基于商品评论主题模型的隐含狄利克雷分布研究
2019-03-20方兴龙
周 梁,方兴龙
(1.安徽工程大学 计算机与信息学院,安徽 芜湖 241000;2.安徽工程大学 生物与化学工程学院,安徽 芜湖 241000)
网络发展到了2.0阶段以后,用户的日常购物行为由实体店拓展到了线上网店。中国电子商务研究中心发布的《2018年(上)中国网络零售市场数据监测报告》显示:2018年上半年国内网络零售市场交易规模达40 810亿元,同比增长 30.1%[1]。随着电子商务发展,大量与用户所购商品相关的内容(比如商品质量、服务水平、物流状况等)即大量商品评论信息随之产生。如何将众多的非结构化的评论提炼加工,生成用户和商家共同关心的有价值信息,成为商品评论文本情感分析的工作重点。
1 概述
商品情感分析是对商品评论信息进行分析和处理,处理过程分为以下几步:①中文分词。目前常用的中文分词工具有:哈尔滨工程大学的LTP语言技术平台;中科院汉语语法分析系统ICTCLAS[2];清华开发的具有中文分词和词性标注的中文词法分析工具包THULAC;可用于python中文分词组件结巴分词[3]。②去除常用词、低频词及使用频率高但无意义的词。比如:“在这价位的车油耗水平还是满意”转变成“价位 油耗 满意”。③文档特征词选取。常用方法如词袋模型[4]及TF-IDF[5]。④情感信息抽取并建立文档空间向量模型,也就是文本分类算法,因为无监督学习方法从而避免了人工标注的耗时、成本昂贵的问题,所以目前广泛使用。主要包括情感分析(Vector Space Model,VSM)[6]算法、(Latent Semantic Analysis,LSA)[7]算法、概率潜在语义分析模(Probabilistic Latent Semantic Analysis,PLSA)[8]算法等,VSM算法将文本转换成高维向量,从而计算任意两个向量的近似程度,但该种方法没有考虑到词与词之间的语义联系;LSA算法[7]可以通过词-文档矩阵进行奇异值分解,将文档投影到潜在语义空间中,但该算法具有奇异空间计算量过大的问题,通过点积和余弦相似度计算文档与原文档相似性的方法不适用于不同领域文章相似度的计算。比如“灌水”和“网贴”两词,可能出现在两篇IT方面的文本中,但词项不匹配,故两词相似度很低,但“灌水”一个出现在IT文章,一个出现在工程类文章,则被看做相似。PLSA算法在LSA基础上结合了数学概率模型,该算法包括文档d的概率,潜在语义Z的概率和生成术语概率三个方面,该算法虽然将文档、语义和词项映射到同一个语义空间,合理解释了“一词多义”现象,但不足在于随着文档线性增长,其输出结果分布矩阵和主题分布矩阵是唯一的,故该算法迭代的潜在语义概率无法重新生成一片新文档,处理文档方式不灵活。Blei[9]等提出了潜在狄里克雷分配模型(Latent Dirichlet allocation LDA),该模型设定每篇文档由隐含的多个主题组合构成,主题的结合分布由Dirichlet分布随机产生,每个隐含主题描述为词汇集的分布,即构成文档、潜在语义、术语三层贝叶斯模型。这样多个词语可以映射到同一主题,一个词语也可以属于不同主题,解决了多词一义和一词多义的问题。LDA模型属于全概率生成模型,适合处理大规模语料库。近几年,针对LDA模型又有多人提出改进其算法[10-11]。如孙艳[12]提出的USTU模型,在原有的LDA基础上添加情感模型,即假设所有词由一种情感产生,建立“文档-情感-句子”关系,同时对词进行主题标签采样,建立“文档-主题-词”关系,但是句子中出现两种情感倾向时无法做出进一步判断。欧阳继红[13]在原有Joint Sentiment-topic Model(Reverse-JST)模型基础上提出改进的MG-R-Jst模型,同时阐述了Reverse-JST可以通过不同主题粒度下主题与情感的分布关系,但仅考虑单词局部情感/主题分布,因而缺少稳定性,而MG-R-Jst模型则考虑两个粒度上的情感/主题分布—文档级和局部,以期提升分类效果和稳定性,但其隐含的变量众多,需频繁利用Gibbs采样对其参数进行估计;武庆圆[14]等提出用户特征与文本主题的情感之间存在一定联系,并构建包含用户特征主题的UMSTM模型,但未能就用户特征包含的内容及其如何提高后期预测效果做进一步阐释。
2 问题描述
在购物过程中,消费者根据他们对于商品及服务的主观判断做出购买决策,而购物后的“知觉评论”反过来又会影响其他消费者的消费决策。所以,对于消费者的“知觉评论”的分析和挖掘会远远大于商品本身的特性。另一方面,对于商家来说,不会仅仅关心商品的总评价度,而是想更大程度了解产品的细节评论,所以单纯从产品“好评率”或“差评率”来评价商品质量会造成分析粒度过粗的问题。因此“情感分布”要包含用户评论文本和曾经购买或浏览信息,以及曾经与商家的互评信息。另外,用户对商品的评论还与用户的兴趣有关,而兴趣随时间变化而变化,如新产品上市,由于其新颖款式、新元素及新技术的引入,用户关注度会提高,而随着产品问世时间推移,用户兴趣度会降低,甚至遗忘,所以需要构建用户兴趣与“时间”序列的数据模型。
3 “显式评论”与“隐式评论”
商家推荐系统是基于用户的历史行为,分析、挖掘用户的行为偏好,从而提供个性化商家推荐。评分是用户综合考察多方面因素给出的整体评价。其中,商家获得用户兴趣最直接的方式中——“显式评分”就是用户曾经购买商品的评分,评分总量反映了商品或服务的热度。比如电影在线评论数量和最终票房呈正比关系,所以评论“极性”会存在一定局限性;有些低评分不是用户对此类商品不感兴趣,而是商品服务质量问题,也就是历史评分存在的“观点”和“情绪感知”分析粒度过粗的问题。特别是电商评论的差评中,要进一步分析差评原因及用户的观点究竟是什么。同时,为了更好解决协同过滤推荐算法中普遍存在的数据稀疏性问题,研究引入“隐式评论”,即将用户喜好加入评论范畴。因为在实际生活中,有些商品的分类是基于人们对某一类商品的现实需求的,比如,用户如果喜欢载重不大的小型汽车,就会在紧凑型车型中寻找自己喜好的商品。通过统计分析MovieLens用户评分数据[15]发现,每位用户对不同类型电影的评分数差异很大,但用户喜好的电影类型较集中,尤其是单个用户更为明显,通过对某类电影所有的评分求和,再求平均值,可以直观地看出某位用户对各种类型的喜好程度。
4 时间序列评论机理
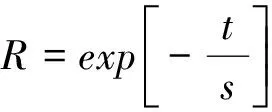
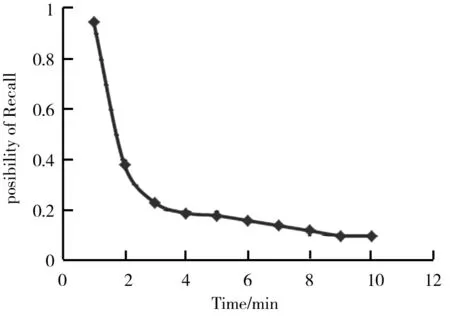
图1 遗忘曲线图
5 模型建立
5.1 用户情感分布模型
考虑到用户对产品的兴趣度对产品的影响,将用户评分内容划分为两部分:显评分(基于用户历史评分行为)和隐评分(基于用户偏好信息)
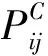
(1)
参照Koren[17-18]提出的矩阵分解方法,有:
(2)
其中,Ui是用户特征向量;Vj是物品特征向量。用户特征向量和物品特征向量分别服从均值为0的高斯分布Ui
(3)
(4)
5.2 用户评论-主题矩阵模型
隐评分模型引入主题时间tur在用户-主题的分布概率,设产品发布时间为tur,评论文本集Wu={Wu1,Wu2,…,Wuq}中第m个文本Wum的时间标记为tum,则用户记忆值
mv(Wum,tum)=e-λ(tur-tum),
(5)
式中,λ是时间参数,默认大于0,时间参数越大,记忆值下降越快。那么用户的评论-主题矩阵可用相应记忆值标记。
可得主题时间tuk在用户-主题分布概率R(tuk)
(6)
由式(1)、式(2)、式(6),可推导出式(7)
(7)
6 UIB-LDA模型的建立
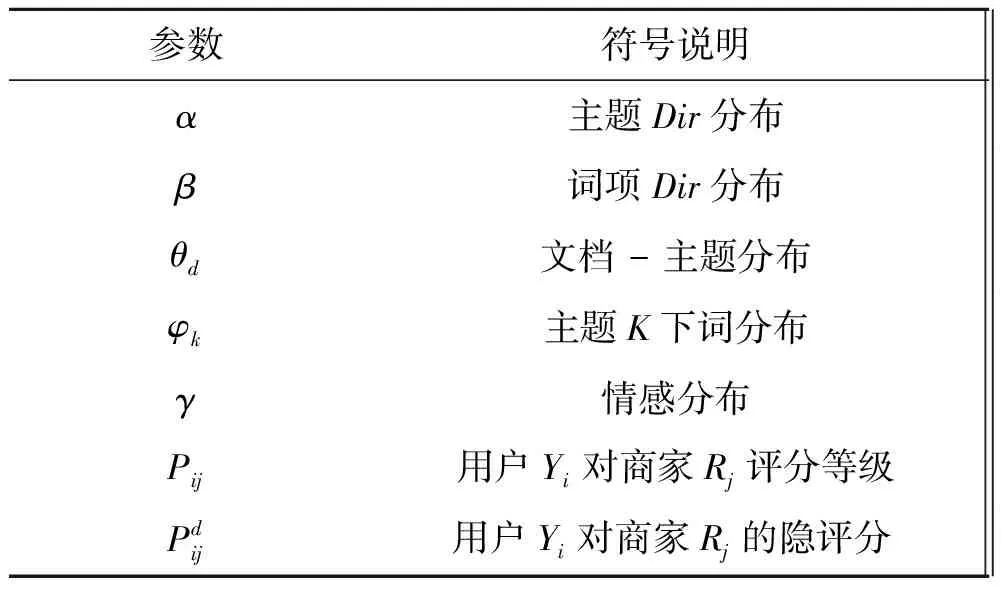
在原有LDA基础之上引入了用户显评价和隐评价,从而构建了User Interesting Based-LDA(UIB-LDA)模型如图2所示。UIB-LDA模型的各符号说明如表1所示。
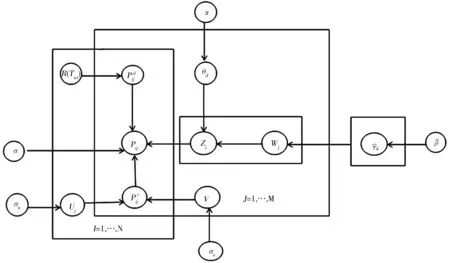
图2 UIB-LDA模型
7 测试对比研究
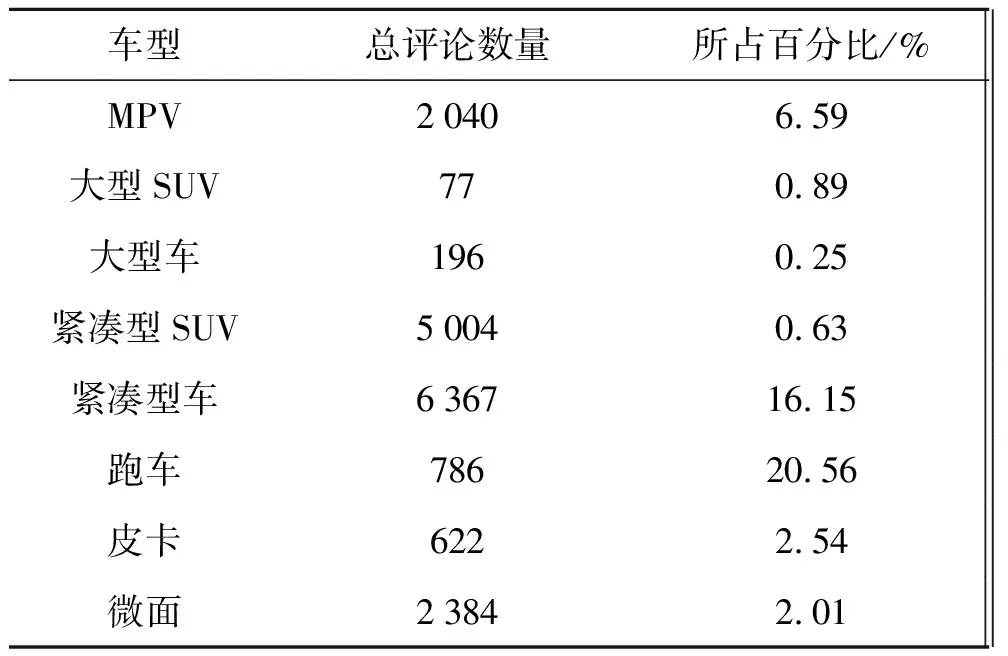
检验使用的数据集采集自“汽车之家”购买及用户评价数据,利用基于python语言的Scrapy框架编写爬虫,应用python的Celery库实现分布式消息队列。本次以关键字“汽车之家”采集购买及评价报告的数据,时间跨度为2014~2017年,共计4年。接着进行数据清洗并采用python的jieba分词库对商品评论数据进行中文分词,分词结果如表2所示(其中已过滤标点及特殊字符),检验中使用中文停用词去除停用词。同时,从评论数据数量发现,当汽车价格超过80万时,在线评论数量明显减少,这正符合经济学的价格和需求呈负向关系的论证;另外对于汽车价格低于6万的商品评论数量也相对较少,分析原因中考虑消费者在选择汽车这种商品时的态度较为慎重,观念中普遍存在价格代表价值的意识。因此本次选择评论数据,会剔除价格大于80万及价格低于6万的汽车商品评论数据。经过筛选,共过得30 975条在线评论数据,其在线评论数量与百分比如表3所示。
(8)
式中,Wi为测试中的单词;Ni是单词总数量。

表2 汽车评论分词结果
表3汽车类型数量及百分比
LDA和UIB-LDA模型迭代次数与主题数对比如图3所示。由图3可以看出,在迭代次数相同情况下,采样时的平均迭代时间随着主题数目的增长而增长。与LDA相比,UIB-LDA模型的迭代次数随主题数增加增长速度明显低于LDA模型。这是因为LDA模型采样时,需要对所有主题进行采样,UIB-LDA模型只需要对文档对应标记的主题和背景(全局)主题进行采样。
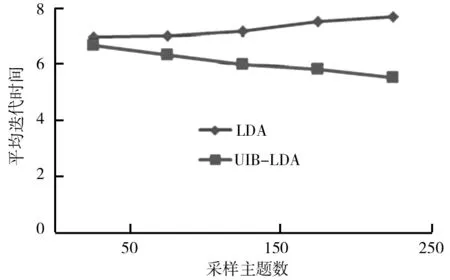
图3 LDA和UIB-LDA模型迭代次数与主题数对比
另外,本次实验还用了用的评价准则的查准率(Precision)和查全率(Recall)。查准率是挖掘出的正确评论信息占总有效评论信息的比例;查全率指挖掘出的正确评论信息占总评论信息的比例。查全率与查准率是反向相关的,正确评论的个数减少会导致查准率增高及查全率降低。因此,实验选取准确率和召回率的综合评价指标F值进行验证。相应计算公式如式(9)、式(10)、式(11)所示:
Precision:
(9)
Recall:
(10)
综合评价指标:
(11)
验证结果如图4所示。研究选取了UIB-LDA模型与LDA模型进行对比,测试样本数目k以样本数目40~200测试其查全率、查准率,并用F值。从图4可以看出,由于UIB-LDA模型不是针对所有的主题进行采样,所以与普通LDA模型相比,其查准率和查全率均优于后者。但测试过程中也发现,随着采样数量的增长并超过一定数量时(比如超过160),查全率及F值会呈现下降的趋势,由此可以得出采样数量控制在40~160之间较理想。
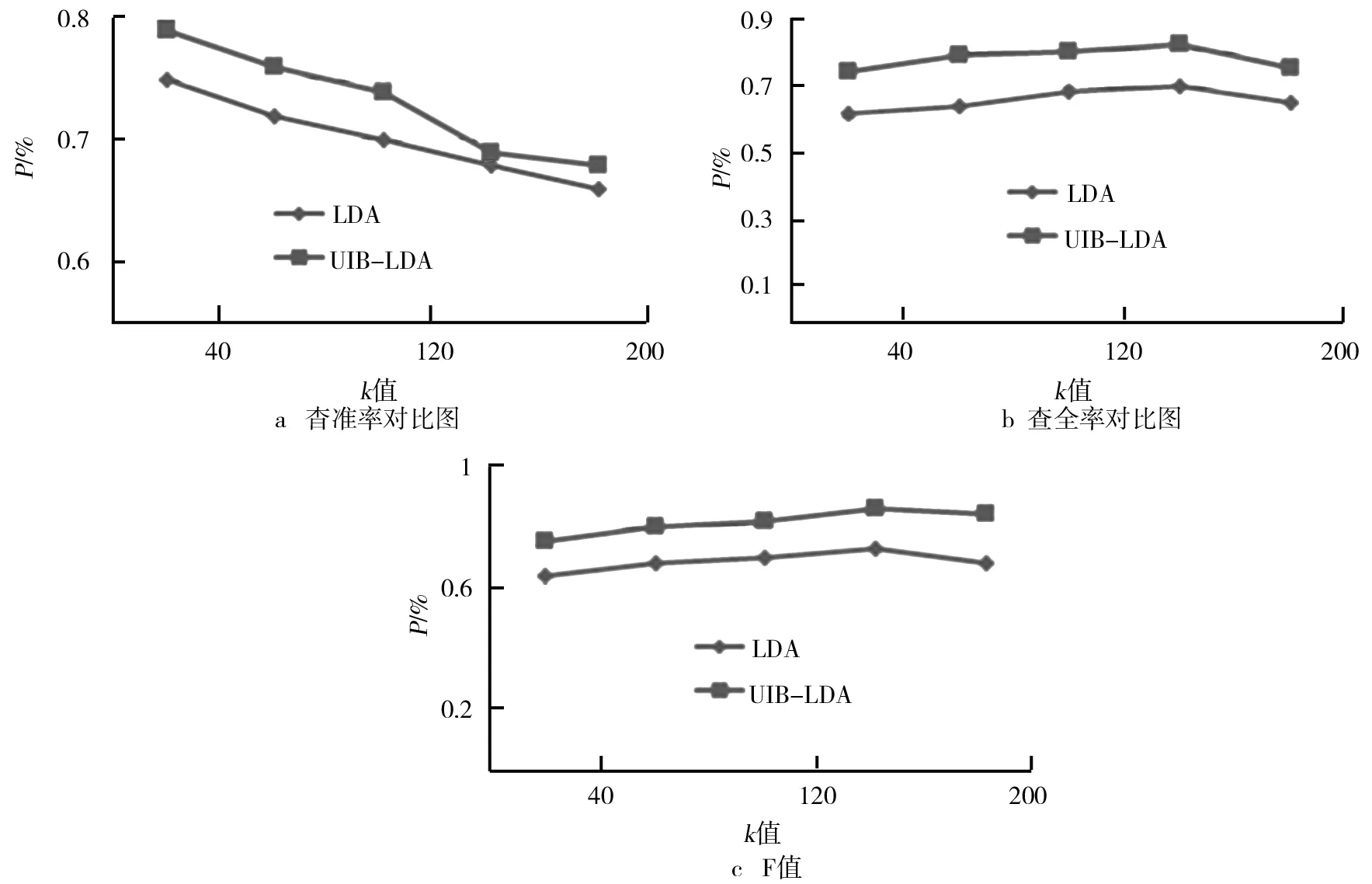
图4 情感分类效果对比图
8 总结
研究主要是以汽车购买评论作为数据研究背景,在原有LDA模型基础之上,针对用户的“知觉评论”对用户购买行为的影响,将用户评论商品的信息及其与商家互评的信息纳入情感分布,同时关注到用户兴趣度随时间推移呈现下降趋势的规律,构建了UIB-LDA模型。通过实验验证,发现当采用数量取值控制在一定范围内时,该模型平均迭代时间较低,查全率、查准率以及综合评价指标均优于LDA。将UIB-LDA模型应用于短文本话题且意见领袖的微博文本是今后研究方向。
