Openstack平台资源负载预测方法研究∗
2019-03-27蔡全旺王庆年
黄 秀 蔡全旺 王庆年
(中国船舶重工集团公司第七二二研究所 武汉 430205)
1 引言
云计算以即付即用的方式为人们提供了弹性的计算资源,引发了信息通信技术产业的彻底变革。然而云平台中的资源一般是静态配置,在大多数的实际应用中无法最大限度地充分利用资源。火狐的数据中心经理德里克(Derek Moore)指出,Mozilla的数据中心服务器CPU利用率在大部分情况下处在6%~10%,这无疑是巨大的浪费。因此,物理服务器上某些资源使用超过限定阈值时,将一些虚拟机迁移到其他物理机上,以保证服务质量,降低负载;在资源利用率低于限定阈值时,将虚拟机集中迁移到一个物理机上,关闭闲置的物理机,实现节能。
Openstack作为一个开源的云计算工具,已经被许多大型的软件公司,诸如IBM,Rackspace所采用。在Openstack中,资源调度主要分为三步:主机过滤、权值计算、主机选择,具体的虚拟机分配由nova-scheduler模块负责,但这只是一种静态的资源分配,虚拟机在初始调动后就不再迁移,实际资源利用率低下,因此我们需要一种动态的调度算法来补充现有算法的不足,提高资源利用率,降低能耗。
本文研究的动态调度算法重点在负载预测算法的研究上,主要是:采用预测算法预测未来下一时刻系统的负载,以便调度系统能够提前做好资源调度准备。
2 相关研究
2.1 负载预测技术
常见的负载预测算法包括时间序列预测[1]、灰色预测、BP神经网络预测和其他预测算法,许多研究人员在上述各领域纷纷提出了自己的预测算法。李丹程等[2]利用回归分析方法,预测云计算环境下服务器负载情况的变化,提出了资源动态调度算法,将计算任务迁移到更合适的服务器,达到提高集群计算能效目的。Beloglazov等[3]则在主机过载检测中采用局部回归算法对CPU的利用率进行预测,将预测值与门限值进行比较,从而做出是否需要对虚拟机进行调度的决策。灰色预测是一种对含有不确定因素的系统进行预测的方法[4],当预测序列具有指数增长特性时才能凸显该模型的作用。Li等[5]则使用的是BP神经网络模型,将虚拟机的负载信息作为输入来预测服务响应时间,然后预测的服务响应时间就可以被当做动态调度策略的基础来进行虚拟机的调度。马尧等[6]在他们的预测算法中采用分形插值方法对Openstack中资源负载情况进行预测,以对虚拟机运行调度提供参考,进而达到提高集群计算效能的目的。Kusic等[7]提出了一种有限预测控制作为资源调度的解决方案,作者使用一个Kalman滤波器来预测未来负载。Herbst等[8]在他们的文章中提出了一种基于决策树的自适应方法,该方法可以根据一个给定的上下文选择合适的预测方式。物理机的负载值是随时间变化的,因此本文采用时间序列预测法作为负载预测的模型。
2.2 Openstack云平台简介
Openstack是现今最活跃的开源项目之一,它采用模块化设计,主要由 Keystone,Glance,Hori⁃zon,Nova,Swift,Cinder,Neutron等7个模块构成[9]。Keystone是认证管理组件,提供了其余所有组件的认证信息的管理,创建和修改;Glance负责镜像管理,提供了对虚拟机部署时所需的镜像的管理;Ho⁃rizon是仪表盘组件,提供了以web的形式对所有节点的所有服务的管理;Nova主要负责虚拟机的生命周期,提供虚拟机的创建,销毁,迁移,快照等服务;Swift是对象存储服务组件;Cinder是块存储组件;Neutron是网络服务组件,负责集群网络及租户网络的管理。Openstack组件主要通过Restful Api进行信息的交互,内部组件则通过AMQP进行信息交换[10]。
3 负载预测算法研究
3.1 预测模型选取
预测模块最主要的目标就是预测未来某时刻的工作负载,然后根据用户定义的伸缩策略进行调整。在这其中涉及到两个重要的问题,一个是数据,另一个就是预测方法。Chen等[11]在他们的文章中就对几种时间序列预测方法进行了比较,主要是自回归移动平均模型(ARMA),自回归模型(AR),指数平滑模型(ES),自适应指数平滑模型(TAES),移动平均模型(MA)的比较。表1是它们的比较结果。
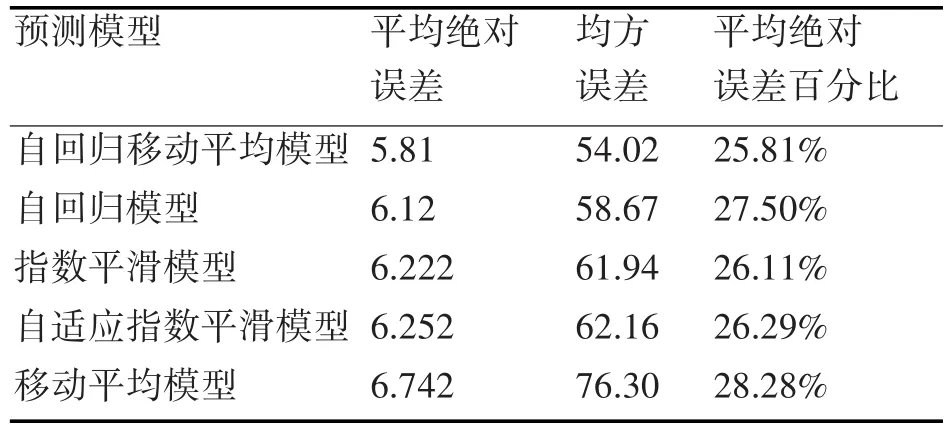
表1 不同预测模型的比较
从表中可以看出,ARMA,AR及ES模型是表现最好的三个,ARMA模型效果是最佳的,但其算法相对其他两个而言很复杂,计算量也比较大,在实际运行时可能会占用一部分的计算资源。故本文根据此文献的研究结果选择了一次指数模型作为此次的预测模型。一次指数平滑的预测计算公式为
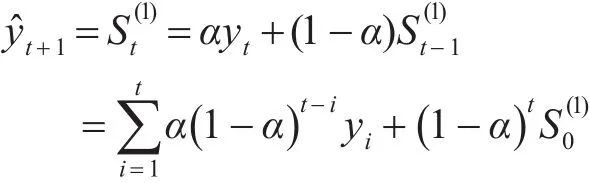
一次平滑值,yt是t期的实际观测值,t+1是t+1期的预测值,α是加权系数,取值范围为0<α<1。当数据样本的个数大于15项时,一次平滑初值一般就取为样本初值;若小于15项,则一般取样本前三项的平均值。
3.2 权系数的动态选取
从上述的一次指数平滑公式可以看出,权系数α是固定不变的,很显然当系统数据波动较大时,α极有可能并不是此时的最优系数,从而预测的准确度也会受到影响,因此如何动态地选取最优的权系数成为了关键。
文献[12]中运用数学推导的方式导出了一种动态的指数平滑模型,它是将传统的指数平滑模型的系数进行了归一化处理。我们将一次指数平滑的公式进一步展开如下:
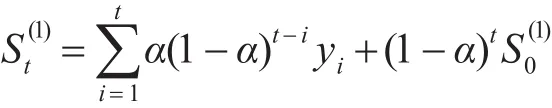
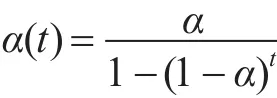
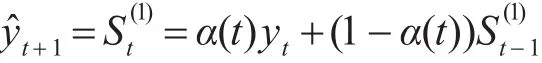
上式呈现的动态预测公式中,α(t)的最终取值结果也是依靠静态的α的选取,一般情况下,α根据人们的经验来取值,这无疑也会影响到预测的准确度,因此我们需要将静态的α选取变为动态的。
本文中,我们采用预测值与观测值的误差平方和SSE最小作为衡量α值是否为最优的标准,也即
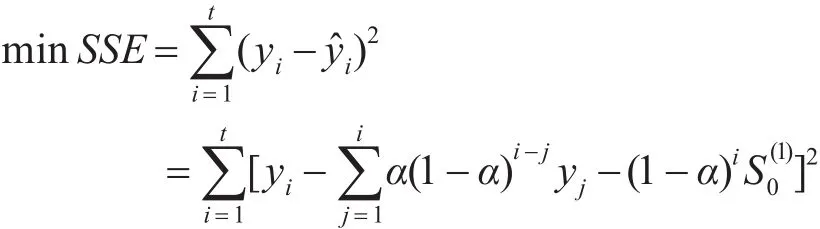
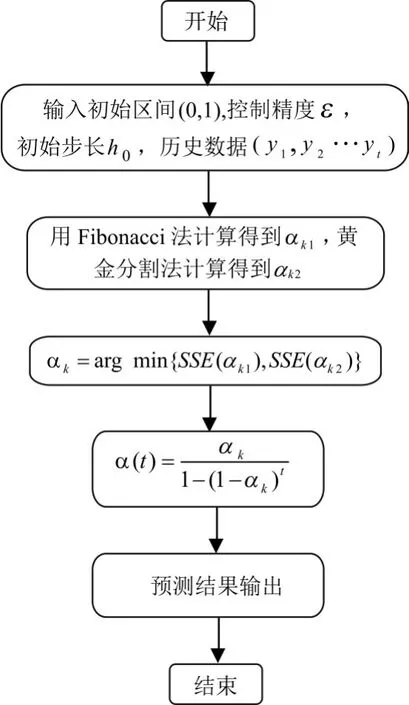
图1 预测算法流程图
通过采用两种一维搜索算法,即Fibonacci法和黄金分割法以获得最优系数,分别计算采用Fi⁃bonacci法时获得的系数αk1和采用黄金分割法获得的系数αk2,然后比较SSE(αk1)和SSE(αk2),取αk=arg min{SSE(αk1),SSE(αk2)},Fibonacci法和黄金分割法的伪代码如Algorithm1和Algorithm2所示。
取得最优系数后,就可以代入归一化公式中中,求出归一化后的权系数,进行预测。
预测算法描述如图1所示。
Algorithm1 Fibonacci
输入:初始区间[a1,b1],最终长度L
输出:极小值点x_opt
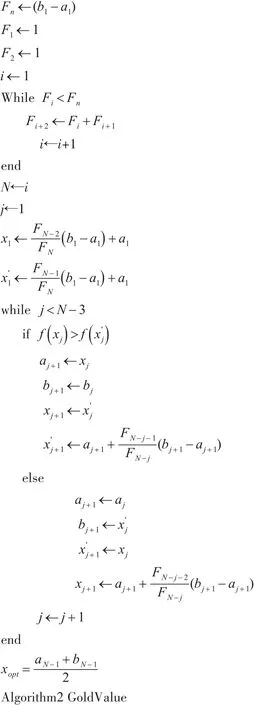
输入:初始区间[a1,b1],精度tol,函数f
输出:极小值点xopt
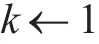
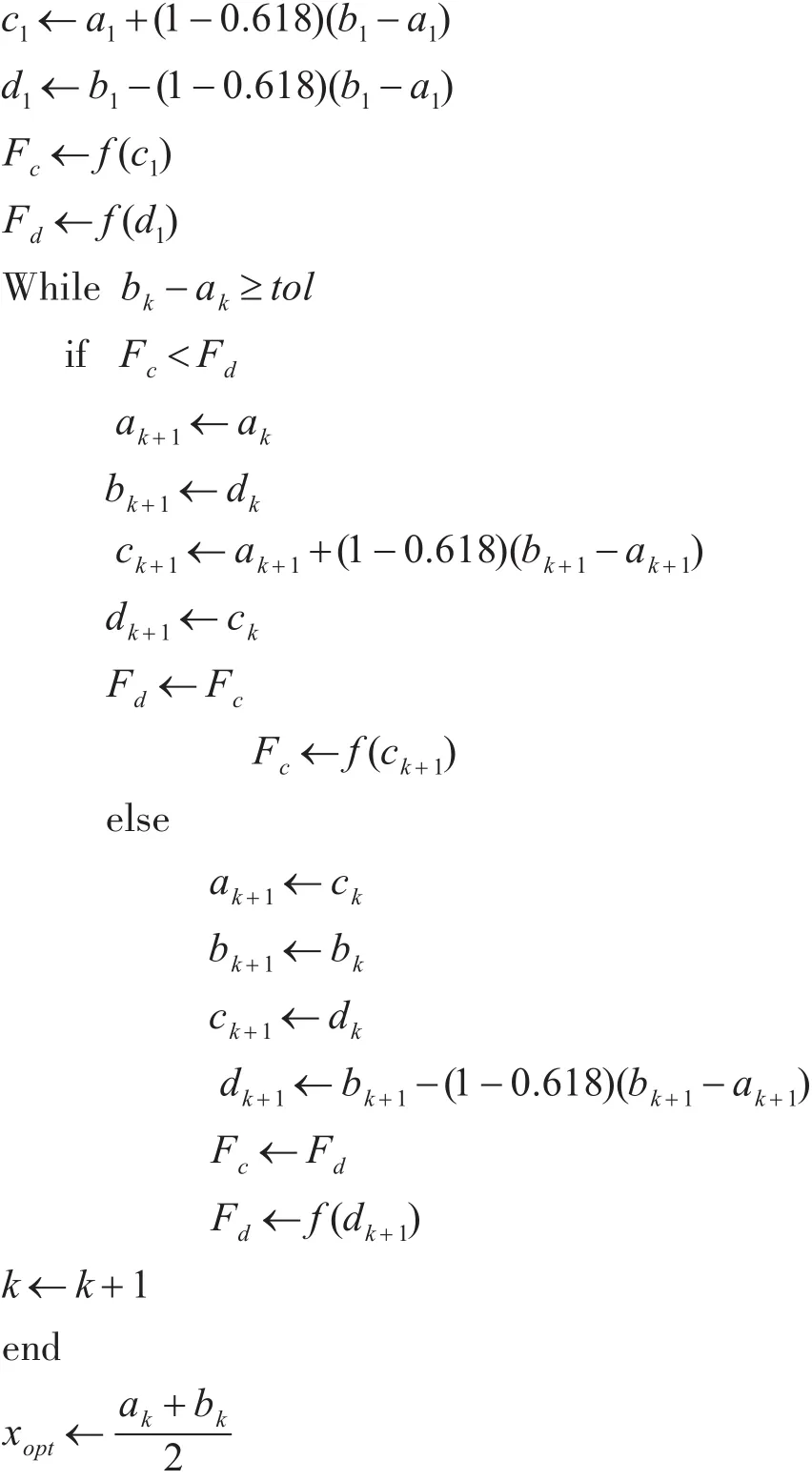
综合来看,本文提出的算法是先由两种搜索算法搜索出最佳的权系数,这一点相对于传统的指数平滑法来说有进步之处。传统的指数平滑法是根据经验判断法或试算法来选定权系数,这两种方法很容易受到主观影响,从而干扰到实际应用中的预测精度;另一方面,其他的预测模型,如回归模型,移动平均模型等在实际使用中是相对固定的,模型不能够依据负载实际的变化情况而进行动态的调整,这就容易出现预测结果不够准确。由于本文对权系数进行归一化,权系数成为了时间的函数,随着时间的推移,权系数也在不断变化,预测模型也可以说是在动态变化,很好地迎合了负载在动态变化这一特点。
4 基于Openstack的负载预测实现
在Openstack中实现负载预测分两步进行:数据采集,负载预测,数据采集模块为预测模块提供物理机中各项资源的历史数据。由于本文采用的实验环境是all-in-one的,数据采集模块和预测模块位于同一个物理节点。本文主要采用Openstack中的Ceilometer项目来进行资源的监控,进而为预测模块提供数据,预测模块则采用上述的动态一次指数平滑模型来实现。
4.1 数据采集功能实现
Ceilometer采用两方式来采集信息,一种是通过Notification agent监听系统中的Message Queues主动消费Openstack内各个服务自动发出的Notifi⁃cation消息,另一种是通过Polling agent周期性调用各个服务的API去主动轮询获取数据。图2是Ceilometer采集信息的架构图[13]。Compute Volume Network Image Object Storage
图2 Ceilometer信息采集架构图
由于本文需要的是物理机的CPU利用率等数据信息,这些信息不会通过Notification来发出,故我们采用第二种方式来获取信息。Ceilome⁃ter-agent-central组件是Polling agent中的一种,它可以通过snmp协议直接收集物理机的CPU、MEM、IO等信息,与此同时还需要对Ceilometer增加一些额外的配置,由于增加的配置原理基本相同,这里我们以采集物理机CPU信息为例。
首先需要在物理机上安装snmp和snmp包,然后修改配置文件snmpd.conf:
agentAddress udp:192.168.0.108:161
view systemonly include.1
重启snmp服务后,在Ceilometer的pipeline.yaml文件中加入以下信息(也可以根据自己的需求配置):

重启Ceilometer服务后,就可以通过相关命令查询到新增的监控项和监控数据。
4.2 预测功能实现
在设计负载预测模块时,主要是通过调用Ceil⁃ometer的API读取存数据库中的数据,然后将数据进行预处理后传入到预测模块。
详细流程如下:
1)调用Ceilometer提供的REST API获取物理机的监控数据。
2)Pre-process对数据进行预处理,剔除偏差过大的数据。
3)根据负载的历史数据调用实现的动态一次指数预测算法预测负载的变化规律。
图3是本文设计的一个系统的预测架构图。
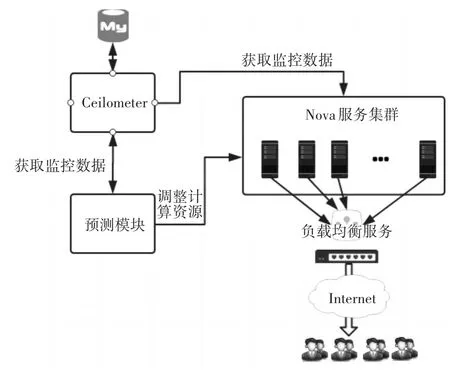
图3 系统预测架构图
5 实验结果及分析
在本次实现中采用了Webbench作为本文的并发测试工具,Webbench最多可以模拟3万个并发连接去测试网站的负载能力。测试的硬件环境为all-in-one,使用的服务器的硬件配置为Intel Xeon 6核CPU,内存容量为8G,硬盘容量为2TB。在这台物理服务器上部署了Openstack Queens版本的云平台环境,在Openstack中部署的虚拟机集群配置如表2。

表2 虚拟机配置
各虚拟机服务器之间通过HAProxy负载均衡器来分发Webbench产生的负载,HAProxy配置中使用了负载均衡算法时roundrobin。由于条件有限,故Haproxy在flavor类型为ds2G的一台虚拟机中进行配置。实验架构如图4所示。
本文主要考虑了在负载突然增大的情况下,对宿主机CPU利用率的预测情况,实验通过Ceilome⁃ter监控模块获取使用Webbench模拟的在负载增大并维持一段时间宿主机的资源利用率情况,预测资源的利用率。

图4 实验环境中的虚拟机配置
在实验过程中,利用Webbench增大模拟用户数,模拟真实系统环境下负载增大时资源需求的变化,监控系统每3分钟采集一次信息,通过监控系统获取90分钟内的宿主机资源数据,主要是CPU的利用率信息,实验中利用这90分钟内的数据计算出预测值。在实际的测试中,Fibonacci取得的最优系数是0.875,而黄金分割法计算得出的最优系数是 0.95,经过计算,SSE(0.875)=0.09663,SSE(0.95)=0.03448。当权系数α取值为0.95时,CPU利用率的预测结果如图5所示。
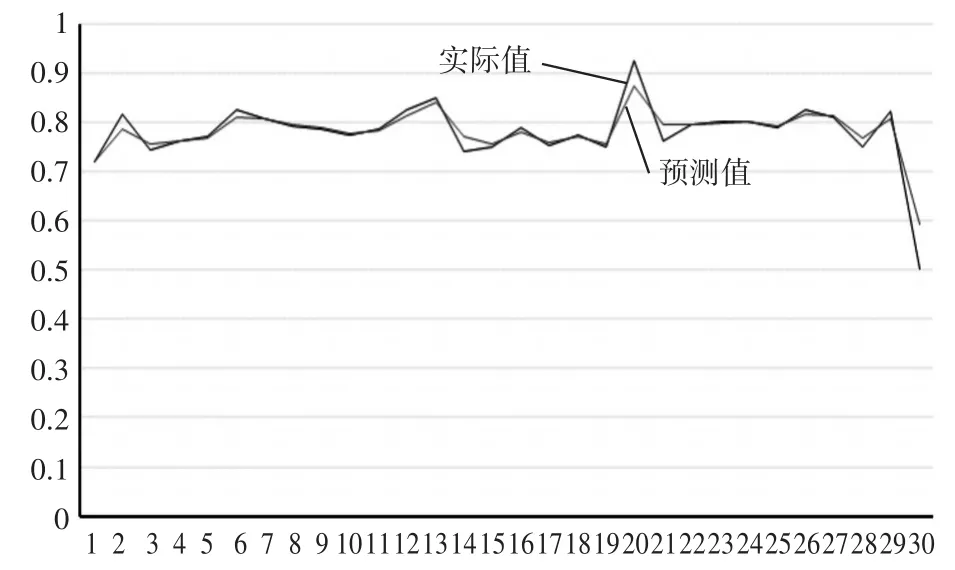
图5 CPU利用率实际值与预测值
我们可以看到,动态自适应的一次指数平滑模型很好地拟合了数据未来走势,预测精度也比较高,因此在实际的资源调度的方案设计中具有很高的实用性,计算也不太复杂。但此次实验也存在着不足,从上面的实验过程我们可以看到,权系数α是分别采用Fibonacci法和黄金分割法计算误差平方和后比较的出来的,当历史数据增长到一定长度时,计算会变得复杂,这样一来反而使预测的目的处于次要地位,因此如何适当地选取数据,设计恰当的时间窗口,使得计算量合适,预测精度又比较准确是下一步的研究工作。
6 结语
本文在一次指数预测模型的基础上进行了改进,提出了利用Fibonacci法和黄金分割法来确定最优权系数,从而避免了人工设置权系数带来的计算偏差,并在Openstack平台中进行了实验验证和结果分析,但正如分析部分所阐述的,在选取合适的数据,设计恰当的时间窗口等方面还有许多要改进的地方。
