基于FPGA的极化码半平行CA-SCL译码器设计∗
2019-03-27王美芹仰枫帆赵春丽
王美芹 仰枫帆 赵春丽
(南京航空航天大学电子信息工程学院 南京 211106)
1 引言
极化码[1]是在2007年由土耳其教授Erdal Ari⁃kan首次提出的一种基于信道极化现象[2]的信道编码,并且其被当作是目前唯一可被证明能达到香农极限[3]的信道编码,且具有较低的复杂度,因此极化码的研究在学术界掀起了一股热潮。随后,学者对SC译码算法做进一步改进,提出了SCL译码算法[4~6],极大地提升了译码性能。尤其是在2013年,由 Niu.K,K.Chen提出的 CA-SCL译码算法[7~8],其获得了优于最大似然算法[9]的性能。与此同时,众多学者也研究了极化码的工程上实现。在众多的SC译码结构[10~13]的基础上,Leroux等设计了半平行结构[14],其以牺牲较小的吞吐量为代价,大幅度的降低了系统复杂度,并具有较小的时延。在本文中,通过对CA-SCL[15]的半平行译码结构的研究分析,提高了硬件吞吐量的同时,又降低了译码的时延,使得硬件资源复用和内部结构优化。
2 极化码
Arika在研究信道的组合和拆分[16]过程中发现,在将N个相互独立的信道进行组合和拆分后,系统的总体容量没有发生改变,而总体截止速率得到了提升。因此,Arikan将N个相互的完全相同的二进制离散无记忆(B-DMC)信道通过组合并为信道WN,并将WN拆分为N个相关子信道,随着N的不断变大,其子信道容量趋向0或1两个极端,这即为信道极化现象。通常情况下,我们将信道容量趋向于1的子信道用来传送信息比特,而信道容量趋向于0的子信道用来传送收发双方均已知的固定比特,其默认值为0。
如何挑选信道非常重要,在学者们不断研究中涌现许多高性能的信道挑选方法[17~19]。Arikan 指出,通常情况下对于任意信道都可以使用BEC信道下的信道挑选方法而不会产生较大的性能损失,通常令初始信道容量为,使用式(1)迭代公式进行信道挑选:
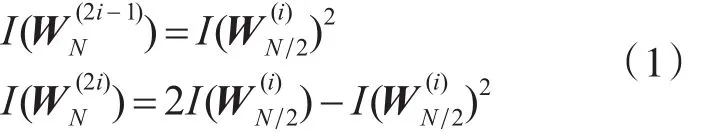
且极化码编码的码率可以调节任意K/N,其中0≤K≤N编码块长度N的大小为2n,任意给定一个N,使用式(2)对信息比特进行编码:
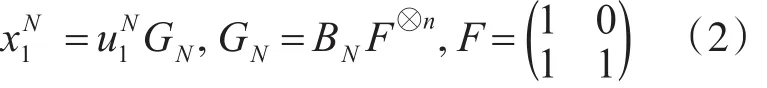
3 CA-SCL译码算法
CA-SCL译码算法是极化码的SCL译码算法的基础上添加CRC校验位,以较少的码率为代价来获取最高的性能。此算法是迄今为止性能最佳的一种极化码译码算法,并且具有较低的译码复杂度能。
3.1 SCL译码算法
SCL译码算法的基本思想是在极化码的译码树上,按照后验概率最大原则寻找最合适路径得到译码序列。假定极化码的码长为N,译码树中的每个节点代表一个比特,第i层中共有2i-1个节点,表示给定所有可能值的情况下比特ui的取值结果。在树的每一层,根据式(3)计算每条路径的路径度量值的大小,然后进行路径的排序、选择和淘汰,最后选择路径度量值最大的路径作为最后的译码结果。L为路径的搜索列表宽度,当路径数大于L时,每层保留L条后,下一层延伸时总是需要计算2L个路径的度量值。

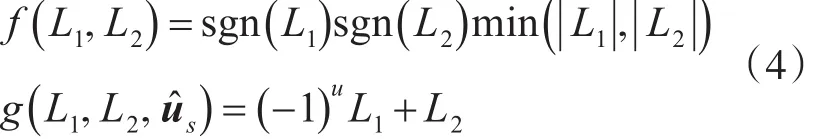
3.2 CRC校验
这里将加入CRC校验码后的极化码详细编译码描绘如图1所示。

图1 极化码的CA-SCL译码框图
如图1所示,在本算法中,在输入信息位为k比特,添加m位CRC码的编码器中,使得输入为K=k+m比特,对此K比特的信息位进行极化码编码,可以得到N位信道输入,经过信道传输后送入CA-SCL译码器进行译码。当SCL译码器译出L个候选序列之后,将此L个序列所对应的路径度量值以由大到小的顺序进行排序,并按照这个顺序进入解CRC码单元。当译出的序列不满足CRC的关系时,此单元将会通过SCL译码器继续传送到下一个序列。就这样直到输入解CRC码单元的序列通过CRC校验,译码结束后,解除CRC校验码,CA-SCL译码器译出的码字就是最后得到的输出序列。
4 半并行硬件译码结构
在硬件实现上,经典SC译码单元有几种典型的译码结构,比如树形结构、线性结构、半平行结构。下面详细介绍本文所采用的半平行结构。
图2为N=8时的SC译码FFT结构,该结构是CA-SCL译码结构的基础。其蝶形算法可应用于硬件实现的“从右往左”蝶形算法。从信道层开始,按照顺序依次计算节点的LLR值并存储在起来作为中间LLR供后面计算调用,避免了在硬件中进行递归调用,同时能达到与递归算法相同的复杂度,如图2中加粗线条为一比特计算过程。
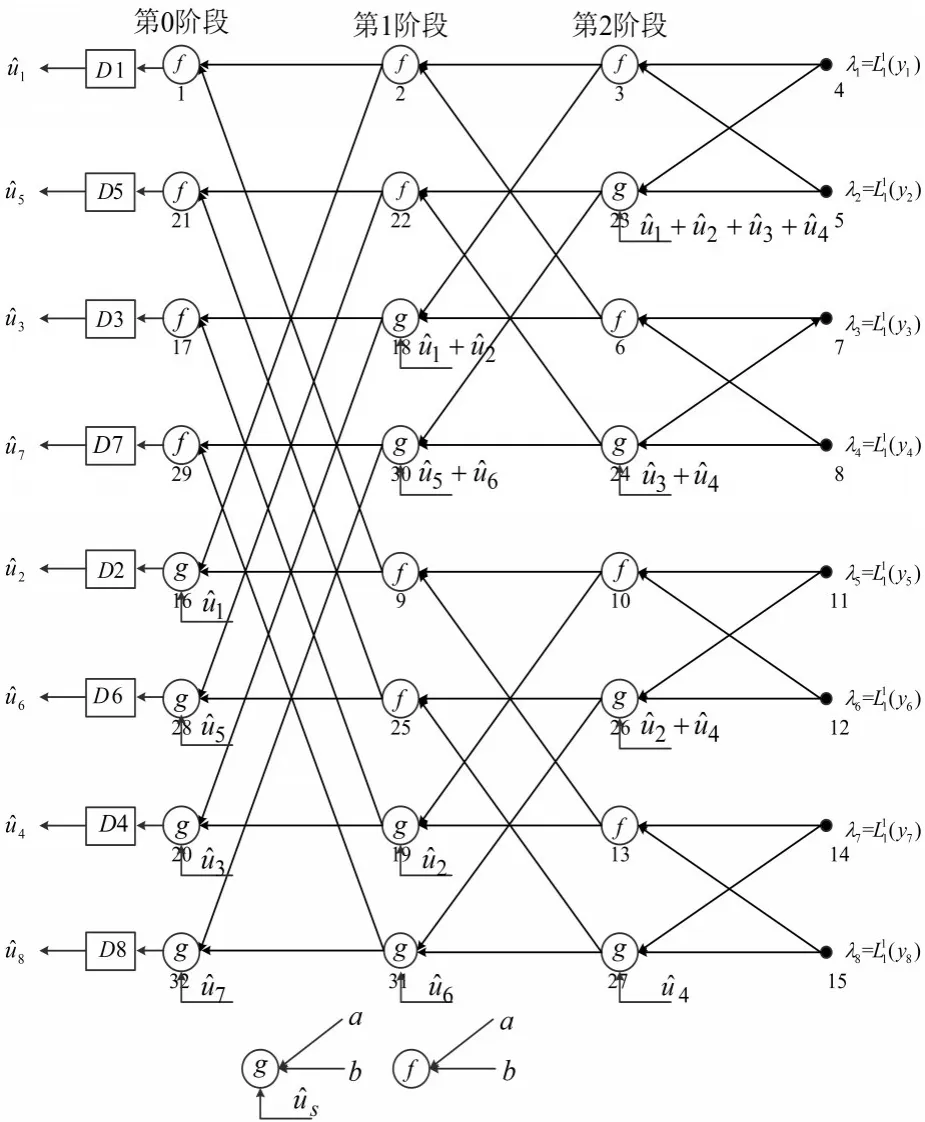
图2 基于蝶形图的典型FFT结构
从图2可以发现,无论第l阶段的节点在何时被激活,实际上在该阶段都只有2m-l-1个节点的值得到更新或被下一阶段所使用。我们将f函数和g函数通过复用器融合为一个计算单元(Process Element,PE),通过状态控制来指示当前使用的函数为f函数还是g函数。在保证译码结构具有较低的硬件复杂度的同时,还需要尽可能地减少PE的数量,以降低资源利用率。因此,Leroux等提出了SC译码的半平行结构,能够以较小的时延大幅降低硬件复杂度,是目前较为优秀的硬件实现架构。
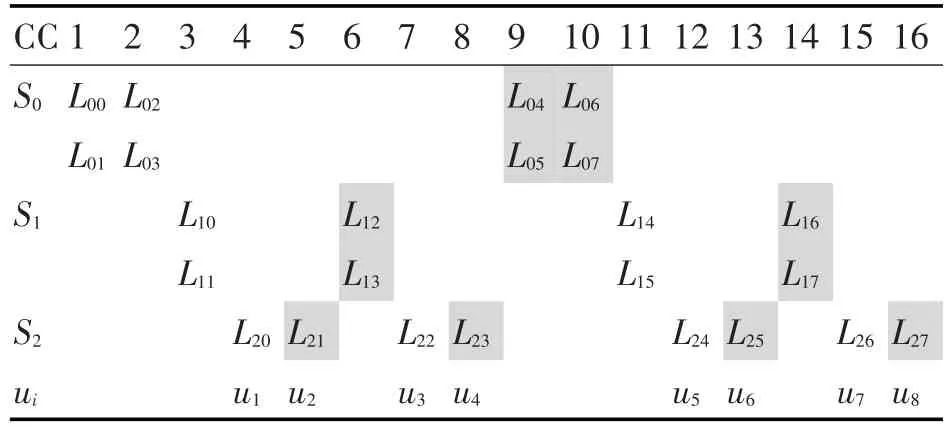
表1 半平行译码结构时序表
如表1所示,以码长N=8的SC译码为例,在半平行结构中只使用了2(N4)个PE,整个译码周期中PE单元基本上都同时工作,使得利用率高,实现资源占用率低。
若PE结构数量为P,则半平行译码结构的时延周期为
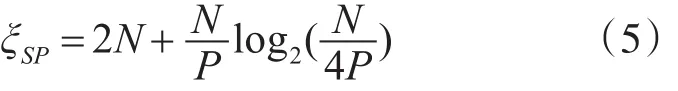
另外,半平行结构译码器的利用率为

相较于全平行的译码结构,半平行结构的译码速度因子为
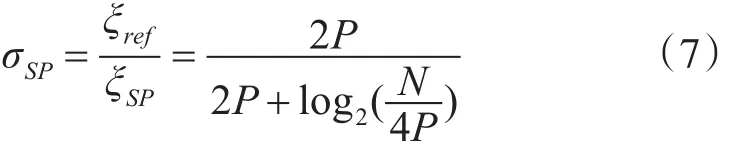
对于CA-SCL译码算法,若L为列表宽度,那么总的PE单元数量为LP。
5 CA-SCL译码器硬件结构设计
5.1 译码器整体结构设计
在本次的译码器设计中,设置条件为码长N=1024,码率是R=1/2,信道挑选方法为BEC方法,列表宽度L=32,采用LTE协议建议的24位CRC检验码,其生成多项式为对译码器中的数据进行8比特量化,路径度量值进行12比特量化。对译码过程中发生的溢出采用截断处理,使得位宽不会逐级递增,在仅有较小性能损失的情况下,就可大大简化了译码器的设计复杂度。
如图3所示,整体译码结构主要包括以下几个顶层模块:LLR计算模块(LLR_top)、修正模块(Corrected)、度量值计算模块(Metric_top)、排序模块(Sort_top)、反馈模块(Feedback)、控制模块(Con⁃troller)、路径恢复模块(Path_recover)、CRC串行译码模块(CRC)等。
在实现半平行结构译码开始之前,要解决的是LLR存储结构问题。先将信道LLR分组,存入位宽为64,深度为256的RAM中作为初始LLR,即图中的LLR_based RAM。
5.2 LLR存储结构
对于码长为N的极化码,信道输出序列经过计算得到N个信道LLR。本文选定量化宽度为,所以总存储单元大小为,而对于总体结构一个时钟下必须有2P个输入LLR以及P个输出LLR,对于LLR存储模块,以为一组,记为一个存储单元,其中每比特为一组PE结构的两个输入信道LLR,单时钟读入一个存储单元作为所有P个PE结构的输入,全部存储深度为N/2P。据此分析,在时钟和读地址的控制下,读完全部的数据需要N/2P个时钟周期。由前面的分析可知,无论码长和码率为多少,初始LLR在整个译码的过程中仅被使用两次,即该RAM将仅被读取两次。
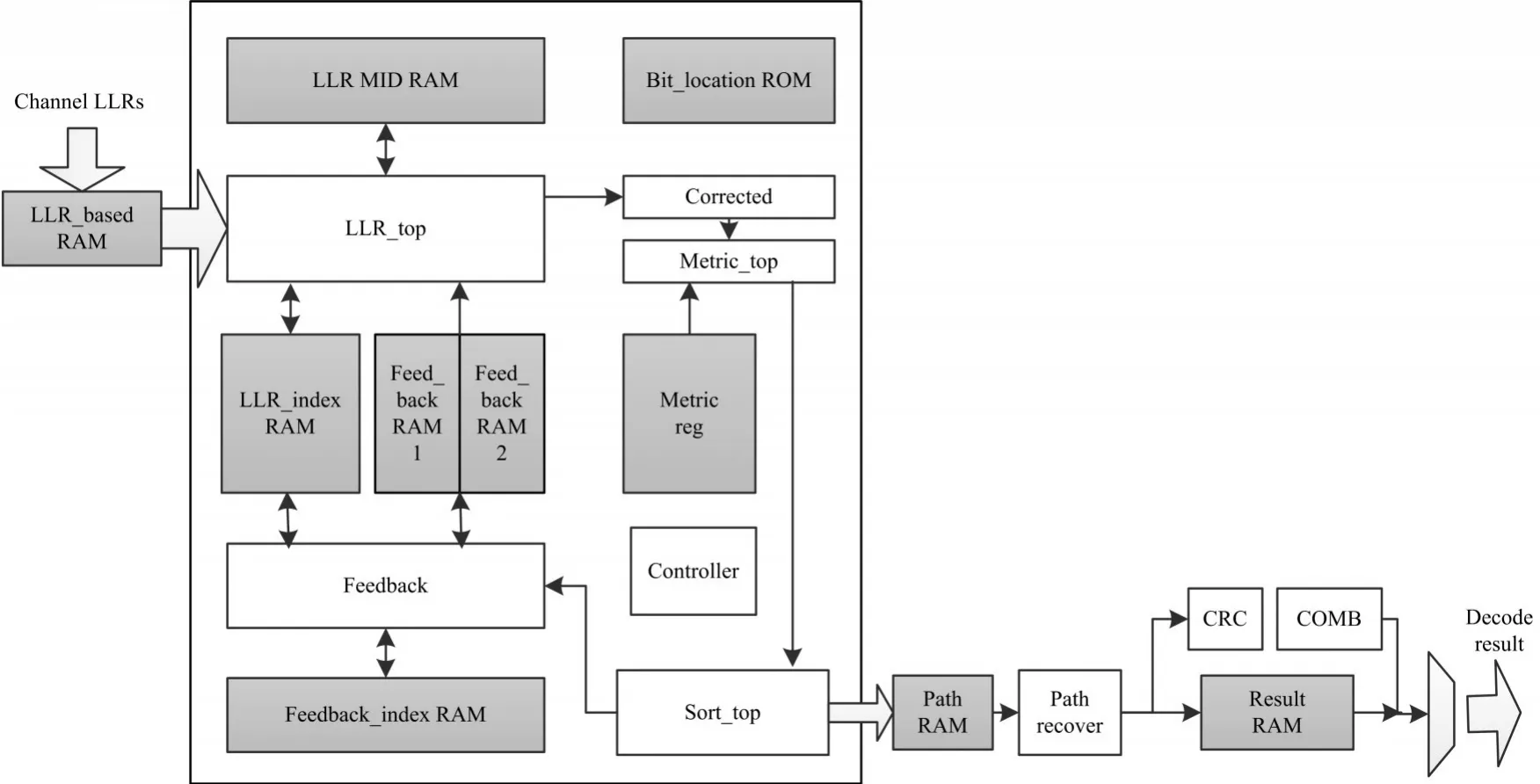
图3 译码器整体结构
因为每条路径包含P个PE单元,所以单次计算会产生P个内部中间LLR,所以每次需要存储的数据为PQLLR,其中QLLR为每个LLR数据的存储位宽,所以内部LLR存储模块输入位宽为PQLLR,同时每次计算需要2P个初始LLR数据,所以内部LLR存储模块输出位宽为2PQLLR,为实现这一结构,本文采用双SRAM来实现2PQLLR数据的输出。
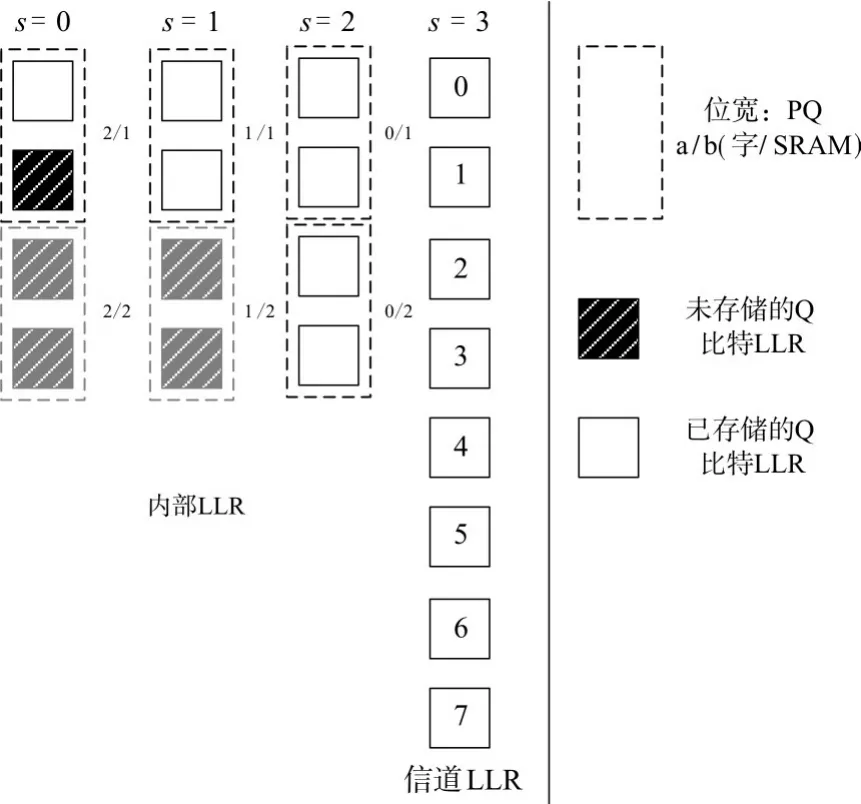
图4 N=8,P=2的LLR存储器结构
以N=8的双PE结构的半平行设计为例,图4即为N=8,P=2的LLR存储器结构。
5.3 LLR计算模块
如图5所示的LLR计算模块硬件结构,该模块主要是由控制单元(LLR_control)、PE计算单元(Polar_fg)、排序器(LMUXL)组成。控制模块用于控制数据读取地址和索引信息;排序器的作用是将输入的LLR数据按照index进行重排,然后传入到L条路径中计算LLR的值;而PE计算结构是由P个式(4)中的f或g模块构成,在单次顶层LLR的计算中,每一层都仅激活f或g节点中的一种。
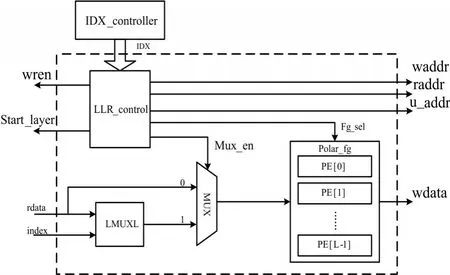
图5 LLR计算模块硬件结构
5.4 度量值计算模块
在得到32条路径对应的顶层LLR之后,要对当前2L=64条路径的度量值进行计算,如图6所示为路径度量值计算模块的硬件结构。用一块1024*1的ROM存放信息比特和冻结比特的位置信息,0对应冻结比特,1对应信息比特。当本模块开始工作时,从Bit_location ROM中读取位置信息和顶层LLR的符号位一起作为控制模块的输入,来控制式(3)中所对应的三种情况。
在计算出候选比特为0和1格子的路径度量值后,使用一个选择器输出其中的较大值和较小值以及它们对应的候选比特。然后对路径进行冒泡排序,将前32条路径度量值进行存储,供下次计算使用。
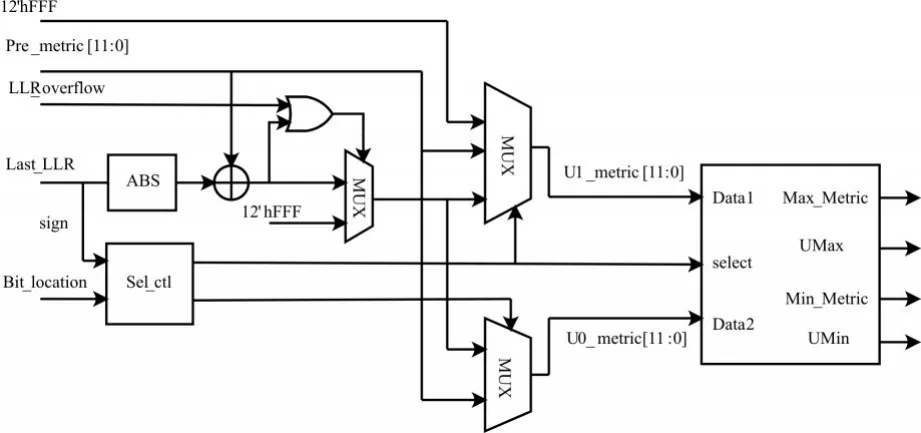
图6 路径度量值计算模块硬件结构
5.5 部分和更新模块
图7为部分和更新模块硬件框图。其中虚线部分为部分和项的存储结构,指针只读取其中实现框内的存储单元。

图7 路径度量值模块硬件结构
根据前面讨论可知g函数的计算中需要部分和的输入,所以需要在每个码字被估计出来之后对部分和项进行更新,为了不影响系统吞吐率,我们采用寄存器进行存储,观察译码蝶形图,每个码字的译码最多同时利用N/2个比特的部分和,所以本文为了节省硬件资源,采用N/2 bit的寄存器长度,每次更新都对寄存器进行清零。
5.6 CRC串行译码模块
本文CRC译码模块采用的是串行逆序译码结构,这是因为在路径恢复模块译出来的信息比特为逆序排列,逆序的CRC校验码是在逆序信息比特序列前面,且序列为串行输出。因此,使用此结构,与并行译码相比不仅减少了资源消耗,所需时间也不会发生改变。该模块如图8所示使用了24个寄存器,这些寄存器是用于存放CRC检验码。解码开始,前24个时钟,按顺序将24个CRC校验码分别存入24个寄存器中。而从第25个数据将按下图的数据流向进行计算,根据生成多项式生成加法器。整个结构如图8所示。

图8 CRC串行逆序译码模块
6 译码器综合结果与分析
在本文的极化码CA-SCL译码器设计实现的过程中,采用的FPGA芯片是Altera公司Strtix V系列的5SGXEA7H3F35C3,使用QuartusⅡ15.0综合后的结果如表2所示。
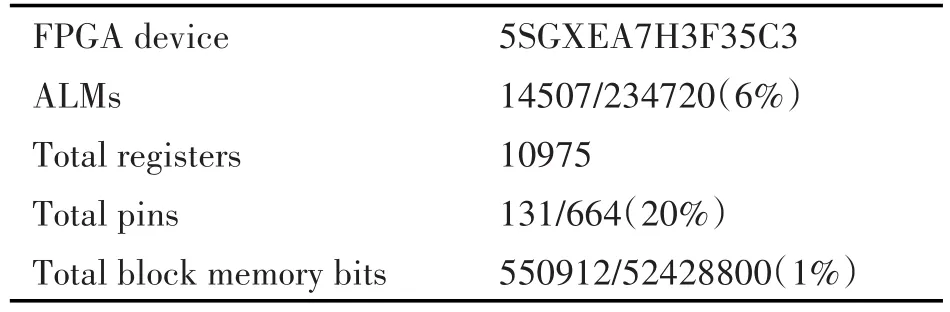
表2 极化码CA-SCL译码器硬件资源统计
吞吐率T是评价硬件译码器性能的重要指标。其计算公式为

在本文设计中,码长为1024,译码器的工作频率为150MHz。译码器平均时延为0.040ms,所以吞吐率可以达到由于系统用两个时钟存储更新LLR,因此总的时延可以计算如式(9):
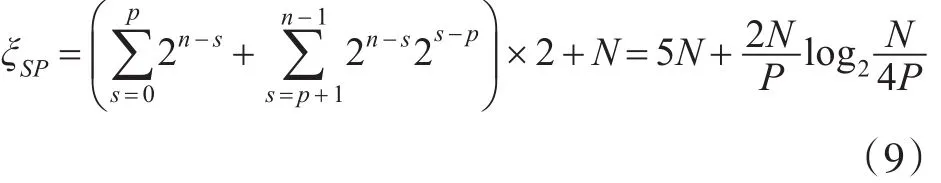
根据译码结果,本文设计的译码算法译出一个码字大概需要6000个时钟周期,与理论值5120个时钟周期相差不大,而系统面积的占用率仅为7%。
硬件译码算法的另一个重要评价指标是误码率(BER),如图9所示为本文8 bit量化与理论未量化译码算法之间BER的性能比较。
如图9所示,CA-SCL半平行译码算法在对数据进行8 bit量化、路径度量值进行12 bit量化后的性能与理论未量化之间比较接近,在误码率BER=10-5时,量化后的BER只与理论值相差0.1dB左右,验证了优异的译码器性能。
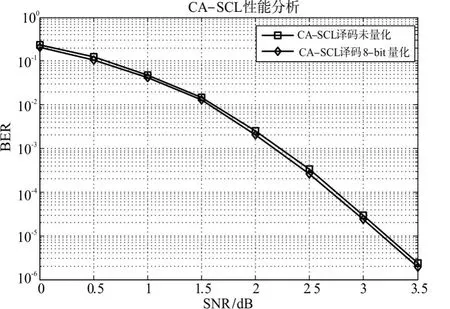
图9 量化与未量化CA-SCL译码算法比较
7 结语
对码长为1024的极化码采用了性能优良的CA-SCL译码算法,在FPGA下设计实现,对每条候选路径运用半平行计算的硬件架构,相较于平行结构大幅减少了系统硬件资源占用,完成了对该算法占用较大系统面积的优化,在此情形下的吞吐率表现并没有达到理想状况。接下来对如何进一步在速度与面积之间取得平衡,来提高系统频率降低平均时延,是后续主要的研究方向。
