基于QEMU的动态二进制插桩技术
2019-04-18颜运强
邹 伟 高 峰 颜运强
(中国工程物理研究院计算机应用研究所 四川绵阳 621999)
近年来,嵌入式软件的规模与复杂度愈发增加,如何进一步通过软件测试、分析与验证提高其可靠性,一直是学术界关注的焦点.其中,软件插桩是一项十分重要的应用于该领域的动态分析技术.通过软件插桩技术[1-2]可有效收集程序执行过程信息,如路径覆盖信息、函数调用关系信息,能用于软件性能分析、程序优化、测试覆盖分析、测试用例生成与约简、软件缺陷检测与修复.
当前,软件插桩技术包含源代码级[3]和二进制级[4-6]2种插桩方式,其中二进制插桩技术又分为动态方式和静态方式.研究表明[7]:源代码级插桩技术对软件具有很强的侵入性,无法应用于逆向工程或软件测试;在二进制插桩技术方面,静态二进制插桩技术,由于其较强的侵入性和代码数据难以区分等难题,在实际工程中极少使用;和静态二进制插桩不同的是,动态二进制插桩[1-2,7](dynamic binary instrumentation)技术通过接管目标程序控制流,为目标程序提供虚拟运行环境,进而监视收集目标程序运行信息.因而,动态二进制插桩技术既不需要重新编译生成目标码,又不会改变目标码的执行流程,完全不影响原程序执行逻辑,具有很好的实用性.目前,动态二进制插桩工具主要包含Pin[8-9],Valgrind[10],DynamoRIO[11]等,这些工具都在动态二进制翻译的过程中对软件插桩,可以完成内存使用、调用流、覆盖信息等程序运行信息分析.然而,这些工具还有十分显著的缺陷,即它们只能对用户级程序进行插桩分析,不能完成对系统级程序分析,难以满足嵌入式系统软件动态分析需要.
因此,亟需能分析嵌入式全系统软件二进制目标码的工具.于是,本文预想通过修改动态二进制翻译技术的全系统仿真工具使其具有动态二进制插桩功能,进而解决上述问题.现在,基于动态二进制翻译技术的系统级仿真工具主要包括QEMU(quick emulator),Bochs,VirtualBox,VMware,其中仅QEMU支持除X86以外其他体系结构的目标机和宿主机,适合用于嵌入式系统.QEMU[12]利用可重定位的动态二进制翻译技术,在多种体系结构的宿主机下高效全系统仿真多种目标机体系结构(X86,ARM,MIPS,PPC),包括操作系统及其所有应用软件都可以无修改的通过QEMU加载仿真运行.这是因为,QEMU在动态翻译执行目标系统程序过程中,模拟了包括CPU、RAM、中断控制器以及其他外设在内的目标体系结构的全部硬件.翻译执行过程中,如果在QEMU仿真执行序列中插入保存模拟运行环境快照的探针功能,那么将为程序的动态分析提供宝贵的运行信息.
本文的主要贡献有3个方面:
1) 研究QEMU的动态二进制翻译全系统仿真执行过程,提出完成中间码层次上的二进制基本块插桩,跟踪和记录程序执行流;
2) 分析与实验研究插桩对仿真性能的影响,发现日志输出是影响仿真性能的关键因素,通过分析计算,解决了由插桩引起的仿真性能骤降的不良影响;
3) 设计插桩日志分析工具,完成了对嵌入式全系统的执行流跟踪、函数调用图、覆盖率分析.
1 相关工作
通过文献查阅发现,目前已有一些学者研究使用和改进QEMU来进行软件动态分析.文献[13]对程序执行路径跟踪,查找程序执行热路径.该文献通过在QEMU的基本块首部插入热路径预测和跟踪指令,并在单独的线程中对热路径进行分析,完成了热路径记录任务,但由于对热路径进行在线解算,严重影响了仿真性能.文献[14]改进QEMU的动态二进制翻译和GDB(GNU project debugger)调试桩,来支持通过GDB控制Linux进程动态插桩,以达到跟踪Linux进程目的;文献[15]在QEMU翻译过程中标记函数调用和返回指令,获取Linux进程的函数调用关系图;文献[16]对每一条翻译后的目标机指令增加dump state指令来收集进程的执行信息,并发送到独立进程进行输出,显著提高了统计运行信息速度;文献[17]对Call/Ret指令的追踪,完成软件运行时的函数剖面分析,成功应对了函数执行过程被硬件中断干扰的情况,保证了函数时间剖面分析的准确性,但该文献对程序追踪粒度太粗,不能用于程序流图、语句覆盖信息产生;文献[18]提出一种故障注入方法来模拟系统故障、检验软件的故障容忍性;文献[19]在中间码的层次上提出了一系列钩子指令,获取目标系统的运行信息,然而其需要为每一种宿主机翻译钩子指令,灵活度低.
从上面这些文献可以看出:1)目前基于QEMU的动态二进制软件分析尚未形成统一的理论和方法,研究者在插桩点选择和探测内容上各不相同.2)研究者都侧重于使用和改进QEMU进行用户级程序执行信息收集.因此,本文旨在通过对动态二进制插桩技术的分析,结合QEMU使用基本翻译块的事实,借鉴Gcov[20]的覆盖分析方法,在基本块粒度上插桩,深度修改QEMU,实现二进制插桩功能,并在此基础上形成对基本块执行日志分析的工具,解决了嵌入式全系统软件的动态二进制分析问题.另外,本文还做了更进一步的工作:1)减少QEMU仿真运行日志记录内容,将日志在线分析变为事后分析,提升仿真性能;2)本文通过解决直接块链不返回问题,将记录日志信息精细到基本翻译块的层次,因而可以同时完成热路径分析、函数剖面分析、函数调用流分析、中断流分析等,丰富了动态二进制插桩在程序动态分析的应用范围.
2 动态二进制插桩与QEMU
本节简要介绍动态二进制插桩和QEMU的技术原理,帮助说明后文对QEMU插桩改进.
2.1 动态二进制插桩
动态二进制插桩,就是在执行客户机程序的流程中,通过添加、修改和删除机器码等操作[5],支持监控客户机软件的一种程序仿真运行技术.在二进制插桩领域,通常以基本块(basic block)为单位进行插桩,完成基本块运行信息收集,生成程序分支(arc)和程序流图,分析程序动态运行信息.所谓基本块,就是程序运行中最基本的指令序列.在这个指令序列中,所有指令顺序执行.停止语句和转向语句只能是基本块的最后1个语句.分支(arc)是指基本块之间的控制流,它连接程序中所有有效基本块形成程序流图.分支表示基本块之间的结构关系,通过分支可以知道程序在执行完基本块的所有语句后会转移到哪一个基本块继续执行.程序流图是程序结构的图形表示.基本块是流图中的节点,程序的所有基本块组成了程序流图的节点集,程序第1个语句所在的基本块称为首节点.把基本块之间的控制流向作为节点之间的有向边集合.对程序流图来说,节点就是基本块,代表了程序的执行语句;有向边就是分支,代表了程序的控制流;首节点就是程序的起始点.
依据插桩技术不同,基本块插桩可以在编译时进行,也可以在运行时进行.例如GNU(GNU’s not Unix)的覆盖率统计工具Gcov就是通过编译选项在基本块上进行二进制插桩,以实现对软件的覆盖统计.当插桩后的程序运行时,动态填充程序内的基本块、分支和程序流图.当程序运行结束时,将基本块、分支和程序流图输出到文件中,最终由Gcov完成动态分析.而Pin,Valgrind,DynamoRIO等工具则是通过动态二进制翻译技术完全控制目标二进制程序的执行.它们在运行目标二进制程序时进行二进制翻译,发现目标程序中的基本块并进行插桩,最后在程序结束时给出程序运行动态信息.目前这些工具存在较大的局限性,例如它们都只能完成应用级程序的动态分析,还没有一种工具可以完成系统级动态二进制插桩,由此可见,系统级程序的动态二进制分析对二进制插桩技术来说是一个巨大的挑战.
2.2 QEMU
QEMU可进行应用级软件仿真和系统级软件仿真.进行系统级软件仿真时,QEMU提供包括处理器、存储器、总线以及中断控制器、MMU(memory management unit)、FPU(float point unit)以及其他外设的全系统仿真,可以不作修改运行任何客户机系统软件.QEMU[12-13]主要包含2方面任务:1)执行调度;2)动态二进制翻译.仿真执行时,QEMU判断当前PC(program counter)对应基本翻译块(translate block, TB)是否已经在TB Cache中,如果不在TB Cache中,则进行动态二进制翻译;否则,执行该基本翻译块的宿主机指令.当执行到未翻译的客户机指令序列时,则表明当前PC对应基本块的开始,QEMU产生基本翻译块,开始进行动态二进制翻译.动态二进制翻译包含翻译前端和翻译后端2个阶段,完成客户机指令序列到宿主机指令序列的语义等效转换.第1阶段,函数gen_intermediate_code读取客户机指令序列进行反汇编产生中间码(intermediate code).在一些学者的研究中,中间码或称为中间表示,或称为虚拟指令集.在这1阶段,跳转指令确定了基本翻译块的边界.第2阶段,函数tcg_gen_code遍历中间码,将中间码转换成宿主机指令,保存翻译块并加入TB Cache.
3 QEMU插桩改进
QEMU的动态翻译仿真执行流程,与Pin,Valgrind,DynamoRIO等工具的动态插桩过程十分类似.然而,Pin,Valgrind,DynamoRIO等不支持系统级程序的仿真执行[2],也不支持交叉动态二进制翻译.所谓交叉动态二进制翻译,即原二进制程序同翻译后的二进制程序体系结构不同.PinOS是一个通过Pin开发的全系统的插桩工具,但其仅能用于Linux架构[2],不支持嵌入式系统.而QEMU全系统仿真时完全掌握系统运行流程和仿真环境状态.因此,可以对其进行深度修改,使其具有二进制插桩功能,解决嵌入式全系统的软件动态分析的难题.而要使QEMU具有二进制插桩功能,必须解决3个问题:
1) 流程嵌入,即如何将插桩过程附加到QEMU仿真执行过程;
2) 桩点选择,即在基本块中如何选择决策探针插入位置;
3) 探针内容,即在探针中如何收集以及收集哪些客户机信息来满足插桩日志分析工具设计.
3.1 流程嵌入
当前,一些文献通过QEMU客户机程序执行流程分析,将探针插在执行调度循环中,如图1所示:
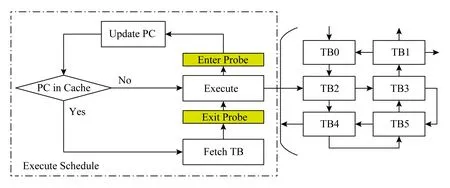
Fig. 1 Instrumentation in the main cycle图1 主循环内插桩
在执行基本块前后分别插入探针,获取虚拟CPU运行信息,记录PC和时间戳.但这种方法会丢失一些基本块运行信息.这是因为QEMU使用了直接块链技术.使用直接块链技术[12-13]后,执行调度程序一旦进入执行基本块流程,控制流不返回执行调度主循环,而直接选择下一个基本块继续执行.如图1所示,开始执行基本块后,控制流进入包含多个基本块的程序流图,不能立即返回执行调度主循环,从而导致丢失部分程序运行信息.为解决这一问题,一些文献提出取消直接块链功能[13,15],甚至提出采用单步执行的方式[13].这些方法虽可解决上述问题,却严重制约QEMU仿真性能.
针对这一问题,要收集基本块执行信息,只能将探针嵌入基本块执行过程内部,如图2所示.在基本翻译块的前后分别插入探针.这样,即使采用直接块链技术,也不会丢失程序运行信息.基本块运行时,记录基本块开始PC和时间戳.基本块结束时,记录其结束时间戳和控制流转移目的地址.
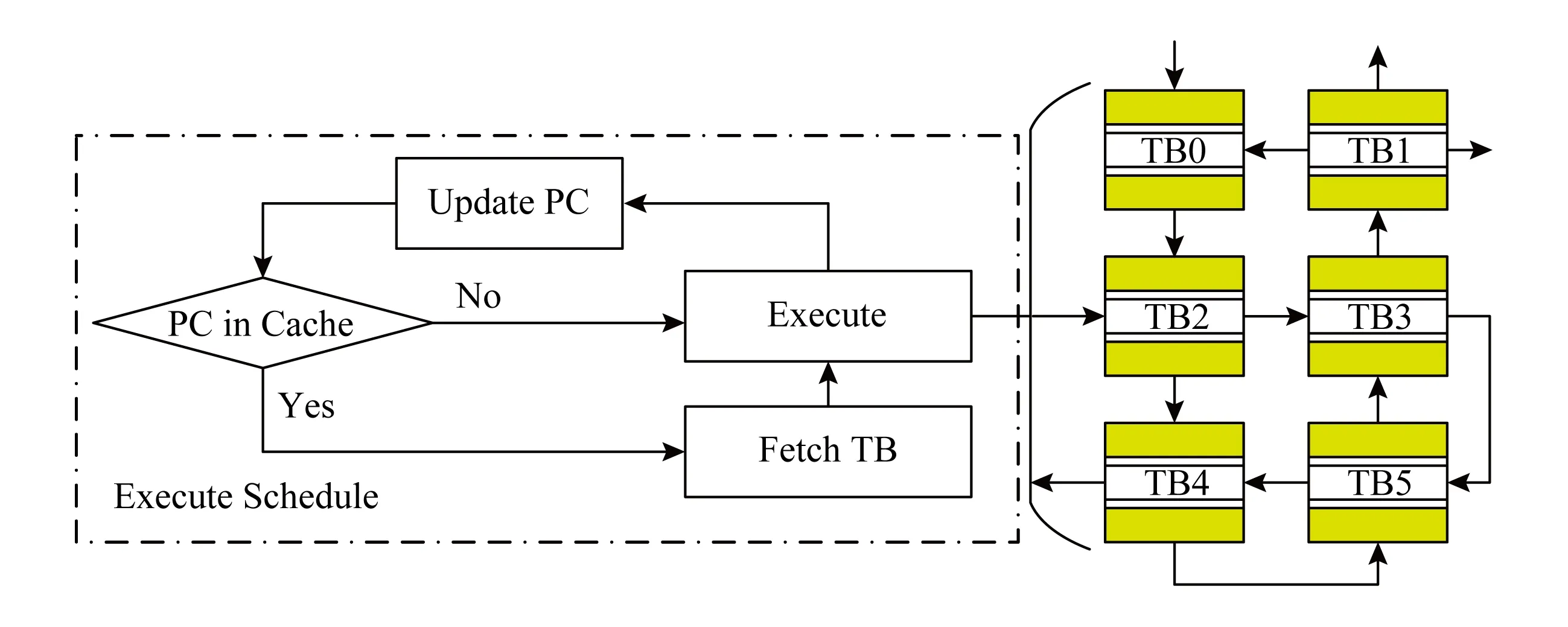
Fig. 2 Instrumentation in basic block图2 基本块内插桩
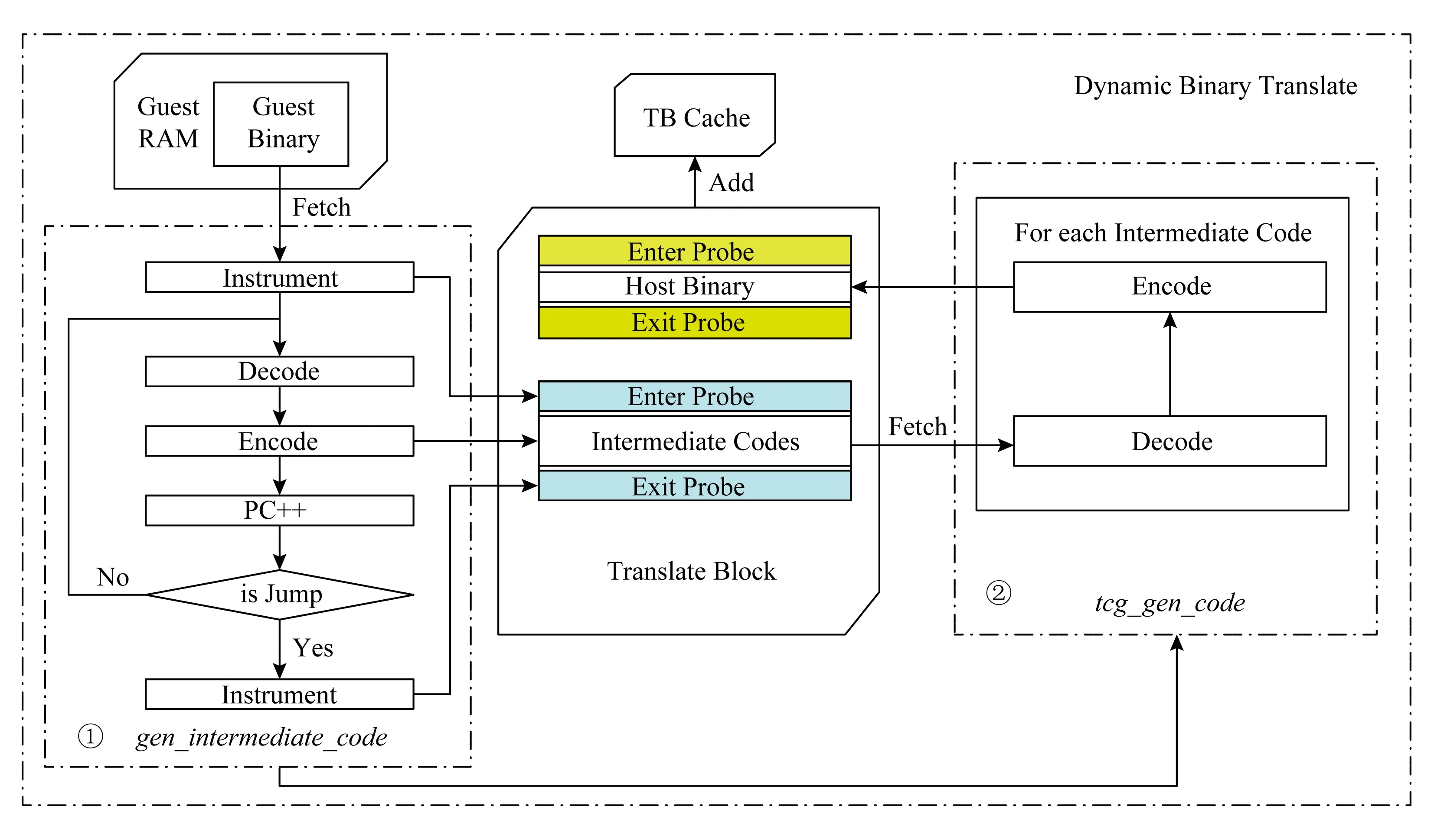
Fig. 3 The flow of dynamic instrumentation in basic block图3 基本块动态插桩流程嵌入示意图
然而,基本块内嵌入探针并不是简单的工作.例如,探针插入可以在翻译前端完成也可以在翻译后端完成.本文选择在翻译前端完成,即在函数gen_intermediate_code中完成.这是因为:1)该方法可以适合多种宿主机,不需要为每种宿主机体系结构修改代码;2)在翻译前端可以更方便通过代码操作客户机运行环境状态信息,而在翻译后端QEMU所能使用的信息仅仅是中间码,完全没有客户机环境信息.因此,本文的动态插桩过程如图3所示.在每一个基本块产生中间码之前,函数gen_intermediate_code先进行块首插桩,插入探针,将探针中间码添加在基本块中间码首部.遇上跳转指令离开基本块时,函数gen_intermediate_code进行块末插桩,插入探针,将探针中间码添加在基本块中间码末端.后端翻译时,即函数tcg_gen_code中,探针中间码连同基本块功能中间码一起翻译成宿主机指令序列,从而完成了对插桩流程的嵌入.
3.2 桩点选择
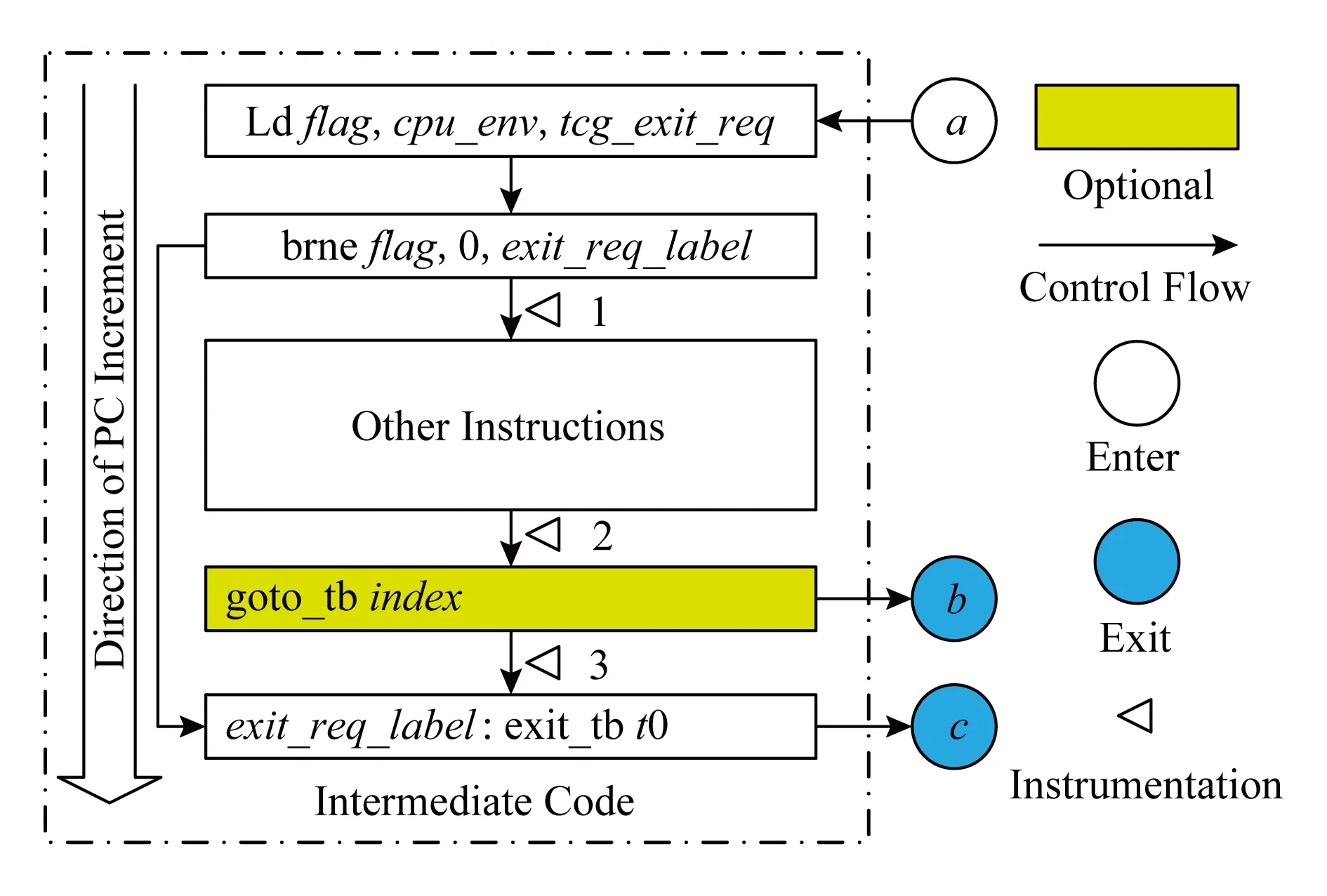
Fig. 4 Intermediate code and instrumentation selection图4 中间码与桩点选择示意图
问题转化为研究基本块前端翻译过程,即如何确定基本块中的插桩点.插桩点的选择既要保证覆盖基本块所有执行路径,又不会产生冗余记录.根据研究发现,基本块中间码组织结构如图4所示,除客户机基本块翻译来的中间码外,中间码中还包括了用于控制直接块链退出的其他中间码,如ld,brne,goto_tb,exit_tb等虚拟指令.仿真执行时,控制流有3条路径离开基本翻译块.
1) 客户机软件控制流从位置a进入基本翻译块,将tcg_exit_req加载到变量flag后,控制流判断flag是否为0,如果不是,跳转到最后1条指令exit_req_lable处,从出口c离开,返回执行调度主循环.这表示被仿真系统处理器收到外设产生中断或产生了异常等,需退出直接块链执行.
2) 客户机软件控制流从位置a进入基本翻译块,将tcg_exit_req加载到变量flag后,控制流判断flag=0时,控制流执行完其他中间指令,遇见指令goto_tb,从出口b离开,进入直接块链控制流.
3) 客户机软件控制流从位置a进入基本翻译块,将tcg_exit_req加载到变量flag后,控制流判断flag=0时,控制流执行完其他中间指令,控制流执行完其他中间指令后,未遇见指令goto_tb,从出口c离开,返回执行调度主循环.
显然,为覆盖全部路径,应选择图4中所示3处插桩点(三角形).这是因为,在直接块链的控制流中,当执行一个基本块时,首先会检查是否需要退出直接块链执行.如果检查到需要退出执行,则控制流直接转到当前块末端,而导致当前基本块的客户机指令没有执行.如果插桩不当,会将此种未运行客户机指令的情况虚假统计到日志记录中.
另外,除以上3条路径离开基本块以外,QEMU还可以在异常或中断触发下离开基本块.为简化插桩操作,本文未对此种路径进行插桩.这是因为,异常或中断产生对嵌入式系统来说是随机的,我们可以认为这是叠加在所有的基本块运行信息上的白噪声信号,不会影响最终分析工具的结果.
3.3 探针内容
插桩流程和探针点选择决策后,确定探测内容和分析时机成为首要问题.理论上,动态二进制插桩可以探测记录目标体系结构全部信息,包括全部寄存器值、存储器内容、程序栈和堆的值、程序执行流以及进入退出基本块时间等.但为了减少系统压力,尽量不影响系统仿真速度,在实践中仅记录少量体系结构运行信息.例如Gcov只记录了基本块的执行次数和基本块的进入地址,因而其函数剖面分析功能结果存在误差.本文参照Gcov,将探测内容定义成四元组(type,ts,pc,dest).type表示插桩点的位置,依据插桩点位置的选择,type分别可以取1,2,3这3种值;ts表示探针运行时刻客户机时间戳;pc表示插桩点运行时客户机的PC值;dest仅在type=2时有效,表示下一个基本块的首地址,记录程序中的跳转信息.
图5是本文所述插桩方法产生的动态插桩实例.目标二进制基本块取自EEMBC(Embedded Microprocessor Benchmark Consortium)组织Core Mark1.0中的main函数.该基本块包含2条指令,分别位于0x159a和0x159c.
从图5可以看出,此时处理器工作在Thumb模式.经过前端翻译后转换成中间码,共产生12条指令.经3处插桩9条指令后,共计21条指令.这3处插桩分别调用helper函数profile_enter_tb,profile_set_pc_tb,profile_exit_tb实现对执行路径及时间戳的记录.
3.4 性能优化
根据3.3节分析,每个插桩点都需要记录客户机时间戳.记录时间戳最简单的方法就是通过系统调用获取宿主机当前tick作为四元组中的ts.然而,采用这种方法存在2方面的问题:1)每一个基本块获取一次tick,即陷入系统一次,严重影响动态二进制翻译执行效率;2)宿主机系统的时间流逝包含了执行调度、动态二进制翻译等非客户机指令运行时间,造成客户机执行时间打点偏移.本文提出的解决方案是,在动态二进制翻译执行过程中,将流逝时间解释为指令计数.因为对于确定的计算机系统来说,单条指令的执行通常在一定的时间内完成.因此,可以通过指令计数来反映客户机系统时间.
指令计数可以在仿真运行中统计,但这不是最佳方法.在插桩日志处理工具的设计中,本文将日志记录转化为基本块序列.在执行基本块中,控制流顺序执行,因此可以通过执行基本块的开始地址和结束地址计算指令计数,从而反映基本块执行时间.这样插桩内容可定义为三元组(type,pc,dest),不包含时间戳,而采用事后分析基本块指令计数来得到基本块执行时间.这样就减少系统调用陷入,也减少了日志输出量,从而限制插桩程序对仿真性能的影响(见5.1节).
本文通过性能测试显示,日志输出I/O严重影响了仿真性能(见5.1节).为了减少日志输出,本文在第4节分析工具设计过程中进一步研究发现,可以将每次基本块运行日志记录优化为一条,这样就可以把日志输出减少到一半.这是因为,当把计时方式改为指令计数时,探针不再需要记录基本块运行开始时间.因此,只需在离开基本块控制流插入探针,就能计算出该基本块对应的函数和语句执行时间.如果控制流跳转到其他基本块,离开基本块时还应该记录目标基本块地址,用于函数调用关系计算.通过这样的方式,本文减少了插桩对仿真性能的不良影响.为减少在线分析对仿真性能的影响,同Gcov一样,本文采用事后分析日志的策略.
4 分析工具
为分析插桩代码运行日志记录,本文设计开发插桩日志分析工具(instrumentation analysis tool, IAT),其工作原理如图6所示.步骤1,读取运行日志记录,完成基本块还原;步骤2,读取目标二进制可执行文件调试信息,还原地址与源代码的映射关系;步骤3,计算基本块命中源代码情况,从而解算出函数调用关系、覆盖信息等.
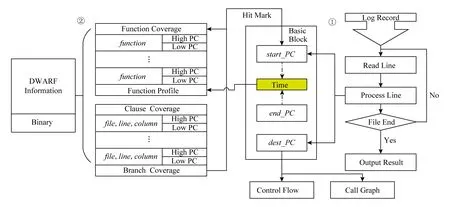
Fig. 6 IAT schematic diagram图6 IAT原理图
4.1 基本块还原
当插桩完成后,QEMU仿真运行客户机二进制代码产生记录日志文件.日志文件中每行包含前文所述的三元组(type,pc,dest)探测内容.如图6右侧①所示,IAT对记录日志逐行扫描,获取每一个基本块的地址范围、目标基本块等信息.然而,这些信息仅含程序运行覆盖的基本块、分支和程序流.如果要进一步统计软件函数调用流图、基本块覆盖情况、语句覆盖情况、函数覆盖情况甚至分支覆盖情况,必须获取目标机软件的全部基本块、语句、函数与二进制目标码的映射关系.
4.2 源码信息还原
在仅有二进制的情况下,可以使用调试信息来获取这种映射关系.现代编译器在将高级语言转换成机器码,同时在目标二进制文件中装入调试信息,方便程序调试和和软件优化.通常,调试信息按DWARF[21]格式保存在目标二进制文件的调试信息段.根据DWARF信息,调试器能获取地址和符号的对应关系、地址和编译单元的对应关系、能获取变量类型、变量存储位置等信息.然而,为了适应多种编译器和目标体系结构,DWARF格式十分复杂.本文借助软件包elftools来分析DWARF格式.通过elftools提供的API,IAT读取目标二进制可执行文件,获取其中全部函数及其地址范围、全部编译基本块及其地址范围等.如图6左侧②所示,IAT通过调试信息项sub_program获取所有函数的地址范围,形成以(function,address)为关键字的函数集合.IAT通过调试信息项line_program获取编译单元,并通过所有函数过滤出可执行编译单元,形成以(file,line,column)为关键字的运行单元集合.这样,就可以通过分析函数集合和运行单元集合的命中性和执行时间来完成软件分析.
4.3 覆盖标记与调用计算
在基本块和源码信息还原后,IAT逐一遍历基本块完成软件分析.在本文中,软件分析指对软件call graph,function profile,coverage,control flow等信息分析.对于每一个基本块,如果该基本块地址范围(start_PC,end_PC)命中函数集中某(function,address)的地址范围,则增加该函数运行时间,并标记函数已覆盖;如果该基本块地址范围(start_PC,end_PC)命中运行单元集合中的某(file,line,column)运行单元,则标记该(file,line,column)运行单元已覆盖.如果该基本块包含dest_PC,那么标记该控制流转移过程和函数调用关系.
对全系统仿真来说,在进行控制流和函数调用关系解算时还需要考虑系统中断的影响.这是因为一些时候主控制流会被中断控制流打断,中断控制流会被计入主控制流或者中断函数被计为被打断函数的子函数.这样,一方面IAT必须将中断控制流从主控制流中剪去;另一方面,IAT必须记录被中断打断的主控制流,以便中断控制流退出后将控制流接续到被打断的主控制流.被中断所打断的中断控制流可以采用相同的方法解决.
5 插桩实验与程序运行结果
本文采用EEMBC组织提供的嵌入式性能评估套件CoreMark1.0[22]完成插桩性能测试和插桩结果分析. CoreMark程序测试集包含链表、矩阵、状态机等相关操作的性能测试用例.
5.1 性能测试与优化
插桩后,当程序执行探针时,QEMU将目标机程序运行时信息输出到指定文件.本文在2个数量级上运行CoreMark,即分别插桩运行CoreMark 10~150次和执行CoreMark 10 000~150 000次,计算插桩代价.这是因为,日志输出I/O严重影响了仿真性能.如图7~8所示.在图7中,浅色(蓝色)(T)数据系列表示原QEMU运行CoreMark的结果为1 690 iter/s;深色(橙色)(NIOST)数据系列表示插桩但不进行日志输出的修改,其运行CoreMark的结果为1 324 iter/s,性能下降21%.然而,插桩并进行I/O的修改最快仅为0.21 iter/s,性能下降99.987%,如图8所示.这表明插桩本身对仿真性能的影响远小于I/O对仿真性能的影响,为本文第3节的性能优化提供了依据.因此,本文做了大量的工作来减少插桩过程中I/O对仿真性能的影响,如3.4节所述.通过优化,仿真性能得到显著提高,如图8所示.图8中,最浅色(蓝色)(GT)数据系列表示包含获取时间的QEMU修改,其仿真运行CoreMark的结果为0.08 iter/s;最深色(橙色)(NT)数据系列表示不包含获取时间的QEMU修改,其仿真运行CoreMark的结果为0.13 iter/s,与GT相比性能提高1.70倍;较深色(绿色)(NST)数据系列表示不获取时间,每个基本块仅有一个插桩点的QEMU修改,其仿真运行CoreMark的结果为0.21 iter/s,与NST相比性能提高1.57倍,性能累计提高2.68倍.
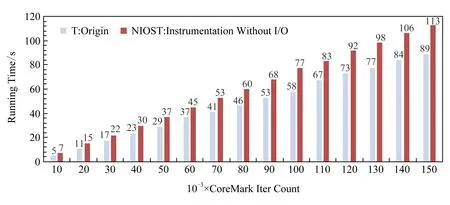
Fig. 7 Instrumentation without I/O图7 插桩不进行I/O
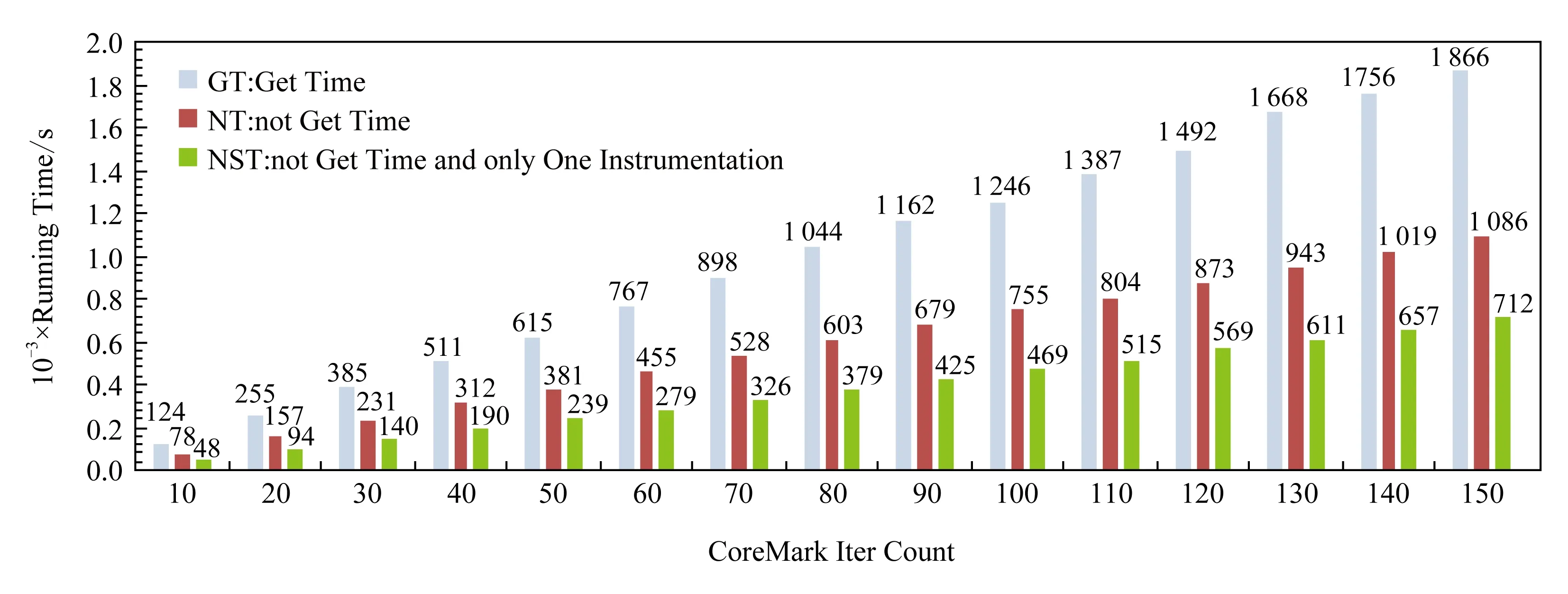
Fig. 8 Instrumentation with I/O图8 插桩进行I/O
然而,这仍然远不能满足实际需要,还需提高仿真性能.为进一步减少插桩对仿真性能的不良影响,本文通过实验研究分析,发现对日志进行分批集中输出,而不是产生1条就输出1条,即不是在每一个桩点都进行输出,仅在日志达到指定的缓冲区大小后进行日志集中输出写入文件,可以有效地提高插桩后程序的仿真执行效率,如图9所示.图9中浅色(蓝色)(B1K)数据系列表示将跟踪日志输出缓冲设置为1 KB时,其仿真运行CoreMark的结果为64.41 iter/s;深色(橙色)(BKK)数据系列表示将跟踪日志输出缓冲设置为1 MB时,其仿真运行CoreMark的结果为64.61 iter/s,与B1K相比速度提高0.003倍.由此可见,缓冲大小对仿真速度并没有显著提高,然而采用集中输出日志的方法比在每个桩点中都进行日志输出,仿真性能提高26.24倍,同不进行优化相比,仿真性能提高303.43倍.因此,本文最终选择采用优化后的集中输出方案,仿真运行CoreMark的结果为64.41 iter/s.
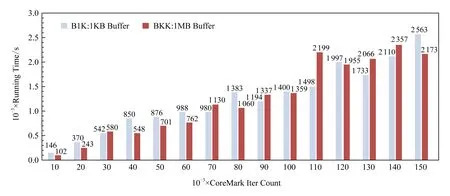
Fig. 9 Instrumentation with buffered I/O图9 插桩进行缓冲I/O
5.2 实验结果
根据设计,IAT工具可以分析call graph,function profile,coverage,control flow等.为减少IAT工具分析数据量,本文将CoreMark的迭代次数设置为3次后通过IAT工具分析日志记录,产生的结果为:
1) 函数调用关系
通过IAT工具,实验分析得出CoreMark的main函数调用关系,如图10~12所示.图11和图12为图10中的子函数,其中图11展示了本文对CoreMark的移植方法.
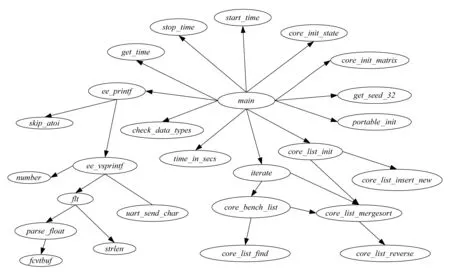
Fig. 10 Function main call graph图10 函数main调用图
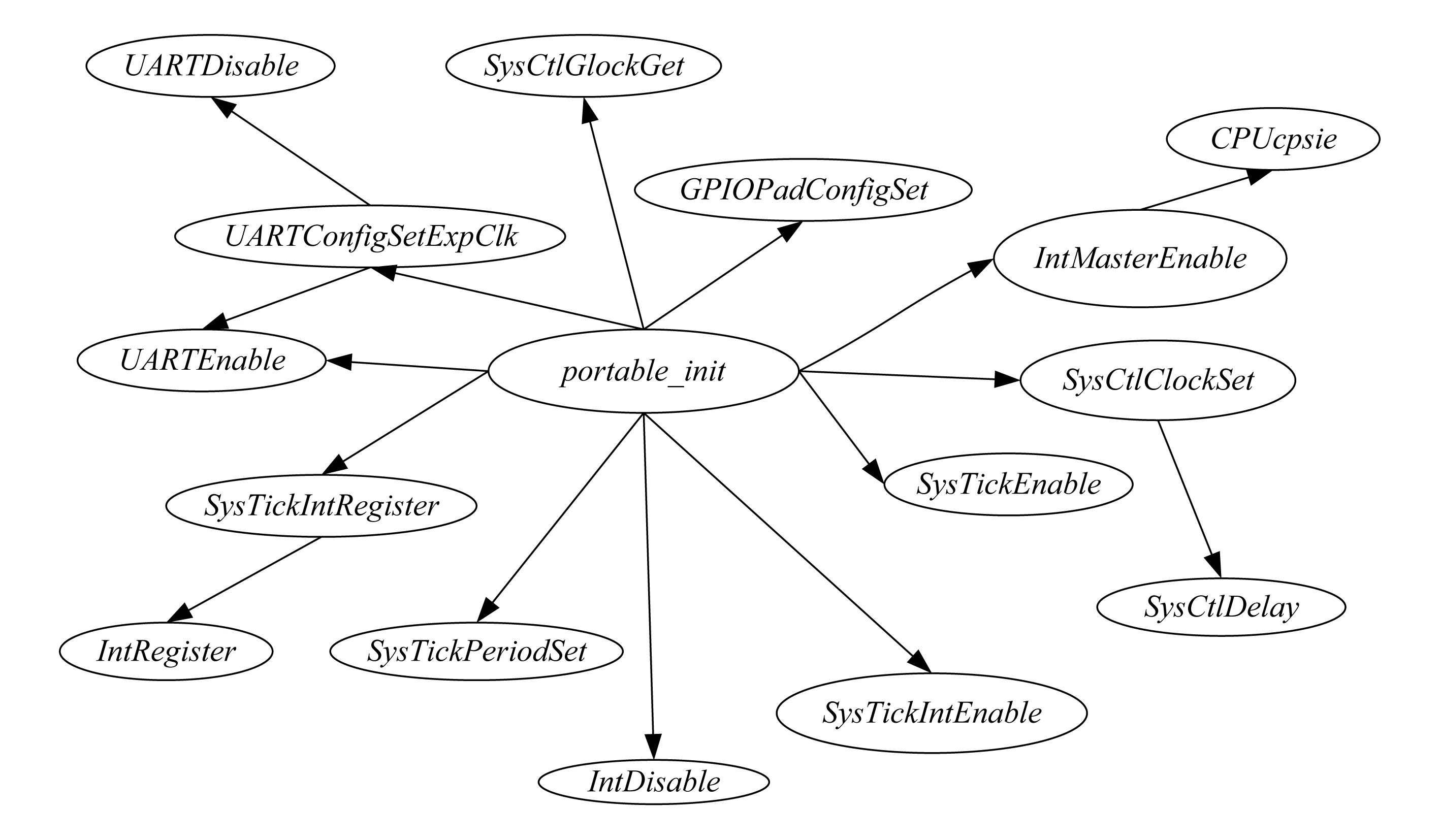
Fig. 11 Function portable_init call graph图11 函数portable_init调用图
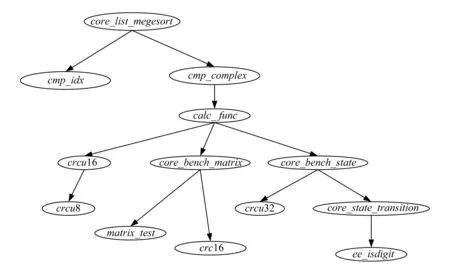
Fig. 12 Function core_list_mergesort call graph图12 函数core_list_mergesort调用图
和使用程序源码分析调用关系不同的是,动态分析得出的调用关系仅仅包含软件运行时覆盖到的调用.但是,实验表明,动态分析函数调用关系具有自己的特点,那就是它可解算出使用函数指针调用的子函数.如图12所示,函数core_list_mergsort通过指针调用了2个链表项比较函数cmp_idx和cmp_complex.
2) 函数剖面分析
通过IAT工具,实验分析得出CoreMark和移植函数中,消耗CPU时间最多前5名依次是core_state_transition,crcu8,core_list_find,core_bench_state,core_list_mergesort,分别消耗的指令计数是427 966,135 551,79 578,33 960,33 787,分别占总运行时间55%,17%,10%,4%,4%.如图13所示.分析完成后,软件设计者可根据上述信息进行软件优化.
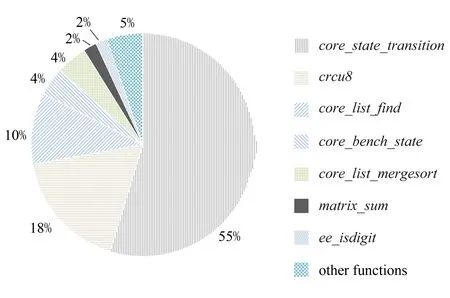
Fig. 13 Function profile图13 函数剖面分析示意图
3) 覆盖分析
通过IAT工具,实验分析得出CoreMark函数和移植函数共计79个,在执行中共覆盖其中52个函数,覆盖率为65.82%.如图14所示,图14中纵坐标为CoreMark中的函数,横坐标值为1的函数表示该函数为执行路径所覆盖,反之值为0的函数表示该函数未被执行路径所覆盖.
通过IAT工具,实验分析得出CoreMark共计包含1192个可执行编译单元,其中444个单元为执行所覆盖,覆盖率为37.24%.如图15所示,图15中纵坐标为(file,line,column)三元组,横坐标通过1和0分别表示该三元组标识的语句块执行与否.通过这些信息,可以解算软件语句覆盖率.如果将这些信息同源码信息、执行控制流信息结合起来,则可以解算软件分支覆盖率、MC/DC覆盖率等.由于篇幅有限,本文不再赘述.
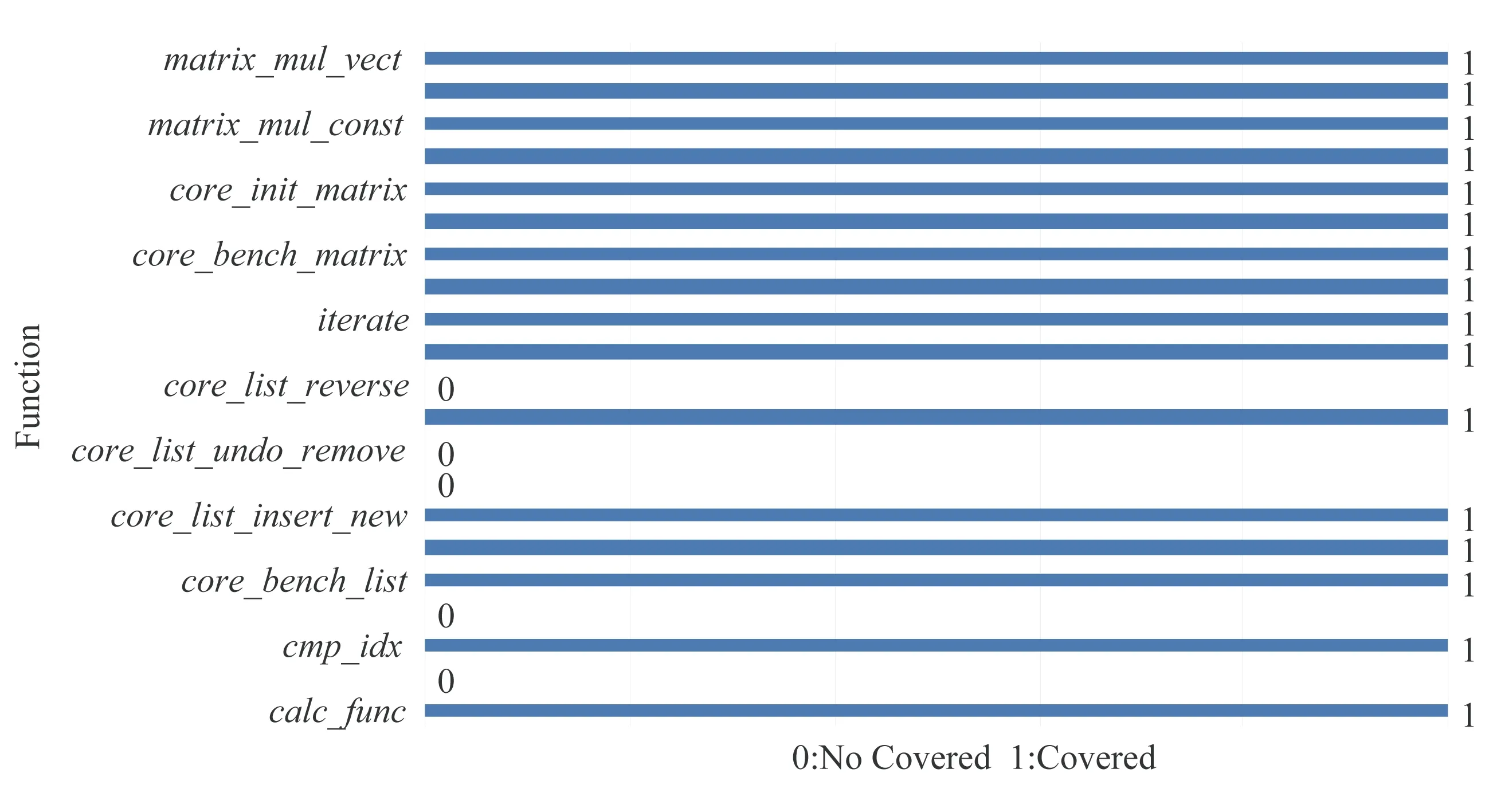
Fig. 14 Function coverage图14 函数覆盖情况示意图
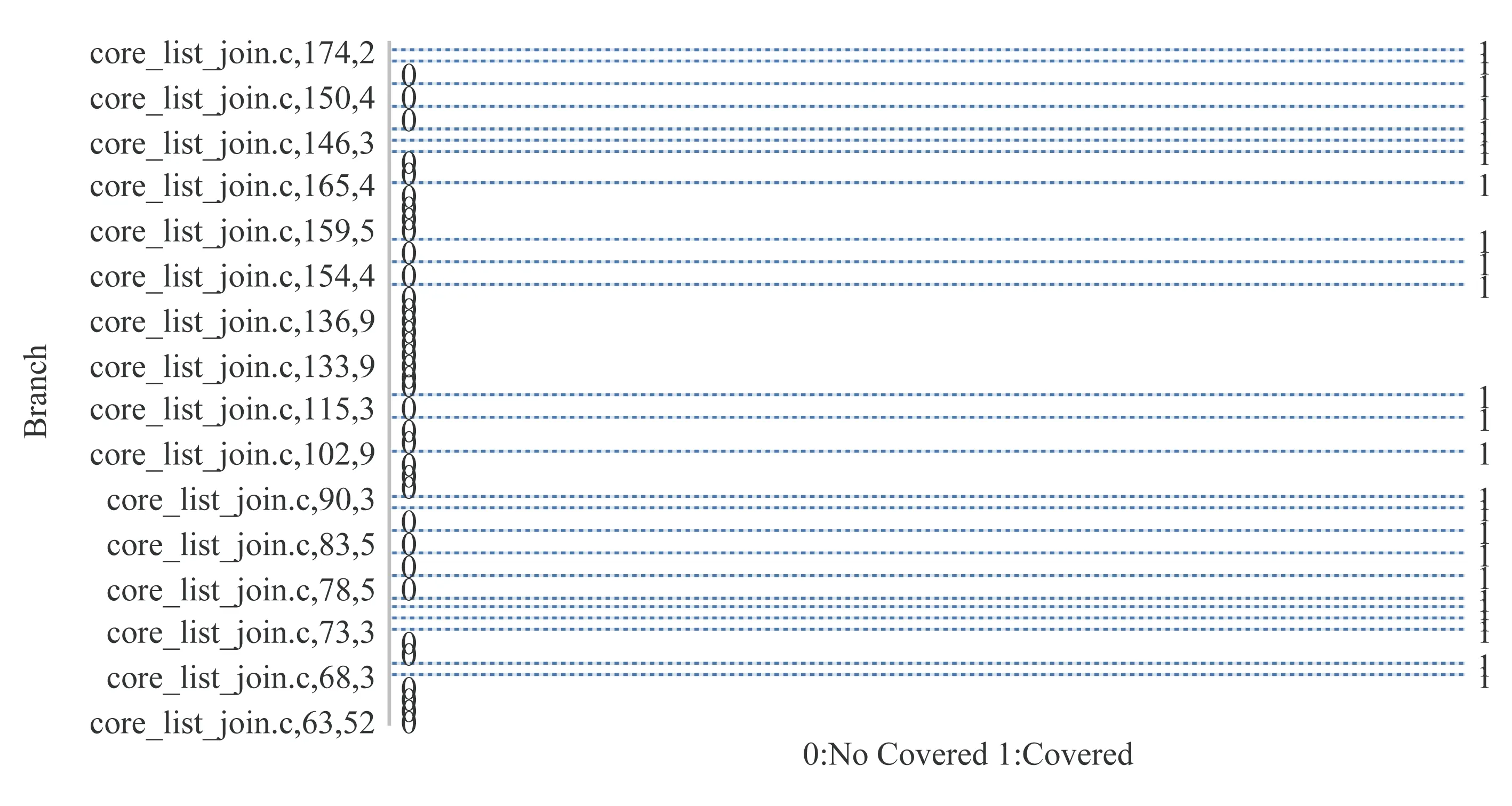
Fig. 15 Branch coverage图15 分支覆盖情况示意图
6 总 结
本文在QEMU的动态二进制翻译技术的基础上,突破基本块中间码动态插桩、基本块运行时间统计、中断对控制流影响消除等关键技术,对QEMU进行动态二进制插桩改造,成功完成软件运行信息动态收集.并在此基础上,设计了插桩日志分析工具IAT,完成了对软件的函数调用、函数剖面分析、函数和分支覆盖率统计等功能.实验结果表明:通过本文的工作,可以有效解决嵌入式全系统软件的二进制插桩问题.
