数据仓库与数据挖掘技术在决策支持系统中的应用
2019-03-21
(天津市机电工艺学院,天津 300350)
当今时代,科学技术日新月异,技术飞速发展的背后是大量科研成果的推出。为了以一个有效的方式管理已有的科研成果,为科研管理者提供快速高效的科研信息获取方式,科研成果管理系统应运而生。传统的科研成果管理多利用数据库将成果数据存储起来。但成果数据与科研项目之间往往存在有价值的关系,这些关系在传统的科研成果管理系统中很容易被忽略。这些蕴含在成果中的关系,对管理人员做出科学的决策有很大的帮助。数据载体广、类型多、存储方式不一等为现阶段研究成果特征,显然,这样不统一的数据类型结构对决策分析和数据应用造成很大阻碍,同时也不利数据的高效使用。而数据仓库可以集成异构的成果数据库,提供面向成果中不同主题的数据。传统的科研成果系统只能单一提取成果信息,而联机分析处理可通过建立多维数据集,对成果信息提供多角度分析。此外,数据挖掘Apriori算法可以对成果数据进行关联分析发现成果之间的关系,为决策分析提供支持。
一、数据仓库与数据挖掘应用现状
(一)数据仓库的应用
数据仓库存储了多种资源的物化视图,目的是给联机分析处理和决策支持提供数据基础。在面向应用的操作环境中提取到的数据存入数据仓库之前,最重要的就是对数据的矛盾信息以及冗余信息进行处理,再进行数据集成。数据仓库对数据的高品质和高效的管理都有深远的影响,这也是数据仓库被广泛研究和应用的原因。
目前国内对数据仓库的研究多应用国外开发的优秀的数据仓库建立自己的数据仓库,已经广泛的应用在了银行,金融,保险,市场零售业中进行风险管理,电子商务和商业智能平台的建造。在电信企业经营分析系统中运用数据仓库技术,建立统一电信数据资源,更好的应对了市场激烈竞争的要求,广东省已经率先建立起完善的基于数据仓库的电信管理系统。数据仓库应用在医院管理系统上也是研究的热点,医院的信息数据仓库将分散在多个部门中的数据,不同管理平台上的报表系统进行集中,建立具有数据整合功能的数据仓库,使得医院的管理系统更加智能。现在数据仓库技术在医院管理系统已经有了较为完善的应用。随着移动互联网的兴起,数据仓库也在逐步与其融合,越来越多的移动供应商开始研究数据仓库技术,帮助开发者对用户的移动端进行分析,并且在移动互联网APP开发中数据仓库也起到了重要的作用。
(二)数据挖掘的应用
1.数据挖掘的定义
最初开始从事数据挖掘的只有50人,而现在数据挖掘正在吸引越来越多的商业、科学团体进行研究。数据挖掘系统发展分为4代,如表1数据挖掘系统四代划分表所示。数据挖掘的出现,解决了对大数据的有效利用,使得各行各业的海量数据得到了很好的利用。国内外对数据挖掘的研究也越来越宽泛,涉及的领域也越来越广泛。
数据挖掘也被称为知识发现(KDD),定义为一种抽取数据库中隐含的,潜在有用的数据如知识规则,约束条件等。最初的知识发现仅在少数实际数据中展开,一个经典的案例就是Buchanan发现的大量光谱规则,还有Michalski在大豆疾病中发现的新的诊断规则。现在对于数据挖掘的研究已经延伸到了智能文本、教育、气象等领域。智能文本数据挖掘系统可以从文本中提取相关碎片让使用者来查询,自动的生成一系列新的查询算法来重组新的文本,输出的结果可以为使用者提供选择主题的新内容,这种工具的规则是基于复杂的启发式教学的。高巨山等提出了挖掘教育数据中其中最重要的被忽视一种模式是基于教育信息化中数据挖掘的研究,在教学和科研工作过程中融入数据挖掘技术来为教育信息化发展做贡献。彭昱忠等提出了数据挖掘技术在气象预报中的应用,解决传统气象预报中遇到的困难,提高气象预报的准确度。

表1 数据挖掘系统四代划分表
2.数据挖掘的过程
问题定义:首先要求技术人员明确数据挖掘任务中的具体要求,了解应用领域相关的内容和用户需求,准确定位数据探索和挖掘对象,确认数据内容,按照挖掘数据对象定位算法。
数据准备:这一部分内容包含数据的抽取数据抽取、预处理、转换等环节。数据抽取就是准备你将要挖掘的数据,因为要进行挖掘的数据不一定集合在一起,也许你要从公共数据库中获得数据。数据预处理就是对抽取到的数据进行再处理,检查数据是不是有完整的结构和数据的结构是不是符合统一的标准,使数据满足进行挖掘的要求,确保数据的一致性和正确性,还要保证所有的数据都经过同样的方式处理。数据转换就是要除去数据中的噪声,对数据进行清洗转换。
数据挖掘的实施:这一阶段就是对数据进行挖掘。这是数据挖掘中重要的一步,你要选择一种算法,你所选中的数据挖掘算法将影响你的数据准备和数据挖掘结果。利用归纳技术如神经网络算法来建立预测模型,用统计分析聚类技术将数据分区存入集群中,识别数据中有用的关联分析,最后检测数据是否能够进行特殊分区中。
结果解释与评估:根据数据挖掘的任务和决策的目的,数据挖掘所获得的数据必须进行结果检验与解释意义。无论多么完美的数据挖掘算法都经过外部数据的检验,才能说明他反应了真实的信息。数据挖掘的时候会产生各种干扰因素,一次挖掘的结果用户可能不满意,也可能出现多余的数据或者与挖掘目的没有关系的数据,因此还要退回上一步,重新开始。为了满足人机交互的需要,对所发现的规则进行可视化,将挖掘结果转换为简洁明了的表示方法,让用户能够理解,增强用户体验。
3.数据挖掘的工具
目前中国业内被广泛使用有三种数据挖掘工具,简单介绍如下:
SAS公司的Enterprise Miner。1997年,SAS发布了Enterprise Miner,为用户提供一个图形化流程化处理环境,这个环境方便建模,而且包含数据挖掘的算法,例如决策树,神经网络,回归,关联等。具有完备的数据探索功能。
IBM公司的Intelligent Miner。Intelligent Miner是IBM开发的数据挖掘软件,包含了算法和可视化工具,可以使用预测模型标识语言来导出数据挖掘模型和可伸缩的数据挖掘算法,并且可以与IBM DB2关系数据库系统集成。它包括Intelligent Miner for Data和IBM Intelligent Miner forText等分析软件工具。
SPSS公司的Clementine。1998年SPSS收购ISL公司,获得了ISL公司的数据挖掘包Clementine,它引入流的概念,在相同工作流中允许用户进行数据清理操作,可以在同一工作流中进行转换数据,甚至是构建数据都能在工作流中完成。
二、决策支持系统
(一)决策支持系统结构
决策支持系统包括面向对象模型库,方法库,知识库,数据库和管理系统,还有联机分析处理和数据挖掘单元,问题过程单元。科学的决策离不开充分的人机交互,只有让计算机理解了人的命令,才能做出符合人需求的响应,人机交互接口是保证决策支持系统能够正常进行的必备条件。决策支持系统体系结构图如1所示。
人机交互系统的主要功能是负责人机交互以及模型计算与数值处理,组织多种模型辅助决策。创造用户体验环境,通过web界面和相应的信息处理机构让用户和计算机进行会话和信息的交互。主要采用的文字和图形界面。
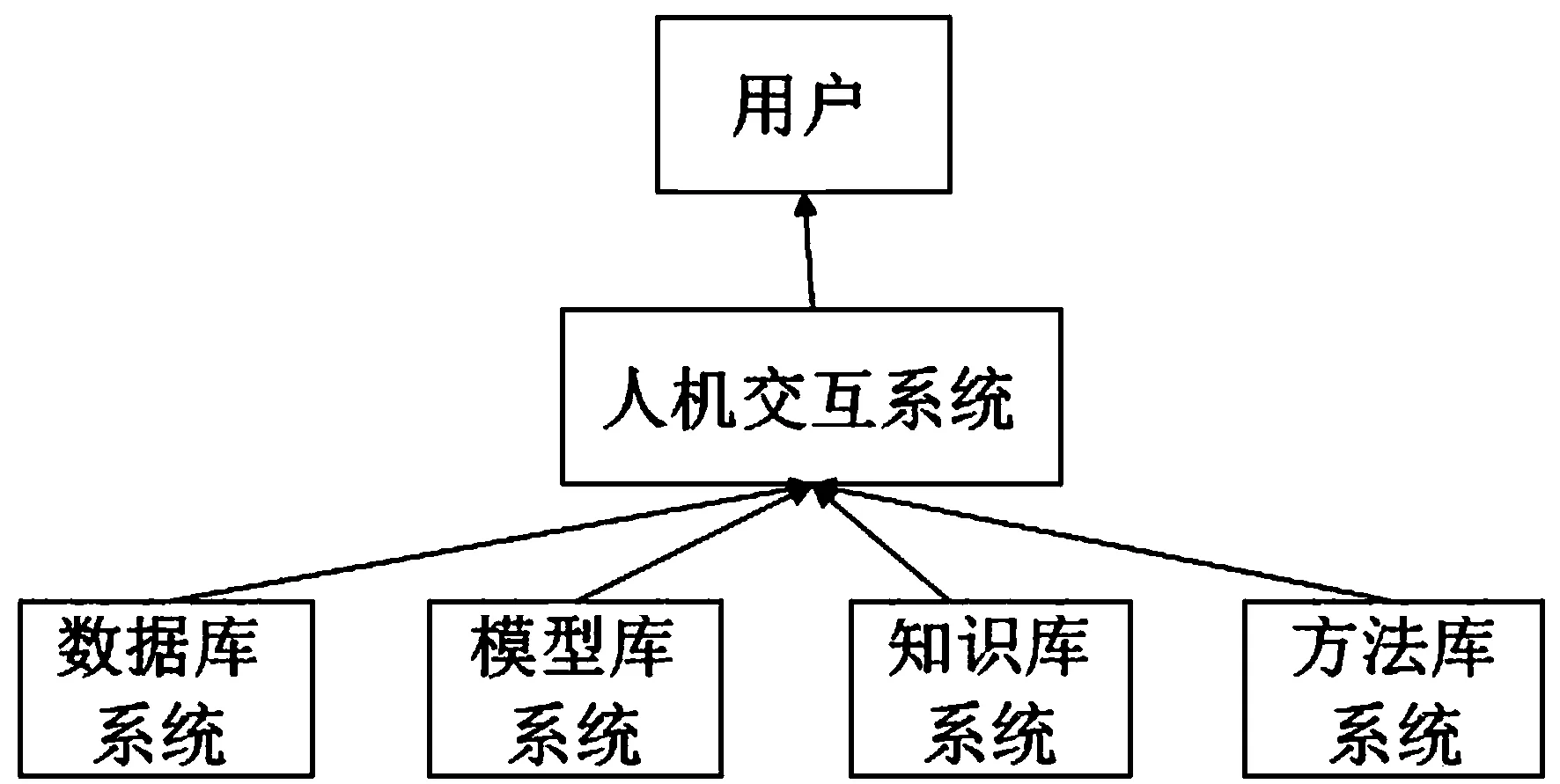
图1 决策支持系统体系结构图
(二)基于数据仓库的决策支持系统
以完整的数据仓库与数据挖掘开发为基础的决策系统主要由三个主体构成。第一个主体是模型库和数据库;第二个主体是存在于数据处理阶段的分析主体,按照顺序有数据挖掘、联机分析处理、数据仓储等。主要反映特征数据经过数据挖掘和相关算法规律处理等被置于仓储库,发现用户可能会有兴趣的知识。第三主体就是用户。用户利用数据挖掘知识,完成分析决策。三大主体相辅相成,相互协同发挥每个主体的特点,实现决策支持。基于数据仓库的决策支持系统体系结构图2所示。

图2 基于数据仓库的决策支持系统结构图
(三)决策支持系统的应用
决策支持系统的应用领域分布在商务智能业务管理,健康医疗和军队等等。任何领域的应用都要结合决策实际。决策支持系统可以解决策略和战略部署问题,面对的都是要求低响应度和高潜在影响的管理。决策支持最经典的例子就是沃尔玛超市发现了“啤酒与尿布”之间的关系,然后将这两种看似无关的货物摆在一起,大大提高了营业额。现在越来越多的商业开始利用决策支持来预测行情,发现规律,帮助管理层做出科学的决定。在医疗领域主要是用在临床专家系统辅助诊断。利用病人和专家系统进行信息匹配与对比分析,以原有的专家医院信息系统为依托,这使得现有的医疗资源得到了最大化利用,而且通过改善资源利用率也降低了医疗成本。在军事领域的决策支持系统,通过存储了海量的战场信息资源和指挥信息等数据,进行战略部署的辅助决策。
三、基于数据仓库的OLAP模型
在当前的研究和背景下,联机分析处理技术充分展现出其在数据挖掘和分析方面的强大优势,其往往在高效分析的基础之上寻找和捕捉事物发展中的异常情况,开辟了数据处理的新的思路和发展前景。在OLAP数据分析的同时,数据库中的数据由ETL处理后进行整理分类归集,这样就非常高效的保证了数据分析的效率。因此本阶段基于此模型下得到的数据立方体更加可靠,一方面在响应速度方面有所提升,另一方面也大大降低了刷新代价。
建立数据仓库的过程中包含着OLAP中所囊括的维和度量。系统选择了支持OLAP功能的SQL Server 2008Analysis Services (SSAS),还包含安全和管理功能选项。利用SQL Server Business Intelligence Development Studio中的AnalysisServices项目模板,建立多维数据集,定义数据源以及建立事实表与维表之间的关系。
根据数据仓库的建立,在建立多维数据集的时候考虑到成果的不同主题,建立以下主题:科研成果类型主题、数量主题、科研成果作者信息主题、科研成果所属项目主题、科研成果完成时间主题、科研成果评估分数主题等等,与数据仓库逻辑模型设计的星型模式相匹配。
OLAP模型支持对数据的切片、钻取、旋转,以及对相关数据的提取可以从多角度进行。这样建立起来的多维数据集可以从不同的角度,选择不同的侧面为用户提供考察成果数据库中的各种与成果有关的数据的操作,获得综合的全面的资料。
切片(slice):在多维数组W(维1,维2,… … ,维X,度量)中选择一维I,并在维I上选择维成员VI,得到多维数组子集WI(维1,维2,…维成员VI … ,维N,度量)成为在维I上的一个切片。
根据定义可知,切片的多少由维中成员的多少来决定。如果将数据立方体切片一次,那么立方体的维度就少了1个单位。切片可以让用户更准确的看到多维数据集中的信息细节,一层一层的剖析,每切一次多维数据集就减少一个维度。选取时间维下的第一季度成果数据,就会在数据立方体中筛选出所有第一季度的成果这就是对该多维数据集进行的一次切片。
切块(Dice):切块指的是在多维数据中选择一个维上的一特定区间的维成员的动作。例如选取第一季度的论文成果维,就得到的数据信息,这就是一个数据切块。切块也是在切片操作之上,再次进行的切片。
旋转(Pivotor Turning):改变数据表中已有维的方向,如将本来在横坐标上的维转移到纵坐标上去或者将纵坐标上的维逆时针转到横坐标上。都是旋转的操作。
钻取(Drilldown):可以将细节都隐藏起来从而得到综合数据的操作是向下钻取,可以得到更多的细节的操作是向上卷取。
OLAP模型对数据仓库中的数据利用MDX(Multidimensional Expression)进行多维查找,可以有效的分析多维数据集。MDX是OLAP的查询语句,语法与结构化查询语言SQL很类似。在成果管理系统中,通过MDX语言,把科研员和决策者需要的成果数据查询出来,展现在前台界面里。
四、基于数据仓库的关联规则挖掘
(一)关联规则相关概念
关联规则(AssociationRules,简称AR)的概念是由R.Agrawal等在1993年提出的。AR是指客体之间的相互关系。形如:A1^A2^…^Ai→B1^B2^…^Bj,,表示目标数据中客体B1,B2,… ,Bj倾向于A1,A2,…Ai一起出现。
项集是一组项。每个项集有大小利用项数来表示。在数据集中有些数据项集出现的频率很高,这些高频项集就是频繁项集。关联规则下挖掘出“发现频繁项集和生成关联规则”两大子问题,前者成为后者挖掘研究的前提和关键。
衡量关联规则兴趣度的两个指标一个是支持度(Support),另一个是信任度(confidece),计算方式如下公式所示。支持度反映了此关联的有用程度,信任度反映了确信程度。例如一个形如X→Y的规则,支持度是指包含X又包含Y的事务的可能性,信任度是指包含X的事务中同时也包含Y事务的可能性。得到的形式定义:
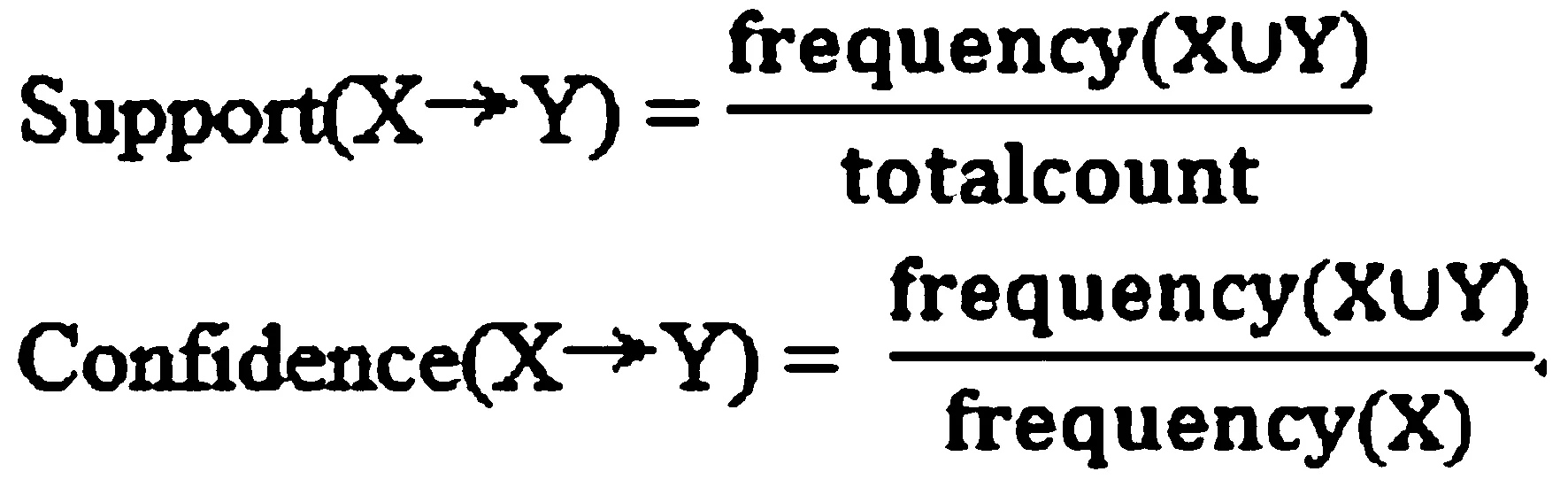
用户可以设置两个阈值来衡量项集出现的次数:最小支持度和最小信任度阈值,如果设计出来的关联规则,通过计算得到的支持度和信任度都小于或等于这两个用户之前设置的阈值,这个规则就是有效关联,因为这两个阈值可以作为一个判断标准。设计关联规则要考虑到以下几点:
1.关联规则满足最小支持度要求是被检测的数据项目集在相应的数据库各事务中出现的最小次数与事务总数的比值。
2.提供友好的操作界面,使得用户可以选择想要进行分析的属性。
3.利用OLAP和Cube来完成关联规则的挖掘。
(二)关联规则的Apriori算法
关联规则中最经典的算法就是Apriori算法,是有Agrawal和Srikant提出的。其中,前者算法的核心概念旨在提升关联规则背景下的结果产生效率。Apriori算法用一种逐层搜索的迭代方法:K项集用于搜索(K+1)项集。首先,找到频繁1-项集的集合,用L1表示,L1用于构建候选项集C2,C2挖掘出频繁2-项集的集合,用L2表示,利用L2构建的候选项集C2去挖掘频繁3-项集L3,按照这个方式循环搜索下去,到频繁K-项集不能被找到为止。
1.Apriori算法描述
输入:数据库D,min_sup=80%;
输出:D中的频繁项集L;

2.Apriori算法的核心
⑴单趟扫描数据库D计算各个1-项集的支持度,得到频繁1-项集的集合。
⑵连接步:通过Lk-1与自身的连接产生的候选K-项集的集合Ck。
设Lk={L1,L2,L3…Li,Lj…Ln},(1≤i≤n;1≤j≤n)
Li={ Li[1], Li[2], Li[3]…Li[m]…Li[k]}(1≤m≤k) Li[m]是项集Li的第m项。Lk中的两个元素是可连接的当且仅当这两个元素但前k-1个元素相同,Li∞Lj={ Li[1], Li[2], Li[3]…Li[m]…Li[k],Lj[k]}, Li∞Lj∈Ck+1。
IV. 剪枝步:只有当子集都是频繁集的候选集才是频繁集,Ck是Lk的超集,Ck的成员可以是也可以不是频繁的,但所有的频繁K-项集都不包含在Ck中,即若Ck-1?Lk-1则Ck?Lk就要在候选K-项的集合Ck中删除候选K-项集。
⑶通过单趟扫描数据库D,计算各个项集的支持度,将不满足支持度的项集去掉。通过上述分析可以看到,Apriori算法要多次扫描数据库,会浪费时间,而且也会产生大量的候选集,增加了工作量。对于成果数据来说,有些数据属性会出现相同的情况,每一次都扫描数据库,对于相同的属性值的重复扫描就造成了时间的浪费,所以可以采用减少候选项集的方式修改算法。将第一次扫描数据库产生频繁项集后,通过频繁项集与数据库的对比,删除掉无用的数据信息,形成新的候选项集,循环往复,以此来判断候选项集中的项集能否成为新的频繁项集,以此为基础,计算支持度,获得关联规则。
五、总结
分析调研大量成型的科研成果,强调做出大量需求分析,整理出数据仓储的相关知识,建立相关知识储备库,为技术的处理和应用创造一个联机的载体和条件,运用数据的挖掘和分析处理技术进行算法原理的研究,继而建立了在数据仓库研究理论基础上的模型,为创建数据仓库系统奠定基础。
开发系统应用的主要技术包括OLAP和Apriori两种实用算法,将OLAP和Apriori算法结合运用于实际的系统开发中,提升了数据运算效率,拓宽了数据运用的范围,运用决策分析智能化的目标性,做到了整体化提升科研成果和决策的实用性。两种技术的同时应用到一个系统中,有一定的理论与实际创新性。数据挖掘技术需要更加深入的与科研管理进行融合,开发出更加有价值的,能在更短的时间内挖掘更多数据信息的应用平台。
