基于概念格的数字图书馆用户知识序列模式挖掘研究
2019-04-25郑州工业应用技术学院图书馆
宇 婷(郑州工业应用技术学院图书馆)
1 引言
随着网络技术和计算机的发展,图书馆的发展也是日渐提高,目前,用户对于图书馆的检索要求更高,迫切的需要一个智能化的检索系统,满足用户快速检索到自己需要的图书内容,而数字化的图书馆检索系统,就可以满足用户对于智能检索的要求,这种控制系统也是目前图书馆智能化发展的中心。[1]在现代图书情报学,研究数字图书馆日渐变的重要,基于多学科技术和理论的支撑,数字图书馆的研究获得一定的发展空间。[2]在数字图书馆用户服务建设中,关于序列模式挖掘的研究则比较少,原因是因为挖掘工作因传统序列模式挖掘活动时间因素变的非常复杂。[3-5]在现实生活中,序列模式对用户能够快速的查找到自己所需的图书具有指导意义。[6]本文基于概念格的数字图书馆,对用户知识序列模式挖掘进行了研究,目的是基于数字图书馆用户检索行为中的挖掘序列模式,对数字图书馆用户服务进行完善和改进。
2 关联规则挖掘技术路线
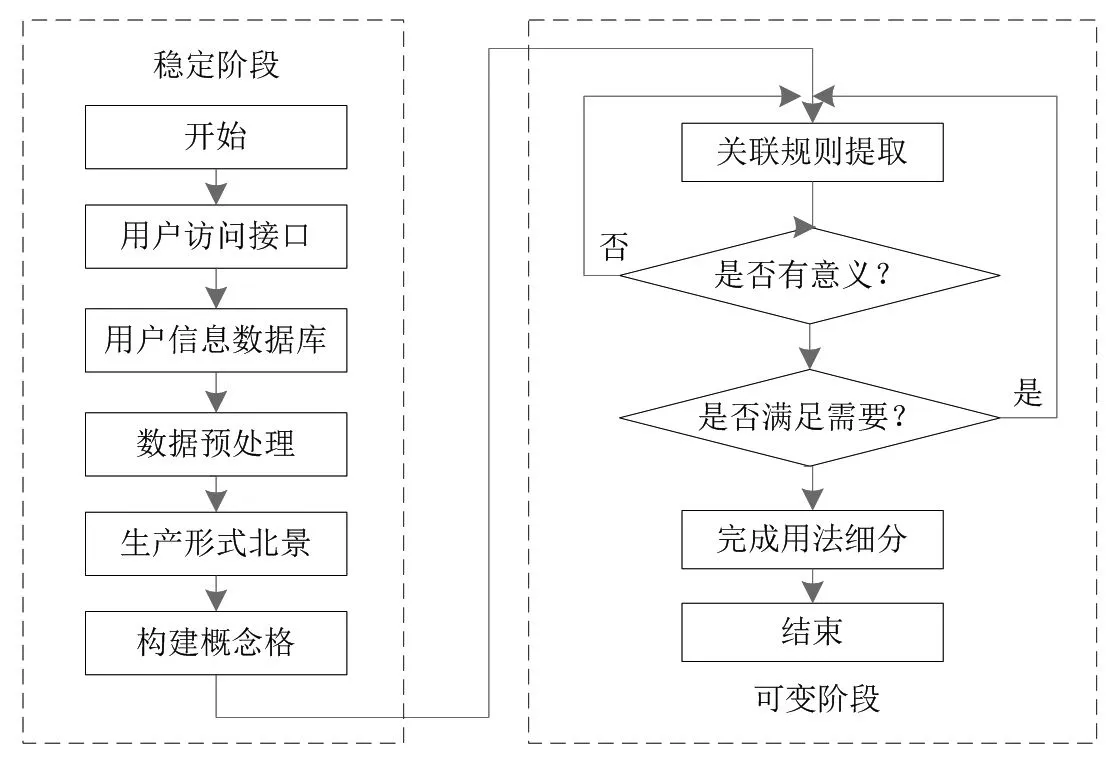
图1 用户知识关联规则挖掘系统流程图
图1 为以概念格为基础的用户知识关联规则挖掘的流程图,这幅图的工作原理就在于,智能数字化的图书检索系统能够对用户的选择进行预判,以及对用户曾经输入的信息进行记忆,当用户再次需要进入系统进行图书查阅时,其立刻快速的满足用户需要。系统核心部分为可变阶段,在进行挖掘时,若获得的规则无实际意义,则对置信度阈值和支持度进行调整,重新在原格结构基础上提取。若得到的规则具有实际意义,则这个规则能够对用户的需求进行准确判断,帮助用户获得其需求成果,如果这个规则无法满足用户的需要,则对阈值再次进行调整。
3 基于挖掘结果的用户知识提取
在进行图书馆用户系统工作时,主要是将数字图书馆用户个性化服务水平提高。[7]图2为置信度阈值为49.21%,支持度阈值为30.50%时的关联规则,规则“j(停留久)=>p(非黑夜模式)”的置信度为65.54%,支持度为49.21%。这表明在数字图书馆“长时间驻留并在白天访问”中,该节点为全部用户的49.21%代表,而占据大部分比重的,则是白天访问的用户以及能够长时间在图书馆逗留的用户。而在另一个部分中,规则“j=>fs(高速接入+PDF文档+经常使用)”具有49.21%的置信度,36.48%的支持度。这表明在使用数字图书馆时,该节点代表36.48%的用户采用“长时间驻留+PDF文档+访问学术信息+经常使用+高速接入”用法。在“长时间驻留”的用户中,能够对图书管理系统综合利用的用户特征的用户比重为49.21%,具体见表1。
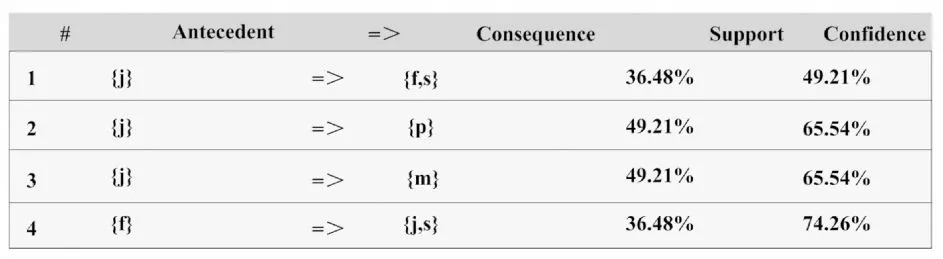
表1 置信度阈值为49.21%,支持度阈值为30.50%时的关联规则
对更多零散用户个性化知识需求,若认为36.48%的用户份额对其关注仍不能充分体现,对于规则“gj(财经类+长时间阅读)=>dmqx(农村IP/速度不佳+晚上进入系统+网页文件+不太常用)”而言,其置信度为100%,支持度为11.49%。这表明在访问数字图书馆过程中,该节点代表在所有用户中有11.49%的用户使用以上所有部分的节点的可信度是100%。根据选用实验数据源,处于同一节点规则包括eg=>cikmopt、cg=>eikmopt、gk=>ceimopt,置信度均为 100%,支持度为11.49%。例如规则gk=>ceimopt,该节点代表在所有用户中,使用“短时间停留+查询财经类图书+正常利用+地址转换+城市地址+网页文件+高端品浏览+白天访问+XLS文档+中速接入”的用户比重为11.49%。在城市,这部分用户大多数情况下都是处于一种快节奏得生活方式,首先来说,大部分人白天都处于上班时间,没有时间对图书进行浏览,另外,由于城市地区的人口众多,互联网比较拥挤,所以实际的互联网传输速度较慢,其次,生活在城市地区的居民,他们都会注重时尚的信息,所以综上所述,得出结论,具体的情况见表2。
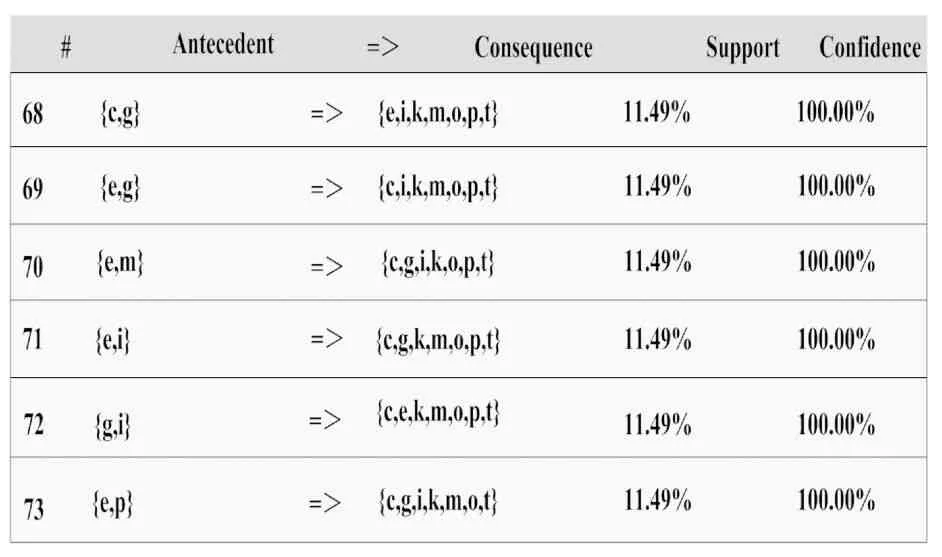
表2 置信度阈值为100.00%,支持度阈值为10.05%时的关联规则
分析以概念格为基础的数字图书馆用户知识关联规则挖掘,对找出用户使用方法间的潜在联系有益,能够有效的从用户的角度去考虑图书的检索方式,进而会给用户一种便捷的体验。[8]在研究中,通过调整阈值,获得更多规则,在规则通过稳定的格结构进行提取复用,对用户的图书利用习惯进行挖掘。[9]
4 基于概念格的数字图书馆用户知识序列模式挖掘
4.1 序列模式挖掘形式化描述
序列模式挖掘是在目前已经有的数据当中,进行归纳整理,并找出规律进行排序的过程,通常情况下,是按照优先级进行排序。对于数字图书馆用户知识序列模式挖掘而言,实质上是由用户检索系统当中的数据库来确定,数据库能够对用户的使用情况进行记录,当用户对于某一种图书的浏览次数较多时,数据库就会把其确定为最大值,同时将所有频率大于或等于给定支持度阈值的序列即频繁序列挖掘出。
项集为非空集合,是用户信息数据库DB中由若干个项组成,记作I=(i1,i2,…,im),其中一个项用ik(1≤k≤m)表示,表示用户寻找的一种图书,k-项集是长度为k的项集。
在图书检索开始时,用户向智能系统中,输入图书信息,从而达到检索的目的,在这期间,图书检索系统包括时间信息,图书名信息等必要因素。并同时规定,当一个用户在不同时段搜索同一本图书或者不同的图书时,其检索系统需要判断为每次检索都为重新检索。表3为用户信息数据库示例。

表3 用户信息数据库示例
项集组成的有序表即为序列(Sequence),项集有序排列不同,记为 I= 〈s1,s2,…,sn〉,其中 Sk(1≤k≤n)称为序列的一个元素(Element),表示一个非空项集。在一个序列中,序列长度是所包含项目的个数。L-序列表示长度为L的序列,表4为用户检索行为序列。

表4 用户检索行为序列
给定两个序列 A= 〈a1,a2,…,am〉、B= 〈b1,b2,…,bn〉,其中m≤n,假定有一组整数i1,i2,…,im,可使a1bi1,a2bi2,…,ambim,于是可以表示,在A中包含B的内容。如果在S序列中,只有S,并没有其他的序列,则我们可以认为,S序列是整个序列中最大的。
如果在一个图书检索系统当中,包含了S序列,那么我们就可以认定,该用户检索的图书可以用序列S来表示。在指数据库DB中,支持序列S的用户数和用户总数之比为序列S支持度。频繁序列是指支持度比最小支持度大的序列。例如给定最小支持度为36.48%,在表3的数据库DB中,则可获得序列模式的5位用户中,有2位用户检索行为序列至少被支持,表5为支持度大于36.48%的序列模式。

表5 支持度大于36.48%的序列模式
由表5知,用户1和用户3支持序列模式<(e)(m)>。在项e和m间,用户3对k进行了搜索,在进行m项进行搜索的同时,不仅仅是只搜索m,该用户还对其他两种项同时进行了搜索,但是这种情况下,仍然支持m项,原因是其模式属于独立的状态。序列<(e)(k)>、<(e)>、<(e)(k)(s)>、<(k)(ps)> 等可满足最小支持度,即频繁。
4.2 序列模式挖掘主要思想
在本文中,对于序列模式的挖掘主要的顺序是一种自上而下的过程,通过数据库投影技术从而可获得投影数据库,自上而下进行检索的优点就是,当用户进行搜索时,其能够进行顺序判断,当上层信息无法满足用户需求时,自动进入下层继续检索,这种检索模式也叫序列检索模式。上层与下层之间相对独立,但又保持着联系。图2为挖掘思想的拓扑结构。
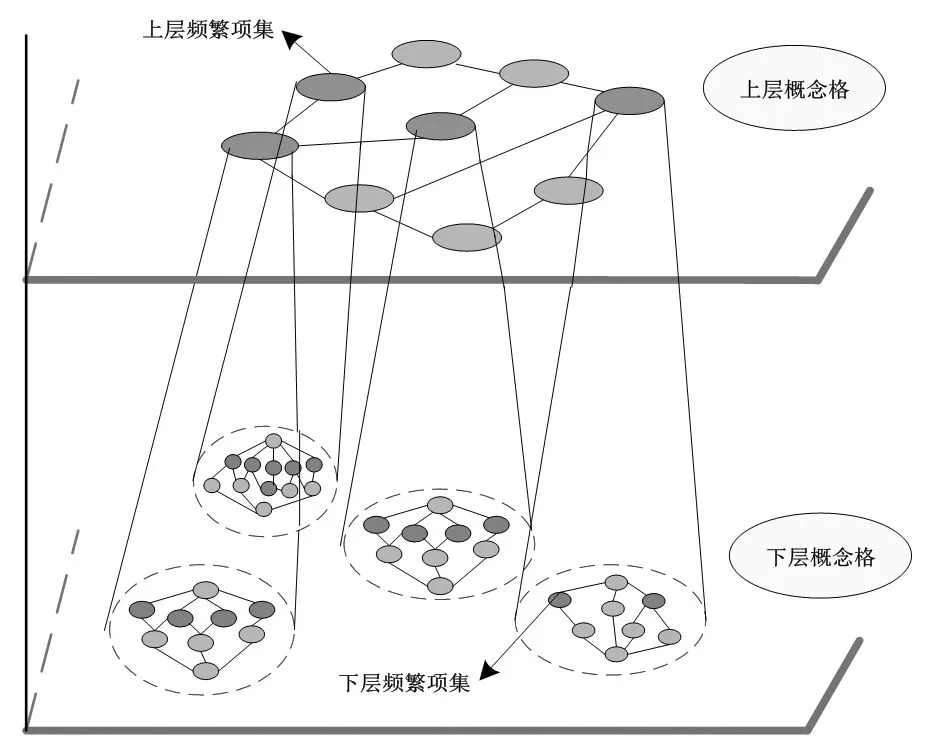
图2 挖掘思想的拓扑结构
基于用户概念的图书检索系统检索步骤可以分为8个步骤来完成。第一步是用户输入相关的个人信息,当成功登录系统后,系统会自动生成用户的数据库,从而使投影数据库生成。Session时间和用户ID是原数字图书馆用户知识行为数据库的主键,在进行归集后,可获得以用户ID为主键的投影数据库。第二步是上层概念格通过形式概念分析(FCA)进行构建,将投影数据库作为形式背景。第三步是在上层概念格中,通过设定的支持度阈值对上层频繁项集进行提取。第四步是在用户已经有的数据库当中,进行新的数据加入,也就是增加新的图书内容,通过形式概念分析(FCA)进行下层概念格的构建。第五步是在下层概念格中,对满足最小支持度阈值要求的下层频繁项集进行提取。第六步是在提取的下层概念格中,通过下层频繁项集将下层概念格最大频繁序列求出。第七步是重复第四、五、六步,直至第三步是对各上层频繁项集数字图书馆用户的检索行为,逐一进行下层概念格的建立,并对每个下层概念格最大频繁序列进行提取。最后一步就是对所有的数据进行重新的归纳和梳理,分析用户最常阅读的图书,将其作为序列的最大值进行排放,下次检索时,直接在最上层。
4.3 用户知识序列模式挖掘
数字化的图书检索系统,其运用的是用户的数据库相关理论,DB为一个三元组K=(U,D,R),所有检索对象集合用D表示,所有检索行为集合用U表示,D和U之间也是具有相关性的,这种相关性利用R表示。通过这种方法,使数据的排序变得更加有序,有序这种方法属于挖掘数据的模式,所以,只采用单纯的1-排序方法并无实际意义。在BD数据库里,它可以根据用户的ID判断用户的需求,这样可大幅压缩得到的投影数据库规模。表6为用户信息数据库投影库的形式背景。
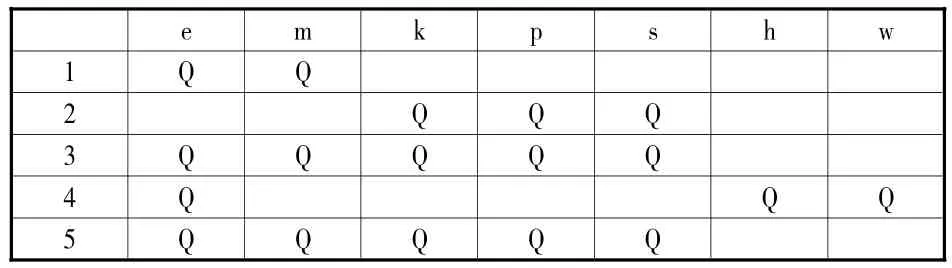
表6 用户信息数据库投影库的形式背景
通过表6,可诱导出上层概念格Hasse图,具体见图3。
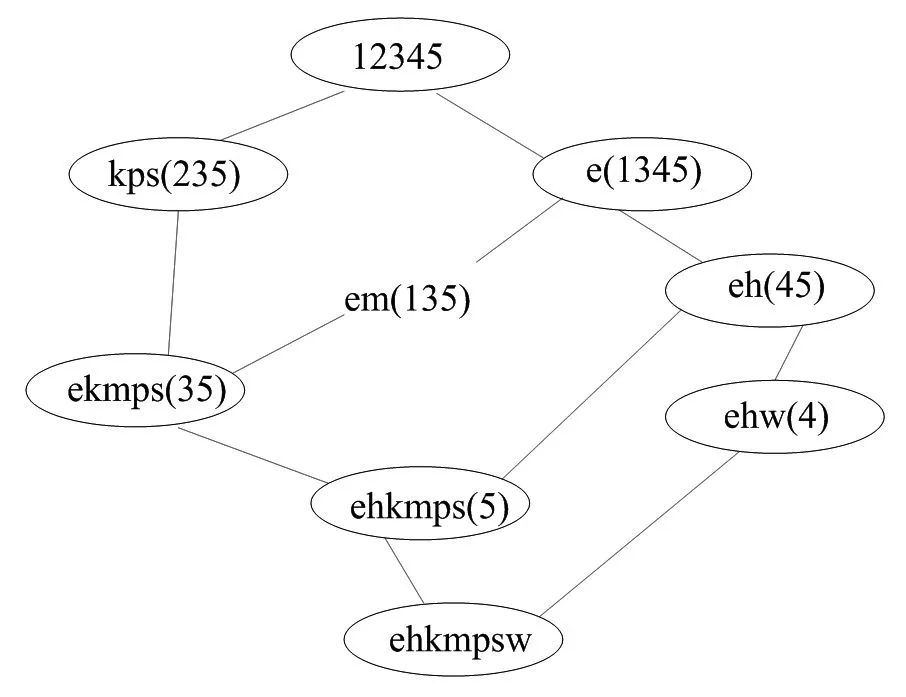
图3 上层概念格Hasse图
由图3知,在设定支持度阈值为36.48%时,可获得长度大于或等于 2的上层集,分别为 (eh)、(ekmps)、(em)、(kps),依照词库的相关规定进行排序工作。1-项集(e)可满足最小支持度阈值,在进行排序工作时,可以发现,1-型序列在实际当中并没有准确的进行应用,所以我们可以把这部分进行排除。当排除上述因素之后,下一步就可以对下层的概念进行建模。上层频繁项集(ekmps)外延集合包含用户3、5的检索行为,表7为其形式背景。
通过表7,可诱导出下层概念格Hasse图,具体见图4。
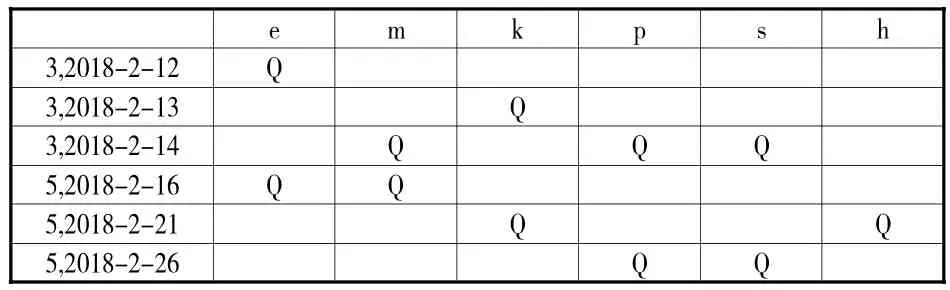
表7 用户3、5检索行的形式背景
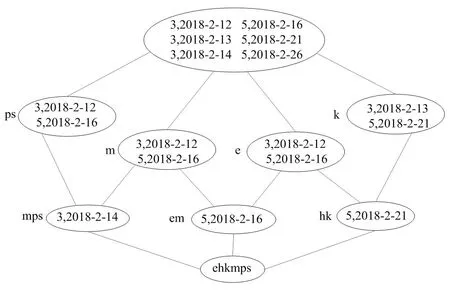
图4 下层概念格Hasse图
在支持度阈值为36.48%时,可获得下层频繁项集(m)、(ps)、(k)、(e)。由图 4知,在下层概念格中,根据各下层频繁项集用户的检索状况进行排序,排序的依据就是以时间作为标准,从前往后的进行排序,排序抛除掉1的部分,对于长度大于2的部分,按顺序进行列举。因此处外延集所包含的用户检索行为只针对上层频繁项集(ekmps),对于原始用户信息数据库无须遍历。针对上层频繁项集(kps)、(eh)、(em)的用户检索顺序,进行下层概念的建模工作,建模结束后,就对相关的顺序进行排序工作。利用上层对应下层的方法,可以得出用户1和用户3的序列<(e)(m)>。在对用户系统进行全面检索中,<(e)(k)(ps)> 的子序列包括序列 <(k)(s)>、<(k)(p)> 是序列,所以需要抛除掉,进而就可以得出正确的图书检索序列为 <(e)(m)>、<(e)(k)(ps)>。
5 序列模式挖掘的讨论
对于挖掘效果而言,在提取频繁项集方面,概念格具有其他的挖掘方式所不具有的优点,他属于一种新型挖掘模式,与传统的挖掘方法存在着显著的不同,这种方法提取的频繁项集数据源能更精准的满足阈值要求,从而使挖掘工作感知有用性得到提高。[10]通过概念格迭代,对概念格提取频繁项集进行多次反复使用,以概念格为工具,最大限度使用概念格复用性,这种挖掘方法充分的考虑到了用户的因素,使用户在进行图书检索工作时,大大节省了图书检索时间。其优秀的图书检索系统,能够从系统方面去考虑优化用户的检索体验,进而能够为建设数字化、智能化的图书馆提供强大的技术动力。
6 结论
本文基于概念格的数字图书馆,对用户知识序列模式挖掘进行了研究,目的是基于数字图书馆用户检索行为中的挖掘序列模式,对数字图书馆用户服务进行完善和改进,得出以下结论:
(1)通过挖掘基于概念格的数字图书馆用户知识关联规则,从用户角度分析了数字图书馆知识组织,本文从概念格方面对基于挖掘数据的方法对图书进行检索系统,一定程度上,优化了用户的检索体验。
(2)通过自顶向下概念格迭代在对用户检索模式进行挖掘工作时,只需要采用一次挖掘的方法,就能够实现准确的用户定位,无需进行多次挖掘,从而使挖掘时间大幅压缩,获得的挖掘效果良好。
