基于决策树的自适应网页正文抽取方法
2019-04-12吕容政刘嘉勇
吕容政,刘嘉勇
(1.四川大学电子信息学院,成都610065;2.四川大学网络空间安全学院,成都610065)
0 引言
Web 页面是目前人们获取信息的主要方式之一,也是舆情监测、数据分析和处理的一个重要来源。常见的Web 网页中除了主要的内容外,还包含大量与主题内容无关的噪声信息,如广告链接、推荐链接、导航信息等。因此,过滤网页中的噪声信息,抽取网页的正文内容,具有重要的研究价值和应用前景。现有的常见Web 信息抽取技术有基于特定网站模板,基于视觉特征,基于DOM 结构和基于数理统计。目前基于DOM 树结构和基于模板的抽取技术得到了广泛的运用。
基于模板的Web 信息抽取技术是假设网页使用相同或者相似的模板构建的,这类方法通过具有相同或者相似模板的网页训练生成一个通用的模板结构进行网页的信息抽取。Bar-Yossef 等人[1]采用基于模板的方式进行正文抽取,但是这种方法难以应对网页结构的更新和修改。Song 等人[2]将文本密度定义为标签内所有文字与所有标签数量之比,这种定义对于标签量大的正文密度评估会有较大偏差,而且计算量较大。基于统计原理的技术在理论上易于实现,但其难点在于确定一个合理的阈值,因此对于内容丰富度网页差异很大的网页效果不理想[3]。李伟男等人[4]基于VIPS 算法,提出了改进的隐马尔可夫模型,实现Web信息抽取。基于VIPS 算法的Web 信息抽取的优点是面对许多表现形式单一、代码层次上区别很大的网页时,有很好的抽取性能,但是这种方法需要对网页进行渲染,相对于其他方法,需要占用更多的计算资源。
在实际应用中,基于密度及文本特征的新闻正文抽取算法往往适应性不高[5]。本文利用节点多个特征,提出一种基于决策树的自适应网页的正文抽取方法。本文以网页中一个叶子结点为单位,分析计算特征向量,然后使用决策树分类方法判断节点是属于正文还是噪声。之后通过信噪比衡量正文信息和噪声信息的相对比重,最终抽取出网页的正文。相对基于文本块密度和标签路径覆盖率的网页正文抽取[6],本文引入信噪比有效减少了由于分类错误而导致的误差。另外,通过选取信噪比值最高的结点,可有效避免阈值需要人工确定的问题,实现网页正文抽取算法的自适应。
1 特征向量提取
对于Web 上的网页,依据其网页类型可以将它们分为三类[7]:主题型网页、Hub 型网页和图片型网页。本文的研究对象是主题型网页,即从主题型网页中抽取网页主题相关的正文信息。由于主题型网页不仅承载有主体内容,有时还会添加一些导航、推荐或者广告链接。本文将网页正文定义为以网页主体内容区域,网页中其他除主体内容以外的部分定义为噪声[8]。
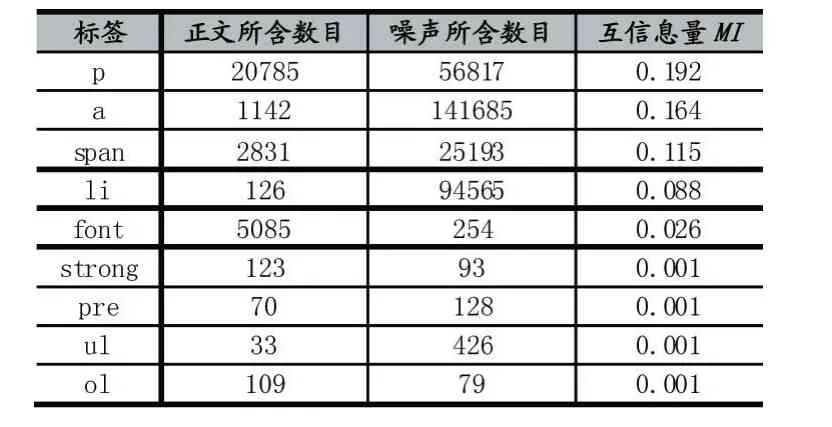
考虑到HTML 文档中 目前HTML 文档结构都遵从于w3c 制定的规范,因此部分标签可能一定的语义[10]。例如 互信息用于表示信息之间的关系,是两个随机变量统计相关性的测度,衡量的是某个特征向量和特征类别之间的统计相关性[11],因此本文采用互信息方法提取标签语义维度的特征向量,计算公式如公式(1): 其中,MI 是标签的互信息量,m 为标签类别数,P(ci)表示类别ci 的概率,P(t,ci)表示包含特征t 且属于类别ci的概率;P(t)表示特征t 的概率。 互信息量较高的向量通常在某个类别ci中出现的概率高,而在其他文本类别中出现概率低,也就可能被选作类别ci的特征。为了探明某个标签的语义,本文通过对凤凰网988 篇已知正文和噪声的网页样本进行了统计,然后计算向量互信息,其中网页样本中正文标签节点的数目为30304,噪声样本共含有331043 个节点,经过统计得出结论如表1。 表1 正文与噪声样本中标签数量与互信息量 如表1,经过互信息计算,可以得出 在标签文本密度向量上,胡俊等人[12]对于网页的文本密度定义为长文本标签比LTR,设T 是DOM 树或其子树,长文本标签比LTR 为T 中非链接长文本节点的文本长度总和与T 中非链接标签数量的比值。这种方法要提前设置长文本的阈值,对于不同的网页文本的阈值不一样,在这种情况下,以上定义方法不能很好地表征不同的网页。通常情况下正文的文本密度比较集中,噪声文本为分散文本,文本字符长度会比较小,因此本文将一个标签内去除停用字符剩下的有效字符数定义为标签所含的文本密度,计算如公式(2)。 其中Tn表示第n 个叶子结点的文本密度,ci表示一个有效字符,m 表示当前叶子结点以内的有效字符个数。 这种计算方法在网页压缩的情况下仍然能够表征文本密度向量。根据w3c 规范,标签节点上可以有指定的属性,但属性只是负责控制显示样式,因此与标签内的文本没有关系。这种文本密度的计算方法有效地防止了标签上添加过多的属性导致文本密度减小问题。 本文采用统计的方法得出文本标签文本密度向量的概率密度分布。本文对988 篇有效网页的DOM 文档的正文与噪声叶子节点密度进行了统计并得出相关直方图与概率分布图。正文节点文本密度概率分布图如图1,噪声节点文本密度概率分布图如图2 所示。 图1 正文样本中节点文本密度概率分布图 图2 噪声样本中节点文本密度概率分布图 从直方图与概率分布图中可以看出,正文部分的文本密度分布比较广泛,因为一般正文部分以一个标签包含一个自然段的内容。而噪声区域的文本密度量大多都小于20,因为噪声区域的大多是一些简短的导航或者链接。 在网页当中,往往正文都是经过特定编辑器编辑产生,而编辑器大多采用某些固定的模板来排版。因此功能区域相同的区块往往标签都具有相似性。本文将拥有相同父节点的DOM 结点定义为兄弟节点,本文定义兄弟节点的相似度为兄弟节点之间标签类别相同数量。 如图3,图中1、2 号标签在同一父节点下有两个相同的标签,因此,兄弟节点相似度为2。同理4、5、6 号节点的兄弟节点相似度为3。而7、8 号标签在同一个父节点下除了节点本身没有其他与之相同的标签,因此相似度为1。 图3 标签兄弟节点相似度示意图 对于兄弟节点相似度,本文同样采用统计的方法获得兄弟节点相似度直方图与概率分布图。本文最终获取到988 篇有效样本。正文节点标签相似性直方图与概率分布图如图4,噪声节点标签相似度直方图与概率分布图如图5。 图4 正文样本标签兄弟节点相似度概率分布图 图5 噪声样本标签兄弟节点相似度概率分布图 从图4 与图5 可以得出,正文当中的标签会出现兄弟节点相似度很大的节点,而噪声当中很少出现类似的节点。这是因为正文当中有大量的语句,往往一条语句由同一种标签包含,因此相似度高。而噪声区域链接、推荐、广告等内容相对分散,故节点相似度相对较低。 外链是互联网的血液,是链接的一种;没有链接的话,信息就是孤立的,结果就是我们什么都看不到。一个网站是很难做到面面俱到的,因此需要链接到别的网站,将其他网站所能补充的信息吸收过来。但是这对于网页正文信息来说是属于噪声信息。通过遍历DOM 树节点信息获取 在对一篇网页训练或者处理之前,首先需要进行预处理。考虑到 本文用以文本为主体内容的网页进行分析,从“标签语义”、“文本密度”、“兄弟节点相似度”以及“标签外链”四个特征来分析网页的正文内容与噪声。将HT⁃ML 标签叶子节点分为两类,正文类与噪声类,正文记为Y,噪声记为N,记类别集合C,那么有C={Y,N}。一个HTML 标签节点可以由以下特征来描述: (1)标签语义,如 (2)标签文本密度,一般来说,文本量越大,越有可能是正文,标记为T。 (3)标签相似兄弟节点相似性,标记为S。 (4)标签的外链,一般来说正文部分是不包含外链接的,标记为L。 所以HTML 叶子节点的特征向量可以表示为:{M,T,S,L},根据决策树分类算法,在构建决策树时需要计算估计每个特征向量的信息增益[13],本文通过对988 篇来自凤凰新闻网页的有效样本做统计,以每篇网页的DOM 树叶子结点作为一个样本,根据统计结果得到网页正文与噪声在HTML 文档中的分布特征。根据四个特征向量的特征计算每个特征向量的信息增益,建立决策树模型,根据建立好的决策树将DOM 树叶子结点分类为正文与噪声;然后根据分类结果计算每个DOM树中非叶子节点的信噪比,选取信噪比最高的DOM 节点即为网页正文区域。 对于一个未知类别的节点,根据决策树分类的方法,按如下步骤对一个节点进行分类: (1)设node={M,T,S,L}分类的一个节点。 (2)当前对一个叶子节点进行分类,仅有两种可能C={Y,N},其中Y 表示当前节点是正文,N 表示当前节点是噪声。 (3)首先选定标签语义特征向量M 来划分所有的样本,根据公式(3)计算标签语义特征向量M 的信息熵,然后通过公式(3): 其中Gain 表示节点的复杂度,Gain 越高,说明复杂度越高。信息增益说白了就是分裂前的数据复杂度减去孩子节点的数据复杂度的和,信息增益越大,分裂后的复杂度减小得越多,分类的效果越明显。节点复杂度可以由公式(4): 其中Pi表示类i 的数量占比。以二分类问题为例,如果两类的数量相同,此时分类节点的纯度最低,熵等于1;如果节点的数据属于同一类时,此时节点的纯度最高,熵等于0。同理对于其他三个特征向量,通过公式(3)和公式(4)得出信息增益。 (4)由四个特征向量的信息增益构建出二叉树,最终得到分类结果。 经过上一阶段的分类,将一片HTML 文档中每一个DOM 树叶子节点分为了正文或者噪声两类。在自适应正文提取阶段,本文通过计算DOM 树中每一个非叶子节点的信噪比,选取信噪比最高的DOM 节点即为正文区域。本文使用公式(5)定义一个DOM 树非叶子节点的信噪比。 其中x 表示某一结点,mi表示x 的子节点,I(mi)表示一个正文子节点的信息量,n 表示当前结点的直接子结点数目。I(mi)的计算方式如公式(6)。 其中α表示正文兄弟节点相似度。ci表示正文结点内的一个有效字符。N(mi)表示一个噪声子节点的噪声量,DOM 树叶子节点标签所含的噪声量计算方式如公式(7)。 其中β表示噪声兄弟节点的相似度,li表示噪声结点内的一个有效字符。为了防止父节点和子节点中所含信息与噪声相等,信噪比相同,最终导致提取正文不够精确,引入一个衰减系数λ(λ>1)。信噪比越高,表示节点信息所含有的信息量越大,信噪比越小,表示网页当中的无用信息越多,或者是文章主体内容不明显。考虑到标签的信息含量不仅与所含文本相关,而且相同的标签在同一功能区具有协同作用,因此本文α和β取值均为该结点兄弟节点相似度的值。 通过计算每个DOM 树非叶子结点的信噪比,选取信噪比最大的节点就是网页正文区域,相对于向菁菁等人[14]只针对单一的新闻网页的正文抽取,本文通过信噪比得出网页正文区域的这种方式无需根据网页的类别调整阈值,因此具有对不同网页的适应能力。 本文通过Python 编写数据采集程序从网易新闻、腾讯新闻、CCTV.com、人民网、新浪网和搜狐网六个网站采集样本,并精确定位1000 个样本的正文与噪声,存储在本地磁盘。在计算过程当中,忽略掉因为格式或者编码等原因出错的12 篇网页,去除 表2 DOM 树叶子结点分类结果混合矩阵 由表2 可知,通过决策树分类算法所提取的四个特征向量对于噪声节点的分类效果比较好,但是对于正文节点的分类效果相对较差,这是因为一些网页中正文部分会夹杂一些文本长度短、外链接等元素,这些类型的节点更加符合噪声的特征,因此被误判。所以本文中节点分类仅仅是本文噪声提取的其中一步,在计算非叶子结点信噪比时,正文中所混杂的少量噪声和噪声中被误判为正文节点会被“平滑”。因此在本文的分类结果可以适用。 正文抽取的评判标准为通过算法抽取正确性与实际精确定位的网页正文相比较,相似度超过95%即判断为抽取正确。本文使用向量空间模型[15],将两篇待对比的文章使用词频向量表示,通过计算两个向量之间的夹角判断文本的相似度。本文使用开源DOM 树解析库XPath 结合正则表达式精确定位正文与噪声,经过XPath 与正则表达式提取到的正文可以认为是标准正文。 正文提取的实验数据和DOM 树分类实验的数据一样,通过特征向量提取章节提取特征向量{M,T,S,L},然后计算出四个特征向量的信息熵,构建出决策树分类模型,将样本分为正文类与噪声类;然后根据分类结果计算每一个DOM 树非叶子节点的信噪比,根据信噪比的大小最终得到DOM 树节点的正文区域。 本文选取陈西安[16]的智能Web 新闻文本采集方法研究和杨柳青等人[17]基于布局相似性的网页正文内容提取研究作为对比实验,以正文抽取的准确性作为评价指标。文献[16]研究方法是一种基于文本标签特征挖掘的网页正文提取方法。文献[17]杨柳青等基于布局相似性的网页正文内容提取研究,该算法基于同一网站下的网页具有在内容布局和样式结构上非常相似的特点,本质上是一种基于模板的正文抽取算法。算法当中的相关参数根据训练样本调整为作者论文当中给出的最优参数。本文的网页正文抽取算法并不需要其他额外的阈值设定。 实际测试样本从网易新闻、腾讯新闻、CCTV.com、人民网、新浪网和搜狐网和六个新闻网站主页上抓取以主题型的有效网页,每个网站中的网页来自五个不同的专题或频道,总共1200 篇。分别用三种算法做正文提取,实际抽取结果正确率对比表如表3。 表3 正文抽取结果对比表 由表4 结果可以看到,相对于文献[16]陈西安的网页抽取算法,在新闻网页的抽取准确性上相对较高,但是在某些类型网页上抽取准确率相对更低,适本文算法对于不同的网站适应性更强,这是因为在他的网页抽取算法当中,算法需要确定一个阈值,该阈值根据经验选取,但是对于不同种类的网页,最优阈值很可能发生变化,因此算法对不同类型网页表现出不稳定。相对于文献[17]杨柳青等的网页正文的算法,因为基于布局相似性的原理,所以对于网页布局变化小的站点比较适用,并且抽取速度较快,从表4 可以看到该方法在新闻类网站上的抽取效果显著,对于搜狐网站的抽取正确性相对较低。由于网页的轻微修改就可能对正文的抽取产生很大干扰,以至于不能正确抽取网页正文,所以该方法对某些站点的正文提取正确率不高。本文以DOM 树结点为单位,使用四个维度的特征向量提高对网页内容的表征性,根据信噪比来自适应确定正确区域,抽取结果表明,本算法适应性好,性能稳定,相对于另外两种正文抽取算法本算法的准确性更高和适应性更强。 本文提出的基于决策树的自适应网页正文抽取算法能够有效提取出HTML 网页当中的正文部分。算法选取了四个相互独立,同时又能较好地表征文本属性的向量,利用决策树分类算法将DOM 树叶子节点做分类,然后借鉴通信工程领域的信噪比定义,有效地“平滑”了由分类错误带来的误差,最终实现了网页正文抽取。本算法根据样本训练出的模型能够很好地适应不同类型题材的未知样本,模型训练完成,对于不同类型的网页不再需要额外调节参数,因此适应性比较强。在实际程序实现当中,由于需要遍历DOM 树的所有非叶子节点,并计算信噪比,对于DOM 结构复杂的网页所需时间相对较长。是否必须对所有非叶子节点都遍历并计算信噪比,日后将做进一步研究,以减小算法运行的时间代价。1.1 标签语义

1.2 标签文本密度



1.3 标签兄弟节点相似度



1.4 标签外链
2 正文抽取算法
2.1 DOM树叶子节点分类


2.2 自适应正文提取



3 实验结果与分析
3.1 叶子结点分类结果分析

3.2 正文提取实验及结果

4 结语
