一种基于自更新的简单高效Cache一致性协议
2019-04-18何锡明黄立波王志英
何锡明 马 胜 黄立波 陈 微 王志英
(国防科技大学计算机学院 长沙 410073)
共享存储是当前使用最为广泛的并行编程模型,然而复杂的一致性协议使设计高效、低功耗、可扩展的多核共享存储系统变得十分困难.为了满足一致性的定义,一致性协议必须对写操作立即响应,失效其他核cache备份.这就要求目录协议实时地记录cache的备份并发送间接消息,或者要求监听协议广播消息去失效备份.除此之外,当前的协议还会增加各种稳定状态(独占E或者拥有O)来提高性能,增加众多中间状态以处理各种情况下出现的竞争.例如GEM5[1]中实现的MESI(modified exclusive shared or invalid)目录协议在L1中就有15个状态.一直以来,大多数的共享存储多处理器实现cache一致性都是基于目录协议.在国际上,针对cache一致性协议的存储开销和验证开销的优化设计层出不穷[2-7].而在国内,研究者们在一致性协议功能扩展和性能优化等方面取得了一系列的成果[8-10].
而实际上,在多核程序运行过程中,大部分的数据都只被一个处理器访问(甚至在程序并行阶段),我们称之为私有数据.私有数据仅由一个处理器访问,不存在cache一致性的问题,不需要一致性的维护.这种数据特性被越来越多的研究者关注,有的研究者利用这种共享特性过滤监听协议中多余的消息来降低监听协议的网络开销[11],有的研究者利用这种共享特性对目录协议的存储开销进行优化,以提高目录的利用率[2,5].
2011年Cuesta 等人[2]利用数据划分的方法对协议进行优化.他们通过测试并行测试集SPLASH-2(Stanford parallel applications for shared memory)中的8个程序、 scientific benchmarks中的2个程序、ALPBench(all levels of parallelism benchmark for multimedia)中的4个程序、PARSEC(Princeton application repository for shared-memory computers)中的4个程序,发现平均有75%的数据块(64 B)是私有的.他们在目录中忽略这些私有数据块的信息,有效地提高了目录的利用率.实验结果表明:在相同的目录大小情况下,他们的方案获得15%的性能提高.然而他们这种针对于目录利用率的优化并没有真正地解决协议中的目录开销、大量的一致性状态和间接访问等问题.2012年Ros 等人[12]利用划分私有和共享数据的方法,进行动态的写策略切换.这种写策略对私有数据进行写回,对共享数据进行写直达,简化了一致性状态.利用并行程序的数据无竞争(data race free, DRF)模型[13],在同步点进行共享数据自失效的方法完全避免了目录的存储开销.相对于目录协议,他们的设计平均减少了14.2%的系统能耗.但是写直达方式以及同步点自失效的方法大大增加了系统cache的缺失率,影响系统性能.
针对上述问题,本文主要研究共享存储一致性协议的简化.在满足DRF的模型下,设计了一种基于自更新操作(self-updating)只包含2个稳定状态(valid/invalid)的简单高效一致性协议,简称VISU(valid/invalid states based on self-updating)协议.协议的简化主要体现在2个部分:
1) 完全消除目录和间接事务.在目录协议中,目录的主要功能是记录每个共享备份的位置以便获取最新的数据和失效过期的备份(间接事务).VISU协议利用数据的共享特性,进行私有共享数据块的动态划分.在共享数据方面,VISU协议采用了写直达和自更新操作,LLC(last level cache)始终保持着最新的共享数据,同时自更新操作及时地更新过期的备份.在私有数据方面,VISU协议采用写回方式,在协议中不需要目录记录信息,不进行一致性的维护(类似于单核访问).因此整个协议消除了目录和间接事务.
2) 简化成2个稳定状态.通过TLB表项提供的页面粒度的私有共享信息,VISU协议在cache line中只需要2个稳定的状态(valid/invalid)就能正确地满足一致性,同时获得了与2种稳定状态的MESI协议相当甚至更优的性能.
1 VISU一致性协议正确性论证
为了论证VISU协议的正确性,首先介绍关于一致性协议需要满足的2个条件,然后具体描述VISU协议,最后结合定义与描述论证VISU协议的正确性.
1.1 一致性的定义
Sorin 等人[13]定义一致性:1)同一时刻满足对于同一存储单元只能一个写或者多个读(single-write multiple-read, SWMR);2)在每个时期开始阶段存储单元的值都必须和最新一次的读写时期结束阶段的值相同(data value invariant),本文称之为数据最新原则.
1.2 VISU协议的描述
本文设计一种基于自更新操作只包含2个稳定状的简单高效VISU协议.协议可分成私有和共享2个独立的部分.首先我们介绍数据无竞争的编程模型,然后介绍VISU协议中私有数据和共享数据的协议.为了直观地阐述协议,假设系统为2级cache,L1 cache和LLC(last level cache).
数据无竞争的编程模型保证在程序中无数据竞争,即当2个不同的线程同时访问相同的存储单元且至少有一个是写操作时,必然存在同步语句把它们分开.数据竞争经常导致程序的错误.DRF编程模型是C++和Java高级编程语言存储模型的基础,绝大部分并行程序都满足DRF编程模型.因此VISU协议利用了程序的DRF特性进行一致性的设计.
VISU协议在同步点进行自更新操作以简化间接事务,并利用数据的共享特性,把协议分成私有和共享2个独立的部分:
1) 私有数据协议.私有数据协议类似于单核处理器的数据访问,消除了私有数据冗余的一致性维护.L1 cache采用了写回的方式.
2) 共享数据协议.与简单的私有数据协议相比,共享数据协议在L1 cache中采用写直达的方式代替写回方式.同时,共享数据在同步点进行自更新操作.
① VISU协议针对私有数据的处理.VISU协议对私有数据处理类似于单核处理器的处理,采用cache写回策略.图1和图2展示了2级cache的VISU协议.图1展示了协议中的主要事务读(read, Rd)、写(write, Wrt)、写回(write-back, WB).图2为VISU的状态转换图,2种稳定状态(V,I)和2种中间状态(VI, IV),其中图2(a)为L1 cache控制器的状态转换图,图2(b)为LLC 控制器的状态转换图.
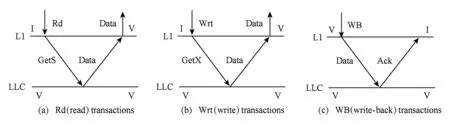
Fig. 1 VISU:Rd, Wrt and WB transactions of private data图1 VISU 私有数据读(Rd)、写(Wrt)、写回(WB)事务

Fig. 2 VISU:State transitions of private data图2 VISU 私有数据协议状态图
当发生读(Rd)缺失时,如图1(a),L1 cache发送GetS到LLC,然后获取Data数据;当发生写(Wrt)缺失时,如图1(b)所示,L1发送GetX到LLC中,LLC返回Data数据.由于数据为私有数据,其他核不存在数据的备份,所以读缺失和写缺失不需要向其他核发送间接事务.当L1 cache发生驱逐时采用写回策略(WB),如图1(c)所示,把脏的数据Data写入到LLC中,并返回Ack消息.图2(a)(b)分别展示了L1 cache控制器和LLC控制器的状态转换图.图2(a)左半部分I→IV→V展示了 L1 cache发生读写缺失,发送了GetS/GetX消息,然后接收到数据Data的状态转换,V→V展示了读写命中的状态转换.图2(a)右半部分V→VI→I展示了L1 cache的驱逐,L1发送WB事务把脏的数据写入到LLC中,然后接收到Ack消息的状态转换.图2(b)左半部分展示了LLC控制器响应L1 cache的GetS/GetX消息,然后进行I→IV→V(LLC无数据时,从内存中读取并返回Mem_data数据)或者V→V的状态转换.图2(b)右半部分则是LLC发生驱逐时,把脏的数据(Own-put)写入到内存中并返回Ack消息的状态转换.整个协议只包含2种稳定状态V和I、2种中间状态VI和IV,并且不需要目录和间接事务.
② VISU协议针对共享数据的处理.为了满足一致性的定义,一致性协议必须对写操作立即响应,失效其他核cache备份,返回最新的数据.因为没有了目录记录数据的共享者和拥有者,VISU协议对于共享数据的处理就要确定最近写入数据的位置并失效过期的备份,所以VISU协议添加了一个额外的自更新操作,用以自动更新过期的备份.相比于私有数据协议,共享数据协议用写直达操作代替写回操作,保证在LLC中始终存放最新的数据,从而使得共享数据协议与私有数据协议一样的简单,没有目录和间接事务.
图3展示了共享数据的读(Rd)、写(Wrt)、写直达(WT-timeout)、同步点(synchronization, Sync)四种事务.

Fig. 3 VISU:Rd, Wrt, WT-timeout and Sync transactions of shared data图3 VISU共享数据读(Rd)、写(Wrt)、写直达(WT-timeout)、同步点(Sync)事务
如图3(a),首先对于读缺失,L1 cache发送GetS到LLC中获取数据Data.对于写缺失,如图3(b),L1 cache发送GetX到LLC获取数据,这部分与私有数据协议相同.不同的是在写操作之后,共享数据协议要进行写直达(WT)操作,把写入的数据及时地写直达(WT)到LLC中,这样保证LLC一直拥有最新的数据.为了降低写直达产生的大量报文,如图3(c)所示,协议采用了延时写直达(WT-timeout)的方式.最后为了更新过期的备份,协议利用DRF编程模型识别同步点,在同步点(Sync)进行自更新操作(SelfU).如图3(d)所示,L1 cache发送SelfU到LLC中,LLC返回最新的数据,主动地自更新操作消除了间接的失效.
1.3 VISU协议正确性论证
本文1.1节引入了描述cache一致性协议正确性的2个条件:单写多读SWMR和数据最新(data value invariant),这里我们将论述在DRF编程模型下VISU协议满足这2个条件,即论证协议的正确性.
首先私有数据被单一处理器访问,这些数据不存在cache一致性问题.故VISU对于私有数据采用了类似于单核处理器的cache写回(write-back)的访问方式.这满足单写多读和数据最新(data value invariant)条件,即满足cache一致性.
其次对于共享数据的访问,对比目录协议,VISU协议需要论证没有目录和间接失效事务的情况下,如何及时地失效过期的备份和保证读到最新的数据.
1) DRF编程模型中不同线程对同一个地址的读写之间必然存在同步操作,即在每一个写时期(写操作开始直到遇到同步点)不存在其他线程的读写操作.例如图3(b)(c)中LLC的虚线段就不存在其他线程针对同一地址的读写操作.利用写直达方式,每次写操作都能及时把最新的数据写入到LLC中,满足了定义中的单写多读的条件.
2) 因为不同线程对同一地址的读写操作(包括读写、写写、写读)之间必然存在同步点,每个同步点都要进行自更新操作.这样就能及时地更新过期的备份,保证在每个时期开始阶段存储单元的值和最近一次读写时期结束阶段的值(最新写入的值)相同.因此满足cache一致性定义的数据最新原则.
综上所述,对比cache一致性定义的2个条件,VISU协议在DRF编程模型下满足一致性.
2 VISU协议的具体实现方案
VISU协议的实现主要有3个部分:数据的划分和切换机制、协议中同步原语的支持 、同步点共享数据的自更新.
具体的设计方案如图4所示,从右半部分可以看出,当访存请求发生TLB缺失时,就进行页面粒度的数据私有和共享的划分(下文将具体描述).图4左半部分是根据私有共享的划分执行协议,然后进行写直达写回策略的动态切换.L1 cache发生缺失,就根据数据的私有和共享分别采用VISU协议中私有和共享数据处理的2个部分发送相应的请求,最终完成数据访存.下文将具体描述私有共享数据的划分、私有到共享的切换机制、协议中同步原语的支持、同步点共享数据的自更新4个部分的实现.

Fig. 4 The block diagram of the action in VISU图4 VISU协议实现框图

Fig. 5 Format of TLB entry and page table entry图5 TLB entry和页表项的组成
2.1 私有共享数据的划分
数据的私有和共享划分,成为了研究者研究的热点.部分研究工作利用硬件机制进行私有和共享的划分,这些方案虽然能够进行细粒度的数据划分,但是造成了大量的存储开销.有的研究者利用编译器进行划分,但由于在编译阶段较难判断数据的私有和共享,这种方案实现较为复杂.本文采用操作系统(OS)辅助进行私有共享数据的划分,Cuesta 等人[2]也采用了类似的划分方法.这种方案利用TLB 表项和页表项(page table entry)存储信息.这是一种页面粒度的私有共享划分方案,当一个页面中的某一个数据共享时,整个页面都标记为共享.
首先对于每一个访存请求,处理器会先查找TLB表项,进行虚实地址转换.每一个TLB表项主要由虚拟地址和物理地址2部分组成,再加上一些页面属性的标记位.TLB表项中往往预留一些标志位没有被使用从而允许在TLB表项中添加一个私有共享的标记位P,因此不需要额外的硬件开销.同理在页表项中添加P域和Keeper域,分别标记页面是否共享和页面的共享者(第1次访问这个页面的CPU),如图5所示.
当TLB表项缺失时,TLB表项和页表项中的域就需要进行处理.处理方法如图4中右半部分所示,访存请求因TLB表项缺失进行页表的访问,如果发生缺页,就造成系统异常,操作系统会进行相应的缺页错误处理并分配新的页面.如果页面被首次访问并且没有缓存在其他TLB中,操作系统设置新分配的页面为私有(P域设为1)页面且记录第1个访问的核为keeper;否则就判断页面的私有和共享的状态,若私有页面且其被不同的核访问,触发私有到共享的切换(下文将详细说明切换机制),切换完成后将页面置为共享(P域设为0),最后将设置好标志位的表项添加到TLB中.
2.2 私有到共享的切换机制
TLB缺失就进行页面的访问,当某个核首次访问一个页面时,页面被置为私有页面且访问的核作为页面的拥有者(Keeper).整个页面里的数据为私有数据,这些数据在L1 cache中采用写回的方式.第2个核访问这个页面,发现页面被Keeper设置为私有(P域为1),这时触发切换机制,向Keeper核发送中断,完成中断后设置页表项中的页面为共享(P域设为0).Keeper核接收到中断就更新这个页面的TLB 表项(设置为共享,P域设为0),把L1 cache中脏的数据写入到LLC中.完成切换后,所有核访问这个页面都会发现页面共享且Keeper核已经将最新的数据写入到LLC中,这样页面的数据就切换成了共享数据.
2.3 协议中同步原语的支持
同步机制通常是以用户级软件例程的方式实现,这些例程依赖于硬件提供的同步语句.在多处理器中实施同步所需要的是一组能够以原子方式读取修改和写入存储单元的硬件原语,例如“Test&Set”或者“Compare&Swap”.如果测试(test)或者比较(compare)一个条件满足,那么核就竞争到一个存储单元,执行原子的读修改写操作;否则在L1中对这个存储单元的备份进行旋转,直到存储单元的数据被其他核修改,即条件被改变.
在VISU协议中没有间接的失效操作.一个核结束了敏感区,释放了一个条件,在协议上不会去通知正在旋转的核条件的改变,从而难以完成同步操作.为此VISU一致性协议针对读-修改-写(RMW)的原子事务,采用重新读取LLC数据的方式(因为存在多个核访问一个数据,所以数据必然共享,LLC有最新的数据),让旋转的核能够感知条件的改变.具体协议如图6所示,不妨设条件满足时数据为0,条件不满足时数据为1,L10遇到RMW原子指令,不管当前是有效还是无效状态(I/V),都发送GetX消息到LLC,LLC接收到GetX就阻塞LLC,防止原子指令被打断.L10获得数据Data(0)即条件满足(锁可用)进入修改写入状态R(0)W0(1),发送WT_lock(1),写直达数据1占用这个锁,并释放LLC的阻塞.此时程序进入敏感区(critical section)工作,直到释放条件W0(0).L1发送WT_unlock(0)操作写入0到LLC中,使条件重新可用.其他核执行RMW时,同样发送GetX消息,例如图6中L11,发现LLC被阻塞,则进入LLC的等待队列.当LLC不阻塞时,L11获得数据Data(1),发现条件不满足,L11不断旋转,直到竞争到条件满足读到Data(0),进入敏感区.这种绕过L1中的数据,直接访问LLC的方式,造成了一定的性能损失,但同步操作在整个程序中出现的频率很小,整体性能损失依然可以被接受,第3节的实验评估也验证了这一点.VISU协议通过这种方式实现了对同步原语的支持.
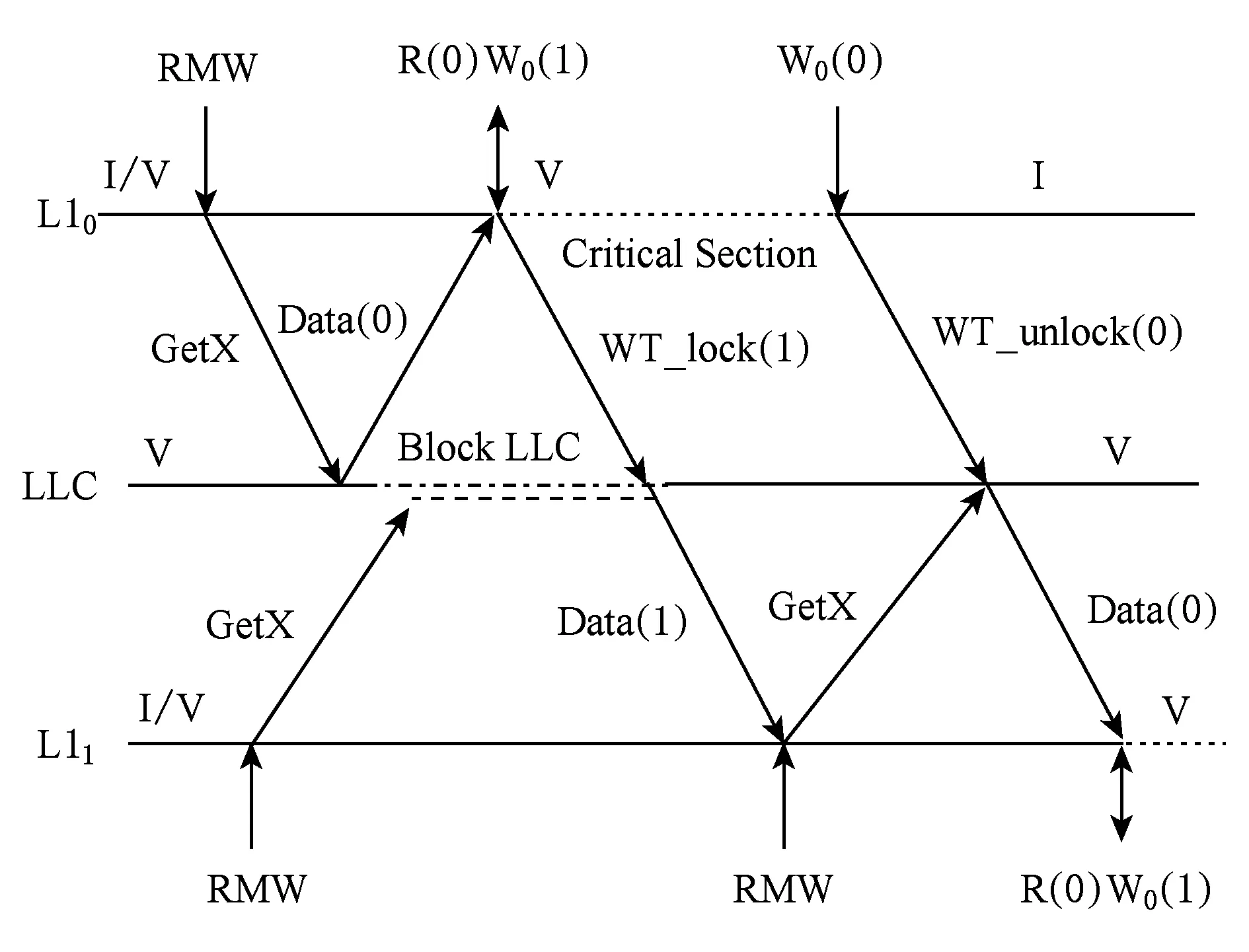
Fig. 6 The atomic RMW transaction of shared data in VISU图6 VISU中共享数据的原子操作(RMW)协议
2.4 同步点共享数据的自更新
在一致性协议中,监听协议通过广播消息作废所有过期的备份,而目录协议通过目录节点间接转发消息失效过期的备份.之前有研究者采用了自失效操作,即每个核在同步点失效各自L1 cache中过期的备份来保证协议的一致性,降低协议的复杂性.共享数据被多个核使用,很大程度上可能被多次地读写.如果每一个同步点都采用自失效操作来失效所有的共享数据,无疑会大大增加共享数据的cache失效率.基于此,本文提出了在同步点进行自更新操作.自更新操作不仅能够有效地降低共享数据cache的失效率和提高性能,而且能够起到和自失效操作相同的作用,保证协议的正确性.每一个进入L1 cache的数据都会根据TLB表项中的私有共享标志位P在cache line中设置共享和私有.基于这些私有共享标记位,当程序识别到同步点时,会完成共享数据从LLC到L1 cache的更新.考虑到随着程序的运行,共享数据的数量会不断地增加,为此本设计中设置了一个阈值,当共享数据数量大于这个阈值时,L1 cache中就采用自失效操作失效共享数据以防止共享数据的累增.
2.5 实现中优化设计
1) 写直达的粒度优化.VISU是基于数据无竞争的情况下满足一致性,但是软件的DRF并不以cache line为粒度.考虑2个核在L1中同时拥有一个cache line的数据,当这2个核同时对这个cache line中不同的字(word)进行写操作时,在软件层上这2个写操作并不违反DRF原则,因此这2个并发的写操作之间不存在同步语句.如果对这种情况不加以处理,最终基于cache line粒度的协议延时写直达就会交错覆盖相互的值.考虑到这个问题,设计中采用了基于word粒度的写直达方式,在L1 cache line中针对每一个word设置1个dirty位.在写直达到LLC时,不同的核只写入其修改的字(word)而不影响其他字.
2) 直接内存处理(direct memory access, DMA)协议设计.DMA是现代处理器的重要特色,在协议上也必须对其有相应的支持.DMA直接使用物理地址进行数据的搬移,不需要经过TLB的虚实地址转换.因此VISU协议中的私有和共享的划分对其并不适用,故此设计采用了广播DMA请求的方式,失效L1中过期的数据,写回脏的数据到LLC中.上述操作完成后,DMA访问LLC,获取和写入数据,完成读取和写入操作.
3 实验结果与分析
3.1 实验环境
为了评估VISU协议的性能,实验采用GEM5[1]全系统模拟器模拟,搭载Linux 2.6.22 操作系统,采用GARNET[14]仿真片上互联网络.同时利用CACTI 6.5[15]工具采用32 nm的技术工艺对cache的开销进行评估.设计中仿真8核的片上多核处理器(chip multiprocessors, CMP)结构,运行SPLASH-2中的测试程序.SPLASH-2程序分成了kernels和apps两类程序,实验中分别选取了这2类中的FFT(64 KB complex doubles),LU(LU-contiguous_block,512×512 matrix),LU-Non(LU-non_contiguous_block,512×512 matrix)和Water-Nsq(Water-nsquared,512 molecules)并行测试程序进行测试.模拟器中主要的参数如表1所示:

Table 1 Configuration of System表1 系统参数配置
实验过程中通过识别操作系统和并行程序中的同步点(旋转锁、栅栏、中断)进行自更新操作.利用GEM5全系统模拟器,仿真整个并行程序,统计程序并行阶段的数据.实验中仿真了3种一致性协议:1)MESI目录协议,该协议由2级cache组成,实时存储着目录信息.MESI目录协议根据目录记录的信息发送消息失效所有的共享者(写缺失)或者发送消息获取最新的数据并降级存在的E/M状态(读缺失).2)VIPS协议,这种协议由Ros 等人[12]提出.VIPS协议在L1中也只有2种稳定的状态,与本设计中的VISU设计类似,但VIPS协议在同步点上采用的是自失效操作.采用同步点自失效的方法保证了协议的一致性,但一定程度上增加了L1 cache的缺失率.3)本文提出的VISU协议.该协议在同步点采用自更新的方式,即在同步点对共享数据进行自更新,提高cache的命中率,从而提高系统性能.
在实验过程中,延时写直达(同步点之前)的延时时间设为500 cycle.写直达延时主要是因为每次写一个数据,就很可能会访存相应cache line的其他字(word)的数据.延时写直达可以合并写操作,然后一次性写直达到LLC,降低由写直达造成的大量报文.但是延时写直达必须在下一个同步点之前完成,所以这个延时时间影响着协议的正确性和系统性能.
3.2 程序请求的分类
VISU协议动态识别程序中的私有和共享数据,采用2种不同的方法进行处理.实验中运行了FFT,LU,LU-Non,Water-Nsq这4个程序并记录了并行阶段这4个程序对私有数据和共享数据发送请求的数量,把请求分成了4类:取指请求、对共享数据的请求、对私有数据的请求以及同步相关的请求,如图7所示:
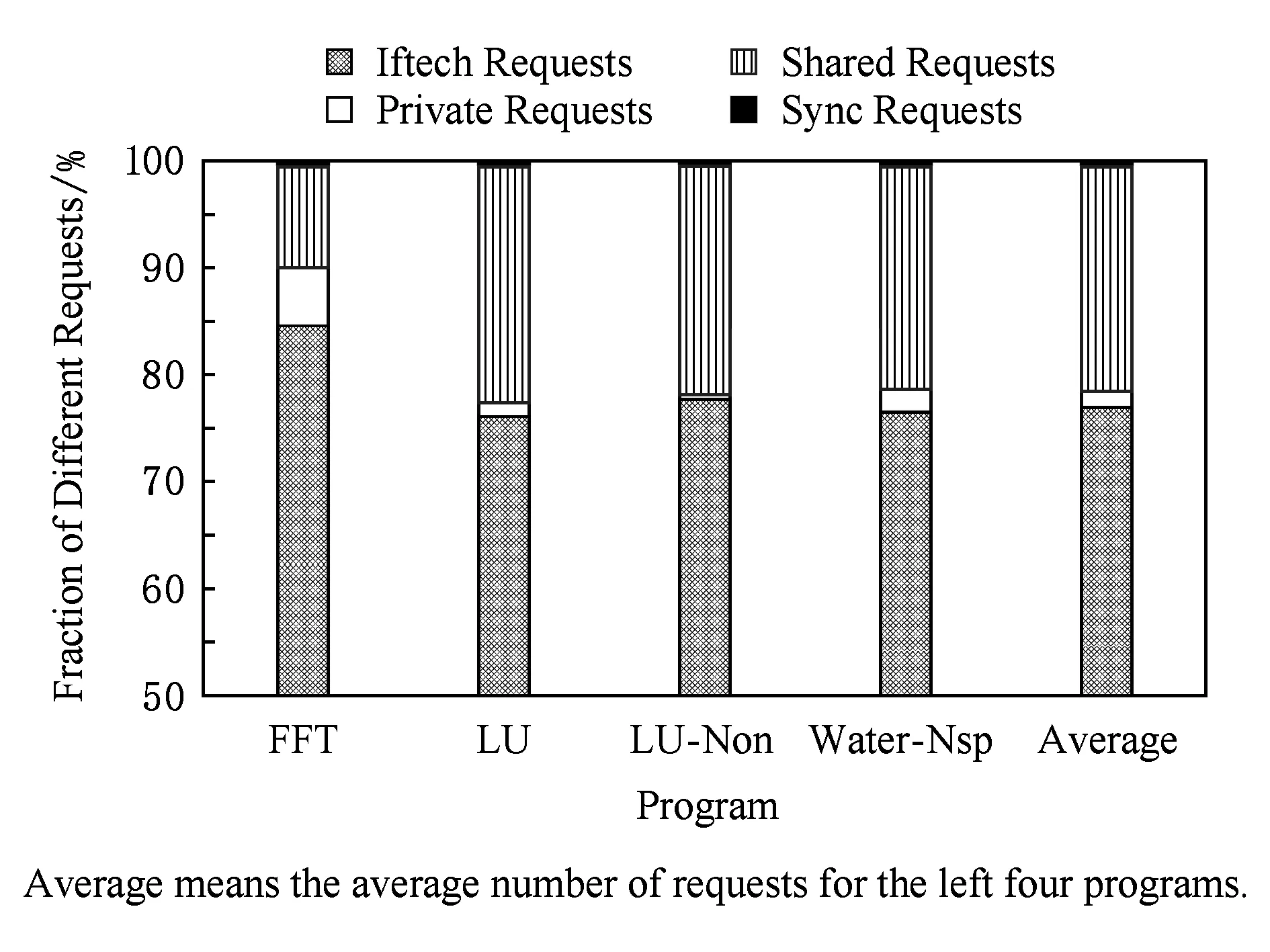
Fig. 7 Fraction of different requests in parallel programs图7 并行程序中各类请求的比例
一般情况下,取指请求是一类只读请求,在VISU协议中采用写回的方式进行处理,不进行私有和共享的划分.从图7可以看出,私有数据请求比例在FFT中最大,占程序总请求的5.1%.若把私有数据请求和取指请求均作为私有请求处理(二者采用相同的私有数据协议),则私有请求数量占有比例高达90.1%.而在LU和Water-Nsq程序中私有请求占比较少(分别占有1.2%和1.8%)、共享请求占比大,这影响着这2个程序在VISU协议中的性能.整体上来看,私有请求(包括取指请求)平均占整个并行阶段请求的77.2%.在4个程序中(FFT,LU,LU-Non,Water-Nsp)同步相关的请求所占比例依次为0.11%,0.10%,0.08%,0.22%,其中Water-Nsp相对来说比例较高,4个程序同步请求平均占比0.14%.
3.3 VISU协议运行性能
为了分析VISU协议性能,实验测试了MESI,VIPS,VISU 这3种协议,并记录了程序并行阶段的运行时间,如图8所示.
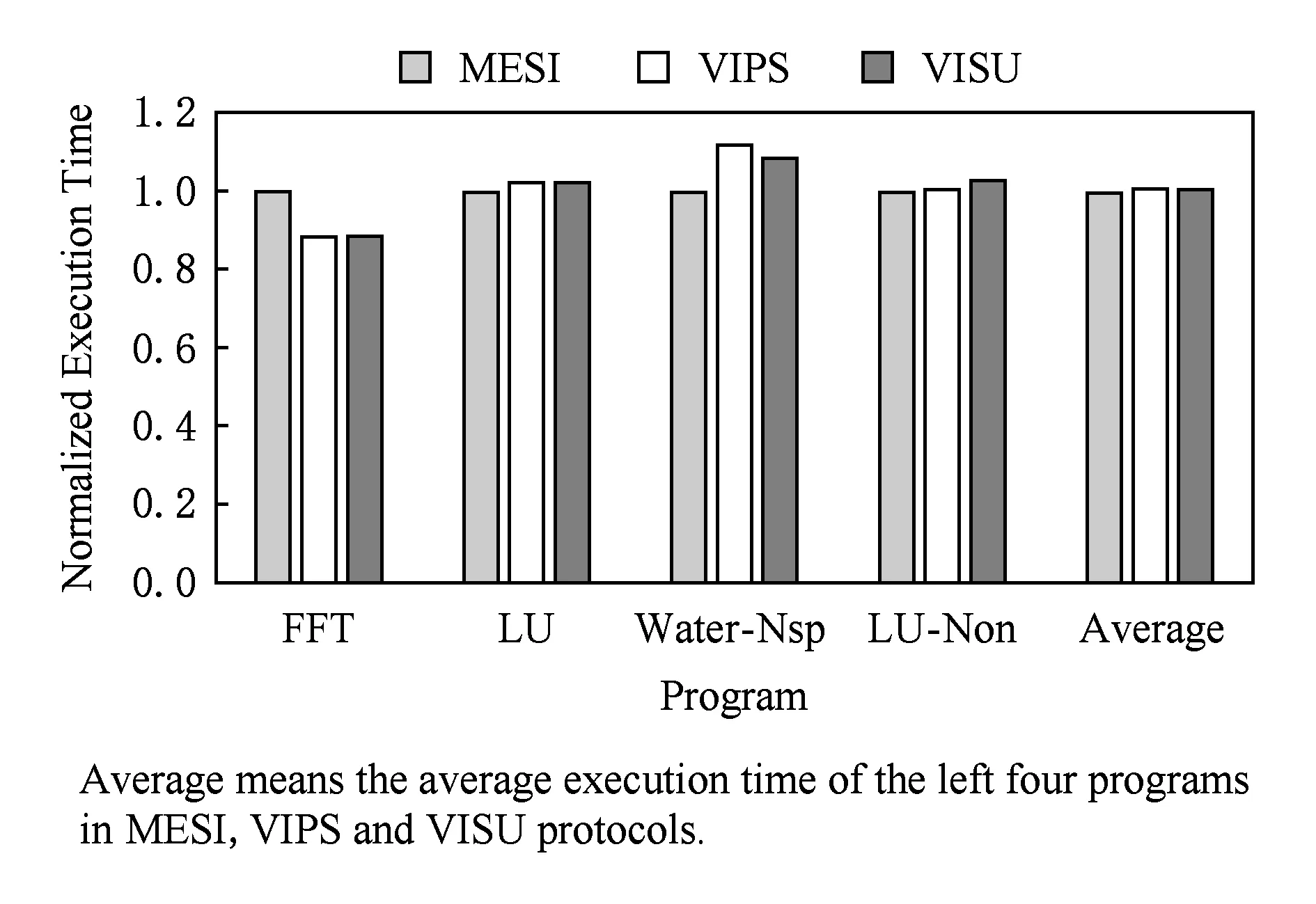
Fig. 8 Normalized execution time图8 归一化的运行时间
实验结果以MESI协议的运行时间进行归一化.平均来看,无目录、有2个稳定状态的VISU协议获得了与有目录、3个稳定状态的MESI协议几乎一样的性能.从FFT程序中可以看出,VISU性能较之MESI协议有11%的性能提升,一方面来源于私有数据占有比例高;另一方面来源于同步操作,在VISU(VIPS)协议中对于同步操作进行自更新(自失效),这是一类为了保证正确性但开销大的操作,但在FFT中所占比例很少.Water-Nsp的同步操作占有的比例较大,同时私有请求比例较少,所以VISU协议的整体性能相比于MESI协议有了8%的性能损失.在同步点比例大时,VISU协议相对VIPS协议能够降低由于同步点导致的大量cache失效,从Water-Nsp程序上可以看出,相对VIPS协议,VISU有了4%的性能提升.整体上来看,简单地更新有限共享数据的VISU协议性能略高于VIPS协议(平均0.2%的性能提高).
3.4 VISU的开销
在存储开销方面,表2为3种协议的特征对比, MESI目录协议采用全映射(full-map)目录.图9展示的是N节点系统的MESI协议基本的目录表项,其中2个主要的存储开销:每个数据block的拥有者(owner)和数据block的共享列表(sharer list),每个表项都需要增加lbN位和N位.这些存储开销严重地影响目录协议的可扩展性.在MESI目录协议中,目录信息存储在LLC的tag中,实验中测试了3种协议LLC tag的面积开销,如表2所示.VIPS和VISU协议没有目录,从而降低了25.4%的面积开销.
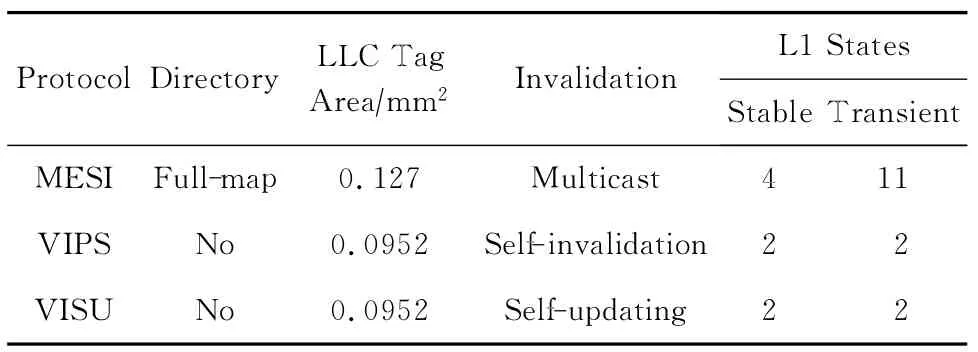
Table 2 Comparison of Three Protocols表2 3种协议对比
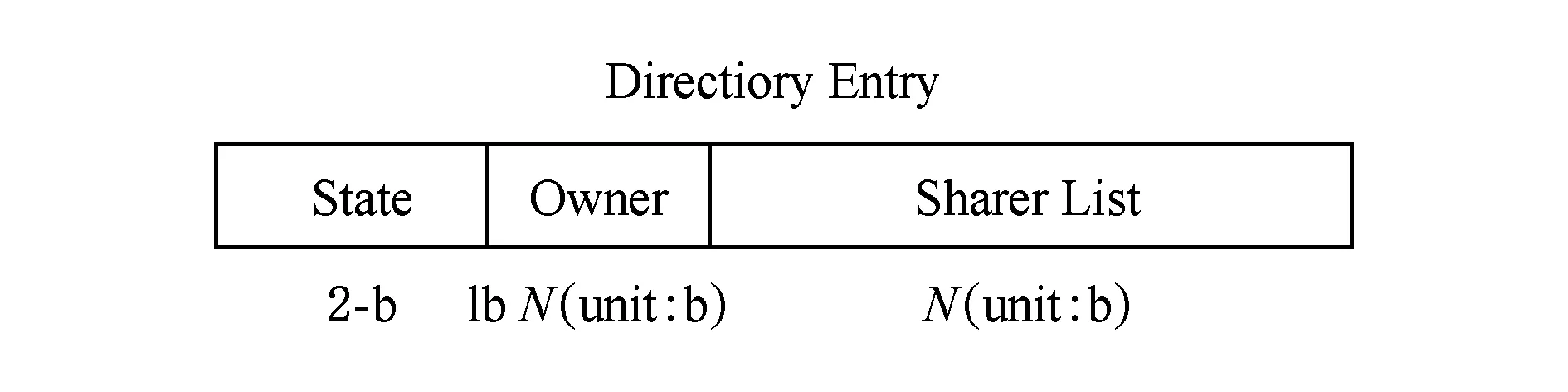
Fig. 9 Directory entry for a bock in a system with N nodes图9 N个节点系统中block的目录表项
cache一致性协议的验证问题是CMP设计中的重要课题,在验证开销方面,VISU与VIPS协议分别采用自更新和自失效的方式作废过期的备份,这是2种1对1的方式,而MESI目录协议采用的是利用目录的共享列表进行多播,如表2所示.
此外目录协议通过目录向数据拥有者(owner)发送数据请求,增加了额外的间接事务,而VISU和VIPS协议没有间接访问.VISU协议利用私有和共享数据的划分,把协议分成了独立的2个部分,可分别进行验证.同时VISU协议只有2个稳定状态:有效(valid)和无效(invalid),在L1 cache中只有2个中间状态(IV,VI),相对于MESI协议有4种稳定状态、在L1 cache中有11种中间状态和各种间接事务,VISU和VIPS协议在验证方面具有显著的优势.
3.5 VISU中延时写直达的影响
为了进一步说明写直达中延时时间对于VISU协议的影响,实验中分别测试了100 cycle,500 cycle,1 000 cycle延时对于测试程序报文数量的影响.如图10所示:
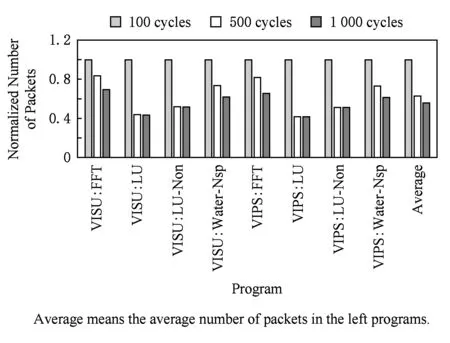
Fig. 10 Number of packects in the VISU and VIPS图10 VISU和VIPS写直达延时时间与报文数量
采用延时写直达,能够利用局部性原理,合并多次对同一个cache line的写操作,减少写直达的次数,降低整个系统的报文数量.但延时写直达操作,必须保证VISU协议的正确性和系统性能,确保写入的数据能够及时对其他核可见.从图10可以看出,当延时从100 cycles增加到500 cycles时,报文数量显著减少,平均减少了30.7%.但从500 cycles 增加到1 000 cycles,报文数量整体减少了6.8%,其中LU和LU-Non 这2个程序报文数量几乎没有减少.因此在VISU协议中设置延时写直达的时间为500 cycle.
3.6 VISU协议对cache缺失率的影响
VISU协议与VIPS协议的主要区别在于采用自更新的方式提高L1 cache的命中率.对于同步点采用自更新还是自失效,主要取决于2个同步点之间的数据是否会被再一次访问.图11描述的是VIPS和VISU协议的L1 cache失效率,以VIPS协议的失效率进行归一化.

Fig. 11 Normalized cache miss rate in the VISU and VIPS图11 自更新VISU协议与自失效VIPS协议缺失率
由于协议中自更新和自失效的数据都是共享数据,共享数据被多个核访存,很可能会被再一次访问到.同时为了解决在自更新的过程中共享数据不断增加的问题,在VISU协议中采用预设一个阈值,当共享数据的数量超过这个阈值时,超过的部分采用自失效,防止共享数据的累增.当共享数据的数量少于这个阈值时,则采用自更新方式.VISU协议采用最后访问的共享数据最先被自更新的策略,设置一个阈值x,对最后被访问的x个共享数据进行自更新,对其他的共享数据采用自失效,在本实验中设置x=50.利用在同步点进行自更新的方式可以明显地降低cache失效率,自更新的VISU协议相比VIPS协议平均降低了5.2%的L1 cache失效率.
4 结束语
本文针对于共享存储中的cache一致性协议进行了简化,提出一种没有目录和间接访问、没有众多一致性状态和竞争的cache一致性协议VISU.VISU协议的关键:1)区分私有和共享数据,对私有数据采用写回策略,对共享数据采用写直达策略;2)利用DRF编程模型中的同步点进行自更新.在VISU协议中,自更新是一种高效处理过期备份的方式.与一直以来获得广泛使用的目录式和监听式协议相比,VISU协议大大简化了复杂性,解决了一直以来困扰目录协议可扩展性的目录开销问题.VISU协议不仅不需要像监听协议一样广播大量的请求,并且还适用于mesh和torus等无序网络.
通过仿真与分析,相对于复杂的MESI协议,简单的VISU协议具有与之相当甚至更优的性能.接下来的工作将会针对VISU自更新操作,优化共享数据,提高自更新操作的效率.并进一步将VISU协议扩展到层次集群式的cache结构(hierarchical clustered cache)上,提高VISU协议的可扩展性.
