WordNG-Vec:一种应用于CNN文本分类的词向量模型
2019-03-13何养明陈荟西
王 勇,何养明,邹 辉,黎 春,陈荟西
(重庆理工大学 计算机科学与工程学院,重庆 400054)
1 引 言
文本特征提取(文本输入表示)作为文本分类技术里重要的一环,其质量决定了分类系统的分类效果.传统文本输入表示方法的主要问题是表示文本或词语的向量具有高纬度、高稀疏性,对特征语义的表达能力不足,而且神经网络模型不擅长对此类数据的处理,此外依赖人工进行特征处理,效率难以支撑数据量越来越大的文本分类任务.近年来随着深度神经网络的逐渐兴起,相关理论模型(如卷积神经网络、循环神经网络等)最初在图像和语音领域得到较为成功的应用,主要原因在于图像和语音可以转换成计算机可以识别和处理的具有连续和稠密性的数据,数据特点是有局部关联性.可见,使用深度神经网络解决大数据的文本分类问题最重要的是解决文本输入表示问题,再利用深度神经网络模型能自动提取深层次特征的能力,去掉繁杂低效的人工特征工程.
词的分布式表示(Distributed Representation)是较早的一种文本输入表示方法,其原理是把词语映射成固定维数的稠密数据向量,即词嵌入(WordEmbedding)或词向量(Wordvector),传统对应的独热编码(One-hotencoding)模型用“0”和“1”来表示词向量空间,其中“1”的位置代表词语在词典中的位置索引.分布式表示的优点是有较好的语义特征表达能力,同时数据形式能够被神经网络高效读取和处理.词嵌入(词向量)近年来能够广泛流行于文本语义建模领域,得益于谷歌2013年开源了Word2vec词向量模型,该模型的推出是文本分类模型研究从传统的浅层机器学习模型转向深度学习模型的关键所在.至此,文本词语利用数学向量的表达方式,把文本输入映射成低维、连续和稠密的向量矩阵(类似图像数据形式),使得深度神经网络模型得以迁移到文本分类领域,极大促进了相关研究的进程.
然而,实际上Word2vec学习到的“向量特征”和实际语义特征有一定的区别,更多学到的是具备相似上下文的词或相似语义的独立词,如“工资”和“薪水”,“解决”和“处理”等,但不能考虑到局部词序特征,如“我负天下人”和“天下人负我”这两个不同的语句,在传统的Word2vec中的特征都是:[“我”、“负”、“天下人”],在特征语义上是没有区别的,如果加入2-gram(bigram)特征,前后两句话的特征还有:[“我负”、“负天下人”]和[“天下人负”、“负我”],这样两个句子就能区分开来了.这无疑会增强文本特征的表达能力,提升文本的分类效果.
2 相关工作
Hinton在1986年提出词的分布式表示,将每个词表达成 n 维稠密、连续的实数向量,奠定了文本词语建模的发展理论基础[1].Bengio在2003年提出了三层语言模型(输入层,隐含层和输出层)的思路,用上下文的词向量来预测中间词,但是计算复杂度较高,对于较大的数据集运行效率低[2].2013年,谷歌的Mikolov等人推出Word2vec,也是三层的语言模型,其中包含了两个词向量模型CBOW(Continuous Bag-of-Words Model)和Skip-gram(Continuous Skip-gram Model),在语义和语法上都得到了很好的验证,推动了文本语义分析的进程[3,4].基于word2vec的思想,Mikolov 于2014年又提出Sentence2vec和Doc2vec,提出了一种更加简单的网络结构来训练任意长度的文本表示方法,这样好处是减少了参数,加快了模型训练,避免模型过拟合[5].
Word2vec在词语建模方面产生了巨大的贡献,然而其依赖于大量的文本数据进行学习,如果一个词出现次数较少那么学到的向量质量也不理想.针对这一问题Mikolov提出使用subword信息来弥补这一问题,简单来说就是通过词缀的向量来表示词,即用一串字符级的n-gram向量来表示一个词[6].Facebook于2016年开源的文本分类工具FastText在词嵌入训练时加入了字符级的n-gram特征,用若干个字符n-gram向量的叠加来表示某个单词,这样的好处是对于低频词生成的词向量效果会更好,因为它们的n-gram可以和其它词共享;对于训练词库之外的单词,仍然可以通过叠加它们的字符级n-gram向量构建它们的词向量[7].Johnson等人直接使用局部小区域的一段文本进行词嵌入转换,代替词向量作为CNN分类模型的输入,在更高维层面充分利用了词序信息进行文本的分类[8].王鹏使用快速聚类算法提取出文本中的语义集,接着对文本n-gram片段进行语义合成,形成候选语义单元,然后根据设置的阈值筛选出合适的语义单元组成语义矩阵,作为CNN的输入,解决了文本特征矩阵语义稀疏的问题[9].王儒等人针对短文本分类任务上的数据稀疏等难点,尝试在短文本特征输入上进行改进.Wordembedding训练时采取non-static和static两种方式,将训练好的Wordembedding进行聚类处理,聚类得到的Wordembedding库作为模型输入的词典库[10].随着词语建模的不断成熟,越来越多的学者开始尝试利用卷积神经网络(CNN)等深度学习方法进行文本分类,Yoon Kim的经典模型TextCNN在句子分类方面取得不错的成果,成为后续相关研究的模型基准[11].
利用形态学改进词嵌入的工作十分丰富,但中文领域似乎很难利用这一思路,虽然中文中也有类似于词缀的单位,比如偏旁部首等等,只不过不像使用字母系统的语言那样容易处理.文本借鉴文献[6]、文献[7]的思想,提出结合N-Gram特征与Word2vec的词向量模型WordNG-Vec,提取出文本句子的局部词序特征,增强文本特征的表达能力,实验表明这个方法有效提高文本分类的效果.
3 相关模型理论
3.1 结合N-Gram特征与Word2vec的词向量模型
N-Gram语言模型是基于一个假设:第n个词出现与前n-1个词相关,而与其他任何词不相关.整个句子出现的概率就等于各个词出现的概率乘积.各个词的概率可以通过语料中统计计算得到.假设句子S是由词序列w1,w2,…,wn组成,用公式表示N-Gram语言模型如下:
P(s)=p(w1,w2,…,wn)=
p(w1)p(w2|w1)…p(wn|w1,w2,…,wn-1)
(1)
词语wn出现的概率依赖于它前面n-1个词,当n很大时,P(s)的计算是非常麻烦甚至无法估算,于是出现了著名的马尔科夫假设,即马尔科夫模型.马尔科夫假设的意思是:“当前这个词仅仅跟前面一个或几个有限的词相关”,即概率计算时不用考虑最前面的词,这就大大简化了计算的复杂度.即:
p(wi|w1,w2,…,wi-1)=p(wi|wi-n+1,…,wi-1)
(2)
特别地,对于n取得较小值的情况,当n=1,就是一元模型(unigrammodel),即为:
(3)
当n=2,就是一个二元模型(bigrammodel),即为:
(4)
当n=3,就是三元模型(trigrammodel),即为:
(5)
在实践中用的最多的就是二元模型和三元模型了,而且效果很不错,四元或高于四元的模型由于需要的训练语料过于庞大,训练时间较长,而且精度效果提升不明显而较为少用.本文使用二元模型(bigrammodel)来提取文本的2-gram特征(bigram特征),并使用卡方统计方法过滤掉低频的bigram特征.
如表1所示,我们对两种特征的文本用Word2vec工具进行处理,得到原始的文本词向量和bigram文本词向量.
表1 两种模型的特征向量
Table 1 Characteristic vectors of the two models

原句美国对中国发起了贸易战Word2vec特征‘美国’‘对’‘中国’‘发起了’‘贸易战’ Bigram 特征 ‘美国/对’‘对/中国’‘中国/发起了’ ‘发起了/贸易战’
结合这两种词向量(Word-NG向量)作为文本的总特征,不但考虑了“词语相似性”,还兼顾了“局部词序特征”,这样就可以区分出到底是“美国对中国发起了贸易战”,还是“中国对美国发起了贸易战”了.WordNG-Vec词向量模型构建流程如图1所示.
3.2 双输入通道的卷积神经网络分类模型(DC-CNN)
卷积神经网络(CNN)是一种有监督的分类模型,具有强大的局部特征提取能力,在语音和图像处理方面已取得巨大的成功,近年来逐渐被引入到自然语言处理领域.
本文借鉴文献[11]中经典的卷积神经网络分类模型(TextCNN),在结构上做以下改进形成本文的分类模型(DC-CNN),如图2所示.
1http://thuctc.thunlp.org/message
模型输入层:为了丰富文本的特征信息,把文本词向量和Word-NG向量作为模型两个通道的输入,输入分别表示为T1=[x1,x2,…,xn]T,T2=[y1,y2,…,ym]T,其中,T1,T2为输入矩阵,xi,yi为第i个相应的词向量,设定为100维.

图1 WordNG-Vec模型构建流程Fig.1 WordNG-Vec model building process
卷积层:为了在卷积操作的过程中避免损坏bigram特征信息,同时能捕获更多的上下文信息,本文在T1通道上采用unigram、bigram、trigram三组卷积核,即每次卷积操作分别覆盖一个词、两个词和三个词,每组卷积核20个;在T2通道上只采用unigram卷积核,共60个.卷积运算操作如下:
C1=f(W1·T1+b1)
(6)
C2=f(W2·T2+b2)
(7)
其中,W1,W2为两个通道上的卷积核权重,b1,b2表示偏置,f(·)选择常用的非线性激活函数ReLU,f(x)=max(0,x).

图2 DC-CNN模型Fig.2 DC-CNN model
池化层:池化操作是对卷积特征进行再次筛选,提取出主要的特征,对特征向量进行降维,减少模型的计算量,并提升模型的畸变容忍能力.常见的池化方法有平均池化(averagepooling)、最大池化(maxpooling)和K_max池化(K_maxpooling).文本采用K_max池化方法(K取2,取最大的两个值)以保留更多的特征.假设句子的长度为L,卷积核高度为h,则池化操作表示为:
C=K_max[c1,c2,…,cL-h+1]
(8)
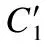
输出层(Softmax层):假设有M个类别的文本,那么特征向量C′经过Softmax层的处理后映射为M个概率的序列P.表示为P=[p1,p2,…,pM].其中判定输入x为第i类的概率由下面的公式得到:
(9)
模型的训练过程使用误差后向传播算法(EBP)和随机梯度下降法(SGD)对模型参数进行调整.
4 实验结果与分析
实验平台:ubuntu17.04.
实验工具:数据预处理基于jieba分词库、nltk自然语言处理工具、Word2vec词向量训练工具;分类模型基于Tensorflow搭建,编程语言采用Python.
4.1 文本数据预处理
本文使用的数据来源于清华大学THUCTC文本分类工具提供的新闻文本语料1,选取其中的6个类别:娱乐、体育、房产、游戏、股票、彩票.在每个类别中各选取10000个文档组成训练集和测试集,即训练集和测试集各3万篇.
首先对文本进行数据清洗,去掉标点符号和特殊符号,然后用jieba分词工具进行分词,处理之后的数据形式为词与词之间用空格分开,单个文本与标签之间用“__label__”分隔.接着用自然语言处理工具nltk完成bigram文本的提取,最后用Word2vec工具对语料进行训练得到bigram词向量和文本词向量(词向量维度为100).
4.2 模型超参数设置
在T1通道上采用unigram、bigram、trigram三组卷积核,每组卷积核20个,在T2通道上只采用unigram卷积核,共60个;每轮的迭代样本数(batch_size)为64,共迭代训练20轮;训练过程中使用L2正则化方法对参数进行约束,使用dropout机制随机丢弃一部分神经元的更迭,设定值为0.5,防止模型过拟合.
4.3 评估指标
在机器学习领域,常用的评价指标有精确率(precision)、召回率(recall)和F1值.在测试集中,假设在判断是否是某类别的样本中,所有被正确检索到的样本记为TP,实际检索到的总样本记为TA,被误检索到其他类别的样本记为FN.则精确率为P=TP/TA,召回率为R=TP/(TP+FN),F1值就是精确率和召回率的调和均值,即F1=2PR/(P+R).
4.4 实验对比与分析
本文设置了三组对比实验来评估所提出的分类模型和词向量模型的性能.
a)分类模型对比.实验采用Yoon Kim 提出的模型—TextCNN(双通道模型),作为对比模型和本文的模型(DC-CNN)进行对比,输入数据都是Word-NG词向量,对比结果如表2所示.
表2 模型实验对比结果
Table 2 Model experimental comparison results

分类模型精确率P召回率RF1值TextCNN0.8530.8390.846DC-CNN0.8550.8410.848
表2展示了DC-CNN和TextCNN模型的试验对比结果,可以看出两者都有着不错的分类效果,但DC-CNN的效果要提升一点,主要原因是DC-CNN在池化层使用K_max池化代替了最大池化,保留了更多的特征.
b)文本词向量对比.由于“文本词向量”和“bigram向量”均为单一文本向量,为了解决模型的输入问题,借鉴了文献[11]中TextCNN模型通道调整方法(static和non-static两个通道的动态调整,以减少由于训练集和测试集语料不一致导致“词向量”存在的偏差,以及提升训练时的收敛速度和模型效果),在DC-CNN模型中,以“文本词向量”作为输入时,关闭T2通道,以“bigram向量”作为输入时,关闭T1通道,而以“Word-NG向量”作为输入时,不关闭任何通道.模型内部参数保持不变.实验对比结果如表3所示.
表3展示了不同文本词向量的实验对比结果,可以看出,单独使用“bigram向量”的效果最差,原因是很多相邻上下词之间的组合并不能构成有意义的词组,训练的词组向量往往不能代表原文语义;使用原始的“文本词向量”比“bigram向量”提在F1值上升了0.159,说明训练出能够代表原文语义的独立词向量对提升文本的分类效果有着重要意义;当以“Word-NG向量”作为输入时,效果最佳,在精确率、召回率、F1值三个指标上都有明显的提升,因为结合这两种词向量能够兼顾独立词的语义以及局部的词序信息,极大丰富了文本输入表示的特征.
表3 不同文本词向量的实验对比结果
Table 3 Contrast results of word vector experiments
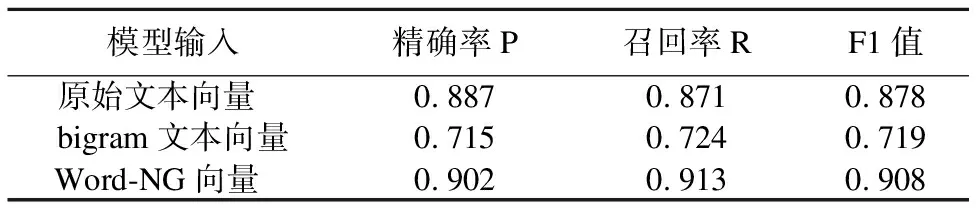
模型输入精确率P召回率RF1值原始文本向量 0.8870.8710.878bigram文本向量0.7150.7240.719Word-NG向量 0.9020.9130.908
c)词语建模方法对比.为了研究局部词序信息对文本分类效果的影响,Johnson在文献[8]中提出了经典的Bow-CNN模型,将附近的连续几个单词映射成一个词向量,在更高维的层面提取出词序特征.本文提出的WordNG-Vec词向量模型和Bow-CNN模型的对比结果如表4所示.
表4 词语建模方法对比
Table 4 Comparison of the modeling of word vector

词向量模型精确率P召回率RF1值Bow-CNN 0.8130.8080.810WordNG-Vec0.9020.9130.908
表4展示了WordNG-Vec与Bow-CNN模型的实验对比结果,可以看出WordNG-Vec的各项指标相比后者均有明显的提高.原因是Bow-CNN模型在对文本向量的预处理过程中还是显得略微粗糙,直接将附近的连续几个词映射成一个词向量,虽然在一定程度上能够提取出“词序特征”,但忽略了单个词语语义特征对整体文本特征的作用,而WordNG-Vec模型能够很好的把两者结合起来,提升了文本特征的表达能力.
5 结束语
本文借鉴文献[6]、文献[7]的思想,提出了结合N-Gram特征与Word2vec的词向量模型WordNG-Vec,该模型利用N-Gram模型中的二元模型提取出bigram特征文本,并用Word2vec工具训练得到了融合单个语义特征和局部词序特征的Word-NG向量.该向量作为文本的输入表示,能够捕获文本内在的局部词序特征,提升文本输入表示的特征表达能力;在分类模型上借鉴文献[11]的TextCNN模型,在结构上进行局部优化,形成本文的DC-CNN模型.通过对清华大学THUCTC的新闻文本数据进行实验对比表明,本方法在精确率、召回率、F1值三个指标上相对基准模型有一定的提升,证明了本方法的有效性和可行性.
