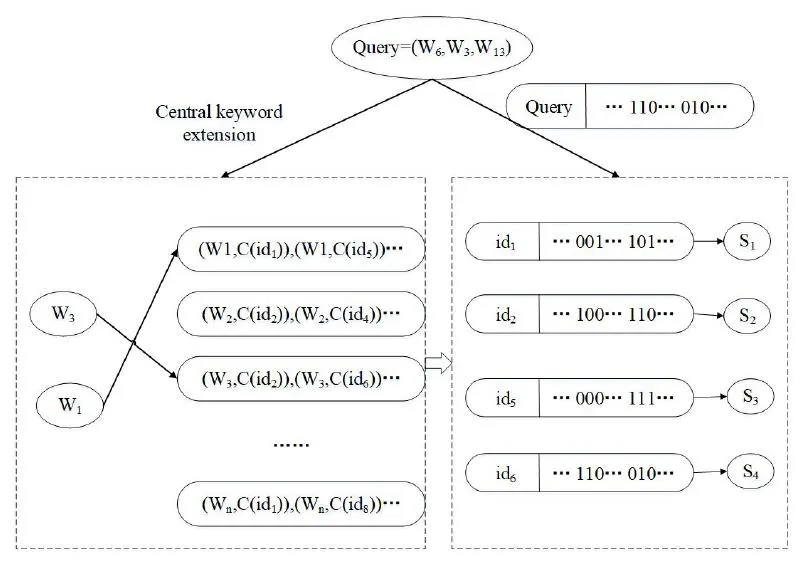
Figure3:The framework of our scheme
4.3 Two-level index framework
Most of the existing index construction methods build reverse indexes to facilitate searching.However,this index construction method still has a lot of space for improvement in efficiency and precision.Therefore,this paper proposes a new search index called two-level index.This index construction method is mainly to index the file set twice with different tags.The construction of the first-layer index is based on keywords,and the index of keyword to file set is constructed; the second-layer index is based on a single file,and the index of a single file to keyword set is constructed.
For improving efficiency and accuracy,our index is divided into two steps when matching.First,the keyword expanded by the central word is matched with the first layer index,thereby narrowing the file range,and then the similarity calculation is performed on the filtered file and the trapdoor,and the result is sequentially returned to the user.
As shown in Fig.3,by matching the extended keywordwith the first-layer index,the file set that needs to be further matched is narrowed down to.After that,the similarity calculation is performed on each file and the trapdoor in the second-layer index.As shown in Fig.3,,,andare the final similarity scores,which is sorted and returned to the user.The higher the score,the more consistent with the user’s needs.
4.4 CKESS1 scheme:secure scheme under the known ciphertext model
Our solution combines two-level index and central keyword expansion on the basis of MRSE [Cao,Wang and Li (2014)].We describe our scheme under the known ciphertext model in detail in this section.We extend each vector todimensions.The extended dimension adds complexity to the index,making it difficult for cloud servers to guess trapdoors and file information.The main algorithms of our scheme are shown as follow.
KeyGen:Given the security parameterand the file set F with the keyword set,the keyis generated safety.The data owner generates the SK.We get two random sequences.re twoinvertible matrices andis a vector.
Index Construction:For a file set F given a set of keywords,the data owner initializesandto an empty array in order to obtain the inverted indexand the forward indexat the same time.Then,for each of the keywords in W,the data owner uses the key to encrypt the file identifier,and the LSH is used in the Bloom filter.The data owner encrypts the file ID and appends them to setand then sets all positions into 1.Finally,encrypting the Bloom filter in the secondary indexusing secure kNN encryption with[Yang,Liu and Li (2015)].The indexis divided into two vectorsFor each elementletifuals 1;otherwiseis a random number,thenis represented ast last,the data owner gets Index =,and uploads the index and the encrypted file set to the cloud.
Trapdoor Generation:The user inputs the query Q,and performs a weight calculation for Q to obtain the central word.Then uses WordNet to expand the central word.So,the user getsthe extension query.The data user encryptsand builds a Bloom filterfor that,we divide the Bloom filterinto two vectors,:Ifequals 0,then set; otherwise,is another random number.Finally,token=btained and uploading to the cloud,where K is the result thatdoes the pseudo-random function.
Search:The cloud server uses the index to match the trapdoor.First,the cloud server get the encryption identifiers in,and matches thewith theto get the intermediate results.Then,Token is decrypted by K,and retrieved the Bloom filter=nd the cloud server obtains the secret key K but it does not disclosure any information except the search result of.This leakage can be acceptable because the search result ofare not the sensitive data.It is easy to get the inner product betweenand.

Then,the server returns the results based on the inner product to the user in turn.
4.5 CKESS2 scheme:Secure scheme under the known background model
Under this model,the cloud server not only knows the information,but also has a certain understanding of the background environment.Through background information such as text analysis and word frequency,the cloud server can speculate on trapdoors and indexes.In order to resist this threat,we propose the following scheme.
KeyGen:The algorithmis basically the same as the previous one.The only difference is that k hash keys are inserted into SK.We get SK=.Index Construction:Due to the change of the SK,the secret key need to re-generated and the vectorof each keyword should be calculated again.Then,data owner encrypts the Bloom filter in the secondary indexusing secure kNN encryption with.The indexis divided into two vectorsccording to the same rules.So,is represented ast last,the data owner gets Index=nd uploads the index and file set to the cloud.
Trapdoor Generation:Compared with the CKESS1,the difference in the algorithm is that the pseudo-random function is modified by using k hash keys,andis changed into.Finally,we represent the token as
Search:In this algorithm,the cloud server compute matches thewith thefirstly,and obtains the intermediate results.Then,according the intermediate results,the cloud server compute the similarity score between theand the.At last,the cloud server returns the top-k results to data user.
5 Security analysis
This paper is mainly to conduct security analysis from the following aspects.
Privacy:In this paper,the documents need to be encrypted before uploading to the cloud.We make use of the secure encryption framework MRSE to encrypt the documents [Cao,Wang and Li (2014)].So,our data privacy is protected well.
This paper uses pseudo-random functions,secure encryption algorithms and KNN algorithm to encrypt keywords,file sets and Bloom filters securely.This prevents the Plaintext Leakage.Due to the increase of random numbers,the cloud server cannot know any trapdoor information (whether different trapdoors are generated by the same search request),except that different trapdoors retrieve the same keyword at the first search.At the same time,in the second search,all query keywords are used to match,so the cloud server cannot know the query results.
Confidentiality:Since the index and trapdoors are encrypted in the cloud server,they are not obtained by the cloud server.This encryption algorithm has been proved to be safe in the known ciphertext model [Yang,Liu and Li (2014)].However,we added k hash keys to improve the encryption algorithm for security under the known background model.
Unlinkability:We introduced k hash keys when splitting the vector,so that the same search request can get different trapdoors.And the random hash key makes the similarity scores different.Trapdoor unlinkability can be guaranteed by using this method.
6 Performance analysis
In this section,we experimented with different scenarios to verify performance.We do these experiments under Windows 7 by using Java language,and the specific CPU parameters is Core 2 CPU 2.93 GHz.
6.1 Precision
In order to improve the semantic precision of the scheme,we have expanded the keywords.In order to evaluate the precision of the scheme,two probabilities have been set,pr1 and pr2,where pr1 represents there is single-character different between the keywords,and pr2 is multi-character.As the Fig.4 shown,when c is the same,pr1 decreases with the number of functions increases,and pr2 is reversed.When the number of functions is constant,pr1 increases as c increases,and pr2 is reversed.So we need to strike a balance between pr1 and pr2.
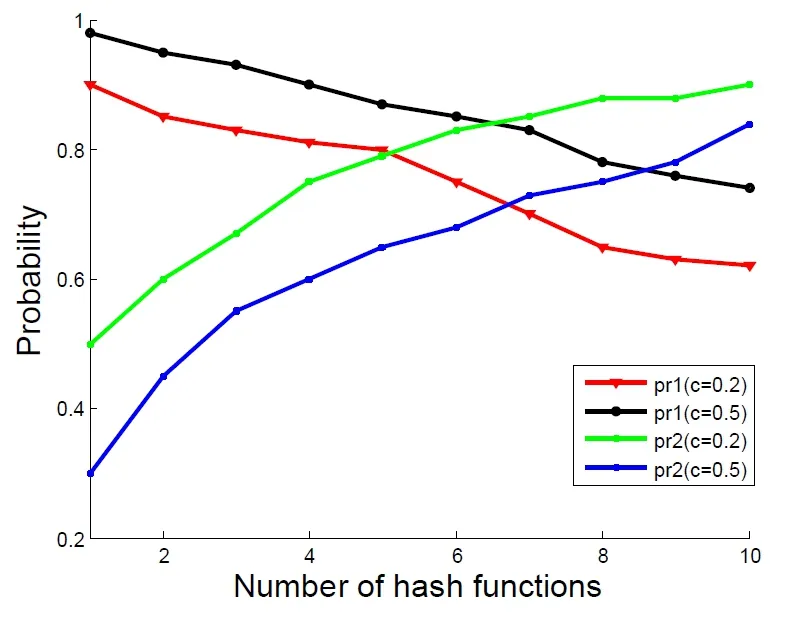
Figure4:Precision of scheme
6.2 Index construction
When constructing and encrypting index vectors,the dimension of the index vector is the important factor that affect the index constructing.As shown in Fig.5,because we use the high-dimensional submatrix to build the secret matrix when encrypting the index,this makes our index construction time much better than MRSE.In addition,there is a positive linear relationship between the index build time and the number of file sets.Since the dimension of CKESS2is more than CKESS1,the build time is higher than CKESS1.
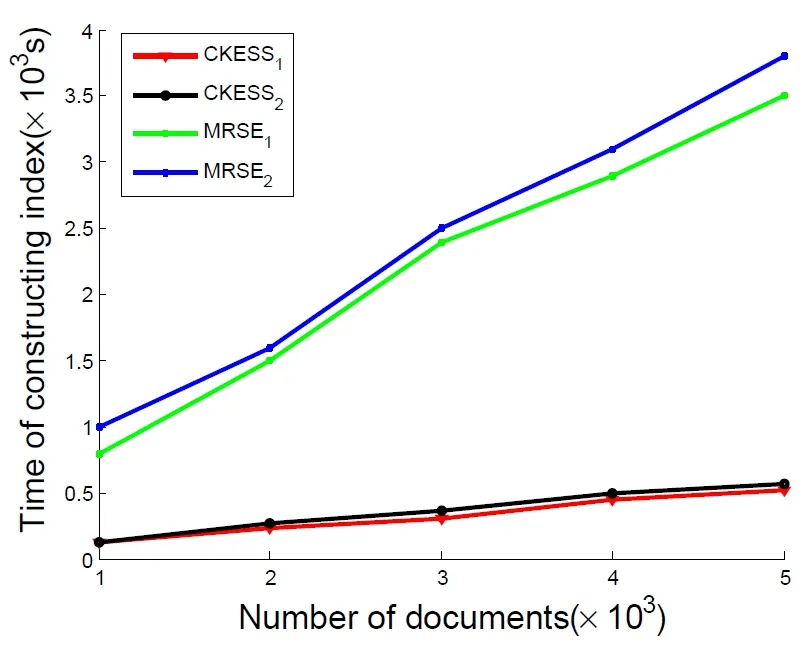
Figure5:The time of Index construction
6.3 Query generation
The time of trapdoor generation mainly includes the confirmation of the central keyword,the extension of the central word,the calculation of similarity,the construction of the query vector and the encryption of query vector.As seen from Fig.6,the build time of MRSE is not increase as the query keyword increases,but our schemes are opposite.The main reason is that our schemes contain the time of expanding the central keyword.With the increase of query keywords,the time taken for the expansion of the central word is also increase.And due to the high dimension,CKESS2cost more time than CKESS1.

Figure6:The time of query generation
6.4 Search efficiency
As the most important performance indicator of the schemes,Fig.7 shows the search time of the scheme.From Fig.7,we can see that with the increase of file sets,MRSE are linearly increase,but CKESS are increased slowly.The reason for it is that MRSE traverse all files in the cloud for each search,while the search time of our schemes mainly depends on the results of the first screening.As the file sets grows,the result of the first screening increases as well,which makes the whole search time grow.

Figure7:The time of search efficiency
7 Conclusion
In this paper,we propose privacy-preserving content-aware search by using the two-level index.The scheme makes the two-level index and expands the central word for improving efficiency and accuracy.At first,through the matching of the central extension word and the first layer index,the file set range is reduced.Then,the similarity calculation is performed on the file set and the trapdoor.Finally,the top-k file is returned to the user.Through experimental analysis,we verify our solution is more efficient,precise and secure than the existed.
杂志排行

Computers Materials&Continua的其它文章
- Security and Privacy Frameworks for Access Control Big Data Systems
- A Data Download Method from RSUs Using Fog Computing in Connected Vehicles
- Quantitative Analysis of Crime Incidents in Chicago Using Data Analytics Techniques
- A Deep Collocation Method for the Bending Analysis of Kirchhoff Plate
- A Distributed ADMM Approach for Collaborative Regression Learning in Edge Computing
- A Noise-Resistant Superpixel Segmentation Algorithm for Hyperspectral Images