地球科学大规模并行应用的重叠存储优化
2019-04-18陈璟锟杜云飞
陈璟锟 杜云飞
(国家超级计算广州中心(中山大学) 广州 510006)
对提升大规模并行计算规模与效率的研究和优化通常集中在算法的设计和优化上,比如在地球科学类程序中,通过特别的网格划分以更好地实现负载均衡和压缩通信的研究仍然长盛不衰[1].然而各种算法的加速比测试往往略去了I/O的占用时间,比如设置了超过计算时间的输出间隔、关闭结尾输出等.但在实际应用中,研究者通常需要获得一个可以描述连续变化的过程而非一个最终状态结果.这就要求模式在迭代计算过程中定期输出中间状态、输入边界数据进行同化以提高结果准确性和输出数个检查点以应对长时间运行可能碰到的硬件故障.所以,地球科学类软件很早就被意识到是一种I/O敏感型的应用[2].
地球科学研究者往往缺乏足够的时间和意愿去系统地学习与研究大规模并行程序的编写,他们更愿意把主要精力放在对科学问题的研究上.因此地球科学模拟软件最常见的输出方式是简单地将信息收集到根进程,由根进程整理并完成串行输出.然而这种输出方式会极大地限制程序在大规模计算时的性能表现.因为I/O时间不会随着进程数的增加而下降,所以I/O时间占总时间的比例会越来越高,最终严重地削弱了峰值性能.在一些算例中,甚至会出现I/O时间远超计算时间的情况.这除了让科研工作者浪费时间和金钱外,更大的负面影响是在精细化数值预报领域,不但降低了数值预报的时效性,还增加了对硬件资源的需求并且提高了维护工作的难度.
在过去的数10年中,计算机科学家为了克服地球物理科学模拟的存储墙问题进行多种研究,最终形成的主流共识是:1)由并行I/O取代串行I/O;2)将I/O和计算重叠[2];3)优化必须是通用且轻量级的.因为计算进程的数据保存顺序和文件存储顺序不同,所以需要建立一个缓存机制将每个进程的数据进行重新排列后再做并行输出,由此诞生了收集式I/O的思路[3].收集式I/O的具体实现还能细分为采用本地硬盘作为缓存[4]和设立I/O结点作为缓存2种[5].这些思路还继续发展并影响到新一代超级计算机的并行文件系统设计[6].为了让收集式I/O发挥出这种并行文件系统的性能,计算科学家又在并行读写(MPI-IO)的基础上根据I/O结点的具体硬件架构进一步开发了更高级的并行I/O库[7-10],比如轻便的收集式并行I/O库ROMIO[7].因为收集式I/O的全过程可再分为通信收集和并行读写2部分,所以后续又有许多工作分别针对收集过程[11-12]和如何隐藏读写过程[13-15].
上述研究基本围绕着底层硬件和基础库,这给程序的移植带来了方便.但在实际的应用当中,地球科学软件往往会采用以常用科学数据格式存储数据,比如NetCDF(network common data form),HDF5(hierarchical data format 5)等.这些文件格式库的数据收集性能在大规模计算下是无法保证的,而且缺乏异步输出的能力.这使得存储墙对现今的地球科学大规模计算的负面影响依然非常严重,极端条件下甚至会出现超过80%的墙钟时间是在输出的情况.虽然有相当多工作在努力地提升并行I/O的读写性能[16],但单从底层对I/O进行优化依然不足以克服存储墙问题,我们还需要对应用软件的访存行为做出优化.
本文就是从应用层出发,参考主-从架构[17],通过设立I/O进程[18]、分离I/O过程和计算过程以实现对地球科学软件的访存优化.本文将按照3方面组织:1)如何从应用层面设计一个重叠存储以适应在天河二号上进行大规模计算;2)将详细阐述这种优化是如何提升WRF(weather research & forecasting mode)的I/O性能,并证明其有效性;3)将这种优化移植到ROMS_AGRIF(regional ocean modeling system_adaptative grid refinement in Fortran)和GRAPES(global/regional assimilation and PrEdiction system),以证明它的普遍性.
1 重叠存储优化地球科学软件输出
因为地球科学的性质,其模拟过程往往是首先读入初始条件,然后进入迭代循环,每当抵达设定好的输出时间时将进行一次中间状态输出,直到循环到达终止时间.这意味着输出的开销会远大于输入,因此,我们先将精力集中在输出优化上.
现在我们面临的情况是输出所花费的时间是一步迭代的数倍甚至数10倍,但一般也不会超过一个输出周期.因此,我们的想法是将输出过程和迭代计算分离,并确保一个输出间隔内完成输出,就是让输出隐藏在计算中,实现输出优化的目标.这样我们就不需要去追求并行输出的极限速度,优化难度会减轻许多.
为了达成这个目标,我们进一步细分整个思路:
1) 建立专用的I/O进程,以实现输出和计算同时进行.
2) I/O进程通过收集通信gather收集数据.
3) 因为gather是堵塞型通信,所以会暴露通信.
4) 根据最小生成树算法(minimum-spanning tree algorithm, MST),需要建立多个I/O进程以减少gather通信的消耗.
5) 多个I/O进程之间使用并行I/O完成输出.
6) 由思路4,5可知,多个I/O进程和计算进程如何分组要符合连续读写的原则.
7) I/O进程应该分布在不同物理结点.
8) 通过划分新通信域从而实现不同功能进程的混合分组.
思路1是实现输出和计算重叠的基础,虽然MPI-IO提供有非堵塞读写(MPI_FILE_iread(iwrite)_at)等接口,但NetCDF和HDF5并没有使用.我们采用的gather通信方式会暴露通信时间,但带来的好处是减轻结点内存的压力以及减少程序编写的复杂性.又因为gather通信是MST算法,耗时正比于进程数的数量,所以需要设置多个I/O进程,每个I/O进程只负责收集部分计算进程的数据,以将通信开销抑制到可以接受的程度.思路5是我们要让每次输出耗时一定要小于一个输出间隔.虽然从理论上无法完备地证明任何情况下并行输出就能满足输出耗时小于输出间隔,但在实际的地球物理模拟中并不需要每一步迭代完毕后都要输出.在绝大部分情况下输出间隔的墙钟时间的量级都在10~100 s,而相应的输出量在1~20 GB.所以我们在此选择并行输出,既可以满足现实应用中的绝大部分情况而且还留有相当富余的性能空间以应对未来的性能需求.为了发挥并行输出的性能,就产生了思路6的要求.思路7是为了突破单结点的物理内存限制和通信带宽限制.思路8是为了方便管理不同种类的进程和减少对核心算法的修改,只需要将计算进程归入一个全新的通信域,并用其代替核心算法中原来的全局通信域(MPI_COMM_WORLD)就可完成修改.
从上述的修改流程中可以看到这种优化方法有4种好处:1)相当于在原来的程序上外接了一个功能包,不涉及修改核心算法的逻辑;2)对核心算法的修改只有通信域的名字,这使得我们可以在不明白模型和算法细节的情况下也能完成重叠存储优化,这也是优化方法具有通用性的一个表现;3)在通信域划分时已经考虑了后续并行输出的速度问题,减少磁盘读写竞争问题;4)更加充分地利用了超级计算机的硬件,突破单结点带来的网络带宽和内存瓶颈.
2 WRF的IO优化
WRF是目前国内与国际上最流行的中尺度天气预报研究软件之一,是典型的地球科学类软件.WRF从3.0版本就开始考虑大规模计算下的输出问题,它同样通过提供设置额外I/O进程的方式实现优化.假设我们将I/O进程设为2,并为作业提供总计12个进程,而运行作业的超级计算机每个结点具有6个CPU核.那设置I/O进程前后的WRF进程分配如图1(a)和图1(b),反映到具体的物理CPU核划分如图1(c).
图1(a)(b)(d)中,每一列代表一个进程,圆形(黑色)箭头代表迭代计算过程,菱形 (绿色)箭头代表通信,长方形(红色)代表输出过程,虚线代表计算进程空闲;图1(c)(e)中,深色(蓝色)方块代表一个计算进程,浅色(黄色)阴影方块代表一个I/O进程,褐色线条围成的区域代表通信域的划分.图1(a)没有I/O进程,由根进程负责输出2个结果文件;图1(b)设置了2个I/O进程,但只有第2个文件的输出与计算实现重叠;图1(c)不同类型进程在12个CPU核上的分布和数据收集通信域的划分;图1(d)优化后的输出流程;图1(e)优化后不同类型进程在12个CPU核上的分布和新的数据收集通信域划分.
图1(a)展示了在没有I/O进程时,根进程负责完成数据的收集并输出结果,在整个收集-输出的过程,其余进程除了发送数据的操作外都处于闲置状态.图1(b)表示设置了2个I/O进程后,每当进入预设的输出时间点,计算进程都会将数据发送给I/O进程,随后由I/O进程完成数据整理和并行输出.每个I/O进程都只会接收到处于同一个通信域的计算进程的数据,数据收集通信域的划分如图1(c).对比图1(a)和图1(b)我们就能发现原设计的第1个问题.虽然在设置了通信进程后,最后1个文件的输出时间和计算时间发生了重叠,对输出时间占比有所改善,但除最后1个文件外,其他文件的输出时间仍然暴露在外.WRF的文件输出顺序是第1层网格—第2层网格—第3层网格.通常研究者会将第3层网格设置得最为密集,其结果文件也是最大,输出耗时最长.这使得原版的设计在部分情况下已经取得了比较明显的效果.但该设计却不适合2种情况:情况1是不同层网格的格点数相差不大,只是格点间代表的距离不同;情况2是研究者设置了辅助变量输出,输出顺序变成先输出1层网格的数据,再收集该层的辅助变量数据并另开1个新文件保存.情况2会使得只有最后1层的辅助变量文件成功被隐藏,而一般辅助数据文件都远小于主要数据,是否隐藏意义不大.原设计的另1个问题是所有的I/O进程都安排在最后,如图1(c)所示,这往往意味着I/O进程会放在同一个结点.虽然放在同一个结点对于收集式I/O是一种理想情况,但却也有通信和内存这2个瓶颈.
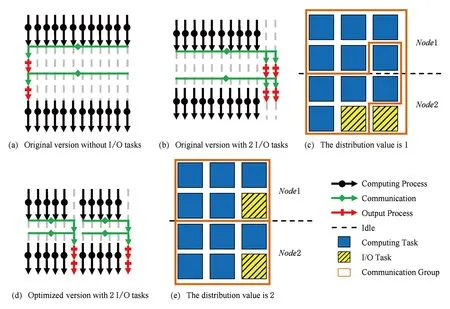
Fig. 1 Cartoon of WRF’s workflow图1 WRF的工作示意图
针对这2个问题,我们首先选择调整I/O进程的工作顺序.每进入1次新的收集-输出时间点,I/O进程先全部接收本次输出的所有数据,然后才开始逐一整理并输出到硬盘.如此调整后,除最后1次输出外,其余时间点的输出将全部实现隐藏,只剩余收集通信暴露在外,如图1(d)所示.
为了抑制收集通信gather的耗时,根据MST算法的特点,我们一是可以增加更多的I/O进程以减少每个I/O进程负责的计算进程数,二是可以将I/O进程分布在各个不同的结点以变相提高通信带宽.为此,我们引入1个可由使用者设定的分布值,可主动控制I/O进程的分布程度.如果设置为1,则如同原设计一般让所有I/O进程排列在最后;如果设置为2,则意味着12个进程被分为2组,每组最后的2/2=1个进程为I/O进程,效果如图1(e),成功利用了2个结点的通信带宽.
自古嫦娥爱少年,这个骚货没准看上你啦,想让你做鸭子哩,她一天到晚就是一个人晃荡,没见过她老公,这熊事,她还不知道是个啥人哩。这样的女人,看她那嘴,像刚喝过鸡血似的鬼,咱可不能招惹,她男人万一是个道上的,要杀你剐你,让你缺胳膊少腿,可甭怨我这个叔没给你打预防针。
3 WRF算例测试结果
我们使用超级计算机天河二号作为性能测试平台,它具有17 920个计算结点,每个结点的配置为2路24 CPU核,单核频率2.2 GHz,4路64 GB内存,自主研发的高速互联具有点点带宽140 Gbps,采用层次式Lustre文件系统,在存储服务器(OSS)和计算结点间还有1层配备了固态硬盘(SSD)的I/O结点用于加速存储性能.
我们选用的WRF测试算例为模拟全中国2015-07-27T12:00:00—2015-07-30T12:00:00共72小时的天气变化,每90 s为1个模拟步.3层嵌套网格:220×180×45,481×391×45,1 216×895×45,每层网格的相邻格点间距分别为45 000 m,15 000 m,5 000 m.每层网格的输出间隔均为1 h,采用PNetCDF库并行输出NetCDF格式文件,没有辅助变量输出,条带数设置为4.我们使用的WRF版本为3.6.1,但其关于输出的代码与3.7.1相同,与3.8.1和3.9相似.我们的编译器为Intel-14,WRF模式选择em_real,只允许根进程输出日志信息.

Fig. 2 Performance of WRF after output optimization图2 输出优化后的WRF性能图
我们选择3种设定以对比优化效果,分别是:原版无I/O进程、原版带2个I/O进程、优化版带2个I/O进程并且分布值为2.第1种设定的输出方式为NetCDF,而后两者均为PNetCDF.我们的测试结果如图2所示.每一组柱状图从左起按顺序分别代表第1,2,3种设定方案.横坐标代表计算进程数,所以每一组柱状图的第2和第3条使用的总进程数实为计算进程数加2.从图2可以看到随着进程数的增加,输出占总时间的比会越来越高,即使在超过了性能峰值后仍具有这种情况.原版程序在设置了I/O进程后,在3072进程时的性能提升了约19.8%,但还是能明显看到输出时间.在对输出做了优化后,峰值性能再次获得约11.4%的提升,相比无I/O进程时则是提升了约33.5%.这证明了我们的输出优化是有效且可行,达到了预想的效果.
我们还能从图2看到,随着进程数的增加,暴露的收集通信时间也在增长,尤其是从进程3 072提升到6 144时最为明显.我们进一步测试在不同I/O进程数和不同分布值下收集通信时间的变化情况,并将结果整理成表1.
Table 1 Effect of Output Tasks and Splits表1 IO进程数和分布值的影响
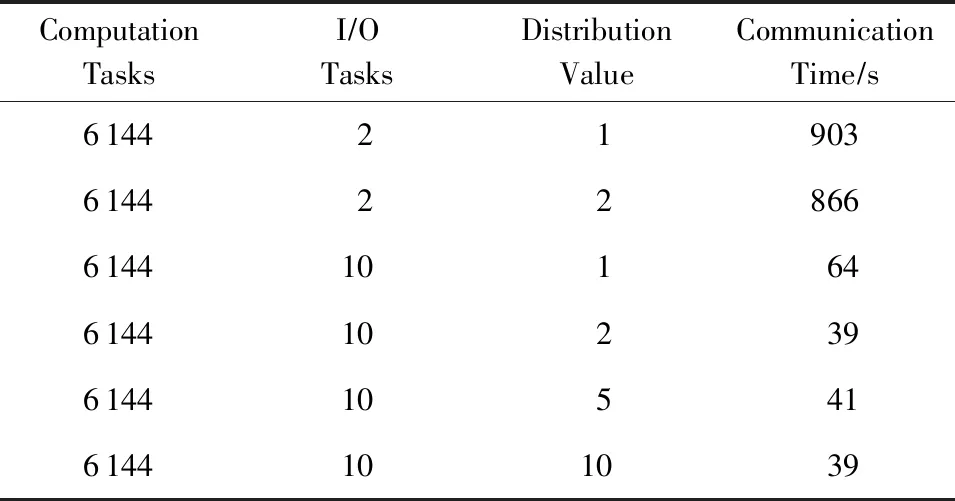
Table 1 Effect of Output Tasks and Splits表1 IO进程数和分布值的影响
ComputationTasksI∕OTasksDistributionValueCommunicationTime∕s6144219036144228666144101646144102396144105416144101039
从表1我们可以看到,在相同分布值下10个I/O进程的通信开销远低于2个,主要原因就是gather通信开销和进程数直接相关.增加I/O进程数意味着每个I/O进程负担的计算进程数变少,自然gather通信开销也会相应地减小.在同I/O进程数不同分布值下,通信开销也会有一定的下降,这表明我们的修改确实更有效地利用了带宽.但因为本例子的通信量并不大,所以还是进程数数量导致的开销占据主导.
我们为完成图1和表1的测试,选择了在计算进程保持一致的基础上设置额外I/O进程.这样可以保证计算的稳定性,但也带来总进程数不一致的问题.由此,我们还可以引出另外1个问题:总进程数一致的情况下,如何分配I/O进程和计算进程是最优解?
在讨论这个问题前,我们有必要先解释为什么会选择固定计算进程数的做法.这是因为WRF的负载均衡策略是将计算进程数分解为2个尽可能相近的因数,并利用它们完成xy平面的划分.但如果这2个因数相差较大时,这个简单的负载均衡策略就会极容易引起程序崩溃.假设现在从6 144个进程数中划分出10个I/O进程,那6 134只能被分解为2×3 067,进而导致作业崩溃.所以当总进程数一定时,I/O进程数的设置还必须考虑负载均衡策略,不能只考虑通信开销和计算时间之间的竞争.在此基础上,我们做出表2.
从表2可得,计算与I/O进程的数量比在1 000∶1至500∶1间能取得最优效果.我们认为这是天河二号硬件性能参数下的特解,不同系统应该会有不同的结果.
Table 2 Performance of Different IO Processes NumbersUnder Constant Total Processes Number
表2 总进程数不变下不同IO进程数的表现

Table 2 Performance of Different IO Processes NumbersUnder Constant Total Processes Number
ComputationTasksI∕OTasksComputationTime∕sCommunicationTime∕s6141312067.2346.466138612038.490.5761321212161.140.376120241224027.28
4 对同类软件的优化
4.1 ROMS_AGRIF
ROMS是国际上知名的海洋模拟软件,它具有多个分支.其中的1个分支ROMS_AGRIF由法国研究小组开发,加入了多个生物化学模块,侧重于模拟研究海洋与生物之间的关系.因为开发者认为应该尽可能地避开通信引起的消耗,所以其输出过程被设计为每个进程按顺序逐一将其保有的数据串行输出到同一个NetCDF文件.
这种设计虽然避开了输出导致的通信消耗,但在大规模计算下多个进程逐一打开关闭同一个文件,逐一输出不连续数据所耗费的时间也同样可观,在现代超级计算机硬件性能下不再是1个合理的交换.按第1节所述的方式,我们优化了ROMS_AGRIF的输出设计.收集过程分为3步:1)通过gather将各计算进程需要传输的数据量大小传送给I/O进程;2)I/O进程通过接收到的信息计算出接收内存的大小;3)用gather完成该变量的数据收集.等所有变量的数据都收集完毕后,I/O进程按顺序整理并采用并行库PNetCDF完成并行输出.
我们选择的算例为南中国海单层网格,网格大小为1 200×1 310×60,模拟129 600步,每720步输出3个文件,每个文件的每次输出量约在1.5 GB,条带数设置为4.
测试结果如图3所示,我们在前48,96,192个计算进程时仅比较了原版和存在2个I/O进程时的情况,从384计算进程开始加入对比24个I/O进程的情况.在48和96计算进程时, 2个额外I/O进程不仅抑制了输出时间,连带计算速度也出现了加快的情况.这是因为ROMS对内存很敏感,在加入2个I/O进程后,我们必须提交3个结点才能满足所需的CPU核数.依照天河二号的作业管理系统设定,这种提交方式会导致50个进程被3个结点平分.这意味着减少了内存带宽的竞争,因此出现计算速度加快的现象.这种对内存敏感的情况也体现在384进程前获得了超线性加速比.

Fig. 3 Performance of ROMS_AGRIF after output optimization图3 输出优化后的ROMS_AGRIF性能图
图3还展示了与计算规模相匹配的I/O进程有利于控制收集通信的开销.在3 072进程时,24个I/O进程可以有效保证输出所占时间不到总时间的5%,充分释放出原作者对通信优化后的计算性能.
4.2 GRAPES
GRAPES是我国自主开发的天气预报程序,在天河二号上已经实现1 km模式的业务化运行,是目前国内网络精度的最高水平.1 km模式需要每12 min启动1次.经过存储优化后的1 km模式,墙钟时间从26 min缩短至9 min,减少了对硬件资源的需求,减轻了运维压力,也提升了1 km预报业务的稳定性.
鉴于GRAPES的版本众多,我们以广州热带所提供的GRAPES业务版本为例开展GRAPES的I/O优化.原版GRAPES的I/O过程为:所有进程通过发送命令MPI_send将数据发送到根进程,而根进程先使用多个接收命令MPI_recv完成通信后开始进行数据整理并串行输出Fortran非格式化文件.
在实际测试中发现,GRAPES的输出所占时间比会随着进程数量的增加而急速上升.这是因为频繁的启动发送和接收命令消耗了大量的时间.我们对GRAPES的收集通信优化手段与ROMS_AGRIF类似,避免了因为频繁启动通信命令而引起的巨额开销.
GRAPES的输出文件采用Fortran非格式化文件格式,与MPI-IO的格式并不完全一致.为了方便后处理程序,我们编写的并行输出过程也仿照了该格式,虽然会对读写速度带来负面影响,但输出耗时依然远小于1个输出周期,不会对总时间带来显著影响.
从负载均衡的考虑出发,几乎所有地球科学模拟软件的负载均衡策略都是按照进程数将xy平面划分为大小相近的区域,而z方向不做划分,GRAPES也是如此.因为算法上的要求,GRAPES的变量数组存储按照的是xzy顺序,这意味着当存在多个I/O进程时,I/O进程只能在x或y方向中选取1个保证该方向的数据连续性.因为GRAPES结果文件内的数据是按照xyz顺序排列,所以在多个I/O进程并行输出同一个变量的同一个xy平面时必然会引起磁盘资源的争抢,最终拖慢输出表现.考虑到在日常的业务化使用当中,GRAPES的每次输出量均不超过1 GB的情况,我们暂时将所有的I/O进程放在同一个结点内,这样做可以直接利用天河二号的层次式存储加速输出速度,避开磁盘资源发生争抢的情况.我们会在将来采取更成熟的收集式I/O,比如ROMIO,以尝试解决这个问题.
对GRAPES的测试结果如图4所示,可见在设置了24个I/O进程时,在3072进程时依然取得了相当好的加速效果.在实际的业务预报应用中规模已经达到了5300核,而其I/O时间依然可以忽略不计.
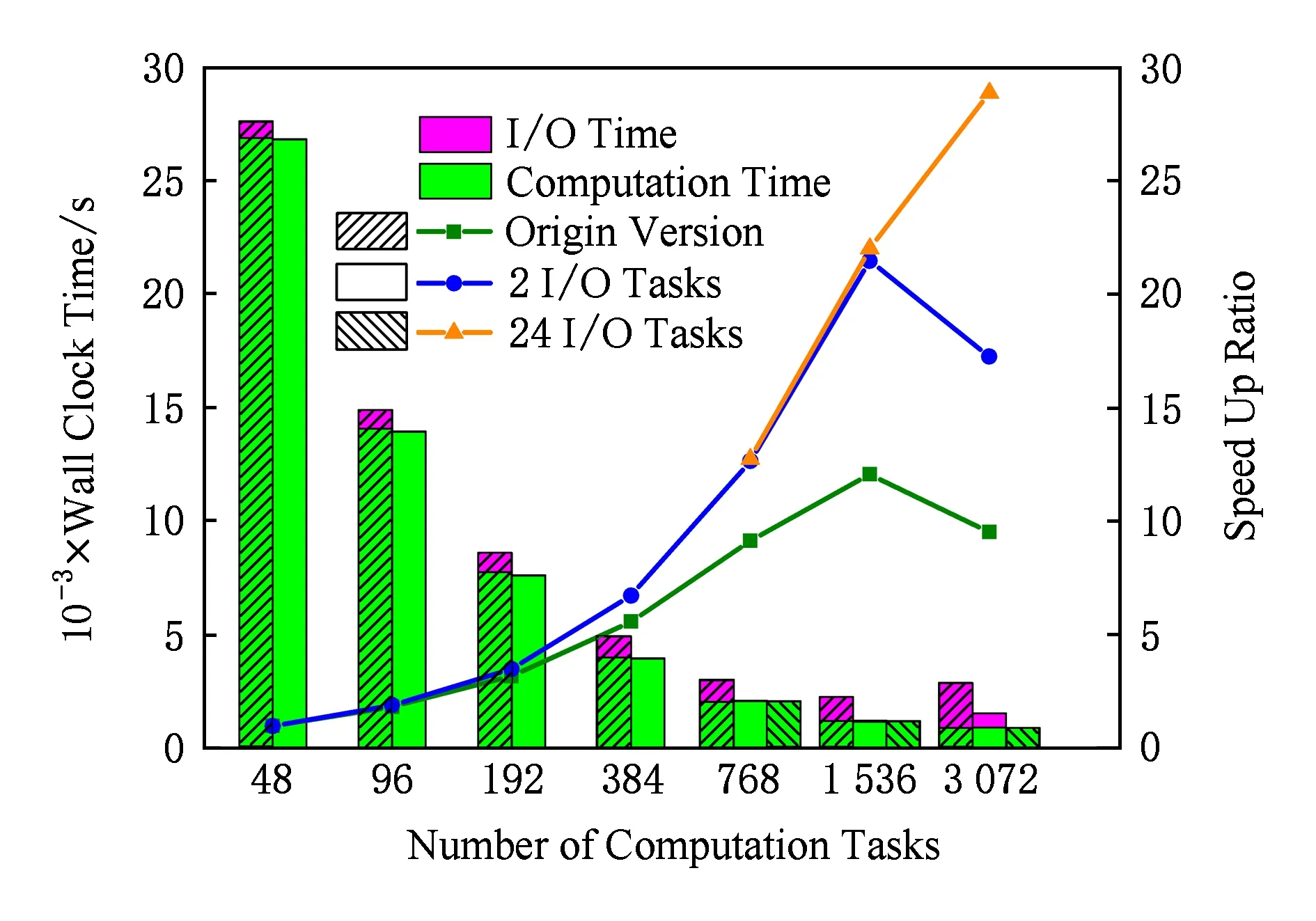
Fig. 4 Performance of GRAPES after output optimization图4 输出优化后的GRAPES性能图
5 总 结
因为硬件上的原因,存储的速度远落后于计算的速度,这使得存储问题一直是大规模算法能否实用化的主要挑战之一.地球科学领域内常用的软件几乎都会碰到这个问题,并且随着规模的扩大,这个问题会越发严重.存储的解决方式和硬件架构有关,因此我们针对天河二号的架构,设计了一套应用级别的重叠存储优化,希望解决大规模计算时的存储问题.
这套重叠存储优化的核心思路是:
1) 建立专用I/O进程;
2) 设置多个I/O进程以抑制通信开销,变相增加内存容量和通信带宽;
3) I/O进程收集完所有文件的数据后再输出;
4) I/O进程之间采用并行输出.
虽然部分应用软件,比如WRF已经有了这方面的探索,但要么不完善,要么不适应天河二号的存储架构,所以都无法发挥出天河二号的存储性能.
本文对WRF,ROMS_AGRIF,GRAPES做出适合天河二号架构的存储优化,均获得了预期中的良好效果.测试表明:经过优化后的WRF峰值性能相比原版有了近11.4%的提升,ROMS_AGRIF的峰值性能提升936%,GRAPES的峰值性能提升140%.因为都不涉及物理模型,优化后的计算结果在有效精度内与原版程序保持一致,这验证了重叠存储优化的正确性和有效性,也证明了该优化思路能普遍应用于天河二号上的地球科学类软件.我们对存储的优化也进一步提升了天河二号在华南地区高精度天气预报业务和南中国海预报业务中的作用.
致谢我们在此感谢国家超级计算广州中心卢宇彤主任的支持,感谢国家超级计算广州中心高性能部门的同事对研究内容的有益讨论和指导,感谢国家超级计算广州中心系统部同事对测试所需的硬件和计算资源提供的技术支持.
