基于逆强化学习的示教学习方法综述
2019-02-20张凯峰
张凯峰 俞 扬
(计算机软件新技术国家重点实验室(南京大学) 南京 210023)
强化学习(reinforcement learning, RL)[1]是机器学习的重要分支之一.在强化学习中,智能体(agent)通过不断与其所处环境(environment)自主交互从而进行学习并完成任务.在交互过程中,智能体将基于最大化累积反馈奖赏的目标对自身策略不断进行优化更新.该过程可以被认为是(正向)强化学习过程.与传统监督学习不同的是,强化学习天生具有一定的“自学”能力,可以自主地对环境进行探索学习.因此,强化学习能够被有效地应用到许多标记数据代价高昂的自主学习问题当中去,这包括:推荐系统、自动驾驶、智能机器人、Atari游戏等.在强化学习中,如图1所示,智能体通过观测所处环境的状态,在动作空间选取合适动作予以执行.环境将依据相应状态转换概率转换至新的状态,并给予智能体一定反馈奖赏.这个过程可以始终执行下去,也可以在智能体观测到终止状态后停止.
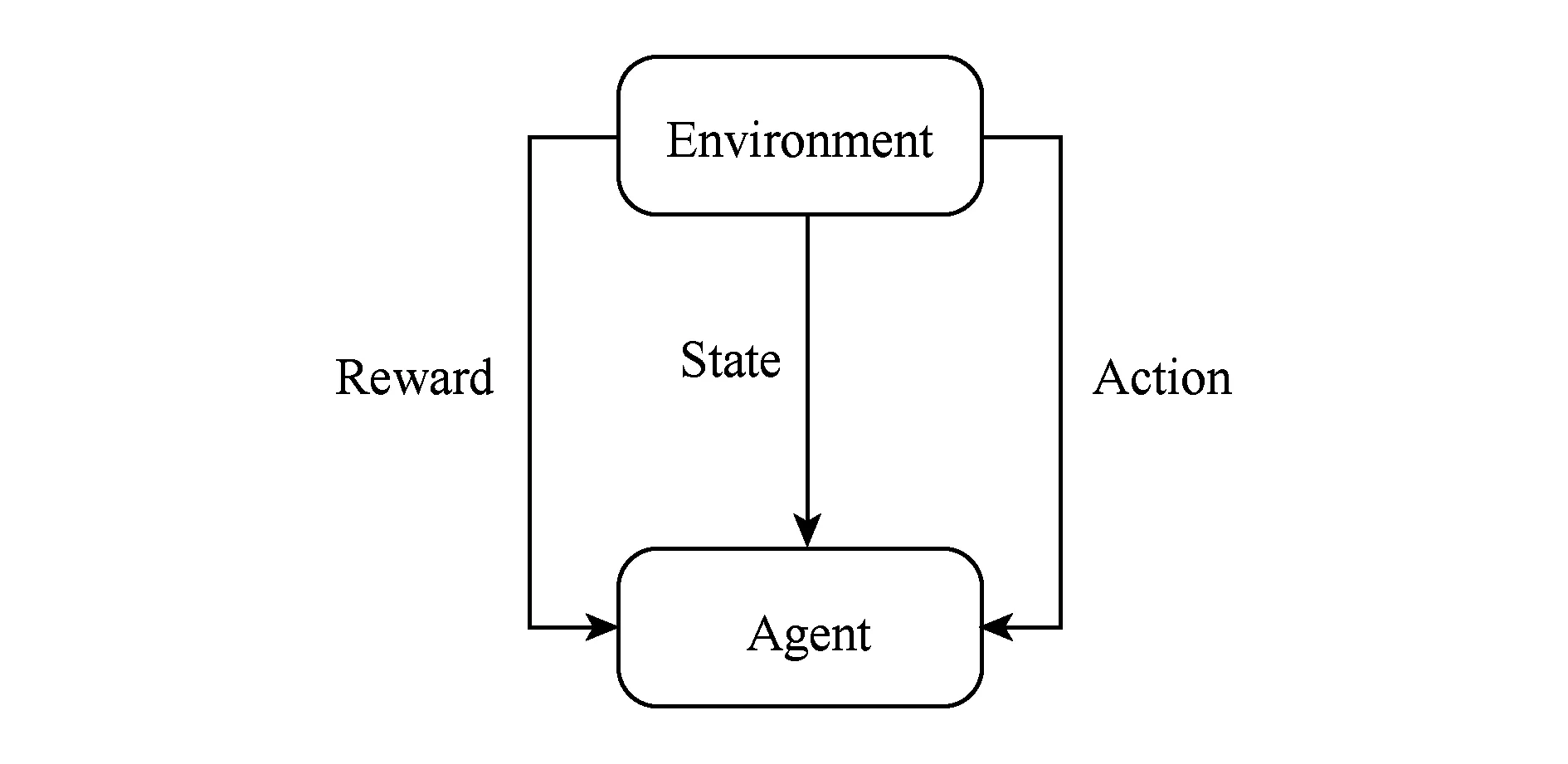
Fig. 1 Reinforcement learning procedure图1 强化学习过程
然而对于绝大多数决策问题而言,环境将难以给出准确的即时反馈信号或者环境给出的反馈信号将具有很高的延迟性.例如在自动驾驶问题中,对于行驶过程中的车辆,环境很难在车辆每执行一个动作后即时地给出反馈信号;而在围棋这一类游戏之中,在每一步的落子后环境也很难立即评价该步的好坏,而往往需要经过多步之后才能来判断之前一步的好坏,这也就是环境所给予的反馈信号延迟性较高的情况.在上述情况下,更为直接的方式是利用大量人类专家的决策数据进行学习从而得到智能体的策略.这样的学习方式被称为示教学习或模仿学习(imitation learning)[2].
示教学习的目标是模仿专家的决策轨迹进行决策,其中每条专家决策轨迹{ζ1,ζ2,…,ζm}包括了一系列的状态-动作对ζi=si1,ai1,si2,ai2,…,sin,ain.近年来,示教学习先后通过学习人类飞行员的飞行操作数据、道路导航数据以及自动系统控制数据等,在Stanford自动直升机[3-8]、导航[9-12]以及HVAC控制[13]等项目中取得了一系列成果.
根据模拟专家行为的不同实现过程,示教学习可以被划分为以下3种实现方式:
1) 行为克隆(behavioral cloning)[14-15].通过传统监督学习方法建立状态-动作之间的分类模型(针对离散动作空间)或回归模型(针对连续动作空间),从而实现决策,也即动作的预测.然而,由于该类方法在大规模状态空间下所得到的策略存在严重的复合误差(compounding errors)[16]并且难以有效学习到专家决策行为的动机.因此,该类方法需要设计人工标记数据的方法进行矫正,例如DAgger等[17],且仅适用于状态空间较小的情况.
2) 基于逆强化学习的示教学习方法.逆强化学习的目标是通过在马尔可夫决策过程上建立合适的优化模型,逆向求解得到决策问题的反馈函数.通过结合传统的正向强化学习方法设计的一系列示教学习方法,例如学徒学习(apprenticeship learning)[18]、代价指导学习(guided cost learning)[19]等,能够更好地解决大规模状态空间所带来的问题,因而在众多机器人项目中得到了广泛的应用.值得说明的是,部分研究工作也认为逆强化学习是示教学习方法的一种[20],这是由于该类方法在工作过程中通过不断的正向策略搜索进而优化算法所需要的反馈信号,因此整个系统(逆强化学习)可以被认为是一类示教学习方法.
3) 基于博弈的示教学习方法.经典的示教学习过程可以看作是智能体和所处环境进行博弈的过程.其中系统依据其混合策略Pt在动作空间选取动作,环境依据相应混合策略Qt选取状态,同时系统将观测到自身在执行决策之后所得到的损失值.相关的经典工作包括通过已有自适应博弈方法[21]来优化学徒学习的MWAL算法[22],以及生成式对抗性示教学习方法[20,23-24],通过生成器(generator)生成策略,由判别器(discriminator)判断其是否是来自专家决策数据抑或是生成器生成的策略数据,通过训练2个学习器,寻找最优策略.
1 基本概念
在强化学习中,马尔可夫决策过程[1]可以形式化为一个五元组S,A,T,R,γ表示.其中,S表示强化学习智能体所处环境的状态空间;A表示智能体可选取动作的动作空间;T表示状态转换概率模型;R表示环境在某个状态-动作对下所给予的反馈信号;γ表示反馈奖赏折扣系数.通常,强化学习所面对的任务的状态转换模型以及反馈量需要通过智能体不断地探索(exploration)从而获取相关信息.
智能体的目标是通过和环境的不断交互最大化自身策略的未来累计反馈奖赏值.其交互过程为:智能体在某个状态s0出发,根据策略在动作空间选取动作a1执行,此时环境将依据其状态转换模型转换到下一个状态,同时将给予智能体一个确定的反馈奖赏.该过程将不断进行直到终止状态.其中智能体的策略π是指状态空间到动作空间的映射.
1.1 值函数
与动态规划算法类似的是,我们可以为每个状态定义一个值函数(value function),这将为强化学习的实现带来很大方便.值函数根据其自变量的不同可以分为:状态值函数V(s)和状态-动作对值函数Q(s,a).其表述形式分别为
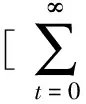
(1)
(2)
可以看出:状态值函数或者状态-动作对值函数分别是某个状态、状态-动作对下的累计未来反馈奖赏.因此只需要通过最大化值函数就可以最大化累计反馈奖赏,这使得强化学习策略求解更加方便.
基于最优策略,我们不难得到以下2个定理:
定理1. Bellman等式.假设马尔可夫决策过程为M=S,A,T,R,γ,智能体策略为π:S→A,对于任意状态s、动作a,其价值函数可以表示为

(3)

(4)
定理2. Bellman最优定理.假设马尔可夫决策过程为M=S,A,T,R,γ,智能体策略为π:S→A,则策略π是最优策略当且仅当对任意状态s:

(5)
1.2 策略搜索
经典的正向强化学习研究是智能体基于最大化累计未来反馈奖赏求解策略的过程.而求解策略可以通过求解值函数实现.
根据1.1节所述,求解值函数可以通过式(6)和式(7)展开进行:
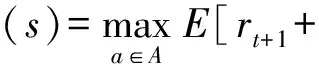
(6)

通过式(6)(7)求解值函数从而获得最优策略的方法可以理解为策略迭代过程,也即通过不断迭代以下2个交互过程:策略评估(policy evaluation)和策略改进(policy improvement),从而获取最优策略.其中,策略评估是指通过当前的策略评估值函数,而策略改进是指通过当前值函数优化得到新的策略.这个过程就是经典的正向强化学习过程.
2 逆强化学习
逆强化学习是通过大量专家决策数据在马尔可夫决策过程中逆向求解环境反馈信号函数的一类方法.其基本原则是寻找一个或多个反馈信号函数能够很好地描述专家决策行为.这也就是说,逆强化学习算法将基于专家决策最优的假设进行设计.
然而,由于在函数空间中可能存在多个函数能够同时满足专家策略最优的假设,例如每一步决策所带来的反馈始终为0的情况.因此,算法设计的模型应能够解决反馈信号的模糊性(ambiguity).目前,我们可以通过3类反馈信号函数的形式实现反馈信号求解过程,它们分别是:1)基于大间隔(max-margin)的反馈信号;2)基于确定基函数组合的反馈信号函数;3)基于参数化的反馈信号函数,例如神经网络.
2.1 基于确定基函数组合的反馈信号函数
逆强化学习发展初期,大多工作均建立在环境反馈信号函数为确定基函数组合的情况下.该类方法通过状态特征构建基函数,从而将求解反馈信号函数的任务转化为求解各个基函数权重的任务.其能够较好地克服反馈信号搜索过程中存在的函数歧义性的问题.
为了建立合适的优化模型求解相关决策问题的反馈信号,该类方法从专家决策轨迹最优的假设出发,通过以下2种方法建立相关模型:
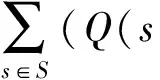
在上述优化目标的基础上,我们可以考虑逆强化学习问题的约束条件还应包括:a1为最优决策动作,根据定理2可以得知,该条件等价于a1动作在相应状态下的Q值将大于其余动作的Q值.此外,约束条件中还应保证立即反馈信号值始终是有限值.当考虑到对模型进行正则化时,我们可以得到Ng等人[25]提出的针对专家决策轨迹的优化模型,如式(8)所示:
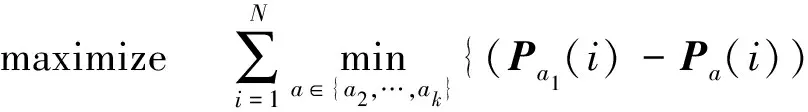

s.t. (Pa1(i)-Pa(i))(I-γ·Pa1)-1R≻0,(8)
Ri≤Rmax,i=1,2,…,N.
其中,Pa(i)表示状态转换概率矩阵.矩阵R表示反馈量矩阵.其中模型约束条件
(Pa1(i)-Pa(i))(I-γ·Pa1)-1R≻0,
表示左侧矩阵各项元素均大于0,以保证a1为最优决策.|Ri|≤Rmax亦表示矩阵中各项元素均小于某个有限值.当考虑到决策问题的反馈函数可以由一组确定的基函数线性拟合时,该优化模型可以很好地通过线性规划(linear programming)求解得到相应环境的反馈函数.
2) 根据强化学习基于动态规划算法最大化未来反馈量的经典研究我们可以得知:最优策略相对于其他策略而言将获得最大的未来奖赏,即:

将取得最大值.
当决策问题的反馈信号可以由一系列确定的基函数φ1,φ2,…,φk线性组合而成时,我们可以定义策略的特征期望[18]为
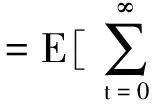
由此,我们可以得到对于任意策略特征期望μ,可以得到:
wTμE≥wTμ.
其中,μE表示专家决策数据所确定的专家策略特征期望,其值可以通过蒙特卡洛算法进行估算:
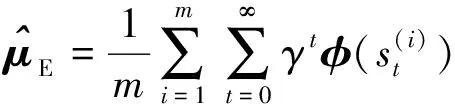
通过建立优化模型:

(9)

我们可以得到以下结论:当优化变量t不大于拟合误差ε时,算法将得到决策问题反馈信号优化变量w,也即得到未来总反馈函数R=wTμ.此时,由于t≤ε,也将得到相应策略,其未来奖赏值wTμ(i)≥wTμE-ε,也即结合不同正向强化学习策略搜索方法设计的示教学习方法得到的策略将不低于专家策略减去某小量的水平.
通过上述2种方式建立的逆强化学习优化模型可以帮助求解得到相关问题的反馈信号.该类方法通过比较专家策略和其他策略的价值,从而建立逆强化学习优化模型,能够较好地实现对专家决策轨迹的学习,并获取环境反馈信号函数.
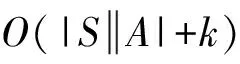
2.2 基于参数化模型的反馈信号函数
随着逆强化学习面对的决策问题复杂度的提升,研究人员开始关注于提升反馈信号函数的表达能力.其中较为有效的是通过参数化模型对环境反馈信号进行建模.
早期的致力于扩大决策问题反馈信号表达能力的工作包括:2010年Levine等人[27]提出的FIRL(feature construction for IRL)算法,其方法通过构建一组基于逻辑联结的合成特征,从而间接实现了非线性反馈信号的建模.2011年,Levine等人[28]又提出了GP-IRL,其方法采用了基于高斯过程[29]的反馈信号,通过高斯过程极大地增强了反馈函数的表示能力.2015年,Jin等人[30]又在GP-IRL算法基础上结合了深度信念网络,实现了深度高斯过程在逆强化学习上的应用(DGP-IRL).其中GP-IRL和DGP-IRL在众多开源环境测试,例如经典的Grid-world测试实验以及gym下的强化学习基准测试实验中都取得了”state-of-the-art”的效果.
随着深度学习的蓬勃发展,通过神经网络对反馈函数进行建模逐渐称为逆强化学习的一大主流方向.其中较为知名的是2008年,Ziebart等人[11]提出的最大熵逆强化学习方法(maximum entropy IRL),通过优化专家决策数据集的似然函数实现反馈信号的优化,很好地解决了专家决策数据中可能存在的噪声以及专家数据本身并不是最优的问题.
最大熵逆强化学习方法是经典的基于“能量”的模型(energy-based model)[31].其中能量函数ε为环境的代价函数(即反馈信号函数的相反数).根据“能量”模型的假设,可以知道专家在策略轨迹空间的采样概率密度为
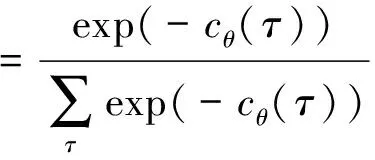
(10)
其中,τ为策略轨迹,分母为划分函数Z(partition function).式(10)可以简单地理解为:当2条决策轨迹具有相同的反馈奖赏时,其具有相同的概率别“专家”采样获得,而当某条轨迹具有更高的反馈奖赏时,“专家”将更有机会能够采样到这条轨迹.
为了让专家决策数据(训练数据)更能够被“专家”采样到,逆强化学习的优化目标是最大化专家轨迹的似然函数,可以表述为
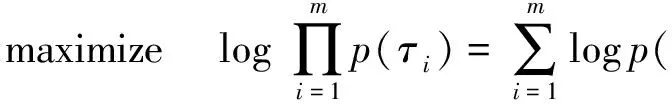
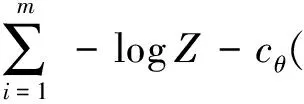
(11)
因此,通过随机梯度方法优化模型式(11)就可以求解得到环境的反馈信号函数.此处需要注意的是:当我们面对的是离散且规模较小的状态空间时,划分函数Z可以通过动态规划算法求得;而当我们面对大规模状态空间时,则需要通过采样等方法实现[19,32].
最大熵逆强化学习方法通过优化专家决策数据的似然函数从而获得环境反馈信号,该方法引入了一定的随机性,可以处理专家决策数据本身不是最优或含有一定噪声的情况.
类似能够处理专家决策数据本身不是最优的方法还包括一系列概率模型.其中包括:2007年,Ramachandran和Amir[33]提出贝叶斯非参数化方法去构建反馈函数特征来实现逆强化学习,该方法称作贝叶斯逆强化学习(Bayesian IRL).其后2013年,Choi等人[34]通过构建了一组合成特征上的先验概率优化了该算法.
2.3 其他函数表示形式
对于某些复杂决策问题,环境反馈信号难以通过单一的一个函数进行表示,也就是说是通过单一函数拟合过程中会出现决策数据和反馈函数严重不一致的情况.通过基于每条专家决策轨迹都能够被多个局部一致的反馈函数所生成的假设,Nguyen等人[35]提出了通过期望最大化(expectation-max-imization, EM)方法来学习不同的反馈信号以及它们之间动态的转换过程.通过该方法,可以实现针对专家决策轨迹的分割,使得各个部分(segments)均能对应合适的局部一致的反馈函数.基准数据测试(Grid-world以及gym等开源强化学习环境测试)表明该方法也取得了”state-of-the-art”的效果.
此外,逆强化学习领域仍有很多问题需要进行研究解决.例如,在考虑到部分可观察的环境(partially observable environments)[36]时,如何有效地将逆强化学习或示教学习方法迁移到这样的环境之中、如何设计实验来提高反馈函数的可识别性(identifiablity)等问题.
3 基于逆强化学习的示教学习方法
示教学习的目标是通过专家决策轨迹去模仿专家的决策行为.本文第2节介绍了逆强化学习的方法和所需解决的问题,逆强化学习是通过学习专家决策轨迹从而获得环境反馈信号的一类方法.本节将介绍通过结合逆强化学习、正向强化学习策略搜索算法所设计的示教学习方法,也即基于逆强化学习的示教学习方法.
目前,基于逆强化学习的示教学习主要的2个框架分别是:1)在经典的正向强化学习算法内循环中使用逆强化学习算法优化问题的反馈信号,基于反馈信号函数继续实现策略的优化,不断迭代实现示教学习过程.其核心在于将逆强化学习方法置于正向策略搜索方法的内循环之中,经典的方法包括学徒学习方法等.2)基于不断优化得到的反馈信号去实现正向强化学习过程,通过采样数据和专家数据相结合实现逆强化学习过程,同时将正向强化学习过程置于逆强化学习的内循环中,经典的方法有代价指导学习等.本节将主要介绍学徒学习方法和代价指导学习方法.
3.1 学徒学习
学徒学习方法是通过在马尔可夫决策过程中,模仿专家行为,最终得到不差于专家行为策略的方法.其核心的思想是通过匹配专家期望特征实现模仿学习过程.
在线性假设下,反馈信号可以由一组确定基函数φ1,φ2,…,φk进行线性组合.因此,策略的价值可以表示为
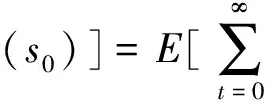


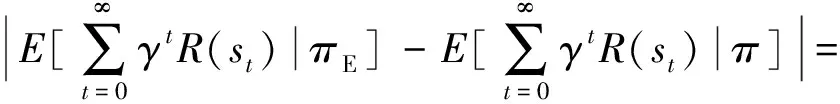
(13)
因此,我们可以得到以下结论:对于某个策略π,若其特征期望接近专家策略特征期望,则该策略是学徒学习的一个解.算法1描述了由Abbeel等人[18]提出的通过结合策略迭代和式(9)的逆强化学习算法所设计的学徒学习方式.
算法1. 学徒学习算法.
输入:专家决策行为数据;
输出:算法得到的策略以及相应的反馈函数.
① 随机初始化一个策略,计算其特征期望:
μ(0)=μ(π(0)),设置i=1;
② 计算:
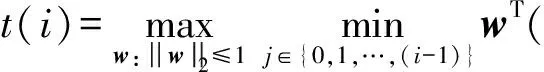
并且获得相应w值为w(i);
③ IFt(i)≤εTHEN
④ 算法终止;
End If
⑤ 使用强化学习算法,计算最优策略π(i)未来累计奖赏为R=(w(i))Tφ;
⑥ 计算策略特征期望μ(i)=μ(π(i));
⑦ 设置i=i+1,并返回步骤②.
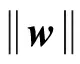
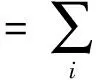

其中,λi可以看作是以λi的概率选择μ(i)策略.
为了将学徒学习方法应用到高性能机器人系统之中,Abbeel等人[37]通过将学徒学习和探索策略(exploration policies)方法结合解决动态未知的机器人环境.其后,该项工作也被应用到了著名的Stanford自动直升机之中.
3.2 代价指导学习
代价指导学习[19]是通过结合正向强化学习中的策略优化[38](policy optimization)方法和最大熵逆强化学习方法[11]实现的示教学习方法.
如图2所示,系统通过初始化策略在机器人或设备上进行轨迹采样,并将采样得到的轨迹和专家决策数据进行合并,共同用于实现逆强化学习过程,优化反馈信号函数.基于得到的反馈信号函数,在内循环中实现策略优化.不断迭代上述过程,最终实现示教学习过程.其实现过程如算法2所示.
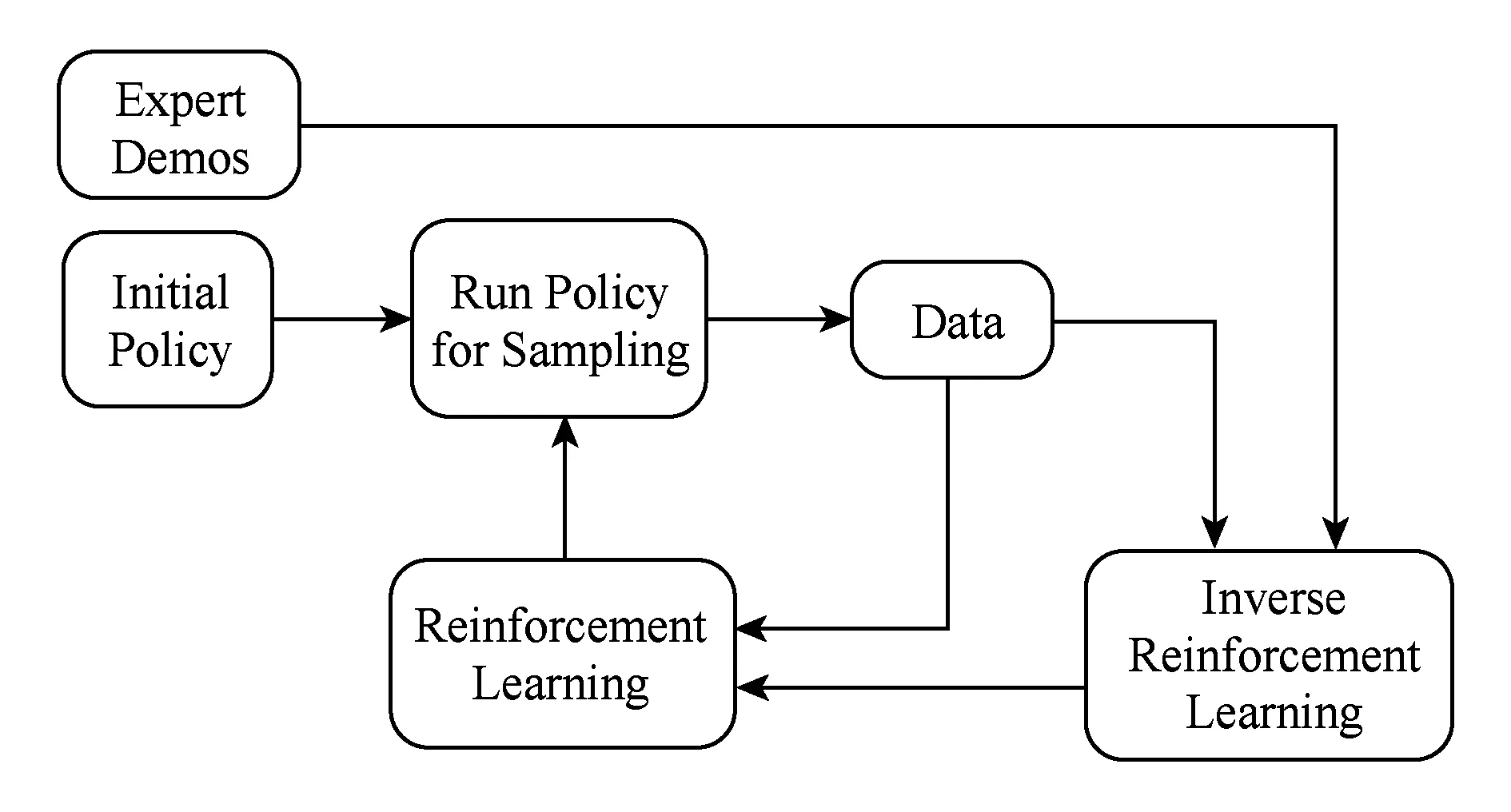
Fig. 2 Guided cost learning procedure图2 代价指导学习过程
算法2. 代价指导学习算法.
输入:专家决策行为数据;
输出:算法得到的策略以及相应的反馈函数.
① 随机初始化一个策略;
② FORi=1 toIDO
③ 通过目前策略采样生成采样数据集;
④ 扩展数据样本集:Dsamp=Dsamp∪Dtraj;
⑤ 通过Dsamp优化问题反馈信号函数;
⑥ 通过正向强化学习更新策略;
⑦ END FOR
⑧ 返回优化后的策略和相应反馈信号.
算法2步骤①实现随机初始化策略;步骤③通过当前策略进行采样;步骤④实现采样数据集和专家决策数据集的合并;步骤⑤实现逆强化学习过程(最大熵算法);步骤⑥实现策略优化;不断迭代步骤③~⑥,实现示教学习过程.
此外,由于强化学习系统采样的样本有限,一般可以通过将专家决策数据集合进行分组,通过多组数据循环优化反馈信号,实现逆强化学习过程.目前,代价指导学习算法在机器人多项智能操作,例如倒水、叠盘子等实验[19]中取得了”state-of-the-art”的效果.
通过上述介绍的学徒学习方法和代价指导学习方法两大类实现框架,我们能够将不同的逆强化学习和正向强化学习方法进行结合从而设计一系列示教学习算法.通过采用不同的逆强化学习方法,我们可以处理专家决策数据本身存在的各种问题,例如数据存在噪声、其决策过程本身并不是最优的以及反馈信号表示能力受到限制等.同样地,通过采用不同的正向强化学习方法,我们可以解决许多由环境所带来的问题,例如实现在高维连续系统中的示教学习应用等.
4 结束语
本文不仅介绍了建立逆强化学习优化模型的方法以及逆强化学习方法发展回顾,还介绍了如何通过结合逆强化学习、正向强化学习方法设计新的示教学习方法,重点介绍了2种框架以及其具有代表性2种的经典方法:学徒学习以及代价指导学习方法.
示教学习是通过模仿专家行为实现专家决策的学习方法.而其中,基于逆强化学习的示教学习方法不仅能够实现针对决策数据的学习,还能够较好地学习到专家行为的动机.
目前,示教学习的主要应用领域为智能机器人操控.在应用过程中,目前示教学习方法也遇到了很多问题,这包括:如何将示教学习算法在不同机器人之间进行迁移[39];如何采用更少量的专家决策数据来学得较好的反馈信号[40]等.此外,将示教学习方法应用到更多的强化学习场景当中也是我们未来的研究方向之一.
