基于信息融合的概率矩阵分解链路预测方法
2019-02-20王智强梁吉业
王智强 梁吉业, 李 茹,
1(山西大学计算机与信息技术学院 太原 030006)2 (计算智能与中文信息处理教育部重点实验室(山西大学) 太原 030006)
社交信息(social-information)网络[1](如微博,Twitter等),不仅包含用户间的网络结构,同时存在大量用户所分享的文本信息,具有规模大、动态变化、信息混杂等大数据通常所具有的特点,属于典型的网络大数据[2].图1为一个带有文本信息的Twitter数据集可视化示例,图1(a)中的网络代表用户间关注被关注(follwingfollowed)的有向网络,图1(b)分别对应网络中每个用户所分享的Tweet文本信息.

Fig. 1 A Twitter example of social-information network with text information图1 带有文本信息的社交信息网络Twitter示例
链路预测作为网络数据挖掘中一项基本挖掘任务[3],它在许多研究及应用领域发挥着重要作用.例如对于网络演化[4-5]、网络数据补齐[6-7]等问题的研究具有重要意义,同时在推荐[8-9]、生物信息[10]等领域发挥着重要应用价值.链路预测的研究目标[11-13]是预测当前网络中节点之间是否存在缺失的连边或是未来网络中是否会产生新的连边.本文将面向社交信息网络,针对其信息混杂特点,从信息融合角度研究社交信息网络中的链路预测问题.
目前针对链路预测的研究已有来自计算机、物理、生物等许多不同领域的研究者,针对不同的网络提出针对性的链路预测方法.现有链路预测方法通常从网络的拓扑结构出发,通过定义网络中节点间的拓扑度量或通过建立网络的统计学习模型来获得网络中节点间链路的可能性.已有基于度量的方法中,如基于邻居信息[14-16]、路径信息[17-18]、随机游走[19-20]等度量方法考虑了网络中节点间的拓扑相似度距离.基于学习的方法如层次网络模型[6]、随机块模型[21-22]、潜在特征模型[23-25]及矩阵分解模型[26-27]等从网络结构全局出发来学习节点间的链路可能性,相比基于度量的方法具有更好的适用范围.
尽管当前针对不同网络的链路预测方法研究已经取得了许多进展,但面向信息混杂的社交信息网络的链路预测研究仍然有待深入.用户所分享的文本信息作为众多形式信息中广泛存在的数据载体,如何充分利用用户所分享的文本信息来提高面向社交信网络的链路预测是一个挑战.社交信息网络中,信息的传播依赖于网络中节点间的关注被关注关系,1条Tweet会从其发布者传递到其跟随者(关注者),同时在Tweet的传播过程中也会影响到网络中链路关系的形成.如当用户对某条Tweet十分感兴趣时,该用户将有一定可能性成为此信息发布者的关注者.当然除此之外,社交信息网络中链路的变化与信息传播间相互影响的情况还有许多.从建模角度来讲,如何将拓扑的网络结构与非拓扑的文本信息进行融合建模是面向社交信息网络链路预测的关键.
本文试图从信息融合的角度,在抽取用户主题信息的基础上,构建用户间的主题相似网络,并提出融合用户间关注被关注网络与主题相似网络的概率矩阵分解模型;进一步基于模型学习到的用户潜在特征表示与用户间的链路参数计算用户间的链路可能性,实现面向社交信息网络的链路预测.
1 相关研究
目前针对网络中链路预测问题所提出的方法主要包括:基于度量的方法、基于分类的方法、基于概率图的方法及基于矩阵分解方法等.
1.1 基于度量的方法
通过定义网络节点间拓扑或非拓扑上的度量来对网络节点间的连边可能性进行打分是链路预测中最为常见的方法.拓扑度量是利用网络中节点对间的各种拓扑信息来定义,如基于邻居信息的度量有公共邻居(common neighbors, CN)[15]、Jaccard[28]、大度节点有利(hub promoted, HP)[29]、大度节点不利(hub depressed, HD)[13]、邻居贡献(adamic-adar, AA)[14]、偏好性(preferential attachment, PA)[16]以及资源分配(resource allocation, RA)[7]等.Katz[17],Local Path[18],FriendLink[30]等方法利用了网络中节点间路径信息;平均通勤时间(average commute time, ACT)[13]、余弦相似度时间(cosine similarity time, CST)[19]、重启随机游走(random walk with restart, RWR)[31]、SimRank[20]、局部随机游走(local random walk, LRW)[32]等则是基于网络随机游走过程来定义.社交网络中常见的非拓扑信息包括用户的简介、标签、文本信息、关键词等[25,33-35].Matthew等人[33]基于用户标签进行用户相似度度量.Prantik等人[35]基于关键词分析社交网络用户的相似度.已有基于拓扑或非拓扑信息度量的链路方法通常与具体网络的性质、领域等密切相关,单一度量方法往往容易领域受限.
1.2 基于分类的方法
基于分类的方法是将链路预测看作二分类问题,其中将网络中存在连边的节点对看作正例,没有连边的节点对看作负例.在建立分类模型时,许多分类器如支撑向量机(support vector machine, SVM)、逻辑斯蒂回归(logistic regression, LR)、k近邻(k-nearest neighbor,kNN)、朴素贝叶斯(Naive Bayesian, NB)等被用在链路预测问题中,而影响预测结果的关键因素之一是特征选择问题.Sa等人[36]利用节点对间的公共邻居、Jaccard、邻居贡献、偏好性及局部路径等来作为分类的特征;Lichtenwalter等人[37]提出了一种基于节点搭配的局部拓扑特征;Leskovec等人[38]利用节点的度和三元组特征来实现链路预测;Chiang等人[39]扩展了Leskovec等人[38]的工作,提出从更长的网络环路中来抽取拓扑特征.同1.1节中的度量方法类似,分类模型的特征选择同样容易受网络性质、领域等影响,且类的非平衡性问题也是制约基于分类模型进行链路预测的一个瓶颈.
1.3 基于概率图模型的方法
概率图模型是对网络数据进行建模的一类重要方法,它能够从网络全局出发揭示深层次的网络结构与性质.Clauset等人[6]提出一种层次网络模型,将网络建模为一种层次结构,其中叶子节点对应网络节点,中心节点对应不同叶子节点间的链路概率.随机块模型[21-22]假设网络节点可以被划分为不同的组,节点间的链路可能性由节点所在的组决定.潜在特征模型[23-24]是一种产生式模型,它假设网络中的节点可以用潜在特征向量来表示,网络中连边的产生式基于节点的潜在特征表示和连边产生的分布假设.已有网络概率图模型通常能够获得较好的链路预测效果,然而此类模型具有较高的计算复杂度,难以适用于较大规模的网络,且难以扩展到具有混杂信息的网络中.
1.4 基于矩阵分解的方法
矩阵分解方法是通过对网络的邻接矩阵进行低秩近似来解决链路预测问题.目前,矩阵分解方法如奇异值分解(singular value decomposition, SVD)[40]、非负矩阵分解(non-negative matrix factorization, NNMF)[41]及概率矩阵分解(probabilistic matrix factorization, PMF)[42]等已被广泛用于推荐系统.相比基于推荐方法,基于矩阵分解的网络链路预测方法研究仍有待深入.Menon等人[26]通过在矩阵分解时加入排序损失来克服链路预测中的非平衡问题,在链路预测准确率与效率2方面都获得了较好的结果.Zhai等人[27]提出一种结合矩阵分解和自编码的链路预测方法,获得了较好的链路预测效果.矩阵分解方法通常可以采用随机梯度下降等快速算法来实现,容易适用于大规模的网络数据[26].总体来讲,矩阵分解方法在解决网络链路预测问题时通常具有时间与效果两方面的综合优势,但目前仍缺乏面向带有混杂信息网络的矩阵分解链路预测方法.
本文试图从矩阵分解方法入手,通过结合社交信息网络中用户的文本内容信息,建立一种能够融合用户网络结构和文本信息的矩阵分解方法,在此基础上实现面向社交信息网络的链路预测.
2 融合的概率矩阵分解模型
社交信息网络既包含用户间的网络拓扑结构信息,同时还包括丰富的用户文本信息.本文基于概率矩阵分解模型来建模的目标是为了将2种信息融合在统一的概率分解框架下,以获得新空间下融合2种信息的用户表示,将此模型称为:融合概率矩阵分解模型(fusion probability matrix factorization, FPMF).以下分3小节来介绍FPMF模型.为便于理解,在此将文中涉及的主要符号汇总为表1:

Table 1 The List of the Main Notations表1 主要符号列表
2.1 用户主题相似网络构建
同质性[43-44]是社交网络中普遍存在的一种特性,它指社交网络中具有相似性的人之间容易产生链接,而存在链接的人之间也会因为相互影响而具有一定相似性.同质性说明社交网络中链路的产生与用户相似性之间具有一定相关性.本节试图从用户的主题相似度出发,利用社交信息网络中用户分享的文本信息抽取用户主题表示,并定义用户间的主题相似度,进一步基于主题相似度构建一种用户间的主题相似网络.
为获取用户主题信息,我们将每个用户历史所分享的所有微博信息看作一个文档,n个用户组成包含n个文档的文档集合D.基于潜在狄利克雷(latent Dirichlet allocation, LDA)主题模型[45],抽取每个用户的主题分布表示(见4.1节关于数据预处理的内容).
由于LDA模型所抽取的用户主题向量是一种多项分布表示,而KL(Kullback-Leibler)[46]散度适合于度量分布之间的距离,因此首先采用了KL散度来度量用户间的主题分布距离;然后基于指数函数exp(-x)将此距离映射到(0,1)之间作为相似度度量.考虑到KL度量是一种非对称的距离度量,对其进行了对称化处理.具体地,用户主题相似度定义如下:


(1)
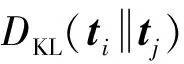
基于主题相似度(式(1)),定义用户之间的主题相似网络如下:
定义2. 用户主题相似网络.用四元组NS=(V,E,S,Sthr)表示用户主题相似度网络.V表示此网络的节点集合;E表示网络中边的集合;S表示该网络的邻接矩阵,其中矩阵S中每个元素的取值Si j代表用户i与用户j之间的主题相似度;Sthr表示构建主题相似网络的稀疏化参数,即当用户间的主题相似度值大于Sthr时,为其建立一条无向的边,反之不建立边,因此,Sthr的取值直接影响主题相似网络的稀疏性,Sthr越大网络越稀疏.
如图2所示,一个包含282个用户的Twitter数据集的主题相似网络构建过程.图2中从左至右分别表示用户的Tweets信息、主题向量以及用户间的主题相似网络,其中网络稀疏化参数Sthr=0.7.需要提及的是,对用户主题相似网络进行稀疏化,主要基于2方面考虑:一方面在利用用户大量的文本信息来计算用户间主题相似度时不可避免会有噪声,稀疏化设置使后续建模中只关注相似性较大的连边,缓解噪声影响;另一方面,网络稀疏化能够减小模型的计算复杂度.稀疏化参数Sthr的具体选取将在实验部分(4.4.3节)进行详细实验分析与讨论.
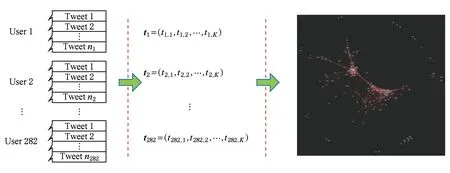
Fig. 2 The construction process of the users’ topic similarity-based network图2 用户主题相似网络构建
2.2 FPMF模型
从概率产生式角度,网络NA和NS的产生式过程可以用3个步骤来描述:
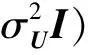

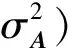
其对应的概率图如图3所示.

Fig. 3 The probabilistic graph model of FPMF图3 FPMF模型概率图表示
在网络产生式过程的第1步,网络中每个节点i的潜在向量Ui∈1×L从高斯先验分布N(0,中产生,网络中所有节点的潜在特征矩阵U的先验分布满足

(2)
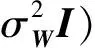
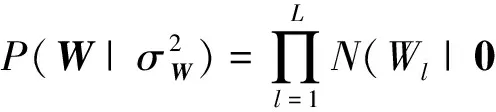
(3)
在生成网络节点的潜在特征表示矩阵U和网络NA的链路关系矩阵参数W的基础上,进一步产生网络NA和NS中的连边与非连边.见网络产生式过程的第3步:网络NA中任意节点对i,j间的连边Ai j=1或非连边Ai j=0是基于高斯分布N(gA(Ui,Uj),产生的,即
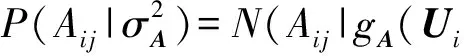
(4)
其中,gA(Ui,Uj)是为了度量网络NA中任意节点对i,j间链路关系而定义的关系函数:
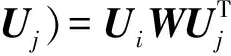
(5)
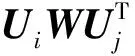
基于网络NA中每对节点连边与非连边的产生过程,其概率分布可以记为

在此统一的概率产生式框架下,主题相似网络NS中任意节点对i,j连边与不连边同样基于一个高斯分布N(gS(Ui,Uj),而产生,即
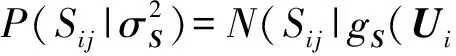
(7)
其中,gS(Ui,Uj)是度量主题相似网络NS中任意节点对i,j之间的链路关系度量函数,定义如下:
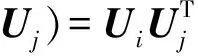
(8)

依据第3步中主题相似网络NS的产生过程,其概率分布表示为

基于网络NA和网络NS的整个产生过程,融合概率矩阵分解的目标就是通过极大化网络中节点的潜在特征表示U和链路参数矩阵W的后验分布,来估计极大后验下的U和W,即

(10)
由于网络NA和NS是已知可观察的,式(10)中的后验分布正比于如下联合概率分布:

(11)
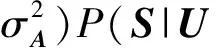
因此,式(10)等价于
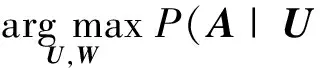
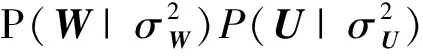
(13)
将式(2)(3)(6)(9)带入式(13),并取对数形式,可以推导出式(13)的优化目标等价于最小化如下目标函数:
,
(14)
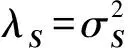
.
(15)
目标函数的局部最小值可以采用梯度下降方法进行求解[47],参数U和W的梯度下降公式为
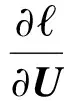
(16)
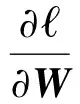
(17)
以包含有282个用户的社交信息网络Twitter为例(如图4),图4(a)为用户之间的关注被关注网络NA,图4(b)为构建的用户主题相似网络NS.模型的意义在于:通过共享同一个网络节点的潜在特征表示U,将网络NA邻接矩阵A的近似A≈UWUT和网络NS邻接矩阵S的近似S≈UUT融合在一个矩阵分解模型中.

Fig. 4 Sketch of the FPMF model图4 FPMF模型示意图
2.3 模型复杂度分析
由于矩阵A与矩阵S的稀疏性,A与U乘积的计算复杂度为O(ηAL),其中ηA为稀疏网络A中非0项个数;类似地,SU的乘积复杂度为O(ηSL),ηS为矩阵S中的非零项个数;剩余部分乘积的计算复杂度为O(nL2).因此,模型求解时每次迭代的总时间复杂度为O(ηAL+ηSL+nL2).由于网络的稀疏性,网络中边的个数几乎是网络节点数的倍数,则有ηA=O(n)与ηS=O(n),因此模型每次迭代的复杂度理论上与网络节点个数成近似的线性关系.
3 基于FPMF的链路预测
基于FPMF模型,能够学习到网络NA和网络NS中节点共同的潜在特征表示U以及网络NA中的链路参数矩阵W.依据模型中所描述的网络NA的产生式过程,对于任意节点对i,j间产生连边的概率可以计算如下:
P(i,j=1)=P(Ai j=1|Ui,Uj,W,
.
(18)
算法1. 基于FPMF模型的链路预测.
输入:关注网络邻接矩阵A、主题相似网络邻接矩阵S;
输出:链路预测的AUC(area under the receiver operating characteristic)值和Accuracy值.
① 初始化:网络节点的潜在特征矩阵UN×L,网络A的链路参数矩阵UL×L,L=integer≼n;
② REPEAT
UnewUold-γ,见式(16);
WnewWold-γ,见式(17);
③ UNTIL CONVERGENCE
END FOR
⑤ 基于P值对所有未知节点对进行排序;
⑥ 基于排序计算链路预测结果的AUC值和Accuracy值,见式(19)(20);
⑦ RETRUN:AUC和Accuracy.
4 实验及结果分析
4.1 实验数据
验证本文方法所需的数据集需同时包含用户间的网络结构和用户的文本信息,本文采用了两种社交信息网络数据集,Weibo和Twitter,均来源于唐杰团队在文献[48]中所共享的数据.由于原始数据集中有许多用户没有发表过或者很少发表微博Tweets,难以满足用户主题抽取需求,因此实验中仅抽取了网络中发表或转发微博Tweets数量超过100条的用户.最终在2个原始的数据集中分别抽取了4组子数据集:Weibo 1,Weibo 2,Twitter 1,Twitter 2,如表2所示:
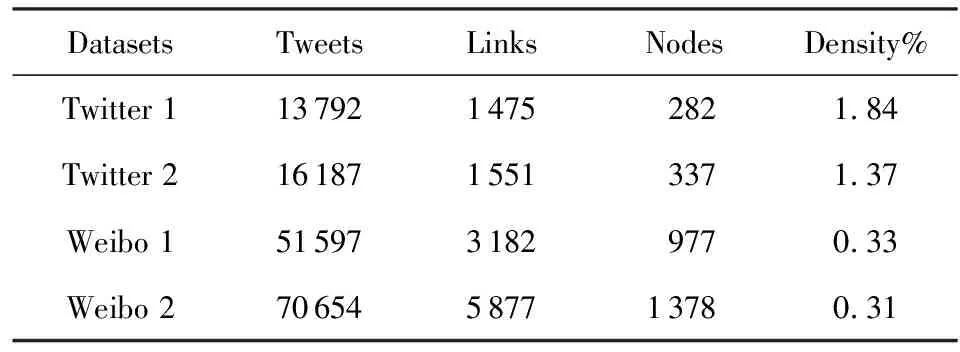
Table 2 Datasets表2 数据集
针对中文数据集Weibo 1和Weibo 2的微博文本预处理主要包括:首先去除掉其中的非文本字符,如数字、表情符号等;然后进行分词和停用词去除处理,并对用户发表或转发微博时经常会出现的“分享”、“转发”、“微博”等频繁词也进行去除处理.针对Twitter数据集,由于文献[48]中的原始数据集已对Tweets进行了预处理,本实验中不作进一步处理.
在数据集预处理基础上,为获得用户主题表示,我们将网络中每个用户所有发表或转发微博Tweets看作一个文档,然后采用Scikit-learn[49]工具包所提供的LDA主题抽取工具对网络用户的主题进行抽取,获得用户的分布式主题向量表示.
4.2 实验设置与评价指标
依据链路预测相关文献通常采用的实验设置[6,13,27],实验中将数据集中的网络划分为训练集和测试集.具体地,本实验将网络划分为90%∶10%,其中90%的部分作为训练集,10%作为测试集,且划分时分别执行独立随机划分5次,每次随机划分保证训练集网络的连通性.
结果评价时,采用了2种评价指标:一是链路预测中最为常用的AUC评价指标[13];另一种是链路预测结果的准确率指标Accuracy.
1)AUC指标
AUC是指ROC曲线(receiver operating char-acteristic curve)下方的面积.实际计算时可以采用抽样的方法来计算AUC值[13,50],即在测试集中随机选择一条边的分值比在不存在的边集合中随机选择一条边的分值高的概率.具体计算公式为
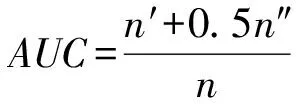
(19)
其中,n′表示随机从测试集与不存在边的集合中抽取n次出现n′次抽取的测试集边的分值大于没有边的分值,而n″是分值相等的次数.
2)Accuracy指标
Accuracy是指预测的准确率,其计算公式为:

(20)
其中,L表示测试集中共有L条边,k表示在排序前L个节点对中正确的个数.
4.3 比较方法
为验证本文方法在社交信息网络中链路预测的有效性,设置了2部分比较实验:一是本文方法与2种基线(baseline)方法作比较;二是本文与已有相关文献中常见的链路预测方法进行比较.
4.3.1 基线方法
基线方法的设定是为了验证本文融合模型将2种信息(网络和主题)在融合后相比融合前的优势.具体设定了2种基线方法:
1) 基本概率矩阵分解的方法
基本概率矩阵分解的方法是只针对网络结构进行概率矩阵分解,即只针对网络A进行概率矩阵分解,其形式化表示为:
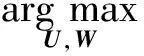
(21)
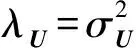
2) 基于主题相似度量的方法
基于主题相似度量的方法是利用用户的主题信息,通过度量用户间主题相似度的大小进行链路预测.用户间主题相似度的计算见式(1),此方法记为TS(topic similarity).
4.3.2 已有的链路预测方法
1) Katz
Katz是在已有文献[13]中被验证表现最好的方法之一.对于给定网络中的节点对i,j,Katz方法定义如下:

(22)
2) 公共邻居(CN)[13]
CN指标是链路预测中非常广泛使用的指标,它在许多网络也被验证通常具有良好的表现[13].由于社交信息网络中用户之间是关注与被关注的关系,用户之间具有不同类型的邻居,即关注者或被关注者.因此,在定义用户间CN指标时利用了不同类型的邻居,最终采用4种CN指标:CN1,CN2,CN3,CN4,如表3所示:

Table 3 CN Indexes表3 CN指标
表3中Γ+(i)表示社交信息网络中关注用户i的用户集合,Γ-(i)表示被用户i关注的用户集合,|Γ+(i)|和|Γ-(i)|分别代表集合Γ+(i)与Γ-(i)的用户数量.
3) 偏好性(PA)
偏好性指标PA也是在社交网络中常用的链路预测方法[13].给定网络中用户i与用户j的邻居数量,PA指标等于2个用户邻居数据的乘积.同CN类似,依据社交信息网络中不同类型的邻居,采用了4组不同的PA指标:PA1,PA2,PA3,PA4,如表4所示:

Table 4 PA Indexes表4 PA指标
4) 低秩近似(low-rank approximation, LAR)
低秩近似方法的目的是寻找一个低秩矩阵用来近似原始的矩阵.在链路预测中,低秩近似方法通过计算得到一个秩为k的最优低秩矩阵Ak用来近似原始的网络邻接矩阵A.进行链路预测时,将矩阵Ak中的第i行和第j列对应位置取值作为节点对i,j间链路的打分.文献[12]采用了奇异值分解SVD方法对原始网络矩阵进行低秩近似表示.本文实验中不仅采用了SVD方法,同时也采用了非负矩阵分解方法NNMF,将2种基于低秩近似表示的链路预测方法分别记为:LAR-SVD和LAR-NNMF.
4.4 实验结果及分析
实验中经过反复测试发现,参数分别进行设置时结果最优:
Twitter 1中,L=80,Sthr=0.9,λS=0.8,
Twitter 2中,L=40,Sthr=0.97,λS=0.6,
Weibo 1中,L=80,Sthr=0.9,λS=1.6,
Weibo 2中,L=60,Sthr=0.9,λS=0.6.
除上述参数外,模型中的正则化参数设置为λU=λW=0.05.以下实验中若非特别说明,上述参数均为最优结果时的参数.
4.4.1 基线方法比较
表5为本文方法FPMF与基线方法BPMF和TS在4组数据集中的比较结果.
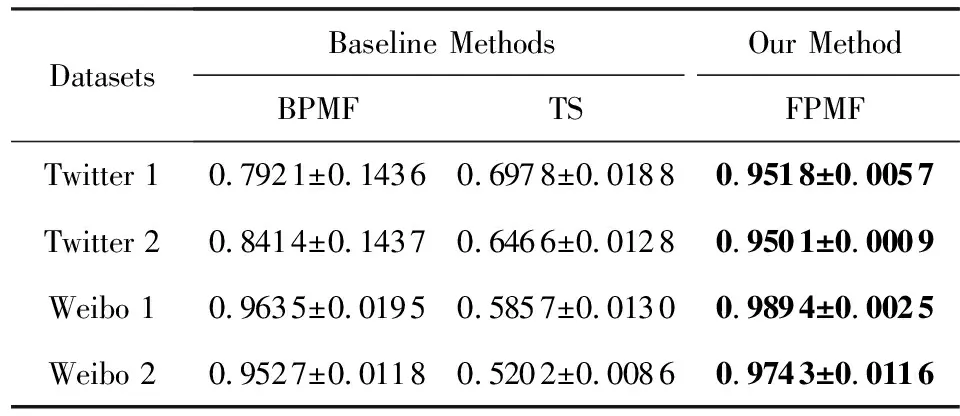
Table 5 Comparison of Baseline Methods表5 基线方法比较(AUC±std)
从表5中可以看出FPMF方法在4组数据集中比2个基线方法获得了更好的AUC结果.2种基线方法BPMF和TS分别是基于用户网络结构和主题相似信息进行链路预测,而FPMF是将2种信息融合在统一的概率产生式框架下进行链路预测.实验中融合后的方法能够优于融合前的2种方法,验证了本文融合概率矩阵分解的有效性.
4.4.2 与已有方法比较
图5与图6分别显示了本文方法与已有4类共11种常见链路预测方法比较的AUC和Accuracy结果.从图5,6中可看到,FPMF方法在4组数据集中大多数情况下获得了最好的Accuracy和AUC,并在不同的数据集中FPMF方法能够获得较为稳定的结果.比较方法中,基于公共邻居的4种方法(CN1,CN2,CN3,CN4)在2组Weibo数据集上的表现都要差于2组Twitter数据集,说明其预测能力的不稳定.在基于偏好指标的方法(PA1,PA2,PA3,PA4)中,PA1与PA2表现较好,且能够获得相比公共邻居更好的AUC结果,同时在2类数据集中保持了较好的稳定性,但就Accuracy结果而言明显低于本文FPMF方法.同偏好指标类似,基于Katz的方法能够获得相对不错的AUC结果,但Accuracy结果也明显低于本文方法.这说明在链路预测排序精度方面,本文FPMF方法能够获得更好的链路排序结果.

Fig. 5 Accuracy results of comparison methods图5 比较方法的Accuracy结果

Fig. 6 AUC results of comparison methods图6 比较方法的AUC结果
相比基于公共邻居、偏好性和Katz方法,基于低秩近似的方法(LAR-SVD,LAR-NNMF)在不同数据集中获得了更稳定的AUC和Accuracy结果,但这2种方法仍然低于本文FPMF方法.总的来说,本文方法既继承了低秩近似方法的稳定性,同时由于融合了社交信息网络中拓扑和非拓扑2方面信息,使得该方法与已有链路预测方法相比有明显提升.
4.4.3 稀疏参数Sthr分析
本文FPMF方法中,参数Sthr用来控制用户主题相似网络S的稀疏化程度,Sthr取值越大主题相似网络越稀疏.图7显示了稀疏化参数Sthr的不同取值在4组数据集中对链路预测结果和算法性能的影响.每个图中横轴代表稀疏化参数Sthr的取值(从0.1~0.99),2个纵轴分别代表模型算法迭代1 000次所花费的时间和链路预测的AUC结果.从图7(a)~(d)中时间曲线可以看出,随着稀疏化参数Sthr取值变大,模型算法迭代所花费的时间会明显减小.这说明用户主题相似网络越稀疏,算法运行所需时间越少.观察图7(a)~(d)中的AUC曲线,可以发现随着稀疏化参数Sthr取值增大,链路预测AUC的结果也在提高,而当稀疏化参数Sthr达到一定阈值时预测结果将会停止提高甚至减小.以上现象说明用户主题相似网络的稀疏化程度在一定程度影响最终链路预测的结果与性能,合理选择Sthr取值能够有效提升链路预测结果.分析其原因,我们认为当Sthr取值很大时,用户主题相似网络会十分稀疏,FPMF模型中只能考虑少量的用户对之间具有很高主题相似度的信息,而当Sthr取值很小时,模型中将会考虑大量用户对之间的主题相似度信息,从而增加噪声,一定程度影响链路预测结果.
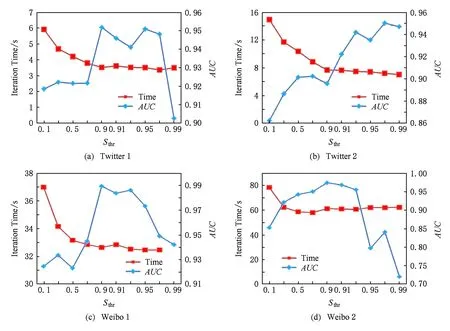
Fig. 7 Analysis of the sparse parameters图7 稀疏化参数分析
4.4.4 参数λS分析
λS参数是平衡FPMF模型中用户关注被关注网络和主题相似网络2种信息的.如果模型中λS=0,等同于只考虑用户间关注网络的信息(如基线中的BPMF方法);如果λS取无穷大,模型只考虑用户间主题相似网络的信息.
图8(a)~(d)显示了该模型在4组数据集中随着λS参数取值变化时AUC结果的变化.可以看到随着λS参数取值增大,AUC结果开始提升;当λS参数增加到一定阈值时,AUC结果会停止提升甚至开始下降.这说明在模型中应选择适中的λS参数来平衡用户关注被关注网络和用户主题相似网络2种信息.
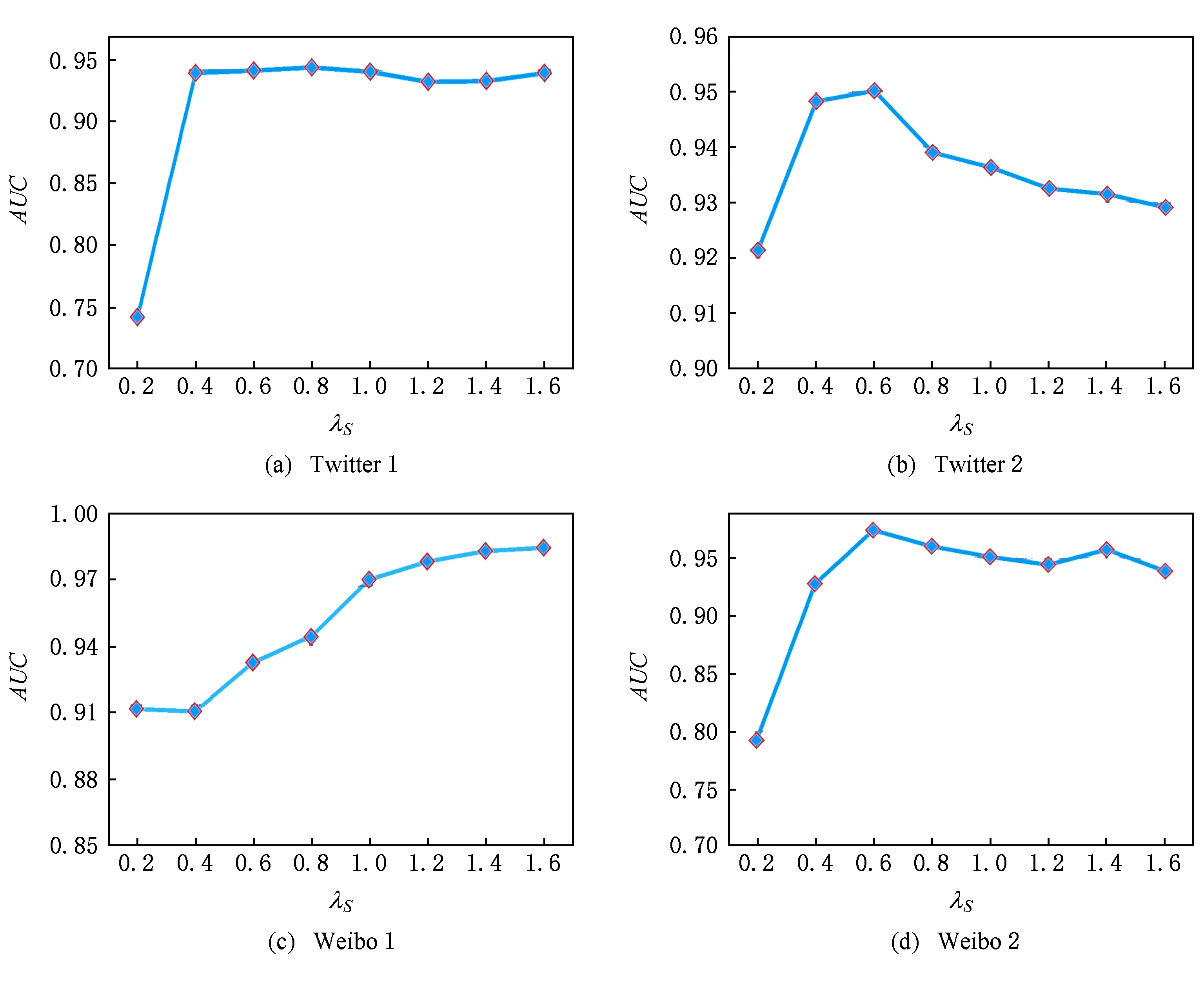
Fig. 8 Analysis of the weight parameters图8 权重参数分析
