基于改进Apriori算法的糖尿病预诊系统①
2019-04-10张云华
张 冲,张云华
(浙江理工大学 信息学院,杭州 310018)
1 引言
糖尿病(diabetes mellitus,DM)已成为世界性疾病,据世界卫生组织(WHO)报道,2025年全球DM患者将达到3亿.而更严重的是,DM相关疾病死亡人数为每年320万[1].随着人们生活水平的提高和生活方式的改变,DM发病率呈现低龄化,我国的DM患病率急剧增加.有关调查显示,在我国经济发达地区DM患病率已高达9%~10%[2].
一方面,由于各方面诊断差异,糖尿病常被漏诊误诊,对患者和社会医疗造成巨大负担.另一方面,互联网发展迅猛,医疗领域产生了海量临床数据,人工处理和分析所耗费成本过大.因此,需要一套良好的系统来完成对大量已确诊病例的挖掘分析.
使用关联规则可以挖掘分析高危因素与糖尿病之间的关系,但是,经典Apriori算法主要存在两大缺陷[3]:① 重复扫描数据库,导致大量时间耗费于I/O操作[4].② 频繁项集自身连接时产生大量候选集,导致空间消耗以指数形式增长.针对以上缺陷,本研究使用矩阵压缩[5]的方式对Apriori算法进行改进,并应用于糖尿病高危因素分析.基于此,设计了一款糖尿病预诊分析系统,该系统能够分析患病概率,辅助医疗诊断.
2 改进算法
2.1 经典Apriori算法
关联分析中的Apriori算法是一种最具影响力的挖掘关联规则频繁项集的算法,其核心是基于两阶段频繁项集思想的递推算法.即首先找出满足最小支持度的所有频繁项集,然后探索同时满足最小支持度阈值和最小置信度阈值的强关联规则,从中发现隐藏在数据间的相关性.将经典Apriori算法用数学语言可描述如下:
记项集X与Y,关联规则可表示为如下蕴涵式:
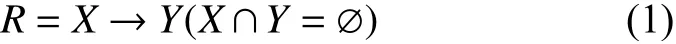
记式(1)中项集X出现的事务次数为 σ(X),事务数据库为T,则支持度的定义可表示为式(2):
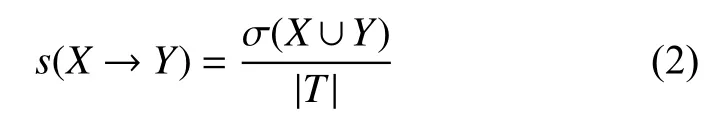
置信度的定义可表示为式(3),其中,支持度大于阈值的项集,称作频繁项集,记为F.
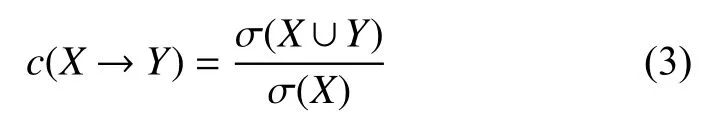
经典Apriori算法使用逐层搜索的迭代方法,用k-项集探索(k+1)-项集.首先找到频繁1-项集,再依据频繁1-项集寻找频繁2-项集,直到找出所有频繁项集,并产生大于阈值的关联规则,如式(4):

记k-项集为Ck,记频繁k-项集为Fk,记事务长度为|Tk|,Apriori算法有如下三条性质:
性质1.Fk出 现的事务次数不小于最小支持数.
性质2.长度小于k的事务不包含任何Fk[6].
性质3.由Ck-1生 成Ck过程中,若Ck-1-2项不同的项做自身连接,将得到冗余项集或非频繁项集[7].
2.2 改进Apriori算法
经典算法每找一个频繁项集Fk都需要扫库一次,导致大量时间耗费于I/O操作;其次,经典算法探索下一个频繁项集过程中做自身连接来产生候选项集时,存在大量冗余.
现有较多Apriori算法的优化或改进方案,文献[8]将算法剪枝与矩阵相联系来减少扫库次数,提高了算法效率,但未处理自连接产生的冗余.文献[9]采用事务矩阵相乘的方法得到频繁项集,一定程度上减少I/O操作,但在事务数据库体量偏大时,矩阵相乘将会占用较多CPU计算时间.
尽管Apriori算法已存在诸多改进方案,但从空间占用率上讲,较少有改进方案处理自连接的冗余,从时间效率上讲,也尚有进一步优化和改进的余地.本文改进算法在自连接过程中去除项集冗余,缩减空间占用率,以避免无效计算.并用事务布尔矩阵压缩的方式对计算方式进行改进,进一步提高算法时间性能.
记项I的向量为,如式(5).其中m为事务总数,Ti为第i个事务.

根据式(5)建立形如式(6)的事务布尔矩阵B.其中m为事务总数,n为项总数.

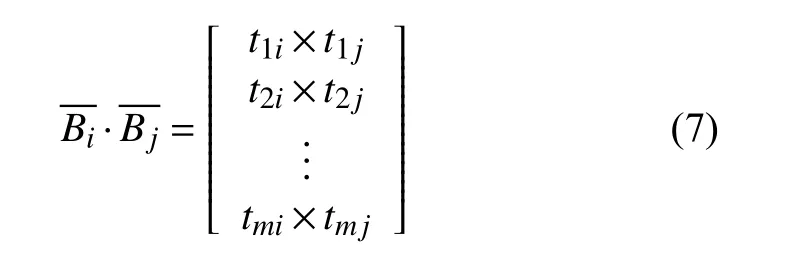
结合以上定义与Apriori算法的三大性质,可推导得到如下三条对布尔矩阵进行压缩的规则:

规则2.布尔矩阵里,长度小于k的事务可以在挖掘Fk过程中删除.即行应满足式(9):

规则3.布尔矩阵里,满足前k-2项相同的项才有必要在挖掘Fk过程中进行自身连接.
下面分析一个建立事务布尔矩阵,在经典算法的基础上对扫库和自连接步骤进行改进,即根据压缩矩阵获取频繁项集和探索关联规则的实例:
① 输入事务数据库T,如表1.输入最小支持度min_sup=0.5,最小置信度min_conf=0.7.
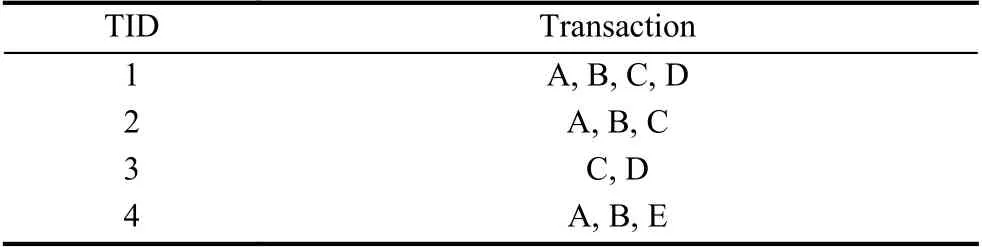
表1 事务数据库
② 扫描事务数据库,建立候选布尔矩阵B′1,并于首行 首列和末行末列各类辅助值,如表2所示.
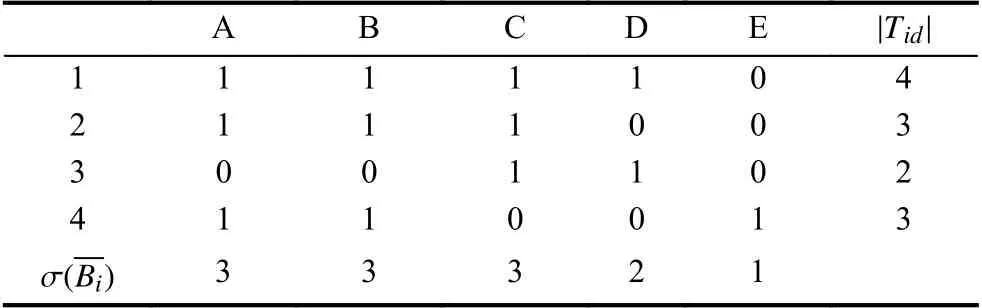
表2 候选布尔矩阵B'1
③ 根据规则1压缩矩阵B'1,即保留A、B、C、D列,得到矩阵B1如表3.分析B1得频繁1-项集如下:


表3 频繁布尔矩阵B1
④ 根据规则2压缩矩阵B1,即保留所有行;再根据规则3对矩阵 B1进行自身连接,即连接AB、AC、A D、BC、BD、CD列;最后得到矩阵B′2如表4.

表4 候选布尔矩阵B'2
⑤ 重复③: 根据规则1压缩矩阵 B′2,即保留AB、AC、BC、CD列,得到矩阵 B2如表5.分析B2可得频繁2-项集和关联规则如下:


表5 频繁布尔矩阵B2
⑥ 以此类推,根据规则1和规则2不断压缩矩阵,直到B′i≠∅,算法结束.
结合上述分析,改进Apriori算法伪代码如下:

2.3 算法分析与对比
为验证性能是否得到提升,对两个算法进行实验对比.实验环境为: Intel Core i5 CPU 3.20 GHz,4 GB内存,512 GB硬盘,Windows 10 操作系统,在Matlab R2017b中得到以下关于两个算法的性能对比图.
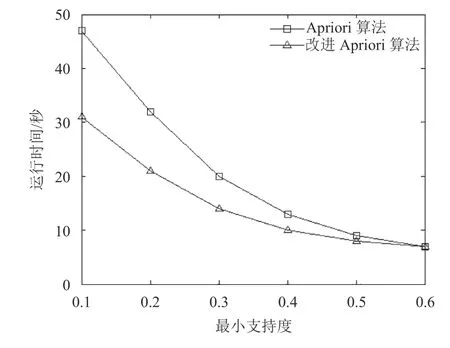
图1 最小支持度与运行时间
从图1可以看出,在相同的最小支持度下,改进Apriori算法在运行速度上得到了明显性能提升.
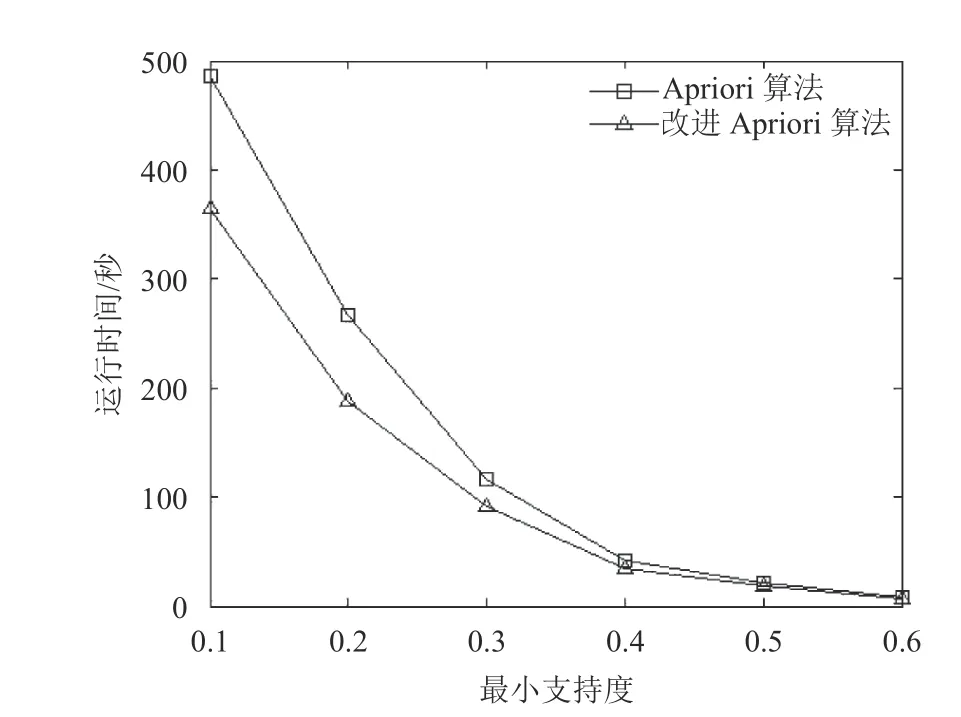
图2 最小支持度与频繁项集数
从图2可以看出,在相同的最小支持度下,改进Apriori算法在探索频繁项集的过程中比经典Apriori算法冗余更少,相应所占用空间也更小.
3 糖尿病预诊系统设计
3.1 糖尿病高危因素分析
本研究从UCL糖尿病数据集选取其中8个相关危险因素[10]进行分析,分别是: 年龄,有无高血压或高血脂病史,身体质量指数(BMI),腰臀比(WHR),是否吸烟,是否饮酒,是否过度饮食和运动量是否达标.将以上因素分别记为项A到项H,针对其中若干非布尔类型的数据预处理[11],年龄大于45记为1,BMI大于28记为1,男性WHR大于0.85、女性WHR大于0.8记为1.最后再加入预诊结果项I,将所有数据整理为事务数据库,便于后续工作进行挖掘和分析.
3.2 系统架构设计
系统选用时下热门技术栈: RPC框架Dubbo,微服务框架Spring Boot,消息中间件RabbitMQ,关系型数据库MySQL,以及作为缓存的Redis.
Dubbo是一款开源RPC框架,它提供了三大核心能力: 面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现.该框架不仅实现了高性能、高可用性,而且使用方便,扩展性极佳[12].
Spring Boot是Java领域知名的微服务框架,微服务的目的在于化解整体架构服务的复杂性,以简单快速的方式实现各个服务的部署和变更.而Spring Boot提供了形式多样的库,支持JPA、RESTFul、Docker等技术,能够让配置、部署和监控变得简单方便[13].
RabbitMQ基于Erlang语言编写,用于在分布式系统中存储转发异步消息,将彼此独立的计算机连接起来组成松耦合的系统,RabbitMQ在易用性扩展性、高可用性等方面表现不俗[14].
MySQL是一款由瑞典的公司开发并且广泛应用于中小型企业或组织的免费数据库,基于Linux 操作系统开发,MySQL体积小、速度快、总体拥有成本低.
Redis是一款基于内存的、可持久化的非关系型Key-Value存储系统,它支持多种数据类型,并支持原子性操作[15].Redis与其他Cache相比,拥有更多的数据结构并支持更丰富的数据操作.
基于上述所选技术栈进行系统架构设计,将系统划分为如图3所示的若干层面.
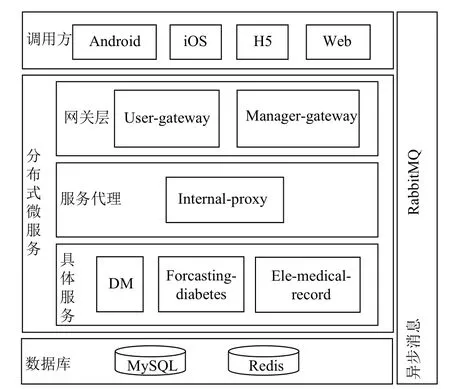
图3 糖尿病预诊系统架构图
网关层: 作为统一请求入口,处理权限认证及负载均衡等,向外提供RESTFul API,并采用令牌桶算法实现API的动态限流.
服务代理层: 为提高系统扩展性和可复用性,抽取公用服务接口,由代理将请求路由至具体服务.
具体服务层: 具体实现三大核心功能,包括关联规则挖掘、糖尿病预诊分析、电子病历处理.
预诊分析模块: 基于用户电子病历中的数据,计算各项高危因素的指标,并匹配满足置信度的关联规则,分析糖尿病的患病概率.
电子病历模块: 为用户建立电子病历,涵盖用户各项相关高危因素信息,并针对特定项进行量化入库.
规则挖掘模块: 对于管理员设定的支持度和置信度,基于所建事务数据库,在后台挖掘满足支持度和置信度阈值的关联规则,并将关联规则落库.
3.3 系统流程设计
系统具体使用流程如图4所示,主要包括三大核心功能的使用流程: 糖尿病自查流程、电子病历录入流程和关联规则挖掘流程.

图4 糖尿病预诊系统流程图
① 当用户提交自查请求,网关层会对请求做权限认证、接口限流令牌校验、安全处理等.随后会生产一条异步消息推送至RabbitMQ,由代理层消费消息并路由至具体服务,实现规则匹配和异步结果返回.
② 当用户电子病历记录为空时,医护人员录入用户各项相关数据.数据提交后,代理层调用具体服务处理数据,生成电子病历并存储入库.
③ 当管理员提交关联规则挖掘请求时,网关层对权限进行校验,随后代理层路由至具体服务,使用改进Apriori算法在后台对数据集进行筛选和挖掘.在关联规则落库后,以站内信和其他特定方式通知管理员关联规则的挖掘结果.
3.4 系统核心配置和UI设计
HIS子系统服务提供者配置文件provide.xml核心内容如下,其中包括暴露的服务接口及注册地址:

服务消费者配置文件consumer.xml核心内容如下,同样包含其注册地址等信息:

接口HisRemoteService定义如下,其中包含根据病历号或姓名性别查找患者、根据患者查找电子病历和诊断结果等方法:

系统用雷达图展示各指标危险临界点与自身指标情况;用饼图展示糖尿病患者某指标异常的比例;最后辅以诊断分析和医嘱建议等文字,效果如图5所示.
3.5 预诊结果分析
截取部分电子病历的核心数据,如图6所示,其中年龄、病史、BMI、WHR、吸烟、饮酒、过度饮食、运动量达标为八项相关因素.
将八项高危因素按照3.1节规则量化,得到如图7所示的项A到项H.运算得出结果即项I,可以发现与真实诊断结果无异.

图5 糖尿病预诊分析界面

图6 电子病历部分数据

图7 量化后的数据
4 结束语
针对Apriori经典算法存在的缺陷,本研究进行了改进,并应用于糖尿病与其高危因素间的关联规则挖掘.通过实验对算法进行对比,结果表明改进Apriori算法性能得到了大幅度提高.基于以上工作,本研究设计了一款糖尿病预诊分析系统,随着挖掘样本数量的逐步增加其准确率也逐步提升.此系统为用户自诊和医护人员辅助诊断提供了更加便捷的方式.
