基于带权词格的循环神经网络句子语义表示建模
2019-04-18张祥文陆紫耀王鸿吉苏劲松
张祥文 陆紫耀 杨 静 林 倩 卢 宇 王鸿吉 苏劲松
1(厦门大学 福建厦门 361000)2 (江苏省计算机信息处理技术重点实验室(苏州大学) 江苏苏州 215006)
如何生成高质量的句子语义表示一直是自然语言处理的核心问题之一.由于现实中自然语言句子的数量是无限的,因此,我们训练好的模型往往需要处理从未在训练语料中出现过的句子.对此,传统方法通常以高频词或多元词串为基础来表示句子,然后在此基础上进行各种运算,以获得表示句子语义的向量.然而,这些方法往往需要人工事先定义特征,所以建模效率较为低下.近年来,随着深度学习研究及其应用的快速发展[1],学术界和产业界将目光转向了神经网络,通过构建深度神经网络来学习句子的语义表示[2],以应用到后续的自然语言处理任务中.
在基于深度学习的句子语义表示建模方面,循环神经网络(recurrent neural networks, RNNs)[3]得到了广泛应用.相比于传统的非神经网络模型,RNN能够保存序列的历史信息,因此对长序列文本具有更好的建模能力.特别地,RNN的一些变种,例如LSTM(long short term memory)[4]和GRU(gated recurrent unit)[5],进一步引入门机制(gating mechanism)来控制信息流动,提高捕获序列内部长距离依赖的能力.针对中文等没有天然词语分隔符的语言,神经网络模型有2种实现句子语义建模的方案:第1种方案直接建模字序列.该方法忽略词语的边界信息,不需要分词,而这一信息对于建模字、词之间的组合关系至关重要;第2种方案则先进行分词,然后以词为单位来建模.该方法同样存在缺陷:一方面,分词工具产生的错误分词对句子的结构造成破坏,并通过错误传播的形式对后续的表示建模产生负面影响;另一方面,使用单一的词序列来表示句子,使得文本表示建模缺乏灵活性.因此,对于中文等语言,如何利用RNN来提高句子语义表示建模的质量是一个有待深入研究的重要问题.
针对上述问题,本文提出基于带权词格的循环神经网络模型.词格是一个能够容纳多种分词结果的压缩数据结构,与单一分词结果相比,它具有丰富的表示能力.目前,词格已经广泛地应用于许多自然语言处理任务当中,并取得了很好的效果,例如机器翻译[6]和语音识别[7].通过基于带权词格进行句子语义表示建模,我们期望提出的模型可以减轻分词错误造成的错误传播,同时也能使句子语义表示建模具备更强的灵活性.在本文工作中,我们提出了2种基于带权词格的GRU神经网络模型:1)基于带权词格的浅层融合循环神经网络模型(shallow weighted word lattice RNN, SWWL-RNN),该模型直接对多个分词输入和相应的前隐状态进行融合,再输入到标准的RNN单元生成当前隐状态;2)基于带权词格的深层融合循环神经网络模型(deep weighted word lattice RNN, DWWL-RNN).不同于SWWL-RNN,该模型先根据每个分词输入和相应的前隐状态分别产生各自的当前隐状态,然后再对这些隐状态进行融合,生成最终的当前隐状态.显然,2种模型都以融合函数为核心.因此,针对隐状态的融合函数,本文尝试了4种不同的融合策略:
1) 池化(pooling)融合函数;
2) 门机制融合函数;
3) 基于词格边权重的融合函数;
4) 融入词格边权重的门机制融合函数.
最后,我们在情感分类和问句分类实验上,分析对比了2种模型、4种融合策略的效果.实验结果表明,基于带权词格的RNN模型的性能明显超过传统的RNN变体模型和现有的其他模型.
1 背 景
本节介绍本文工作的基础:带权词格[6]和GRU[5]循环神经网络.
1.1 带权词格
带权词格[6]是一种包含指数级别分词结果的压缩数据结构.图1所示为1个句子根据3种不同的分词标准进行分词的结果及相对应的词格结构.3种分词标准,分别来自北京大学(Peking University, PKU)、中文树库(Chinese treebank, CTB)和微软研究院(Microsoft Research, MSR)公开的分词语料训练的分词模型.如图1(d)所示,给定由N个字组成的1个序列c1:N=c1c2…cN,带权词格在形式上表现为1个带权重的有向图G=V,E.这里,V表示结点的集合,其中结点vi∈V(i=1,2,…,N-1)表示ci和ci+1之间的位置.此外,词格还包含2个特殊的结点:1)v0,该结点在c1之前,表示字序列的开始位置;2)vN,该结点在cN之后,表示字序列的结束位置.E表示边的集合,以边ei:j为例,它以vi为起点,并指向vj,同时覆盖了字序列ci:j,ci:j对应潜在的一个候选分词.而ei:j对应的权重weightei:j,则代表ci:j被作为候选分词的可能性.
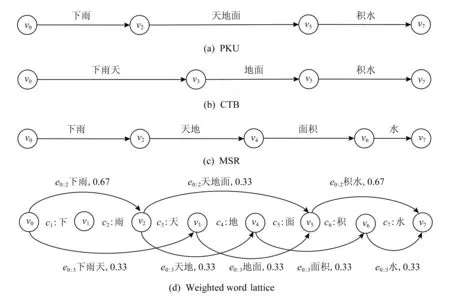
Fig. 1 A weighted word lattice图1 一个句子的带权词格
词格中的边权重可以使用前后向算法[8-9]来计算.具体而言,对于结点vi,我们首先递归遍历它左边的前序结点,以迭代方式累加计算出从v0到vi的路径数目αvi,即:
(1)
其中,vik是结点vi的第k个前序结点.然后,对于结点vj,我们递归地遍历它右边的后序结点,同样以迭代累加的方式计算出从vN到vj的路径数目βvj,即:
(2)
其中vjk是结点vj的第k个后序结点.最后,weightei:j可定义为

(3)
如图1(d)所示,从v0指向v3的边e0:3,覆盖了c1到c3的字序列,表示一个候选词“下雨天”,其权重为0.33.边权重在一定程度上体现了不同分词标准的一致性.权重越大,边覆盖的字序列被切分为词的可能性就越高.同时,边权重也增强了词格的容错性,使词格结构的信息表示更加丰富,从而得以有效应用于各种自然语言处理任务中.
1.2 GRU循环神经网络模型
RNN[1]虽然具有较好的文本序列建模能力,但仍然面临着模型参数梯度消失和爆炸的难题[10-12].对此,研究者引入了带有门机制的LSTM[4]和GRU[5]来控制网络信息流动,以提高RNN在长序列文本上的建模能力.由于GRU与LSTM性能相同,同时所需参数更少.因此,本文选择GRU作为循环神经网络单元进行文本建模.需要说明的是,本文方法同样适用于LSTM等其他RNN的变种模型.
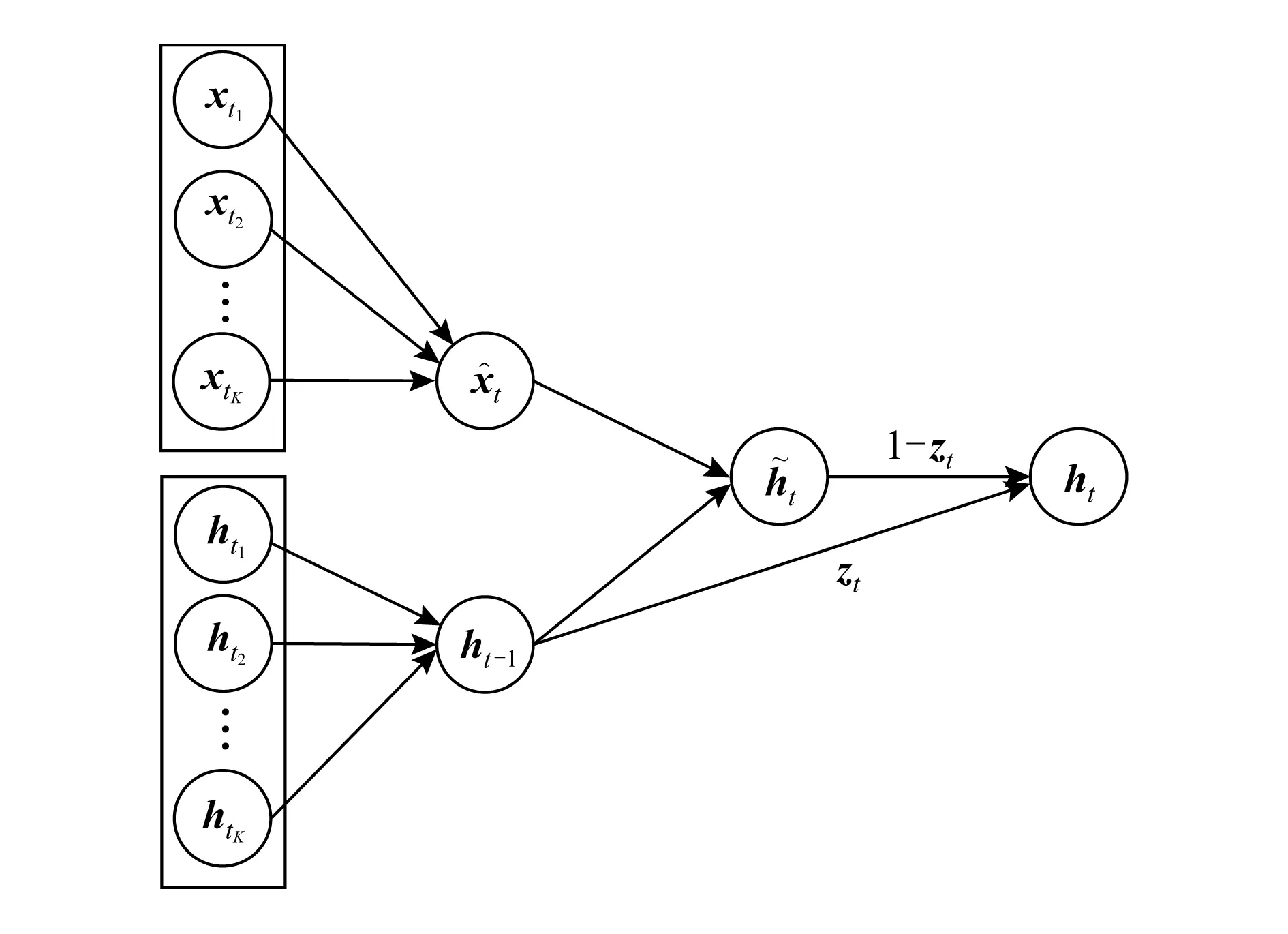
如图2所示,与RNN相同,GRU在每个输入单元循环地应用1个转移函数,以生成当前时刻的隐状态表示.
具体来说,时刻t的隐状态向量ht∈d,由当前输入向量xt∈d和前一时刻的隐状态向量ht-1生成:
ht=f(xt,ht-1),
(4)
其中,f(*)通常定义为一个仿射变换及双曲正切函数tanh.对于文本序列而言,xt是句子中第t个词的向量表示,ht则代表到时刻t为止的词序列向量.
正如本节第1段所述,GRU在RNN的基础上,进一步引入了重置门和更新门来控制信息流动.图2所示为一个时刻t的GRU单元,其转移函数定义为
rt=σ(W(r)xt+U(r)ht-1+b(r)),
(5)
zt=σ(W(z)xt+U(z)ht-1+b(z)),
(6)

(7)

(8)

2 基于带权词格的GRU循环神经网络
受现有工作[6,13-14]的启发,本节对基于词格的循环神经网络[15]进行扩展,提出了基于带权词格的GRU循环神经网络,以学习句子语义表示,用于后续的自然语言处理任务.显然,与词序列相比,带权词格具有更为丰富的信息和更为复杂的网络拓扑结构.以它为基础来进行神经网络建模将面临着2个难题:1)在带权词格中,一个句子通常会存在许多分词结果,这意味着当前单元可能会同时存在多个输入和多个前隐状态,传统循环神经网络[4-5]无法建模这样的结构;2)带权词格的边权重能够较好地区别不同分词结果的可能性.如何在本文所提出的模型中体现出不同分词结果在句子建模过程中作用的差异,是本文研究工作的一个关键问题.
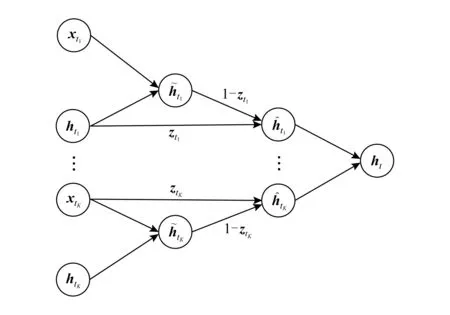
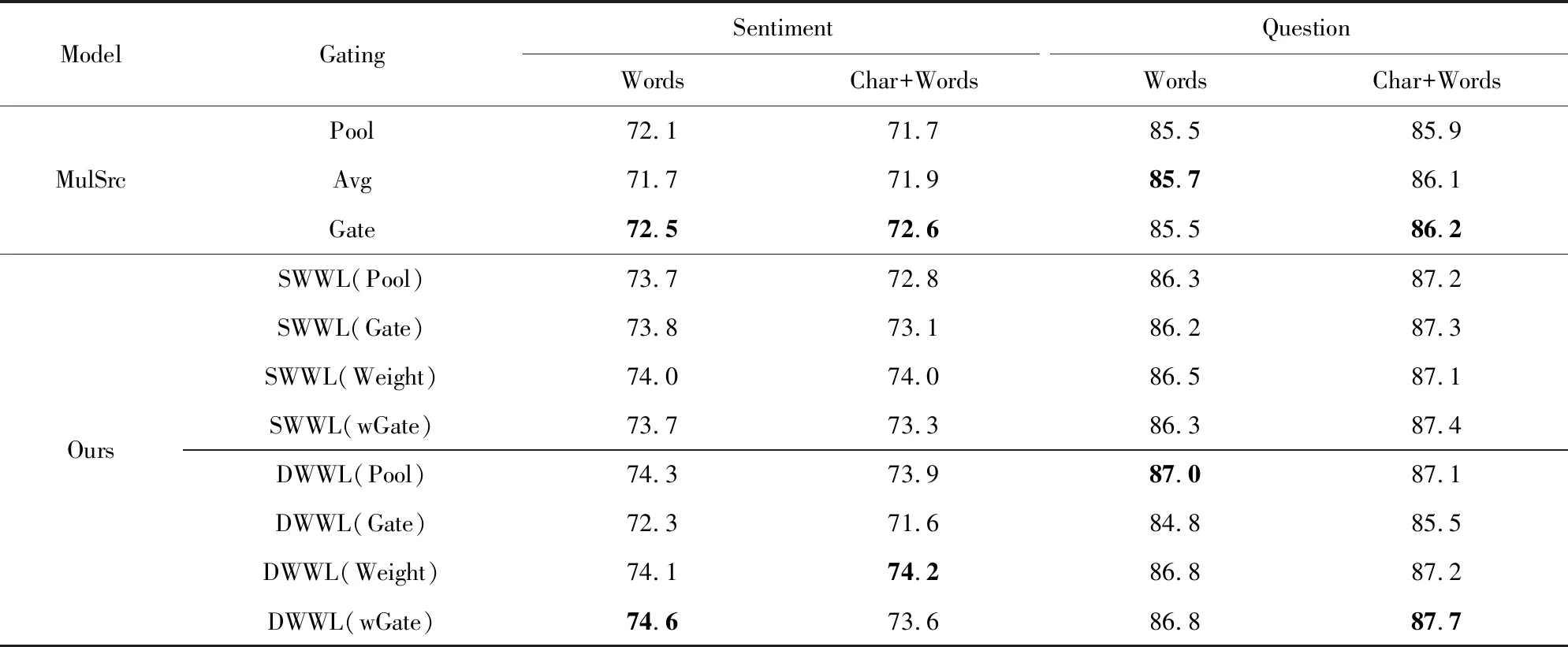
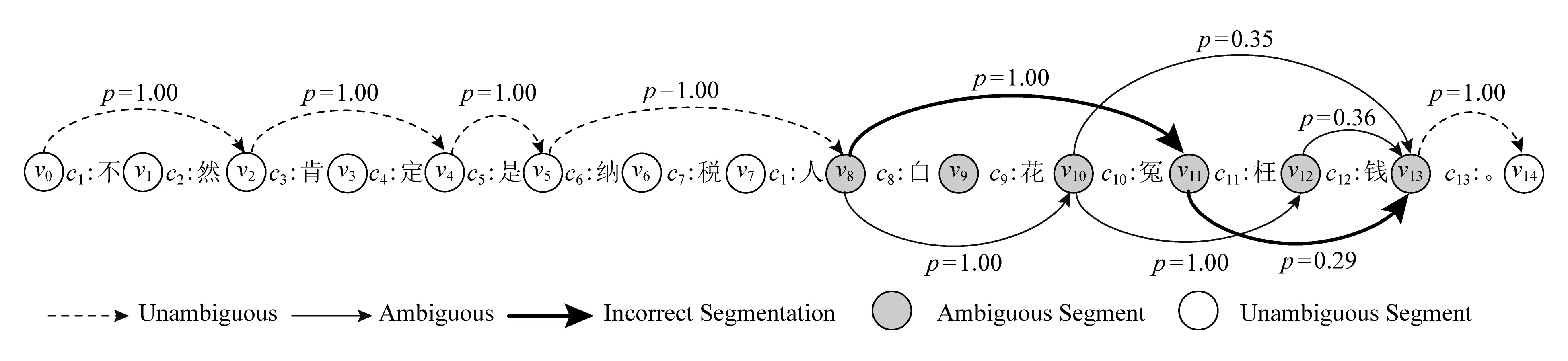
在建模过程中,我们的模型以句子的字序列为输入,逐字地读取句子.在时刻t,对于当前结点vt,我们首先确定以字ct为结尾的一个入度边集合,即{etk:t=(xtk,htk)|0≤tk 浅层带权词格GRU模型的单元结构如图3所示: Fig.3 A SWWL-GRU unit图3 浅层带权词格GRU单元 形式上,该单元的建模函数定义为 (9) (10) (11) (12) (13) (14) 深层带权词格GRU循环神经网络的单元结构如图4所示: Fig. 4 A DWWL-GRU unit图4 深层带权词格GRU单元 与浅层带权词格GRU单元相比,深层模型在更细粒度的语义表示层次上,对多种分词结果进行分词状态的融合生成.浅层模型选择融合循环单元的输入,而深层模型采取对循环单元的输出进行融合的方式.简单来说,两者的具体区别在于选取融合操作的时机不同.从时间复杂度来考虑,深层模型的时间复杂度为O(KN),即关于句子的字数和边的最大个数成正比;而浅层模型的时间复杂度为O(N),与基于字的普通RNN模型相等.这2个模型涉及到融合函数的部分,时间代价可以忽略不计. 形式上,该单元的建模函数定义为 rtk=σ(W(r)xtk+U(r)htk+b(r)), (15) ztk=σ(W(z)xtk+U(z)htk+b(z)), (16) (17) (18) (19) 其中,xtk,htk与2.1节公式符号的含义相同.式(15)~(18)用于生成第k个分词对应的隐状态,式(19)采用语义融合函数g(*)生成ht. 在常见的基于字或词的模型中,句子可以被视为一个特殊的有向无环图,其中每个结点的入度和出度均为1.然而,对于词格,每个结点的入度和出度则至少为1,因此基于RNN的序列建模模型[4-5]无法处理词格结构的输入数据[6-7]. 在浅层、深层带权词格模型的基础上,我们进一步提出了使用融合函数来融合循环单元的输入或输出,生成单一的压缩表示,以转换成标准循环单元能够接受的输入形式.这里,本文在文献[15]中2种融合函数的基础上,进一步提出2种基于词格边权重的融合函数.为了不失一般性,本文以深层带权词格中的ht为例,描述在带权词格GRU单元中如何使用这些融合函数.需要注意的是,这些定义同样适用于生成其他向量,例如xt. 首先介绍文献[15]中2种基础的融合函数:池化融合函数与门机制融合函数;接着,介绍本文提出的以门机制为基础的2种新融合函数. 1) 池化融合函数 (20) 其中,max(*)是一个逐元素最大值函数. 池化融合函数忽略了词格的边权重信息,直接通过聚集入度边集合对应的隐状态来获取最重要的特征. 2) 门机制融合函数 目前,门机制已经大量应用于神经网络中,用以自动学习不同输入信息的权重.与文献[16]相似,该融合函数在形式上定义为 (21) 其中,u(g)和b(g)分别是门机制融合函数的参数向量和偏置项标量,上标g表示门. 门机制融合函数则计算每个隐状态的归一化分数,作为边的权重,对隐状态进行加权平均.这个分数可以视为动态生成的边权重,表示模型将该边作为候选分词的置信度. 3) 基于词格边权重的融合函数 带权词格的一大特点是边权重可以有效区分不同分词结果的可能性.基于词格边权重,我们将ht定义为不同分词结果的隐状态的加权和,即: (22) 其中,weightetk:t是根据式(3)计算出的边权重.显然,在这种融合方式中,融合权重主要取决于词格本身,而独立于网络模型. 与门机制融合函数不同,基于词格边权重的融合函数使用1.1节所述算法计算的词格边权重,对隐状态进行加权平均.同门机制生成的动态权重相比,词格边权重是静态的,可以直接表示边上的词作为候选分词的可能性. 4) 融入词格边权重的门机制融合函数 该融合函数与2)基于门机制的融合函数相类似.不同的地方在于,门机制融合函数是无监督的,直接受模型训练目标影响,而相比之下,基于词格边权重的门机制融合函数则利用词格边权重作为外部监督信息来改进门机制学习到的融合权重.具体而言,我们要求门机制学习到的融合权重与词格边权分布尽量接近.为此,本文进一步引入门机制权重与词格边权重的欧式距离来作为惩罚项: (23) 融入词格边权重的门机制融合函数进一步使用静态边权重作为正则化项,指导动态边权重的生成,这一方法可以视为门机制融合函数与基于词格边权重的融合函数的结合. 上述4种融合函数,各自以递进的方式,从静态和动态到动静态结合地利用词格边权重,从而充分发挥模型的运算能力和利用词格结构提供的监督信息. 基于带权词格的GRU模型的训练过程与标准RNN相同.模型目标函数与后续所应用任务紧密相关.对于分类任务,本文模型首先建模学习句子语义表示,然后通过一个softmax层来预测句子的标签分布: (24) 其中,θ代表模型参数;hNs∈d是句子s在时刻t的隐状态,作为句子的向量表示;W(y)和b(y)分别是softmax层的参数矩阵和偏置项向量,上标y表示该层的输出用于预测标签.设数据中共有L个候选标签,L为模型建模的概率分布,并且满足给定训练数据D,模型的目标函数最终定义为 (25) 其中,pl(s)是句子真实标签的one-hot向量的第l个分量,Rgate是根据式(23)定义的惩罚项.当本文模型使用前3种融合函数时,λ=0;反之,当使用第4种融合函数时,λ为一个大于0的常数. 本文采用基于Adadelta[17]的随机梯度下降算法来优化模型.此外,本文在训练过程中使用dropout[18]和最大范数正则化[19]来防止模型训练过拟合. 为了验证本文模型的有效性,我们将2种基于带权词格的GRU循环神经网络和4种融合策略,分别应用于情感分类和问句分类任务,与传统GRU及现有的其他模型进行比较. 本文将在情感分类和问句分类2个数据集上测试我们提出的方法.下面从数据集大小和数据特点等方面分别介绍这2个数据集. 1) 情感分类 数据集来自于新浪微博,为了保证数据信息的充分性,我们删除长度不足6个字的句子,然后安排2名标注人员对句子按照不同的情感(消极、中性和积极)倾向进行独立标注,最后保留标注结果完全一致的数据作为实验数据.按照上述方式,本任务实验数据集共包含消极情感句子4 454条、中性情感句子5 100条和积极情感句子5 594条.然后,本文采取分层抽样的方式,按照7∶1∶2的比例从每个类别随机抽取样本,将数据划分为训练集(10 603条实例)、验证集(1 514条实例)和测试集(3 031条实例).句子的平均长度17.19个词或25.69个字. ① https://code.google.com/archive/p/fudannlp/ 2) 问句分类 数据来自FudanQuestionBank①提供的中文问句分类数据集.为了降低数据类别不均衡问题的影响,本文只选取数据量最大的5个分类.该数据包含1 517,4 987,1 101,3 185,2 174条文本,对应的类别分别为枚举、事实、评价、推荐和需求.同样,本文对该数据集按照7∶1∶2的比例划分为训练集(9 075条实例)、验证集(1 297条实例)和测试集(2 592条实例).平均长度为9.33个词或14.60个字. 3) 带权词格生成 本文使用北京大学(PKU)、宾州大学中文树库(CTB)以及微软研究院(MSR)的分词语料分别训练3个分词模型,然后按照1.1节中所述方法生成每个句子的带权词格. 本文所考察的对比模型包括: 1) GRU GRU[5]的最后一个序列状态作为句子语义表示用于预测句子标签.另外,除了最简单的单层单向GRU模型之外,本文还同时比较了3个GRU的简单变种模型:双层单向(2 layer GRU, 2L-GRU)、单层双向(bidirectional GRU, BiGRU)和双层双向(2 layer bidirectional GRU, 2L-BiGRU)模型. 2) LSTM LSTM[4]的实验设置与GRU模型相同.这一对比实验的目的是验证GRU与LSTM的性能,证明2个RNN的变种模型在本文2个任务上的效果相近. 3) CNN 卷积神经网络(convolutional neural network, CNN)[20]使用不同大小的窗口处理输入序列,能够获得句子在不同粒度,包括字、词语甚至短语级别的语义信息.本文参考Kim[20]的实验设置,使用单层卷积神经网络模型. 4) DCNN 动态卷积神经网络(dynamic convolutional neural network, DCNN)[21]通过利用动态k最大池化操作,具有与RNN相似的处理变长序列,以及捕捉句子内部长短距离依赖关系的能力.DCNN使用2个卷积层,k最大池化操作的k=4. 5) RAE RAE(recursive autoencoder)[22]通过贪婪方式构造文本序列的树结构,并将树的根结点作为该句子的向量表示.RAE能够建模序列中词与词之间的组合顺序关系,学习句子内部成分的结构特征.模型参数参考Socher等人[22]的实验设置. 6) MulSrc MulSrc(multiple source)独立地建模句子的字序列及词序列,最终通过2.3节所述的融合函数将句子表示进行一次融合,生成句子的语义表示.MulSrc可以同时基于字和词建模,是本文模型的简化版本.与词格不同,由于不存在句子级别的权重,我们简单地使用平均分布作为加权系数(Avg),模拟2.3节中基于边权重的融合函数,与本文所提出的带权词格GRU模型进行对比. 7) SWWL-GRU和DWWL-GRU 本文提出的基于带权词格的GRU循环神经网络模型在4种融合函数上进行了实验,相应的模型分别记为SWWL(Pool),SWWL(Gate),SWWL(Weight),SWWL(wGate),DWWL(Pool),DWWL(Gate),DWWL(Weight),DWWL(wGate). 此外,字序列与词序列相比,是更简单的一种句子表示形式.为了研究这种表示是否有助于文本语义建模,本文同样引入字序列到SWWL-GRU和DWWL-GRU的词格中,并与之进行对比实验与分析. 在实验参数方面,本文统一使用dropout[18]防止模型训练过拟合,并根据验证集结果对dropout值进行选择.我们根据验证集挑选式(22)中调节惩罚项的λ值,将其设为1.0.词表由语料中出现次数在2次及以上的高频词构成.词向量和隐状态的维度分别为50和300维.所有模型均使用基于随机梯度下降的Adadelta算法[17]实现优化,批梯度更新的大小为1.每个模型分别训练5次,根据开发集的效果选择最优模型,并取测试集上的平均准确率作为最终结果. 表1和表2分别给出了基线模型与本文模型在情感分类和问句分类任务上的实验结果.从表1和表2中数据可以看出,本文模型的分类效果要显著高于单一字序列或词序列的模型. 从表1和表2可得出5条结论: 1) GRU和LSTM的性能相近 GRU[5]与LSTM[4]模型,是针对梯度消失和梯度爆炸问题[10-12]所提出的2个RNN[3]变种模型.在本文实验中,GRU和LSTM在2个数据集上的性能没有表现出显著差异,然而GRU模型具有更少的参数,因此在某种程度上降低了过拟合的风险. Table 1 Results of Baseline Models on Sentiment Classification and Question Classification表1 基线模型的情感分类和问句分类实验结果 % Notes:The values in boldface indicate the best accuracy in that experimental group. Table 2 Results of Our Work on Sentiment Classification and Question Classification表2 本文模型的情感分类和问句分类实验结果 Notes:The values in boldface indicate the best accuracy in that experimental group. 2) 基于词序列的GRU及其变种模型一致地优于基于字序列的模型 分词在中文等没有词语分隔符的自然语言处理任务中具有非常重要的作用,这是因为分词可以在一定程度上消除纯字序列存在的语义歧义现象.相比之下,基于字序列的模型忽略了句子中的词语边界信息,从而无法消除句子中存在的语义歧义,导致模型学习到的句子语义表示不能很好地服务于分类任务.然而,模型在问题分类任务上的结果并没有明显地反映出这一趋势.据统计结果显示,GRU具备强大的捕捉长短期依赖的能力,但对于短序列而言,短期依赖则占据了主要地位.这使得循环神经网络无法发挥其建模长期依赖关系的优势,从而对以短句为主的问句分类任务,弱化了基于词序列与基于字序列的模型在结果上的差异. 3) 基于CNN的模型效果弱于基于RNN的模型 正如文献[23]所示,相比于CNN,RNN模型对长序列文本的建模优势较为明显.尽管CNN在速度上具有明显优势,但在性能表现上却难以取代RNN.就表1中实验结果来说,CNN由于同时使用多个卷积核,使其在某种程度上能够捕捉所有的多元词串,从而与本文所提出的模型一样具备建模不同分词结果的能力.然而,并非所有多元词串都能表示一般意义上的有效词语,因此CNN也同时引入了更多的错误分词,导致基于CNN的模型在2个任务上的表现均明显不如RNN模型 4) 基于带权词格的模型优于基于字、词序列以及MulSrc的模型 相比于对比模型,本文提出的2个模型在情感分类和问句分类任务上均一致取得了更高的准确率.首先,只基于字和词建模的模型,缺乏表达分词多样性的能力;其次,同时基于字和词建模的MulSrc模型,由于仅在句级别融合句子语义表示,使得句子的最小单元无法在字、词序列间进行交互.此外,在大部分情况下,DWWL-GRU性能超过SWWL-GRU,取得了2个任务上的最好结果,这证明深层次的语义融合比浅层次的语义融合效果更好.此外,本文提出的2个模型在使用融入词格边权重的门机制融合函数上均取得最好结果,其次分别是门机制融合函数,以及基于词格边权重的融合函数.这一实验结果与我们的直觉相符.首先,门机制是无监督的权重学习,而基于词格边权重的融合函数则直接根据词格边权重来进行加权融合.相比之下,融入词格边权重的门机制融合函数,有效结合了上述2种融合机制的特点,进一步提高了所生成权重的质量,从而得到了更好的融合文本语义表示. Fig. 5 The semantic modeling of an example sentence图5 一个例句的语义建模 5) 融合函数的建模能力影响模型性能 引入字信息后,基于带权词格的模型在问句分类任务上的效果得到进一步提升,但情感分类任务的效果却降低.直观上看,字信息的引入能够有效扩充词格的信息量.但实际而言,情感分类的词表大小为42 685,问句分类则只有11 634,因此情感分类任务的词表更大,更难学习到有效的句子表示.在情感分类上引入字后,词格模型所要建模的分词组合数量进一步增加.我们的融合函数无法充分建模所有相应的分词情况,从而加剧了数据稀疏问题的影响.问句分类任务则恰恰相反,单纯就词表大小而言,即使引入字,词格模型中可能的分词组合数量也远远低于情感分类.因此与Words相比,我们的模型对于问句分类任务可以在Char+Words上更有效地建模,充分利用引入字后的词格信息增益,进而提升模型效果.实际上,本文提出的4种融合函数中最复杂的wGate融合函数,依然只包含一个与隐状态同等维度的参数向量,所以建模能力有限.因此,一个更复杂的融合函数应当能够在情感分类的Char+Words上进一步改进模型的性能.但为了证明基于带权词格的循环神经网络模型相对于传统基于词序列模型的有效性,我们在尽量不引入额外参数的前提下,保证融合函数足够简单.本文的讨论范围限于验证基于带权词格模型的有效性,因此我们将对具有更强学习能力的融合函数的研究放到未来工作中深入探讨. 为了探究所提出模型的工作机制,以性能最好的DWWL(wGate)为例,我们在图5中展示了一个句子的文本建模结果.在所示词格中,每条边标注有一个分数,该分数为模型动态生成的权重,表示该边所对应的词,在特定上下文中被作为一个候选分词的可能性,该权重直接影响模型的文本语义表示建模质量. 图5中所示为句子:“不然肯定是纳税人白花冤枉钱.”的建模结果.句中存在歧义的部分集中在v8~v13部分,即“白花冤枉钱”这一片段,根据上下文,我们判断其正确的分词结果应当为“白花冤枉钱”或“白花冤枉钱”.图5中粗边表示错误的候选分词,实边表示正确的候选分词.可以观察到,词格中存在来自不同分词模型产生的错误分词,如“白花冤”和“枉钱”.结点v13有3条入度边,分别对应:“钱”、“枉钱”、“冤枉钱”3个候选分词.其中,正确的分词“钱”和“冤枉钱”被作为候选词的置信度p为0.36和0.35;而错误分词“枉钱”的置信度p只有0.29.尽管“白花冤”在结点v11的置信度为1.00,但由于错误分词“枉钱”存在于“白花冤”的分词路径中,因此该路径依然得到了更低的分数.我们可以将模型建模的边置信度视为概率,通过路径的概率来更好地理解这一示例.图5中包含错误分词“白花冤枉钱”的路径,其概率p(false)=1.00×0.29=0.29.而包含正确分词“白花冤枉钱”和“白花冤枉钱”的路径,通过将其概率相加,可知正确路径的总概率为p(true)=1.00×1.00×0.36+1.00×0.35=0.71.因而在示例中正确路径的置信度是远高于错误路径的.不难看出,词格模型具有容错的能力,当错误的候选分词被赋予低权重后,错误路径的权重被降低,而正确路径所产生的影响通过高权重放大,从而减轻纯词序列中分词错误传播的问题.另一方面,单纯基于字和词序列的建模方法,则易受到错误分词的影响,而基于带权词格的模型则能够利用其容错能力来保证即使存在错误分词,模型仍然能够学习到高质量的句子语义表示. 目前,基于深度神经网络的文本语义表示学习已经成为自然语言处理的热门研究方向.其中,神经词袋(bag-of-words)模型是最为简单的一个模型,它对句子中所有词的词向量取平均直接得到句子的语义表示向量.显然,这种建模方式忽略了对文本语义表示极为重要的词序信息.因而,许多研究者转向研究考虑词序信息的模型,包括序列神经网络模型和拓扑神经网络模型等.典型的序列神经网络模型包括RNN[3],LSTM[4,24-30],以及带门机制的其他变形[31-33].而与序列神经网络模型不同,拓扑神经网络模型依赖给定的词间拓扑结构来建模生成文本语义表示[22,34-36].例如句子的依存和组合范畴语法可被作为骨架用于学习句子语义表示[28,37-39].进一步,一些研究者提出多维度的神经网络模型,该类模型将文本组织成一个多维网格而非序列作为输入[40-41].此外,除了上述模型,卷积神经网络也被用于句子建模[20-21].该类网络也是以词向量序列作为输入,建模过程中通过多层的卷积和池化操作来得到句子语义表示. 在上述工作中,与本文较为相关的工作主要有文献[15,27-28]中所提出的模型.文献[27-28]在本质上属于拓扑神经网络模型,分别将序列LSTM扩展到树结构和森林结构的网络.文献[40]提出了基于网格的LSTM,把LSTM单元按照多维网格的方式排列,以应用到一维、二维甚至更多维度的序列数据的语义建模学习.此外,文献[42]提出在生成当前隐状态时,对RNN中多个前隐状态使用与本文门机制相似的方式分别计算权重,然后将多个前隐状态加权输入到RNN单元.文献[15]提出基于词格的循环神经网络,通过Pooling运算和门机制来融合生成词格单元的输入.不同于这些网络,本文工作在文献[15]的基础上进行扩展,引入了带权词格来提高句子建模的能力,更重要的是本文模型引入词格权重来指导融合函数的建模学习,进一步提高词格循环神经网络语义表示的学习效果. 文本提出了2种基于带权词格的GRU循环神经网络模型,用于句子的语义表示建模.2种模型均以带权词格为基础,利用任意数量的输入词和前隐状态信息来融合生成当前隐状态,最终得到句子语义表示.在以句子语义表示为基础的情感分类和问句分类2个任务上的实验结果证明了本文模型的有效性. 未来,我们将在下面3个研究方向展开工作: 1) 研究如何把带权词格集成到其他神经网络中,例如卷积神经网络等; 2) 融入词格边权重的门机制融合函数虽然取得最好效果,但与其他融合函数相比优势有限,如何设计其他更加有效融合函数也是下一步工作的重点之一; 3) 本文所使用构造词格的方法较为简单,因此,我们将尝试使用其他的语言学信息构造词格,以进一步提升模型性能.2.1 浅层带权词格






2.2 深层带权词格
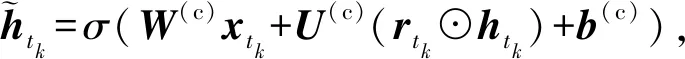


2.3 融合函数

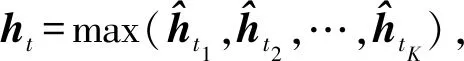
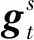
3 模型目标和训练

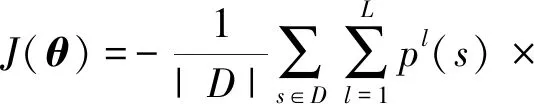
4 实验与分析
4.1 任务和数据集
4.2 实验设置
4.3 实验结果分析

5 相关工作
6 总 结
