硬件加速神经网络综述
2019-02-20陈桂林
陈桂林 马 胜 郭 阳
(国防科技大学计算机学院 长沙 410073)
随着数据的爆炸式增长和计算性能的阶跃式提升,机器学习的研究在经历20世纪由计算瓶颈引起的寒潮后重新变得火热起来.机器学习算法已广泛地运用到许多智能应用和云服务之中.常见应用有语音识别如苹果Siri和微软小娜,面部识别如Apple iPhoto或Google Picasa,同时智能机器人也大量使用了机器学习算法.目前,机器学习领域最火热的是以神经网络为代表的深度学习.据统计,深度神经网络运用在语音识别上比传统方法要减少了30%的单词识别错误率[1],将图像识别竞赛的错误率从2011年的26%降至3.5%[2-4].此外它还被广泛地应用到数据挖掘中.但由于神经网络的应用范围越来越广,精度要求越来越高,导致神经网络的规模也越来越大.通常对大规模神经网络加速的方法是设计性能更强大的通用芯片,并且增加专门的神经网络处理模块,如英特尔的Knight Mill和英伟达最新的Volte架构都添加了对神经网络的加速模块.不过它们作为通用运算器件始终限制了它们完成特殊任务时的效率,比如CPU必须包含高速缓存、分支预测、批处理、地址合并、多线程、上下文切换等多种通用功能,这些功能并不会完全用于神经网络的加速,但它们会占用芯片的设计面积.这就导致神经网络加速时硬件资源并没有完全利用.所以人们也开始设计专用芯片来实现对大型神经网络的加速.
近年来各大科研机构纷纷提出了各自的加速器结构,如中国科学院陈天石团队[5-8]的Diannao家族、Google的TPU[9](tensor process unit)和cloud TPU[10]、普度大学推出的Scaledeep[11]、MIT(Massa-chusetts Institute of Technology)提出的Eyeriss[12]、HP实验室和犹他大学联合提出的基于忆阻器的ISAAC[13],以及Parashar等人[14]提出的压缩稀疏卷积神经网络加速器SCNN等.现有神经网络加速芯片的研究主要集中在4个方面:1)从神经网络的计算结构出发,研究了树状结构和阵列结构如何高效地完成神经网络的卷积运算;2)从存储的瓶颈角度出发,研究了3D存储技术如何应用到加速器的设计中;3)从新材料器件的探索出发,研究了忆阻器等新器件如何实现神经网络处理存储一体化;4)从数据流的调度和优化出发,研究了如何最大化利用网络中各类数据的局部重用以及稀疏网络的处理.
1 神经网络概述
神经网络分为生物启发的神经网络(biologically inspired neural network)和人工神经网络(artificial neural network)2类.前者由神经生物学家关注,用来建立一种灵感来源于生物学的模型以帮助理解神经网络和大脑是如何运转的,比较有代表性的是脉冲神经网络.IBM的TrueNorth[15]和Furber等人[16-18]提出的SpiNNaker就是这种结构.但由于脉冲神经网络在处理机器学习任务时精度低的缺点,目前并没有得到广泛应用,本文不对其进行过多的赘述.后者人工神经网络是本文讨论的重点.
人工神经网络是一种典型的机器学习方法,也是深度学习的一种重要形式.1943年McCulloch和Pitts[19]提出了第1个人工神经元模型(M-P神经元如图1(a)),在这个模型中,神经元接受来自n个其他神经元传递过来的信号,这些输入信号通过带权重的连接进行传递,神经元接受到的总输入值将与神经元的阈值进行比较,然后通过“激活函数”产生神经元的输出.常用的激活函数有sigmoid函数、阶跃函数、ReLU等非线性函数.为了把人工神经网络研究从理论探讨付诸工程实践,1958年Rosenblatt[20]设计制作了感知机,如图1(b).感知机输入层并不是功能神经元,只接受外界输入信号后传递给输出层,输出层是一个M-P功能神经元.一个感知机可以实现逻辑与、或、非等简单的线性可分问题,但要解决一个复杂的非线性可分问题时,就要用到多层感知机(神经网络).如图1(c)的2层感知机可以解决一个异或问题,与单层感知机相比,它包含一个隐含层.当隐含层不断增加就有了深度神经网络(deep neural network, DNN)的概念,如图1(d).这里所谓的深度并没有严格的定义,在语音识别中4层网络就可以被认为是“较深的”,而在图像识别中20层以上的网络比比皆是.不过随着隐含层数的增加,深度神经网络有个明显的问题——参数数量的急剧膨胀.这就导致了计算量的急剧上升,进而使得网络模型的计算时间增加、计算功耗升高.为了解决这个问题,20世纪60年代,Hubel和Wiesel[21]提出了卷积神经网络(convolutional neural network, CNN)的概念.卷积神经网络局部感知和参数共享的特点使它能够有效地减少参数数量,降低深度神经网络的复杂性.
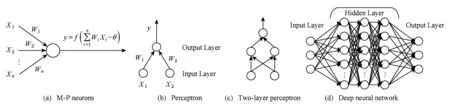
Fig. 1 The evolution of neural network图1 神经网络的演变过程

Fig. 3 A representative CNN architecture—LeNet5图3 一个具有代表性的CNN结构——LeNet5
1) 局部感知,指通过对局部信息进行整合到达识别图像的目的.在传统的深度神经网络中,第i层每个神经元都会与第i-1层所有神经元连接,这样做不仅导致了计算量非常大,而且网络缺少泛化能力,容易造成过拟合的情况.采用局部感知的方法,在机器进行图像识别时每个神经元不必对全局图像进行感知,只需要对局部进行感知,而后在更高层将局部的信息综合起来就得到了全局的信息.这样做不仅增强了网络的泛化能力,还有效减少了计算量.对应到具体操作是指上一层的数据区有一个滑动的窗口,只有窗口内的数据会与下一层神经元有关联,如图2所示.

Fig. 2 The process of convolution图2 卷积的过程
2) 参数共享,即权值共享.对一个特征图来说,卷积操作就是提取特征的过程,这里简单介绍卷积核的概念,卷积核就是一个有相关权重的方阵,它的作用是用来提取图像的特定特征.提取特征和目标在图像中的位置无关,这也意味着某一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,都能使用同样的学习特征.具体来说就是将卷积核的每一个元素作用到输入特征图的每一个位置(边界因素先不考虑).参数共享保证了训练时对输入特征图只需要学习一个参数集合,而不是对每一个位置都需要学习一个单独的参数集合.
因为局部感知和参数共享这2个特点,卷积神经网络被广泛应用在图像识别领域.图3展示了一个经典卷积神经网络框架LeNet5[22]完成数字识别的过程.从图3中可以看出,卷积神经网络主要由卷积层、池化层和全连接层组成.
1.1 卷积层
介绍卷积层前,我们先介绍一下输入图像、输入特征图、输出特征图的概念.输入图像是指要进行识别的原始图像,并且它也是第1层网络的输入特征图,输出特征图是指神经网络某1层的输出,同时它也是下一层网络的输入特征图.卷积层是为了提取输入特征图中的某些特征,它的输出是由神经元组成的一幅新的2D特征图.计算过程是先卷积再通过一个激活函数得到结果,卷积过程如图2所示.计算公式为
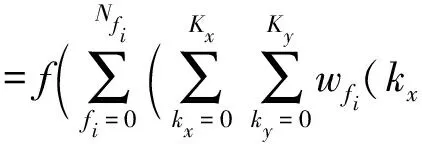
In(x+kx,y+ky)fi+βfi)),
其中,f(·)是非线性激活函数,βfi表示偏移值,out(x,y)表示在输出特征图坐标(x,y)处的值,w(kx,ky)表示卷积核坐标(kx,ky)上的权重值,In(x+kx,y+ky)表示输入特征图坐标(x+kx,y+ky)上的输入值;Kx,Ky表示卷积核的大小,fi表示第i幅输入特征图,Nfi表示输入特征图的数目.
卷积层计算中卷积的实现方法有4种,直接卷积、展开式卷积(Toeplitz矩阵方法[23])、Winograd卷积[24]和快速傅里叶变换(fast Fourier transform,FFT)卷积[25].直接卷积方案在Alex编写的cuda-convnet框架[26]中有详细介绍.卷积过程如图2所示,与数字信号中的卷积运算不同[27],直接卷积是指卷积核在输入特征图上滑动时将滑动窗口内的元素对应相乘与累加(数字信号中的卷积会将卷积核翻转再与输入对应相乘累加).展开式卷积就是将输入图像展开成列,将卷积核展开成行,将卷积操作转换成矩阵乘法操作,最后通过高度优化数学库(GPU的cuBLAS)实现.Winograd卷积是通过计算步骤的转换将卷积操作中的乘法操作和加法操作的数目改变,使乘法操作减少,加法操作增加,从而提升效率.FFT卷积就是将空间域中的离散卷积转化为傅里叶域的乘积.它的实现分3个步骤:1)通过快速傅里叶变换将输入特征图和卷积核从空间域转换到频域;2)在频域中这些变换后的矩阵相乘;3)计算结果从频域反转到空间域.
1.2 池化层
池化层也叫下采样层,通常是跟在卷积层的后面,根据一定的采样规则(通常是最大值或平均值采样)[28]做采样.池化层的作用是提取局部特征.这是由于图像具有一种“静态性”的属性,在一个图像区域有用的特征可能在另一个区域同样适用.例如,卷积层输出的特征图中2个相邻的点的特征通常会很相似,假设a[0,0],a[0,1],a[1,0],a[1,1]都表示颜色特征是红色,没有必要都保留作下一层的输入.池化层可以将这4个点做一个整合,输出红色这个特征.这样可以降低输入特征图的维度,减少过拟合现象,同时缩短网络模型的执行时间.
1.3 全连接层
全连接层的作用是将有用的局部信息提取整合,也就是将以前的局部特征通过权重矩阵重新组装成新的特征图.它的核心思想是非线性变换和拟合,多个全连接层的非线性变换嵌套叠加会使网络有很强的拟合能力(也可能造成过拟合).具体来说,在全连接层中,输出神经元与上层的输入神经元全部以独立的权重值相连接.我们可以将全连接层的计算看作是一个矩阵乘向量,再加上激活函数的非线性映射,即:
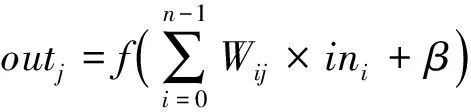
其中,out是输出值,f(·)是激活函数,n表示输入特征图的输入数目,β代表偏移值.每个输入对应1个权重值.全连接层的运算实质也是一个乘累加运算.
以上就是一个卷积神经网络的基本组成,卷积神经网络的训练基本上和BP(back propagation)神经网络的训练一样,通过递归不断地更新权重减小误差.现在又新兴的一种权重训练方法即采用遗传算法训练权重[29],文中总结的加速器大多只完成推导阶段,所以这里对训练不进行过多赘述.
2 通用芯片对人工神经网络的支持
常见的通用芯片包括CPU,GPU,DSP,FPGA,随着深度学习的火热,它们的最新设计都对神经网络进行了一些支持.下面分别来介绍它们为支持神经网络所作的改进.
2.1 CPU
CPU作为应用最广泛的通用处理器,其对神经网络的运算优化主要集中在软件层面,比如优化对神经网络框架(如Caffe[30]和TensorFlow[31])的支持.硬件方面,随着研究表明推导时操作数的精度对准确率的影响不大,如表1所示:

Table 1 Effect of Operand Accuracy on Recognition Accuracy表1 操作数精度对识别准确率的影响
CPU也开始支持低精度运算.Intel就对最新的处理器Knights Mill[32]增加了他们称之为“可变精度”的支持.另外,它对向量处理单元(vector pro-cessing unit, VPU)也做了改进.和上一代Knights Landing相比,Knights Mill在VPU上用1个较小的双精度端口和4个向量神经网络指令(vector neural network instruction, VNNI)端口,取代了Knights Landing的VPU上2个大的双精度单精度浮点(64 b32 b)端口.VNNI端口支持单精度浮点和混合精度整数(16 b输入32 b输出).由于操作数精度的降低,以往指令取出的32 b操作数如今变成了2个16 b操作数,这样运算相同数目的操作数将会采用更少的指令,同时也降低了计算的复杂度,进而提高了性能.
2.2 GPU
图形处理器GPU强大的并行计算能力适用于CNN计算过程中的大量并行浮点计算以及矩阵和向量运算,这促使了GPU成为最常见的神经网络硬件加速平台.许多机器学习的框架都利用了含有CUDA编程接口的GPU,如cuda-convnet[33],Torch[34],Theano[35],Caffe[30].与此同时,许多GPU的深度学习库也在被探索用来加速神经网络,如英伟达的cuDNN[36]和Facebook的fbfft[37]等.需要注意的是并没有哪一种框架或库对所有类型的神经网络都能有最好的加速效果.针对不同类型、不同结构神经网络上述框架和库都有不同的表现.
除了支持深度学习库之外,GPU也在体系结构上支持半精度的运算,如tesla P100采用的GP100核心、tesla V100采用的GV100核心以及AMD的Vega架构.英伟达最新的Volta架构更是设计了一个专门用来处理深度学习任务的Tensor Core.每个Tensor Core包含1个4×4×4的矩阵处理阵列来完成D=A×B+C的运算,其中A,B,C,D是4×4的矩阵,如图4所示.
矩阵相乘的输入A和B是16 b半精度浮点数(FP16)矩阵,矩阵C和D可能是FP16矩阵或FP32矩阵.该Tensor Core支持16 b和32 b的混合精度运算.FP16的乘法得到了一个全精度结果,该结果和上一周期得到部分和进行累加,如图5所示.

Fig. 4 4×4×4 matrix multiplication and accumulation of the Tensor Core图4 Tensor Core的4×4×4矩阵乘法与累加

Fig. 5 Flow chart of the Tensor Core图5 Tensor Core流程图
2.3 DSP
数字信号处理(DSP)芯片能够提供强大的数字信号处理能力,它也是一种实现神经网络加速的有效平台.四大DSP IP产商也都发布了支持神经网络的DSP IP,包括Synopsys的EV6x(embedded vision)处理器[38]、CEVA的CEVA-XM6[39]、VeriSilicon的VIP8000[40]以及Cadence的Vision C5 DSP[41].

Fig. 6 The structure of EV6x图6 EV6x结构图
EV6x在硬件结构上实现了对CNN的加速.为了增加对神经网络卷积运算的支持,从图6可以看出在EV6x的设计中引入了1个CNN Engine.CNN Engine是一个可编程嵌入式深层神经网络引擎,它支持当前所有主流神经网络模型(包括AlexNet,GoogleNet,ResNet,VGG,Yolo,Faster R-CNN,SqueezeNet).CNN引擎的可配置性使不同的网络模型可以灵活地映射到硬件资源.它能提供每周期800MAC(multiply-and-accumulate)(一般将1次MAC看作2个操作:1个乘法和1个加法)性能,与同类解决方案相比,性能提高了6倍.此外,神经网络还经常涉及到稀疏矩阵的处理,有效数据并没有连续存储,因此在EV6x的4个视觉CPU中提供了“分散-收集”(scatter-gather)功能,scatter-gather是将不规则存放的数据一次取出,再组合成一个向量以便它们能够被VPU并行处理.
CEVE-XM6针对神经网络处理做了2点优化:1)为了优化对神经网络中稀疏矩阵的处理,针对不规则访存增加了并行Scatter-Gather内存装载机制;2)采用了类似EV6x设计中DSP加硬件加速器的结构.为了利用图像卷积处理时卷积核滑过输入特征图时出现的数据重叠,加速器中采用了滑动窗口2.0(sliding windows 2.0)机制,这有助于在更广泛的神经网络中实现更高的利用率.
VIP8000由高度多线程的并行处理单元、神经网络单元和通用存储缓存单元组成.它具有可灵活配置的特点,可以导入由Caffe和TensorFlow等主流深度学习框架生成的神经网络.它的并行处理单元、神经网络单元和通用存储单元都具有可扩展性.为了实现最佳计算效率和准确率,神经网络单元支持定点8 b精度和16 b浮点精度,并支持混合模式应用.VIP8000最终能取得每秒3 TMAC的性能.
最后,Cadence的Vision C5 DSP为了实现神经网络所有层的计算(卷积层、池化层、全连接层),而不仅仅是卷积层的加速.它将图像处理运算单元和神经网络加速单元合二为一.通过移除神经网络加速器和主视觉/图像DSP之间的冗余数据传输,Vision C5 DSP的功耗远低于现有的神经网络加速器.为了支持低精度运算提高计算效率,它大量增加了低精度乘累加(MAC)单元的数量,有1 024个8 b MAC单元(512个16 b MAC单元).另外为了适应快速变换的神经网络领域,可编程的设计也是必不可少的.
通过比较以上4个DSP IP的设计,不难发现设计DSP IP实现神经网络硬件加速的一些共同点:1)都支持低精度的向量运算;2)具有可编程可扩展的特点;3)支持当前所有的主流神经网络框架.
2.4 FPGA
现场可编程门阵列(field programmable gate array,FPGA)也常被用作神经网络的加速平台,这类加速器利用可编程门阵列的特性,设计新的硬件结构,更好地匹配了神经网络的计算特点.与CPU和GPU相比,它节省了部分通用功能所占芯片面积,更加高效地利用了硬件资源,性能更高并且能效也更高;与ASIC(application specific integrated circuit)相比,FPGA能够实现快速的硬件功能验证和评估,从而加快设计的迭代速度.
具体来说,FPGA针对神经网络的优化主要包括2个方面:1)从计算结构的角度出发;2)从算法的角度出发.计算结构上的优化尽量使神经网络计算并行化和流水化,并且利用FPGA可编程的特性来设计满足加速器的灵活性和可扩展性;算法上的优化主要针对卷积层,利用FPGA的可编程性硬件实现各类卷积方法.下面通过几个例子介绍这些优化方法是如何实现的.
早在2002年Yun等人[42]就在FPGA上实现了多层感知机,他们提出了一种硬件实现数字神经网络的新体系结构——ERNA.在传统SIMD(single instruction multiple data)结构的基础上,采用灵活的阶梯式总线和内部连接网络.所提出的架构实现了基于并行化和流水线化的快速处理,同时不放弃传统方法的灵活性和可扩展性.此外,用户还可以通过设置配置寄存器来改变网络拓扑.
2011年Farabet等人[43]提出了基于FPGA的卷积神经网络处理器——NeuFlow.它是一种运行时可重构的数据流处理器,包含多个计算瓦片.在计算瓦片中,集成了多个1D卷积器(乘累加单元MAC),形成1个2D卷积算子.输入输出块通过级联卷积器和其他具有可编程性的操作元件形成,然后再经过路由多路复用器连接到全局总线.
在FPGA2017会议上,张弛等人[44]提出了一种在CPU-FPGA共享内存系统上对卷积神经网络进行频域加速的方法.首先,利用快速傅里叶变换(FFT)和重叠加法(overlap-and-add, OaA)来减少卷积层的计算量.具体做法是将频域算法映射到FPGA上高度并行的基于OaA的2D卷积器上.然后在共享内存器中提出了一种新颖的数据布局,用于CPU和FPGA之间高效的数据通信.为了减少内存访问延迟并保持FPGA的峰值性能,该设计采用了双缓冲.为了减少层间数据重映射延迟,该设计利用了CPU和FPGA进行并发处理.通过使用OaA,CNN浮点运算次数可以减少39.14%~54.10%.
总的来说,由于FPGA可编程性强,作为加速器研发周期短,在它上面实现神经网络加速的研究越来越多.但目前的深度神经网络(DNN)计算还是重度依赖密集的浮点矩阵乘法(GEMM),抛开独特的数据类型(利用稀疏压缩后的数据类型)设计,它更利于映射到GPU上(常规并行性).因此市场上依然是GPU被广泛地用于加速DNN.FPGA虽然提供了卓越的能耗效率,但它并不能达到当今GPU的性能.但是考虑到FPGA的技术进展以及DNN的算法创新速度,未来的高性能FPGA在处理DNN方面可能会优于GPU的性能.例如英特尔即将推出的14 nm的Stratix,10个FPGA将会具有数千个DSP和片上RAM.还将具有高带宽存储器HBM(一种3D存储技术).这种功能组合就提供了FPGA与GPU相差不多的浮点计算性能.再加上现在的DNN算法里开始利用稀疏(剪枝等产生)和紧凑的数据类型来提升算法的效率.这些自定义数据类型也引入了不规则的并行性,这对于GPU来说很难处理,但是利用FPGA的可定制性就能非常高效地解决.例如清华大学汪玉团队就在FPGA上优化了对神经网络稀疏性的处理.
以上4种通用硬件加速平台由于在优化神经网络处理的同时还要考虑其对通用计算的支持,因此并不能完全利用所有计算资源来完成神经网络的加速.此时,体系结构研究者考虑设计一种专用芯片来完成这一加速工作.
3 专用人工神经网络加速器
当前存在许多关于神经网络加速器的研究,本节从运算存储结构和数据流调度优化的角度对现有专用人工神经网络加速器设计进行分析梳理.
3.1 体系结构设计
现有加速器大都采用基于CMOS(complementary metal oxide semiconductor)工艺的冯·诺依曼体系结构,这类加速器设计注重2个的模块:运算单元和存储单元.运算单元的实现分为2种:树状结构和阵列结构.存储单元的设计用来存储神经网络每一层的输入值、权重和输出值等参数.如何平衡片上片外的数据分配,最小化数据的搬移是它设计的重点.值得注意的是,随着器件工艺的发展,一些体系结构研究者开始采用忆阻器等新器件来设计处理存储一体化的加速器.这类加速器有效地解决了带宽的瓶颈,具有功耗低速度快的特点.另外,专用指令集也是体系结构设计的一大重点.下面分别介绍这几个方面.
3.1.1 CMOS工艺下的运算单元结构
运算单元是加速器设计的重点,根据神经网络的计算特点,本文总结了2种运算单元的实现结构:1)树状结构,通过对神经元计算过程的抽象得到;2)PE阵列结构,利用神经网络每一层有大量乘累加并行计算的特点,将乘累加操作放入1个PE里,这样可以通过PE阵列实现神经元的并行处理.具体设计方案如下.
图7给出了树状结构图.方框内是一个简易的神经元计算单元NFU,最右端的根节点是每个神经元的输出,子节点包括乘法器、加法器和非线性激活函数,叶子节点是神经元的输入.特别地,图7中第2层的结果有的并没有经过NFU-3的函数激活,而是直接输出(图7中虚线部分),这是因为神经网络中有的层并没有激活操作,典型的如池化层.采用这种树状结构的设计有DianNao[6],DaDianNao[5].两者都采用了NFU作为加速器的基本处理单元,不同的是DaDianNao有更好的扩展性,可以高性能地支持大尺寸网络模型.不过从NFU的结构可以看出DianNao和DaDianNao仅能很好地支持神经网络的计算(NFU只有乘累加运算单元).为了运行更多的机器学习算法,PuDianNao[7]设计了新的计算单元(machine learning unit, MLU),它的子节点包括计数器、加法器、乘法器、加法树、累加器(accumulator)和杂项作业(miscellaneous, Misc).支持了更多的机器学习算法,如k-均值、k-最近邻、朴素贝叶斯、支持向量机、线性回归、神经网络、决策树等.PuDianNao运行上述机器学习算法时的平均性能与主流通用图形处理器相当,但面积和功耗仅为后者的百分之一量级.

Fig. 7 A typical tree structure of NFU图7 一个典型树状结构的NFU

Fig. 8 Systolic data flow of the matrix multiply unit in TPU图8 TPU矩阵运算单元的脉动数据流
阵列结构主要以Google TPU[9]的脉动阵列结构为代表.TETRIS[45],Eyeriss[12],ShiDianNao[8],Scaledeep[11]所采用的处理结构都在脉动阵列上进行或多或少的改动.脉动阵列的设计核心是让数据在运算单元的阵列中进行流动,增加数据的复用,减少访存的次数.图8展示了TPU中矩阵乘法单元的脉动数据流.权重由上向下流动,输入特征图的数据从左向右流动.在最下方有一些累加单元,主要用于权重矩阵或者输入特征图超出矩阵运算单元范围时保存部分结果.控制单元负责数据的组织,具体来说就是控制权重和输入特征图的数据如何传入脉动阵列以及如何在脉动阵列中进行处理和流动.
3.1.2 CMOS工艺下的存储结构
因为数据存取的速度大大低于数据处理的速度,因此存储单元的设计直接影响到加速器的性能.英伟达公司首席科学家Steve[46]曾指出,在40 nm工艺下,将64 b数据搬运20 mm的能耗是做64 b浮点乘法的数倍.因此,要降低处理器功耗,仅仅优化处理结构是不够的,必须对片上存储单元的结构也进行优化.传统的存储单元设计是将不同数据放在同一个存储器里.在DianNao里提出了一种存储方式(图7),对神经网络参数进行分块存储(用于存放输入神经元的输入缓冲器NBin、存放输出神经元的输出缓冲器NBout、存放突触权重的缓冲器SB),将不同类型的数据块存放在片上不同的随机存储器中,再优化神经网络运算过程中对不同类型数据的调度策略.与CPUGPU上基于缓存层次的数据搬运方法相比,DianNao的设计方案可将数据搬运次数减少至前者的130~110.DaDianNao也延续了这种存储结构设计,同时DaDianNao使用了eDRAM来存放所有的权重值并将其放在计算部件附近以减少访存延时.
另外,随着神经网络规模越来越大,训练集越来越大,处理能力也越来越强,对带宽的要求就变得越来越高.传统2D存储结构的DDR技术不能提供如此高的带宽.人们开始将3D存储技术引入到神经网络加速器的设计中.现在3D存储方案有AMD和海力士研发的HBM以及Intel和美光研发的HMC.Google的Cloud TPU[9]采用了HBM作为存储结构.Neurocube[47]和TETRIS[45]采用了HMC作为加速器的存储结构.另外,3D存储的出现使人们开始考虑将累加器设计到3D存储体里.这样做可以减少1次数据的读取,从而降低延迟,节省功耗,提高性能.TETRIS给出了4种在HMC中设计累加器的方案,分别是内存控制器级累加、DRAM芯片级累加、Bank级累加和子阵列级累加.第1种方案是将累加器做在HMC的逻辑层,这样设计并不能减少数据的读写次数.后3种设计能带来性能提升,但子阵列级累加实现困难,所以主要还是采用DRAM级累加和Bank级累加.
3.1.3 新工艺下的一体化结构
运算存储一体化结构的加速器打破了冯·诺依曼体系结构的束缚,要想实现这类加速器依靠传统CMOS工艺较为困难,新型器件的研究和非传统电路的实现是这类加速器的研究方向.最新研究表明忆阻器是实现一体化结构的一种较好选择,它本身具有存储数据的功能,另外利用基尔霍夫定律产生的位线电流就是卷积运算乘累加的结果,节省了乘法和累加的计算时间.去年,在忆阻器领域具有领先地位的HP公司与犹他大学合作研究发表了基于忆阻器的神经网络加速器ISAAC[13].它的结构与DaDianNao[5]相似,由多个Nodes或Tiles组成,忆阻器交叉(crossbar)开关阵列组成了每个Tile的核心来完成存储权重和卷积计算的功能.与DaDianNao相比,吞吐量是其14.8倍,功效是其5.5倍,计算密度是其7.5倍.
目前做神经网络加速的忆阻器器件主要以ReRAM为主.加州大学圣塔芭芭拉分校谢源教授课题组也发布了一种基于ReRAM的神经网络加速器PRIME[48].基于新型材料的ReRAM被认为是今后可以替代当前DRAM的下一代存储技术之一.作为忆阻器的一种,ReRAM除了是存储单元之外,其独特的交叉网络结构(crossbar)和多比特存储(multi-level cell)性质,能以很高的能量效率加速神经网络计算中的重要计算模块——乘累加.实现方法是通过在ReRAM存储体内修改一部分外围电路,使其可以在“存储”状态和“神经网络加速器”状态之间灵活切换.
现阶段使用ReRAM之类的忆阻器器件来实现CNN加速器还有许多挑战,如精确度、内部数据调度以及模数转换等.清华大学的张悠慧教授等人[49]提出了神经网络模型转换方法,将原神经网络稀疏化后划分成规模适应于ReRAM阵列的子网络,并对数据进行量化来解决硬件精度受限问题,这一定程度上从软件的角度解决了计算精度的问题.而李楚曦等人[50]提出的基于忆阻器的PIM结构实现深度卷积神经网络近似计算,通过利用模拟忆阻器大大增加数据密度,并将卷积过程分解到不同形式的忆阻器阵列中分别计算,增加了数据并行性,减少了数据转换次数并消除了中间存储,从而实现了加速和节能.但是目前实现人工神经网络大多还是采用存储分离的结构,不过随着忆阻器技术的不断成熟,由于其低功耗和快速处理数据的特点,新工艺下的一体化结构终将会是加速器发展的一大趋势.
3.1.4 指令集设计
与基于RISC指令集的通用处理器不同,专用芯片多采用基于CISC来设计自己指令集.这类指令集侧重于完成更复杂的任务,适用于指令数量少和复杂程度高的神经网络.传统指令集实现一个神经元的操作需要上百条指令,如果使用专有指令集一个神经元的操作可以只用一条指令执行,减少功耗的同时提升了速度.TPU的指令集就是CISC类型,平均每个指令的时钟周期数是10~20.指令总共只有十几条.其中比较重要的包括读权重值和读输入特征图数据、矩阵运算卷积、激活和写回计算结果等一系列神经网络运算相关的指令.
不过另一方面.越来越多研究者指出指令集的设计除了专用性外,还需要足够的灵活来满足加速器处理不同的神经网络的效率.为了解决这个问题,中科院陈天石团队[51]基于RISC设计了一种新的用于神经网络加速器领域的专用指令集架构,称为Cambricon,它是一种集标量、向量、逻辑、数据传输和控制指令于一体的存取架构.Cambricon在广泛的神经网络技术上表现出强大的描述能力,并且比通用指令集架构(X86,MIPS,GPGPU)提供更高的代码密度.
3.2 数据流调度和优化
3.1节介绍了专用芯片在体系结构方面对神经网络所作的支持,但是在神经网络处理过程中数据流的组织和调度的方式以及数据流的优化对硬件实现神经网络的性能影响同样很大.在神经网络中常用的数据流有权重固定流、输出固定流、无局部复用和行固定流,常用的数据流优化处理手段有0值跳过、稀疏矩阵、参数压缩等.
3.2.1 数据流的调度
1) 权重固定流
在卷积神经网络的卷积操作过程中,同一个卷积核会卷积多个输入特征图.此时对这个卷积核里的权重是有复用的.如果把多次使用的权重存在每个PE的寄存器里,那么卷积层的计算过程将会减少从全局缓冲取数据和向全局缓冲存数据的开销.由于部分和(partial sum, Psum)还会用到,因此将它暂时存放在全局缓冲里,如果缓冲区不大就必须限制同时产生Psum的数量,这样也限制了一次性可以在片上加载的权重.此时若采用脉冲的方式将会有效减少Psum对全局缓冲大小的依赖,图9(a)给出了这种数据流的处理过程.权重值存放在PE里,输入激活值被广播到所有PE单元.部分和在每个PE累加过后传到下一个PE.
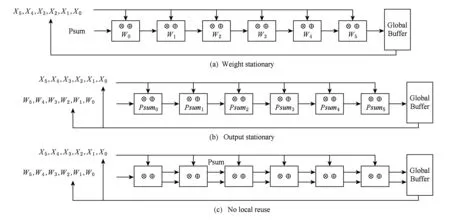
Fig. 9 Dataflow of the neural network图9 神经网络的数据流
采用这种数据流的芯片设计有NneuFlow[43],它用了2D卷积引擎来处理卷积核.每个引擎处理过程中权重值保持不变.其他采用这种数据流的例子还有[52-54].
2) 输出固定流
指在寄存器中存放每个周期计算的部分和.卷积操作是一个乘累加操作,每个周期计算的部分和需要与下一个周期的部分和相加得到新的部分和,直到这个卷积核的计算完全结束.把部分和存在寄存器里同样也是减少了从全局缓冲取数据和向全局缓冲存数据的开销.同样这种数据流设计采用脉冲结构实现是最佳的.图9(b)给出了这种数据流的处理过程.部分和在PE内部累积最后流出到全局缓冲区,权重值被广播到所有PE.输入激活值在PE进行乘法运算后传给下一个PE.
采用这种数据流的芯片设计有ShiDianNao[8].它的每个PE通过从相邻PE获取相应的输入激活来处理每个输出激活值.PE阵列通过实现专用网络来水平和垂直地传递数据.每个PE还具有数据延迟寄存器,以便在所需的循环周期内保持数据周期.全局缓冲区流入输入激活值,并将权重广播到PE阵列中.部分和积累在每个PE内部,然后被流出回到全局缓冲区.其他采用这种数据流的例子还有[55-56].
3) 无局部复用
指不在PE的寄存器文件里存放权重和部分和,每个周期需要计算的数据都从全局缓冲获取,计算完后将结果传回全局缓冲,最后通过PE阵列累积部分和.这样的好处是减少了PE所占的面积,但是由于PE没有数据保持固定,所以这样的设计也增加了全局缓冲区和空间PE阵列的流量.图9(c)给出了这类数据流的处理过程.
采用这种数据流的芯片设计有UCLA[57],Dian-Nao[6],DaDianNao[5],PuDianNao[7].其中DianNao系列由于采用了专门的寄存器来保存部分和,并不用从内存里取,因此可以进一步降低访问部分和的功耗.
4) 行固定流
指在高维卷积过程中通过将高维卷积分解成可以并行运行的1D卷积原语;每个基元(原语操作)表示1行卷积核权重和1行输入特征图像素的点积,并生成1行部分和Psum.不同原语的Psum被进一步累积在一起以生成输出特征图.具体做法是将每个原语映射到1个PE进行处理,每个行对的计算在PE中保持独立,这就实现了卷积核和寄存器级别的输入特征图数据重用.图10给出了这类数据流的处理过程.

Fig. 10 The row stationary dataflow in PEs set to process a 2D convolution图10 处理2维卷积时的PE阵列中的行固定流示意图
采用这种数据流的芯片设计有Eyeriss[12]和TETRIS[45].
5) 其他数据流
上述数据流都没有将权重值和输入激活值(上一层输出经过激活函数得到的值)完全复用.在SCNN[14]中提出了一种全新的数据流,笛卡儿数据流.实现方法是将需要计算的权重和输入激活值做成2个向量,然后2个向量做笛卡儿积,这样向量中每个数能达到最大复用.
3.2.2 数据流的优化
神经网络在数据的处理过程中还存在很多的优化技巧.首先,神经网络在推导过程中的对精度要求不高,这使几乎全部的神经网络专用加速器都支持低精度运算,其中TPU[9]更是支持了8 b低精度运算.其次,稀疏性.人们在神经网络训练和推导过程中发现会产生许多的0值,一部分来源于网络训练阶段的剪枝,另外一部分来源于推导阶段采用ReLU激活函数参数的0激活值.而0值在卷积操作中是可以跳过的,因为卷积操作由多个乘累加操作组成,乘数有一个为0则乘法和后面的加法就没必要计算.在Cnvlutin[58]就采用了跳过权重中0值的数据流,在Cambricon-X[59]里则采用了跳过输入的0激活值,而在SCNN里通过压缩稀疏性和将非0参数编码的方式同时做到了跳过0值权重和0激活值.这也引出了神经网络的另一种优化方法——压缩.在SCNN[14]和EIE[60]中都采用了压缩参数的方法.
虽说压缩稀疏权重从计算量的角度来看能够直接提高性能,但最近的研究表明在不损失精度的情况下直接通过权重剪枝却会造成性能的下降[56],这是由于解码压缩的权重需要额外的时间,并且压缩的非0权重值需要额外的索引值来记录它们原来矩阵的位置,这也增加了存储开销.最终的结果导致只有在大量剪枝的情况下,剪枝后的新网络的性能才会优于剪枝前的网络,而且会有精度的损失.在文献[61]中提出了2种解决办法分别针对并行性不同的2种硬件:1)采用基于SIMD的权重剪枝用于低并行度的硬件,实现方法是采用权重分组索引,这样一条SIMD指令可以读取多个权重值;2)使用节点剪枝用于高并行的硬件,具体实现思想是利用正则化既不完全去掉参数又可以将它的影响降到最小.
4 加速器未来发展的挑战和机遇
第2节和3节论述了许多硬件加速神经网络的方案,其中在通用芯片平台实现的包括支持低精度计算、支持更多的神经网络框架以及设计一个加速卷积运算的模块;在专用芯片平台实现的包括改进运算存储结构、优化数据流和设计专用指令集.虽然这些设计已经在神经网络加速方面取得了重大进展.但还是有许多问题和挑战要解决.下面列举的4个方面或许会是加速器未来研究的可行方向.
1) 设计功耗更低的加速器.嵌入式应用是加速器应用的一种趋势,加速器未来可能会应用到像可穿戴这样的领域,这就需要把功耗进一步降低,可突破的方向包括采用新器件,进一步探索数据的组织形式以减少数据的移动等.
2) 设计通用性更强的加速器.随着神经网络应用的增多,神经网络的结构和框架也会越来越多.未来加速器设计需要考虑到支持各个框架的核心算法.
3) 解决访存瓶颈.存取速度跟不上运算速度依旧是加速器设计的难题.目前3D存储是解决该问题的一个方向.不过随着新工艺的发展,采用新器件的非冯·诺依曼体系结构或许能进一步改善这个问题.
4) 应用其他领域的突破成果.技术革命通常伴随着不同领域的飞跃,采用基于生物启发的脉冲神经网络、量子计算机以及使用忆阻器等新器件都可能是加速器未来设计的可行方案.
