基于ESP32的实验材料存储柜人脸识别系统设计
2019-03-24陈文敏陈庭轩
郎 磊,曹 霞,胡 元,陈文敏,陈庭轩
(1.华中师范大学物理科学与技术学院,湖北 武汉 430079;2.武汉晴川学院电子信息工程系,湖北 武汉 430000)
实验材料科学、规范的管理是高校实验室教学与科研工作顺利开展的保障,其中对实验材料的储存和取用控制是实验材料管理工作的重要环节[1-3]。目前,大多存储柜或门禁系统采用IC卡[4-5]、密码锁[5]、指纹[6]等解锁方式,对穿戴防护装备的实验人员来说较为繁琐,同时接触式的开锁方式存在取用不便、易丢失、易窃取、管理不便等缺陷,而使用传统人脸识别功能的门禁或监控系统[7-8]存在造价高、需要网络接入、操作复杂等问题,已经无法满足实验室材料的安全管理需求。
针对以上问题,本文提出了一种基于人脸识别和语音唤醒功能的实验材料存储柜系统。系统通过比对语音信息中的关键字唤醒设备,随后进入人脸识别程序解锁材料柜,同时柜门的状态信息也会随着设备的唤醒或识别发送至服务器中以便于管理人员查看设备使用情况,设备在无网络状态下也能正常进行工作,需上传信息则在网络恢复后进行。最终实现对实验材料存储柜的安全管理。
1 系统的硬件组成
本系统的硬件主要包括物联网模块ESP32、图像采集模块OV2640摄像头模块、语音采集模块、电源模块和电磁锁。其中ESP32为系统的控制器,负责接收语音模块与摄像头采集的语音信息和人脸图像信息,并运行语音比对和人脸识别程序,根据程序处理结果控制储物柜门锁的开关。同时,ESP32利用其内部集成的WIFI模块自动配网,实现与服务器的通信。
当语音模块采集到语音信息后,通过I2S接口传送给ESP32进行比对,比对成功唤醒系统,随后启动OV2640摄像头拍照,图像信息经数据总线传送到ESP32后进入图像识别程序,将采集到的图片与用户预先存储的人脸图像进行识别和匹配,ESP32根据匹配结果控制储物柜门锁的开合,最后将当前柜门操作过程中的信息通过WIFI上传至服务器。
1.1 ESP32芯片的最小系统
ESP32芯片是乐鑫公司推出的一块2.4GHz WIFI加蓝牙双模双核MCU芯片,支持高达240MHz的时钟频率,拥有34个GPIO端口,外部内存方面最多支持4个16MB的外部QSPI flash和SRAM,其采用台积电超低功耗的40nm工艺,电源供电仅需3.3V供电即[9]。相对市面上多数单片机而言,ESP32具有运算能力强、射频性能高、开发简单、功耗低和高度集成的优势[10]。
以往人脸识别系统中,人脸识别的程序由服务器来运行完成,单片机与WIFI模块为两个独立的模块,其工作流程是首先外部摄像头采集图像信息后发送给单片机,单片机通过WIFI模块将图像信息上传至服务器;服务器接收到的图像信息识别后,将识别结果再由WIFI传输至单片机进行处理[11-13]。采用这样的方法,系统成本高、体积大、速度慢并且人脸识别的效率低,在硬件选型和使用时还需要考虑WIFI模块的波特率和单片机的波特率的匹配问题。
本系统采用乐鑫ESP32芯片作为主控芯片,利用其较高的频率和丰富的内部资源能够有效的进行语音唤醒和人脸图像识别的计算,通过内部集成的WIFI和蓝牙模块在与服务器进行数据交互时,通讯速度更快,同时也节省了外部接口的资源。ESP32芯片丰富的外设和高扩展性,使实验材料存储柜的设计拥有多种管理方案和丰富的变化空间,ESP32最小系统电路图如图1所示。

图1 ESP32最小系统电路图
1.2 OV2640摄像头模块
系统中的图像采集模块OV2640 是一款1/4 寸的 CMOS UXGA图像传感器,其输出图像最高像素可达1 600×1 200,用户也可以根据需求调整像素规格[14]。使用该模块不但满足本系统进行人脸图像信息识别的分辨率要求,并且符合电路系统高集成度和低功耗的发展趋势。
OV2640通过SCCB总线选择输出图像格式和图像数据帧的位数,输出图像数据格式有RGB565 和 JPEG两种,输出数据帧的位数有8位和10位[15]。综合系统的功能需求和相关硬件的数据处理工作量,本模块输出图像设置为320×240像素,采用JPEG输出图像格式和8位数据输出接口。
2 人脸识别材料存储柜软件程序设计
乐鑫公司为ESP32提供了一套名为ESP-WHO的开发框架,在ESP-WHO中可以方便的添加自己所需的库或者其他功能,能够帮助用户快速开发物联网应用。开发框架中集成了FreeRTOS实时操作系统,方便了用户对程序的移植。使用ESP-WHO开发框架,可以快速构建面部检测与识别功能。在ESP-WHO中,检测、识别和图像处理单元是该平台的核心。
设备上电后进入主程序,主程序流程图如图2所示。设备主要工作在以下5个阶段。首先进入到初始化阶段,该阶段会将设备需要的外设进行简单快速的初始化。随后进入到语音唤醒阶段,当数字麦克风接收到的音频信息中含有用户所配置的唤醒关键词时,设备将退出此阶段进入到联网配置阶段。联网配置阶段的设备将载入之前所保存WIFI信息,自动连接该网路;若网络连接失败,用户可使用手机APP通过ESP32的SmartConfig模式进行一键配网,并在配置完成后自动连接。网络连接成功后,设备进入到人脸检测与识别阶段,ESP32对图片信息进行人脸检测和人脸识别。最终根据识别结果进行柜门开关,操作完成后,不论结果如何,设备都会将识别到的人脸图像发送至服务器,便于负责人员的查看与管理。在每个阶段中都会有指示灯显示出设备当前所处阶段,以及该阶段的进行状况。
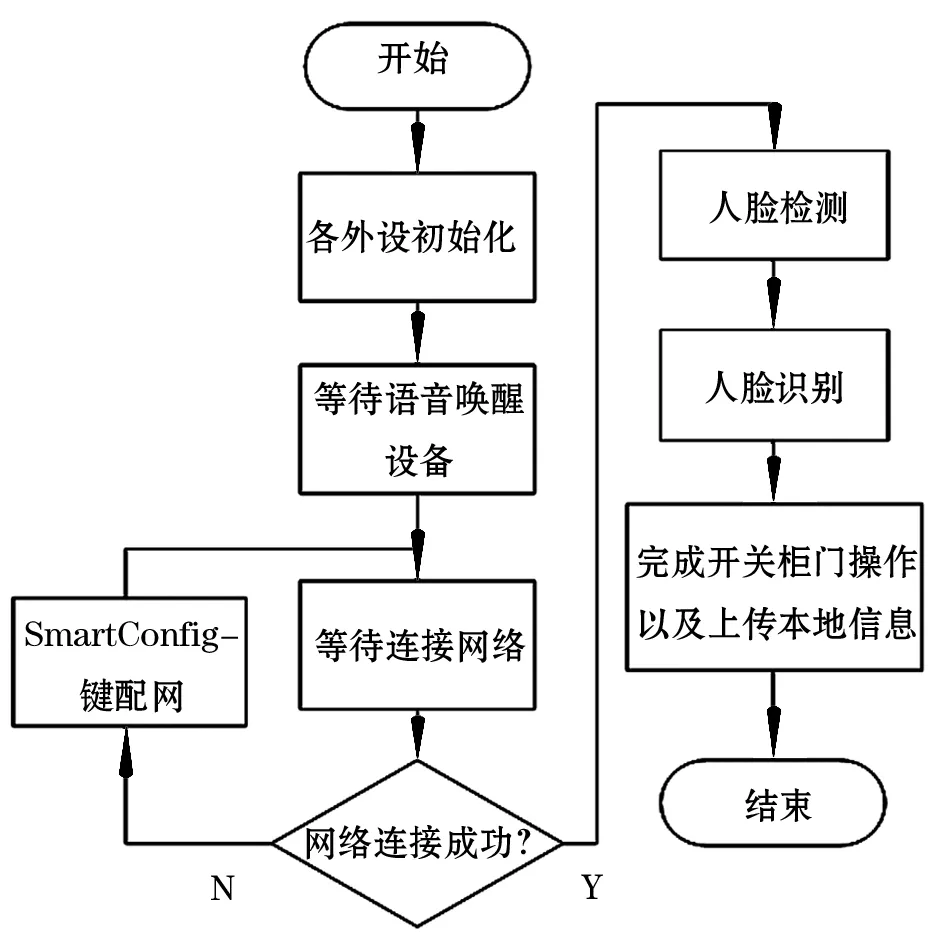
图2 主程序流程图
2.1 语音唤醒模块的程序设计
音频模块初始化完成后,检测音频输入,将由数字麦克风录入的音频数据储存于一组16位带符号的数组中,通过队列传输到处理进程中。音频处理进程检测到队列有数组输入,将传入的音频流样本提供给语音识别模型,并检测是否找到唤醒关键词。若检测到唤醒字,则唤醒设备;否则,返回0。
2.2 人脸识别模块的程序设计
人脸识别模块程序主要由人脸检测程序和人脸识别程序两部分组成。ESP32会将接收到的图像信息,通过算法完成对人脸信息的检测与识别,进而根据不同结果完成具体的工作。
人脸检测程序主要用于检测输入图像中是否存在人脸,若存在,则截取面部图像信息;否则,进行新一轮的检测。人脸检测程序使用一种轻量级人脸检测模型,该模型是基于轻量级卷积神经网络(MobileNet V2)[16]和多任务学习级联卷积神经网络结构(Multi-task Cascaded Convolutional Net-works,MTCNN)[17]的新型人脸检测模型,它将MTCNN网络中卷积神经网络部分替换成MobileNetV2。这种检测模型的网络架构极大的减少了运算量和内存,同时保持较高的精度,为在嵌入式设备运算人脸检测程序提供可能。
本系统所用轻量级人脸检测模型由提案网络(P-Net)、精炼网络(R-Net)、输出网络(O-Net)三个主要部分组成。P-Net是一个全卷积网络,用来生成候选窗和边界框,并将其发送到R-Net;R-Net用来改善和筛选候选窗;最后由O-Net输出精确的边界框和5个特征值位置。
人脸识别程序主要用于检测输入面部图像信息是否与设备录入面部图像信息相匹配,若匹配,则输出匹配的人员信息,否则输出0。人脸识别程序使用一种轻量级人脸识别模型,该模型基于MobileNet V2和ArcFace算法构建的新型人脸识别模型,它既保证了人脸识别模型较小,又保证模型具有较高的精确度和较快的识别速度。
人脸检测与识别流程图如图3所示,首先根据图像信息中人脸面部特征截取面部图像;然后通过面部识别算法生成面部图像ID;最后将新生成的面部ID与现有面部ID进行比对,获取它们之间的差值并与设置阈值比较,判断该人员是否在设备注册。
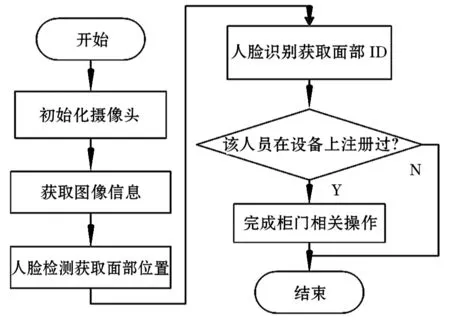
图3 人脸检测与识别流程图
3 系统测试与实现
为了检验本系统的性能,分别对语音唤醒、人脸识别范围和准确率进行了测试。
在确保环境安静的前提下,对设备在0~10m的范围内进行语音唤醒成功率的测试,每隔1m对设备发出100次以上的唤醒指令,通过打印出设备唤醒的次数来计算设备唤醒的成功率。测试结果如图4所示,语音唤醒指令在0~3m时识别成功率很高。距离较远时,需要音量提高,才能保证设备正常唤醒。
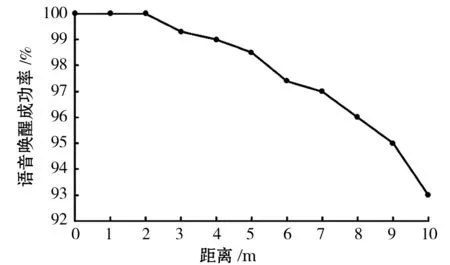
图4 语音唤醒成功率
人脸识别模型中训练图片尺寸多为56×56像素以上,本系统将人脸识别网络中可检测面部的最小尺寸设置为80×80像素、输入图像的渐变缩放比例设置为0.7。设备在1m内的识别效果较好,可检测人脸范围如图5所示,此图为设备检测人脸的最大范围图,超出范围时,设备不能准确识别。
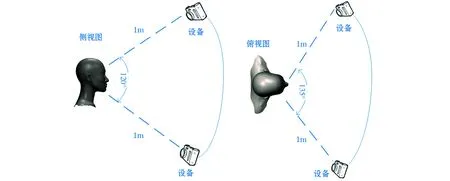
图5 设备可检测人脸范围
为了验证系统人脸识别的准确率,关闭音频唤醒功能,仅开启面部检测与识别功能。每隔1s进行面部检测,若在5s内未能检测到人脸,则默认为检测识别失败。人脸识别输入图像尺寸为56×56像素,脸部识别域值设置为0.75。提前将被测人员的FaceID录入设备之中,每位成员录入人像次数为3次。测试环境在实验室中进行,光照足够充足,测试人员坐于摄像头正前方0.5m的位置,此位置为人脸检测与识别最佳位置。为了模拟设备在真正使用时的情况,被测人员在测试期间可微微改变面部朝向,每位成员测试100次以上。
人脸识别准确率测试结果如表1所示,其中识别准确率指实验中准确检测人脸并识别为正确ID的实验次数与总实验次数的比值;识别平均时间指开始人脸检测程序、检测后由人脸识别程序得出结论所花总时长。测试表明,单次识别时间在1.5s左右,最高不超过2s;识别成功率平均为80.54%。由于ESP32设备内存有限,每个FaceID录入样本数为3个,而人脸识别程序中使用512-d vector代表一个FaceID的面部特征,输入特征参数较少,导致该面部特征不能较完美的表示当前测试人员的面部特征情况,至此识别精度不如理论中测试结果那么完美。若对安全性有较高要求,可增加脸部识别域值大小,降低错误识别率;反之降低该值,可提高识别率成功率;此值设置为0.75为测试效果最佳值。在不提高错误识别率的情况下,提高人脸识别正确率,设备可选用更大的PSRAM内存,提高FaceID录入样本的数量,从而更好地拟合被测人员的人脸特征。图6为人脸检测识别结果。
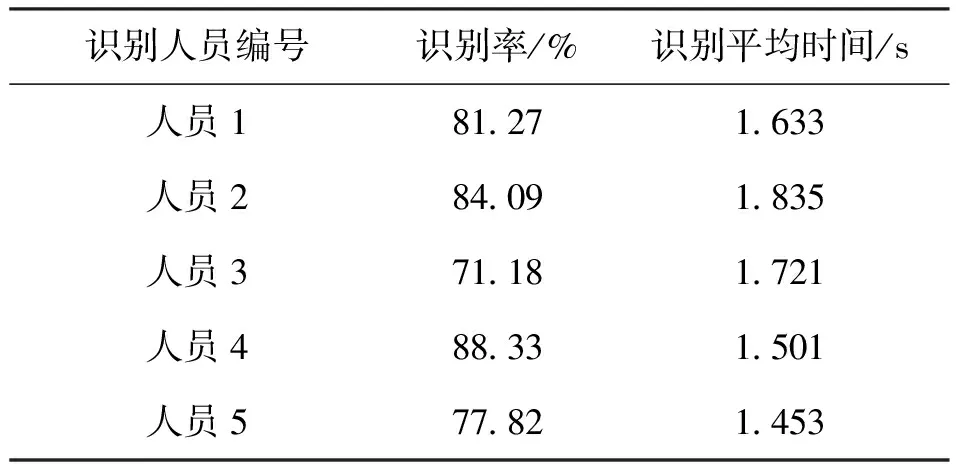
表1 人脸识别准确率结果
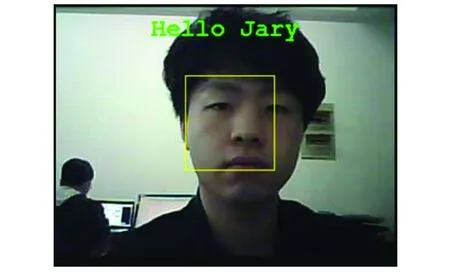
图6 识别结果
4 结语
通过测试表明,设备可以通过语音快速且准确的唤醒设备,已录入系统的用户可通过语音人脸识别实现开柜功能,管理员可通过服务器向设备发送删除用户、添加用户等功能,随时随地查看设备使用情况。系统使用数字麦克风和OV2640摄像头模块输入音频信息和图像信息,语音唤醒功能和人脸识别与检测功能完全通过本地设备进行计算和比对,与传统人脸识别设备相比,极大的节省了数据与服务器传输所消耗的时间和服务器搭建的成本[18]。整个系统电路简洁、兼容性高、移植性强、集成度高。使用该存储柜系统时,只需对普通的储物柜的机械部分进行简单改装,因此具有较高的实用价值。
