基于Apriori算法的个人医疗费用关联规则分析
2019-03-24
医疗保健相关问题是当今世界最重要的社会问题之一,医疗费用的激增更是加剧了这一问题。因此,在众多与医疗费用相关的因素中,如何甄选出最核心的影响因素[1],有效控制医疗费用持续上涨,提高医疗资源的利用效率,进而提高全民健康水平就变得尤为重要。由于医疗领域所涉及的相关因素众多、数据类型复杂,传统的统计分析、调查研究方法耗时巨大[2],以及人工处理大量数据时出错等原因,应用新技术手段解决这一问题十分必要。数据挖掘技术能从大量杂乱数据中高效、准确地挖掘出隐含信息[3]。关联规则中Apriori算法能够在大量数据中挖掘出与高医疗费用有强关联的因素,同时将结果可视化,提高数据的可读性,便于直观理解医疗费用与各因素之间的关系及关联强度。
国内,李江平采用不同模式的数据挖掘方法,对基层医药卫生工作展开研究,通过对保健数据的研究验证,给提高农村卫生水平提供了有价值的意见[4];余岚通过为学生定制个人体育锻炼计划提高学生身体素质的研究,应用数据挖掘的方法,对干预措施的有效性进行验证从而得出了关联紧密的因素[5];王帅通过研究居民健康管理决策和患者临床合理用药的依据,对基层医疗卫生机构门诊用药规律进行了研究,利用关联算法对高频用药和高频合并用药进行的研究,促使了基层医疗合理用药[6]。孙健对影响我国健康保健费用支出进行的研究,运用数据挖掘法发现了相关强关联因素[7]。
国外,Gosain、Kumar采用不同数据挖掘模式挖掘医疗保健数据,研究了决策树和关联规则如何在大量卫生健康数据中的应用;Sivagowry、Durairaj、Persia 对数据挖掘技术在心脏病分析和预测中的应用进行了实证研究,通过应用数据挖掘技术,从医疗保健系统中获得隐藏的信息[8];Nagavelli、Guru Rao通过对疾病可能性程度的研究和在医疗保健数据挖掘中疾病预测统计测量方法的研究,发现能够通过对已有病例记录的分析能预测可能发生的疾病。
本文拟在前人的研究基础上,将关联规则应用于医疗费用研究领域中,利用Apriori算法在大量数据中挖掘出与高医疗费用有强关联的因素,并分析不同属性之间的潜在关联性,为医药卫生领域相关政策的制定和相关科研人员的未来研究提供参考。
1 关联分析概述
关联分析可以发现大量数据集合中某些事务(属性)的关联关系[9],通常用支持度和置信度2个指标为依据判断一条关联规则的左项与右项之间是否存在强关联。如果一个事务集合的左右项既能满足最低支持度又能满足最低置信度要求,则可将其称之为“左右项存在强关联关系”,它同时具有频繁项集和关联规则[10]。频繁项集是指满足最小支持度的、频繁出现的事务集合,一般以支持度作为衡量指标。在得到频繁项集的基础上,再设置一定置信度为筛选条件进而挖掘出关联规则;关联规则是隐藏在数据项之间的关联或相互关系,可以根据一个事务项的出现推导出其他事务项的出现[11]。
2 数据与方法
2.1 数据来源与预处理
本文数据来源于DataFountain平台(https://www.datafountain.cn/)提供的2016年美国医疗费用数据集,该数据集共有1 338行。数据集合名称为“医疗费用个人数据集”,数据类型包括字符串、数值型数据,有7个字段,没有缺失值。7个字段分别是age(年龄)、 sex(性别)、BMI(身体质量指数)、children(保险覆盖的儿童数量)、smoker(是否吸烟)、region(居住地)、charges(保险承担的医疗费用)[12]。
以影响高额医疗费用的因素为探究内容,首先用Excel电子表格打开源数据,进行初步整理分析,清洗变换,完成数据预处理。部分原始数据如表1所示。数据完整,无缺失值、异常值,未发现重复数据。

表1 2016年美国医疗费用原始数据
2.2 离散化处理
Apriori算法可以用于数据类型为0/1的布尔类型[13],也可以用于分类数据类型。由于数据集中部分属性的取值是连续型变量数据(如年龄、医疗费用),无法直接运用算法进行挖掘,因此对这类数据要进行分层和离散化处理[14]。此外,为了便于后期数据处理及关联挖掘,我们使用代码代替分层离散后的数据。
Age(年龄):将年龄分为5层,用A1代表18~29岁人群,用A2代表30~39岁人群,用A3代表40~49岁人群,用A4代表50~59岁人群,用A5代表60~64岁人群。
比较两组冠心病心绞痛患者对护理服务满意度;住院的时间、患者舒适度(0-100分,得分越高则舒适度越高);护理前后患者焦虑情绪评分(20-80分,得分越高则焦虑程度越高)、心功能等级。
Sex(性别):用B1代表男性,B2代表女性。
BMI(身体质量指数):用C1代替低体重人群,用C2代替正常体重人群,用C3代替过重人群,用C4代替一类肥胖人群,用C5代替二类肥胖人群,用C6代替三类肥胖人群。
Children(保险覆盖的儿童数量):用D0、D1、D2、D3、D4、D5分别替代保险覆盖的儿童数量为0、1、2、3、4、5的人群。
Smoker(是否吸烟):用E1、E2分别替代不吸烟人群和吸烟人群。
Region(居住地):用F1、F2、F3、F4分别替代东北区居民、西北区居民、东南区居民、西南区居民。
Charges(保险承担的医疗费用):2016年美国人均医疗费用为9535.9美元,假定以该人均医疗费用为界定标准,用G1、G2分别代替较低医疗费用和高额医疗费用。
2016年美国医疗费用离散化处理后的部分数据如表2所示。

表2 2016年美国医疗费用离散化后数据
3 关联分析及可视化
3.1 关联分析
经过运算挖掘出45条符合当前设置支持度和置信度的关联规则,调用函数可以展示出所有挖掘出的关联规则,结果如表3所示。
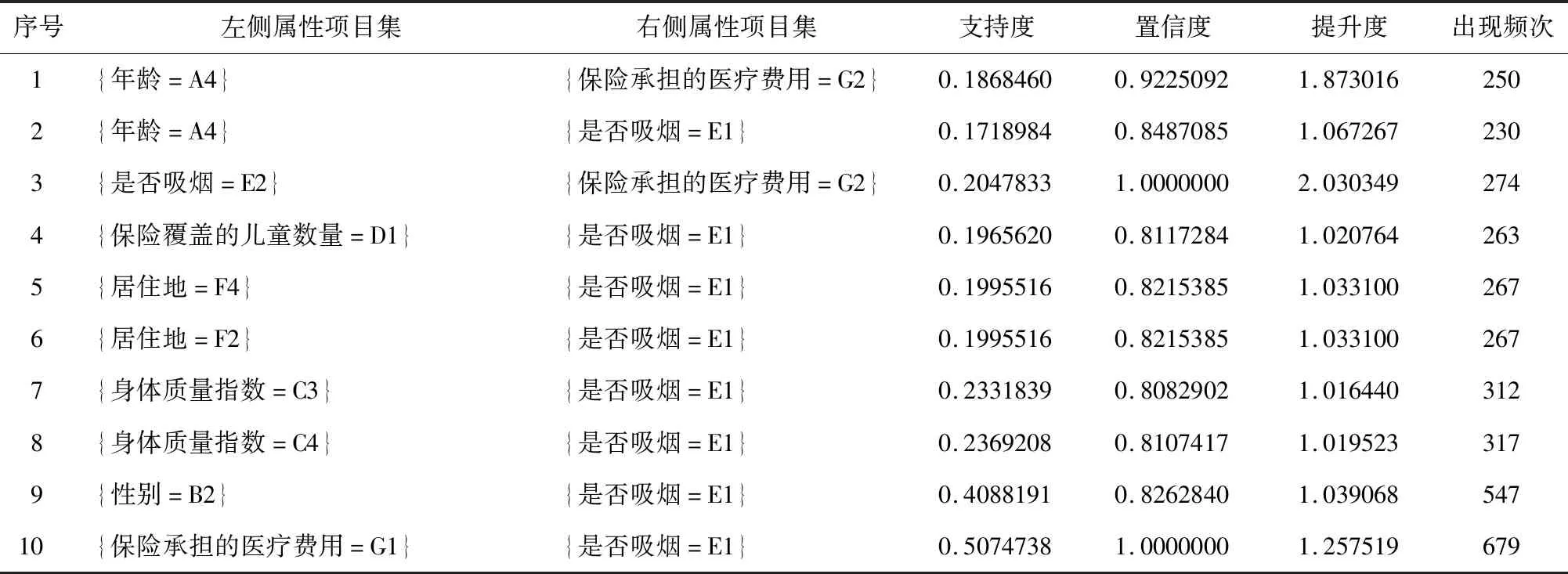
表3 根据当前阈值所产生的关联规则

续表3
其中,“LHS(left-hand side)”表示左侧属性项目集,“RHS(right-hand side)”表示右侧属性项目集,“support”为支持度,“confidence”为置信度,“lift”为提升度。用“count”统计该事务集合在数据集中出现的总频次[17]。部分规则具有较高置信度和提升度,如规则3:{smoker=E2}=>{charges=G2};部分规则具有较高支持度,如规则10:{charges=G1}=>{smoker=E1},所挖掘出的规则的提升度均大于1。
3.2 结果可视化
由于挖掘出的关联规则较多,难以直接读出核心信息[18],因此调用R软件中的可视化绘图函数,将挖掘结果绘制成散点图、气泡图和基于图形的可视化结果,便于快速准确读取信息。
根据45条规则绘制的散点图如图1所示,图中的横轴表示支持度,纵轴表示置信度,彩色条带用颜色表示提升度的大小。

图1 基于45条规则的散点图绘制效果
通过观察图1可以获得挖掘出的全部规则在总体上的分布特征,提升度较高的规则往往置信度也更加趋近于1,但这些规则在支持度的分布上并无明显特征。同样,提升度较低的规则在支持度的分布上也未发现明显趋势。此外,部分规则偏离总体分布趋势,可能为不合理规则。在分析挖掘结果时应关注到这些异常点,排除潜在的对结论的不良影响。但从散点图中无法获得具体关联规则中左右侧分别是哪些属性,以及它们之间关联程度的信息。
气泡图如图2所示,其中每个有颜色的气泡表示一个规则,颜色深浅表示提升度,气泡大小表示支持度,支持度越大,气泡尺寸越大[19]。LHS表示左侧属性项目集,RHS表示右侧属性项目集。
在图2所示的气泡图中,可以获取各组规则中左右侧项之间关联强弱比较,其中规则{sex =B1,age=A1}=>{smoker=E1}支持度最高,而规则{smoker=E2,sex=B1}=>{charges=G2}提升度最高。右项中,支持度smoker=E1>charges=G1>charges=G2,提升度charges=G2>charges=G1>smoker=E1。各组关联规则的提升度从左上方到右下方呈现递减趋势,各组关联规则的支持度从左上方到右下方呈现递增趋势。此外,左侧属性项目集(LHS)和右侧属性项目集(RHS)中所示条件可以让我们快速了解数据中有代表的属性,如吸烟、年龄等因素均是频繁出现的项目集,其重要性更为显著。因此在对挖掘结果进行分析时应首先关注这些因素,但气泡图未能反映各条规则的相互关系以及属性的共享情况。

图 2 基于45条规则的气泡图绘制效果
45条关联规则的图形可视化结果如图3所示。在图3中,圆形代表各项集,箭头代表规则间关系,圆形大小表示支持度,圆形越大支持度越高,颜色深浅表示提升度,颜色越深提升度越大。
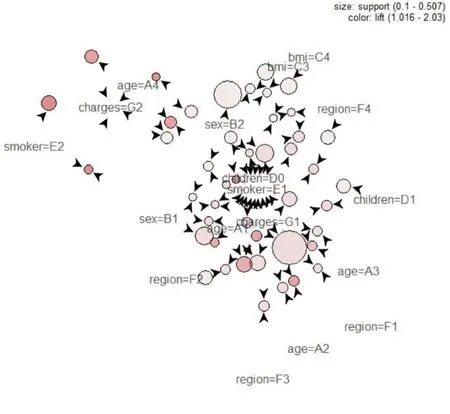
图3 45条关联规则的图形可视化结果
图形可视化既能显示各强关联规则由哪些属性组成,又能显示这些规则共享了哪些属性。通过这些共享的属性可以找出相似规则,从而得出更为稳健的结论,便于我们从另一个角度理解挖掘出的关联规则,以不同视角展现数据特征。
4 讨论
对挖掘出的45条规则进行分析,选取具有代表性的几条规则为例,示范分析过程。
规则1:{age=A4}=>{charges=G2}支持度为0.1868460,置信度为0.9225092,提升度为1.873016,在整个事务集中出现频次为250次。该规则的含义为:1 338人中约有18.68%的人同时具有50~59岁和高额医疗费用的特征;在年龄为50~59岁的前提下,约有92.25%概率会出现高额医疗费用的特征;年龄为50~59岁这一特征出现后,高额医疗费用的出现概率较原来提升了1.873016倍。这条规则的支持度、置信度、提升度3个指标值均为较高水平,因此认为这是一条强关联规则,年龄50~59岁与高额医疗费用之间有较强潜在关联。
规则23:{sex=B2,region=F2}=>{smoker=E1}支持度为0.1008969,置信度为0.8231707,提升度为1.035153,在整个事务集中出现频次为135次。该规则含义是:1 338人中约有10.09%的人同时具有女性、居住在西北区以及不吸烟的特征;在居住在西北区的女性中,约有82.31%的概率不吸烟,但该规则的提升度十分趋近与1,说明居住在西北区的女性的不吸烟属性不显著。因此这一规则并不是强关联规则,西北区的女性与不吸烟无明显关联。
采取上述方法,对全部45条关联规则进行分析,得到强关联规则30条,非强关联规则15条,综合30条强关联规则得出研究结论。结论显示,高龄、吸烟与高额医疗费用有较为显著关联的属性(规则1、3、10、15),低龄人群中低医疗费用者往往不吸烟(规则11、12、32、33、39),且在高龄人群中女性比男性更容易具备高额医疗费用这个属性(规则1、13),男性中的吸烟者有较高概率出现高额医疗费用(规则16)。
5 结语
本文运用R软件中的关联算法研究1 338条个人医疗费用数据集中与高额医疗费用有强关联的属性。通过设置支持度和置信度筛选强关联规则,挖掘出的关联规则基本合理,可以作为医疗费用数据研究的新方法,对该领域今后的研究发展具有参考和借鉴意义。本文仍然存在某些缺点和不足,如受数据来源中原有变量种类和数据数量的限制,只是在有限的数据特征中发现与医疗费用的关联规则,而这些数据特征可能不是医疗费用的重要影响因素或与之具有因果关系;数据所反映的情况可能与真实情况间存在一定偏差;在数据预处理阶段的数据离散化步骤中,一些属性数据的分层离散处理可能不尽合理。此外,怎样合理设定用于挖掘的支持度和置信度也是值得探讨的问题,阈值设定的高低会导致挖掘结果的质量。
