文本图像条带污染去除的0稀疏模型与算法
2022-07-12耿则勋
喻 恒 耿则勋,2
1(平顶山学院信息工程学院 河南 平顶山 467000) 2(信息工程大学地理空间信息学院 河南 郑州 450052)
0 引 言
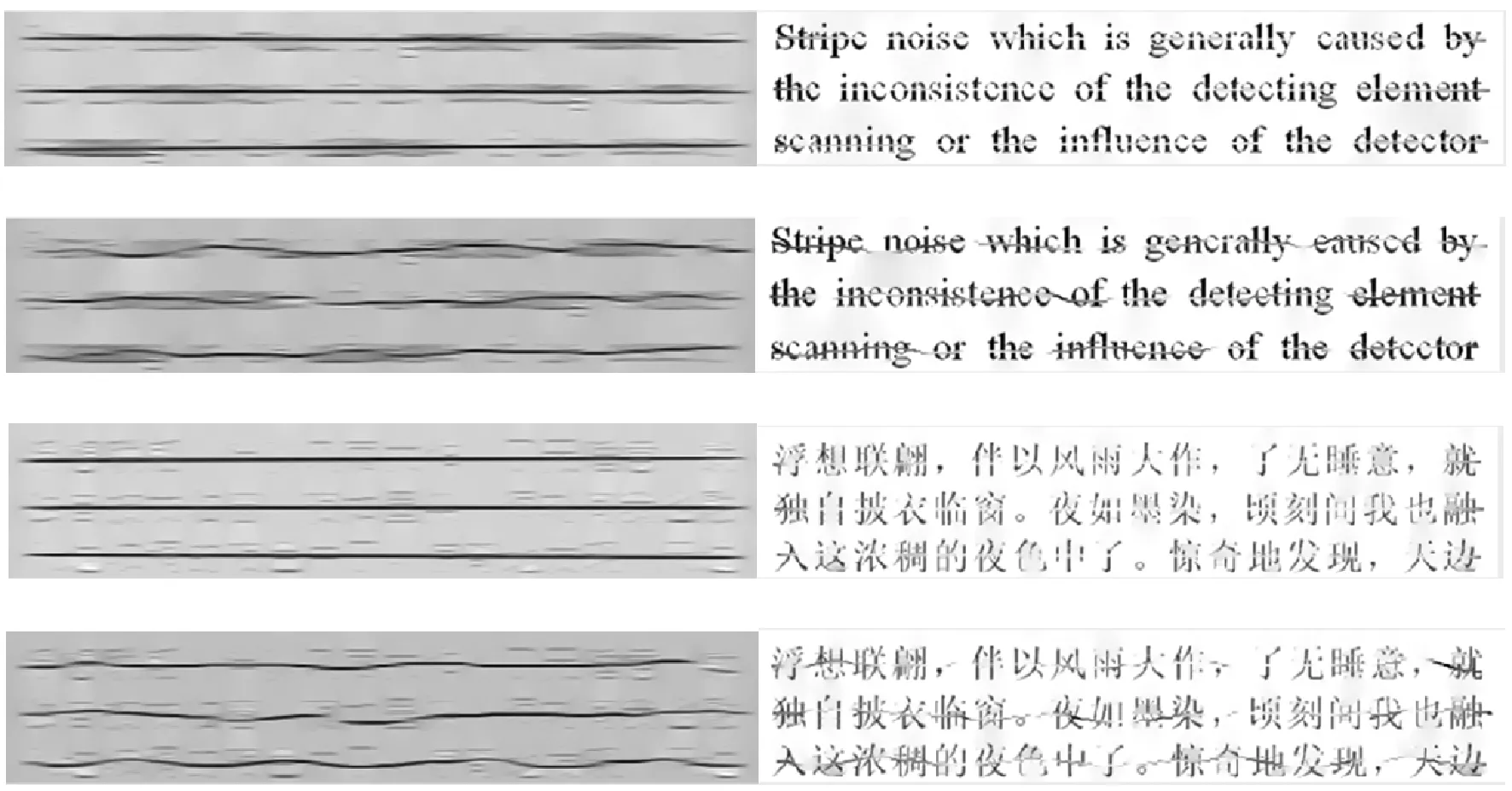
文字作为人们普遍使用的信息交流载体,在信息传播中发挥着重要作用,现代文字通常采用横向表述的方式,因此条带污染是网络文本图像最常用、最经常出现的干扰、加噪及涂改方式(如图1所示),这种图像涂改方式并不会影响阅读者对于文字图像内容的理解,但是会严重干扰网络监管系统的对文字信息的自动识别,因此研究污染的文本图像条带去除技术,对网络中文本图像的识别和监管具有重要的现实意义。

(a) 文档图像 (b)网络文本图像图1 条带污染的文本图像
一般意义上受污染的文本图像主要指采用扫描仪、复印机等光学仪器对纸质文档扫描成像时,受纸张质量、背景等原因产生的噪声[2],大量研究都集中在去除这类噪声污染而针对人为或手工故意添加的条带型污染、划痕、标注等噪声去除与恢复的研究较少。通常学术界对条带噪声的研究一般集中于遥感图像,是由探测元件扫描不一致或探测器运动、温度变化等因素的影响引起的一种系统性条纹污染[3]。这种噪声污染与文本图像的条带污染都是对图像的像素进行逐行破坏,具有一定相似性。
近年来,针对遥感图像的条带去除方法主要是分为三类:基于滤波的方法、基于统计的方法和基于泛函变分的方法。基于滤波的方法是通过各种滤波器去除遥感图像的条带噪声(如文献[4-6])。基于统计的方法主要是分析条纹的分布(如文献[7-8])。最近,基于泛函变分的方法在遥感图像去除条带噪声问题上显示出优越性,该方法主要是探索和发现内在先验知识,生成合理的正则化模型。文献[9]提出了一种去除MODIS图像条纹的单向全变分(Unidirectional Total Variation,UTV)模型。文献[10]提出了一种将UTV与稀疏条纹先验相结合的优化模型。文献[11]利用具有各向异性光谱空间全变分正则化的分裂Bregman迭代法去除多光谱图像条纹。文献[3]提出了一种非凸L0稀疏遥感图像去噪模型,并通过近似交替方向乘数法(PADMM)为基础的算法求解得到了较好的结果。然而,文本图像中的条带噪声相比较于遥感图像中的条带噪声对于图像像素的逐行破坏比较严重,对文字覆盖的像素宽度比例也更大,单纯采用遥感图像的去条带方法并不能准确地估计出条带图像,需要寻找到合适的方法准确地估计并修复条带区域,这也是本文的主要工作。
图像修复方法主要分为两类:基于偏微分方程(PDE)的方法和基于范例/样本的方法。基于样本的方法是一种非常有效的大目标区域修复方法。它们倾向于通过直接从源区域复制和粘贴来填充目标区域,从而很好地保留图像纹理[12-14]。基于偏微分方程的方法不太适合恢复大区域的纹理,但非常适合于完成直线、曲线和修补小区域,可以有效避免断裂边缘,因此更适合文本字符图像的修复。这项技术首先由Bertalmio等提出[15]。根据Bertalmio等的工作,文献[16-17]提出了两个基于偏微分方程的模型,全变分(TV)模型和曲率驱动扩散(CDD)模型,用于处理非纹理图像的修复问题。近年来基于TV模型的修复研究得到不断拓展,文献[18]提出了一种自适应分数阶TV修复算法,利用分数阶微分的全局性,将ROF修复模型的正则项由一阶微分拓展到分数阶微分。文献[19]提出结合纹理结构的分数阶微分TV模型,文献[20]改进了TV修复算法,在正则项中加入自适应参数扩散调节系数,提高了运算速度,获得了较好的效果。因此可以判断出TV模型算法是一种广泛使用的基于偏微分方程的修复算法。
综上所述,为了去除文本图像的条带污染,我们从条带的结构特性出发,提出了一个基于稀疏模型的污染范围(或区域)估计方法,该模型主要由三个稀疏先验构成,包括基于原图与修复图相似性的约束项、条带(Y轴)的方向特性的L0稀疏先验、条带(X轴)的过平滑“L0稀疏先验”;在X轴和Y轴先验模型中引入自适应参数,实现对水平条带的细节保持和其他方向纹理的平滑并给出对该稀疏模型的优化求解算法,估计出准确的条带污染区域。为了保证字符的完整连续,我们采用经典的TV模型图像修复方法恢复文字。仿真和测试图像的结果表明,该方法可以有效去除文本图像的条带污染,与当前最新的遥感图像去除条带噪声算法以及条纹脉冲噪声图像修复算法相比,本文估计的条带污染区域更加准确,PSNR和SSIM值也有很大提高,均值分别在20和0.93以上,污染英文文本图片文字正确识别率提高40%以上,中文文本提高10%以上。
1 条带估计算法研究
1.1 条带噪声模型
遥感图像条带噪声一般由加性成分和乘性成分组成[21]。文本图像中的条带污染主要是人为在原图上添加的规则或不规则的条纹型噪声污染,因此本文将研究集中在加性条带模型上。
u(x,y)=n(x,y)+s(x,y)
(1)
式中:u(x,y)表示观察图像;s(x,y)表示条带分量;n(x,y)表示底层文本图像。为了方便起见,将式(1)按照逐行转置叠加的方式改写成如下的向量形式:
U=N+S
(2)
式中:U,N,S∈Rn,n=M×N,分别表示观测图像、修复图像和条带噪声,M和N表示图像的行列数。我们的工作目的是估计条带S,找出被污染的区域,然后进行修复。
1.2 0梯度最小化模型
(3)
式中:第一项是保真项,Sp表示平滑后输出图像,Up表示输入的观测图,p表示图像像素坐标位置;λ是正则化参数,C(S)表示0范数正则化项即
C(S)=‖▽Sp‖0=#{p||▽xSp|+|▽ySp|≠0}
(4)
式中:▽是图像的差分运算符,▽x表示沿水平方向的差分运算,▽y表示沿垂直方向的差分运算。C(S)表示图像在水平方向和垂直方向梯度不为0的像素个数。
1.3 条带估计模型
分析条带污染的文本图像,可将未覆盖的文字区域看作待平滑区域,条带区域为平滑后的待保留区域。污染条带一般是逐行(X轴)或近似逐行出现的,并且条带自身可近似为灰度相等、均匀连续的水平条状窄带,相邻像素之间水平差异(X方向梯度)很小,或者甚至接近零,因此,我们使用条带水平方向(X轴)梯度稀疏的先验模型,即:
R1=λ1‖▽xS‖0
(5)
∂yS>>∂xS∂xS≠0
(6)
式中:∂xS和∂yS分别表示图像水平方向和垂直方向的偏导数。如果只采用式(5)的正则项,可以对图1(a)所示的条带污染进行完美的估计,但是对手工添加的不规则条带污染(图2(a))提取效果比较差。图2(b)所示为只包含式(5)的模型对图2(a)提取的条带区域,可以看出无法精确地提取出非水平方向的条带。

(a) 人工条带污染文本图

(b) X轴正则项提取条带图像

(c) 非自适应正则参数提取条带图像图2 只保留X轴正则项和不包含自适应参数条带提取
为此我们引入带自适应参数的垂直方向正则化项并定义正则化项参数:
(7)
同时定义式(5)正则化参数λ1为:
(8)
式中:k1,k2∈R+为辅助参数;ε为不等于零的极小正数,防止出现分母为零的情况。在近似水平条带区域,▽xS值较小,▽yS的值较大,λ1值趋近于无穷小,λ2的值趋近于无穷大,可以有效地平滑掉垂直方向的纹理,保持水平条带,这与我们的目的一致。但是在垂直纹理区域(文本字符部分区域)当▽xS值较小,▽yS的值较大,λ1值趋近于无穷大,λ2的值趋近于无穷小,会保持垂直纹理,这与我们的目的不一致,因此设置两个辅助参数k1、k2,k1参数值偏大,用来抑制Y轴方向梯度,k2参数值偏小,用来尽可能保持水平纹理。而在非垂直非水平的纹理(字符的部分笔画)部分,λ1、λ2可保持在合适的数值,使得非条带区域的文本部分被有效地平滑掉。如果缺乏自适应参数,则模型会有效地保持任意梯度的纹理条纹,使得针对条带污染的提取失败,如图2(c)所示。
(9)
式中:第一项为保真项,S为条带图像,U为观测的条带污染图像。
1.4 模型求解
(10)
C1(S)=#{p||▽xS|≠0}
(11)
C2(S)=#{p||▽yS|≠0}
(12)
引入辅助变量(hp,vp),令hp=▽xSp,vp=▽ySp,将目标函数重写为:
(▽yS-vp)2]+λ1C1(h)+λ2C2(v)}
(13)
式(13)的目标函数可分解为下述3个子问题:
S子问题:
(14)
h子问题:
(15)
v子问题:
(16)
下边分别讨论每个子问题求解方法。
1)S子问题最小化可写作以下形式:
(17)
以矩阵向量的形式表示为:
(18)
式(18)为连续可微凸泛函,对J求关于S的一阶偏导数,并令偏导数等于零,得到:
S=[E+β(BTB+DTD)]-1[U+β(BTH+DTV)]
(19)
直接求逆矩阵计算耗时,可对上述方程两端作傅里叶变换,注意B、D为循环矩阵,其傅里叶变换的卷积等于对应元素的乘积,因而有:
(20)
2)h子问题能量函数可以写作:
(21)
因为C1(h)是0范数,当λ1/β≥(▽xSp)2时,若hp不等于0,则:
(22)
若hp等于0,则:
Ep=(▽xSp)2
(23)
所以hp=0时,minEp=(▽xSp)2。
当λ2/β<(▽xSp)2时,若hp不等于0,则:
(24)
若hp等于0,则:
(25)

综合以上两种情况,有h子问题最优解表达式为:
(26)
3) 对于v子问题最优解表达式为:
(27)
综合以上三个子问题的分析,对于式(9)的最小化求解算法如算法1所示。
算法1式(9)算法
输入:观察图像U(包含条带污染),参数β0、βmax迭代系数r,参数k1、k2。
初始化:S←U,β←β0,i←0
当β≤βmax重复:


3)β←rβ,i++
输出:图像S
结合步骤1)到步骤3),给出式(9)的完整算法。特别是子问题都有闭式解公式。有关算法的收敛性分析参见文献[22]。算法1中总结了求解过程,其中β0、βmax、k1、k2是预先定义的参数。本文将k1设置为1 000,k2设置为0.001。
由于文本或文档图像中的字符包含有极小的水平梯度的像素区域,因此通过算法1得到的条带估计图像会一定程度上保留这些水平梯度区域,在估计的条带图像中以噪声的形式存在,因此需要对条带图像做进一步去噪处理,以得到准确的条带图。本文采用了形态学去除小区域的方法,以8连通域为标准,计算各区域像素个数记为该连通域面积,将像素面积较小的噪声区域进行去除,从而得到文本图像条带污染区域的最终估计。
2 文本图像修复
文本文档图像中的条带污染一般可分为覆盖文字区域和未覆盖文字区域两类对于未覆盖文字的条带形标注、涂改可采用N=U-S直接获取底层文本图像,但是因为覆盖文字的条带区域较大,简单的通过式(2)获得的去条带图像会有很大部分的像素缺失,对于文本识别是不利的。考虑到文本图像不同于普通的灰度图像,文字特征在图像中的表达更趋近于一种纹理,因此本文采用基于TV模型的图像修复,在之前估计出的污染区域的基础上,进一步恢复被条带污损的文字。
TV模型图像修复方法是一种基于偏微分方程的图像修复方法,其修复模型为:
(28)
式中:D为待修复区域即估计的条带区域,E为D的邻域,第一项为正则项,作用是寻求E∪D区域的最优解,第二项是保真项,u0为待修复图像,u为估计得到的最优修复图像,λ为平衡正则项和保真项的正则化参数。
(29)
(30)
3 实验结果与比较
本节将对所提出的方法性能进行分析,针对英文和中文文本图像中水平方向的规则条带、近似水平的不规则条带以及各种行宽强度的条带污染进行估计和修复,并分析修复前后的文本图像PNSR和SSIM值,以及文字识别率。因为目前针对文本图像去条带污染的相关研究较少,本文与几种最新的去条带方法和图像修复方法进行比较,包括遥感图像条带去除和脉冲噪声图像修复等。由于没有标准的测试图像集,我们使用规则/非规则条带噪声污染文本图像建立一个包含150幅图像的测试集(测试文本包含原图以及污染图片,内容为随机选取中英文文档,不包含任何含义),其中规则条带污染各种文本文档图像50幅,不规则条带污染各种文本文档图像50幅,不同强度条带污染图像50幅。所有实验均在4 GB RAM和Inter(R)Core(TM)CPU i7- 5500UCPU,@2.40 GHz的台式机上用MATLAB(R2016a)进行。
3.1 规则条带文本图像修复
规则的条带污染文本文档图像一般指使用办公软件或者图像编辑软件自动添加的水平条纹,这种方式添加的条带一般为绝对水平梯度,覆盖整个文字区域。本文算法效果如图3所示。

(a) 英文文本图像修复

(b) 中文文本图像修复图3 规则条带污染的文本图像条带估计与修复
可以看出,使用办公软件对英文和中文文本添加的规则水平梯度的条带污染,本文算法可以准确地估计出条带图像,修复后的图像能够完整地去除条带部分,并对条带遮挡区域进行了效果满意的恢复,如字母“e”和汉字“民”,但是个别字符仍然存在修复不完全的情况,如字母“A”和汉字“毛”。
为了客观评价算法的有效性,我们比较去除条带前后图像的PSNR、SSIM值,同时为了验证算法的实际应用性(即条带污染的网络文本图像的文字识别),我们使用同一文字识别模型的OCR识别算法对修复前后的文本图像进行识别。按照识别率=正确识别字符个数/全部字符个数×100%的公式计算(下文的识别率都按照此方法进行初步定性分析)。
图2(a)英文文本图像修复前PSNR、SSIM值分别为16.216 4、0.876 7,正确识别(按顺序)率44.2%,修复后PSNR、SSIM值分别为22.357 9、0.967 3,正确识别率98%,;图2(b)汉字文本图像共31个字符(包括标点)修复前PSNR、SSIM值分别为18.382 6、0.889 4,正确识别率87%,修复后PSNR、SSIM值为25.397 7、0.953 3,正确识别率达到100%。我们对50副规则条带污染文本图像(英文23副,中文27副)进行实验,英文条带文本图像PSNR平均提高6.53,SSIM值平均提高0.087,字符识别率平均提高53.2%,中文条带文本图像PSNR平均提高7.93,SSIM值平均提高0.092,字符识别率平均提高14.9%,因此本文算法对于规则条带污染的文本图像修复具有较好的效果。
3.2 不规则条带文本图像修复
不规则条带污染指的是人为添加条状或近似条状的涂改,一般包括两种情况,一种是指通过图像编辑软件手动添加的条状涂改标注等,这一类是直接对数字图像进行编辑;另一类是纸质书籍、文档中手工添加的条带状标注、涂改、删除等,当需要转化为电子文档、数字图片进行保存或对书籍文档中的文字进行自动识别时,就需要将这些条带污染去除。这类条带污染一般是近似水平梯度的情况,而且是不规则的出现,如图4所示。

(a) 中文书籍文本图像修复

(b) 英文书籍文本图像修复

(c) 中文电子文档文本图像修复

(d) 英文电子文档文本图像修复图4 不规则条带污染的文本图像(黑色背景上的 白色条子图带表示估计的污染区域)
可以看出,分别对中文书籍图像(图4(a))、英文书籍图像(图4(b)),中文字符电子文档图像(图4(c))、英文字符电子文档图像(图4(d))人工添加条带污染,虽然条带噪声在部分区域呈现非水平梯度,算法仍然能够很好地提取完整的条带图像,并对文本图像进行修复,达到正常阅读和识别的目的,这从实验的视觉效果中可以直接体会到。修复前后PSNR、SSIM与OCR算法文字识别率(只针对条带覆盖字符区域)结果如表1所示。

表1 人工条带污染文本图像修复前后评价数据对比
可以看出,条带污染对英文文本的字符识别率破坏比较严重,而被污染的中文字符的识别率稍高,经本文算法处理后的文本图像的PSNR、SSIM值以及识别率都得到了有效改善。通过对50幅人工污染的条带文本图像(中文书籍图片15幅,英文书籍图片8幅,中文电子文档图片15幅,英文电子文档图片12幅)仿真实验分析,中文书籍图片修复后文字PSNR和SSIM平均分别提高4.98、0.079,识别率平均提高12.5%,英文书籍图片修复后PSNR和SSIM平均提高4.33、0.068,识别率提高50.3%,中文电子文档图片修复后识别率提高9.8%,PSNR和SSIM分别提高7.84、0.082,英文电子文档图片修复后识别率提高62.4%,PSNR和SSIM分别提高8.14、0.089。因此本文方法在去除人工污染的英文文本图像中不规则条带方面同样有很好的表现,有效去除了条带噪声,提高了文本图像的识别率。
3.3 不同强度条带去除分析
从图4的结果中可以初步分析出,条带区域在覆盖文字字符占比较大即条带行宽较大的情况下,文字修复后的视觉效果和识别率均有一定程度的降低。为了进一步分析本文算法对于文本图像不同行宽的条带污染估计和修复能力,我们对同一文本图像添加不同行宽的条带污染,分析本文算法对条带图像的估计情况和修复效果。
如图5、图6所示,对同一英文文本图像和中文文本图像添加不同行宽强度的规则与不规则的条带污染,通过实验结果视觉效果可以看出,本文算法能够精确地估计出不同强度的条带污染区域,但是随着条带行宽强度增大,字符修复的效果逐渐变差,在条带噪声强度最大的最后一行出现字符被遮挡区域效果更差。

图5 英文文本不同强度条带估计与修复

图6 中文文本不同强度条带估计与修复
为了分析本文方法在不同强度条带污染的文本图像修复的文字识别率,对同一文本图像添加强度逐渐增加的条带污染,计算PSNR和SSIM值,通过OCR方法进行识别,并分析识别率。
如图7所示,对同一英文文档图像(共计34字符)添加三种强度宽度规则条带污染和不规则条带污染。修复前后的PSNR与SSIM值如表2所示。图7(a)三幅图像字符识别率分别为58.8%、26.5%、0%;修复后图7(e)字符识别率分别为100%、79.4%、18.8%;图7(b)字符识别率分别为64.7%、56.3%、41.2%,修复后图7(f)字符识别率分别为100%、91.2%、79.4%。通过实验结果可以分析出本文方法在不同强度条带污染的英文文本图像修复上都大幅度提高了字符的识别率,但是随着条带强度的增大,PSNR与SSIM值以及识别率有所下降,但相比较比原图有着一定提高,这一数据也和主观视觉感受相一致。

(a) 规则条带 (b) 不规则条带

(c) 规则条带估计 (d) 不规则条带估计

(e) 规则条带修复图像 (f) 不规则条带修复图像图7 多强度条带英文文本图像修复

表2 多强度条带英文文本图像修复PSNR和SSIM
如图8所示,对同一中文文档图像(共计15字符)添加三种强度宽度规则条带污染和不规则条带污染,修复前后的PSNR与SSIM值如表3所示。原始图像图8(a)三字符识别率分别为80%、66.7%、60%;修复后图8(e)字符识别率分别为100%、93.3%、53.3%;图8(b)字符识别率分别为93.3%、53.3%、46.7%,修复后图8(f)字符识别率分别为100%、93.3%、46.7%。通过实验可以分析出因为中文字符的结构与英文的差别,条带污染对中文字符识别率的影响要低于英文字符,但相同的是条带强度越大,PSNR、SSIM值和识别率越低,通过本文算法修复后的各项数据均有一定提高,在条带强度逐渐增大的情况下,数据改善效果逐渐降低。

(a) 规则条带 (b) 不规则条带

(c) 规则条带估计 (d) 不规则条带估计

(e) 规则条带修复图像 (f) 不规则条带修复图像图8 多强度条带中文文本图像修复

表3 多强度条带中文文本图像修复PSNR与SSIM
为了验证本文方法在不同强度条带污染图像修复效果一般性,我们采用图7、图8实验方法分析三种强度条带污染(规则和不规则)的文本图像50幅(电子文本图片)的文字识别率,每幅不少于100字符。其中英文25幅(规则条带12幅,不规则13幅),每幅中文25幅(规则条带12幅,不规则13幅),计算修复后的字符识别率(如图9、图10所示),直方图纵坐标为字符识别率,横坐标为测试图像编号,浅灰色直方图为0.5磅宽度条带,标注为强度1,深灰色直方图为1.5磅宽度条带,标注为强度2,黑色为2.5磅宽度条带,标注为强度3。

(a) 规则条带英文OCR识别率直方图
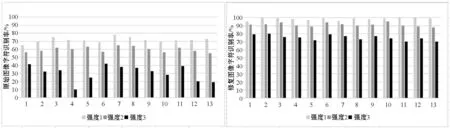
(b) 不规则条带英文OCR识别率直方图图9 英文文本图像OCR识别率直方图对比

(a) 规则条带中文OCR识别率直方图

(b) 不规则条带中文OCR识别率直方图图10 中文文本图像OCR识别率直方图对比
由识别率直方图对比结果可以看出,本文算法对不同强度条带污染文本图像的修复识别率显著提高,但是随着条带行宽增加(如强度3条带图像),条带覆盖字符区域面积比例较大,对字符结构破坏比较严重,修复后识别率提高效果不明显,说明修复算法还有进一步提升的空间,但是实验结果仍然证明本文方法在去除条带,提高文本图像识别率上确实有效的。
3.4 本文算法与其他算法比较
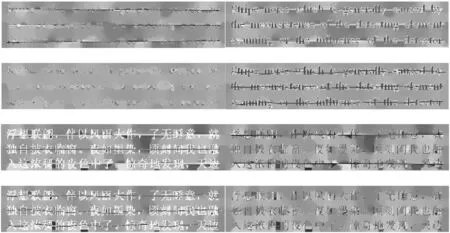
因为目前在文本图像条带污染去除方面的研究较少,为了进一步分析本文算法与其他方法在文本图像去除条带的修复效果,我们选择在遥感图像去除条带噪声效果较好的几种最新算法,包括方向0稀疏建模的图像条纹噪声去除(UESTC)[3](图11(a))、基于图像分解的遥感图像条纹噪声去除(LRSID)[25](图11(b)),以及0TV稀疏优化方法的脉冲噪声图像恢复算法[23](图11(c))。可以看出三种算法在条带估计和图像修复上都有较好的视觉效果。

(a) UESTC

(b) LRSID

(c) 0TV图11 三种算法条带估计和去除
为了比较三种算法和本文方法文本图像条带去除效果,实验选用0.5磅强度的规则/不规则条带污染文本图像,分别给出了四种算法对测试图的条带估计级图像修复效果,并比较去除条带后图像的PSNR、SSIM值以及OCR识别率。
如图12(b)所示,UESTC算法能够较好地估计出文本图像规则条带污染图像,修复效果也可达满意效果,但是对于不规则条带的估计和修复效果不好,特别是非水平梯度区域;图12(c)中LRSID算法也可估计出规则条带,但是对于不规则条带的估计以及整体修复结果较差;图12(d)0TV算法因为缺少精确的条带估计方法,使得对所有类型文本图像修复效果都比较差。本文算法可以精确地估计规则条带进行修复,尤其在不规则条带的估计和文本图像修复上有着明显优于其他算法的表现,这从实验的视觉效果中可以直接体现出来。

(a) 条带污染文本图
(b) UESTC

(c) LRSID
(d) 0TV

(e) 本文算法图12 不同算法去除文本条带污染效果比较
为了量化本文算法文本图像去条带能力,实验分别给出4种算法条带污染文本图像修复后对应的PSNR、SSIM以及文字OCR识别率(以单个字符为准)计算值如表4所示。为了制表方便,图12(a)四幅受污染文本图像分别标记为图像1、图像2、图像3和图像4。

表4 四种算法PSNR、SSIM和OCR识别率
可以看出,本文算法修复的图像在PSNR和SSIM值上都明显优于其他三种算法,尤其在修复图像识别率上有着更优秀的表现。采用以上方法对10幅条带污染图像的实验分析比较,本文算法在英文文本修复图像的PSNR值均在20左右,SSIM值在0.93左右,对中文文本修复图像的PSNR值均在24左右,SSIM值在0.94左右,都优于其他算法。OCR识别率本文算法的规则条带识别率都在90%以上,不规则条带文本识别率均在95%以上,综合以上实验数据,本文算法具有良好的文本图像条带去除能力,基本达到提高识别率的要求。
3.5 一般性实验
为了验证算法的一般性,我们又对包含文本字符较多的大幅文本图像进行了仿真实验,部分实验结果如图13所示。

(a) 英文文本条带提取与修复

(b) 中文文本条带提取和修复图13 多行大幅文本图像条带提取和修复
由图13的实验结果可以观察到,本文算法针对行数较多的大幅文本图像也能够较好地提取条带污染并进行修复。我们在测试集基础上添加了20幅平均超过15行的大幅文本污染图像,经过实验均能有效地提取出文本中的条带污染进行修复,证明本文算法针对一般尺寸的书籍、文档等数字图像的条带污染具有较好的修复能力。
3.6 局限性分析
由于我们的方法是假定文本图像条带的具体类型是水平梯度和近水平梯度的,虽然这与文本涂改的一般情况相一致,但是对于非水平梯度的涂改污染修复效果还是有限的。同时本文方法虽然可以良好地估计出各种行宽强度的条带图像,但是对强度较大的条带图像修复效果还达不到满意的结果,因此对于任意方向、行宽强度条带污染文本污染的估计和文本图像的修复算法还需要进一步研究。
