生物医疗大数据隐私与安全保护的应对策略与技术
2019-03-24346
346
生物医疗大数据是现代生物医疗研究的重要基础性资源。在生物医学信息学研究过程中,可利用生物医疗数据越来越多,如电子病历数据、基因数据、图像数据等。生物医疗大数据的种类多、体量大(如个人全基因组测序在几百GB)、数据频率高(如实时的移动医疗数据),包含大量的个人敏感信息。随着生物医疗数据的重要性越来越被认可,其数据本身的一些特性(数据隐私和安全)也为随之而来的广泛医疗数据应用带来了一定的挑战。生物医疗数据包含大量敏感的个人信息,如何合理保护这些敏感信息,规避不必要的隐私泄露风险已成为广泛推行生物医疗数据分享和联合分析及多元医疗数据融合中的关键问题。
随着大数据挖掘和人工智能在生物医疗领域的不断渗透和发展,以及生物医疗科学研究的不断深入,生物医疗数据分享和分析的需求日益增强,随之衍生而来的医疗数据隐私和安全问题也就更加突出。其中最大的挑战之一是生物医疗数据使用过程中涉及个人敏感信息的泄露风险和保护的问题。例如通过比较男性的Y染色体和公开的基因族谱数据库恢复个体的姓氏[1],通过几十个统计学上独立的基因位点(SNPs)就可以很大程度上唯一确定一个个体[2],以及通过基因数据预测个体的体征信息(如声音、眼镜、肤色、身高、体重和年龄等)[3]。另外,基于生物医疗数据的各项科学研究通常需要大量样本,单一机构的数据量很难满足这样的需求(特别是在罕见病的研究中)。然而跨机构的医疗数据共享面临很多挑战,不同机构所在的不同国家和地区可能有不同的隐私保护法律法规。此外,直接分享个人隐私数据可能造成数据的滥用和隐私的泄露。这使得各机构并不能够有效地在多中心合作的模式下直接和第三方分享自身数据,造成医疗数据孤岛问题,影响医疗研究合作的开展。
1 生物医疗大数据隐私保护的应对策略
医疗数据隐私保护是指在医疗数据收集、储存、传播和使用过程中对数据主体敏感信息的保护。医疗数据隐私相关的研究涉及到公众对个人隐私保护的需求和围绕其间的法律、政策、技术等多方面的问题[4]。数据隐私的保护重点在于使用数据的过程中对患者可识别信息和隐私偏好的保护[5-6]。
目前针对生物医疗数据中个人信息隐私保护的应对策略主要分为立法规范和政策引导、对隐私保护技术的开发和应用两种。世界上主要的国家和地区(中国、美国及欧盟等)一方面加强医疗数据隐私保护方面相关的法律建设和政策规范,另一方面也在积极鼓励隐私保护技术的创新和应用。法律法规的建立为技术的发展划定了具体的标准和方向,同时技术的不断发展和创新也引导了法律法规的进一步完善。两者相辅相成,缺一不可,是针对生物医疗数据隐私保护中各种问题的主要应对策略。
2 隐私保护法律法规
近年来,全球很多国家和组织均对个人数据的隐私保护问题进行了专项立法(表1)。
各国通过立法强调了对个人敏感信息,尤其是在采集、传播和研究生物医疗数据过程中的隐私保护,并为管理个人信息的机构(如医院、保险公司、大数据公司、运营商等)的数据运营建立了法律规范。
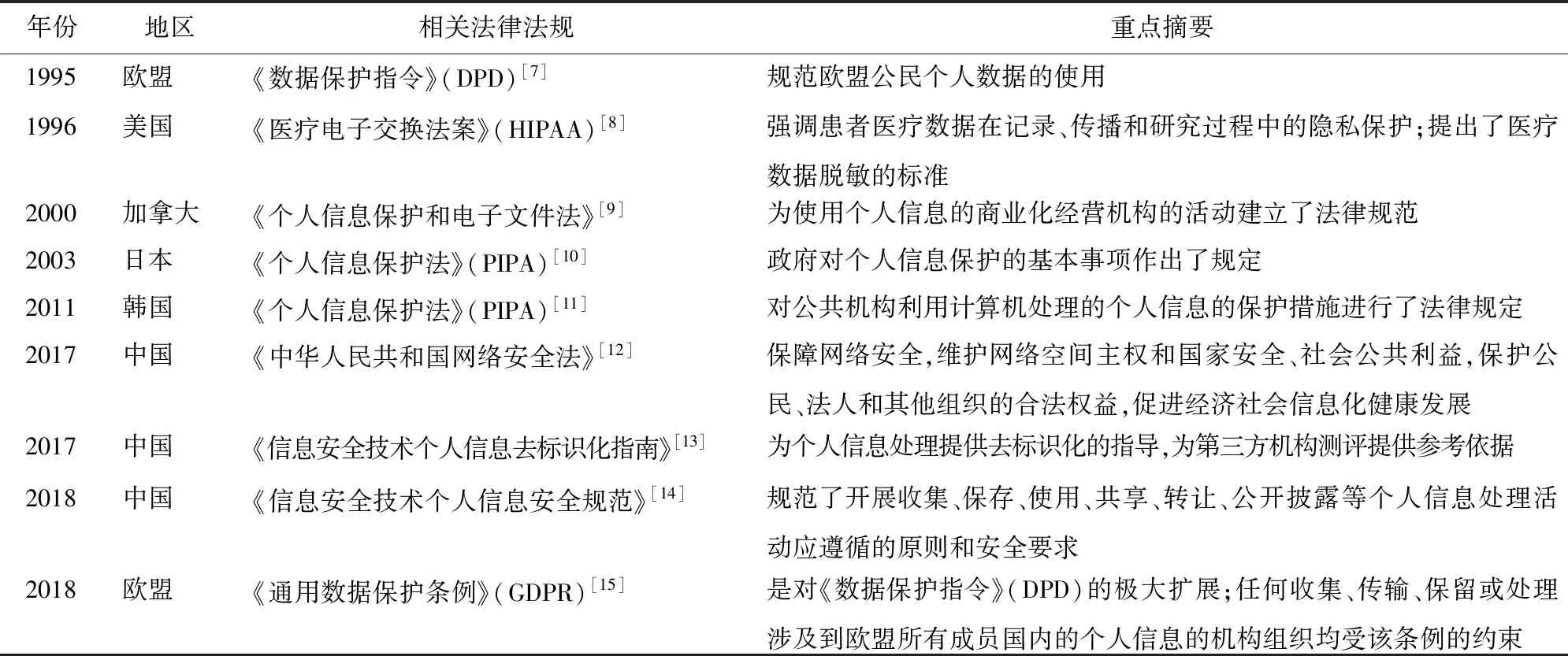
表1 全球部分地区对数据隐私保护的法律法规概述
3 隐私保护技术
针对大数据潮流下数据安全共享和隐私保护的巨大市场需求,多种多样的隐私保护技术应运而生。隐私保护技术泛指一类保护数据隐私的数据处理和计算技术[16]。目前主流研究方向和技术包括但不限于数据脱敏/消隐[8]、同态加密[17]、安全多方计算[18]、置信计算环境以及联盟计算[19-21]等。
3.1 数据脱敏/消隐
电子病历数据是生物医疗数据中最重要的组成部分,各种生物医疗研究中使用的电子病历数据中包含着大量的个人敏感信息。因此,电子病历匿名化(数据脱敏)是一种非常重要的隐私保护手段。数据脱敏中比较常用的标准是美国《医疗电子交换法案》(HIPAA)中提到的安全港(Safe Harbor)方法, 它规定了医疗数据在脱敏后需要剔除的18种可能用来识别个人的标识符,用来指导数据脱敏标准的实施。通过HIPAA安全港方法对数据进行脱敏后,提供方可在HIPAA管辖的范围内免责与第三方进行数据的分享。然而研究表明[22-24],传统的数据脱敏方法并不完美,即便是通过HIPAA安全港方式脱敏的数据依然存在泄露个人信息的风险,如之前的研究发现大概每15 000人中就有2个人可以在HIPAA安全港方式脱敏后的数据中被识别出来[23]。此外,HIPAA 并没有明确规定基因数据如何实现数据脱敏,所以基因数据脱敏的法律法规是滞后的。
除了上述的数据脱敏方法外,数据消隐也是另一种被广泛采用的数据隐私保护技术,如很多早期方法包括但不限于K-匿名[25]、L-多样性[26]以及T-亲密度[27]等。近来,差分隐私作为一种更为流行的数据消隐技术,被医疗领域广泛采用,其优势在于不需假定特定攻击者的背景知识并在数学上量化了隐私泄露的风险。差分隐私的数学定义如下[28]:
若随机算法K对于任何一个输出集合S和任意临近集合D1,D2总有:
Pr[K(D1)∈S]≤exp(ɛ)·Pr[K(D2)∈S]
则称K满足ɛ差分隐私,其中Pr[] 表示概率,ɛ为隐私预算,临近集合指只相差一条记录的一对数据集合。
实现差分隐私的数据分享,主要通过在计算过程或计算结果上加入不同类型的噪音,如拉普拉斯机制和指数机制是两种常用的实现差分隐私方法[29]。大量生物医疗数据分析研究都使用差分隐私技术进行数据保护,如Johnson和Shmatikov发明了一种基于差分隐私的基因数据卡方检验算法[30],将差分隐私技术应用到了全基因组关联分析等研究中[31]。
3.2 同态加密
同态加密后的密文支持在加密后的数据上直接进行加密的运算得到相应的加密结果,其解密的结果和对明文数据进行同样运算的结果一致。2009年一项研究从数学上证明了全同态加密的可行性[32]。通过同态加密,用户可将敏感数据加密后发布到不被信任的第三方(如公有云计算中心),进行加密数据下的加密计算而不泄漏明文信息给第三方。同态加密分为3种:全同态加密(Fully homomorphic encryption),支持密文上任意次数的加法和乘法运算操作;部分同态加密(Partial homomorphic encryption),仅支持密文上加法或乘法运算中的一种;类同态加密(Somewhat homomorphic encryption),支持有限次数密文上的乘法计算[33]。
基因数据分析研究中大量应用了同态加密技术,如对罕见病的研究[17]、一般基因数据分析[34-36]以及全基因组关联分析等[37]。
3.3 安全多方计算
安全多方计算(Secure Multiparty Computation)最初是由图灵奖获得者姚期智院士提出的,其主要目的是在保护各方数据隐私安全的前提下实现多中心数据和计算上的合作。根据计算参与方的数量不同,MPC分为安全两方计算和安全多方计算,分别为混淆电路[38]、秘密分享[39]。MPC技术在生物医疗数据研究中被大量应用,应用中不依赖可信任的第三方,但其缺点在于节点之间的通信量很大,如多机构医疗数据记录匹配算法[40-41]以及全基因组关联分析算法[42]等。
3.4 置信计算环境
置信计算环境是指在计算芯片上的一块被隔离的安全计算区域。该区域上运行的数据和代码能够保证完整性和私密性(如英特尔SGX软件防护扩展),可有效防止底层操作系统或虚拟平台被挟持后对数据和代码的攻击,从而可以在不授信的第三方进行高性能的安全计算,并提供对不授信第三方安全计算环境的远程验证。但是SGX限于安全计算内存大小(128MB)和特定算法的旁路攻击(side channel attack)[43-44]。
基于英特尔SGX技术,Chen Feng等人设计了一种分析罕见病基因数据的系统[19],提出了一种安全高效的基因数据分析框架[20],发明了一种安全的基因亲缘关系分析方法[21]。
3.5 联邦学习
联邦学习是一种分布式的机器学习技术,可保证各个计算参与方原始数据不出本地的情况下,实现共同建模。根据数据的分布方式,联邦学习可分为横向联邦学习(样本联合)及纵向联邦学习(特征联合)两种方式。联邦学习也可以通过和上述安全计算技术结合,用来保证模型参数在计算过程中的私密性,二者结合可实现不分享原始数据情况下的联合更新模型。很多生物医疗数据分析算法使用了联邦学习框架,如SHI Haoyi等发明了一种基于联邦学习的逻辑回归算法[18],JIANG Wenchao等设计了一种基于联邦学习的网格逻辑回归算法[45],WANG Shuang提出了一种基于联邦学习的分布式期望分布逻辑回归训练模型[46],LU Chia-Lun等人展示了一种基于联邦学习的比例风险回归模型算法[47]等。
4 生物医疗数据隐私保护的未来展望
生物医疗大数据的隐私保护是一个十分复杂的问题,涉及多个利益相关方的妥协与合作,需要法律法规和技术手段的共同支持完成一个既定目标。建立满足各方权力和义务的法律法规,研发符合法律法规的技术手段,并通过新的技术手段辅助决策者制定新的标准和规范。在复杂的医疗大数据应用场景下,综合运用和调节不同的技术手段和法律规范是未来生物医疗数据隐私保护发展的基本方向。
