基于相似性连接的时间序列Shapelets提取
2019-03-22张振国温延龙袁晓洁
张振国 王 超 温延龙 袁晓洁
1(延边大学计算机科学与技术系 吉林延吉 133002)2(南开大学计算机学院 天津 300350)3 (南开大学网络空间安全学院 天津 300350) (zhangzhenguo@dbis.nankai.edu.cn)
近年来,对于时间序列数据(time series,简称时序数据)的研究与分析受到越来越多的关注,已成为数据挖掘领域的一个重要的研究课题[1-2],其原因在于时序数据广泛地存在于我们日常生活的诸多领域,如医疗、金融、运动轨迹以及天文星系观测等[3].一般来说,时序数据是由某一观测量随时间变化产生的,每一数据值之间有严格的时间先后顺序,这是时序数据区别于其他类型数据的本质特征.广义上,任何具有严格先后顺序的数值构成的序列,都可以称为时序数据.作为一项基础工作,时序数据的分类是被研究最多的问题之一,具有重要的应用价值,如在心电图信号分析中,对其进行分类能够快速鉴别信号的正常与异常,有助于辅助医疗;在工业生产中,对设备性能数据的采集与分类,能够及时了解设备的运行状况.相比于其他数据的分类,在提取时序数据特征,构建分类器的过程中,数据之间的先后顺序是必须要考虑的关键因素.因此,以时序数据整体作为处理对象,利用数据间相似性的最近邻分类器(nearest neighbor classifier, NN)被首先用于时序数据的分类问题[4-5].
基于NN分类器的时序分类算法的核心在于如何计算时序数据间的相似性.由于噪音、采集时间上的对齐等因素,时序数据在获取过程中可能会存在一些轻微的幅值偏移,这就使得在计算时序数据间的相似性时,相似性算法必须能够处理这种时间轴上的数据错位现象.有2种类型的相似性计算方式被广泛应用:1)基于动态时间规整(dynamic time warping, DTW)的距离计算[6];2)基于编辑距离(edit distance)的相似度计算[7].DTW及其相关改进算法,如导数DTW(derivative DTW)[8]、权重DTW(weighted DTW)[9],通过寻找一条有效的规整路径来最小化对应的时序数据点间的总距离并借此计算2条时序数据的相似性.DTW已被认为是时序数据相似性计算的基准[5].同DTW一样,编辑距离也通过寻找数据间的最佳匹配来计算相似度,所不同的是,基于编辑距离的方法,如时间规整编辑(time warp edit, TWE)[10]、移动-分裂-融合(move-split-merge, MSM)[11],允许数据间存在跨越和改变.这2种类型的时序数据相似性计算被称为弹性距离度量(elastic distance measures).在很长一段时间内,使用这些弹性距离度量的简单NN算法在时序数据分类问题上占据主要地位且很难被超过[12].然而,由于NN算法需要存储和搜索整个时序数据集,而这些弹性距离度量的计算又比较耗时(通常情况下,时间复杂度为O(m2),m为时序数据长度),这就导致在处理较大时序数据集时,时间和空间的消耗都比较大,限制了其应用.另一方面,这种方法是将时序数据作为整体来考虑的,然而更多的时候,对于时序数据类别区分起关键作用的是局部信息而非全局信息,同时,局部信息更能体现出时序数据间的本质差异.
为了解决上述2个问题,Ye等人[13]提出使用子序列(subsequence)作为区分不同类别的依据,并将具有高类别可区分的子序列称为Shapelets.相比于使用NN分类器的算法,Shapelets提供了良好的可解释性,易于体现不同类别时序数据之间的关键差异.因此,Shapelets一经提出便受到研究者的关注.如何快速提取高质量的Shapelets已成为最近几年时序数据处理领域的一个热点问题.然而,由于任意长度的时序子序列都可能是Shapelets,而子序列数量庞大(例如长度为60,时序数量为600的数据集,子序列数量达1.098×106),所以逐一判断子序列的类别可分能力是一项非常耗时的工作.针对该问题,Ye等人[13]提出使用剪枝策略加速子序列分类能力的判断.这些策略对于小数据集是可行的,但对于大数据集仍难以处理.为了提高Shapelets提取效率,许多使用加速技术的算法被提出,如使用空间换时间的Logical Shapelets算法[14]、借助时序数据的离散化SAX(symbolic aggregate approximation)[15]表示的Fast Shapelets算法[16]等.这些方法虽然能够在一定程度上加速Shapelets的提取,但仍需要大的时间消耗,且会损失一定的预测准确率.除此之外,Hills等人[17]更改子序列分类能力度量方法,使用易于计算的Kruskal-Wallis度量和F-statistic作为衡量标准,但加速效果并不明显,并且降低了分类准确率.
除了上述直接使用提取的Shapelets构建分类器外,Lines等人[18]提出了一种使用Shapelets构建对应时序数据特征向量的方法,可以使用当前比较成熟的分类器,如SVM,而不必拘束于Ye等人[13]使用的决策树分类器.使用时序数据的特征向量表示,一方面可以保证Shapelets的可解释特性,另一方面可以充分利用成熟分类器的优点,提高分类准确率.该方法的关键问题仍然是如何提取出高质量的Shapelets,然而作者并没有改变辨别子序列分类能力的方式,故其方法仍然非常耗时.
为此,本文在Yeh等人[19]所提出的时间序列matrix profile基础上,提出了一种基于相似性连接的时间序列数据Shapelets提取方法.该方法舍弃了现有工作中先生成子序列,再对子序列进行区分能力判断的方案,而是通过差异向量体现不同类别时序数据本身的差异,利用相似性连接策略快速计算出隐含高分类能力Shapelets的候选矩阵,然后通过对比候选矩阵中的数值差异,筛选出Shapelets集合.以子序列为单位的时序数据间的相似性可以通过快速傅里叶变换计算得到,大大减少了距离计算带来的时间消耗.在获得Shapelets集合之后,利用这些Shapelets将原时序数据集转换成相应的特征向量表示,使用SVM分类器完成分类工作.本文在多个领域的真实数据集上进行一系列实验,对比了目前主要Shapelets提取算法.实验结果表明:本文提出的Shapelets提取算法具有很好的时间效率,同时,又能保证很高的分类准确率,与其他算法相比具有更好的实用性.
1 相关工作
目前的研究工作中对于Shapelets的提取思路主要有2种:基于搜索的策略[13-14,16-17,20-23]和基于学习的策略[24-25].
1.1 基于搜索策略的Shapelets提取
在Shapelets提取最初的研究中,其基本思路是考虑训练数据中的所有子序列,然后使用信息增益(information gain, IG)来评估每一个子序列对于类别的区分能力,通过循环获取当前训练数据中具有最优信息增益度量的子序列来构建决策树分类器,实现时序数据的分类[13].类似于信息增益度量,一些新的度量方式,如F-Statistic,Kruskall-Wallis等,也被应用于衡量子序列的区分能力,但从效果上来看,信息增益要优于这些度量方式[17].
由于时序数据子序列数目众多,逐一进行判断的brute-force算法需要大量的运行时间,其时间复杂度为O(n2m4)(n为训练集中时序数据的条数),因此,相应的剪枝方法和加速技术是研究的重点.基于最小距离的提前终止计算和基于信息增益的熵剪枝是最早提出的策略[13],这些策略虽然在一定程度上可以加速搜索过程,但仍然十分耗时.Mueen等人[14]提出以空间换时间的方法,使用5个充分统计量使得在距离计算过程中可以部分重用之前的结果.另外,使用新的度量方式(信息增益上界)来减少耗时的熵的计算.通过这些技术,算法的时间复杂度被减少至O(n2m3).在文献[14]的基础上,原继东等人[20]提出利用Shapelets之间的逻辑组合关系来提高分类准确率,但并没有提升Shapelets提取效率.为进一步压缩搜索空间,Rakthanmanon等人[16]借助于时序数据符号化表示,将时序数据离散化,在低维空间中通过随机映射方法快速过滤掉类别区分能力低的子序列.对于筛选出的有可能成为Shapelets的子序列,则继续使用信息增益加以判断.该方法能够大大减小搜索空间,使得时间复杂度降低至O(nm2).
除了使用加速技术改进算法外,其他方式的策略也被用于加快Shapelets提取.Chang等人[21]借助GPU运算对不同的子序列使用并行化方法来判断子序列分类能力.然而,这一方面需要对距离计算方式做较大的修改,另一方面,其Shapelets的搜索时间非常依赖于硬件性能.Wistuba等人[22]基于有区分能力的Shapelets应当在时序数据中经常出现的假设,使用随机采样的方式构成Shapelets.这种策略确实可以减少运行时间,但分类准确率相对较低.Zhang等人[23]提出没有数值变化的子序列成为Shapelets的可能性很小,只利用有数值变化的子序列构成Shapelets候选空间.这种方法大大减小搜索空间,有很好的加速效果,但本质上并没有改变算法时间复杂度.
1.2 基于学习策略的Shapelets提取
与搜索整个子序列空间不同,基于学习的策略试图寻找针对Shapelets提取的数学表示作为时序数据分类的目标函数,通过优化算法从时序数据集中学习到Shapelets.以这种方式得到的Shapelets有可能不是时序数据中的子序列,但确能将不同类别的时序更好地区分.Grabocka等人[24]使用logistic回归分类模型构建Shapelets提取的目标函数,称为LTS(learning time series),以随机梯度的方式不断地优化目标函数,使损失将至最低,进而构造出Shapelets.该方法得到的Shapelets往往不是某条时序数据中的子序列,而是能够对数据进行划分的特征.目前,LTS仍然是在不使用集成策略前提下的分类效果最好的算法[26].但是这种策略的最大问题是时间和空间消耗都很大,在硬件资源受限情况下无法得到分类结果.另一种基于学习的方法是由Hou等人[25]提出的FLAG(fused lasso generalized eigenvector method)算法,与LTS直接优化产生Shapelets不同,FLAG通过构建目标函数来寻找具有好的分类能力的数据所在的位置信息,然后提取这些位置上的子序列形成Shapelets.这种方法的优点是速度快,但是分类准确率有一定的降低.
2 相关定义与符号表示
定义1. 时序数据.一条时序数据是一组实数值变量组成的向量,表示为T=(t1,t2,…,tm),其中m为时序数据的长度.
定义2. 子序列.给定长度为m时序数据T,子序列S是T中的一个连续片段,记为S=(tp,tp+1,…,tp+l-1),其中p为子序列在T中的起始位置,l为子序列长度,1≤p≤m-l+1.
长度为m的时序数据T中包含m-l+1条长度为l的子序列,可以使用滑动窗口逐一取出.
定义3. 全子序列集合.时序数据T的全子序列集合是指由长度为l的滑动窗口在T上生成的子序列集合,记为A={S1,l,S2,l,…,Sm-l+1,l}.为了表示方便,本文使用A[i]表示Si,l.
时序数据间的相似性通常是通过距离大小来度量的,长度相等的2条时序数据T与R之间的距离
(1)
式(1)只能度量长度相等的时序数据,而本文主要的处理对象是子序列,也就是在不等长情况下度量序列间的相似性,为此,需要定义子序列与时序数据间的距离表示.
定义4. 子序列与时序数据的距离.给定时序数据T(全子序列集合为A)及子序列S,两者之间的距离定义为子序列S在T中最优匹配时的欧氏距离:
sd(T,S)=min(d(A[1],S),d(A[2],S),…,
d(A[m-l+1],S)).
(2)
图1直观地描述了距离sd(T,S)中最小值的含义.

Fig.1 Illustration of best matching in T for subsequence S图1 子序列S在T中的最优匹配示例
尽管式(2)易于理解,但由于子序列数量庞大,其计算需要大量的运行时间,Yeh等人[19]提出借助均值、方差等充分统计量和点积运算来降低计算的复杂度,即S与T中每一条子序列之间的计算为
(3)
其中,μA[i],μS,σA[i],σS分别为子序列A[i],S的均值和方差.通常情况下,对于每一条子序列,均值和方差的计算时间复杂度为O(l),但可以通过存储T中数据值和数据值平方的累积和向量,使得在每一次运算中都可以直接用来计算任意长度的子序列的均值和方差[27].这样,在式(3)中,A[i]与S的点积运算就成为制约计算效率的关键因素,3.2.1节将给出快速计算该点积操作的算法.
定义5. 最近邻函数.给定2条时序数据的全子序列集合A和B,对于任意一子序列对A[i],B[j],如果A[i]在B中的最优匹配是B[j],则最近邻函数θ值为1,否则为0,即:

(4)
其中,k∈[1,m-l+1]且k≠j.使用最近邻函数,可以得到2条时序数据的相似性连接向量.
定义6. 相似性连接向量.给定2条时序数据的全子序列集合A和B,对于A中的每一条子序列A[i],使用最近邻函数在B中寻找其最优匹配B[j],每一个匹配对之间的距离所构成的向量称为A与B之间的相似性连接向量,记为PA B.
需要注意的是,PA B是有序的,在计算过程中严格按照第1条时序的全子序列集合A中子序列的先后顺序寻找在B中的最近邻,也就是说A中的子序列一定会在θ=1的最优匹配对中出现,而B中的子序列不一定全部在θ=1的匹配对中,因此,PA B并不是对称的,即PA B≠PBA.
定义7. 自相似性连接向量.在计算PA B时,若B=A,这样构成的相似性连接向量称为自相似性连接向量,记为PA A.
PA A可看作表示一条时序数据的元数据.由于每一条子序列都来自该时序数据,所以总能找到距离为0的最优匹配以及在最优匹配附近近似等于0的匹配子序列,这样的匹配对于描述数据特性是没有意义的,通常称之为平凡匹配(trivial matching)[28].因此,在计算过程中,需要避免这样的匹配.2条时序数据之间的相似性可以通过PA A和PA B表现出来,为此,我们定义差异向量来描述时序数据之间的差异.
定义8. 差异向量.对于2条不同时序数据的全子序A和B,则两者的差异向量DiffA B定义为以A为基准的相似性连接向量PA B和A的自相似性连接向量PA A之间差的绝对值,形式化表示为:若
(5)

在时序数据集中,如果同一类的时序数据之间在DiffA B的某些分量上值比较小,而在不同类的数据上值比较大,则可认为相应的子序列是具有较高的类别可分性,是比较好的Shapelets.在第3节中,将详细描述如何使用这些定义提取高质量的Shapelets.
3 Shapelets提取
本文所提出的基于相似性连接的时序数据Shapelets提取主要由3部分构成:1)数据的预处理过程,主要完成对时序数据集的精简工作,只保留对Shapelets提取起关键作用的训练数据以加速后续处理;2)通过计算相似性连接向量、自相似性连接向量及差异向量来生成Shapelets候选矩阵,然后从候选矩阵中提取相对应的子序列,并对这些子序列进行合并操作实现Shapelets提取,这是本文的核心;3)完成时序数据的转换工作,借助已提取的Shapelets将时序数据转换为由距离值构成的特征向量表示.对于时序数据的特征向量表示,使用现有成熟的分类器,如SVM,完成分类工作.本文方法的整体框架及流程如图2所示:

Fig. 2 The overall framework and whole process of the proposed method图2 本文方法的整体框架及流程
3.1 关键时序数据的选择
在时序数据集中,往往存在着一些高度相似的数据,其全子序列集合也非常相近.由于使用相似性连接向量计算差异向量的过程相对复杂,因此,对原始时序数据集进行精简,只选择相似度比较小的关键时序数据进行计算是十分必要的.Wistuba等人[22]基于Shapelets在时序数据集中出现的频率高的假设所做的工作也验证了只选用关键时序数据提取高质量的Shapelets是可行的.
由于在选择关键时序数据时不仅要求整体上有极大的相似度,还需要子序列之间也要高度相似,因此本文使用不具有任何偏移处理的欧氏距离(式(1))计算时序数据间的相似程度.通常情况下,同类别中存在高相似性的数据的可能性大,而不同类之间,时序数据的差异较大.基于此,本文按类别分别进行关键时序数据的选择.对于每一类中的时序数据,使用队列作为核心数据,计算队首时序与其他时序的距离,若距离小于预先设定的阈值,则认为两者有高度相似性,然后提取队首时序作为关键时序数据,而与队首时序相似的时序就可以舍弃.具体算法如算法1所示:
算法1. 关键时序选取算法.
输入:时序数据集dataSet、相似度阈值mthres;
输出:关键时序数据集nDataSet.
①tempDataSet=partitionByClasses(dataSet);
②nDataSet=[];
③ for eachclassDataintempDataSet
④queue=index(classData);*使用队列存储当前类时序的索引*
⑤ whilequeueis not empty
⑥pos=distance(classData,queue,mthres);
⑦queue=remove(queue,pos);
⑧nDataSet=[nDataSet;classData(queue[1])];
⑨ end while
⑩ end for
算法1所消耗的运行时间是很少的.首先,算法在选取关键时序数据时是以类别为单位的,不同类的时序数据间不进行距离计算,这使得参与相似度计算的时序数据条数大大减少.其次,在每次迭代过程中,算法在只保留1条关键时序数据的同时,从队列中删除与之相似的数据,减少了下次迭代过程中参与计算的时序数量.具体地说,若时序数据集(大小为n)的第i类中含有ni条时序,则在最好情况下,所有时序均相似,每一条时序只参与一次距离计算(ni-1次);在最坏情况下,所有时序均不相似,需进行ni(ni-1)2次距离计算,故算法1在处理第i类时序数据时距离计算的次数介于ni-1至ni(ni-1)2之间.因此,算法1的距离计算次数约为n~n(ni-1)2.通常情况下,ni要比n小得多且数据集中存在大量的相似时序数据,所以算法1具有很高的时间效率.
3.2 候选矩阵
候选矩阵(candidate matrix)是本文基于相似性连接策略提取时序数据Shapelets的核心,候选矩阵中隐含着可用于表示类别差异的Shapelets,其值表示相连接的时序在相应子序列上的差异,值越大,对应子序列区分能力越强,因此,可从候选矩阵中快速定位并提取出高类别可分性的子序列.候选矩阵生成的时间消耗是影响算法整体效率的关键因素,如何快速的生成候选矩阵是本文的重点研究内容.
计算候选矩阵的关键是相似性连接,而相似性连接属于全匹配问题,即需要计算出时序数据全子序列集合中每一个子序列在其他集合中的最近邻子序列.候选矩阵的计算分为3个部分:1)计算距离向量,即子序列与时序数据全部子序列间的欧氏距离;2)根据相似性连接策略计算两条时序数据全子序列集合间的最优匹配,得到两者之间的相似性连接向量;3)利用2条时序数据的相似性连接向量和其中1条时序数据的自相似性连接向量构造差异向量,将由同一条时序数据的自相似性连接向量得到的差异向量合并,即可组成候选矩阵.
3.2.1 距离向量的快速计算
距离向量是某一子序列S与一条时序数据T全部子序列之间的欧氏距离构成的向量,其核心是2个子序列距离的计算问题.然而,由于子序列数量庞大,逐个计算子序列间的距离会消耗大量的运行时间,降低算法效率.为此,本文根据Rakthanmanon等人[27]提出的方法,使用式(3)的计算方式,实现子序列与时序数据全子序列集合之间距离的快速计算.式(3)中最关键部分是子序列之间内积的运算,Mueen等人[29]已经证明,借助快速傅里叶变换,可以使得子序列与时序数据全部子序列之间的内积在1次计算中完成.距离向量的具体实现如下:
算法2. 距离向量计算算法distanceVector.
输入:时序数据T及长度m、子序列S及长度l;
输出:S与T的距离向量D.
① [μT,μS,σT,σS]=meanStd(S,T);*根据文献0计算均值方差*
②S′=reverse(S);*将S翻转*
③Ta=append(T,m);*对T扩充,填m个0*


⑥Taf=FFT(Ta);

⑧ST=inverseFFT(STt);
⑨D=distance(l,ST,μT,μS,σT,σS).*根据式(3)计算距离并组成距离向量*
算法行⑧得到的ST是子序列S与T中每一个子序列点积所构成的有序向量,即ST[i]表示S与T中第i条子序列A[i]的点积.因此,在使用式(3)计算距离向量(行⑨)时,只需要从中取出相应的值,而不用每次都计算内积.该算法的一个优势在于算法的时间复杂度与子序列长度无关,这也就不存在最好情况与最坏情况的差异,其主要时间消耗在于傅里叶变换(O(mlbm)),故算法的运行效率高.
3.2.2 提取相似性连接向量
对于2条时序数据T,R(其全子序列集合分别为A,B),可以迭代使用算法2计算A中每一条子序列与R的距离向量.T和R的相似性连接向量PA B就可以通过查找这些距离向量的最小值得到.在计算过程中,本文采用在每次计算距离向量之后更新PA B的方式,逐步得到与T中每一条子序列最优匹配的R中的子序列,记录其距离和位置,具体算法如下:
算法3.PA B提取算法similarityJoinVector.
输入:时序数据T,R及长度m、子序列长度l;
输出:PA B.
①B=allSubseqSet(R);
② initializePA B;
③index=1;*B中子序列索引变量*
④ for eachS∈B
⑤D=distanceVector(T,m,S,l);
⑥PA B=updating(PA B,D,index);
⑦ end for
在算法3中,PA B是以T为基准计算的,每一次的迭代中,算法都更新T相应位置上的距离值,直至B中所有子序列计算完成.这种更新方式的好处是不必开辟内存空间去存储所有子序列对之间的距离,减少了空间消耗.如果算法3的输入中R替换为T,则算法得到的是T的自相似性连接向量PA A,但必须要处理平凡匹配导致的距离为0的问题.本文采用Yeh等人[19]的处理方式,直接跳过相关区域的计算,且不更新PA A中对应位置上的值.图3直观描述了算法3生成PA A的过程.当PA A初始化为Inf后,按顺序计算每一条子序列与T的距离向量并更新PA A,为了方便展示,本文只选取第i条和第j条子序列作为示例来更新PA A.在得到A[i]与T的距离向量(以Di表示)之后,按照逐元素取最小值的策略更新PA A对应位置上的值(图3中第1行和第2行),得到更新后的PA A.当遇到平凡匹配的情况时,即距离向量中值为0的情况,则保留PA A原来的值.对于A[j],思路相同,所不同的是生成的距离向量(以Dj表示)比较的对象是上次更新后的PA A(图3中第3行和第4行).

Fig. 3 The process of PA A updating图3 PA A更新过程
3.2.3 候选矩阵生成
由3.2.2节可知,PA B是以子序列为单位描述两时序数据的,其相似性可以通过PA B与PA A的差值来体现,即差异向量DiffA B.然而由于Shapelets是具有类别可分性的子序列,体现的是类别差异,因此,需要考虑数据集中的全部时序数据,将得到的差异向量进行综合分析,为此,本文将所得到的差异向量进行组合,形成候选矩阵,用于后续处理.
① http://www.cs.ucr.edu/~eamonn/time_series_data/
一个关键的问题是并不是所有时序数据之间的差异向量对于提取Shapelets都是有用的.如果2条时序数据具有相同的类别标识,其差异向量描述的是两者在数据生成过程中的差异,并不是体现不同类别时序数据的本质区别.因此本文以类别为依据,在计算差异向量时,从不同类别中选取时序数据,而同类别时序数据间不进行计算.若某一时序数据集中包含3个类别,分别为Ⅰ,Ⅱ,Ⅲ类,差异向量的计算过程为:从Ⅰ类中选出1条时序数据T,以T为基准依次计算其与Ⅱ类和Ⅲ类中所有时序数据的差异向量.对T与每一类时序数据得到差异向量进行逐点求平均值,得到平均差异向量,将其合并到候选矩阵中,之后对Ⅰ类中的其他数据进行相同的操作.然后再以Ⅱ类中时序数据为基准计算其与Ⅲ类中时序数据的平均差异向量.本质上,平均差异向量从统计意义上表示了T与某一类别时序数据间的不同.候选矩阵生成的具体算法过程如下:
算法4. 候选矩阵生成算法.
输入:关键时序数据集nDataSet、子序列长度l;
输出:候选矩阵M.
①tempDataSet=partitionByClasses(nDataSet);*按类别划分关键时序数据集*
② initializeM;*初始化候选矩阵*
③ for eachcurrClassintempDataSet
④ for eachT∈currClass
⑤PA A=similarityJoinVector(T,T,l);
⑥ initializeZ;*初始化差异矩阵*
⑦ for eachotherclassaftercurrClass
⑧ for eachR∈otherclass
⑨PA B=similarityJoinVector(T,R,l);
⑩Z=[Z;abs(PA B-PA A)];
在候选矩阵生成过程中,需要对数据集中所有的时序对计算PA B和PA A,算法4本身的复杂度较高,但由于本文在预处理阶段借助算法1大大减小了数据集规模,仅使用关键时序数据用于计算,因此,在实验中不会消耗很多的运行时间.候选矩阵中的每一行代表着1条时序数据与另一类时序数据的平均差异,使用平均值的目的在于剔除这一类时序数据之间的差异,只使用共性的特征来提取Shapelets.
3.3 基于候选矩阵的Shapelets提取
从3.2节可知,候选矩阵中的每一个值表示1条子序列与1类时序数据中最优匹配的差异,其值的大小代表该子序列区分能力,因此,Shapelets可以通过提取候选矩阵中较大的值对应的子序列得到.为了更形象地描述Shapelets提取过程,本文首先以2条时序数据为例,展示其相似性连接向量、自相似性连接向量及差异向量的计算过程,提取出能够表示两者之间差异的子序列,然后将其扩展到整个时序数据集上.在差异向量上选取可能成为Shapelets的子序列时,阈值的选择对于Shapelets的数量有很大影响.阈值设置过大,会导致仅有少数子序列构成Shapelets,不能够全面体现时序间的差异;阈值过小,则会使得大量可区分性不明显的子序列也被加入到Shapelets中,这一方面会导致后续处理计算量的增加,另一方面会对分类过程形成干扰.在实验中,本文通过交叉验证的方式来确定合适的阈值.时序数据的Shapelets提取地过程如图4所示.
2条示例时序数据T和R选自于UCR archives①的UWaveGestureLibraryAll时序数据集,且属于不同的类别,如图4(a)所示.假设T和R的全子序列集合分别为A和B,则由算法2得到的PA B与PA A如图4(b)所示.从图4(b)中可以看出,PA B与PA A之间在某些位置上存在着明显的差异,这些差异所对应的子序列就可以将T和R进行区分.图4(c)给出了两者的差异向量,根据其值的大小可以很容易得到有区分能力的子序列所在的位置,如图4(c)中的点P,然后在原始时序数据T中即可将相应的子序列A[P]提取出来.在构成Shapelets时,若子序列位置之间的距离小于子序列长度(如图4(c)中以P和Q开始的子序列),本文将其合并形成Shapelets,如图4(d)所示.
如果由算法1所提取的关键时序数据集中只包含2类数据且每类中仅有1条时序数据,按照图4的流程就是Shapelets提取的全过程,差异向量DiffA B即为候选矩阵.但在一般情况下,数据集中会包含多类,而每类中含有若干时序数据,因此在提取Shapelets时,需要逐行扫描候选矩阵,在每一条时序上均提取子序列,实现算法如下:

Fig. 4 The process of Shapelets extraction between T and R图4 时序数据T和R的Shapelets提取过程
算法5. Shapelets提取算法.
输入:候选矩阵M、子序列长度l、阈值th、时序数据集DataSet;
输出:Shapelets集合SL.
① initializeSL;*初始化Shapelets集合*
② for eachrowinM
③ initializetempSL;
④ fori=1:length(row)
⑤ ifrow[i]>th
⑥subSequence=DataSet(row,i:i+l-1);*提取子序列*
⑦tempSL=[tempSL;[i,subSequence]];
⑧ end if
⑨ end for
⑩tSL=mergeSubsequence(tempSL);
算法5与图4所描述过程本质上是一样的,唯一的区别在于候选矩阵值的计算方式有所不同.假设时序数据集中包含3类:Ⅰ,Ⅱ,Ⅲ类,则多类情况下的Shapelets提取基本过程如图5所示.图5中第Ⅰ类所提取的Shapelets,可以将Ⅰ类时序数据从数据集中区分开来,但并不能将Ⅱ类和Ⅲ类的时序数据进行区分,因此还需要以Ⅱ类时序数据为基准从Ⅱ类中提取Shapelets,此时,Ⅰ类中的时序数据不再参与计算以减少时间消耗.
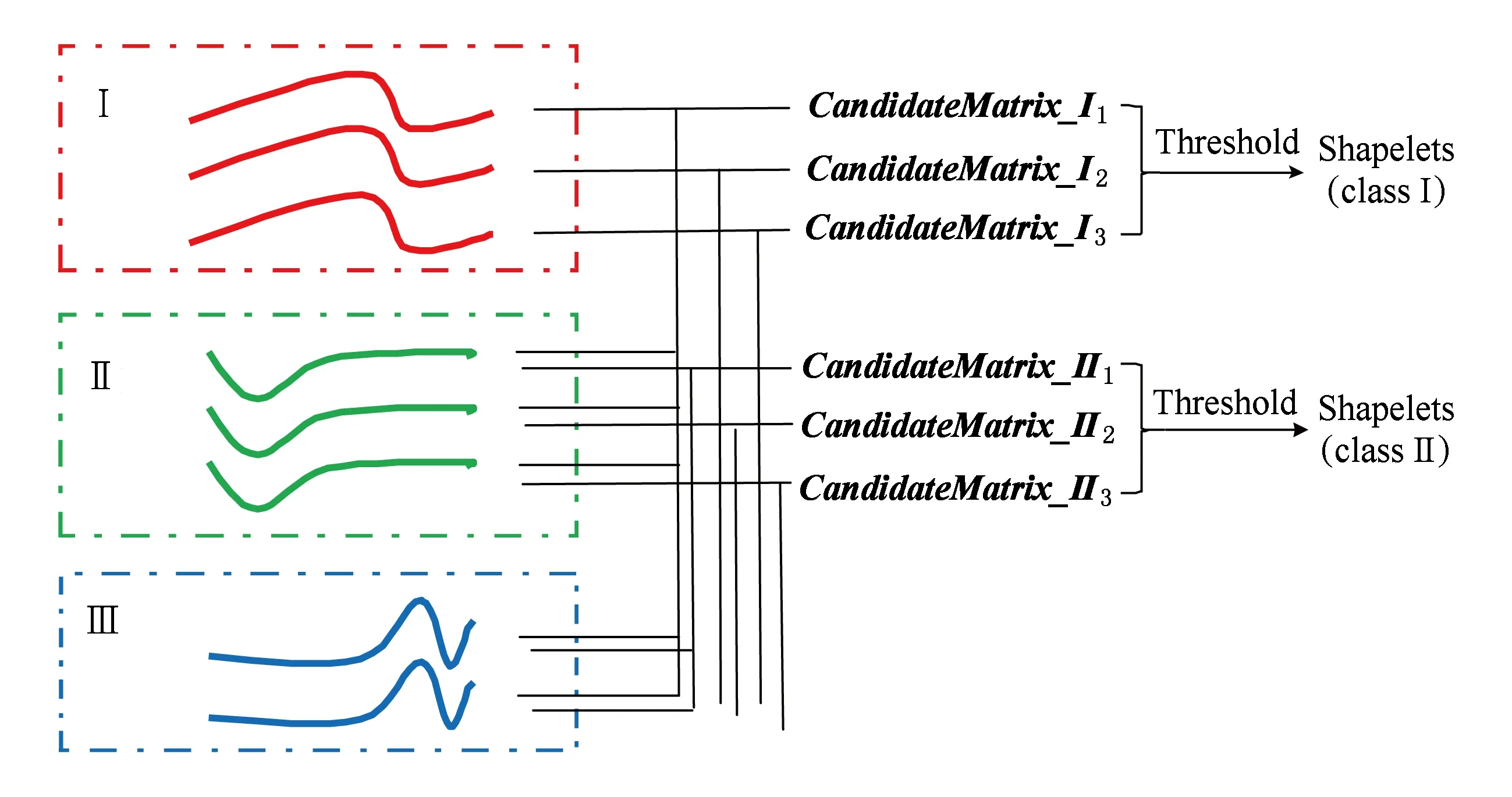
Fig. 5 The process of shapelets extraction图5 Shapelets 提取过程

Fig. 6 The space transformation of time series图 6 时序数据的空间变换示意图
3.4 算法分析
从算法2~5描述过程可以看出,本文所提出的Shapelets提取算法以不同类别时序的差异为基本出发点,从时序数据中提取能够区分不同类别的子序列是一种最直观的方式.与现有Shapelets提取算法不同的是本文直接从子序列的角度描述时序数据间的相似性,其优势在于易于发现时序间差异所对应的子序列.研究的核心在于如何以子序列为基准快速地计算不同类别时序间的差异.本文通过2个方面来加速计算:1)通过选取关键时序数据来减少后续参与计算的时序数量,通过实验验证(5.2节)该步骤是合理和有效的;2)借助傅里叶变换快速完成时序间的相似性连接向量和自相似性连接向量.本质上,本文是通过两两比较来构成Shapelets集合的,这样得到的每一条子序列至少能区分来自不同类别的2条时序,由其构成的集合也能够很好的将不同类别的时序区分开来,因此,算法是合理可行的.
4 时间序列空间变换
在以Shapelets为特征的时序数据分类算法中,决策树是使用最为广泛的分类器,其优点是容易构造,对分类结果有直观的解释,但缺点也很明显.决策树以Shapelets为节点,将数据集不断地进行划分,直至每个子数据集不能再分或者达到某些终止条件.这会导致2方面的问题:如果只使用少数Shapelets构建浅层二叉树,其分类准确率受到限制,并且很多Shapelets具有非常相近的分类能力,不恰当的选择也会导致分类准确率降低;而如果使用的Shapelets太多,树的结构复杂,又会导致运行时间加大.Bagnall等人[30]指出将时序数据映射到特征易于被检测的空间是解决时序数据分类问题的一个好方法,本文借鉴Lines等人[18]的策略,将时序数据映射到Shapelets所构成的空间,形成原始时序数据的特征表示.
图6描述了基于距离运算的空间转换的方法:
① http://www.uea.ac.uk/computing/machine-learning/shapelets/shapelet-data
假设提取的Shapelets数目为k,对于每一条时序数据Ti,依次计算其与k条Shapelets(SL1,SL2,…,SLk)之间的距离(式(2)),将这些距离组合起来形成1个距离向量,该距离向量即为原时序数据在Shapelets空间中的表示.这种表示一方面保持了Shapelets在时序数据分类问题中的优势,因为向量中每一个值都是以Shapelets为单位得到的;另一方面,向量中的每个值都蕴含着时序数据中数据的先后次序关系,因此,向量中各元素之间具有相互独立性,可以使用现有成熟的分类器(本文使用SVM)进行分类.
5 实验与分析
本文通过对时序数据进行分类来验证所提出的Shapelets提取方法的有效性.本节将首先介绍相关的实验设置,包括实验所使用的时序数据集、评价指标以及用于比较的Shapelets提取算法,之后给出实验结果并进行分析和讨论.
5.1 实验设置
5.1.1 数据集
本文使用UCR archives和UEA时序数据集①中的26个数据集来评估方法的性能,这些数据集是目前Shapelets相关研究中普遍使用的数据集[16,25].数据来自于多个领域,包括传感器数据、图像轮廓信息、人体心电图以及动作数据等,数据集的基本信息如表1所示:

Table 1 Datasets Used in the Experiments表1 实验中所使用的数据集

Continued (Table 1)
从表1可以看出,所使用的数据集类型多样:从二分类到多分类,且多分类问题较多,最多可达37类(Adiac);长度不一,最短为24(ItalyPower.),最长为512(Otoliths);训练集和测试集的数据差异也比较大,因此,可以全面的度量算法的性能.为了便于性能比较,本文采用默认的训练集和测试集划分,实验中相关的参数均通过交叉验证的方式获得.
5.1.2 方法对比
本文算法(similarity join for Shapelets extraction, SJS)与目前主要的7个Shapelets提取算法进行性能比较:
1) 标准基于Shapelets时序数据分类算法使用不同的度量指标:信息增益(IG)[13]、Kruskal-Wallis检验(KW)[17]、F-统计量(FS)[17].
2) FSH(fast-Shapelets)[16]算法.将时序数据转换为离散的低维表示,在低维空间中过滤掉大部分子序列以加速搜索的算法.
3) LTS[24]算法.使用梯度下降法从数据中学习出最优Shapelets和分类决策函数的算法.
4) IGSVM[18]算法.首次对时序数据进行空间变换的算法,以信息增益作为Shapelets区分能力度量,使用线性SVM作为分类器完成分类工作.
5) FLAG[25]算法.采用学习优化的策略,使用广义特征向量的方法对时序数据进行降维,进而提取相应子序列作为Shapelets的算法.
上述对比算法的实现均由提出该方法的原作者提供,其参数为作者推荐的设置.
5.1.3 评价指标

Fig. 8 Running time comparison of SJS and N-SJS algorithm图8 SJS算法和N-SJS算法的运行时间对比
对于分类问题,分类准确率是评价算法性能最重要的标准,但对于多种算法在多个数据集上的结果比较,分类准确率难以直观地度量各个算法的性能,因为在很多情况下,某一算法在一数据集上效果很好,但在另一数据集上,分类结果可能较差.因此,本文采用在机器学习领域广泛使用的无参数Friedman测试作为评价算法性能的标准.本质上,Friedman测试是基于分类准确率计算的.在获得K个算法在N个数据集上的分类结果后,对每一个数据集上的K个算法进行排序,分类准确率最高的算法标记为“1”,次高标记为“2”,以此类推,分类效果最差的算法标记为“K”,这样就可以得到N×K的排序矩阵H,其中,hi j表示第i个数据集上第j个算法的标记值.然后,计算每个算法的平均标记值

(6)

(7)
可以用具有K-1个自由度的卡方分布近似.Demšar[31]通过分析前人的工作得出卡方分布是相当保守的近似,提出使用
(8)
作为度量.当实验结果拒绝零假设时,Demša提出将所有算法按照F值分到不同的组,使得同一组内的算法在分类准确率上没有显著差异.这样,不同算法的性能差异可以通过包含平均次序和无明显差异算法组的关键差异图(critical difference diagram)表示.
5.2 提取关键时序数据对实验结果的影响
本节首先验证仅仅使用关键时序数据所提取的Shapelets对于分类结果的影响.图7显示了在表1数据集上使用算法1和不使用算法1的情况下,所提取的Shapelets用于分类的结果对比,其中,N-SJS表示使用全部时序数据时的算法,SJS算法表示仅使用关键时序数据的算法.横、纵轴均以分类准确率为单位.

Fig. 7 Classification accuracy comparison of SJS and N-SJS algorithm for datasets in Table 1图1 SJS算法和N-SJS算法在表1数据集上的分类准确率比较
从表1数据集上的分类结果(图7)可以看出,在绝大多数数据集上,SJS和N-SJS几乎没有区别,即分类结果位于中间对角线附近,说明通过算法1精简数据集后,并没有减弱本文方法提取高质量Shapelets的能力.同时,在部分数据集上,准确率略有提升,意味着冗余的Shapelets也可能导致分类器性能的下降.
另一方面,算法1的主要目的是减少参与计算的时序数据的数量,加速Shapelets的提取,图8是两者的运行时间对比图(纵轴为对数坐标).在绝大多数的数据集上,使用算法1之后,加速效果明显,如在Adiac数据集上的运行时间比为23.6 s∶626.1 s,Chlorine.数据集上为7.7 s∶957.3 s.仅有4个数据集没有加速效果,这是因为这些数据集的训练集本身非常小,且数据之间差异比较大,算法1将所有时序都作为关键数据.但这并没有影响本文算法的效率,因为算法在这些数据集上使用全部时序数据的时间消耗非常小(Coffee:3.5 s,ItalyPower:0.7 s,Sony:0.1 s,TwoLeadECG:0.4 s).
5.3 实验结果对比
本节从分类准确率和运行时间2方面来验证本文算法SJS的性能.
5.3.1 分类准确率
表2列出了本文算法与所有对比算法在各个数据集上的分类准确率.其中,每个数据集上的最优算法以加粗的形式表示,需要说明的是IG,KW,FS这3个方法在部分数据集上运行时间过长,无法在合理的运行时间内结束(超过24 h),标记为“*”.表2的最后一行表示各个算法在不同数据集上具有最好分类效果的次数.从该统计结果上来看,LTS具有一定的优势,在13个数据集上取得最好的分类准确率,本文算法SJS仅次于LTS,在9个数据集上处于领先,而标准的使用IG和KW作为度量标准的Shapelets算法效果最差.
然而,仅从算法在各个数据集上获胜的次数来评价算法性能是不全面的,为此,本文使用5.1.3节的方法来评价各个算法,其结果如图9所示.从该关键差异图可以看出,本文算法与最优的LTS算法差别很小(2.54∶2.35),但与其他算法有比较明显的差别,如其他算法中最好的FLAG算法其平均次序已到3.15.尽管IGSVM算法也在7个数据集上取得最好的准确率,但在平均次序上,与本文算法差距明显(2.54∶3.58).

Table 2 Testing Accuracy of Different Methods on the Datasets表2 不同方法在各个数据集上的测试准确率 %
Note: The results highlighted in bold denote that the method gets the highest accuracy for this dataset and the “*” represents the corresponding method cannot finish in 24 hours.
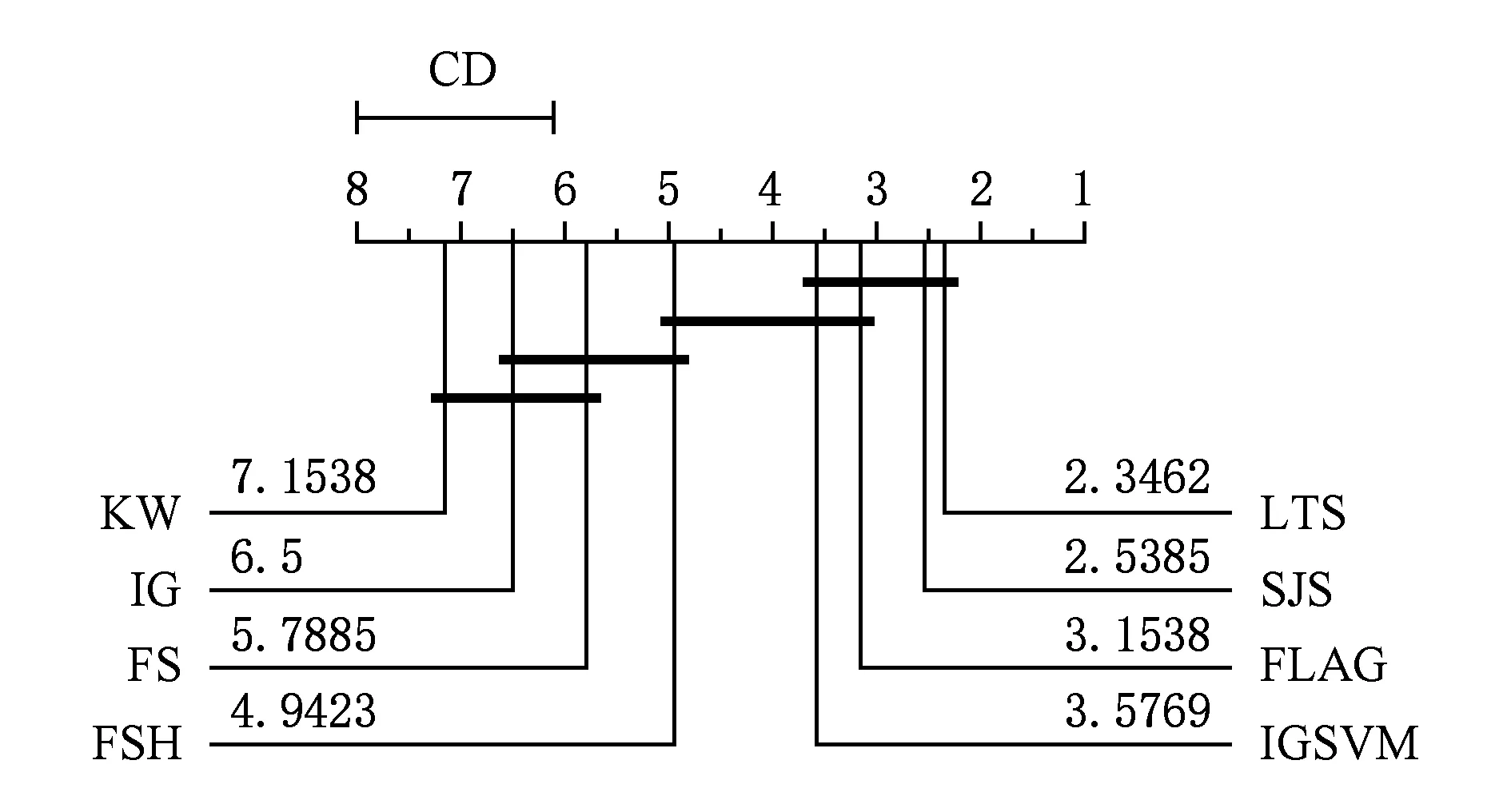
Fig. 9 Critical difference diagram for SJS and other baselines图9 SJS和对比算法的关键差异图
综合上述2方面的分析,可以看出本文所提出的SJS算法具有很好的分类准确率,要优于目前绝大多数Shapelets提取算法.除此之外,SJS的最大优势在于算法的稳定性,在几乎全部的数据集上,SJS都保持很高准确率,而LTS算法则有些波动,如在Adiac和Otoliths数据集上,LTS准确率不足60%.更显著的是,当类别数增多时,SJS优势明显,如在37类的Adiac数据集和10类的MedicalImages数据集上,SJS都要优于LTS.
5.3.2 运行时间比较
对于算法的评价,除了准确率之外,算法的运行时间也是一个重要的评价指标.对于实际应用,如金融、医疗等数据的处理,算法在可接受的时间内得到结果显得尤为重要.本文算法的核心在于时序数据间的相似性连接,子序列与1条时序数据的距离计算借助快速傅里叶变换完成(算法2),其算法复杂度为O(mlbm)(m为时序数据长度),因此,计算2条时序数据相似性连接的时间复杂度为O((m-l+1)mlbm),即近似于O(m2lbm).对于时序数据集,如果要处理所有时序数据对的相似性,算法复杂度会很高,但本文通过算法1提取每类中的关键数据,且相似性连接计算只在不同类的时序数据间进行,使得参与计算的时序条数大大减少,降低了运行时间消耗.
本文算法与其他对比算法的运行时间如表3所示(所有结果均在使用Intel i7 CPU和16 GB内存的计算机上得到),括号中的数字表示算法运行时间在每一个数据集上的排序次序.同表2一样,算法如果无法在合理的时间内完成,标记为“*”,且次序用“(8)”表示.为了方便对比,本文按照式(6)计算每一算法的平均次序,表3中的最后一行Average Rank给出了相应的结果.该统计结果表明:FLAG算法具有最好的时间效率(平均次序为1.2),SJS次之(平均次序为2),标准使用IG作为度量的Shapelets提取算法的时间消耗最多.

Table 3 Running Time of Different Methods on the Datasets表3 不同方法在各个数据集上的运行时间

Continued (Table 3)
Note: The results highlighted in bold denote that the method gets the highest accuracy for this dataset and the “*” represents the corresponding method cannot finish in 24 hours.
虽然运行时间的平均次序能够体现出算法的时间效率,但没有体现具体运行时间差异的大小.从表3中可以看出,尽管FLAG要优于SJS,但在大部分数据集上,两者几乎在同一个数量级范围内,均在几秒甚至更短的时间内得出结果.相反,其他算法则需要很长的时间,特别是准确率最高的LTS算法,稍大一点的数据集都需要几千甚至上万秒的时间消耗.
本节的实验表明:LTS具有最好的分类效果,但运行时间长,尤其在类别数多时,时间消耗大,如在Adiac数据集上,差不多需要24 h的时间;FLAG的时间效率最好,但分类准确率不高,而本文算法SJS不仅在分类准确率上接近LTS算法,而且在运行时间上与最优的FLAG具有同等的数量级.因此,综合分类准确率和运行时间2方面,SJS的实用性更好.
5.4 算法可扩展性
本文以UCR archives中的最大时序数据集之一StarLightCurves来验证算法的可扩展性.该数据集包含3类的“星光”数据,共计9 236条,其中Eclipsed Binaries有2 580条,Cepheids有1 329条,RR Lyrae Variables有5 236条.实验中采用默认的训练集和数据集划分.Shapelets的提取时间主要受2方面的影响:1)时序的长度;2)训练集的大小.本文从这两方面进行实验.由于对比算法IG,KW,FS,IGSVM在StarLightCurves数据集上的运行时间太长,难以获得实验结果,因此,本文舍弃与这些算法的比较.

Fig.10 Experimental results for varying the length of time series图10 时序数据长度变化时的实验结果
首先验证时序长度的变化对于分类准确率和运行时间的影响,具体设置为:固定训练集中时序的数量,将时序的长度从100变化至1 024,以100为间隔单元.实验中,LTS算法受限于时间和空间消耗,在长度大于300时难以得到结果,因而只有3个实验数据.实验结果如图10所示,图10(a)是随着时序长度的增加,各对比算法在测试集上分类准确率的变化,图10(b)是对应运行时间的变化.从图10(a)中可以看出,本文算法SJS受时序数据长度变化影响最小且相对稳定,而其他算法在长度为100和200时,分类准确率很低且在长度增大过程中分类结果有波动,这说明,SJS在提取Shapelets过程中能够很好的发现当前处理的数据集中最具类别可分性的子序列.运行时间对比的结果与表3基本一致,即FLAG具有最优的运行时间,SJS次之,但长度在100~600之间时,SJS要优于FLAG,这充分验证了SJS的主要时间消耗来自时序数据间的相似性连接.

Fig.11 Experimental results for varying the number of training time series图11 训练集时序数据数量变化时的实验结果
其次,固定时序数据的长度为1 024,将训练集中时序数据数量从100增加至1 000,使用默认的测试集.由于LTS算法无法在合理的运行时间内得到结果,所以本实验中仅有SJS,FSH,FLAG这3个算法的结果,如图11所示.与FSH和FLAG在训练集增大时,分类准确率有起伏不同,SJS一直处于上升的趋势,如图11(a),说明当训练集增大时,FSH和FLAG所提取的Shapelets可能会不同,而SJS则会在原有提取出的Shapelets基础上,对新增加的训练集数据提取Shapelets,进而提高分类准确率.这一特性对于优化算法的运行效率更为重要,如图11(b)所示,尽管在同等规模的数据集上FLAG要优于SJS(如图11(b)所示),但SJS在应对数据集变化时可以重用之前结果,能够减少后续计算量,如图11(b)中的SJS-R曲线,因此,SJS有更好的增量扩展性.
6 结 论
本文针对时序数据中的Shapelets提取问题进行研究,提出了基于相似性连接策略的Shapelets提取算法SJS.该方法以子序列为基本单元描述时序数据之间的相似性,通过不同类别的时序数据之间的差异向量构建候选矩阵,然后提取候选矩阵中大差异值对应的子序列构成Shapelets.在大量真实时序数据集上进行分类的实验表明,本文方法所提取的Shapelets不仅能获得良好的分类准确率,还具有很高的时间效率,实用性强.同时,可扩展性实验表明:在训练数据集增大时,本文算法能够增量提取Shapelets,可以减少大量重复计算.
