基于高光谱成像技术的工夫红茶数字化拼配
2019-03-11宁井铭李姝寰王玉洁张正竹陆国富
宁井铭,李姝寰,王玉洁,张正竹,宋 彦,徐 乾,陆国富
(1.安徽农业大学 茶树生物学与资源利用国家重点实验室,安徽 合肥 230036;2.祥源茶业有限公司,安徽 祁门 245600)
工夫红茶是中国传统出口茶类之一[1]。拼配是工夫红茶生产和经营中重要的工序,是保持产品质量稳定的重要手段。茶叶拼配是根据成品茶的质量标准(一般以实物样为标准),将多种不同的筛号茶(原料),按一定的比例混合,组成某一确定花色等级的成品茶[2-4]。对于同一款产品,如采用高等级原料拼配而成,企业的经济利益就会受到损失;如用低等级原料拼配,又会达不到产品质量要求,因而拼配对于茶叶企业而言至关重要。准确掌握拼配质量是调剂茶叶品质,稳定产品质量,充分发挥茶叶经济价值,提高经济效益的关键环节。目前,茶叶拼配通常采用的方法是由拼配人员先对各茶叶样品进行外观和内质审评,再根据经验和审评结果,试拼小样,然后进行适当调整,最终确定拼配方案[5],因而不同批次拼配结果具有偶然性,无法进行量化、标准化生产。另外,拼配专家的培养过程较为漫长,不利于拼配技术的推广。
高光谱图像技术融合了光谱信息和图像信息,既能利用光谱信息分析样品的内部品质信息,也能基于图像信息表征样品的外部品质特征[6-8]。近年来,高光谱图像技术在农业生产得到了广泛应用[9-13]。高光谱图像技术在茶叶上的研究主要集中在茶类识别、等级划分、茶园管理以及茶叶品质检测等方面。蔡健荣等[14]结合纹理特征值和支持向量机的模式识别方法进行了碧螺春茶叶的真伪鉴别;艾施荣等[15]也通过纹理特征值结合BP神经网路方法对不同产地的庐山云雾进行了鉴别。于英杰等[16]结合20 个光谱特征参数和支持向量机分类模型对不同等级的铁观音茶叶进行等级分类识别;茶园管理主要体现在叶绿素含量及分布在线无损检测以及茶树缺素诊断[17]和病虫害检测[18]等方面。熊俊飞[19]利用高光谱图像技术结合表面增强拉曼技术快速检测茶叶中的农药残留。李浬[20]结合纹理特征值快速检测出龙井茶的含水率,并建立了含水率预测模型。高光谱图像技术应用到预测茶叶拼配配比的研究,鲜见相关报道。对茶叶拼配质量的定量化、智能化评估,实现拼配过程的自动化,是未来拼配技术的发展趋势。
由于生产中茶叶拼配涉及的原料太多,比较复杂,因此,本研究采用4 种原料进行拼配,依次逐步判别。以不同等级不同唛号的祁门红毛茶为原料[21],按照一定比例进行拼配,采集拼配样本的高光谱图像,利用连续投影算法筛选特征光谱变量,并基于灰度共生矩阵提取图像的纹理值,融合光谱和纹理特征值建立茶叶拼配比例的定量预测模型,构建拼配比例求解与优化算法。本研究将为茶叶拼配工艺提供一种品质定量评估的新方法,研究结果有利于提高拼配工艺的自动化、智能化水平,推进茶叶生产标准化。
1 材料与方法
1.1 材料
实验材料来自祥源茶叶股份有限公司,原料A:祁门工夫红毛茶5 级6 孔正子口;原料B:祁门工夫红毛茶6 级8 孔正子口;原料C:祁门工夫红毛茶6 级6 孔正子口;原料D:祁门工夫红毛茶5 级8 孔正子口。
1.2 仪器与设备
高光谱图像系统(HSI-NIR-XEVA,五铃光学股份有限公司),系统主要由高光谱图像摄像仪(Imspector V17E, Spectral Imaging Ltd., Oulu, Finland)、2 个150 W的光纤卤素灯(3900型,Illumination Technologies Inc., New York, USA)、移动平台、暗箱以及包括图像采集和分析软件(Spectral Image Software, Isuzu Optics Corp., Taiwan, China)的电脑等组成。
1.3 方法
1.3.1 样本处理
由于在生产中用于拼配的原料太多、太复杂,本研究采用逐步判别的方法,首先采用2 种原料进行拼配、判别,再采用4 种原料进行拼配、判别,依次类推。实验采用原料A和B按照比例0%~100%,以10%的变化为梯度且每个梯度拼配10 个样本,共拼出110 个样本,原料C和D按照同样的比例拼出110 个样本。分别从2 次拼出的茶样中任挑一个比例的拼配样本,本实验挑取的是由原料A与原料B以5∶5的配比拼出的茶样P1,以及由原料C与原料D以5∶5配比拼出的茶样P2。然后由P1和P2再次按照比例0%~100%,以10%的变化为梯度拼出110 个样本。利用高光谱图像系统采集茶样的高光谱信息。全部样品按照2∶1的比例将样品随机分成校正集(73 个)和预测集(37 个),利用校正集的样品建立判别模型,预测集的样品测试模型的性能。
1.3.2 高光谱图像采集和处理
为防止信息的过度饱和成像失真,需对高光谱成像系统的参数进行设置。经过反复调节,最终曝光时间设置为2 ms,物镜的高度设为26 cm。拼配样品(10±0.5)g均匀平铺在规格为7.5 cm×1 cm的培养皿中,置于移动平台上以7.2 mm/s的速率采集高光谱图像。系统的光谱分辨率5 nm,光谱范围为908~1 735 nm,共508 个波段。样本在图像采集的过程中,由于受高光谱成像仪硬件的影响,获取的样本数据在采集开始和结束时受噪声的影响较大,因此在后续的数据处理过程中,选取957~1 670 nm波段范围内,共438 个波段的高光谱图像进行分析。
在高光谱成像系统中,光源强度分布不均匀。因此在对高光谱图像处理前,先要按照式(1)对图像进行黑白校正。

式中:Rc为校正后的图像;R为原始的图像;B为黑板校正的图像;W为白板校正的图像。
1.4 数据分析
1.4.1 主成分分析法
高光谱数据量庞大,因此,要对高光谱数据进行降维,去除冗余信息,优选特征波长。主成分分析[22](principal component analysis,PCA)法主要是通过协方差最大的方向将高维数据空间向低维数据空间投影,将原始数据转化到新的坐标系统中[23],得到几个彼此相互独立的综合变量,且都是原始数据的线性组合,本研究根据方差贡献率提取主成分图像,并通过比较主成分图像下各波长的权重系数的绝对值大小优选特征波长。
1.4.2 光谱特征值的选取
连续投影算法(successive projections algorithm,SPA)[24]利用向量的投影分析,在光谱信息中充分寻找含有最低限度的冗余信息的变量组,将变量间共线性的影响降到最低,从而减少信息的重叠,同时筛选出的几个变量就能代表原始数据的大部分信息,提高了建模的速度和效率。
1.4.3 纹理特征提取
基于灰度共生矩阵提取特征波长图像下的纹理值。灰度共生矩阵[25]是关于图像亮度变化的二阶特征统计[26],是计算特定像素间距离和角度的函数。本实验中,距离设置为1,对0°、45°、90°和135°四个角度的对比度、相关性、能量和同质性提取纹理变量。其中对比度反映目标图像的纹理沟槽的深浅程度以及清晰度;相关性是对目标图像灰度矩阵所有元素在图像的行、列方向相似度的体现;能量反映了目标图像在灰度方面的纹理粗细与均匀度;同质性则体现目标图像的局部平滑[27]。
1.4.4 建模方法的筛选
偏最小二乘(partial least squares,PLS)法[28]结合了PCA和多元线性回归的化学计量学方法,通过优选因子数达到最佳的模型效果。最小二乘支持向量机(least squares-support vector machine,LS-SVM)是Suykens等[29]为减少计算复杂程度、降低训练时间以及提高泛化能力提出的一种在经典SVM上改进后的新型统计学习方法。其优势是在于采用了等式约束,使用求解线性方程组的方法得出最优化结果,占用内存小,求解速度高。采用径向基核函数(radial basis function,RBF)两个重要参数为回归误差权重γ和RBF核函数的核参数δ2。这两个参数字在很大程度上决定了算法的学习和泛化能力,采用二次网络搜索和留一交叉验证的方法对γ和δ2进行了全局寻优。初始值分别设置为100和0.1。反向传播人工神经网络(back propagation-artificial neural networks,BPANN)是一种反向传递并修正误差的多层映射神经网络,具有很强的非线性建模能力,适合解决复杂的映射问题。
1.4.5 数据分析软件
ENVI 4.7(ITT Visual Information Solutions, Boulder, USA),Matlab 2014a(The Mathworks Inc., Massachusetts, USA)。
2 结果与分析
2.1 不同样品的光谱差异
本实验采集908~1 735 nm波长范围的近红外光谱数据,选择图像中间100×100像素范围为感兴趣区域(region of interest,ROI),提取ROI所有像素的光谱值,并计算出其平均值,作为这个样本的光谱值[30]。化学含量以及物理特征的不同,样本对特定的波长有着不同的反射率,通过分析光谱信号的差异实现样本品质信息的定性或者定量检测。原料C和原料D光谱值差异比较明显,从图1可以看出,3 条光谱曲线的趋势相似,在1 112 nm和1 307 nm波长处出现明显的特征峰,且峰的高低有明显差异。
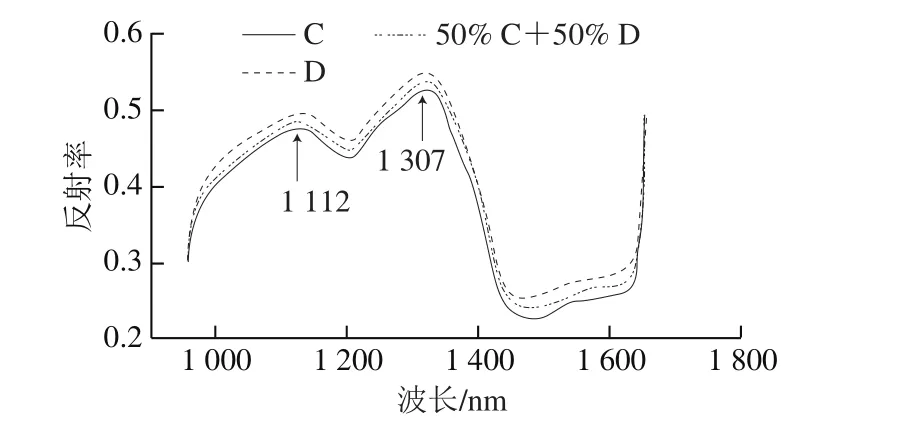
图1 茶样C、D与拼配茶样的平均光谱图Fig. 1 Average reflectance spectra of samples C and D and their blend
2.1.1 光谱预处理方法筛选
为减少实验中外界环境的噪声对信息带来的影响,本实验比较了一阶导数、平滑、极小/极大归一化和标准正态变量变换4 种光谱预处理方法对原始光谱进行处理,4 种方法预处理后的光谱图见图2,并且采用PLS分别建立定量模型,分析光谱预处理方法对建模结果的影响,结果如表1所示。
图2 一阶导数(a)、平滑(b)、归一化(c)和标准正态 变量变换(d)预处理后的光谱图Fig. 2 Preprocessed spectra with first derivative (a), smoothing (b),maximum-minimum normalization (c) and standard normal variate (d)
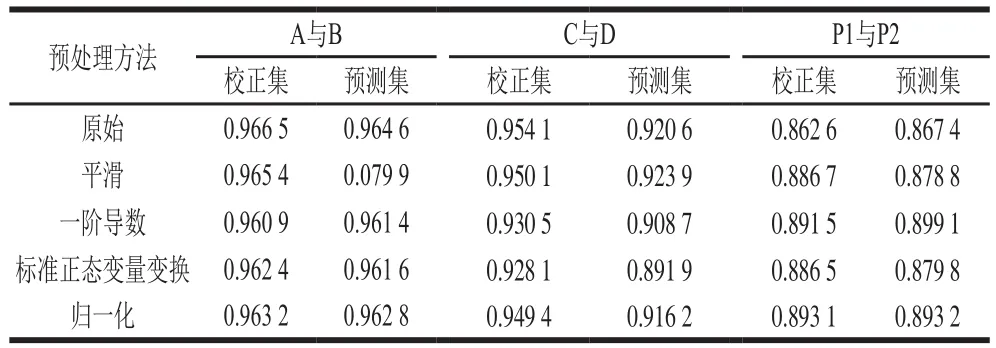
表1 不同预处理方法拼配样PLS模型的结果比较Table 1 Comparison of the results of PLS with different preprocessing methods for calibration and prediction sets
表1通过对比校正集相关系数(Rc)和预测集相关系数(Rv)确定各预处理方法的效果。其中原料A与原料B的拼配样,由于进行光谱预处理后建立模型的效果并没有明显优于原始数据,从建立模型简单易行的角度考虑,认为原始光谱数据最优,所以后面的数据处理全部是基于原始光谱数据。原料C与原料D的拼配样,通过比较校正集与预测集的相关系数,平滑为最佳预处理方法。P1与P2的拼配样,归一化为最佳预处理方法。
2.1.2 光谱特征值的选取
全光谱的波段较多,数据量大,且数据间冗余性强,本实验通过SPA提取特征光谱值。图3表示的是原料A和原料B拼配样本通过SPA优选特征光谱变量的过程,当输入模型的变量个数为10时,RMSE最小,为0.048,所以最终优选出10 个特征波长;这10 个特征波长的位置依次为966、1 019、1 113、1 267、1 338、1 386、1 627、1 647、1 660、1 670 nm。
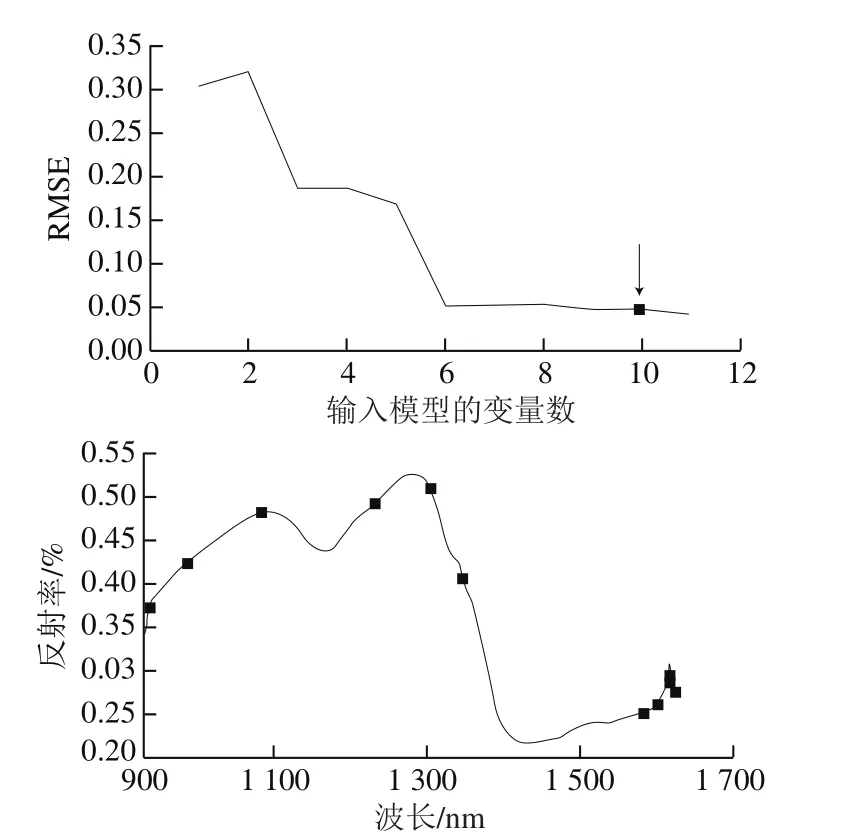
图3 SPA筛选特征光谱变量过程图Fig. 3 Selection of characteristic spectral variables by SPA
2.1.3 PCA结果
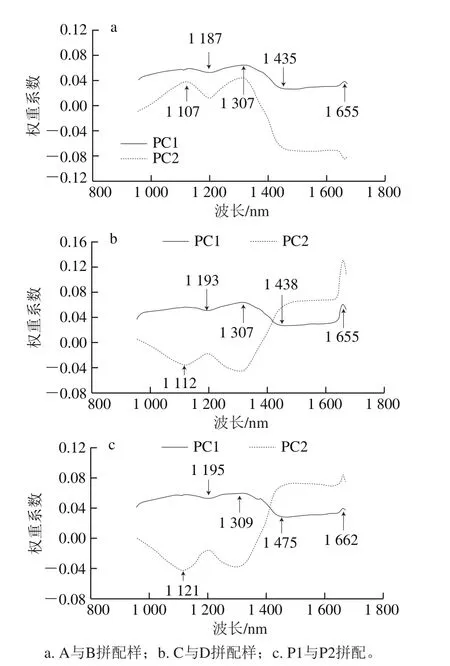
图4 拼配茶样的权重系数图Fig. 4 Weighted coefficient plots for tea blends
依次对3 次拼出的茶样高光谱图像进行PCA,得到前3 个主成分图像,其中A与B、C与D、P1与P2拼配样的PC1的方差贡献率分别为98.85%、98.51%和97.20%,PC2的方差贡献率分别为0.79%、1.20%和2.08%,前2 个主成分的累计方差贡献率均达到了99%以上,几乎可以代表全部信息,因此,可以利用前2 个主成分来进行特征波长的提取。如图4所示,根据前2 个主成分图像下各波长的权重系数的绝对值的大小优选5 个特征波长。
如图4所示,A与B拼配样的特征波长为1 107、1 187、1 307、1 435、1 655 nm;C与D拼配样的特征波长为1 112、1 193、1 307、1 438、1 655 nm;P1与P2拼配样的特征波长为1 121、1 195、1 309、1 475、1 662 nm。
2.2 图像纹理特征值分析结果
基于灰度共生矩阵的方法来计算茶样图像的纹理,提取5 个特征波长下的纹理特征为特征变量。即对A和B在1 107、1 187、1 307、1 435、1 655 nm波长处的灰度图像分别提取0°、45°、90°、135°的对比度、同质性、能量和相关性。对C和D在1 112、1 193、1 307、1 438、1 655 nm波长处的灰度图像分别提取4 个角度的对比度、同质性、能量和相关性。在茶样表面沟纹越深、灰度差越大,则对比度越大,反之越小;若茶样灰度分布均匀、纹理较粗糙,则能量值越大,反之越小;同质性体现目标图像的局部平滑;茶样的灰度共生矩阵值均匀相等时,相关性较大,反之较小。如表2所示,相比而言,原料A沟纹较深、灰度差大,纹理较平滑,条索较紧细;原料B沟纹较浅、灰度分布较均匀,纹理较粗糙,条索较松散;原料C沟纹深度次于原料A,灰度差大,纹理平滑,条索紧细;原料D沟纹稍深于B,灰度分布较均匀,纹理粗糙程度稍高于B,条索较松散。
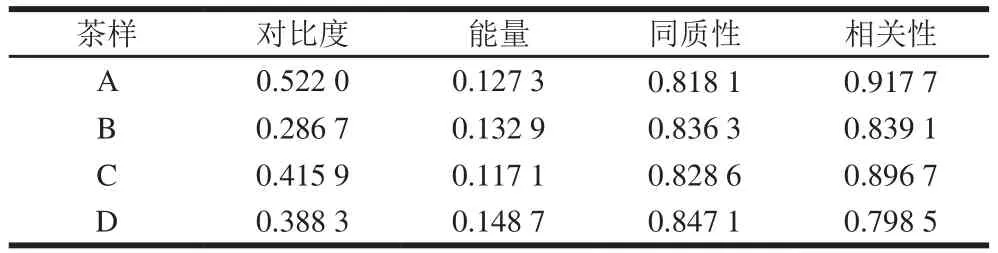
表2 基于灰度共生矩阵的纹理特征均值Table 2 Mean textual features based on gray level co-occurrence matrix
2.3 定量预测模型的建立结果
光谱特征能表征拼配茶叶的内部品质,纹理特征能表现拼配茶叶外形特点。为更好地表示拼配茶叶随着拼配比例的不同茶叶整体品质发生的变化,本研究将优选的光谱特征值与纹理特征值在特征层[31]进行融合。分别将光谱特征值、纹理特征值以及光谱和纹理特征值融合得到的数据作为PLS、LS-SVM和BP-ANN模型的输入值,建立拼配茶样配比定量预测模型,结果如表3所示。以光谱特征值和纹理特征值融合数据作为LS-SVM模型的输入值时预测结果最好,原料A与原料B拼配样预测集判别率为91.89%,原料C和原料D拼配样预测集判别率为86.13%,茶样P1和茶样P2拼配样预测集判别率为94.5%,其中通过预测茶样P1、P2配比,即可分别得到原料A、B、C、D的配比,可以间接解决4 个原料茶样拼配预测配比的问题。结果表明本研究能实现对拼配茶样配比的量化判别。
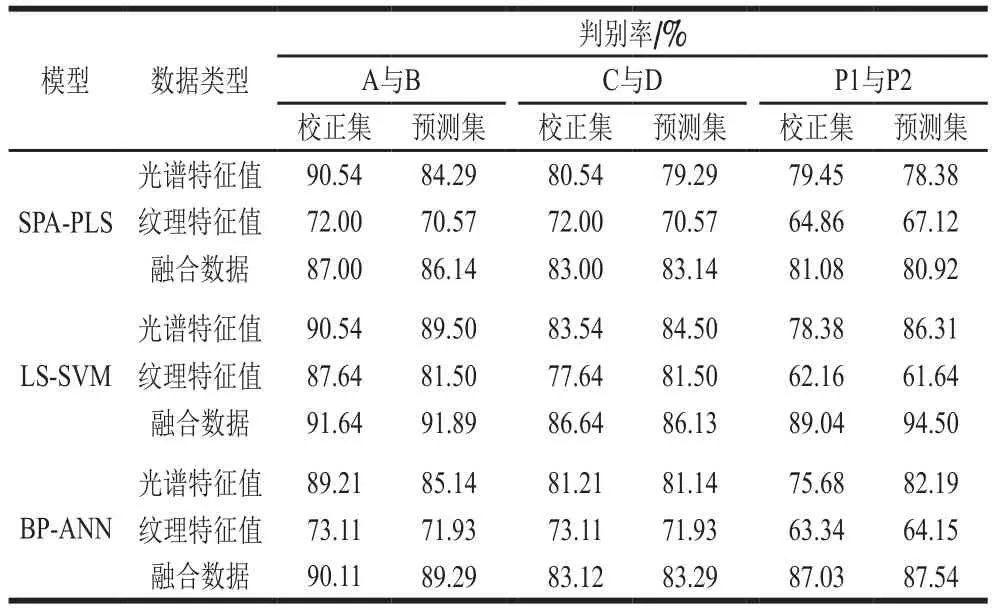
表3 拼配茶样配比预测结果Table 3 Comparative evaluation of three prediction models based on different input values
2.4 模型的验证结果
为验证模型的稳定性,重新拼出30 个样本进行模型的外部验证。其中P3茶样是原料A与原料B配比为3∶7的拼配样,P4茶样是原料C与原料D配比为6∶4的拼配样。通过PLS筛选出90 个变量,导出预测集模型和系数,然后代入计算预测出样本的配比。由表4建模结果可知,总判别率达到86.7%,发生误判的样本分别为第7、26、29、30个茶样。此结果达到了具有统计学意义的判别率不低于85%的要求。

表4 验证模型判别结果Table 4 Validation of the LS-SVM prediction model
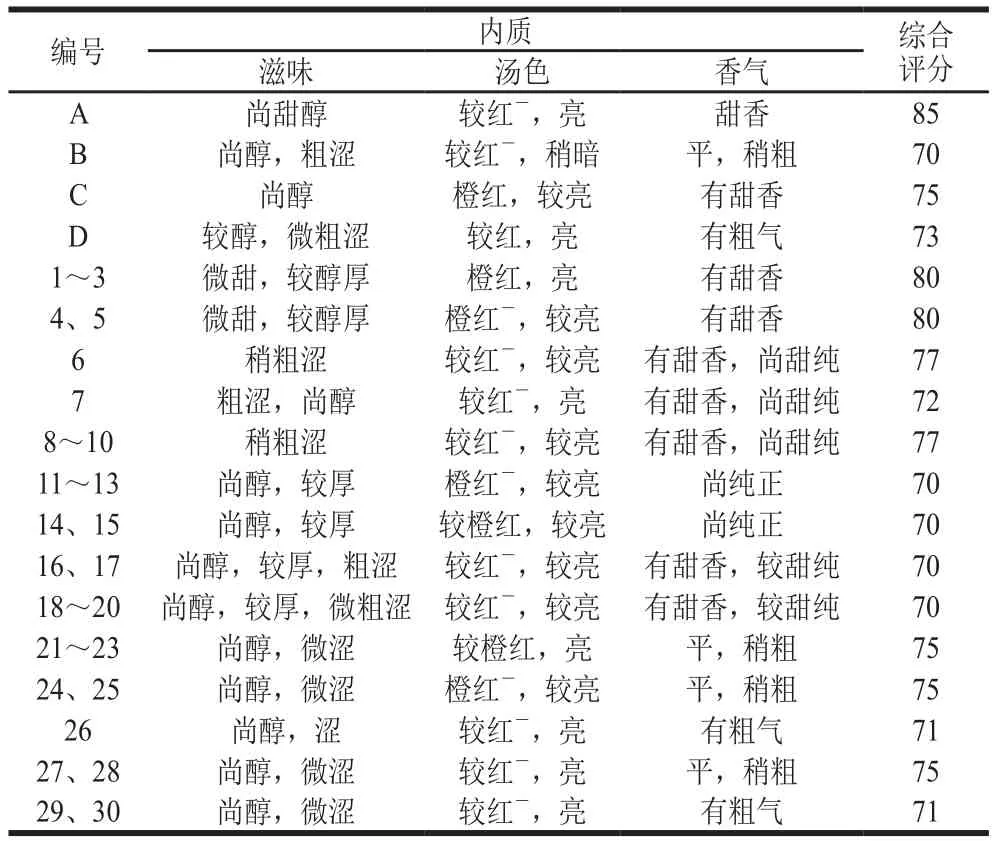
表5 拼配茶样审评结果Table 5 The result of tea tasting of tea blends
本实验对以上30 个拼配样本审评,并将原料茶样A、B、C和D作为标准样。由于光谱信息是对内质的反映,所以更偏重于对滋味的评审,并依据GB/T 13738.2—2017《红茶 第2部分:工夫红茶》感官品质要求进行评分,结果如表5所示,从审评结果可以看出,编号分别为7、26、29、30的样本所得分数与组内其他样本分数相差相对较大,与模型验证的结果一致。
3 讨 论
本研究利用高光谱图像技术获取经4 种茶原料按照一定比例拼配出的茶样的光谱图像,通过PCA法提取出5 个特征波长,然后进行光谱数据与图像纹理数据的提取,本实验尝试基于光谱信息和图像信息融合技术结合模式识别,预测拼配茶叶的配比。结果显示,融合光谱和纹理特征值结合LS-SVM模型算法,建立拼配茶叶配比预测模型,判别率最高,达到94.5%,预测结果较好。用模型以外的随机30 个样本进行对模型进行验证,结果其中有4 个样本发生误判,总判别率为86.7%,因采用的原料在品质上接近,对结果有一定的影响。
目前,拼配茶叶的配比通过高光谱图像技术结合数学模型可以相对准确地预测出,但是,实际生产中,茶叶拼配原料需要很多种,比较复杂,需要大量的数据对模型进行进一步的训练和优化,从而求解标准茶样中各原料的比例。
