情景修正与认知重评策略的ERPs
2019-03-18李颖洁
郭 城, 李颖洁
(1. 上海大学通信与信息工程学院, 上海200444; 2. 上海大学生物医学工程研究所, 上海200444)
情绪调节是一个人适应社会环境、拥有健康身心与幸福生活的重要指标. 众多精神疾病患者经常表现出情绪紊乱的现象[1], 因此如何有效地调节情绪至关重要. 在日常生活中, 人们经常会使用不同的调节策略来降低、保持或提高情绪体验[2], 从而有效地管理情绪. 研究发现,如果个体经常使用分心、认知重评、反思或社会分享等策略, 能对情绪产生积极的影响; 而习惯于沉思或抑制行为表达的个体, 会增加消极情绪心理[3]. 然而, 在这样的社会心理现象的背后存在怎样的生理机制还是研究者一直关注的话题.
1998 年, Gross[2,4-5]提出了情绪调节动态模型, 认为情绪调节是一个不断循环的、动态变化的过程, 包括情景选择(situation selection)、情景修正(situation modification)、注意分配(attentional deployment)、认知改变(cognitive change)和反应调整(response modulation)5 个阶段. 在这个过程中, 不同的情绪调节策略会对个体情绪的产生、心理体验与行为表达施加不同的影响[4]. 针对调节策略, 近20 年的研究工作主要集中在注意分配、认知改变和反应调整阶段, 而很少有人会关注情景修正阶段的策略研究. 究其原因可能为: ①情景修正发生在情绪产生的早期阶段, 对于情景的选择和修正的界线较难划分, 并且当个体努力地改变某个情景的同时, 会进入另外一个情景[4]; ②情景修正改变的是外部环境, 即物理环境, 而认知改变的是内部环境, 即认知[6], 因此在实施策略时情景修正策略与认知重评策略容易混淆在一起.近期Gross 建议, 建立一些有效的情景修正对研究情绪调节动态过程是很有必要的[5]. 本工作设计了一种指导性(instructions)情景修正策略, 并预期这种策略可以有效降低负性情绪体验.
有关情景修正最初的解释是关注问题的处理或初步控制的过程[7-8]. 人们可以采取具体的措施来改善自身的体验, 例如身处于浪漫的晚餐情景中, 你可能会叫服务员将位置换到壁炉旁边, 或者订购一瓶香槟来为晚餐添加情趣[6]. 通过一系列情境的处理来修正事件的情景, 从而改变情境对情绪的影响, 构成一种重要的情绪调节方式, 这便是情景修正[4]. 研究表明, 在情景修正阶段, 情绪事件发生之前个体通常会进行资源的积累, 并不断地期望和评估潜在的威胁,从而做出相应的策略来应对[6]. 本实验在指导情景修正策略时要求被试者在情绪刺激呈现时,对所看到的情景(外部环境)进行修正, 而所修正的画面是期望看到的场景, 如当刺激的画面是一个堆满垃圾的生活场景时, 人们通常期望的是垃圾被清理掉的情景, 故被试者可以仅仅去想象垃圾被清理的画面. 与情景修正策略相比, 认知重评策略的发展已相对成熟. 认知重评是指为了降低情绪的影响而改变个体对情绪事件的理解和事件意义的认识[5], 如被试者可以认为那个堆满垃圾的地方原本就是一个垃圾场. 大量的认知心理学和神经影像学研究表明, 认知重评策略可以有效地改变情绪体验、生理活动和行为表达[2], 在调节负性情绪时可以有效抑制大脑杏仁核的活动, 并激活前额和顶叶的活动[9].
根据情绪调节的动态模型, 这2 种策略应该都处于先行关注时期(antecedent-focused), 即情绪反应发生之前的时期[5]. 情景修正是对情景的选择做出自我控制, 并对注意资源的分配做准备的, 因此应在早期对情绪产生影响[10]; 而认知重评涉及对情绪刺激的初步评估构建, 之后才做出重新解释, 其对情绪的影响相对较晚[11]. 然而, 情景修正在干预情绪产生的过程时是否比认知重评更早, 目前还缺乏实验依据.
事件相关电位(event-related potentials, ERPs)是从头皮表面记录到并以信号过滤和叠加的方式从脑电中分离出来的一种电生理信号, 能直接反应神经元的活动, 并同步检测神经元电位的变化过程[12]. 在情绪调节策略的ERPs 研究中, 晚期正电位(late positive potential,LPP)一直是人们关注的热点问题, 是一个在情绪刺激约300 ms 之后出现的正电位慢波, 在顶区附近的峰值最为明显[13]. 研究发现, 情绪刺激相比中性刺激能诱发出更大的LPP 幅值, 并且LPP 对认知重评的情绪调控策略非常敏感, 当认知重评有效改变人们对负性情绪的体验时总是伴随着顶区附近LPP 的降低[14]. 更重要的是, LPP 是一种能够可靠地反映情绪变化的电生理指标, 可以用来描述情绪活动的时间特性[12]. 近期的研究发现, 在情绪调节时重评策略对LPP 的调制会比分心策略更晚发生[15]. 这些结果都较好地从电生理机制的角度解释了情绪调节动态模型的时间特性.
综上所述, 本工作采用ERPs 技术, 以情景修正策略与认知重评策略设计实验, 比较情景修正和认知重评策略在“下调”(down-regulating)负性情绪时的时间动态特性. 本工作提出假设: ①情景修正与认知重评在调节负性情绪时都能有效地降低情绪体验; ②与认知重评相比,情景修正能够更早地干预到情绪的产生, 表现为更早地对LPP 进行调制.
1 材料和方法
1.1 研究对象
为了避免性别在情绪调节中的差异, 本工作招募了26 名在校女大学生参加实验, 年龄范围在18∼25 岁(M=20.88, SD=2.42, 其中M 为均值, SD 为标准差). 所有被试者均利右手、视力正常或校正正常. 经焦虑自评量表(self-rating anxiety scale, SAS)测试, 被试者标准评分均小于50 分; 抑郁自评量表(self-rating depression scale, SDS)测试, 被试者标准评分均低于53 分, 即SDS 评估均符合要求, 被试者在实验前无焦虑和抑郁症状, 无神经损伤史、家族遗传史、药物和酒精滥用史. 由于实验中2 名被试者因数据漂移严重提前终止实验, 4 名被试者因可用数据段过少而被剔除(有效段数<60%), 故最终对20 名被试者的数据进行分析. 所有被试者在实验前均自愿签署了知情同意书, 实验结束后给予适量报酬.
1.2 情绪刺激材料
本实验的刺激材料全部取自国际情绪图片系统(International Affective Picture System,IAPS)[17]. 120 张彩色情绪图片中, 30 张中性图片, 情绪效价(M=5.10, SD=0.38), 唤醒度(M=3.14, SD=0.47); 90 张负性图片, 情绪效价(M=2.55, SD=0.52), 唤醒度(M=5.75,SD=0.81), 并将其随机分为3 组, 每组的30 张负性图片分别用于简单注视负性、情景修正负性和认知重评负性图片的实验任务, 3 组负性图片之间的效价和唤醒度均无显著差异(所有概率p 值大于0.2).
采用美国PST(Psychology Software Tools)公司提供的E-Prime 2.0 软件编写实验程序.为避免外部环境及电磁信号等信息干扰, 实验时被试者在封闭隔音房间中进行测试.
1.3 实验流程
首先, 被试者进入实验室, 完成实验知情同意书; 随后, 在清洗头发后佩戴32 导电极帽,此时实验人员会简单地向被试者解释脑电实验的相关原理, 以缓解被试者的紧张心理. 在完成佩戴电极帽后进行预实验, 实验人员向被试者解释4 种实验任务各自代表的含义(6 trials).当指导语提示“注视”负性或者中性图片时(2 trials), 被试者仅需要直观地感受情绪刺激图片,如果提示“情景修正”(2 trials), 则当刺激呈现时, 被试者需对所看到的场景进行外部环境的修正, 修正的画面是其希望看到的场景[6], 例如当呈现的是一个火灾现场时, 被试者可以想象大火被扑灭的情景; 如果提示完成“认知重评”任务(2 trials), 被试者需对所看到的场景做出认知上的改变, 如被试者可以认为这个场景只是一个电影特效而不会有人员伤亡[14]. 随后,指导实验操作流程(12 trials), 为了确保被试者充分理解不同策略之间的差异和各自的含义,在每张图片呈现完之后被试者需要向实验人员口头汇报其采用各种情绪调节策略时具体的心理活动[16]. 在熟悉实验流程后, 提醒被试者实验注意事项, 如被试者双眼与屏幕距离应保持在50∼80 cm 之间, 实验期间要避免抖腿、头部倚靠座椅、视线回避等行为. 在给予被试者2 min 的静息时间后, 正式开始实验并记录脑电数据.
将实验所需的120 张图片(120 trials)分为6 组(6 blocks), 每组20 张图片, 包括简单注视中性图片(5 trials)、简单注视负性图片(5 trials)、情景修正负性图片(10 trials)或者认知重评负性图片(10 trials), 即6 个block 中有3 个block 包含认知重评负性图片的任务,另外3 个block 中包含有情景修正负性图片的任务, 这样设计的目的是为了避免在同一个block 中出现2 种策略而造成概念的混淆[15]. 每个block 中的20 张图片都被随机呈现, 且每位被试者的block 顺序也做随机处理, 在每个block 结束后会有1 min 的短暂休息, 使被试者能调整状态, 按任意键后开始下一个block 的实验.
实验中每个trial 的组成如图1 所示. 先显示2 000 ms 任务提示信息, 如显示“认知重评”,即提醒被试者随后出现的图片应该使用认知重评策略来做出调整. 紧接着出现1 000 ms 的间隔, 期间屏幕中心会出现一个黑色的“+”, 其目的是为了将被试者的视线聚焦到屏幕中间, 之后会呈现一张与之前任务提示所对应的情绪图片, 持续5 000 ms, 在这期间要求被试者在图片开始呈现时便使用相应的任务做出反应; 当情绪图片消失之后, 屏幕上会出现提示语“请根据自身的真实感受对图片评分”, 要求被试者对情绪效价进行按键评分, 评分等级为1∼9 (1 为极度消极, 2 为非常消极, 3 为比较消极, 4 为有一点消极, 5 为中性, 6 为有一点积极, 7 为比较积极, 8 为非常积极, 9 为极度积极), 当被试者对效价进行评分之后, 会出现另一个提示语“请根据自身的感受强度对图片评分”, 要求被试者对情绪唤醒度进行按键评分, 评分等级从1∼9, 即从“极度平静”到“极度强烈”由弱到强依次递增[17]. 在被试者完成对唤醒度按键评价后, 会出现2 000 ms 的淡灰色空白图片, 其目的是消除trials 之间的影响[18], 至此一个trial 完成. 整个实验大约持续35∼40 min, 被试者在实验期间有任何疑问都可向实验人员询问, 并且有权在任何阶段因个人原因而终止实验.

图1 实验范式Fig.1 Paradigm of the experiment
1.4 数据采集与预处理
本实验使用了武汉格林泰克科技公司生产的37 导电极帽, 以NeuroScan 4.3 系统记录脑电图(electroencephalography, EEG)信号, 电极分布遵循国际标准10-20 系统; 在采集数据时以右侧乳突作为参考, 用眼电图(electro-oculogram, EOG)记录水平眼电和左侧垂直眼电, 电极与眼睛距离约2 cm. 数据采样频率为1 000 Hz, 低通滤波为70 Hz, 电极和头皮之间的阻抗小于5 kΩ.
当离线分析时, 转参考电极为左右乳突平均参考, 使用Scan 4.3 将眼电伪迹去除, 低通滤波20 Hz, 同时剔除幅值不在±150 µV 范围内的信号, 分段时以刺激前500 ms 作为基线, 所有被试者可用trials 在63.3%∼91.7%范围之内. 采用Matlab 2014a 完成后续电极的取得和分时间窗、trials 平均叠加等处理.
相关研究表明, LPP 的最大峰值主要分布在顶区Pz附近[12], 因此本工作选择P3, Pz,P4 电极信号的均值来分析LPP. 本工作将LPP 划分为早、中、晚3 个时期, 其中早期400∼1 600 ms, 中期1 600∼3 200 ms, 晚期3 200∼4 800 ms. 采用统计分析软件SPSS 20.0, 通过重复测量方差分析(repated measures analysis of variance, RMA)对LPP 不同的时间窗进行统计检验. 所有主效应的p 值都采用Greenhouse-Geisser 进行校正, 如果任务与时间窗存在交互效应, 则进行简单效应分析, 多重比较的p 值采用Bonferroni 进行校正.
2 结 果
2.1 行为学数据
本实验在简单注视中性、简单注视负性、情景修正负性和认知重评负性图片4 种任务状态下, 要求被试者分别对每张情绪刺激图片进行效价和唤醒度的评分, 结果如表1 所示.4 种任务经RMA 法分析, 效价评分: 任务有主效应(F 检验的统计量值F(3,57)=110.12, 概率p<0.001, 偏η 方=0.85), 简单注视负性图片与简单注视中性图片相比, 效价有显著差异(t(19)=16.27, p<0.001); 情景修正负性图片和认知重评负性图片相比于简单注视负性图片, 效价评分都显著升高, 分别为(t(19)=6.98, p<0.001; t(19)=6.54, p<0.001); 但是情景修正负性与认知重评负性这2 个策略间并无显著差异(t(19)=0.44, p>0.5). 唤醒度评分: 任务有主效应(F(3,57)=96.79, p<0.001,=0.84), 事后比较发现, 简单注视负性图片与简单注视中性图片相比, 唤醒度有显著差异(t(19)=11.67, p<0.001); 情景修正负性和认知重评负性图片相比于简单注视负性图片, 唤醒度评分都显著降低, 分别为(t(19)=6.93,p<0.001; t(19)=5.29, p<0.001); 情景修正与认知重评这2 个策略的评分有显著差异的趋势(t(19)=2.64, p=0.097), 这说明情景修正负性与认知重评负性都影响到了被试者对情绪效价和唤醒度的判断.
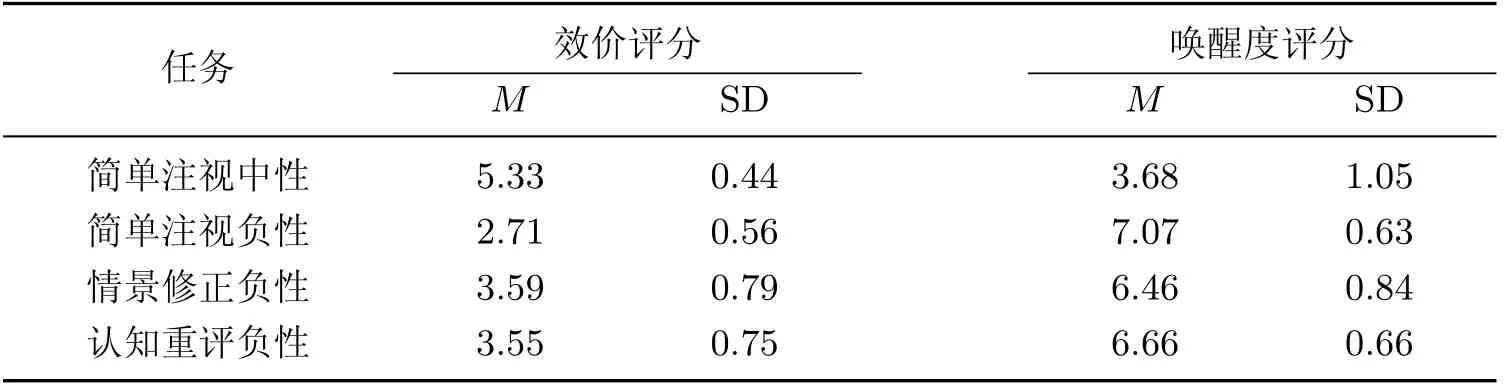
表1 情绪体验评分Table1 Self-reported feelings
2.2 LPP
根据之前相关研究, 在整个刺激呈现阶段, 不同任务对于LPP 的调制作用应该是不同的.为此, 使用RMA 法对400∼5 000 ms 时间窗的不同任务LPP 的均值做统计检验.
如图2 所示, 在400∼5 000 ms 时间段内有任务主效应(F(3,57)=7.51, p<0.001,=0.28). 经配对样本t 检验发现, 与简单注视中性(M =4.95, SD=3.66)图片相比, 简单注视负性(M =9.17, SD = 4.39)图片诱发了更大的LPP(t(19) = 3.81, p<0.01); 与简单注视负性图片相比, 情景修正负性(M=5.59, SD=3.24)图片显著降低了LPP 的幅值(t(19)=1.96,p<0.01); 然而, 简单注视负性与认知重评负性(M=7.01, SD=2.71)之间LPP 的幅值只有显著差异的趋势(t(19)=1.96, p=0.065), 表明对负性刺激的调节方面, 情景修正负性与认知重评负性在整个时间(400∼5 000 ms)内对LPP 的调节作用是不同的.

图2 不同任务状态下顶区P3, Pz, P4 电极处LPP 平均波形图Fig.2 Event-related potentials following the neutral pictures viewing,negative pictures viewing,modification of negative pictures and reappraisal of negative pictures at parietal(P3, Pz,P4) recording sites
2.2.1 LPP 早期(400∼1 600 ms)
根据Gross 情绪调节的时间动态模型[4], 本工作希望不同的调节策略对LPP 的影响发生在不同的时期. 将LPP 早期阶段进一步划分为3 个等间隔的时间窗, 即根据RMA 法进行分析:4 任务(简单注视中性、简单注视负性、情景修正和认知重评负性)×3 时间段(400∼800, 800∼1 200, 1 200∼1 600 ms).
分析结果显示, 任务有主效应(F(3,57)=10.59, p<0.001,=0.36), 时间有主效应(F(3,57)=24.02, p<0.001,=0.56), 并且任务与时间有交互效应(F(6,114)=2.76, p=0.02,=0.13), 进一步进行简单效应分析显示, 与简单注视负性相比, 情景修正负性时LPP 的幅值在800 ms 开始显著降低(见表2).
同样, 简单注视负性与认知重评负性相比, LPP 的幅值在早期的3 个时间段内均无显著差异(p>0.1), 结果如表3 所示. 此外, 在早期简单注视中性时LPP 的幅值均显著低于简单注视负性(p�0.001), 而情景修正负性与认知重评负性之间的LPP 幅值并无显著差异(p>0.1).
2.2.2 LPP 中期(1 600∼3 200 ms)
同样, 根据RMA 法进行分析: 4 任务(简单注视中性、简单注视负性、情景修正负性和认知重评负性)×4 时间段(1 600∼2 000, 2 000∼2 400, 2 400∼2 800 和2 800∼3 200 ms).
分析结果显示, 任务有主效应(F(3,57)=7.23, p<0.001,=0.276), 时间窗有主效应(F(3,57)=7.43, p=0.006,=0.281), 任务与时间无交互作用(F(9,171)=1.55, p=0.18,=0.075). 针对任务主效应, 对整个时期(1 600∼3 200 ms)不同任务的LPP 均值做配对样本t 检验, 结果显示, 与简单注视中性(M =3.91, SD=4.21)相比, 简单注视负性(M =8.11,SD = 4.43)诱发了更大的LPP 幅值(t(19) = 3.46, p = 0.003); 与简单注视负性相比, 情景修正负性(M =4.24, SD = 3.35)显著降低了LPP 的幅值(t(19)=4.32, p<0.001). 更值得注意的是, 与简单注视负性相比, 认知重评负性(M =5.67, SD=2.84)时LPP 的幅值显著降低(t(19)=2.24, p=0.037), 表明认知重评负性对LPP 有调制作用, 出现的时间比情景修正负性晚. 另外, 情景修正负性和认知重评负性这2 个策略间LPP 的平均幅值无显著差异(t(19)=1.67, p=0.11).

表2 早期(400∼1 600 ms)简单注视负性与情景修正负性各时间段LPP 的均值(标准差)比较Table2 Means(standard deviations)for pair-wise comparisons between negative-view and negativemodification at each 400 ms time increment within the early stage (400∼1 600 ms) of the LPP

表3 早期(400∼1 600 ms)简单注视负性与认知重评负性各时间段LPP 的均值(标准差)比较Table3 Means(standard deviations)for pair-wise comparisons between negative-view and negativereappraisal at each 400 ms time increment within the early stage (400∼1 600 ms) of the LPP
2.2.3 LPP 晚期(3 200∼4 800 ms)
与中期时间窗的划分类似, 根据RMA 法进行分析: 4 任务(简单注视中性、简单注视负性、情景修正负性和认知重评负性)×4 时间段(3 200∼3 600, 3 600∼4 000, 4 000∼4 400 和4 400∼4 800 ms);
分析结果显示, 任务有主效应(F(3, 57)=5.24, p=0.004, η2p=0.22), 时间有主效应(F(3,57)=4.83, p=0.013,=0.20), 任务与时间无交互效应(F(9, 171)=0.90, p=0.51, η2p=0.045).针对任务主效应, 对整个时期(3 200∼4 800 ms)不同任务的LPP 均值做配对样本t 检验, 结果显示, 与简单注视中性(M=5.72, SD=3.70)相比, 简单注视负性(M=10.33, SD=6.78)诱发了更大的LPP 幅值(t(19)=3.01, p=0.007); 与简单注视负性相比, 情景修正负性(M=5.43,SD=4.65)显著降低了LPP 的幅值(t(19)=3.20, p=0.005). 然而, 晚期简单注视负性与认知重评负性(M=7.75, SD=3.46)LPP 的幅值之间无显著差异(t(19)=1.55, p=0.138), 表明认知重评负性对LPP 的调制作用仅出现在中期, 而在晚期这种调制作用不再显著. 更有趣的是,简单注视负性和认知重评负性2 个策略间的LPP 幅值在晚期存在显著性差异(t(19)=2.37,p=0.029).
3 讨 论
尽管神经心理学相关研究已经表明, 情景修正负性是一种非常有效的情绪调节方式[6],然而却很少有相关的电生理研究, 并且其脑机制和时间动态特性还不明确. 为此, 本工作以Gross 情绪调节动态模型为基础设计实验, 采用ERPs 技术从时间特性的角度比较2 种情绪调节策略对负性情绪刺激加工产生的影响.
从行为学角度分析的结果显示, 被试者在负性图片呈现时使用情景修正负性或认知重评负性策略, 都能显著增加效价评分, 且降低对负性情绪的唤醒度, 说明2 种策略都影响了被试者对情绪属性的自我评估和唤醒程度判断. 从另一个角度来说, 2 种策略都能有效地降低负性情绪体验, 这与本工作预期结果是一致的. Gross 认为, 在认知改变阶段人们会有选择性地去解释看到事件的意义和认知(“增强”“维持”或“降低”), 这些选择会改变人们对情绪反应的趋势, 进而影响人们的情绪体验[2]. 本工作当被试者在实验中有选择性地去修正所看到的画面时, 可能会改变被试者的注意资源的分配, 进一步改变认知从而影响情绪的体验, 这也符合动态模型的过程, 在一定程度上说明本实验设计的情景修正是有效的. 但是, 从行为学角度分析的结果往往带有一定的主观意识, 实验的有效性与策略的时间动态特性需进一步通过ERPs 结果加以论证.
ERPs 的结果显示, 与简单注视中性相比, 负性刺激能诱发出更大的LPP 波幅(400∼5 000 ms), 其中情景修正负性时LPP 显著降低, 而认知重评负性时则仅表现出显著降低的趋势, 这表明2 种策略对情绪的影响是不同的, 主要体现在刺激呈现的不同时间段. 正如本工作预期, 情景修正负性对LPP 的调制出现的相对较早, 大约在8 00 ms 阶段开始; 而认知重评负性对LPP 的调制出现在中期1 600 ms 阶段. 此结果暗示, 情景修正实施发生在被试者对情绪刺激持续的评估之前, 因而能更早地对情绪进行干预. 进行类似的研究, 在考察分心和认知重评的时间动态特性时, 分心策略的实施早于认知重评, 其原因是分心策略改变了个体对情绪事件注意资源的分配, 从而抑制了认知的评估过程[15]. 与此相比, 本实验中情景修正在早期介入的是外部环境, 因此这可能改变了认知的评估过程而不是抑制. 另外还发现, 相比于简单注视负性, 情景修正对LPP 的调制作用不仅出现在早期800∼1 600 ms 阶段, 还包括中期1 600∼3 200 ms 和晚期3 200∼4 800 ms 阶段, 而认知重评对LPP 的调制作用仅出现在中期1 600∼3 200 ms 阶段. 这是一个很有趣的结果, 按照Gross 的说法, 即当个体努力地改变某个情景的同时, 会带入另外一个情景[4], 因此新带入的场景可能会导致被试者对情绪事件注意资源的转移, 进而评估的是这个新的资源. 当然, 这只是一个初步的推论, 未来的研究可以关注情景修正负性和分散注意力策略的时间动态特性.
LPP 对情绪图片的刺激是敏感的, 其情绪效应对低水平的感知特性并不明显, 如刺激的大小或图片背景的复杂性[19]. 因此, 作为一种处理情绪的稳定指标, 本身能表现出负性情绪刺激比中性刺激诱发更大的LPP 幅值[12], 本工作同样也证明了这一点. 此外, LPP 的调制过程也被认为是一个高级认知的加工过程. Hajcak等[12]认为, 在指导认知重评策略时LPP 的调制与情绪体验评分密切相关, 即LPP 的降低反映了情绪调节的过程, 且往往伴随着情绪体验评分的降低. 在本实验中, 与认知重评负性一样, 情景修正负性降低了LPP 的幅值, 并且也伴随着情绪体验评分的降低, 这进一步说明了本实验的有效性. 值得注意的是, 尽管2 种策略的差异性较好地体现在了情绪调节的时间动态过程当中, 但是这种差异并未体现在行为学分析的结果中, 即并未发现2 种策略在效价评分上的差异, 而只是在唤醒度评分上二者有显著差异的趋势(p=0.097), 情景修正负性的评分要降低更多一些, 这似乎只能说明情景修正后, 被试者对负性情绪的感受强度更小, 这种趋势是否是因为2 种策略在时间特性上的差异而造成的还有待进一步研究. 此外, 本实验重点比较情景修正与认知重评对负性情绪刺激加工产生的影响, 因此目前还无法确定在情绪产生后, 当同样的刺激再次呈现时, 被试者的心理会如何变化, 未来的研究可以重点关注如何设计更加完善的情景修正策略, 进一步地验证其有效性, 并应用到实际生活中. 另外, 还可以使用策略来干预不同强度的情绪刺激, 并观察情绪调节的时间动态过程, 其结果可能会更有意义.
总之, 本工作设计的情景修正与认知重评一样, 在调节负性情绪时都能有效地降低情绪体验, 是一种有效的情绪调节方式; 与认知重评相比, 情景修正能够更早地影响到情绪产生的轨迹, 表现为更早地对LPP 进行调制. 本工作进一步丰富了Gross 的情绪调节动态模型, 为情绪调节策略的研究提供了一定的参考价值.
