基于Faster R-CNN 的复杂背景下的人脸检测
2019-04-12王翰林何中市
王翰林,何中市
(重庆大学计算机学院,重庆400044)
0 引言
近些年,由于深度学习与图像检测的结合,导致图像检测领域的极大发展。人脸识别问题作为图像检测领域最活跃的问题之一,自然也取得极大的进步。各种新的基于深度学习网络的人脸检测方法层出不穷,在单一环境下的人脸检测问题已经得到较为完善的解决。但是在复杂环境下,由于存在光照、遮挡、姿势和分辨率等问题,人脸检测的精度和速度还是有待提高。
目标检测(Object Detection)领域在Ross Girshick引入深度学习模型CNN 之后,开始了新的篇章。Ross的主要贡献是把CNN 这个模型作为特征提取器引入到了目标检测领域,在这之前,目标检测领域的所有处于特征提取阶段的方法都是利用数学和经验来人为的设计针对特定任务的特征,例如Viola-Jones 在人脸检测领域内使用的Haar-like 特征,还有在行人检测方向使用的HOG(Histogram Of Gradient)特征以及后来的SIFT(Scale-Invariant Feature Transform),这些特征在特定任务上的效果都比较好。但是,在涉及到更为复杂的环境下的检测任务时,它们都不能很好地做到提取更为灵活准确的特征的效果。
CNN 模型以及其后来发展的变种,之所以能够很好地适应复杂环境下的特征提取工作,是应为它具有大量的可调整的参数,而模型基于这些参数的不断变化,可以带来极强的拟合能力,这就能够充分适应复杂的图片和物体的变化,从这些样本中提取真正关键的特征,而这些特征是靠人类事先设计是不可能实现的。
在通用目标检测领域,基于Ross 提出的R-CNN模型,由何凯明博士提出了SPPnets,改进了图像的输入的需要固定尺寸的问题,接着Ross 又在SPPnets 的基础上提出了Fast R-CNN 进一步的改进了模型,提出了RoI(Region of Interest)层,进一步提高了模型的速度和精度,然后何凯明等人又一次提出了Faster R-CNN模型,主要的贡献是提出了RPN(Region Proposal Net⁃work)改进了Fast R-CNN 模型在生成候选区域的工作,共享了卷积计算,真正实现了端到端(end-to-end)的目标检测模型。而Faster R-CNN 也是目前检测精度最高的通用目标检测模型。此外,还有YOLO 和SSD 等模型,在检测速度上面比Faster R-CNN 模型的效果要好,但是检测精度上总体上还有一些不足。
本文是以Faster R-CNN 模型为基础,其中Faster R-CNN 模型中的CNN 部分采用了ResNet50 作为特征提取器。这是因为残差网络在现今的特征提取方面综合性能是最好的,设计的模型的最重要的两个点是人脸周围的环境以及人类的注意力机制的引入。
人脸周围环境考虑的是人脸因为在复杂背景下,会有很多的遮挡,光照或者分辨率问题,那么,我们在采用anchor(可以理解为模板),就要考虑我们是单纯提取人脸大小的区域,还是根据人脸的大小采取适当的扩大,或者是采用针对一个人脸大小的范围来采取特定大小的缩放。本文采用的是最后一种,这是基于论文find tiny face 提出的,其中有关于这个效果好的具体分析。
人类注意力机制,是模仿人类在观察一张图像时,我们总是倾向于去先查看Salient Object(明显的目标),而不是对所有的物体都做同等重要的关注。所以我们考虑到这一点可以加速模型的检测工作,我们具体是利用ResNet50 中的每个block 的最后一层的特征图,赋予每个层不同的权重,来模仿人类的注意力机制,效果显示能够有效的加速模型的检测速度。
1 相关工作
在人脸检测领域出现了很多优秀的模型,从最早的能够进行实时检测的优秀模型Viola-Jones,该框架是首次在级联的AdaBoost 分类器中使用了矩形Haarlike features,从而实现了实时的人脸检测。缺点是特征的尺寸是相对较大,而且在处理非正面的人脸和复杂环境下的人脸的效果不是很好。为了解决VJ 算法的缺点,陆续在特征的使用上做了改进,例如HOG、SIFT、SURF 和ACF。还有一类是在分类器上面做了文章,如Dlib C++Library 使用了SVM 作为分类器,还有一些方法使用了random forest(随机森林)来作为分类器。
接着出现了DPM(Deformable Parts Model)这种模型,这个模型是基于HOG 描述子改进而来的,主要是解决了物体的多个角度不同而导致的检测不准的问题,在很多检测领域都取得很好的检测效果,一时间成为最好的检测模型,在人脸检测领域也连续成为最好的模型,直到CNN 模型引入到目标检测领域。
近些年随着深度学习模型的不断发展,有很多优秀的人脸检测模型结合了深度学习模型,取得巨大进步,例如Yunzhu Li 在其论文中使用了一个集成了Con⁃vNet 和3D mean 人脸模型的端到端的多任务学习框架,取得了不错的效果。最近,由于Faster R-CNN 模型的兴起,很多模型都开始采用Faster R-CNN 模型,例如Hongwei Qin 在他的论文中使用了该模型,在FD⁃DB 数据集上取得很好的效果。更多的模型都是对Faster R-CNN 模型进行一定的修改来使得自己的模型更适合复杂背景下的人脸检测。例如Wan 等人联合ResNet 和OHEM(Online Hard Example Mining)设计的模型在很多人脸数据集上取得优异的效果。还有Xudong Sun 在Faster R-CNN 的基础上采用了特征融合(Feature Concatenation)、Hard Negative Mining、多尺度训练(Multi-Scale Training)等策略来改进模型,在FDDB 数据集上取得了很好的效果。
还有很多人开始探索模拟人类的视觉机制来设计模型,例如最著名的就是Salient Object 检测,这是利用了人类的注意力机制来设计模型,其主要思想是每一层的特征层提取的特征是不同,计算量也是不同的,越往后,特征图越小,包含的信息越抽象,便于用来识别大的物体,但是小的物体或者说分辨率低的物体就比较容易被忽略,这是因为最后的特征图往往每一个像素点都包含了巨大的接受域(receptive field)。而合理安排每个特征层权重,我们可以对图片中出现的明显物体进行快速的检测,然后对非明显物体进行详细的检测。这样可以加快我们对图像中人脸的检测速度。例如在CVPR2018 会议上,Xiaoning Zhang 的论文提出了一种新的注意力引导网络模型,它以渐进的方式选择性地集成多层次上下文信息。除了模拟人类的注意力机制外,还有一些研究工作是在分析人脸对象周围信息对于判断人脸位置的重要性。
例如,Peiyun Hu 的find tiny face 论文提到了怎么选择一个合适的模板来对人脸信息进行提取。
在本文中,我们提出了一种通过加入人类注意力机制以及环境模板信息的改进的Faster R-CNN 模型。
2 我们的模型
2.1 处理流程
我们的模型是在采用了ResNet50 网络模型作为特征提取器,ResNet50 是在ImageNet 上进行预先训练过的,我们采用的人脸检测的数据集是WIDER FACE,它包含了32,203 张图像,标记了393,703 个人脸,在图像的尺寸、姿势和遮挡方面具有高度的复杂性。这个数据集按照40%/10%/50%的比例划分了训练集,验证集和测试集。模型的处理流程(Pipeline)如图1 所示。
我们首先把基于注意力机制和环境信息改进的模型在WIDER FACE 的训练集上进行OHEM(Online Hard Example Mining)的训练,然后在验证集上面进行超参数的选择,接着我们对自己的模型进行最后的测试,绘制PR 曲线来评估,最后再与表现良好的模型进行对比,获取自己模型的优缺点。

图1 模型处理的基本流程
2.2 关于环境信息的使用
在我们的人类的认识里,环境对于物体的识别是至关重要的。我们通常都会根据人脸周边的环境进行辅助人脸的识别。这里所说的环境,其实指的是人脸这个目标周围的像素点,也就是人脸的ground-truth 之外的包围框。这些多出的信息可以帮助我们进行人脸的识别,但是问题是我们需要采用多大的模板才能有效地帮助我们进行人脸的识别呢?
我们根据文章find tiny face 中的方法总结:
(1)对于大的目标(高度大于140px),使用0.5 倍的模板。
(2)对于小的目标(高度小于40px),使用2 倍的模板。
(3)对于两者之间的就使用1 倍的模板。
这种环境信息的引入导致了模型检测的准确度大幅度提升。
2.3 关于注意力机制的引入
注意力机制在这里的使用,主要是为了提高模型运行的检测速度。注意力机制是对不同层的特征图采用不同的权值,这些权值的大小决定了我们对不同大小物体(人脸)的重要程度,对于高度小于40px 的我们会侧重于使用浅层的特征图来进行检测,对与高度大于140px 的物体我们会侧重于使用深层的特征图的特征进行检测,介于两者之间的物体我们则侧重于使用中间的特征图进行检测。
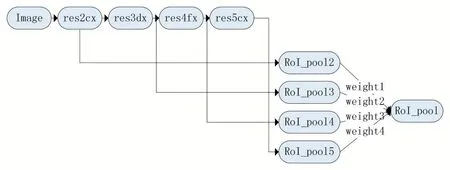
图2 键模块的展示
3 实验
3.1 实验的准备
我们在WIDER FACE 数据集上进行了训练、测试。这个数据集包含了32,203 张图片,总共有393,703张人脸的标记,对于每张人脸的不同的表情(expres⁃sion)、光照(illumination)、图像是否合法(invalid)、遮挡(occlusion)以及(pose)都有标注,这对于训练和测试来说是十分有利的划分。
我们使用了TensorFlow 框架作为训练和测试模型的基本架构,使用ResNet50 作为网络的backbone,进行特征的提取,这个网络是在ImageNet 上面进行过预训练的。我们实验的第一步是使用WIDER FACE 的训练集进行训练,其中每个人脸的对应的标签如表1 所示。

表1
其中2 表示这张图片中的人脸的个数。
下面的10 个参数分别为:x1,y1,w,h,blur,expres⁃sion,illumination,invalid,occlusion,pose。
标注后的图如图3 所示。

图3
我们训练的设置的学习率为0.001,我们的anchor的设置改为根据人脸的大小也就是上面表格中的h 来设置相应的anchor 的大小,而不是采用传统的anchor的设置方式,只是单纯地采用长宽比和scales 来设置anchors 的大小。
我们在训练的时候,还设置相对的res2cx、res3dx、res4fx 以及res5cx 的权重,一开始的初始化采用的是zeros 而不是正态分布的方式,这样的实际效果要好一些。
第二步是在我们使用改进之后的RPN 生成的候选区域放入RoI 层进行相应参数的学习,之后会根据类别概率的损失函数和回归损失函数进行学习,之后就得到了一个学习好的具有复杂背景下识别能力的模型。
3.2 模型在WIDER FACE数据集上的测试结果
图4 给出了我们模型在WIDER FACE 上面的PR曲线,还有一些表现较好的其他的模型的PR 曲线作为对比。可以看到我们的在整体PR 曲线都和其他优秀的模型的PR 曲线持平或者有所超越。同时,经过测试,我们模型的检测速度达到了3FPS,在这个精度下的,速度是比较快的。
另外,我们通过模型测试之后,随机选择一些测试结果的图像,来展示我们模型的检测效果。
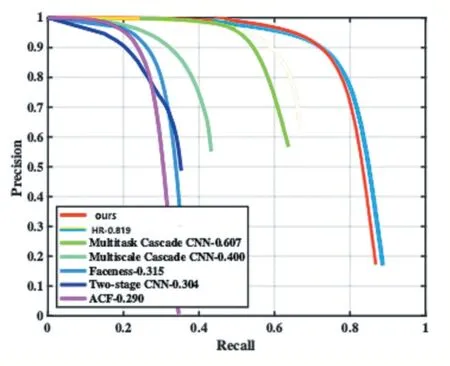
图4

图5
4 结语
通过上面的分析比较,可以说利用人脸周围的环境信息和注意力机制的引入是对复杂背景下的人脸检测的效果提升比较明显的,而且速度相对较快。但是可以注意到,检测的精度和速度还是有很大空间进行提升的,尤其是检测的速度,这一点可能需要更加合理地利用注意力机制来进行有效提升,这也是我们下一步努力的方向。
