融合前景和背景种子点扩散的显著性目标检测
2019-03-13顾广华刘小青
顾广华,刘小青
1(燕山大学 信息科学与工程学院,河北 秦皇岛 066004) 2(河北省信息传输与信号处理重点实验室,河北 秦皇岛 066004)
1 引 言
近年来,有效的显著性检测已经成功的运用到许多计算机视觉场景当中.作为图像的预处理过程,它能够检测出图像中感兴趣的区域,提取图像的重要信息从而减少计算复杂度[1].但如何能精准的找到显著性目标区域仍是一个具有挑战性的问题.
现有的显著性检测算法主要分为两类:自底向上和自顶向下的显著性检测模型[2].自底向上的模型是数据驱动的,预先没有任何图像显著性区域的先验信息,通过图像中一个区域和周围邻域的差异得到区域的显著性值.自顶向下的模型是任务驱动的,需要某些先验信息,才能够找到显著目标.和自底向上的模型相比,自顶向下的算法比较复杂,所以研究者更加倾向于自底向上的显著性检测算法.Itti[3]等人提出了一种中心环绕对比算法,通过结合在不同尺度下的颜色、强度和方向特征图得到显著图.Achanta[4]等人提出了一种调频的算法,通过计算图像中每个像素的颜色特征和整幅图像像素颜色平均值的差异得到图像中每点的显著值.该方法虽然简单,但对于背景复杂的图片,检测的结果不理想.Goferman[5]等人根据相邻上下文区域的差异计算局部对比度,得到最终的显著图.Cheng[6]等人采用全局对比方法,通过计算空间加权颜色对比先验得到显著图.上述两种方法虽然考虑了整幅图像的特征对比,能很好的定位显著目标,但忽略了局部信息,从背景中找到具有相似外观目标的能力有限.Gopalakrishnan[7]等人将图像中的显著性检测问题视为马尔可夫随机游走,遍历马尔可夫链的平衡命中次数是确定最显著节点的关键.Wei[8]等人把图像的边界区域为背景先验建立模型,能够将前景区域从图像中分离出来,但把边界区域作为背景先验是不够准确的,边界区域有可能包含前景点.Kong[9]等人采用模式挖掘的方法找到图像中比较准确的前景点,然后对前景点进行随机游走.这种方法可以有效的检测出图像的显著区域,但对前景点的准确性要求比较高,如果找不到比较准确的前景点,就会影响显著区域的检测.
为了解决上述问题,本文同时选择前景点和背景点作为种子点,并融合前景点和背景点扩散得到的显著图,这样不仅减小了显著区域对前景点的依赖性,也使得显著图更加准确.
2 显著性目标检测
本文主要思路为:首先是选取前景点和背景点作为种子点,然后背景和前景种子点进行显著性扩散,并将种子点各自扩散的显著图融合,最后优化得到最终显著图.图1所示为本文算法框图.

图1 显著性检测框图
Fig.1 Saliency detection framework
2.1 种子点的选取
首先利用简单线性迭代聚类算法[10]对输入图像进行超像素分割.利用背景先验[11],图像边界作为背景点,为了避免对象出现在边界的情况,计算图像的边缘概率[12],具有较强边缘特征的超像素更可能属于目标,本文去掉边界区域中边缘概率值大于自适应阈值[13]的超像素,然后将图像边界中其余的超像素选为背景种子点.
将一幅图像分割成N个超像素,边缘概率为PB,背景种子点集合为E:
(1)
{i∈E|PBi>T1}
(2)
其中Bi表示超像素i的边缘像素个数,Ipb表示像素I的边缘概率值,T1是根据边缘概率得到的自适应阈值.
基于得到的背景点,本文通过颜色空间加权对比度得到初始显著图Si,计算出图像中其余节点和背景点之间的关系,图像中的超像素和背景种子的颜色差异越大,它越有可能是显著点.
背景种子集为E,超像素i的显著值定义为Si,前景种子点集合为F:
Si=∑n∈Ed(Ii,In)(1-d(Pi,Pn))
(3)
{i∈F|Si>T2}
(4)
其中d(Ii,In)和d(pi,pn)分别表示图像中的超像素i与背景种子集E中超像素n的颜色距离和空间距离,T2是根据显著值Si得到的自适应阈值.这里(1-d(pi,pn))起到了调节的作用,能更好的突出目标区域.当显著值大于T2时,该超像素判为前景点.
背景和前景种子点可以为下面基于种子点的显著性扩散提供足够的对象信息.
2.2 显著性扩散
本文将背景点和前景点都进行显著性扩散,将种子点的信息传播到图像中的其余节点,并融合得到的显著图.
将输入图像表示成一个稀疏的连通图G=(V,E),其中V表示由所有超像素组成的节点,E表示连接各个节点的无向边界集合,当且仅当两个节点共用一个边界时成立.权重矩阵W表示每对节点之间相似度和邻接关系,连接两个超像素的边缘权重定义为wij∈W:
(5)
g(si)和g(sj)表示两个超像素节点在CIELab颜色空间上的颜色均值.σ控制边缘权重的强度,关联矩阵W是高度稀疏的.
D为对角矩阵,di=∑iWij,拉普拉斯矩阵L定义为:
L=D-W
(6)
二次拉普拉斯算子为:
L2=L×L
(7)
2.2.1 背景种子点的显著扩散
设ρ表示种子点的集合,f=[f1,f2,…,fn]T表示所有超像素节点的标签向量,如果节点si∈ρ,则fi等于1,否则为0.
显著性扩散是基于种子点来推断所有超像素节点的标签,其通过最小化能量函数g(f)来实现:
(8)
其中,fi=1,yi表示初始显著图中节点si的平均显著值,β是权衡参数,通过实验验证参数最终设为0.01,得到的显著图结果是最好的.式中第一项强调了相似节点标签的一致性,第二项是把初始显著图的平均显著值作为先验知识,并惩罚与先验值不同的显著性预测.
设l为标签节点的集合,即为背景种子点的集合,u为未标签节点的集合,f和y也可以写为f=[flTfuT]T,y=[ylTyuT]T,最小化(8)式用矩阵形式表示:
(9)
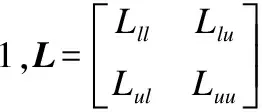
(10)
M=L+βI,其中I为单位矩阵.
对上面得到的整幅图像的显著值加入二次拉普拉斯算子,可以将种子的信息更好的传播到远端的节点,则:
(11)
则基于背景种子点扩散得到的显著值为:
(12)
2.2.2 前景种子点的显著扩散
基于前景种子点的扩散,前景种子点为标签节点,过程和上述类似,设l是标签节点的集合,u为未标签节点的集合.同样令(9)式等于0,得未标签节点的显著值fu,对图像中所有节点加入二次拉普拉斯算子得:
(13)
(14)
2.2.3 融合显著图
融合背景种子和前景种子显著扩散得到的显著图,融合显著图的显著值为:
Ssal=Sb×Sf
(15)
图2是上述过程中得到的显著性检测结果图.
图2(a)是输入图像,(b)是根据边界先验和边缘概率筛选得到的背景点,图像边界的黑色区域表示背景种子点,(c)是筛选后的背景点通过计算特征距离得到的初始显著图,可大体看到显著区域,但没有有效的从背景中分离出来.(d)是背景种子扩散的显著图,能很好的抑制背景.(e)是前景种子扩散的显著图,前景比较突出,但有些背景噪声.(f)是融合显著图,结合(d)和(e)的优点,能很均匀的突出显著目标区域,同时能有效的抑制掉图像的背景.(g)是真值图.

图2 显著性检测结果图Fig.2 Saliency detection result maps
3 显著优化
3.1 聚类优化
尽管融合后的显著图能很好的检测出显著区域,但对于有些背景比较复杂的图像,显著目标检测的不完整,并且存在背景噪声,本文采用聚类优化,增强显著图的前景区域.
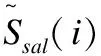
(16)
这里的K是聚类中心,一般不会很大,需要提前设定,本文根据先验经验[14]将K设为8.λ表示每个节点被类内其它节点优化的权重,设为0.5,用来平衡本身显著值和类内优化的贡献作用.x指的是CIELab空间的三维颜色特征,Ssal(j)是和节点i在同一类内节点的显著值.那么从上式可以看出对于每个节点i,是通过自身的显著性值和同一类内其余节点的显著性值实现优化的.图3为结合显著图和聚类优化后显著图的对比.从中可以看出,结合显著图可以整体上检测出显著区域,但在细节上不够完整,聚类优化考虑到超像素间的联系,完善了显著图的细节信息,使显著区域更加完整.

图3 融合显著图和聚类优化后显著图的对比Fig.3 Comparison of combination of saliency map and clustering optimized saliency map
3.2 抑制函数
聚类优化能够增强显著区域,为了有效去掉一些背景噪声,本文引入了抑制函数[15],我们将函数定义为:
(17)
这里τ是一个用来区分前景和背景的阈值,x表示每个超像素节点的显著性值.由于前景的显著值接近1,背景的显著值接近0,为了保留前景同时抑制背景,本文把τ设为0.6.图4表示聚类优化和抑制函数优化后的显著图对比.其中输入图像的背景比较复杂,聚类优化的显著图可以检测出显著目标,但仍存在一些背景干扰.和显著目标相比,背景噪声的显著值相对较小,所以抑制函数优化后的显著图能够抑制掉大多数的背景点,使目标区域更加突出.

图4 聚类优化和抑制函数优化后显著图对比Fig.4 Comparison of saliency maps after optimizing clustering and suppressing functions
4 实验结果分析
本文在两个公共数据库MSRA-1000和DUT-OMRON上进行实验.MSRA-1000数据库是从数据库MSRA中挑选出来的,每幅图像都有一个比较清晰的目标.DUT-OMRON数据库含有5166张图片,是一个比较庞大、复杂的数据库,图像中有一个或多个目标,而且背景比较杂乱,对显著性算法具有挑战性.两个数据库都含有像素级的真值标注,本文设超像素N=200.
本文在两个数据库MSRA-1000和DUT-OMRON上把本文算法和其它六种显著性算法进行了对比,分别是GB算法[16],FT算法[4],BM算法[17],SF算法[2],BFS算法[18],GR算法[19].
图5是七种算法在MSRA-1000数据库中部分图片显著图的对比,输入图片的目标比较单一.前六种算法相比较,显著图结果较好的是BM算法、GR算法和BFS算法,这三种算法可以直观的看到显著目标.BM算法的目标比较突出,但背景干扰也很多;BFS算法和GR算法显著区域不是很亮、很完整,也有背景噪声.GB算法、FT算法和SF算法显著图结果相对较差,GB算法的显著图模糊,只能看到目标的轮廓,FT算法显著区域不突出,SF算法检测到的目标不完整.相比于这六种算法,可以看到本文算法显著图的显著区域比较突出,而且背景抑制的也比较好,和真值图最为接近.

图5 七种算法在MSRA-1000部分图片上的显著图Fig.5 Saliency maps of the seven algorithms on the MSRA-1000 part of the pictures
图6是七种算法在DUT-OMRON数据库中部分图片显著图的对比,输入图片的内容比较复杂,目标不单一.前六种算法结果相对较好的是BFS算法和GR算法,它们都能突出目标,相比较而言,但BFS算法背景干扰较少,GR算法的显著目标更完整.结果较差的是GB算法、FT算法、BM算法和SF算法,GB算法整个区域都比较模糊,效果最差;FT算法和BM算法的显著图有目标,有背景,显著区域不突出;SF算法相对背景较少,但目标不清晰.从图中可以看出本文算法和其它六种算法相比效果比较好,目标比较明显,背景干扰少,由于图片背景复杂,和真值图相比检测到的目标还不够完整.

图6 七种算法在DUT-OMRON部分图片上的显著图Fig.6 Saliency maps of the seven algorithms on the DUT-OMRON part of the pictures
为了进一步分析本文算法的优越性,本文采用准确率-召回率曲线和准确率、召回率和F-measure柱状图来衡量显著性算法的效果.首先采用固定阈值将显著图进行二值化,准确率为显著图和真值图交集中1的个数和除以显著图像素值为1的个数和,召回率为显著图和真值图交集中1的个数和除以真值图像素值为1的个数和.将[0,255]之间的每个值设为一个阈值,得到256幅二值图像,参照真值图,计算得到待测图像的256个准确率和召回率,再把每个阈值下的P和R取平均,以召回率为横轴,准确率为纵轴,画出准确率-召回率曲线.准确率、召回率和F-measure柱状图的阈值和上面的不同,是通过自适应阈值二值化显著图,再取所有图片的平均准确率和召回率,F-measure值计算如下:
(18)
其中,β用来确定准确率对于召回率的重要性,β2>1表示召回率重要,β2<1表示准确率在评价体系中占主导.本文设β2=0.3,用来强调准确率的重要性.
图7是七种算法在MSRA-1000数据库上的准确率-召回率曲线图.上三角连线组成的代表本文算法,从图中可以看出本文算法要优于其它算法.GB算法和FT算法的准确率和召回率偏低,因为GB算法检测到的显著区域不明显,分辨率较低,FT算法虽然能检测出显著目标,但含有大量的背景.GR算法采用背景先验和光滑先验理论,P-R曲线较高,但本文算法的显著目标突出,背景干扰少,实验效果比GR算法好.虽然召回率在0.1左右时,本文算法准确率低于BFS算法,但较低的召回率对显著性检测的意义不大.

图7 七种算法在MSRA-1000数据库上的准确率-召回率曲线图Fig.7 Precision-Recall curves of the seven algorithms on the MSRA-1000 part of the pictures
图8是七种算法的准确率、召回率和F-measure柱状图,从图中看到结果较好的是SF算法、GR算法和本文算法,本文算法的结果都比SF算法好,其中召回率要远远高于SF算法.准确率和GR算法持平,在F值和召回率上都要高于GR算法.本文算法的准确率为0.9238,召回率为0.8191,F-measure值为0.8973,总体上本文算法在召回率和F值上都要优于其它六种算法.
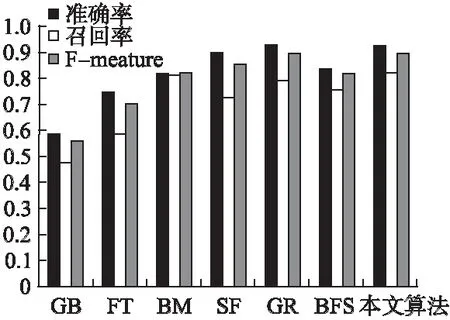
图8 七种算法在MSRA-1000数据库上的准确率、召回率和F-measure柱状图Fig.8 Precision,Recall and F-measure values of the seven algorithms on the MSRA-1000 part of the pictures
图9是七种算法在DUT-OMRON数据库上的准确率-召回率曲线图.DUT-OMRON数据库图片都相对比较复杂,而且数量较多,所以从图9中看到这七种算法在这个库上的实验结果比图7在MSRA-1000数据库上的结果要低很多.虽然图片对算法的要求比较高,但是本文算法的结果仍然是最好的,P-R曲线要高于其它六种算法.
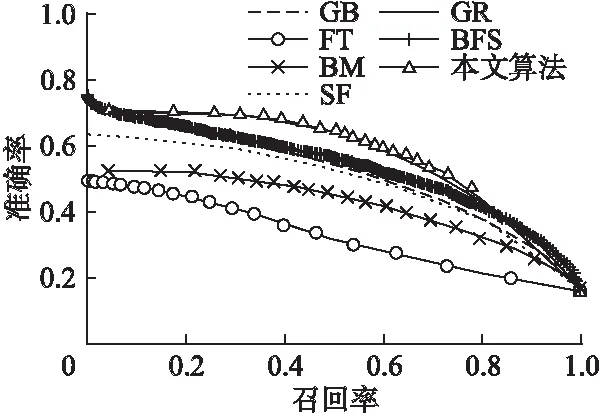
图9 七种算法在DUT-OMRON数据库上的准确率-召回率曲线图Fig.9 Precision-Recall curves of the seven algorithms on the DUT-OMRON part of the pictures
图10是七种算法在DUT-OMRON数据库上的准确率、召回率和F-measure柱状图.图中本文算法的F-measure值要高于其它六种算法,达到了0.5814;本文算法的准确率仅次于GR算法,但要高于其它五种算法;本文算法的召回率和GB算法、BFS算法基本持平,但要高于其它四种算法;所以虽然本文算法的准确率和召回率的结果不是最好的,但是F值是最高的,能够从整体上说明本文算法的有效性.

图10 七种算法在DUT-OMRON数据库上的准确率、召回率和F-measure柱状图Fig.10 Precision,Recall and F-measure values of the seven algorithms on the DUT-OMRON part of the pictures
本文选择了在MSRA-1000数据库上显著图结果较好的四种算法,比较四种算法在MSRA-1000数据库上运行的平均时间,如表1所示.
表1 运行时间对比
Table 1 Comparison of running time

方法SF[2]GR[19]BFS[18]本文算法时间(秒)0.2790.4490.5900.552代码类型MatlabMatlabMatlabMatlab
由表1可知,BFS算法运行的时间最长,SF算法最短.本文算法运行时间虽然高于GR算法和SF算法,但是本文算法的显著区域检测性能最好.
5 结束语
本文提出了一种融合前景和背景种子点扩散的显著性目标检测算法.背景点和前景点同时作为种子点进行显著性扩散,前景种子点扩散检测到的显著图能完整的突出显著区域,但有很多背景噪声,而背景种子点扩散得到的显著图能较好的抑制背景区域,两者融合,能够互相补充.为更加完善显著图,采用了聚类优化和抑制函数对显著图进行改进.为了评价本文算法的性能,在MSRA-1000和DUT-OMRON数据库上与其它六种算法比较,相应结果证明了本文算法的有效性.本文方法也存在一些不足,对于比较复杂的图片,显著区域检测的还不够准确,仍有待于提高.
