基于改进损失函数的YOLOv3网络①
2019-04-10吕铄,蔡烜,冯瑞
吕 铄,蔡 烜,冯 瑞
1(复旦大学 计算机科学技术学院,上海 201203)
2(上海视频技术与系统工程研究中心,上海 201203)
3(复旦大学 智能信息处理实验室,上海 201203)
4(公安部第三研究所物联网技术研发中心,上海 201204)
目标检测具有广阔的发展前景和巨大的商业价值,已经成为国内外相关从业者的研究热点,在智能安防、自动驾驶等领域具有广泛应用.经典的目标检测方法有Dalal于2005年提出的基于HOG特征的检测方法[1],Felzenswalb等人于2008年提出的可变行组件模型(Deformable Part Model,DPM)检测方法[2],该方法先利用梯度算子计算出目标物体的HOG特征并采用滑动窗口+SVM的方法进行分类,在目标检测问题中表现良好.
与经典方法相比,深度神经网络提取特征能力强,准确率高,在计算机文本、图像分析等领域取得令人瞩目的成果,受益于深度学习的快速发展,基于卷积神经网络(CNN)的目标检测模型层出不穷,检测效果不断提升,Girshick R等人于2014年提出R-CNN网络[3],采用选择性搜索(selective search)方法代替传统的滑动窗口,将VOC2012数据集上目标检测平均准确率(mean Average Precision,mAP)提高了30%;Girshick R和Ren SQ等人相继提出了Fast R-CNN[4]与Faster R-CNN[5]网络,Faster R-CNN采用区域推荐网络(Region Proposal Network,RPN)生成候选框,再对这些候选框进行分类和坐标回归,检测精度大幅提升,检测速度约5 fps,这些方法由于生成候选框和进行预测分成两个步骤进行,所以称为为Two-Stage方法,同时进行这两种操作的网络称为One-Stage方法,代表有YOLO[6],SSD[7]等.2016年Redmon J等提出YOLO网络,其特点是将生成候选框与分类回归合并成一个步骤,预测时特征图被分成S×S(S为常数,在YOLOv1中取7)个cell,对每个cell进行预测,这就大大降低了计算复杂度,加快了目标检测的速度,帧率最高可达45 fps,之后,Redmon J再次提出了YOLOv2[8],与前代相比,在VOC2007测试集上的mAP由67.4%提高到76.8%,然而由于一个cell只负责预测一个物体,面对被遮挡目标的识别表现不够好.2018年4月,YOLO发布第三个版本YOLOv3[9],在COCO数据集上的mAP-50由YOLOv2的44.0%提高到57.9%,与mAP61.1%的RetinaNet[10]相比,RetinaNet在输入尺寸500×500的情况下检测速度约98 ms/帧,而YOLOv3在输入尺寸416×416时检测速度可达29 ms/帧,在保证速度的前提下,达到了很高的准确率.
为了实现实时分析的目标,本文针对One-Stage方法的代表YOLOv3网络模型进行研究和改进,根据坐标预测值和Sigmoid函数的特殊性质,将原版的损失函数进行优化,不仅减少了梯度消失的情况,而且可以使网络收敛更加快速,同时通过分析数据集中目标的分布情况修正anchor box,使得anchor box更加符合目标尺寸,增强收敛效果,在Pascal VOC[11]数据集上的实验表明,在不影响检测速度的情况下准确率提高了1个百分点左右,且收敛速度变快,使目标检测能力进一步提升.
1 传统YOLOv3网络
YOLO网络将目标检测问题转化为回归问题,合并分类和定位任务到一个步骤,直接预测物体的位置及类别,检测速度可以满足实时分析的要求.YOLOv3包含了新的特征提取网络Darknet-53,以及三种尺度的YOLO层,也就是预测层.通过在三种尺度上进行预测的方法,有效的增强了对不同大小物体及被遮挡物体的检测效果,并引入跃层连接以强化收敛效果,同时采用随机多尺度训练的方式增强了鲁棒性.
1.1 检测过程
YOLOv3提出了新的提取图片特征的网络Darknet53,作为全卷积网络,darknet53主要由卷积层、Batch Normalization及跃层连接组成,激活函数采用LeakyRelu,其网络结构如图1所示.

图1 YOLOv3的网络结构
YOLO卷积层负责输出检测结果,包括目标的中心位置xy,宽高wh,置信度,以及类别,这种检测分别在三个尺度上进行,13×13,26×26,52×52,通道数为3,也就是每个box负责对三个anchor box进行回归,取其中的一个作为最终检测结果,共对9个anchor box进行回归,所以对于一张输入图像,最后的输出尺寸为1×(3×(13×13+26×26+52×52))×(5+k)=1×10647×(5+k),k代表类别数,在COCO数据集上为80,VOC数据集上为20,如图2所示.

图2 YOLOv3网络的输出格式
在YOLOv1版本中,x,y,w,h是直接预测物体实际值,预测值的微小变化都会被放大到整个图像的范围,导致坐标波动较大,预测不准确.YOLOv2对其进行了改进,其公式为:


其中,tx,ty为网络预测值,经过Sigmoid运算将其缩放到0和1之间,tw,th也为网络预测值,无需Sigmoid;cx,cy为cell坐标,也就是距离左上角的偏移量;pw,ph代表该cell对应anchor box的宽高,计算出bounding box的位置,如图3所示.通过对confidence这一项设定阈值,过滤掉低分的预测框,然后对剩下的预测框执行非极大值抑制(Non Maximum Suppression,NMS)处理,得到网络最终的预测结果.
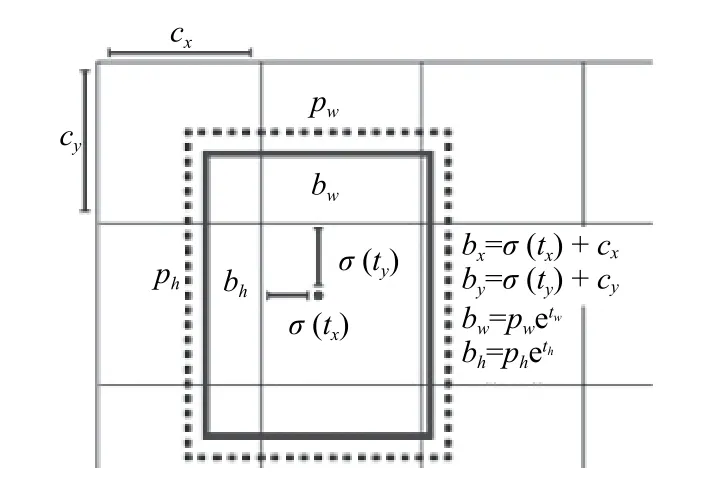
图3 YOLOv3的bounding box坐标转换公式
1.2 损失函数
对于YOLOv3的损失函数,Redmon J在论文中并没有进行讲解,本文作者根据对Darknet,也就是Redmon J实现YOLOv3网络的平台的源代码进行解读,总结出YOLOv3网络的损失函数为:

其主要分为三大部分,坐标损失,置信度损失及分类损失,λobj在该cell存在物体时为1,其他cell为0,且均采用SSE计算,最终Loss采用和的形式而不是平均Loss,主要原因为预测的特殊机制,造成正负样本比巨大,尤其是置信度损失部分,以一片包含一个目标为例,置信度部分的正负样本比可以高达1:10646,如果采用平均损失,会使损失趋近于0,网络预测变为全零,失去预测能力.并且,根据作者描述,Lin TY等提出的,用于解决正负样本不均衡,使得网络专注于困难样本计算的Focal Loss无法解决这个问题,会导致mAP下降.
2 模型训练与改进
2.1 Anchor参数设定
PASCAL VOC数据集是目标分类、检测等常用的数据集,通过模型在VOC2007 test部分的表现衡量目标检测模型的性能已经成为常用的验证方法,在实际训练过程中,一般使用VOC2012的全部样本及VOC2007的train及val部分样本作为训练集,VOC2007 test部分作为测试集,本文也是如此.训练集部分包含图片16 551张,物体40 058个,测试集包含图片4952张,物体12 032个.根据标签数据,对训练集的物体宽高进行分析,其分布情况如图4所示,可以发现VOC数据集中较小目标占比较大.
作为聚类算法的一种,K-means具备简洁快速,易于实现的优点,应用非常广泛,其基本思想是以空间中K个点作为形心,将最靠近他们的点进行归类,然后迭代更新这K个点的值,直到K个值不再变化或达到最大迭代次数.本文使用K-means算法对VOC数据集进行分析,结果如图5,纵坐标表示平均畸变程度,越小说明类内距离越小,根据肘部法则选择K值为9,并确定相应的anchor box.

图4 VOC物体宽高分布情况,大点为聚类结果

图5 K-means聚类分析结果
2.2 损失函数分析
作为深度神经网络对误检测样本进行惩罚的根据,损失函数可以在很大程度上影响模型收敛的效果,如何设计更合适的损失函数以获得更好地预测效果也成为模型优化的重要方向,学界对此也进行了很多研究[12,13].在YOLOv3网络的最终输出中,x,y,物体置信度以及类别置信度部分均经过Sigmoid函数激活,然后采用SSE计算最终损失,从Sigmoid函数的导数图像(图6)可以看到,当神经网络的输出较大时,(x)会变得非常小,此时使用平方误差得到的误差值很小,导致网络收敛很慢,出现误差越大收敛越慢,也就是梯度消失的情况,为了解决这个问题,当真实值只能取0或1时,一个常用的方法是采用交叉熵(cross-entropy)损失函数,其形式为:
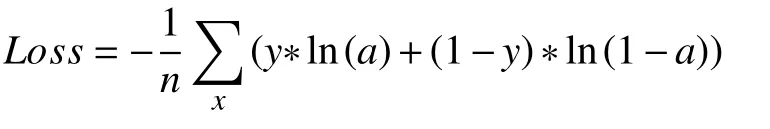
a代表神经网络经过Sigmoid以后的输出值,也就是a=σ(ωx+b),令z=ωx+b,可以计算出交叉熵函数的导数.


图6 Sigmoid函数及其导数
特别的,对于predx和predy的输出,它们的真实值并不是0或1,而是0和1之间的某个值,也就是说predx,predy并不是离散变量,以truthx=predx=0.7为例,交叉熵损失为 -0.7 ln(0.7)-0.3 ln(0.3)≈0.61,不为0,所以不能采用交叉熵损失函数.
通过以上分析可知,损失函数的导数形式f(x)需要具备以下性质: ①f(x)的定义域为x2(-1,1),值域f(x)2(-1,1);②f(x)为 单调递增函数,且f(0)=0;③f(x)的 图像需要关于坐标原点对称;④(x)≠0.因此,本文设计了一种新的损失函数,称为tan方损失(Tan-Squared Error,TSE),导数形式为LossGrad=tan(t-σ(z))/tan(1),在YOLOv3中,t-σ(z)2(-1,1),由于t也是不定项,此差值与σ(z)本 身的取值无关,令x=t-σ(z),作出 函数图像如图7.

图7 TSE与SSE导数图像
在本网络的训练过程中,由于极其巨大的正负样本比,训练开始时会难以避免地出现网络输出全零的情况,此时负样本部分,也就是真实值为0的部分,其误差逼近于0,而真实值为1的部分,误差则非常的大,对于predx和predy来说,差值更是为(-1,1),而不是常见的(0,1),作者采用平方损失进行计算,并且是定义了梯度值的计算方法,也就是直接使用公式grad=tx-predx进行梯度计算,这也正是平方损失函数的导数形式,遵循同样的思路,本文定义了TSE导数形式的计算公式,通过TSE与SSE的图像(图7)可以直观地看出,TSE与SSE导数的值域均为(-1,1),并且TSE导数的绝对值要小于SSE,也就是说对于较大的误差,可以将它进行适当地缩小,这样当梯度传播到Sigmoid函数时,可以使小幅度地增大,加快初始时的收敛速度,减小梯度消失的影响;同样的,对于误差已经逼近0的情况,由于TSE要略微小于SSE,可以使输出层权重的调整幅度更小,使模型得到更好收敛.这种调整也应该控制在一个较小的幅度,防止对输出层的权重作出过大的调整,导致模型不收敛或者发散的情形.对两函数求导,得到他们的导数图像如图8.
可以看到,TSE导数的值域约为(-2.2,2.2),即使误差极大导数也在有限范围内,并且最小值约为0.64,不会出现梯度为0从而导致梯度消失.不同于SSE的常数梯度值,TSE的梯度会随着误差的变化而变化,具有误差大时梯度大,误差小时梯度小的性质,既能在误差较大时加大权重的调整,也在误差减小以后,以更小的变化率调整权重,使网络模型可以收敛得更好,这是对 于连续变量predx和predyTSE所具有的优势.

图8 TSE与SSE导数的梯度变化
2.3 调整幅度验证
对预测损失值的大小进行控制可以增强反向传播时卷积层权重调整的效果,TSE控制梯度变化的幅度是否合适也需要验证.将TSE与梯度调整幅度更大的损失函数进行对比,其导数形式为:
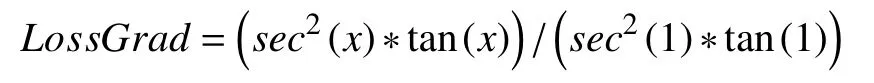
从它与TSE的对比图像如图9.
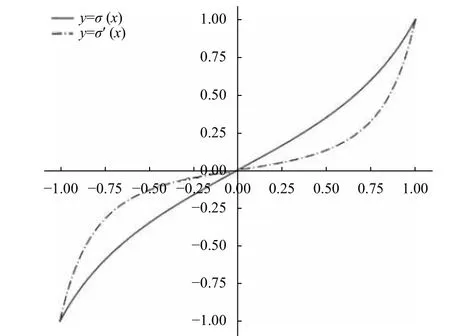
图9 TSE与另一函数对比
从图9可以看出: 该函数在训练的初期可以对损失进行更大幅度的调整,理论上来讲可以更大程度地减少梯度消失的情况,使得预测层梯度保持在一个较大的数值.在实际的实验过程中,训练的初始阶段Loss下降得非常快,正样本的置信度上升速度也加快了很多,但是由于误差靠近0时梯度的过度减小,负样本的置信度未能得到有效下降,训练后期梯度消失的现象也导致正负样本没有被很好地区分开,模型收敛效果变差,最终的mAP很低;而且由于采用较大的学习率,训练中也出现了预测值变为Nan的情况,说明过大的调整幅度也可能导致梯度发散.
3 实验结果
在Pascal VOC数据集上进行实验,使用两块1080TI的显卡,显存为2×12 GB,CPU为Intel Xeon E5-2620 V4@2.10 GHz,软件环境为cuda9.0 + cudnn7,训练集为VOC07+12,测试集为07 test-dev,由于作者并未公布相关的mAP数据,本文直接使用作者提供的训练配置文件进行训练,总计训练了50 000个batch,除了更换损失函数和修改anchor box外不作其他改动,结果如表1所示.

表1 VOC数据集训练结果
由于本实验的主要目的是验证TSE的有效性,作者并没有对训练时的超参数进行仔细调参,不保证该mAP一定为YOLOv3网络模型在VOC数据集上可以达到的最高值.通过最终的mAP值可以表明,只是改用TSE就可以得到1个百分点左右的提升,TSE可以使网络获得更好地收敛效果.
为了验证TSE相比于SSE在收敛速度方面所获得的优势,采取每10 000个batch保存一次模型的方式,收集了5个阶段的mAP数据,如图9所示,可以看出,在训练10 000个batch时,TSE就可以比SSE取得更高的mAP值,并且在30 000个batch时mAP就达到了SSE训练40 000个batch的水平,说明使用TSE可以使网络收敛得更加快速.当训练40 000个batch以后,学习率被减少为原来的1/10,模型进一步收敛,mAP获得了比较大的提升,并且受益于TSE的函数性质,模型获得了1个百分点左右的mAP提升.

图10 三种方法训练的mAP
4 总结与展望
4.1 本文工作总结
本文分析了YOLOv3模型的结构,并且对它实际的训练应用过程做出了有益尝试.通过对原版损失函数特点的分析,提出了一种新的损失函数TSE,在VOC数据集上的实验结果表明: ① 与SSE相比,TSE适用于连续变量的情况,减少了梯度消失的情况,mAP稳步提升;② 模型的收敛速度得到提升,能够使训练所需轮数减少,节省训练所需时间;③ 对比实验表明TSE进行梯度调整的幅度比较合适,可以在保证正负样本区分度的基础上有效增强正样本的置信度.基于改进损失函数的网络模型取得1个百分点左右的mAP提升,获得了更好的检测效果.
目前,YOLO系列网络由于其检测快速的优点,已经在实际生产中获得了大量应用.如郑志强等将YOLO网络应用于遥感图像的飞机识别[14],王福建等将YOLO网络应用于车辆信息的快速检测[15],蔡成涛等基于YOLO网络实现机场跑道目标的快速检测[16],都取得了非常好的效果,本文提出的方法适用面广,通用性强,可以很好地应用于现有的YOLO检测系统中,获得更为准确的检测效果,使系统性能获得进一步增强.
4.2 未来工作展望
本文从损失函数的角度,提出了现有网络的改进方法.在下一步的研究工作中,将会在更多其他的网络模型中,采用更大规模的数据集如MSCOCO[17]等,用以验证TSE的通用性与鲁棒性;同时也对连续变量的梯度控制问题,寻求更好的解决方案;另外,针对于网络结构本身的改进,如何设计出性能更强的网络来提取图像特征,也需要更加细致地研究.

图11 检测结果示例
