基于最大匹配算法的似然导向中文分词方法
2019-03-13杨贵军凤丽洲徐玉慧
杨贵军,徐 雪,凤丽洲,徐玉慧
(1.天津财经大学 统计学院,天津 300222;2.中国联合网络通信有限公司 青岛分公司,山东 青岛 266000)
一、引言
近年来,随着互联网技术的快速发展产生了大量的文本数据,其中蕴含着丰富的信息为人们日常生活的各个方面提供决策支持。中文分词作为中文信息处理的基础环节,分词准确率的高低将直接影响中文文本数据挖掘的效果[1]。中文分词技术具有非常广阔的应用前景,已得到广泛关注。因自然语言的模糊性和复杂性加大了中文分词的难度,而高准确度的中文分词方法对舆情分析[2]、信息推荐以及市场营销等领域的中文文本数据挖掘,具有重要意义[3-4]。
目前,常用的中文分词方法可以划分为两类:基于规则的分词方法和基于统计的分词方法[5],其中最大匹配算法(Maximum Match)是最常用的基于规则分词方法之一。该方法利用词典作为分词依据,以长词优先为基本原则,不需要考虑领域自适应性问题,只需要具有相关领域的高质量词典即可[6],因而分词速度较快。也正因为如此,该类方法歧义处理能力不强,经常会错误地切分歧义字段,分词效果仍有待提高,目前已经出现了一些改进的最大匹配算法。莫建文等在传统分词词典构造的基础上,结合双字哈希结构,利用改进的前向最大匹配分词算法进行中文分词[7],而该算法没有针对词汇粘连现象进行特殊处理,无法避免由于词典颗粒度过大导致的歧义切分问题;张劲松等利用前向匹配、回溯匹配和尾词匹配有效发现了歧义字段[8];周俊等将最长词条优先原则改为最长广义词条优先原则以解决歧义问题,得到了比传统最长词条优先原则更好的效果[9]。从研究方法可以看出,传统的基于规则的分词方法单纯依赖词典信息,并未有效利用分词语料中词与词之间的共现关系,导致其分词效果不够理想。
基于统计的分词方法利用已经切分好的分词语料作为主要的分词依据,根据相邻字或词的紧密结合程度构造统计模型进行分词,当紧密程度高于某一个阈值时,可认为相邻的字组成了一个词组[10]。n-gram语言模型是基于统计分词方法的常用模型之一[11],该模型采用马尔可夫条件假设,可以有效地利用训练语料信息以及上下文相邻词之间的共现频率等统计信息,很好地反映训练语料中词和词之间的转移关系,歧义处理能力较强。
针对以上两类分词方法具有的相对优势,部分学者提出了新的分词方法,将词典信息融入统计分词模型中以改善分词方法的性能[12-13],但该类方法大多都仅将词典当作一种内部资源引入,其训练和解码都使用同样的词典[14],同时也很少从统计模型的角度对基于规则的分词序列进行概率判定。
笔者将两类方法相结合,提出一种基于最大匹配算法的似然导向分词方法。创新点主要包括:一是在分词阶段,利用基于词典的最大匹配方法进行初始词识别,在后续词切分过程中根据训练集数据的统计信息构建训练集共现词典,并依据共现性自动识别后续词,既提高了分词效率,又能够较好消解歧义词,提高了分词的准确性;二是在判定阶段,利用基于马尔可夫性的n-gram模型,提出基于似然导向的判定方法,并计算在分词阶段获得的不同分词序列的概率值。基于最大似然原理确定最优的分词模式,既充分利用了已有的统计信息,又合理避免了每类分词算法的不足。
二、最大匹配算法和n-gram语言模型
(一)基于规则的最大匹配算法
基于规则的最大匹配算法主要包括前向最大匹配、后向最大匹配和双向匹配算法等。假设将包含所有词条的通用词典记为D,其最长词条所含字数记为MaxLen。不失一般性,记长度为M的待切分汉字串S=s1,s2,…,sM。为了从语句中切分出词条,前向最大匹配算法是从左向右取待切分语句的候选字串,记:
(1)
其中
(2)
则s1,s2,…,sk与通用词典匹配成功,将s1,s2,…,sk作为一个词切分出来;再继续对汉字串sk+1,sk+2,…,sM按照式(1)进行匹配和切分,直到切分出所有词为止,通常情况下k>1。当k=1时,即s1∈D,表示切分的单字作为一个词条;当k=0时,即s1∉D,表示切分的单字作为一个未登录词。后向最大匹配与前向最大匹配算法的基本原理相同,只是进行语句的反向切分。
最大匹配分词方法不具备歧义检测和消解能力,加大了后续歧义消解的难度。由于最大匹配分词方法遵循“长词优先”的规则,导致每个词语的长度相对较大,会造成算法的很多无效循环,并对分词效率产生负面影响。此外,传统的最大匹配分词方法一般都是利用通用词典按照某种模式进行字串的切分,会使分词结果受词典的颗粒度影响较大,容易产生词语粘连现象[15],影响分词准确性。例如:
逻辑/思维/能力→逻辑思维/能力(前为正确切分,后为错误切分,下同)
国际/贸易壁垒/的/现状→国际贸易壁垒/的/现状
在不考虑标准分词结果的情况下,有些分词结果也可以认为是正确的。但是,标准分词结果是以训练语料为基础获得的,因而所提出分词方法产生的分词结果需要符合训练语料中词语的切分模式。
(二) 基于统计的n-gram语言模型
假设S=s1,s2,…,sM为待切分汉字串,可以切分为N个词条,记为S=w1,w2,…,wN。采用n-gram语言模型,词条序列w1,w2,…,wN出现的概率为:
P(S=w1,w2,…,wN)
=p(w1)p(w2|w1)…p(wn|w1,w2,…,wN-1)
(3)
其中约定p(w1|w0)=p(w1),表示以词条w1开始的句子在训练集中出现的概率。上式的概率计算在当前的计算机水平下往往是不可行的。因而,n-gram语言模型引入马尔可夫条件假设,即认为第n个词出现的概率只与其前面的n-1个词相关,而与其它词都不相关。S出现的概率就是词条序列w1,w2,…,wN出现概率的乘积:
P(S=w1,w2,…,wN)
(4)
其中max(1,i-n)表示1和i-n的最大值。当n=1时,一个词的出现仅依赖于其前面出现的1个词,分词模型被称为bi-gram,即:
(5)
仍约定p(w1|w0)=p(w1)。
本文将基于规则的分词方法和基于统计的分词方法结合起来,其中将基于规则的最大匹配分词方法视为一种初级分词法,并利用其对待测试文本进行简单、快速处理;利用统计语言信息处理词语粘连以及后续词/前缀词的自动扩展等,生成多组候选分词序列;利用基于马尔可夫性的n-gram模型,计算候选分词序列的概率值,以最大似然原理作为依据选择最优的分词模式,得到最终的分词结果。新方法不仅充分利用了训练集的词频规律,还有效弥补了单一分词算法的不足。
三、基于最大匹配算法的似然导向中文分词方法
基于最大匹配算法的似然导向中文分词方法主要包括三个阶段:预处理阶段、分词阶段、判定阶段,具体流程如图1所示。预处理阶段的目的是构建共现词典,为分词阶段的自动识别后续词/前缀词以及为判定阶段的计算多组概率值做准备;分词阶段的任务是将基于规则的前向/后向最大匹配算法与基于统计信息的词共现性方法相结合,对测试语料中待划分的句子进行分词操作,生成多组候选分词序列,而在该阶段中每种候选分词序列的作用应该是均等的;判定阶段的任务是利用基于马尔可夫性的n-gram语言模型,计算多组候选分词序列对应的概率作为序列子串的似然函数,并选取似然概率值最大的分词序列作为最终的分词结果。
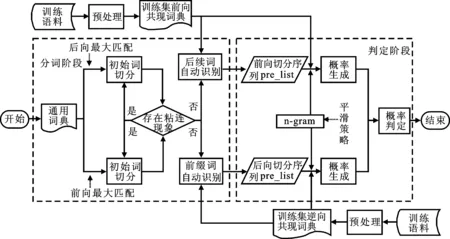
图1 基于最大匹配的似然导向中文分词方法流程图
(一)预处理阶段
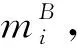
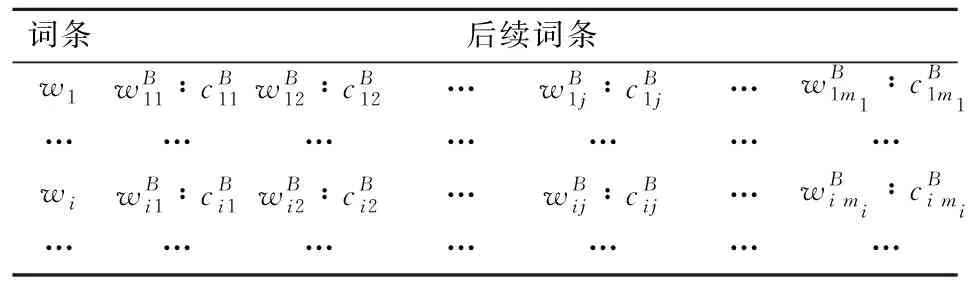
表1 正向训练集共现词典DF表
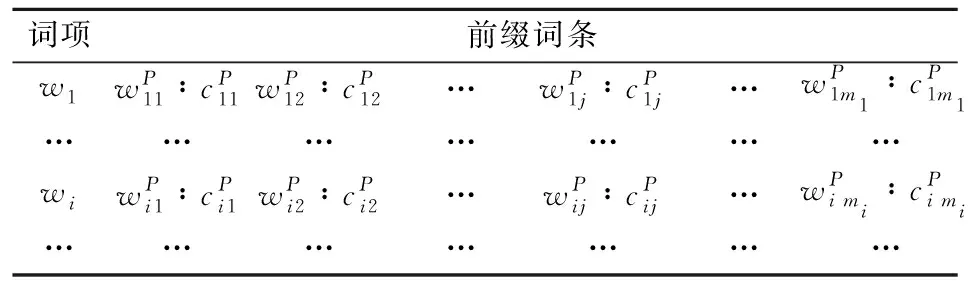
表2 逆向训练集共现词典DB表
(二)分词阶段
针对前向/后向最大匹配算法,使用两类词典:一类为不含上下文信息的通用词典D;另一类为在预处理阶段构建的包含上下文信息的共现词典DF和DB。该阶段的分词策略是利用基于通用词典的最大匹配方法切分初始词,为了提高分词效率并消解歧义词,本文在后续词切分过程中,基于领域训练集语料的统计信息和后续词的共现性自动识别后续词。
本文利用前向最大匹配与后向最大匹配算法进行分词的实现思想基本相同,区别在于利用了不同的训练集共现词典DF和DB。下面,以前向最大匹配算法为例描述具体分词过程:
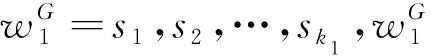
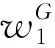
wN=skN-1+1…sM
(6)
后续词的自动识别,一方面是基于词语的共现性,比较符合人们进行文字表述的规律;另一方面是大大减少重复切词和匹配通用词典的循环操作,可以提高分词方法的效率。实际操作时,如果在DF中找不到可以匹配的后续词,则转step1,重新在D中进行查找是否有匹配项,并执行后续操作。
经过上述步骤,最终可以生成多组候选分词序列。
(三)判定阶段
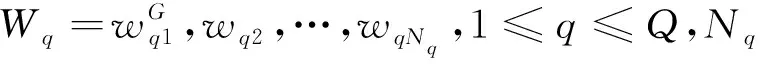
(7)
语料库不可能包含所有可能出现的序列,某些词条在语料中出现频数会很少。为了降低数据稀疏问题对计算似然概率带来的影响,仅使用bi-gram语言模型估计似然概率。将式(7)简化为式(8)的形式,即得到基于马尔可夫性的bi-gram语言模型:
(8)
在训练语料中用未曾共现过的新序列计算似然概率时,会出现估计值为零的情况。为此,采用数据平滑策略对其进行处理,似然概率计算公式如下:
(9)
其中δ(0≤δ≤1)为平滑参数,表示每个词出现的频数比实际统计频数多δ次;DF为DF中词共现词条的总频数。
四、 实验
(一)实验语料
实验语料来源于SIGHAN组织的国际中文自然语言处理竞赛(Bakeoff),实验数据包括标准词典、训练语料、测试语料以及测试语料的标准切分。由于编码方式的不同,实验仅在中文简体语料库上进行了测试,训练语料包含44.947万词,测试语料包含11.35万词。在训练过程中,实验还使用了通用词典,包含42.7452万词。
(二) 实验方法
本文针对8种算法进行中文分词对比实验:
1)FMM:传统前向最大匹配分词方法。
2)BMM:传统后向最大匹配分词方法。
3)FBMM:将似然导向用于FMM和BMM的分词方法。
4)IFMM:利用词共现性改进的前向最大匹配分词方法。
5)IBMM:利用词共现性改进的后向最大匹配分词方法。
6)POMM:基于最大匹配算法的似然导向中文分词方法。在该方法中,分词阶段利用词共现性改进FMM和BMM,判定阶段结合n-gram语言模型实现似然导向功能。
7)IPOMM1:在POMM的基础上,为解决分词粘连现象,针对分词阶段获得的初始词加入再次切分策略。
8)IPOMM2:在IPOMM1的基础上,为避免零概率问题,在判定阶段计算似然概率时采用平滑参数δ=0.000 01的平滑策略。
(三)评价指标
为了评价本文方法的分词性能,分别选择准确率、召回率、F1值和时间开销作为评价指标。准确率是在分词方法生成的分词结果中切分正确的目标词所占的比例,即分词方法正确分词数/分词方法分词总数,记为P;召回率是针对标准分词结果中,分词方法生成的分词结果被正确切分的目标词所占的比例,即分词方法正确分词数/标准分词总数,记为R;F1值为F1=2PR/(P+R),F1值折中考虑准确率与召回率,综合反映分词方法的整体效果。
(四)实验结果与分析
将以上8种方法归纳为3种类型,其中第1类包括FMM、BMM、FBMM;第2类包括IFMM、IBMM、POMM;第3类包括IPOMM1、IPOMM2。表3给出了3类方法的对比实验结果,其中“right”列表示分词方法生成的分词结果中切分正确的目标词数量;“split”列表示分词方法生成的全部词数量;“goal”列表示标准分词结果中词的数量。
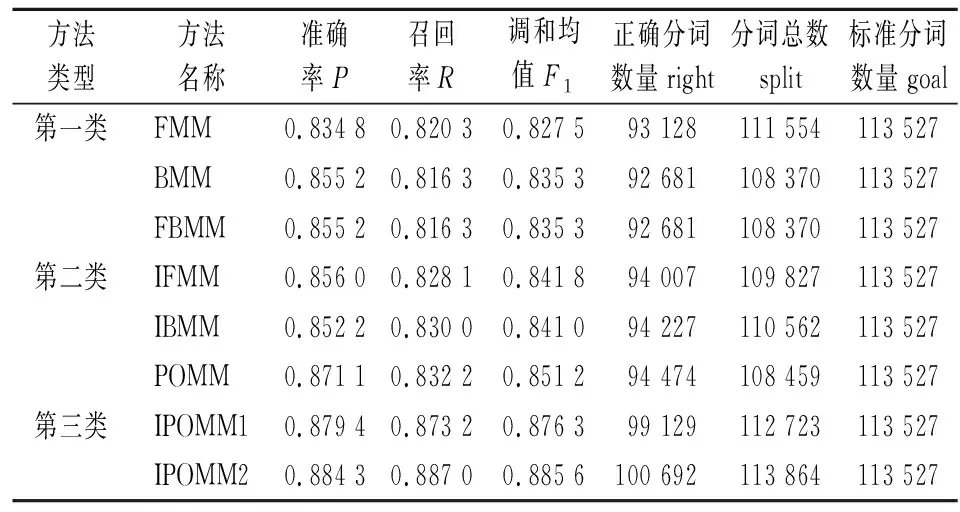
表3 不同方法的准确率、召回率、F1值比较表
由表3可知:在第1类方法中,BMM与FBMM方法对应的准确率、召回率及F1值均为0.855 2、0.816 3、0.835 3,FBMM表现与BMM一致,这是由于似然导向策略使得FBMM方法对应结果由BMM决定;虽然BMM在准确率上高于FMM方法,但从正确切分目标词数量上可以看出BMM对应的right值(92 681)少于FMM对应结果(93 128)。可见,BMM方法在召回正确切分目标词数量上并未获得提高。
第2类方法中,IFMM、IBMM、POMM在P、R、F1值方面,相比于第1类方法均有改善,尤其在使用基于n-gram的似然导向策略时准确率从0.834 8提高到0.871 1、召回率从0.820 3提高到0.832 2,这说明在基于规则的最大匹配算法中考虑基于统计的词共现性信息能有效提高算法的准确率和召回率;同时,对POMM方法判定阶段的似然导向策略起到了积极作用,从正确切分目标词数量上也可以看出POMM 对应的right值(94 474)大于FBMM对应结果(92 681),似然导向策略增加了目标词的召回率,这说明POMM方法综合考虑了IFMM、IBMM各自的优势,引入词共现性和似然导向策略能有效提高分词算法的性能,验证了似然导向相比于单个分词方法的优势。
第3类方法中,IPOMM1、IPOMM2相对于第1、2类方法,在P、R、F1值方面都得到明显提升。例如第1、2类方法准确率的最大值分别为0.855 2和0.871 1,明显小于IPOMM1和IPOMM2的结果;在召回率方面,从第1、2类方法的最大值0.820 3、0.832 2,提高到了0.887 0。通过对比召回目标词数量发现,第1类方法中FMM方法最优,正确分词数量为93 128;第2类方法中POMM方法最优,正确分词数量为94 474;第3类方法中IPOMM2方法最优,正确分词数量为100 692,这进一步说明了引入词共现性和似然导向策略能有效提高分词算法性能。
对具体的错误分词结果进行分析发现:第1类方法基于最大匹配算法,受到通用词典颗粒度的影响,易出现粘连现象;第2类方法通过加入基于统计的词共现性信息,在一定程度上减少了这种粘连现象,但在初始词划分时依然受到通用词典中词的颗粒度的影响;第3类方法在第2类方法的框架下优化了初始词切分策略,克服了最大匹配算法受通用词典颗粒度影响较大的问题。此外,该方法在判定阶段调整了平滑参数,降低了数据稀疏对概率计算准确性的影响。图2展示了第3类方法IPOMM2与第1类方法FBMM在错误分词结果方面的对比情况,即图2中的词是采用FBMM方法会被错误切分但采用IPOMM2方法时可以正确切分的词,例如在FBMM 方法中切分错的词“国有企业”、“非关税壁垒”、“经济运行”等,通过IPOMM2方法正确切分为“国有/企业”、“非关税/壁垒”、“经济/运行”等;第3类方法IPOMM2有效解决了中文分词中受词典颗粒度影响而产生的词语粘连问题。

图2 错误分词结果对比词云图

第1类方法第2类方法第3类方法FBMMPOMMIPOMM1IPOMM2T= 63.74T= 56.30T= 56.51T=59.84
表4对比了3类分词方法中采用似然导向策略时所需的时间开销,即第1类方法中的FBMM、第2类方法中的POMM、第3类方法中的IPOMM1和IPOMM2。由表4知,第2类方法、第3类方法所产生的时间开销普遍少于第1类方法,说明分词阶段进行后续词/前缀词的自动扩展有助于提高运算效率;第3类方法为了减少词语粘连现象和避免零概率问题,在第2类方法的基础上优化了初始词切分方法并调整了平滑参数,因而导致第3类方法的时间开销稍高于第2类方法,在提升分词性能的同时稍微损失一些计算效率,也是在可接受范围内。
五、结语
本文结合基于规则的分词方法与基于统计的分词方法的优势,提出了一种基于最大匹配算法的似然导向中文分词方法POMM。新方法在分词阶段引入词共现性,很好地发挥了基于统计的分词方法处理词与词之间紧密程度的优势;在判定阶段利用n-gram语言模型的马尔可夫性对不同的概率值进行似然导向调整;在POMM的基础上,针对粒度较大的初始词进一步切分以消解歧义,并调整平滑参数,避免数据稀疏所带来的精度下降问题。相比于传统的最大匹配算法或者单一分词方法,新方法在准确率、召回率、F1值方面均得到了显著的提升。
对于某些词语,似然导向也带来了一定的负效应,即前向最大匹配/后向最大匹配可以正确切分的词,使用似然导向方法偶尔会发生切分错误。在下一步研究中,一方面将考虑引入多种不同的分词策略或者新词识别方法以解决无法正确切分的句子;另一方面将引入集成学习方法以保留更多的正确导向,降低错误率。
