SegGraph:室外场景三维点云闭环检测算法
2019-02-20廖瑞杰杨绍发孟文霞董春梅
廖瑞杰 杨绍发 孟文霞, 董春梅
1(计算机科学国家重点实验室(中国科学院软件研究所) 北京 100190)2(中国科学院大学 北京 100190)3 (中国科学院软件研究所 北京 100190)
随着机器人技术的快速发展,移动机器人正在逐步走向完全自主化,而同时定位与地图创建(sim-ultaneous localization and mapping, SLAM)是机器人能否真正实现完全自主化的关键技术之一[1].SLAM是指机器人在未知环境中从某个未知位置开始移动,根据运动传感器(如里程计等)获得的信息及环境传感器(如相机、激光雷达等)获得的场景信息,在移动过程中同时自主近似计算出当前位置、姿态、运动轨迹并渐进地构建环境地图.每一步的近似计算和渐进建图都因运动传感器的信息偏差而产生误差,误差会不断累积.闭环检测(loop-closure detection)[2]是避免误差过多累积的关键模块.闭环检测的任务是根据环境传感器信息判断当前机器人位置是否与之前某时刻位置邻近,以抵消运动传感器的累积误差.机器人在差距较大的不同时刻所经过的2个距离较近的不同位置合称为1个闭环.闭环检测的准确度和效率对SLAM均很关键.如实际闭环被正确检出,则可大幅减少相应2个时刻位姿等信息估计的误差,并进而校正全局相关时刻位姿和地图信息的误差.如对在实际相距较远位置所得的2组点云误判为闭环,则可能导致全局位姿和地图信息的近似计算出现较大偏差,甚至导致约束信息不一致而不可解.SLAM的未来发展趋势是应能支持机器人在大范围场景长时间自主移动[3].在这些应用场景中,闭环检测尤其关键,难度也更大.
闭环检测研究依应用场景大致可分为室内场景和室外场景2类,依所用环境传感器可大致分为基于视觉传感器(如双目相机)所得图像数据和基于三维激光雷达所得点云数据两大类.本文专注于基于三维激光雷达的室外场景闭环检测.深度相机能同时获得关联的图像及点云数据,但其只适用于室内场景,而且其所得点云深度信息精度远小于激光雷达.在室外场景中,由于视觉传感器所得图像对光照、天气等的影响甚为敏感,而三维激光雷达通过激光对环境进行高分辨率扫描获得环境中各点在雷达坐标系中的位置信息,其所得信息不受光照、天气等影响,而且精度远高于从视觉传感器图像所估计出来的位置几何信息.故室外场景闭环检测当前研究更倾向于基于三维激光雷达所得点云数据.
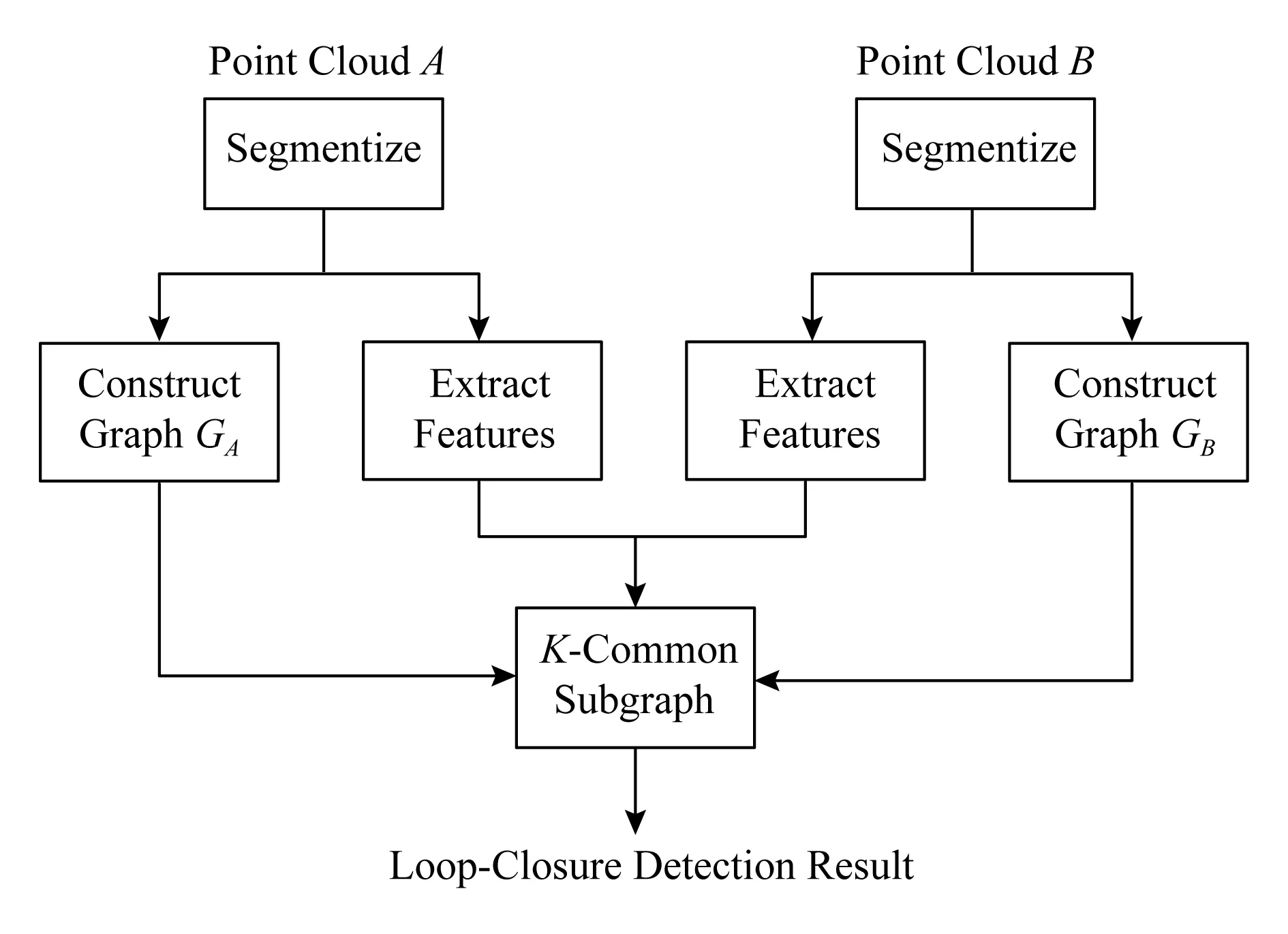
Fig. 1 Flow of algorithm SegGraph图1 SegGraph算法流程
基于三维激光雷达所得点云的闭环检测本质是将2组点云进行比较,以判断它们是否有较高相似度.在SLAM过程中,将当前时刻所得的1组点云分别与过去某时间段内选取的若干组点云一一进行闭环检测,将判断为闭环的2组点云认为是在相邻近位置所得,并将由此2组点云邻近而产生的全局约束融入到全局的定位与建图计算中.本文提出适用于室外场景基于三维激光雷达所得点云数据的新的闭环检测算法,命名为SegGraph.对作为输入的2组点云A和B,SegGraph的流程如图1所示,主要分为点云分割、点云簇图构建、点云簇特征提取、K-公共子图检测四大模块.
1) SegGraph对点云A和B分别分割成多个点云簇,分割前先对点云作预处理移除大地平面.大地平面通常是场景中最大的平面及对点云相似度判定最没有参考价值的平面,并且该平面连接了大部分的小平面如建筑物的外墙、汽车表面等,移除大地平面能避免其对点云分割准确度的影响.
2) 以A中点云簇为顶点、以点云簇图心间距离为边权值构建完全的带权无向图GA,使用同样的方法对B构建完全图GB.
3) 判断GA和GB是否存在有K个顶点的公共子图,其中K是设定的参数.在匹配GA和GB的子图时,我们以边权值(即点云簇图心间距离)为主要匹配依据.这是因为点云数据中的噪声及点云分割方法的不完美会导致从邻近地点得到的2组点云被分割成差别很大的点云簇集,尤其是同一物体表面可能会表现为面积差别很大的点云簇.然而点云簇图心间距离则相对稳定,这在第3节中有详细例子说明.另一方面,为提高子图匹配效率,我们分别对GA和GB中点云簇提取其具有代表性的局部特征,以用于对匹配过程进行剪枝操作和优化,这些特征包括图心、法向量等.
K-公共子图的判定是很著名的NP-hard问题[4].我们提出了一个近似算法,基本思路如下:在初始化阶段,分别从GA和GB中选取匹配的边,并组成匹配的2-公共子图.假如选择不唯一,则从符合要求的边对中随机选取.在递归阶段,假设当前已找到GA的-子图HA和GB的-子图HB,使得HA与HB匹配,其中 本文主要贡献有3个方面: 1) 提出以边匹配为主要依据的基于K-公共子图判定的室外场景三维点云闭环检测算法SegGraph,提出解决其中核心问题——K-公共子图判定的近似算法. 2) 基于C++语言和开源的第三方点云库(point cloud library, PCL)①http:pointclouds.org实现完整的SegGraph算法,代码在GitHub上发布②https:github.comJarilySegGraph. 3) 以广被采用的KITTI(Karlsruhe Institute of Technology and Toyota Technological Institute)城市街景数据集③http:www.cvlibs.netdatasetskittieval_odometry.php评估SegGraph,实验结果显示SegGraph有良好的准确度和运行效率. 基于激光雷达所得三维点云的室外场景闭环检测是近年来的研究热点,仍为一大挑战.主要有3个难点:1)单组点云含点个数数量庞大(如KITTI数据集中单组点云约含12万个点),点在空间分布不均匀,疏密不一;2)点云中各点数据噪声很大,这是目前激光雷达测量技术的不完美所致;3)激光雷达只能测量不被阻挡的物体表面的点的空间位置,对被阻挡的表面无法取得数据,这就可能导致在相邻很近但视角不同而得的2组点云可能差别很大.闭环检测的本质是判别2组点云是否有较高的相似度,从已有研究工作看主要有2类方法. 第1类方法是2组点云点对点的直接匹配.在这类方法中最著名并被广泛采用的是最近邻迭代算法(iterative closest point, ICP)[5]和它的改进算法[6].假设从里程计信息或其他方式已取得2组点云的大致几何转换对应关系,ICP算法利用迭代一步步近似计算出误差越来越小的2组点云的几何转换对应关系.ICP算法的局限性是需要已有大致精确的几何转换对应关系.点对点直接匹配方法还有适用范围更广并且不需要先验信息的4点(4-points congruent sets, 4PCS)算法[7]和它们的改进算法,如超级4点(super-4PCS)算法[8]等.因单组点云含点个数庞大,点对点直接匹配计算效率并不高.另外,此方法对个别点测量误差较为敏感,容易因局部部分点误差而导致全局匹配的大偏差. 第2类方法是基于描述子的点云匹配.首先为2组点云各计算出1个较简约的描述子,然后通过比较描述子来衡量2组点云的相似度.与点对点直接匹配方法相比,基于描述子的方法计算量相对较小,受局部点测量误差影响也相对较小.描述子的计算方法主要基于3个方面:1)基于场景点云的局部特征;2)基于场景点云的全局特征;3)基于对场景点云进行分割所得的平面集或者物体集. 基于点云局部特征的描述子算法大多是从点云中选取关键点并从这些关键点抽取局部特征形成特征向量.Bosse和Zlot[9]通过构建1个投票矩阵计算每点经其最近的若干个邻近点投票所得权值,再基于这些权值选取关键点建立描述子,称为三维Gestalt描述子.Gawel和Cieslewski[10]也用了类似的方法.Zhuang和Jiang[11]则将点云的局部点集转换成方位图像,并从这些图像中计算出SURF(speed up robust features)描述子.Rusu等人[12]采用较经典的快速点特征直方图(fast point feature histograms, FPFH)构建描述子.受FPFH描述子构建方法的启发,又产生了视点特征直方图(viewpoint feature histogram, VFH)[13]描述子和CVFH(clustered viewpoint feature histogram)[14]描述子等. 基于全局特征的描述子计算主要是提取点云的若干全局特征并加以组合构成全局描述子.Rohling等人[15]首先将点云中的点按高度值分成若干层,然后为每层计算出一维的直方图,最后将这些直方图组合起来构成全局描述子.2组点云的全局描述子以它们之间的Wasserstein距离来衡量相似度.Granström等人[16]提取出点云中具有旋转不变性的全局特征并将其组合构成全局描述子,这些具有旋转不变性的特征包括体积、法向量、距离直方图等.描述子的匹配用机器学习中用于分类的AdaBoost算法来完成,项皓东[17]继续了该方法的研究,在一些细节方面做出了相关改进,同样是把机器学习中的相关算法和传统方法相结合.Magnusson等人[18]首先将点云按三维网格划分为多个子集,然后计算每个子集中局部点云的形状属性(如球形、线状或平面等),最后将每个子集的形状属性描述组合构成点云的全局描述子.He等人[19]首先计算点云在多个预先选定的二维平面上的投影并对每个投影构建1个向量,然后将从各投影所得向量组合成1个全局矩阵,最后以对全局矩阵进行奇异值分解所得的左、右奇异向量构成全局描述子.各投影向量描述的计算方法是将平面分成许多小块并计算各小块里面所包含的点的个数. 基于点云分割所得平面和物体构建描述子是近年来较新的思路,其能兼顾到点云中的局部特征和全局特征.Fernandez-Moral 等人[20]研究基于RGB深度相机所得点云数据的室内场景闭环检测,其方法首先从2组点云中分别检测出属于某个平面的若干点子集,再对2组点云的平面进行匹配,寻找相匹配的构成场景某一局部的2组平面子集.该方法只适用于有较多含平面表面物体的室内场景,并依赖RGB图像选取场景某一局部,并不适用于室外场景激光雷达所得三维点云的闭环检测. 我们的方法SegGraph受SegMatch及其改进方法的启发,并克服了这2个方法的不足.SegMatch在将2组点云所得的点云簇集进行匹配时,忽略了点云簇间距离的信息,故对闭环检测准确率影响很大.而改进它的方法中,2组点云的点云簇要首先进行匹配,但在真实的室外场景中,受限于点云分割算法的辨识能力及点云数据中的噪声干扰,从相邻很近地点所得的点云簇很难形成一对一的匹配. SegGraph首先采用受噪声点干扰程度更小的区域增长分割算法将2组点云A和B各分割成多个点云簇,该方法分割出来的每个点云簇近似于1个光滑的表面,并保留了点云中的关键局部特征.假定A和B具有较高的相似度,即使A和B中有很多点云簇难以形成一对一的匹配对,但点云簇间距离是较为稳定的信息,因此,我们以A和B中的点云簇为顶点构建1个带边权值的完全图GA和GB,其中边的权值是点云簇图心间的距离.然后我们再以边匹配为主,检测GA和GB是否含1个足够大的(带权)公共子图.在公共子图检测中,我们将点云簇在分割中较稳定的局部特征如图心、法向量等作为辅助判定依据,以提高公共子图的检测效率.在第4节中的实验结果显示了SegGraph能够取得良好的准确度和运行效率. 本节将详细介绍 SegGraph算法的第1步——点云分割,即将2组输入点云分别经移除大地平面后分割成多个点云簇.为了提高SegGraph中K-公共子图判定的效率,我们还将从每个点云簇中提取其具有代表性的局部特征,包括图心、法向量、点云数量等. Fig. 2 Visualization of before and after ground plane removal for point cloud 2, sequence 06 KITTI图2 KITTI 06 序列的第 2 组点云移除大地平面前后的可视化 SegGraph专注于处理室外场景的点云数据,大多数此类场景如城市街景等均有1个较显著的大地平面.通常大地平面是场景中面积最大的平面,也是对场景相似度比较最没有参考价值的平面.故先将大地平面移除可以大大减少场景相似度比较的计算量. SegGraph采用一致性分割算法(SAC segmen-tation)[24]来移除点云中的大地平面.一致性分割算法的功能是从点云中提取与指定目标模型相对应的点云子集,如平面、球体、圆柱等.SegGraph用该算法提取出点云中最大的1个平面,认为其是大地平面,并将其移除.图2显示了KITTI数据集 06序列第2组三维点云数据的可视化图像和将该组点云移除大地平面后的可视化图像. SegGraph采用区域增长算法[25]对移除大地平面后的点云数据进行分割.其算法包含3个步骤: 1) 计算曲率.对点云中每个点p,以与p在1个很小的指定范围内的邻近点子集信息计算p的曲率. 2) 选取初始种子点集.以点云中曲率小于指定阈值的点构成初始种子点集. 3) 区域增长.从种子点集中取出1个点p,将以p为基础点构建1个可以近似认为是平滑表面的点云簇,该点云簇包含与p距离在一定范围内且与p的法向量夹角小于指定阈值的所有点. 点云数据经移除大地平面和分割后,将形成1个点云簇集,每个点云簇可以近似地视为场景中某个平滑表面的一部分.图3显示了从KITTI数据集06序列第2组点云所得点云簇集合的可视化图像,其中,同一个点云簇内的点以相同颜色显示,相邻的点云簇用不同的颜色显示. Fig.3 Visualization of point clusters resulting from segmentizing point cloud 2, sequence 06, KITTI图3 KITTI 06序列第2组点云分割所得点云簇集的可视化 为提高SegGraph后续K-公共子图检测的效率,我们对点云分割所得点云簇提取关键的局部特征.对每个点云簇,我们计算出图心、法向量、曲率、点的个数等信息.这些信息将辅助SegGraph后续K-公共子图检测进一步优化. SegGraph的第2步是就2组点云A和B分割所得的点云簇构建带权值的完全图GA和GB,并以检测GA和GB是否含有K-公共子图来判定A和B的相似度.从点云簇提取的特征将作为辅助匹配信息以提高K-公共子图检测的效率.本节将详述SegGraph中建图与K-公共子图检测算法. 我们将判定2组点云A和B是否相似转化为检测GA和GB是否含有K-公共子图,其中K是预先设定的整数.我们称GA和GB含有K-公共子图当且仅当存在UA⊆VA,UB⊆VB,|UA|=K=|UB|,而且以UA为顶点集的子图HA与以UB为顶点集的子图HB能相匹配,其中HA和HB为完全图.更确切地说,存在从UA到UB的一一对应的映射f,满足: 2) 对UA中任意顶点uA,uA所代表的点云簇的图心、法向量等特征与f(uA)所代表的点云簇的相应特征的差值在指定阈值内. 第1节提到的SegMatch及其改进方法均基于上述的假设,即依据点云簇的形状、面积及其他局部特征能使2组点云A和B分割所得的大多数点云簇能够形成唯一匹配,即A中大多数点云簇vA能在VB中找到唯一1个vB,使得vA与vB的形状、面积及其他局部特征匹配.而这个假设在实际场景所得点云数据的分割中是很难满足的.主要原因有3点: 1) 激光雷达测量的误差会使三维点云数据含有一定的噪声,并且激光雷达所获取的点云中点的分布并不均匀,且疏密不一. 2) 激光雷达只能扫描未被阻挡的物体表面,视点与视角的轻微变化及场景中瞬间出现的动态物体如车辆等均会使点云数据产生较大的偏差. 3) 点云分割算法有局限,无论是SegMatch中采用的欧基里德分割算法,还是本文采用的区域增长分割算法,均不能完美地使分割出来的点云簇与场景中的实际物体表面一一对应,其他点云分割算法也无法避免此问题. 因而,我们将点云簇间距离作为点云相似度比较的主要依据.图4展示了KITTI数据集06序列第2组点云和第836组点云在分割后所得点云簇集的可视化图像. 在图4的2组点云局部图中,同个点云簇内的点以相同颜色显示,邻近的点云簇之间用不同的颜色显示,根据KITTI提供的位姿信息,这2组点云获取地点(即三维激光雷达所处位置)相差仅为0.265 m,可以将2组点云近似看作是对同一个场景的扫描,图4中X与Y为同一个位置分割出来的2个点云簇,但其面积差别很大,X′与Y′也是类似的情况,但X图心与X′图心间距XX′和Y图心与Y′图心间距YY′相差却不大,可作为2组点云相似度比较的主要依据.另一方面,X与Y,X′与Y′的图心、法向量等信息基本一致,可以作为辅助信息提高点云相似度比较的效率. K-公共子图检测是NP-hard问题.我们提出一种穷尽搜索算法来求解. 算法1.K-公共子图穷尽搜索算法. 输入:完全图GA,GB,整数K,以VA,VB分别记GA,GB的顶点集,以w(v,v′)记GA或GB中边(v,v′)的权值; 输出:布尔值,即GA,GB是否含K-公共子图. ①w(eA)与w(eB)相差小于指定阈值; 2) 初始化.令UA,UB为空集,=0,fAB为空映射.在K-公共子图搜索过程中,UA是GA顶点集的子集,UB是GB顶点集的子集,fAB是从UA到UB的一一映射.UA,UB,fAB联合代表已构建的含个顶点的公共子图,其中|UA|==|UB|,≤K. 3) 公共子图搜索.调用算法2搜索公共子图,DetectSubGraph(GA,GB,K,UA,UB,fAB,). 算法2.DetectSubGraph公共子图搜索算法. 输入:GA,GB,K,UA,UB,fAB,,其中GA,GB,K同算法1中,UA,UB,fAB联合构成GA,GB的有个顶点的公共子图,且≤K; 输出:布尔值,即UA,UB,fAB是否能扩展为GA,GB的K-公共子图. 2) 枚举所有满足下列条件的顶点对(vA,vB),记为CVP(candidate vertex pairs). ①vA是GA中在UA外的顶点,vB是GB中在UB外的顶点. 3) 依次对CVP的顶点对(vA,vB)执行下列操作. ① 递归调用DetectSubGraph(GA,GB,K,UA∪{vA}UB∪{vB},fAB∪{(vA,vB)},+1). ② 如果返回值为真,则返回真并退出算法. 4) 若至此,则说明CVP中不存在顶点对能与UA,UB,fAB联合扩展为GA,GB的K-公共子图,故搜索失败,返回假并退出算法. 对实际移动机器人定位与建图应用,我们提出更高效的K-公共子图检测的随机搜索算法.随机搜索算法与穷尽搜索算法架构相同,只需将DetectSubGraph算法的步骤3)和步骤4)替换为下列步骤: 随机从CVP中选取1个顶点对(vA,vB),然后执行以下步骤. ① 递归调用DetectSubGraph(GA,GB,K,UA∪{vA}UB∪{vB},fAB∪{(vA,vB)},+1). ② 如果返回值为真,则返回真并退出算法;如果返回值为假,则返回假并退出算法. 很显然,穷尽搜索的最坏复杂度是指数级的,随机搜索的复杂度则是多项式级的.我们在KITTI数据集的实验表明基于K-公共子图随机搜索算法的闭环检测与基于K-公共子图穷尽搜索算法的闭环检测这两者的准确度差别不大,但是在时间耗损上,随机搜索算法具有巨大的优势. 本文所详述的完整的SegGraph算法均以C++实现(KITTI数据预处理部分利用了Python语言和KITTI官方提供的Python第三方库实现).我们采用开源的PCL库[26]来实现算法模块的部分功能和可视化操作等.程序运行在1个图形工作站上,其CPU为英特尔双核i7-2600,主频3.4 GHz,内存4 GB,操作系统64位Windows 7.我们选取KITTI三维点云数据集[27]中适合用于闭环检测算法评估的00,05,06,07序列数据进行实验.这4个序列的三维点云数据是以车载三维激光雷达在真实城市街道中扫描获得.KITTI官方提供由高精度GPSIMU导航系统测得的准确激光雷达位姿信息,以供闭环检测算法评估之用.这4个序列中各组点云的位姿信息用MatLab软件可视化所得轨迹如图5所示. 图5中轨迹上每个点代表1组点云(即1次扫描)的位置.激光雷达的运动是从黄色的点开始,由黄绿蓝渐变的方向移动,到达蓝色的点终止.KITTI的00,05,06,07序列分别含4 541,2 761,1 101,1 101组点云.每组点云由激光雷达在某个位置扫描而得,约有12万个点.我们以数据集提供的位姿信息作为评估闭环检测算法准确度的依据.每个序列的各组点云是依次在运行轨迹上的位置扫描所得,所以对扫描次序间隔不大的2组点云,其对机器人定位与建图依里程计信息估计的误差并不大,不需再从环境信息加以校正.因而我们在实验中只选取部分扫描次序间隔大于50的点云对作为闭环检测实验的样本,即对我们选取的每个点云对样本(A,B),A和B属于同一个序列,若A是第iA次扫描所得,B是第iB次扫描所得,则|iA-iB|>50. Fig. 5 Pose information of KITTI sequences 00,05,06,07图5 KITTI 00,05,06,07序列的位姿信息 对每个点云对样本(A,B),设A和B分别是激光雷达位于全局三维坐标系中位置pA和pB处获得,若pA,pB相距(欧基里德距离)小于3 m,则认为A,B构成闭环,称(A,B)为1个正样本;若pA,pB相距大于或等于3 m,则认为A,B不构成闭环,称(A,B)为1个负样本. 按上述实验设定,我们计算出KITTI 00序列共有7 403个正样本,由于负样本数量太多(由图5可知,激光雷达车重复经过的点占比很少),我们只从00序列中负样本中随机选取10 274个,即对00序列,共采用17 677个样本进行闭环检测算法评估.同理,对05,06,07序列,我们选择所有的正样本并随机选取部分负样本进行实验,具体来说,05序列共采用4 827个正样本和10 274个负样本,06序列1 577个正样本和10 794个负样本,07序列1 858个正样本和11 242个负样本. 我们依惯例[16]以检测率D(detection rate),丢失率MD(missed detection rate),误报率FA(false alarm rate)三个指标来衡量闭环检测的准确度.令P表示实验中正样本总数,N表示实验中负样本总数.用TP表示实验中被闭环检测算法判定为闭环而实际为闭环的样本数量,用FN表示被算法判定为非闭环而实际为闭环的样本数量,用FP表示被算法判定为闭环而实际为非闭环的样本数量,则3个指标的计算公式为 其中,D+MD=1. 好的闭环检测算法应做到使检测率很高,丢失率偏低,而误报率极低,这是因为在机器人即时定位与建图应用中,闭环通常是在机器人轨迹中成段连续出现的,见图5中黄色点和蓝色点的重叠部分.具体地说,如果存在第i组点云(由第i次扫描所得)与第j组点云形成闭环(i 每个序列参数K的设定是对该序列分别以K=7,8,9,10,11,12运行并综合选取准确度最优的对应K值,原则是误报率应极低而检测率较高.总的来说,单组点云分割后所建的图顶点数约为40,K的设定要适当.若K取得太小,则容易将许多稍有相似但实际上不是闭环的点云对误判为闭环;若K取得太大,则因点云数据噪声影响容易将许多实际为闭环的点云对误判为非闭环,并且导致K-公共子图判定的运行时间过大.表1列出了KITTI 06序列在K取不同值时的实验结果: Table 1 Accuracy of SegGraph on KITTI Sequence 06 forDifferent Values of K 从表1可以看出,当K=10时,SegGraph在KITTI 06序列上的误报率只有0.26%,而检测率仍高达94.23%,所以对这个序列我们将参数K设定为10.其他序列参数K的设定与06序列同理.我们最终的实验结果见表2: Table 2 Accuracy of SegGraph on KITTI Sequences00, 05, 06, 07 实验表明我们提出的SegGraph闭环检测算法在KITTI 4个序列中都取得了理想的检测率和较低的丢失率.在误报率方面,06序列的效果最为明显,仅为0.26%;00,05序列误报率都能控制在3%左右;07序列的误报率偏高,达到了8.74%,由图5的位姿信息可看出,07序列和其他序列最大的不同在于07序列中激光雷达车几乎没有重复走过同一段路线,即图5中颜色几乎没有重合的部分,所以导致了闭环信息较少,同时07序列中有2段相距很远但结构与外观都非常相似的街道,这就导致了算法将这些不是闭环的样本误判为闭环,该序列在其他闭环检测算法的实验中[19]效果也不理想. 我们还测量了SegGraph的运行时间,对单个点云对,SegGraph运行分两大部分:第1部分是点云分割和点云簇局部特征提取时间;第2部分是K-公共子图检测.由于正样本与负样本在第2部分所花时间差距甚大,我们对正负样本在第2部分所花时间分开测量.表3给出了KITTI 06序列的运行时间统计(单位为s),其中tmin和tmax分别表示单个点云对的最小耗时和最大耗时,tavg表示所有点云对的平均耗时.其他序列的运行时间与06序列类似. Table 3 Running Time of SegGraph on KITTI Sequence 06表3 SegGraph在KITTI 06序列上的运行时间 s 从表3可以看出,SegGraph第2部分时间中,正样本的检测时间大约是负样本检测时间的4倍,这是由于在正样本中,边匹配成功的较多,相应迭代的次数就更多,所以花费的时间就更长.从总体时间上看,第1部分占据了大部分时间,这是因为在该过程中,使用了区域增长算法来进行点云分割,该算法需要求出点云中每个点的曲率和法向量,这个步骤需要消耗大量的时间.相比于其他适用于城市街道的点云分割算法如欧基里德分割算法,虽然区域增长算法在时间上不占优势,但是欧基里德算法分割的结果为无规则状的点云簇,而我们所采用的区域增长分割算法分割出来的点云簇则非常接近光滑的平面,这使得K-公共子图检测中基于点云簇局部特征优化更加简洁和高效.同时,区域增长分割算法相对欧基里德分割算法来说更为精确且鲁棒性更好,前者基于曲率的变化增长,后者根据距离的远近聚类[22],假如存在一些雷达扫描不可避免的噪声点,很有可能本应属于2个点云簇的局部点云被欧基里德算法聚为了同一类,这是因为噪声点干扰了算法中对距离的判定.而区域增长分割算法受噪声点干扰的程度远没有欧基里德分割算法大. 区域增长分割算法中的主要耗时在于求点云中每个点的曲率和法向量.每个点的曲率和法向量只需从其邻近若干点的几何信息计算得出[25],因而对点云中各个点,其曲率及法向量的计算可以并行执行.如果将这部分计算在多核或GPU平台上实现,将能大大降低区域增长分割算法的运行时间.这将是我们下一步的工作. 本文提出适用于室外场景三维点云数据的闭环检测算法SegGraph.算法主要有3个步骤:1)对输入的2组点云分别移除大地平面后采用区域增长算法分割为点云簇集,并提取每个点云簇的局部特征;2)分别以点云簇集为顶点集,以点云簇间距离为边的权值,构建无向完全图;3)通过检测它们是否含K-公共子图来判定2组输入点云是否有较高的相似度,其中K是根据实际情况可以调整的参数.我们提出了检测K-公共子图的高效随机搜索近似算法.在公开数据集KITTI的4个序列上的实验表明SegGraph有良好的准确度和运行效率.1 相关研究工作

2 点云分割与点云簇局部特征提取
2.1 大地平面移除

2.2 点云分割

2.3 点云簇局部特征提取
3 K-公共子图检测
3.1 建 图
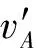
3.2 K-公共子图检测



3.3 K-公共子图检测近似算法
4 实验与结果



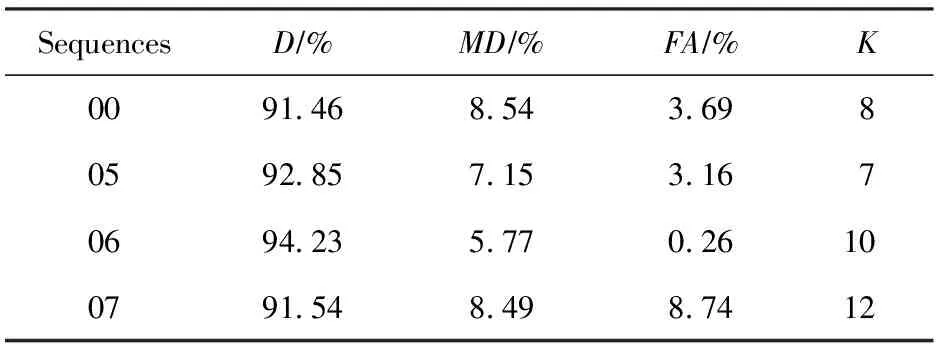

5 总 结
