基于关键区域的井下人员轨迹挖掘方法
2019-03-20顾优雅
赵 端 ,顾优雅 ,张 雨 ,冯 凯
(1.中国矿业大学 物联网(感知矿山)研究中心,江苏 徐州 221008;2.中国矿业大学 信息与控制工程学院,江苏 徐州 221008;3.矿山互联网应用技术国家地方联合工程实验室,江苏 徐州 221008)
为确保井下安全生产和井下人员安全,国家安全生产监督总局明确要求井下必须安装人员定位系统[1]。但从实际使用状况看,该系统只能实现定位器周边定位,人员的实际轨迹分布、异常轨迹并无法有效获取。因此,如何在现有定位系统上增加人员轨迹的分析功能是煤矿企业亟待解决的问题之一。
研究人员针对地面上移动对象的定位数据研究取得了一定的成果。如LO Alvares等[2]首次提出利用驻足点对轨迹数据进行语义建模,节约计算时间;袁冠[3]对人员活动进行建模,提出多粒度周期活动发现方法;吕绍仟等[4]提出基于轨迹结构的热点区域发现框架筛选出移动对象活动的热点区域。这些研究表明,对地面上的定位数据进行分析能挖掘出移动对象定位信息隐藏信息。由于矿井下特殊的环境,直接利用地面上的轨迹挖掘方法存在如下问题:①井下条件恶劣造成定位数据大量缺失,无法像地面一样形成大量连续的轨迹;②矿井环境的特殊性,使得井下巷道的行走规则有局限性。针对上述问题,提出基于关键区域的井下人员轨迹挖掘框架(Key Location-based Trajectory Mining,KL_TM),该框架利用井下定位数据生成不同工种的矿工日常轨迹并筛选出异常轨迹。首先利用筛选、过滤、降噪等预处理手段剔除原始数据中不符合规定的点,之后利用KL_TM框架发日常轨迹和异常轨迹。KL_TM框架由关键位置发现(Key Location Discovery,KLD)和移动对象轨迹挖掘(Trajectory Data Mining,TDM)组成。
1 基于KLD的井下关键位置发现
井下关键位置是轨迹中特殊语义的点,井口是轨迹密集的位置,但井口对整体轨迹并没有太大的实际意义。因此,关键位置发现算法首先用人员语义划分轨迹,再用拐点[5]和驻足点[6]对定位数据进行筛选,提取轨迹中重要语义点形成关键位置序列。
2 基于关键位置的人员轨迹挖掘方法
关键位置发现算法只考虑了每条轨迹的关键位置特征,没有考虑到整体结构,因此移动对象轨迹挖掘从整体出发对轨迹进行挖掘,主要分为2个部分:①关键区域的选取;②井下人员轨迹的挖掘,包括日常轨迹的发现和异常轨迹的检测。
2.1 关键区域的选取
由于矿井下定位数据噪声点多,密度不均匀,采用DBSCAN聚类算法[7-9]对轨迹数据聚类。TDM算法中利用改进的DBSCAN算法来优化DBSCAN无法识别多密度的缺点。算法主要根据数据集中点间距离进行排序,动态识别第MinPts个点组成近邻矩阵,计算矩阵的密度变化率,通过设置密度变化率阈值筛选出不同的簇DLSi,之后利用式(1)计算每个簇的聚类半径Eps。
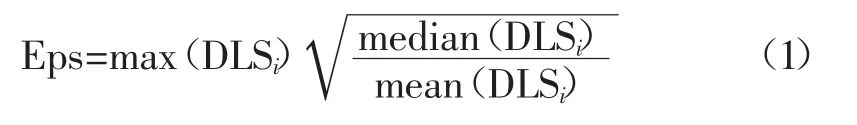
式中:EPS为簇DLSi的聚类半径;max(DLSi)、median(DLSi)、mean(DLSi)为分别表示簇DLSi距离的最大值、中值以、平均值。
经过上述操作,将原本零散的关键位置聚类成关键区域序列,表示为 C={C1,C2,…,Cn}T,其中 Ci包含关键位置{KL1,KL2,…,KLm}T,m 是聚类簇的数量。
2.2 井下人员轨迹的挖掘
井下人员轨迹的挖掘包括日常轨迹的发现和异常轨迹的检测。矿井下同一工种的矿工轨迹呈现出规律性和统一性,因此可以利用聚类中心点对关键区域C进行抽象选取,将点的集合转化成点的表示方法,还原了移动对象的日常轨迹 A={a1,a2,…,at}。
属性特征上偏离大多数轨称为异常轨迹,乘坐装物料的运输工具、擅自脱岗等都是违规的行为,这些行为会导致矿工的轨迹发生改变,形成异常轨迹。本文采用Hausdorff方法[10]检测轨迹的异常。
3 算法性能比较
选取某矿井采煤工、综掘人员、安检员各10名,记录其6个月的定位数据,标记为DS1、DS2、DS3。其中 DS1有 27 602个轨迹点,DS2有 28 392个轨迹点,DS3有12 748个轨迹点。
计算不同的参数对改进的DBSCAN算法和DBCSAN算法准确度的影响,结果如参数对DBSCAN算法的影响见表1。从表1中可以发现,2种算法识别异常轨迹的能力相同,但改进的DBSCAN总体相似度明显高于DBSCAN,这表明改进的DBSCAN算法的比DBSCAN算法的聚类精度更高,识别出的轨迹点间耦合度更高。

表1 参数对DBSCAN算法的影响
利用改进的DBSCAN算法对数据集进行优化,对比筛选前后轨迹点个数,检测前后轨迹点个数的比较见表2。从表2中可以得出:KL_TM框架能筛选掉约1/4的数据点,且随着定位点数目的增多,删选出点的个数越多。

表2 检测前后轨迹点个数的比较
综上所述,改进的DBSCAN算法保持了DBSCAN的优点且能有效地识别多密度区域;其次,筛选出约1/4没有语义的点,节约程序运算时间,提高了精度。
4 案例分析
某采区示意图如图1,其包含3条主要大巷(西区运输大巷、辅助巷、回风巷)和1个工作面,长方形图标表示监控站。本次实验总共收集井下6个月定位数据,共68 742个轨迹点。
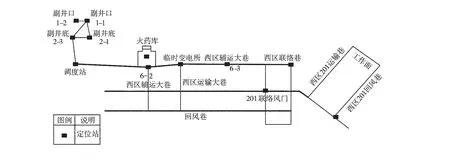
图1 某采区示意图
利用KL_TM框架分析后形成的综采队矿工的轨迹如图2。图2(a)是日常轨迹,利用Hausdorff距离对综采队员工的轨迹进行差异度分析,将差异度大于350的轨迹可视化,结果如图2(b)。
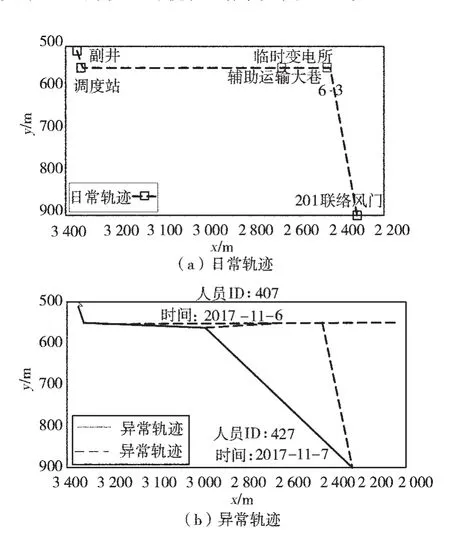
图2 采煤工的日常轨迹与异常轨迹
图2(a)中方块表示的是矿工日常轨迹中的关键区域。从结果发现,井口被聚类成1个簇;西区辅运大巷6-2,调度站和临时变电所在西区辅运大巷这一条巷道上,所以用调度站和临时变电所表示采煤工人的前进路线。从图中可以直观地判断采煤工人的日常轨迹符合井下的采煤作业流程。
图2(b)是根据图2(a)中的日常轨迹进行筛选,轨迹上标注了产生该轨迹的人员ID和时间,方便管理者及时对矿工的行为轨迹进行管理。从图中可以看出人员ID为427的员工直接从201联络风门到西区辅运大巷6-2,该矿工可能是直接通过西区运输大巷到达西区辅助大巷6-2。而员工ID为407的员工则在2017年11月6日走到了原本不该经过的西区联络巷。
5 结语
提出的基于关键区域的井下人员轨迹的挖掘框架(KL_TM)由KLD算法和TDM算法2部分组成。KLD算法利用拐点和驻足点删除约1/4的定位数据同时将定位数据变成关键位置序列;TDM改进DBSCAN算法,动态识别聚类的半径,改善DBSCAN算法需要调参的缺点,将关键位置序列聚类成移动对象的历史位置序列,从而识别出移动对象轨迹的关键区域,最后利用聚类中心挖掘出移动对象的日常轨迹,通过日常轨迹的异构性发现异常轨迹。通过矿井下的数据集证明KL_TM框架能有效的发现矿工的日常轨迹和异常轨迹,改善了原来井下定位系统只能显示人员位置的缺陷,提高井下人员管理水平,最大限度地保证矿工的安全。
