基于信息熵和Monte Carlo方法的分布检验
2019-03-13张志娟李星野
张志娟 李星野

摘 要:在统计分析中,分布检验非常重要,应用较多的检验方法有卡方检验、K-S检验、S-W检验、A-D检验等。提出一种借助Monte Carlo方法、采用信息熵指标实现统计分布检验的方法,检验结果的对比表明信息熵方法简便有效。
关键词:信息熵;均匀分布;置信区间;卡方检验
中图分类号:O21 文献标志码:A 文章编号:1673-291X(2019)03-0159-03
引言
在数据统计领域,分布检验是其中的重要步骤,具有方便、快速、准确等优点,现已广泛应用在医学、统计学等领域,在判断实验结果是否符合预期,产品质量是否合格等方面作用重大。卡方检验是基于统计样本中实际观测值与理论推断值两者偏离程度而发展起来的一种典型的分布检验方法,该方法可以解决检验数据是否符合假设的分布类型的问题,可以很好地描述分类资料统计推断的特点。但是由于卡方检验较为依赖样本空间的划分,不同的样本空间分段数会导致不同的结论[1~3]。K-S检验方法是另外一种较为典型的分布检验方法,它需要将做统计分析的数据和另一组标准数据进行对比,求得它和标准数据之间的偏差,但是当数据规模较小时,相应参数检验是无效的,统计推断是不可信的[2,4~6];与K-S检验方法相对的是S-W检验方法,S-W检验解决了小样本情况下数据服从正态分布的统计检验,但是这种检验方法在大样本情况下的适用性是不明确的[4]。A-D检验方法成功解决了上述两种方法的问题,且可以用于多种分布类型的检验,但是,A-D检验受两端异常值的影响较大[4]。本文提出了一种新的分布检验方法,该方法基于Monte Carlo方法,运用信息熵理论,求得不同置信度的检验下边界,可以检验随机数的分布类型,信息熵方法更加简便有效。
一、信息熵方法实现分布检验的原理
(一)检验原理
本文对经典的分布检验方法不再赘述,根据假设检验的基本原理,可以利用来自总体X的样本x1,x2,x3…xn检验总体是否服从特定分布F0(X)。此时,检验的原假设为H0:F(x)=F0(x),备择假设为H1:F(x)≠F0(x)。当原假设成立时,随机变量Y=F0(X)服从[0,1]上的均匀分布[7]。因此,检验样本x1,x2,x3…xn是否服从分布F0(X),可以转化为检验y1,y2,y3…yn(其中yi=F0(xi))是否服从[0,1]上的均匀分布。对于均匀分布的检验,本文借助信息熵指标,基于Monte Carlo方法,求得检验均匀分布的下边界,实現分布检验。
(二)信息熵
信息熵最早是从热力学中熵这个概念演化而来,熵的物理意义表示体系混乱程度的度量[8]。信息论之父Shannon 指出,任何信息都存在冗余,冗余大小与信息中每个符号(数字、字母或单词)的出现概率或者说不确定性有关[9]。信息熵表示信息中排除了冗余后的平均信息量,本文选取以e为底的自然对数,信息熵可以表示为:
式中,i∈[1,k]表示样本空间划分后的第i个区间,P(i)指样本空间划分后,在样本含有n个子样本的观察中落入i区间的频数ni与样本个数n的比值。
在判断一组随机数是否服从均匀分布时,根据数据的均匀性质,越均匀的数据,其混乱程度越低,包含的信息量越大,信息熵越大。当数据完全均匀时,信息熵达到最大值,如下所示:
其中,k表示样本空间分段数。当数据完全均匀时,样本容量大小对信息熵没有影响。
二、下边界拟合过程
当大量的值都具有计算出的概率时,国内外通用的方法是运用Monte Carlo方法求得问题的解。Monte Carlo方法是指使用随机数(或更常见的伪随机数)来解决很多计算问题的方法[9]。本文为了得到下边界,采用Monte Carlo方法。实验数据是通过随机数生成器生成的,随机生成服从[0,1]上均匀分布的数据,数据包含100组,样本容量为n,n∈{100, 200,300,400,500,600,700,800,900,1 000}。
(一)95%下边界拟合过程
论文运用基于信息熵为指标的均匀分布检验的方法对数据进行检验的过程中,为了得到下边界,本文以样本容量n=100及95%下边界为例进行说明,首先计算95%下边界与样本空间分段数的关系。当样本容量n=100时,把样本空间分成互不相容的k=2个区间,计算得到100个信息熵Hk,挑选升序排列的第6个信息熵作为95%熵,保证在95%熵以上包含95%的信息熵(改变置信度,边界以上包含信息熵的个数不同,可以得到不同置信度的下边界)。改变k∈[2,17]值,得到16个与样本空间分段数k相关的95%熵,求得95%熵与样本空间分段数k的关系拟合95%下边界当数据容量n∈{200,300,400,500,600,700,800,900,1 000}时,95%下边界与样本空间分段数关系的计算方法同上。其次,计算95%下边界与样本容量的关系。
本文首先研究了95%下边界与样本空间分段数k的关系及与样本完全均匀时的信息熵Hk的距离。假设95%下边界的形式为lnk-f(n,k),为了求的f(n,k)的具体形式,将16个95%熵与对应k的最大信息熵lnk作差,即yk=lnk-95%熵,yk为f(n,k)的真实值。
图1为当n=100时,差值yk和分段数k的折线图,由图中可以看出,差值yk随着k的增大呈上升趋势。为了进一步得到yk和k之间的关系,本文假设两者之间为线性关系,函数形式为yk=a+b1k。将yk与k做OLS回归,得a=0.0044,b1=0.00746,调整的R2为0.98516。但由于常数项a太小,假设函数不包含常数项为yk=b1k,OLS回归结果为b1=0.00783,调整的R2为0.99685,OLS拟合效果很好。同时,观察图中差值和拟合函数曲线之间的关系,可以得出拟合函数对原曲线的拟合效果很好,因此假设yk和k之间的函数关系为线性是恰当的。
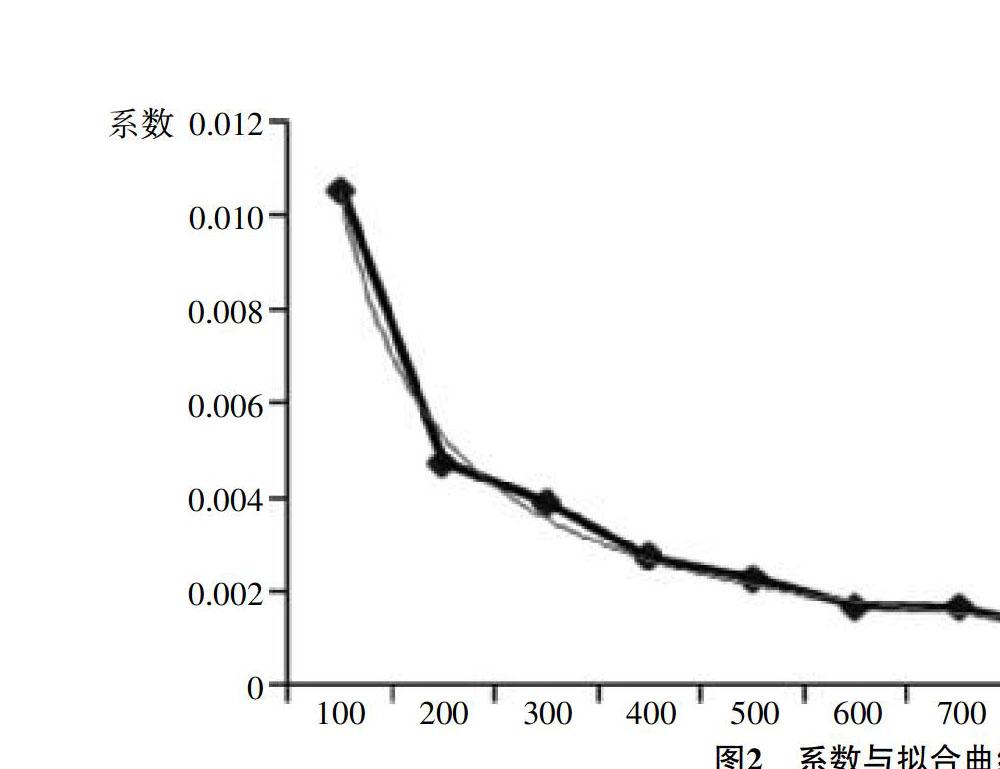
本文进而研究了95%下边界与样本容量n的关系,当改变样本容量n的值,求出b2,b3,b4…b10。下页图2为系数b与样本容量n的关系,由图中可以看出,系数b随着样本容量n的增加呈现出逐渐下降的趋势。为了得到曲线的具体形式,假设曲线的函数形式为b=cnd,以非线性函数线性化方法计算c、d的值,得c=0.60571,d=-0.93745,调整的R2为0.99544。同时,观察图2中拟合函数曲线,对比拟合函数曲线与系数图可知,拟合函数曲线对系数b与样本容量n之间关系的拟合效果较好,且通过计算求得系数预测值与系数真实值之间的差值很小。因此,假设曲线的函数形式为幂函数是适当的。
根据上述步骤,通过计算得:
则95%下边界的公式可以表示为:
(二)样本外数据验证及其他下边界
为了检验通过以上方法得到的95%下边界的准确性,需要通过样本外数据进行验证。随机生成服从(0,1)上均匀分布的数据,数据包含100组,每组数据的样本容量为n,n∈{280,420,500,650,880,1 100,1 500}。检验结果为:当n=280,k=15时,95%下边界=2.66522<95%熵=2.66594;当n=420,k=5时,95%下边界=1.59982>95%熵=1.59946;当n=500,k=6时,95%下边界=1.78203>95%熵=1.78194;当n=650,k=8时,95%下边界=2.0694<95%熵=2.06972;当n=880,k=11时,95%下边界=2.38761<95%熵=2.38796;当n=1100,k=15时,95%下边界=2.69678>5%熵=2.69647;当n=1500,k=17时,95%下边界=2.82378<95%熵=2.82434。
对于样本外数据进行任意分段时,通过以上方法得出的95%熵有较大部分大于95%下边界,说明95%下边界作为检验随机数是否服从均匀分布的边界是恰当的。例如,当样本容量n=280、分段数k=15时,得到的95%熵为2.66594,是大于95%下边界2.66522的,信息熵方法得到的95%下边界是合适的。但是由于给出的边界是不会包含所有的均匀分布数据的,还有一小部分的95%熵是小于95%下边界的。
根据上述方法,可以得出不同置信度的下边界。当置信区间为90%时,下边界為lnk-0.58775n-0.96634k;当置信区间为91%时,下边界为lnk-0.59545n-0.96469k;当置信区间为92%时,下边界为lnk-0.60894n-0.96497k;当置信区间为93%时,下边界为lnk-0.61176n-0.9621k;当置信区间为94%时,下边界为lnk-0.68140 n-0.97612k;当置信区间为95%时,下边界为lnk-0.69751n-0.97577k;当置信区间为96%时,下边界为lnk-0.72685n-0.97819k;当置信区间为97%时,下边界为lnk-0.73876n-0.97331;当置信区间为98%时,下边界为lnk-0.86220n-0.99301k;当置信区间为99%时,下边界为lnk-0.99351n-1.00611k;当置信区间为100%时,下边界为lnk-0.98126n-0.98655k。随着置信区间的增大,下边界逐渐远离数据服从完全均匀分布时的上边界。当样本数据密度增加时,即使样本分段数和样本容量不同,下边界也逐渐趋于重合。
三、信息熵方法与卡方检验比较
为了验证本文运用信息熵和Monte Carlo方法得出的检验边界的有效性,本文使用卡方检验来验证上述实验数据的均匀性。在用卡方检验检验本文实验数据的均匀性过程中,选取不同样本容量、不同分段数的95%信息熵的数据组进行检验。对于相同样本容量,不同分段数会出现95%信息熵数据组是同一组数据的现象,为了避免重复计算,以下只需选取相同样本容量的任意一个分段数进行卡方检验,检验结果同时作为其他分段数的结果。由于数据量大,检验结果只呈现一部分,以此说明结果的表示形式如:当样本容量为100,分段数为2时,卡方检验P值为0.046;当样本容量为100,分段数为3时,卡方检验P值为0.059;当样本容量为100.分段数为4时,卡方检验P值为0.073等等,依此类推。
在对95%信息熵数据组进行卡方检验的结果中,有94组数据的卡方检验p值是大于0.05的,表明在5%的显著性水平下这些数据是不能拒绝服从均匀分布的原假设的,其余的数据在5%的显著性水平下不能接受服从均匀分布的原假设。由于本文所用到的实验数据是运用Monte Carlo方法随机生成的服从均匀分布的数据,运用本文的信息熵方法在95%下边界检验下均是服从均匀分布的。但是在卡方检验下,95%信息熵数据组有41.25%的数据在5%(下转168页)(上接161页)的显著性水平下不能接受服从均匀分布的原假设。由此说明,在信息熵方法与卡方检验的对比下,卡方检验是稍显严格的。
结语
本文根据均匀分布的性质和信息熵指标的意义,运用Monte Carlo方法通过仿真实验得出检验均匀分布的90%~100%的下边界,经过样本外数据的验证,最后运用信息熵方法与卡方检验进行对比,从而得出以下结论:信息熵方法计算过程简便,结果准确有效,在实际运用中既优化了计算步骤,又降低了应用复杂度。
根据其他类型分布与均匀分布的关系,本文所提出的信息熵方法不仅可以实现均匀分布的检验,而且对于其他类型的分布也可以有效实现分布检验。
