基于工作负载感知的固态硬盘阵列系统的架构设计与研究
2019-04-18许胤龙李永坤
张 强 梁 杰 许胤龙,2 李永坤,2
1(中国科学技术大学计算机科学与技术学院 合肥 230026)2 (安徽省高性能计算重点实验室(中国科学技术大学) 合肥 230026)
大数据时代,应对海量数据的存储分析,基于固态硬盘的容错阵列系统能够很好地解决海量数据的可靠存储和高效访问的困难.原因有2方面:1)容错阵列系统既能通过多盘I/O提供数据的高并发性,又能通过存储冗余信息保障数据的可靠性;2)固态硬盘相比机械硬盘,因其具有更高访问性能、更低能耗和更强抗震性等特点,进一步提升容错阵列系统的性能.
多块固态硬盘组成的容错阵列系统,往往按照轮转(round-robin)的顺序,并行地在各个固态硬盘上读写数据(即每块盘的地位相同).由于数据本身具有时间局部性及空间局部性的特点,易造成局部盘成为热点盘,进而会造成整个固态硬盘阵列的性能出现瓶颈(极端情况下会出现单盘热点),又由于固态盘有寿命限制,对某些盘的过多写易造成固态盘故障等问题,也会对整个阵列可靠性造成影响.本文在由8个固态硬盘(solid state drive, SSD)构成的RAID -0(redundant array of independent disks 0)阵列系统中测试不同企业级工作负载,均发现热点盘的现象.
如何保证阵列系统级的负载和磨损均衡以及如何区分各个固态硬盘在阵列中的角色,设计合理的固态硬盘阵列系统架构,对提升固态硬盘阵列系统整体性能及可靠性都有很重要的意义.
本文的主要贡献有2个方面:
1) 利用工作负载感知特性,在RAID -0阵列中设计了一种基于冷热数据分离存储的固态硬盘阵列系统架构HA-RAID(hotness aware RAID),并结合滑动窗口技术进行性能优化.实验结果表明,HA-RAID可将热数据相对均匀地存储到各个盘上,很好地实现了阵列系统级的负载和磨损均衡,从而将阵列中热点盘出现的比例降低到几乎为0.
2) 在真实的企业级工作负载下,相比传统RAID -0,HA-RAID可减少12.01%~41.06%的平均响应时间,很好地实现了阵列系统级的I/O性能提升.
1 相关研究工作
近年来,国内外开展了大量针对固态硬盘的相关研究.其中,许多工作关注固态硬盘本身的内部结构,进而分析并设计高效的垃圾回收机制,以提升固态硬盘的读写性能、延长使用寿命;另外,还有不少工作关注多块固态硬盘构成的存储阵列系统,利用数据冗余提髙数据的可靠性、延长固态硬盘阵列系统寿命并提升阵列系统性能,这些工作可以分别被概括为2方面:
1) 对于单个固态硬盘的研究.关注固态硬盘的内部结构,如文献[1]探索了固态硬盘的内部组成以及并行化等,同时实现相应的固态硬盘模拟器.关注固态硬盘逻辑地址到物理地址的映射方式,如文献[2-3]通过探索在不同的应用场景采用不同的地址映射方式来优化固态硬盘的性能.此外,还有关注固态硬盘的垃圾回收过程,如文献[4]通过建立分析模型探究了不同垃圾回收算法在垃圾回收开销和擦写均衡性之间的权衡关系,提出了可以根据需求调整的d-choice垃圾回收算法;文献[5-6]通过建立理论模型分析了固态硬盘垃圾回收开销与工作负载之间的关系,证明了将冷热数据分离存储在固态硬盘中能够大大改善垃圾回收性能;文献[7-8]提出了不同的热数据识别方法,以部署到固态硬盘中改善其读写性能、减少其垃圾回收开销等.
2) 对于固态硬盘阵列系统的研究.文献[9]研究了由多块固态硬盘构成的阵列系统,通过在多块固态硬盘之间引入冗余数据,进一步提高了系统的可靠性;文献[10]针对于固态硬盘的特点,构建了新型的适用于固态硬盘的文件系统;文献[11-12]通过构建可靠性分析模型对基于固态硬盘阵列系统进行了可靠性评估;文献[13]通过引入弹性条带机制解决了传统磁盘校验块更新方式不适用于固态硬盘阵列的问题等.
综合海量存储的背景和国内外研究现状可知,将固态硬盘应用于大规模存储系统(例如阵列系统)已经成为了当前的趋势和热点.尽管已经有很多针对于固态硬盘及其阵列系统的性能优化研究,但是其中仍然存在着很多的不足,特别是从感知工作负载的角度来优化固态硬盘及其阵列系统的性能方面,仍有着进一步的改善空间.如在固态硬盘中部署冷热数据识别方法用于冷热数据分离存储,以减少热点盘出现的概率,实现阵列级负载和磨损均衡,已有的热数据方法并不能很好地适应工作负载的变化.
2 阵列系统原始架构
在Linux内核的MD模块,固态硬盘阵列系统以条带的形式对阵列的存储空间进行统一编址.每个请求数据的逻辑地址根据阵列系统的编址方式,映射到某块盘上的固定逻辑地址(固态盘内部闪存转换层会进一步对该逻辑地址映射为固态盘上真实物理地址,该映射方式限定在单个固态盘内部映射,并不影响数据在阵列级别的分布).由4块固态盘组成RAID -0阵列系统如图1所示.图1中数字0…7, 8…15,分别代表扇区(sector,大小为512 B)0到7以及扇区8到15;1个页(page,大小为4 KB)包含8个扇区,如图1中,page 0包含扇区0到7;1个块(chunk)包含2个页,图1中的扇区0到15构成1个块;1个条带(stripe)包含4个块,条带大小可表示为
stripe_size=4×chunk_size=4×2 page=
4×2×8 sector=64 sector.
如果请求的数据(扇区编号为32~39)为热数据,根据阵列存储空间的编址方式,计算得到扇区编号为32~39的数据存放的物理地址:
stripe_num=32/stripe_size=32/64=0,
chunk_num=32/chunk_size=32/16=2,
dd_idx=chunk_num%disk_num=2%4=2,
chunk_offset=32%chunk_size=32%16=0,
sector_num=stripe_num×chunk_size+
chunk_offset=0×16+0=0.
因此,扇区编号为32~39的热数据存放在2号盘上,并且盘上的起始物理扇区号为0.各应用系统请求的数据具有时间及空间局部性原理,对某些数据的过多访问会造成对部分盘的过多读写,从而导致热点盘的出现.例如,对扇区编号32~39的热数据频繁访问,将导致对2号盘的过度读写,从而使2号盘变为热点盘.如果大部分I/O请求集中在2号盘,则不能充分发挥RAID阵列高并发的优势,进而造成整个阵列系统的I/O性能出现瓶颈.固态盘有擦写次数寿命限制,对某些盘的过多写,也会对整个阵列可靠性造成影响.
3 数据冷热区分算法
为避免第2节中提到的热点盘出现的问题,需对数据进行冷热区分,并对区分过的数据进行分别处理.设计冷热数据区分算法,首先要求其识别结果的有效性,否则不能达到冷热数据分离存储对存储系统性能的优化;其次要求算法识别过程的计算开销要尽可能小,以免降低存储系统的请求处理吞吐量.
先前的研究者们已经提出了很多有效的冷热数据区分算法,其中比较典型的冷热数据区分算法分别是:基于访问频次的算法DAMS[14]、基于缓存替换的算法Two-level LRU list[15]、基于访问频次和LRU分组的算法GLRU[16]、基于访问频率和最近信息的算法MBF[14-17]、基于采样技术的算法HotDataTrap[17-18].
DAMS假定可用的内存空间无限大,采用直接地址写次数统计方法,为每个逻辑块地址(logical block address, LBA)设立一个计数器,记录其写统计次数,图2为其算法流程.一个LBA请求页被识别为热数据,当且仅当其写统计次数大于等于预定义的阈值.
不同的工作负载一般表现出不同的访问特征,为了能够精确地捕获各种工作负载的访问特征,保证冷热数据划分的合理性,采取以下方法:统计最近访问数据的修改频率来动态调整热度阈值,并对每个逻辑地址的计数器值进行定期减半的衰退操作以反映工作负载的动态性.实验结果证明该方法能准确地识别出热数据,从而很好地实现了阵列系统的负载均衡.
考虑到计算开销对存储系统的请求响应时间的影响,因此本文在设计和实现固态硬盘阵列系统架构时采用最理想的DAMS作为冷热数据区分算法,DAMS只需很小的计算开销,但需要较大的内存开销来记录访问频次,4.3节会进一步讨论如何对内存开销进行优化.
4 基于热度感知的阵列系统架构设计研究
本节我们利用工作负载感知特性,在RAID -0阵列中设计了一种基于冷热数据分离存储和滑动窗口的固态硬盘阵列系统架构,以此来减少热点盘出现的概率,使阵列系统达到负载和磨损均衡.
4.1 架构设计
利用第3节介绍的冷热数据识别方案,我们设计了基于冷热数据分离存储和滑动窗口的HA-RAID阵列系统架构,如图3所示.
基于冷热数据分离存储和滑动窗口的HA-RAID阵列系统架构由4个模块组成:
1) 冷热数据识别模块.用于对到来的请求数据进行冷热识别,以用于在固态硬盘阵列系统中进行冷热数据的分离存储.该模块用第3节介绍的典型的冷热数据区分算法来实现.
2) 滑动窗口模块.该模块用来变换各个盘的角色,使每个盘都有机会成为热点盘,从而达到将热数据均匀放置在每个盘上的目的,实现阵列水平的磨损均衡.如图3所示,设定滑动窗口大小为4,初始窗口位置为1~4号盘.当处理一定数量的连续请求后(本文设置的滑动阈值是1 000),窗口以轮转的方式向右滑动1个位置,移出窗口的盘由普通盘变为热点盘,移入窗口的盘由热点盘变为普通盘.对于识别为热的数据,将其存储到热点盘,普通数据存储到普通盘.
3) 映射表模块.该模块用来记录请求的逻辑地址到阵列中物理地址的映射关系,由于固态硬盘读写的最小单位为页(4 KB),并且本文所用工作负载全部4 KB对齐,因此映射表中只需记录数据起始地址除以8后的值即可.本文用数据结构(LBA,SSDN,PSN)来实现该映射表,其中LBA表示请求数据块的起始逻辑地址(起始逻辑扇区号)除以8后的值,SSDN表示请求数据块在SSD阵列中被存储的盘号,PSN表示请求数据块被存储的起始物理地址(起始物理扇区号) 除以8后的值.
4) 编址模块.不同于原始架构以条带的形式对阵列进行地址空间的编排,我们设计的架构中根据冷热数据识别结果对请求数据的逻辑地址在阵列中乱序编址,数据在每块盘上顺序存放,当有数据需要存储到盘上时,以顺序的方式为其分配物理地址,并更新映射表模块对应的表项.如图3所示,下半部分的编址空间中,扇区0…7,存储于Disk3的2号物理位置,而右上角处的映射表模块的表项0,
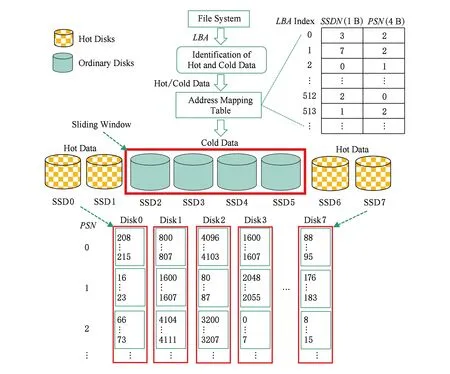
Fig. 3 HA-RAID architecture based on coldhot data separation and sliding window图3 基于冷热数据区分和滑动窗口的HA-RAID系统架构

Fig. 4 The I/O flow chat of HA-RAID图4 HA-RAID的I/O处理流程
即page 0(对应扇区0…7),记录SSDN为3号盘,且PSN=2.
4.2 处理流程
基于冷热数据分离存储和滑动窗口的HA-RAID阵列系统架构,对I/O请求的基本处理流程如图4所示.首先对阵列中的滑动窗口进行初始化(如滑动窗口大小、滑动窗口初始位置、滑动窗口滑动周期等),然后开始处理文件系统层下发的请求.
对于文件系统层下发的请求LBA,首先判断它是读请求还是写请求,如果为读请求,则根据维护的地址映射表得到其物理地址(盘号和扇区号),然后在底层盘上读取数据,完成此次I/O请求;如果为写请求,则利用冷热数据识别模块对其进行冷热识别:
1) 如果该请求LBA被识别为热数据,则将其以轮转的方式存储到热点盘中(数据在盘中根据请求先后顺序,顺序编址并存放),然后更新地址映射表中对应的物理地址,完成此次I/O请求.
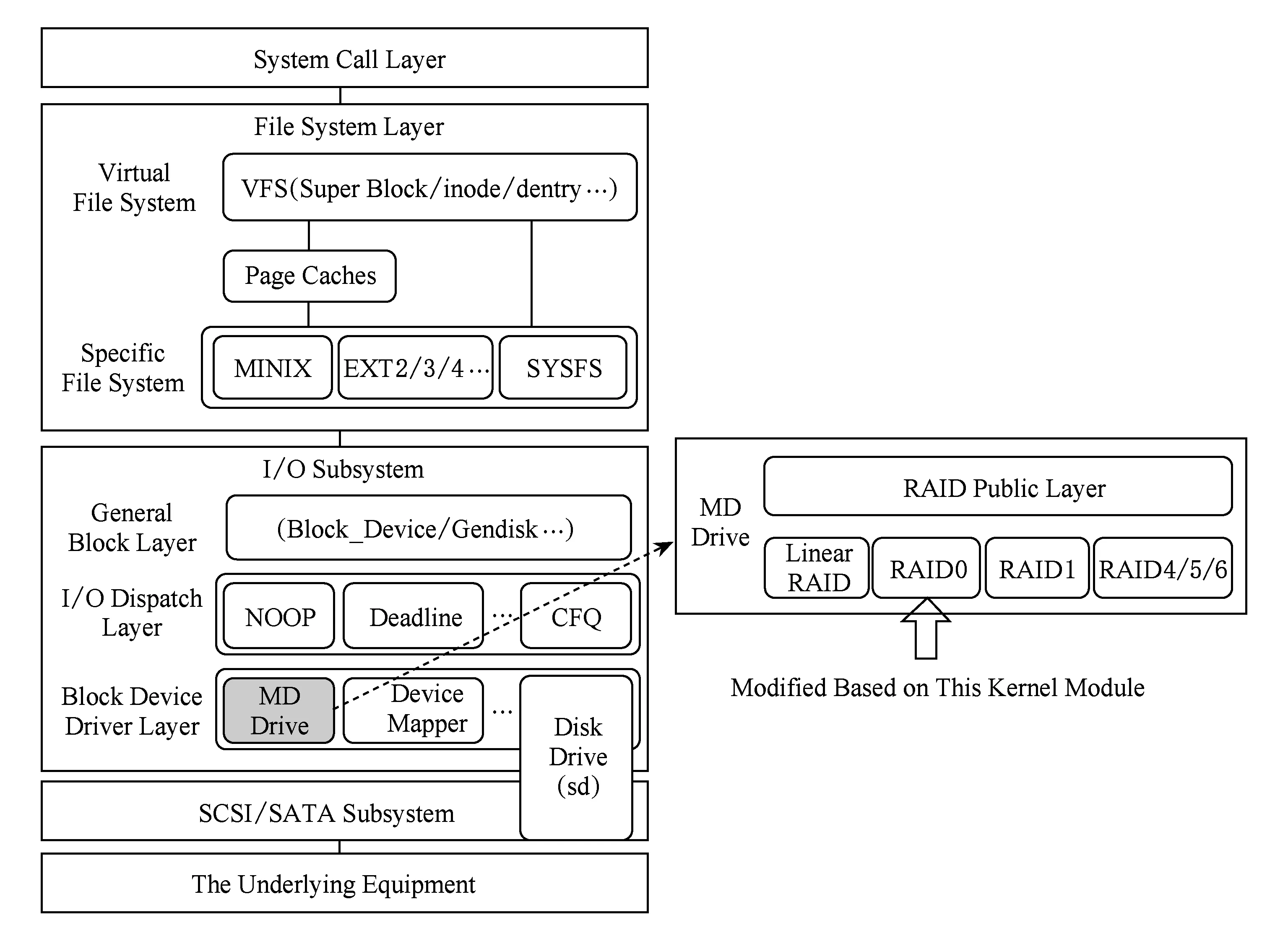
Fig. 5 The hierarchy diagram of Linux kernel block devices for read and write requests图5 Linux内核块设备读写请求的层次结构图
2) 如果该请求LBA被识别为冷数据,则将其以轮转的方式存储到普通盘中(数据在盘中根据请求先后顺序,顺序编址并存放),然后更新地址映射表中对应的物理地址,完成此次I/O请求.
最后判断连续请求的数量是否超过滑动窗口的滑动阈值,如果超过,则将滑动窗口向右滑动1个盘的距离,继续处理下一个I/O请求;否则,结束此次I/O请求并开始处理下一个I/O请求.
4.3 实现细节
本文在Linux内核MD模块下的RAID -0中用C语言实现SSD阵列系统架构,这里将详细介绍SSD阵列系统架构实现过程中的一些实现细节,如Linux内核MD模块的层次结构图,实现逻辑地址到物理地址转换的映射表的构造与管理,处理请求过程中的数据对齐.
1) MD模块层次结构.Linux内核响应块设备读写请求的层次结构,主要由系统调用层、文件系统层、块I/O子系统、SCSI(small computer system interface)/SATA(serial advanced technology attach-ment)子系统和底层存储设备组成.本文通过修改图5中块设备驱动层的MD驱动下的RAID -0源码来实现冷热数据区分算法和基于冷热数据分离存储的SSD阵列系统架构,以实现底层设备阵列中各盘的负载和磨损均衡.
2) 映射表的构造与管理.由于在本文设计的系统架构中,同一个写请求不是固定写到一块盘的固定物理地址上,而是每次都写到不同盘的不同物理地址上,以实现负载和磨损均衡.因此需要构造与管理一张映射表来实时记录请求数据块的逻辑地址到SSD盘号和该盘上物理地址的映射关系.用数据结构 (LBA,SSDN,PSN) 来实现该映射表,如图6所示,其中LBA表示请求数据块的起始逻辑地址(起始逻辑扇区号) 除以8后的值,SSDN表示请求数据块在SSD阵列中被存储的盘号,PSN表示请求数据块被存储的起始物理地址 (起始物理扇区号) 除以8后的值.使用双数组进行阵列系统中映射表的管理.

Fig. 6 The mapping table图6 映射表示意图
LBA用于双数组中的索引,无需存储;SSDN使用1 B存储,能够存储最多256块盘;PSN使用4 B存储,能够存储的扇区号最多为4 294 967 296,满足120 GB固态硬盘的容量要求.这样仅用5 B就足够记录1个数据块的映射关系,对于固态硬盘阵列1 TB的数据空间仅仅需要的映射表空间为1.25 GB.
3) 数据对齐.在系统架构实现中,设定系统的读写单位为一个特定大小4 KB的数据块chunk.为了实现读写请求的数据对齐,当一个到来的请求不能与设定的chunk对齐,若小于chunk大小,则将其补充到chunk大小;若大于chunk大小,则将其补充到chunk的整数倍.这样做是因为固态硬盘的读写基本单位为4 KB,并且实验中设置chunk大小为4 KB,为了让一次chunk大小的请求集中在1个块,而不是操作多个块 (比如未对齐时,1个chunk大小的请求可能会操作2个块,写入数据时需要读-擦-写,造成性能下降;对齐时,1个chunk大小的请求只会操作1个块,从而提升固态硬盘性能).
5 实验与结果
为了进行评估,本文将设计的系统架构部署到由多个商用固态硬盘组成的阵列系统上,并在系统中使用了4个真实的企业级工作负载.由于本文的方案是在原始RAID -0阵列系统上进行的改进,故将原始RAID -0用作本文的实验基准,并从2个方面对RAID -0和HA-RAID进行对比,即固态硬盘阵列系统的负载均衡以及请求的平均响应时间.
5.1 实验设置
1) 工作负载.实验中使用了企业数据中心的块级traces工作负载,分别为写占主导的hm_0,src2_0,usr_0和stg_0.其中,hm_0代表硬件监控服务器上的负载,src2_0代表源控制服务器上的负载,usr_0代表用户主目录服务器上的负载,stg_0代表Web分段服务器上的负载[19].
我们在实验中对工作负载进行了预先处理,即数据4 KB对齐.所有工作负载的工作集总大小在10 GB到20 GB之间;与此同时,所有的工作负载具有很强的访问倾斜性和很高的访问局部性.例如在后3个工作负载中,大部分写请求集中在2%~4%的地址空间,而第1个工作负载中,大部分的写请求集中在10%的地址空间.各工作负载的统计数据如表1所示.
2) 实验环境.本文将HA-RAID阵列系统架构在物理机器上加以实现.实验硬件配置为:戴尔PowerEdge T620服务器 (配有4个2.40 GHz Intel Xeon CPU和8 GB物理内存空间) ,1个Intel 530系列固态硬盘用作系统盘,8个Intel 530系列固态硬盘用于构建一个固态硬盘阵列,每个盘的容量120 GB,SATA3接口,MLC(multi-level commission)类型.阵列设置数据块chunk的大小为4 KB.使用FIO工具测试了固态硬盘的随机读写延时 (50%读,50%写,I/O大小4 KB,队列深度设置为1,单线程,并且绕过磁盘缓存),测试结果如表2所示.

Table 1 Statistical Data of Different Workloads表1 不同工作负载的统计数据
3) 冷热区分算法参数设置.由于本文重点研究阵列系统的磨损均衡和性能提升,并不对冷热数据区分算法做深入研究,留在以后再探究.因此在实验中使用计算时间开销最少的DAMS作为本文设计的阵列系统架构中的冷热数据区分算法.不同工作负载下DAMS算法的参数设置如表3所示.
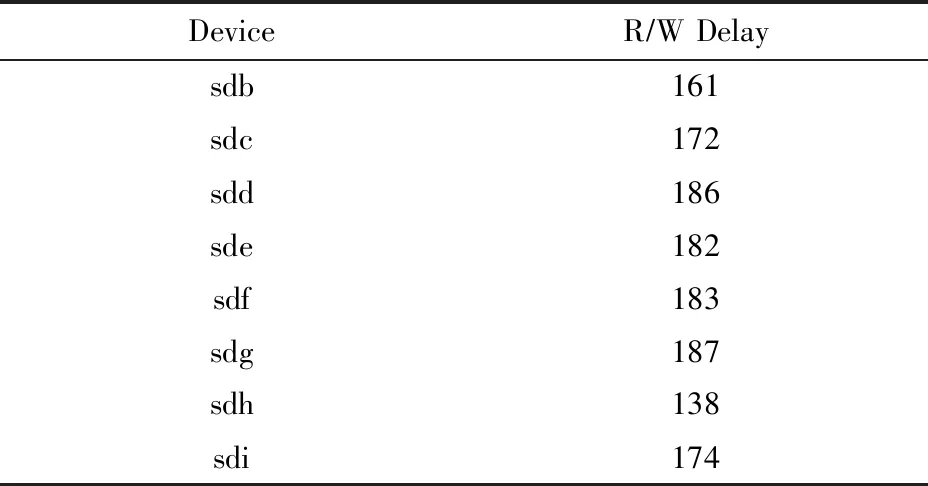
Table 2 Performance Indicators of Intel 530 Series SSD

Fig. 8 Read/write ratio of each disk in RAID -0 and HA-RAID under hm_0图8 负载hm_0下RAID -0与HA-RAID阵列中各盘上的读写比例

Table 3 Parameter Setting of DAMS Algorithm Under
Note:Under various workloads, the parameters of DAMS algorithm are experimentally tested and the best value is taken.
5.2 系统请求平均响应时间评估
实验中,通过记录每个请求的响应时间和系统处理请求的总个数,计算得到每个请求的平均响应时间,实验结果展示在图7中.
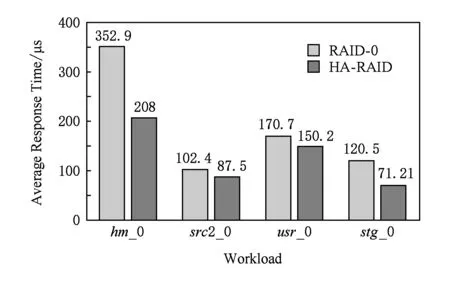
Fig. 7 The average response time of I/O requests图7 不同工作负载下系统请求的平均响应时间
通过图7可知,采用阵列系统架构HA-RAID,相比于原始架构RAID -0,部署在实际系统上时,极大地减少了请求的平均响应时间.实验结果验证了区分数据冷热的有效性,因为原始架构会因为冷热数据的混合存储而导致热点盘的出现,从而不能发挥RAID阵列高并发的优势,进而会一定程度上延迟用户的访问请求,造成整个阵列系统的I/O性能出现瓶颈.对比原始架构RAID -0,本文设计的阵列系统架构HA-RAID部署在系统上时,对请求的平均响应时间减少了12.01%~41.06%,有效提高固态硬盘阵列系统的I/O性能.
5.3 系统负载均衡评估
固态硬盘容错阵列系统的负载和磨损不均衡,都容易降低系统的可靠性,造成数据的遗失.因此,本文实验统计了各种工作负载下阵列系统中各个盘的负载和磨损情况,统计结果如图8~11所示.
由图8所示可知,工作负载为hm_0时,对于原始架构RAID -0,各盘上的读写比例在每个时间点都有较大差异,且波动幅度较大;对于热度感知架构HA-RAID,各盘上的读写比例在每个时间点都差异不大,主要集中在0.1~0.15,且波动幅度很小,很好地实现了阵列系统级的负载均衡.
由图9所示可知,工作负载为src2_0时,对于原始架构RAID -0,各盘上的读写比例在每个时间点都有较大差异,且波动幅度较大;对于热度感知架构HA-RAID,各盘上的读写比例在每个时间点都差异不大,主要集中在0.1~0.15,且波动幅度很小,很好地实现了阵列系统级的负载均衡.


Fig. 9 Read/write ratio of each disk in RAID -0 and HA-RAID under src2_0图9 负载src2_0下RAID -0与HA-RAID阵列中各盘上的读写比例


Fig. 10 Read/write ratio of each disk in RAID -0 and HA-RAID under usr_0图10 负载usr_0下RAID -0与HA-RAID阵列中各盘上的读写比例

Fig. 11 Read/write ratio of each disk in RAID -0 and HA-RAID under stg_0图11 负载stg_0下RAID -0与HA-RAID阵列中各盘上的读写比例
由图10所示可知,工作负载为usr_0时,对于原始架构RAID -0,各盘上的读写比例在每个时间点都有较大差异,且波动幅度较大;对于热度感知架构HA-RAID,各盘上的读写比例在每个时间点都差异不大,主要集中在0.1~0.15,且波动幅度很小,很好地实现了阵列系统级的负载均衡.
由图11所示可知,工作负载为stg_0时,对于原始架构RAID -0,各盘上的读写比例在每个时间点都有较大差异,且波动幅度较大;对于热度感知架构HA-RAID,各盘上的读写比例在每个时间点都差异不大,主要集中在0.1~0.15,且波动幅度很小,很好地实现了阵列系统级的负载均衡.
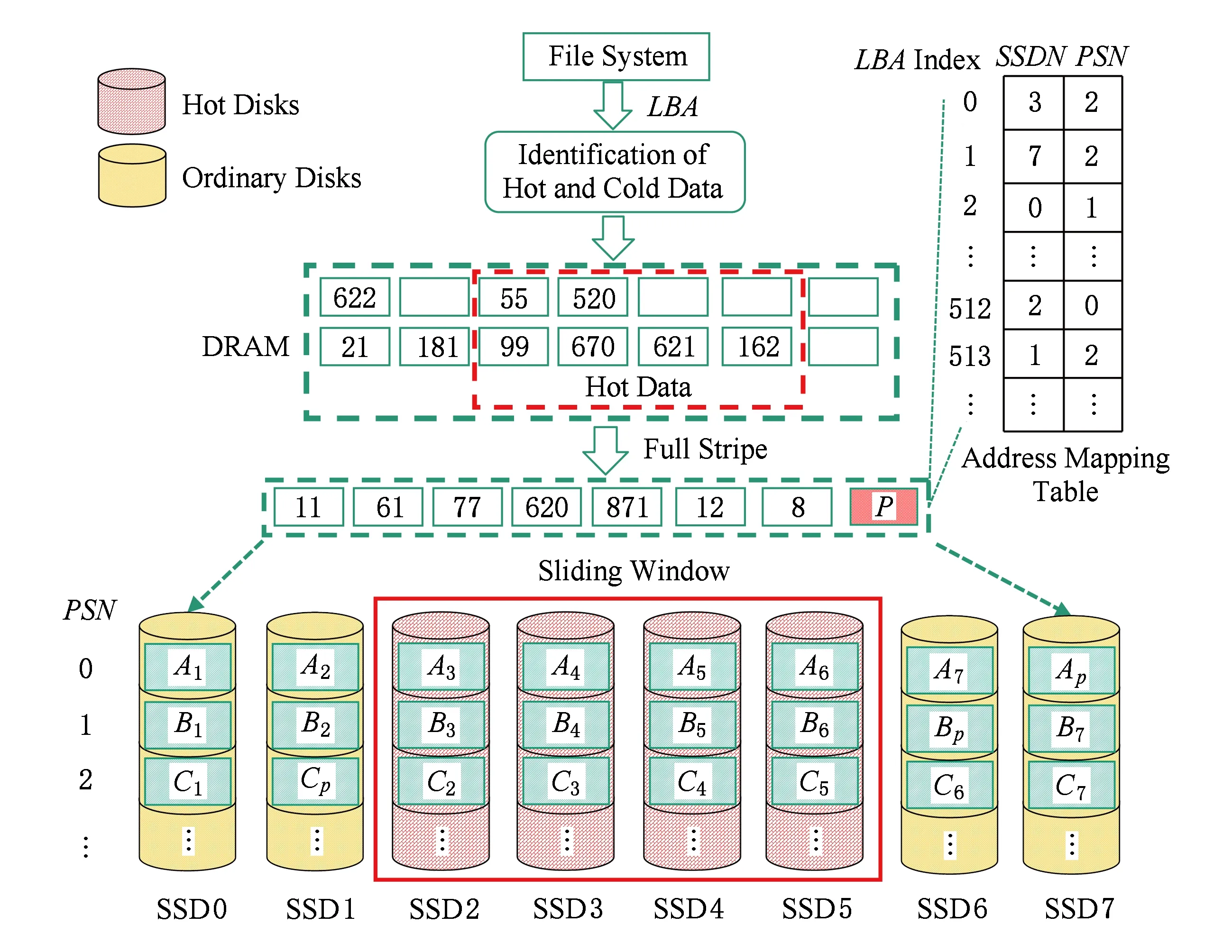
Fig. 12 HA-RAID architecture extended to RAID -5 array图12 扩展至RAID -5阵列上的HA-RAID系统架构
6 HA-RAID扩展至RAID -56
基于RAID -0设计的系统架构HA-RAID 很好地实现了阵列系统级的负载均衡和磨损均衡,从而延长整个阵列的使用寿命并提升I/O性能.但RAID -0阵列没有引入任何冗余数据,无法保证数据的可靠性.而数据可靠性保证在实际应用中又非常重要,企业的核心数据一旦丢失,损失将是无法估量的.因此,我们将基于RAID -0设计的HA-RAID系统架构扩展至RAID -5阵列,主要设计思路如图12所示.
对基于RAID -0的HA-RAID系统架构,将其扩展至RAID -5阵列,需要做3个方面的修改:
1) RAID -5阵列需要对写入内存中的数据以条带形式组织,并使用与阵列盘上对应的滑动窗口将条带划分为热区域和冷区域,条带中的热区域存放识别出的热数据,冷区域存放普通数据.
2) 对于LBA读请求,根据地址映射表得到其物理地址(盘号和条带号),然后在底层盘上读数据.
3) 对于LBA写请求,在内存以条带的组织形式对其进行缓存:①如果该LBA被识别为热数据,则将其存储到条带的热区域(滑动窗口内); ②如果该LBA被识别为冷数据,则将其存储到条带的冷区域(滑动窗口外).当一个条带上数据存满,则计算产生该条带的校验信息P,然后将条带数据和校验数据以条带形式追加写入阵列(校验数据以轮转的方式存储到普通盘上),并更新地址映射表中对应的物理地址.
RAID -6阵列上的实现方法与RAID -5阵列类似,只是增加了计算开销和额外校验数据的存储,数据可靠性更高,这里不再赘述.
7 总 结
本文在RAID -0阵列中设计了一种基于冷热数据分离存储的固态硬盘阵列系统架构HA-RAID,并结合滑动窗口技术进行优化.相比原始RAID -0阵列架构,HA-RAID可以将热数据相对均匀地存储到各个盘上并减少12.01%~41.06%的平均响应时间,很好地实现了阵列系统级的负载和磨损均衡及阵列系统的I/O性能提升.
