GA-iForest:An Efficient Isolated Forest Framework Based on Genetic Algorithm for Numerical Data Outlier Detection
2019-03-07LIKexinLIJingLIUShujiLIZhaoBOJueLIUBiqi
LIKexin,LIJing*,LIU Shuji,LIZhao,BO Jue,LIU Biqi
1.College of Computer Science and T echnology,Nanjing University of Aeronautics and Astronautics,Nanjing 211106,P.R.China;2.State Grid Liaoning Electric Power Supply Co.,LTD,Shenyang 110004,P.R.China
Abstract:With the development of data age,data quality has become one of the problems that people pay much attention to.As a field of data mining,outlier detection is related to the quality of data.T he isolated forest algorithm is one of the more prominent numerical data outlier detection algorithms in recent years.In the process of constructing the isolation tree by the isolated forest algorithm,as the isolation tree is continuously generated,the difference of isolation trees will gradually decrease or even no difference,which will result in the waste of memory and reduced efficiency of outlier detection.And in the constructed isolation trees,some isolation trees cannot detect outlier.In this paper,an improved iForest-based method GA-iForest is proposed.This method optimizes the isolated forest by selecting some better isolation trees according to the detection accuracy and the difference of isolation trees,thereby reducing some duplicate,similar and poor detection isolation trees and improving the accuracy and stability of outlier detection.In the experiment,Ubuntu system and Spark platform are used to build the experiment environment.The outlier datasets provided by ODDS are used as test.According to indicators such as the accuracy,recall rate,ROC curves,AUC and execution time,the performance of the proposed method is evaluated.Experimental results show that the proposed method can not only improve the accuracy and stability of outlier detection,but also reduce the number of isolation trees by 20%—40%compared with the original iForest method.
Key words:outlier detection;isolation tree;isolated forest;genetic algorithm;feature selection
0 Introduction
As a significant subject,outlier detection has been widely researched recently.The general idea of outlier detection is to identify data objects that do not fit well in general data distribution.Outlier detection is related to many aspects of real life,such as track clustering[1],cyber malicious attacks,transaction fraud,grid data anomaly,and so on.For example,the governance of power grid data may be abnormal,missing and repeated to some extend for power data from different systems.These abnormal data often can reflect some potential problems faced by various business systems,power equipment and platforms in practical work.How to effectively govern the data from different sources will have a profound impact on the“management”,“viewing”,“using”and“checking”of data.How to detect and identify abnormal data(outlier)has become a hot research topic.
The definition of outliers given by Hawkins[2]is generally accepted,which is“An outlier is an observation that differs so much from other observation as to arouse suspicion that it was generated by a different mechanism”.In the field of outlier detection,the commonly used methods mainly include distance based[3-5],density based[6-8],cluster based[9-11],tree based[12-13],etc.
In the process of detecting outliers,traditional methods based on distance,density and clustering usually need to define abnormal distance,neighborhood radius,abnormal density,etc.,and then obtain outlier scores through a large number of calculations or comparisons on the whole dataset.The labels of data(outliers or inliers)are finally determined by different thresholds of different methods.These methods construct a profile of normal instances,then identify outliers that do not conform to the normal profile.In addition,some of these methods(such as clustering)don’t intend to specifically detect outliers which are merely a by-product.Therefore,these methods have two major drawbacks:(i)they are optimized to profile normal instances,but not optimized to detect anomalies.And the results of outlier detection might not be as good as expected causing too many inliers identified as outliers or too few outliers identified as inliers.(ii)Many existing methods can only be used in the small data size because of their high computational complexity.Later,an outlier detection algorithm based on isolated forest(iForest for short)appears.This method uses the idea of random sampling to sample the original dataset without using all the whole data when performing the outlier detection.Therefore,it does not require a large amount of calculations and comparisons.And the amount of calculation required for this method is greatly reduced.The method of iForest obtains a number of samples by randomly sampling the original dataset,and then establishes an isolation tree(iTree for short)on each sub-sample.It is considered that the data closer to the root node is more likely to be abnormal data.Finally,the path lengths of the data on different iTrees are integrated to obtain the final abnormal score by which the abnormality of the data can be judged.Although iForest has logarithmic time complexity and can effectively process large data sets,it also has the following drawbacks:
(i)Since iTree is constructed based on subsamples from random sampling,the structure of iTree built by different samples may be similar or identical.As the number of iTrees increases,the difference between iTrees gradually decreases,which will cause memory waste and unnecessary computational overhead.
(ii)The purpose of building iTrees is to find out which data is closer to the root node.However,due to the random sampling of the original dataset and the next construction of iTrees,it is possible that some of the iTrees are complete binary trees and cannot realize the detection of outliers.
(iii)Although the iForest can use part of the data to detect outliers through random sampling of the original data,the iTree established on different sub-samples will appear similar or repeated,so the detection results of outliers may vary greatly each time,and the stability of detection cannot be guaranteed.
In response to the above questions,a method is proposed to optimize the construction of iForest using genetic algorithm on the basis of the original iForest algorithm.The proposed method selects iTrees with high detection accuracy and large difference to form iForest,thereby optimizing the detection of outliers.In this paper,the detection accuracy,difference index and fitness function of the iTrees are established first,and then the iTrees selected by the genetic algorithm are used to improve the accuracy and stability of outlier detection.The main contributions of this paper are as follows:
(i)It has reduced the generation of 20%—40% iTrees and saved computing resources and memory space.
(ii)Some indicators are built for selecting iTrees,such as accuracy of each iTrees,similarity of difference iTrees and fitness function.
(iii)It has improved the stability of outlier detection by adding a selection process of iTrees according to the accuracy and similarity of each iTree.
1 Related Work
Outlier detection is a very popular area in the field of data mining.In recent years,many scholars have done a lot of work in this field.Here,several advanced and representative outlier detection methods are introduced.
The distance-based outlier detection method is a basic method for outlier detecting,which tries to find the global outliers far from the rest of the data based on k nearest neighbor distances of the data points.This method calculates the distance of the k nearest neighbors of each data as the abnormal distance,and then sorts the abnormal distance.The data with a large abnormal distance is more likely to be considered as outliers.Then,based on this point of view,some distance-based outlier detection methods are proposed,for example,KNN-weight[14].
The density-based approach and its variants try to find the local outliers located in a lower density region compared to their k nearest neighbors.This method defines the anomaly factor[15]concept for the first time and counts the number of neighbors within the specified radius of the data point as outlier score.It is generally considered that the data with a small outlier score is outlier.Based on the idea of density,some improved density-based outlier detection methods have been proposed,for instance,K-LOF[16].This method uses a clustering algorithm to find the center of the original dataset,and then determines whether the data is outlier according to the distance from the data to the center.
The cluster-based method divides the data into a series of clusters by basic cluster algorithm,and judges whether the data is abnormal according to the size of the cluster.The data in clusters with less data is generally considered to be outlier.Later,some scholars proposed an anomaly data recognition algorithm based on sample boundaries[10].Firstly,clustering was used to obtain the boundary sample set of normal clusters,and then the relationship between the data to be tested and the boundary sample set was analyzed.If the data to be tested belonged to the boundary sample set,it was judged as normal data;otherwise,it was outlier.
The above abnormal value detection methods are usually based on a large number of calculations or comparisons,which will result in a large computational overhead when the number of data is larger.In addition,these methods often under-perform resulting in too many false alarms(having normal instances identified as anomalies)or too few anomalies be detected.Although the emergence of iForestbased outlier detection methods have improved the efficiency of outlier detection,as mentioned above,it still has some shortcomings.Aryal at al.[17]pointed out that the underlying similarity or distance measures in iForest had not be well understood.Contrary to the claims that these methods never rely on any distance measures,they found that iForest had close relationships with certain distance measures.This implies that the current use of this fast isolation mechanism is only limited to these distance measures and fails to generalize to other commonly used measures.And then they proposed a generic framework named LSHiForest for fast tree isolation based ensemble anomaly analysis with the use of a locality-sensitive hashing(LSH)forest.This framework can be instantiated with a diverse range of LSH families,and the fast isolation mechanism can be extended to any distance measures,data types and data spaces where an LSH family is defined.Zhang et al.[18]indicated that while iForest-based methods were effective in detecting global anomalies,they failed to detect local anomalies in datasets having multiple clusters of normal instances because the local anomalies were masked by normal clusters of similar density and they became less susceptible to the isolation.And they proposed a very simple but effective solution to overcome this limitation by replacing the global ranking measure based on the path length with a local ranking measure based on relative mass that took local data distribution into consideration.Although the shortcomings of the iForest-based outlier detection methods were pointed out,they could not be fundamentally improved.In this paper,indicators such as detection accuracy and difference are established for the iTrees,and then the genetic algorithm is used to select the iTrees to filter those iTrees with low detection accuracy and duplicates or similar ones,so as to reduce the generation of iTrees and improve the effectiveness and stability of detection results.
2 The Proposed Solution
2.1 Fundamental iForest algorithm
The idea of the iForest algorithm comes from two characteristics of outliers[19]:(i)the exception data instance occupies a small part of the entire dataset;(ii)their attribute values are greatly different from the normal data attribute values.That is to say,the outliers are usually“less and different”,which makes them easily to be recognized by the outlier detection algorithm,i.e.“isolated”.
The iForest uses the structure of the binary tree to define the iTree.Since the outliers are usually a small part of the entire dataset,iForest can isolate the outliers to the leaf nodes that are close to the root node,thereby identifying the outliers.The key to iForest algorithm is to construct iTrees so as to form the forest.For the convenience of description,the notion of iTree and calculation method of path length and outlier score are defined as follows.
iTree Assuming that T is a node of an iTree,T is either an external node(leaf node)with no child or an internal node with one test and exactly two child nodes(Tl,Tr).The test at node T consists of an attribute q(segmentation attribute)and a split value p(segmentation value)so that the test q<p determines the traversal of a data point to either Tlor Tr.The data records less than the segmentation value are assigned to the left child node,while the data records larger than the segmentation value are assigned to the right child node.Repeat this process until the child node has only one data or has reached the maximum height of the iTree.
Let X={x1,x2,…,xn}be the given data set of a d-variate distribution.A sample ofφinstances X′⊂X is used to build an iTree.X′is recursively divided by randomly selecting an attribute q and a split value p,until either:(i)the node has only one instance or(ii)all the data at the node have the same values.An iTree is a proper binary tree,where each node in the tree has exactly zero or two daughter nodes.
Path length The path length h(x)of the data record x refers to the number of edges x traverses an iTree from the root node until the traversal is terminated at an external node.
Outlier score The path length of the data record in iForest algorithm is taken as an outlier score.Firstly,the length of the data record x in different iTrees is solved.Then the average path length of iTrees is calculated as a normalization factor.Finally,the outlier score of data record x is obtained by the normalization of path length.According to the binary search tree,for a sample instance with a given sample size ofφ,the average length of the corresponding binary search tree is
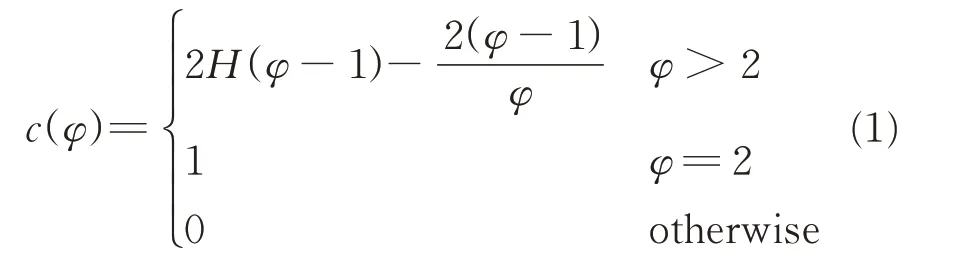
where H(φ)is the harmonic function and can be estimated by ln(φ)+0.577 215 664 9(Euler constant).As c(φ)is the average of h(x)givenφ,it can be used to normalize h(x).The outlier score s of an instance x is defined as
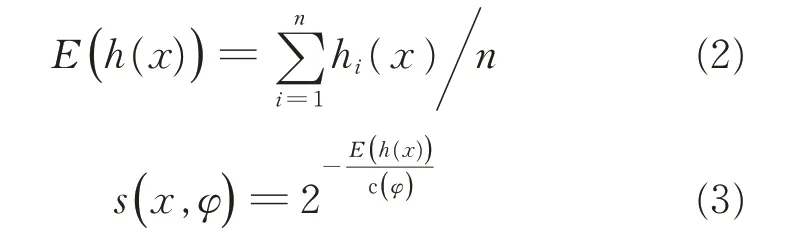
where hi(x)represents the path length of data x in the i th iTree and E(h(x))is the average of h(x)from a collection of iTrees.The following conditions provide three special values of the anomaly score.

The process of detecting outliers by the iForest algorithm can be divided into two steps:(I)The training process.The original dataset is randomly sampled,and multiple iTrees are constructed according to the sub-dataset.Then the iForest is composed by the constructed iTrees.(II)The evaluation process.The outlier score is calculated based on the path length of the data record in the constructed iForest.For the calculation method of the outlier score established above,the following assessments can be made:(i)the closer the average path length E(h(x))of data x is to the average length c(φ)of the corresponding binary search tree,the closer the outlier score s is to 0.5.If all the instances return s≈0.5,the entire sample does not really have any distinct outliers.(ii)The closer E(h(x))is to 0,the closer s is to 1.If instances return s very close to 1,they are definitely outliers.(iii)The closer E(h(x))is to the sampling sizeφ,the closer s is to 0 for the outlier score.If instances have s much smaller than 0.5,they are quite safe to be regarded as normal instances.
2.2 GA-iForest:iForest based on genetic algorithm
Although the iForest algorithm integrates the iTree through the idea of selective integration and realizes the accurate detection of abnormal data.However,it does not consider the difference between the iTrees(individual classifier),which will affect the final effect and the stability of the algorithm.In this paper,based on the original iForest algorithm,the idea of genetic algorithm is used to select the iTrees.After the selection of genetic algorithm,the iTrees with similarity,repetition and poor detection effect are removed,so as to improve the difference between individual classifiers and finally form a classifier with stronger generalization ability.
The iForest based on genetic algorithm(GAiForest)consists of three algorithms,whose specific descriptions are shown in Algorithms 1,2 and 3.Firstly,the iTree is constructed by sampling the original dataset.Secondly,the detection accuracy and the difference of the constructed iTrees are calculated according to the test data(randomly sampling from the original dataset and has no label).Thirdly,the iTrees with high detection accuracy and great difference are selected by the genetic algorithm according to the corresponding indexes.Finally,the selected iTrees are used to construct the iForest to calculate the outlier score,and the outlier is judged according to the outlier score.The general process of GA-iForest is shown in Fig.1.
The process of detecting outliers for GA-iForest can be roughly divided into five steps:sampling,building iTrees,selecting iTrees,building iForest,and scoring outliers.The specific steps for building iTrees,selecting iTrees,and scoring outliers are described in Algorithms 1,2 and 3.
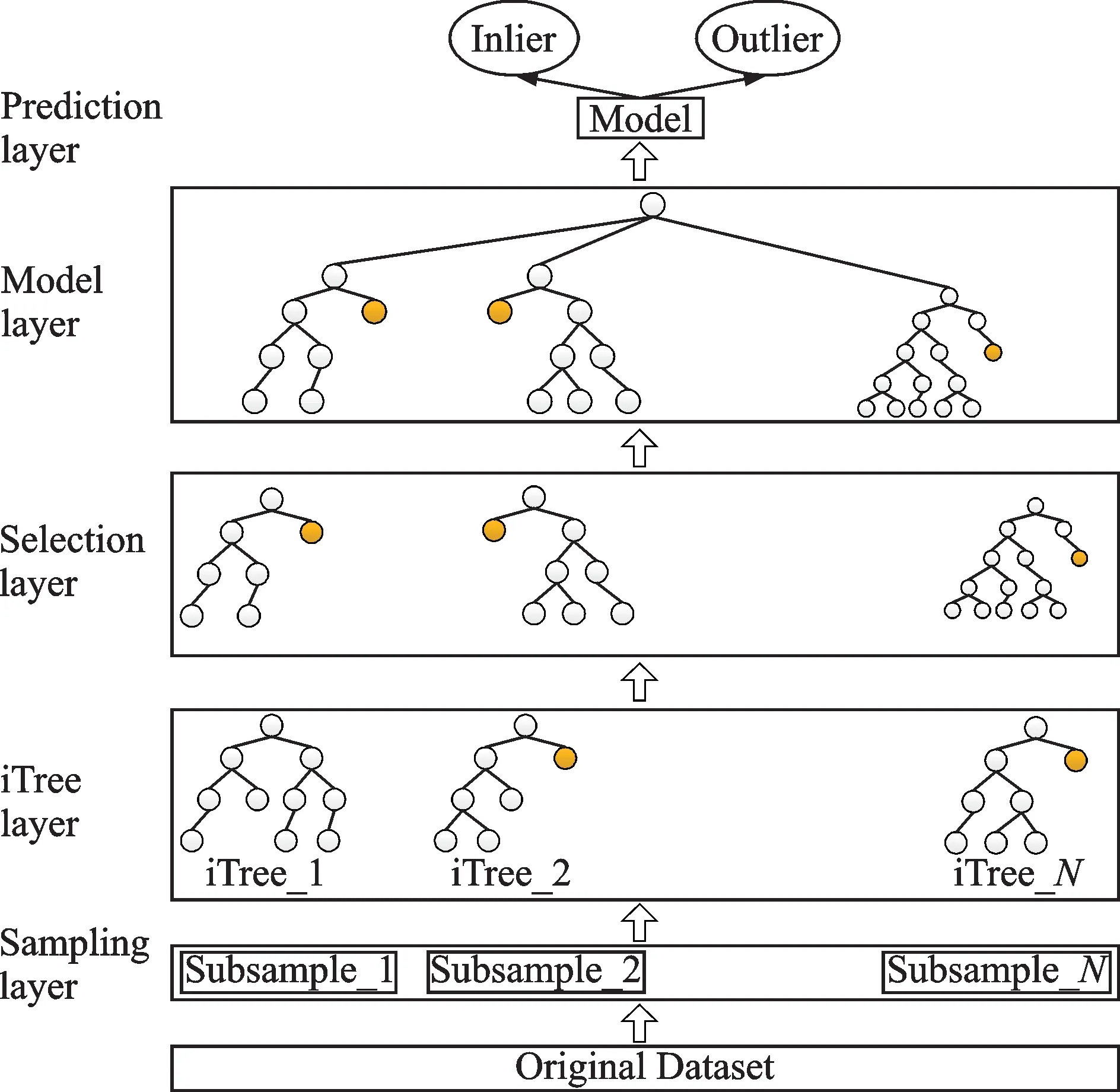
Fig.1 Framework of GA-iForest

images/BZ_156_1281_1464_2223_1522.pngInputs:X'-input data Output:an iTree 1.if X'cannot be divided then 2. return external Node{size←|X'|}3.else 4. let Q be a list of attributes in X'5. randomly select an attribute q∈Q 6. randomly select an split value p between the max and min values of the q 7. X l←select(X',q<p)8. X r←select(X',q≥p)9. return inNode{Left←iTree(X l),10. Right←iT ree(X r),11. SplitAttribute←q,12. SplitValue←p}13.End if
In algorithm 1,there is an input parameter,which is the sampled data.Different sub-datasets are obtained by subsampling approach[20]randomly sampling the original dataset,and then an iTree is established on each dataset.The process of building an iTree is the same as the iForest mentioned above.And then the iTrees are selected according to the detection accuracy and difference between the iTrees.The specific process of selecting is described in algorithm 2.The fitness function and related concepts in algorithm 2 are defined as Eqs.(4—7).

images/BZ_157_256_397_1194_456.pngInputs:M iTrees Output:the n optimal iT rees 1.encoding the iTrees according the accuracy and dissimilarity of each iTrees 2.initial population 3.calculate the fitness 4.for fitness value<expected and iterations<maximum do 5. nature select by the higher fitness with high probability of selection 6. cross with the probability P c 7. calculate the fitness 8. if fitness value>expected and iterations>maximum then 9. End 10. else 11. variation with probability P m 12. End if 13.End for 14.return n optimal iTrees
In this algorithm,a part of the data(randomly sampling from the original dataset and has no label)is used to calculate the detection accuracy and difference of the iTree,and then the genetic algorithm is used to select the iTrees.The iTrees with high detection accuracy and large difference are selected and then the iForest can be generated.

images/BZ_157_256_2110_1194_2168.pngInputs:D–input dataset,N–the sample size,M–the number of trees Output:outliers 1.set the parameters of the iTree 2.for i=1 to M do 3. X'←sample(D,N)4. iTree(X')5.End for 6.Select_iTree(iTrees)7.build the iForest according to the selected n optimal iTrees 8.calculate path length to get the outlier scores 9.rank the outlier scores 10.return outliers
Algorithm 3 is based on algorithms 1 and 2.In this algorithm,the iTrees are generated by algorithm 1,and then the iTrees are selected by algorithm 2.Finally,the iForest is constructed to calculate the path length of the data point and determine which data is abnormal according to the path length.The GA-iForest consists of the above three algorithms.The process of selecting the iTrees by genetic algorithm is divided into two steps.
The first step is to define the accuracy index of the iTree and the similarity index between different iTrees.To reduce the similar and repeated iTrees,the degree of similarity between different iTrees is measured by cosine similarity.The M datasets are obtained by randomly sampling the original data,and the M iTree(T1,T2,…,TM)are established according to algorithm 1.Then a part of the data D={d1,d2,…,dn}(randomly sampling of the original data and has no label)is used to selecting iTrees.For each data sample dj(1≤j≤n),if the score on Tiis greater than 0.6(this value is the abnormal value threshold),rij=1,otherwise 0.That is

The result vector Vi={ri1,ri2,…,rin}(1≤i≤M)is constructed for each iTree.The accuracy of each tree is defined as
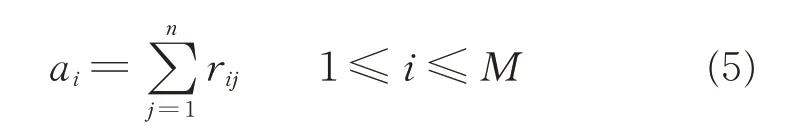
The similarity between the two trees Tiand Tjis

where“·”represents the inner product of the vector,“×”the normal multiplication,and||·||the length of the vector.Thus,the similarity coefficient matrix between M iTrees can be constructed as

It can be known from the linear algebra,if the similarity between two iTrees is lower,the value of cosine is close to-1.The higher of the similarity,the closer the cosine value is to 1.And the value of cosine on[-1,1]increases with the increase of the similarity.
In the second step,according to the difference index and the accuracy index,different test data(random sampling of the original dataset has no label)are used to compute the detection accuracy and similarity of different iTrees.Then,according to the detection accuracy of the iTrees and the dissimilarity between different iTrees,the fitness function is constructed.Finally the genetic algorithm is used to select the iTrees with high detection accuracy and small similarity.The fitness function is

where f(Ti)represents the fitness function of Ti,cosθijthe phase difference between Tiand Tj,ajthe accuracy of Tj,and w1and w2are the weights corresponding to the phase difference and accuracy,respectively.
The constructed M iTrees are selected according to the detection accuracy and the difference indexes defined above,and the specific steps are as follows.
(1)Individual coding:encoding the accuracy and difference of each iTrees.The accuracy uses the binary coding with the length■ ■logn2,and the difference uses the floating-point coding.
(2)Generation of initial population:a population of size n is generated,and the encoding format of each individual is(01110…1,0.54).The first dimension is the accuracy coding,and the second dimension is the difference coding with a floating point number between-1 and 1.
(3)Fitness calculation:the individual fitness is calculated according to the fitness function defined by Eq.(8).Fitness value determines the merits of each iTrees and the chance of inheritance to the next generation.
(4)Selecting the operation:the specific process includes:(i)Calculating the total fitnessof all individuals in the group;(ii)Calculating the relative fitness of the each individualand it is used as the group probability of each individual to inherit to the next generation;(iii)Calculating the cumulative probabilityof each individual;(iv)Generating a random number r in the interval of[0,1];(v)If r<q1,select individual 1,otherwise select individual k such that Pk-1<r≤Pkholds;(vi)repeat(iv)and(v)n times;
(5)Crossing:according to the probability Pcto exchange some codes between two individuals,a single point crossing method is adopted,such as the crossing of individual T1=(011 010…0,0.42)and individual T2=(101 010…1,0.35)at position 1.Ttturns into T1=(111010…0,0.42) and T2=(001 010…1,0.35)after crossing or the exchange of the second-dimensional decimal.
(6)Variation:the coding of a certain position of the individual was changed according to the probability Pm,for example,the fourth position of the first dimension of the individual Ti=(101010…0,0.42)is mutated.It turns to Ti=(101110…0,0.42)after the variation.
3 Analysis of Algorithm Complexity
3.1 Analysis of time complexity
In this paper,the genetic algorithm is used to realize the improvement of iForest.The algorithm complexity of iForest is analyzed firstly.In the iForest algorithm,the storage structure of the binary tree is used to construct the iTrees,and then the corresponding path length is calculated.For a binary tree,in the worst case where all nodes have only left children or only right children,the time of each search operation is T(n)=cn and the traversal can only be assigned into the left or the right subsequence each time.So the time complexity satisfies

In the average case,the binary tree is a full binary tree.Each search only needs to traverse half of the sequence,and then each traversal sequence is divided into two halves each time,so the time complexity satisfies
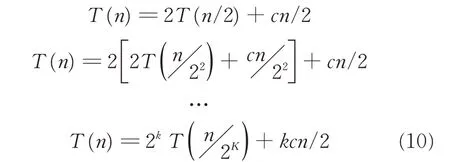
Supposing that 2k=n,then

For the iForest,the average time complexity is O(n log n).
For the genetic algorithm used in this paper,it can be seen as a ONE-MAX problem,which is a GA-easy problem.The problem can be described as

where x=(x1,x2,…,xn)is the individual code,xi∈{0,1};n the code length;the fitness function f(x)=x1+x2+…+xn.The optimal solution is x*=(11…1),and the optimal function value is f(x)=n.The following genetic algorithm is constructed to solve the time complexity of the above problems.
N samples are selected as the initial population,denoted asξ0.Let f(ξ0)=0 and k=0.
Reorganization operation:For any reorganization operation,generating a new population,denoted asξi;Mutation operation:For each individual xi(binary string)inξi,one bit is randomly selected and converted into its complement to generation a new individual yiand a new populationξN={y1,y2,…,yn};Selection operation:Select N individuals from the populationξNas the next generation population,denoted asξN+1,and concatenate k=k+1.If f(ξN+1)=n,the process is ended,otherwise the above process is repeated.
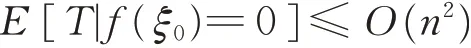
Prove Let T0=0,T1=T0+mki n {f(ξk+T0)≥1},… andthen
T=T1-T0+T2-T1+…+Tn-Tn-1
For a given m(1≤m≤n),let T′m=Tm-1+{f(ξk+Tm-1)=m},on the one hand

On the other hand,

So
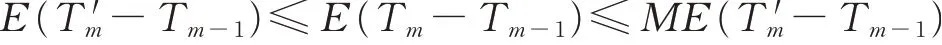
Let the populationξ′be the progeny population after a cycle of populationξ,since P(f(ξ′)<m-1|f(ξ)=m-1)=0,therefore

Therefore,the time complexity of genetic algorithm application in this paper is O(n2).
3.2 Analysis of spatial complexity
In this paper,the iTrees need to be constructed in the process of detecting outliers,and the construction process of iTrees is similar to the construction process of the binary tree.Therefore,the spatial complexity of the method is the same as that of the binary tree,namely O(N).
4 Experiment
In this paper,the"Spark on Yarn"cluster mode is used to construct the experimental environment of outlier detection.The experiment uses three virtual machines as the outlier detection nodes,one of which is the master and the other two are the slaves.Each node uses the Ubuntu-14.04 operating system, Hadoop-2.7.6, Spark-2.1.1-bin-hadoop2.7,Scala-2.11.7,and JDK-1.8.0_16 to build a software environment.The three virtual machines are all 4 G memory.In this paper,the parameter setting of the iForest and the GA-iForest is set by the default,that is,the number of iTree is 100 and the sampling size is 256.In the LOF algorithm,the parameter K is settled to 6.The experimental datasets are all from ODDS,and the specific information of the dataset is shown in Table 1.

Table 1 Infor mation of exper iment dataset
To verify that as the number of iTrees increases,the similarity between them gradually increases,the final detection accuracy is compared by changing the number of iTrees.In the experiment,two datasets of Annthyroid and Arrhythmia are selected as the representatives and AUC is used as the comparison index.The results are shown in Figs.2 and 3.
As can be seen from Figs.2 and 3,as the number of iTrees increases gradually,the value of AUC gradually tends to be stable.In Fig.2,when the number of iTrees is around 80,the change of detection accuracy AUC tends to be flat.While in Fig.3,when the number of iTrees is around 60,the detection accuracy AUC starts to be flat.This indicates that as the number of iTrees increases,the similarity between them increases gradually,leading to no significant improvement in detection accuracy.
Experiment 1 Comparison of detection accuracy and actual number of iTrees

Fig.2 Detection performance AUC varying with the number of iTrees on Annthyroid dataset

Fig.3 Detection performance AUC varying with the number of iTrees on Arrhythmia dataset
To verify the detection accuracy of GA-iForest,the datasets in Table 1 are used as the test data.For the sake of ensuring the credibility of the experiment,the experiment is performed 10 times and the average value is taken as the final result on each dataset.For the verification of the detection accuracy,ROC curve and the value of AUC are selected as metrics,whose results are shown in Figs.4,5 and 6.
From the above experiment,it can be seen that the ROC curve of GA-iForest can completely cover the ROC curves of iForest and LOF.It indicates the detection accuracy of the GA-iForest is better than iForest and LOF in Breastw and Forestcover dataset.The GA-iForest selects high-performance iTrees and optimizes the construction process of iForest.Therefore,GA-iForest algorithm can improve the detection accuracy of outliers.To fully verify the superiority of the detection accuracy of the GA-iForest to iForest and LOF,experiments on several other datasets are carried out,whose results are shown in Fig.6.

Fig.4 ROC curve on Annthyroid dataset

Fig.5 ROC curve on Forestcover dataset

Fig.6 AUC performance on the other datasets
It can be seen from the results of ROC curve and histogram of AUC performance that the proposed method GA-iForest is superior to the iForest and LOF in terms of detection accuracy.In this paper,efficient detection of abnormal data is achieved by filtering similar or repeated iTrees.Due to different datasets,the number of iTree reductions on each dataset is not equal,the specific results of iTrees reduction are shown in Table 2.
Experiment 2 Comparison of detection time
To compare the execution time of each algorithm,the above datasets are also used in this experiment.For GA-iForest and iForest algorithms,thetraining time and prediction time are selected as the comparison basis,and their total time is calculated.For the LOF algorithm,there is no training and prediction process,so the total time is directly used as the comparison basis.The specific running time of each algorithm is shown in Table 3.

Table 2 Reduction of iTrees on differ ent datasets
From Table 3,it can be seen that in terms of total time,the GA-iForest has no significant improvement compared with the iForest algorithm.The reason is that GA-iForest needs a selection process when training.For the sake of comparison,the predicted time and training time in Table 3 are made into a histogram,whose results are shown in Figs.7 and 8.
From the perspective of training time and prediction time,the GA-iForest requires longer training time and shorter prediction time.The reason lies in that the method in this paper will select the iTree when constructing the iForest,so the training time will be longer than the original method.Through the selection of genetic algorithm,the iTrees with partial similarity,repetition and poor detection ef-fect are reduced,so the prediction time will be improved to a certain extent.

Table 3 Compar ison of execution time s

Fig.7 Comparison of prediction time

Fig.8 Comparison of train time
Experiment 3 Comparison of algorithm stability
To compare the stability,the amount of change in detection accuracy AUC is chosen as the measurement index.The iTree established by iForest through random sampling will have similar structure or repeated iTrees.Due to the randomness of sampling,the results of each detection may be different.GA-iForest selects the iTrees with high detection accuracy and large difference for outlier detection by filtering the established iTrees.Although sampling is random,there is no similar or repeated iTrees after selection,which improves the stability of detection results.
The construction of iTrees is based on randomly sampled dataset.To compare the stability of the detection results,10 times experiments are used on a dataset(Mammography),and the mean detection accuracy AUC and the standard deviation of AUC for each experiment are compared.Fig.9 shows the variation of the detection accuracy of the three algorithms on Mammography dataset.Table 4 shows the average detection accuracy AUC and standard deviation of AUC of the three algorithms on different datasets.
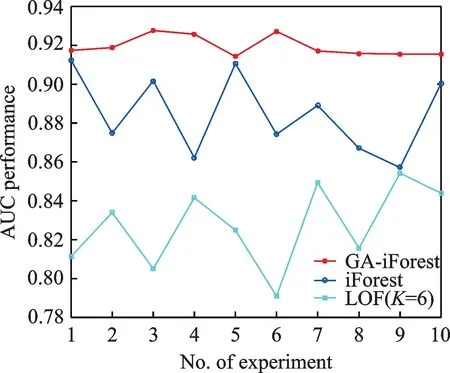
Fig.9 T he variation of detection accuracy
From Fig.9,it can be seen that GA-iForest has a smaller fluctuation range compared with iForest and LOF.It indicates that GA-iForest has the better stability on the Mammography.According to the calculation,the standard deviation of GA-iForest is 0.005 while iForest and LOF are 0.058 and 0.041,respectively.The variation of detection accuracy AUC is also compared on the other datasets,whose results are shown in Table 4.From Table 4,it can be known that the mean detection accuracy AUC of GA-iForest is higher than that of LOF and iForest,and the standard deviation of AUC is lower than that of LOF and iForest.It can be concluded that the stability of GA-iForest is better than LOF and iForest.The reason why GA-iForest is more stable in detecting accuracy is that the selection oper-ation of iTrees is added on the basis of the original iForest algorithm.Therefore,the uncertainty and similar iTree caused by random sampling is reduced.

Table 4 The mean and standard deviation of AUC performance
5 Conclusions
In this paper,an iForest algorithm based on genetic algorithm GA-iForest is designed on the basis of the iForest algorithm.The method uses genetic algorithm to select the high-performance iTrees to construct the iForest and optimize the construction of the iForest.The optimized iForest does not have similar,duplicate and low detection accuracy iTrees,which saves memory space and improves the detection accuracy compared with the original iForest algorithm.However,GA-iForest needs a more stage of selection when constructing the iForest,which will lead to an increase in the training time.In the future work,how to improve the training process of the proposed method will be studied.
杂志排行

Transactions of Nanjing University of Aeronautics and Astronautics的其它文章
- BeiDou B1I/B3I Signals Joint Tracking Algorithm Based on Kalman Filter
- Impact Analysis of Solar Irradiance Change on Precision Orbit Determination of Navigation Satellites
- Characterization of Self-driven Cascode-Configuration Synchronous Rectifiers
- Cooperative Search of UAV Swarm Based on Ant Colony Optimization with Artificial Potential Field
- H∞Preview Control for Automatic Carrier Landing
- Single-Phase to Three-Phase Inverter with Small DC-Link Capacitor for Motor Drive System