Object removal from complex videos using a few annotations
2019-02-17ThucTrinhLeAndresAlmansaYannGousseauandSimonMasnou
Thuc Trinh Le(),Andr´es Almansa,Yann Gousseau,and Simon Masnou
Abstract We present a system for the removal of objects from videos.As input,the system only needs a user to draw a few strokes on the fi rst frame,roughly delimiting the objects to be removed.To the best of our knowledge,this is the fi rst system allowing the semi-automatic removal of objects from videos with complex backgrounds.The key steps of our system are the following:after initialization,segmentation masks are fi rst re fi ned and then automatically propagated through the video.Missing regions are then synthesized using video inpainting techniques.Our system can deal with multiple,possibly crossing objects,with complex motions,and with dynamic textures.This results in a computational tool that can alleviate tedious manual operations for editing high-quality videos.
Keywordsobjectremoval; objectsegmentation;object tracking;video inpainting;video completion
1 Introduction
In this paper,we propose a system to remove one or more objects from a video,starting with only a few user annotations.More precisely,the user only needs to approximately delimit in the fi rst frame the objects to be edited.Then,these annotations are re fi ned and propagated through the video.One or more objects can then be removed automatically.This results in a fl exible computational video editing tool,with numerous potential applications.Removing unwanted objects(such as a boom microphone)or people(such as an unwanted wanderer)is a common task in video post-production.Such tasks are critical given the time constraints of movie production and the prohibitive costs of reshooting complex scenes.They are usually achieved through extremely tedious and time-consuming frame-by-frame processes,for instance using the Rotobrush tool from Adobe After Effects[1]or professional visual effects software such as SilhouetteFX or Mocha.More generally,the proposed system paves the way to sophisticated movie editing tasks,ranging from crowd suppression to unphysical scene modi fi cation,and has potential applications for multi-layered video editing.
Two main challenges arise in developing such a system.Firstly,nopart of the objects to be edited should remain in the tracking part of the algorithm;otherwise,they would be propagated and enlarged by the completion step,resulting in unpleasant artifacts.Secondly,the human visual system is good at spotting temporal discontinuities and aberrations,making the completion step a tough one.We address both issues in this work.
The fi rst step of our system consists of transforming a rough user annotation into a mask that accurately represents the object to be edited.For this,we use a classical strategy relying on a CNN-based edge detector,followed by a watershed transform yielding super-pixels,which are eventually selected by the user to re fi ne the segmentation mask.After this step,a label is then given to each object.The second step is the temporal propagation of the labels.There we make use of state-of-the-art advances in CNN-based multiple object segmentation. Furthermore,our approach includes an original and crucial algorithmic block which consists in learning the transition zones between objects and the background,in such a way that objects are fully covered by the propagated masks.We call the resulting block asmart dilationby analogy with the dilation operators of mathematical morphology.Our last step is then to remove some or all of the objects from the video,depending on the user’s choice. For this,we employ two strategies:motion-based pixel propagation for the static background,and patch-based video completion for dynamic textures.Both methods rely heavily on the knowledge of segmented objects.This interplay between object segmentation and the completion scheme improves the method in many ways:it allows for better video stabilization,for faster and more accurate search for similar patches,and for more accurate foreground-background separation.These improvements yield completion results with very little or no temporal incoherence.
We illustrate the effectiveness of our system through several challenging cases including severe camera shake,complex and fast object motions,crossing objects,and dynamic textures.We evaluate our method on various datasets,for both object segmentation and object removal.Moreover,we show on several examples that our system yields comparable or better results than state-of-the-art video completion methods applied to manually segmented masks.
This paper is organized as follows.First,we brie fl y explore some related works(Section 2).Next,we introduce our proposed approach which includes three steps: fi rst-frame annotation,object segmentation,and object removal(Section 3).Finally,we give experimental results as well as an evaluation and comparison with other state-of-the-art methods.A shorter version of this work can be found in Ref.[2].
2 Related works
The proposed computational editing approach is related to several families of works that we now brie fl y review.
2.1 Video object segmentation
Video object segmentation,the process of extracting space-time segments corresponding to objects,is a widely studied topic whose complete review is beyond the scope of this paper.For a long time,such methods were not accurate enough to avoid using green-screen compositing to extract objects from video.Signi fi cant progress was achieved by the end of the 2000s for supervised segmentation:see e.g.,Ref.[1].In particular,the use of supervoxels became the most fl exible way to incorporate user annotations in the segmentation process[3,4].Other efficient approaches to the supervised object segmentation problem are introduced in Refs.[5,6].
A real breakthrough occurred with approaches relying on convolutional neural networks(CNNs).In the DAVIS-2016 challenge[7],the most efficient methods were all CNN-based,both for unsupervised and semi-supervised tasks.For the semi-supervised task,where a fi rst frame annotation is available,methods mostly differ in the way they train the networks.The one shot video object segmentation(OSVOS)method,introduced in Ref.[8],starts from a pre-trained network and retrains it using a large video dataset,before fi ne-tuning it per-video using annotation on the fi rst frame to focus on the object being segmented.With a similar approach,Ref.[9]relies on an additional mask layer to guide the network.The method in Ref.[10]further improves the results from OSVOS with the help of a multi network cascade(MNC)[11].
All these approaches work image-per-image without explicitly checking for temporal coherence,and therefore can deal with large displacements and occlusions. However,since their backbone is a network used for semantic segmentation,they cannot distinguish between instances of the same class or between objects that resemble each other.
Another family ofworks deals with the segmentationofmultipleobjects. Compared with thesingleobjectsegmentation problem,an additionaldifficulty hereisto distinguish between different object instances which may have similar colors and may cross each other.Classical approaches include graph-based segmentation using color or motion information[12-14],the tracking of segmentation proposals[15,16],or bounding box guided segmentation[17,18].
The DAVIS-2017 challenge[19]established a ranking between methods aiming at semi-supervised segmentation of multiple objects.Again,the most efficient methods were CNN-based.It is proposed in Ref.[20]to modify the OSVOS network[8]to work with multiple labels and to perform online fi ne-tuning to boost performance.In Ref.[21],the networks introduced in Ref.[22]are adapted to the purpose of multiple object segmentation through the heavy use of data augmentation,still using annotation of the fi rst frame.The authors of this work also exploit motion information by adding optical fl ow information to the network.This method is further improved in Ref.[23]by using a deeper architecture and a reidenti fi cation module to avoid propagating errors.This last method has achieved the best performance in the DAVIS-2017 challenge[19].With a different approach,Hu et al.[24]employ a recurrent network exploiting long-term temporal information.
Recently,with the release of a large-scale video object segmentation dataset for the YouTube video object segmentation(YouTube-VOS)challenge[25],many further improvements have been made in the fi eld. Among them,one of the most notable is PreMVOS[26]which has won the 2018 DAVIS challenge[27]and the YouTube-VOS challenge[25].
In PreMVOS,the algorithm fi rst generates a set of accurate segmentation mask proposals for all objects in each frame of a video.To achieve this,a variant of the mask R-CNN[28]object detector is used to generate coarse object proposals,and then a fully convolutional re fi nement network inspired by Ref.[29]and based on the DeepLabv3+[30]architecture produces accurate pixel masks for each proposal. Secondly,these proposals are selected and merged into accurate and temporally consistent pixel-wise object tracks over the video sequence.In contrast with PreMVOS which focuses on accuracy,some methods trade offaccuracy for speed.Those methods take the fi rst frame with its mask annotation either as guidance to slightly adjust parameters of the segmentation model[31]or as a reference for segmenting the following frames without tuning the segmentation model[32-34].
Although these methods yield impressive results in terms of the accuracy of the segmentation,they may not be the optimal solutions for the problem we consider in this paper.As noted above,when removing objects from video,it is crucial for the video completion step that no part of the removed objects remains after segmentation.Said differently,we are in a context whererecallis much more important thanprecision;see Section 4.2 for de fi nitions of these metrics.In the experiments section,we compare our segmentation approach to several state-of-the-art methods with the aim of optimizing a criterion which penalizes under-detection of objects.
2.2 Video editing
Recently,advances in both analysis and processing of video have permitted advances in the emerging if eld of computational video editing. Examples include,among others,tools for the automatic,dialogue-driven selection of scenes[35],time slice video synthesis[36],and methods for the separate editing of re fl ectance and illumination components[37].It is proposed in Ref.[38]to accurately identify the background in video as a basis for stabilization,background suppression,or multi-layered editing.In a sense,our work is more challenging since we need to identify moving objects with enough accuracy that they can be removed seamlessly.
Because we learn a transition zone between objects and the background,our work is also related to image matting techniques[39],and their extension to video[40]as a necessary fi rst step for editing and compositing tasks.Lastly,since we deal with semantic segmentation and multiple objects,our work is also related to the soft semantic segmentation recently introduced for still images[41].
2.3 Video inpainting
Image inpainting,also called image completion,refers to the task of reconstructing missing or damaged image regions by taking advantage of image content outside these missing regions.
The fi rst approaches were variational[42],or PDE-based[43]and dedicated to the preservation of geometry.They were followed by patch-based methods[44,45],inherited from texture synthesis methods[46].Some of these methods have been adapted to video,often by mixing pixel-based approaches for reconstructing the background and greedy patch-based strategies for moving objects[47,48].In the same vein,different methods have been proposed to improve or speed up reconstruction of the background[49,50],with the strong limitation that the background should be static.Other methods yield excellent results in restricted cases,such as the reconstruction of cyclic motions[51].
Another family of works which performs very well when the background is static relies on motion-based pixel propagation.The idea is to fi rst infer a motion fi eld outside and inside the missing regions.Using the completed motion fi eld,pixel values from outside the missing region are then propagated inside it.For example,Grossauer describes in Ref.[52]a method for removing blotches and scratches in old movies using optical fl ow.A limitation of this work is that the estimation of the optical fl ow suffers from the presence of the scratches.Using a similar idea,but avoiding calculating the optical fl ow directly in the missing regions,several methods try to restore the motion fi eld inside these missing regions by gradually propagating motion vectors[53],by sampling spatialtemporal motion patches[54,55],or by interpolating the missing motion[56,57].
In parallel,it was proposed in Ref.[58]to address the video inpainting problem as a global patch-based optimization problem,yielding unprecedented time coherence at the expense of very heavy computational costs. The method in Ref.[59]was developed from this seminal contribution,by accelerating the process and taking care of dynamic texture reconstruction.Other state-of-the-art strategies rely on a global optimization procedure,taking advantage of either shift-maps[60]or an explicit fl ow fi eld[61].This last method arguably has the best results in terms of temporal coherence,but since it relies on two-dimensional patches,it is unsuitable for the reconstruction of dynamic backgrounds.Recently,it was proposed in Ref.[62]to improve the global strategy of Ref.[59]by incorporating optical fl ow in a systematic way.This approach has the ability to reconstruct complex motions as well as dynamic textures.
Let us add that the most recent approaches to image inpainting rely on convolutional neural networks and have the ability to infer elements that are not present in the image at hand[63-65].To the best of our knowledge,such approaches have not been adapted to video because their training cost is prohibitive.
In this work,we propose two complementary ways to perform the inpainting step needed to remove objects in video. The fi rst method is fast and relies on frame-by-frame completion of the optical fl ow,followed by propagation of voxel values.This approach is inspired by the recently introduced method in Ref.[57],itself sharing ideas with the approach from Ref.[61]and yielding impressive speed gains.Such approaches are computationally efficient but unable to deal with moving backgrounds and dynamic textures.For these complex cases,we rely on a more sophisticated(and much slower)second approach,extending ideas we initially developed in Ref.[62].
3 Proposed method
The general steps of our method are as follows:
(a)First,the user draws a rough outline of each object of interest in one or several frames,for instance in the fi rst frame(see Section 3.1).
(b)These approximate outlines are re fi ned by the system,then propagated to all remaining frames using different labels for different objects(see Section 3.2).
(c)If errors are detected,the user may manually correct them in one or several frames(using step(a))and propagate these edits to the other frames(using step(b)).
(d)Finally,the user selects which of the selected objects should be removed,and the system removes the corresponding regions from the whole video,reconstructing the missing parts in a plausible way(see Section 3.3).For this last step two options are available:a fast one for static backgrounds,and a more involved one for dynamic backgrounds.
In the fi rst step most methods only select the object to be removed.There are,however,several advantages to tracking multiple objects with different labels:
1.It gives more freedom to the user for the inpainting step with the possibility to produce various results depending on which objects are removed;in addition,objects which are labeled but not removed are considered as important by the system and therefore better preserved during inpainting of other objects.
2.It may produce better segmentation results than tracking a single object,in particular when several objects have similar appearance.
3.It facilitates video stabilization and therefore increases temporal coherence during the inpainting step,as shown in the results(see Section 4.3).
4.It is of interest for other applications,e.g.,action recognition or scene analysis.
An illustration of these steps can be found in the supplementary website:https://object-removal.telecom-paristech.fr/.
3.1 First frame annotation
A classical method to cut out an object from a frame involves commercial tools such as the Magic Wand of Adobe Photoshop which are fast and convenient.However,this classical method requires many re fi nement steps and is not accurate with complex objects.To increase the precision and reduce user interaction,many methods have been proposed where interactive image segmentation is performed using scribbles,point clicks,superpixels,etc.Among them,some state-of-the-art annotators achieve a high degree of precision by using edge detectors to fi nd the contour map and create a set of object proposals from this map[66];the appropriate regions are then selected by the user using point clicks.The main drawbacks of these approaches are large computation time and a weak level of user input.
In order to balance human effort and accuracy,we adopt a fast and simple algorithm.Our system fi rst generates a set of superpixels from the fi rst image,and then the user can select suitable superpixels by simply drawing a coarse contour around each object.The set of superpixels is created using an edgebased approach.More precisely,the FCN-based edge detector network introduced in Ref.[67]is applied to the fi rst image,and its output is a probability map of edges.Superpixels are extracted from this map by the well-known watershed transform[68],which runs directly on edge scores.There are two main advantages of using this CNN-based method to compute the edge map:
1.It has shown superior performance over traditional boundary detection methods that use local features such as colors and depths.In particular,it is much more accurate.
2.It is extremely fast:one forward pass of the network takes about 2 ms,so the annotation step can be performed interactively in real time.
After computing all superpixels,the user selects the suitable ones by drawing a contour around each target object to get rough masks.Superpixels which overlap these masks by more than 80%are selected.The user can re fi ne the mask by adding or removing superpixels using mouse clicks.As a result,accurate masks for all objects of interest are extracted in a frame after a few seconds of interactive annotation.
3.2 Object segmentation
In this step,we start from the object masks computed on the fi rst frame using the method described in the previous section,and we aim to infer a full space-time segmentation of each object of interest in the whole video.We want our segmentation to be as accurate as possible,in particular without false negatives.
Doing this in complex videos with several objects which occlude each other is an extremely challenging task. As described in Section 2,CNNs have made important breakthroughs in semantic image segmentation with extensions to video segmentation in the last two years[19,27,69].However,current CNN-based semantic segmentation algorithms are still essentially image-based,and do not take global motion information sufficiently into account.As a consequence,semantic segmentation algorithms cannot deal with sequences where: (i)several instances of similar objects need to be distinguished;and(ii)these objects may eventually cross each other.Examples of such sequences areLes Loulous①https://perso.telecom-paristech.fr/gousseau/video_inpainting/introduced in Ref.[59],andMuseumandGranados-S3②http://gvv.mpi-inf.mpg.de/projects/vidinp/introduced in Refs.[49,60].
On the other hand,more classical video tracking techniques like optical fl ow-based propagation or global graph-based optimization do take global motion information into account[70].Nevertheless,they are most often based on bounding boxes or rough descriptors and do not provide a precise delineation of objects’contours.Two recent attempts to adapt video-tracking concepts to provide a precise multiobject segmentation[71,72]fail completely when objects cross each other,as in theMuseum,Granados-S3,andLouloussequences.
In the rest of this section,we describe a novel hybrid technique which combines the bene fi ts of classical video tracking with those of CNN-based semantic segmentation.The structure of our hybrid technique is shown in Fig.1.CNN-based modules are depicted in green and red;their inner structure is described in Section 3.2.1 and Fig.2.Modules inspired from video-tracking concepts are depicted in blue and are detailed in Section 3.2.2.
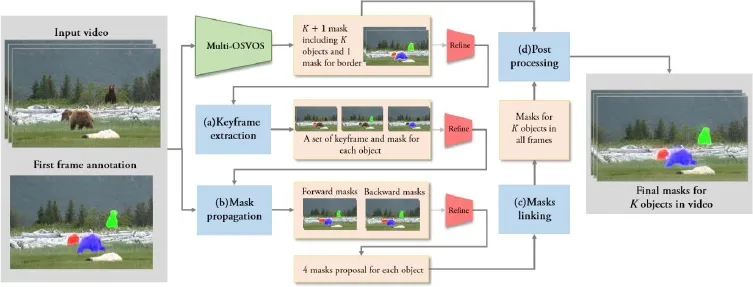
Fig.1 General pipeline of our object segmentation method.Given the input video and annotations in the fi rst frame,our algorithm alternates two CNN-based semantic segmentation steps(multi-OSVOS network in green,re fi ning network in red)with 4 video-tracking steps(blue blocks):(a)keyframe extraction,(b)mask propagation,(c)mask linking,and(d)post processing.See Section 3.2.

Fig.2 Two networks used in the general pipeline.Left:multi-OSVOS network,right:re fi nement network.They serve different purposes:the multi-OSVOS network helps us separating background and objects while the re fi nement network is used to fi ne-tune a rough input mask.
Note that the central part of Fig.1 operates on a frame-by-frame basis.Each segmentation proposal from themulti-OSVOS network(green),or from themask propagationmodule(blue)is improved by there fi nement network(red).On the right of the fi gure,themask linkingmodule(blue)builds a graph that links all segmentation proposals from previous steps,and makes a global decision on the optimal segmentation for each of theKobjects being tracked.Finally thekeyframe extractionmodule is required to set sensible temporal limits to themask propagationiterations,while the fi nalpost-processingmodule further re fi nes the result with the objective of maximizing recall,which is much more important than precision in the case of video inpainting.All these modules are explained in more detail in the following sections.
3.2.1Semantic segmentation networks
Our system uses two different semantic segmentation networks:amulti-OSVOSnetwork and are fi nementnetwork.Both operate on a frame-by-frame basis.
Our implementation ofmulti-OSVOScomputesK+1 masks for each frame:Kmasks for theKobjects of interest and a novel additional mask covering the objects’boundaries. We call this latter mask asmart dilationlayer;it is the key to guaranteeing that segmentation does not miss any part of the objects,which is especially difficult in the presence of motion blur.
While themulti-OSVOS networkprovides a fi rst prediction,there fi nement networktakes mask predictions as additional guidance input and improves those predictions based on image content,similarly to Ref.[9].
Training these networks is a challenging task,because the only labeled example we can rely on(for supervised training)is the fi rst annotated frame and the correspondingKmasks.The next paragraphs focus on our networks’architectures and on semi-supervised training techniques that we use to circumvent the training difficulty.
Multi-OSVOS network.The training technique of our semantic segmentation networks is mainly inspired from the OSVOS network[8],a breakthrough which achieved the best performance in the DAVIS-2016 challenge[7].The OSVOS network uses a transfer learning technique for image segmentation:the network is fi rst pre-trained on a large database of labeled images. After training,this so-calledparentnetwork can roughly separate all foreground objects from the background. Next,the parent network is fi ne-tuned using the fi rst frame annotation(annotation mask and image)in order to improve the segmentation of a particular object of interest.OSVOS has proven to be a very fast and accurate semi-supervised method to obtain backgroundforeground separation.Our multi-OSVOS network uses a similar transfer learning technique,yet with several important differences:
·Our network can identify different objects separately(instead of simply foreground and background)and provides a smart dilation mask,i.e.,a smart border which covers the interfaces between segmented objects and the background,signi fi cantly reducing the number of false negative pixels.The ground truth for this smart dilation mask is de fi ned in the fi ne-tuning step by a 7-pixel wide dilation of the union of all object masks.
·Unlike OSVOS,which uses a fully convolutional
network(FCN)[73],our network uses the Deeplab v2[74]architecture as the parent model since it outperforms FCN on some common datasets such as PASCAL VOC 2012[75].
·In the fi ne-tuning training step we adopt a data augmentation technique in the spirit of Lucid Tracker[21]:we remove all objects from the fi rst frame using Newson et al.’s image inpainting algorithm[76],then the removed objects undergo random geometric deformations(affine and thin plate deformations),and eventually are Poisson blended[77]over the reconstructed background.This is a sensible way of generating large amounts of labeled training data with an appearance similar to that which the network might observe in the following frames.
The smart dilation mask is of particular importance to ensure that segmentation masks do not miss any part of the object,which is typically difficult in the presence of motion blur.A typical example can be seen in Fig.3 where some parts of the man’s hands and legs cannot be captured by simply dilating the output mask,because motion blur leads to partially transparent zones which are not recognized by the network as part of the man’s body. With the smart dilation mask,the missing parts are properly captured,and there are no left over pixels.
Refinement network.The multi-OSVOS network can separate objects and background precisely,but it relies exclusively on how they appear in the annotated frame without consideration of their positions,shapes,or motion cues across frames.Therefore,when objects have similar appearance,multi-OSVOS fails to separate individual object instances.In order to take such cues into account,we propagate and compare the prediction of multi-OSVOS across frames using video tracking techniques(see Section 3.2.2),and then double-check and improve the result after each tracking step using the refinement network described below.

Fig.3 Advantages of using the smart dilation mask,a smart border layer in the output map of our multi-OSVOS network.(a)Border obtained by simply dilating the output map of the network:some parts of the objects are not covered.(b)Border layer learned by the network:the transition region is covered.
The re fi nement network has the same architecture as the multi-OSVOS network,except that(i)it takes an additional input,namely mask predictions for theKforeground objects from another method,and(ii)it does not produce as an output the(K+1)-th smart dilation mask that does not require any further improvement for our purposes.
Training is performed in exactly the same way as for multi-OSVOS,except that the training set has to be augmented with inaccurate input mask predictions.These should not be exactly the same as the output masks;otherwise,the network would learn to perform a trivial operation ignoring the RGB information.Such inaccurate input mask predictions are created by applying relevant random degradations to ground truth masks,e.g.,small translations,and affine and thin-plate spline deformations,followed by a coarsening step(morphological contour smoothing and dilation)to remove details of the object contour;fi nally,some random tiny square blocks are added to simulate common errors in the output of multi-OSVOS.The ground truth output masks in the training dataset are also dilated by a structuring element of size 7×7 pixels in order to have a safety margin which ensures that the mask does not miss any part of the object.
3.2.2Multiple object tracking
As a complement to CNN-based segmentation,we use more classical video tracking techniques in order to take global motion and position information into account. The simplest ingredient of our object tracking subsystem is a motion-basedmask propagationtechnique that uses a patch-based similarity measure to propagate a known mask to the consecutive frames. It corresponds to block(b)in Fig.1 and is described in more detail below.This simple scheme alone can provide results similar to other object tracking methods such as SeamSeg[71]or ObjectFlow[72]. In particular it is able to distinguish between different instances of similar objects,based on motion and position.However it loses track of the objects when they cross each other,and it accumulates the errors.To prevent this from happening we complement the mask propagation module with fi ve coherence reinforcement steps:
Semanticsegmentation.There fi nement network(see Section 3.2.1)is applied to the output of each mask propagation step in order to avoid errors accumulating from one frame to the next.
Keyframe extraction.Mask propagation is effective only when it propagates from frames where object masks are accurate(especially when objects do not cross each other). Frames where this is detected to be true are labeled askeyframes,and mask propagation is performed only between pairs of successive keyframes.
Mask linking.When the mask propagation step is unsure about which decision to make,it provides not one,but several mask candidates for each object.A graph-based technique allows all these mask candidates to be linked together.In this way,the decision on which mask candidate is best for a given object on a given frame is made based on global motion and appearance information.
Post-processing.After mask linking,a series of post-processing steps are performed using the original multi-OSVOS result to expand labelling to unlabelled regions.
Interactive correction.In some situations where errors appear,the user can manually correct them on one frame and this correction is propagated to the remaining frames by the propagation module.
The following paragraphs describe in detail the inner workings of the four main modules of our multiple object tracking subsystem:(i)keyframe extraction,(ii)mask propagation,(iii)mask linking,and(iv)post-processing.
Keyframe extraction.A frametis a keyframe for an objecti∈{1,...,K}if the mask of this particular object is known or can be computed with high accuracy.All frames in which the object masks were manually provided by the user are considered keyframes.This is usually the fi rst frame or a very few representative frames.
The remaining frames are considered keyframes for a particular object when the object is clearly isolated from other objects and the mask for this object can be computed easily.To quantify this criterion,we rely on the multi-OSVOS network which returnsK+1 masksOifor each frametandi∈{1,...,K+1}.This allows us to compute the global foreground maskTo verify whether this frame is a keyframe for objecti∈{1,...,K}we proceed as follows:
1.Compute the connected components ofOi.Letrepresent the largest connected component.
2.Compute the set of connected components of the global foreground maskFand call itF.
3.For each connected componentcompute the overlap ratio with the current objectri(O′)=andO′are isolated from the remaining objects①i.e.,if ∩=O′∩=∅for all j∈{1,...,K}such that j/=i.then this is a keyframe for objecti.
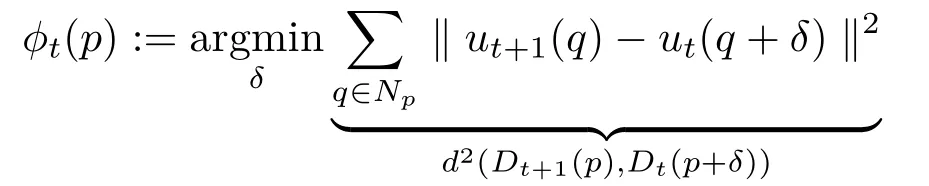
Mask propagation.Masks are propagated forwards and backwards between keyframes to ensure temporal coherence. More speci fi cally,forward propagation proceeds as follows:given the maskMtat framet,the propagated maskMt+1is constructed with the help of a patch-based nearest neighbor shift mapφtfrom framet+1 to framet,de fi ned as i.e.,it is the shiftδthat minimizes the squared Euclidean distance between the patch centered at pixelpin framet+1 and the patch aroundp+δat framet.In this expression,Npdenotes a square neighborhood of given size centered atp,andDt(p)is the associated patch in framet,i.e.,Dt(p)=ut(Np)withutthe RGB image corresponding to framet.Theℓ2-metric between patches is denotedd.To improve robustness and speed,this shift map is often computed using an approximate nearest neighbor searching algorithm such as coherency sensitive hashing(CSH)[78],or FeatureMatch[79].To capture the connectivity of patches across frames in the video,two additional terms are used in Ref.[71]for space and time consistency:the fi rst term penalizes the absolute shift and the latter penalizes neighbourhood incoherence to ensure adjacent patches fl ow coherently.Moreover,to reduce the patch space dimension and to speed up the search,all patches are represented with lower dimension features,e.g.,the main components in Walsh-Hadamard space;see Ref.[71]for more details.We use this model to calculate our shift map.
Once the shift map has been computed,we propagate the mask as follows:letut(p)be the RGB value of pixelpin framet.Then the similarity between a patchDt+1(p)in framet+1 and its nearest neighbourDt(p+φ(p))in frametis measured as
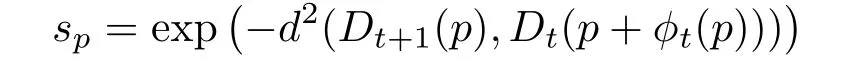
Using this similarity measure the maskMt+1is propagated fromMtusing the following rule:
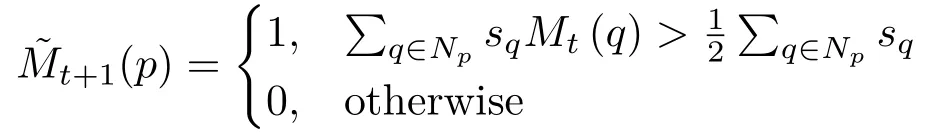
The fi nal propagated maskMt+1is obtained by a series of morphological operations including opening and hole fi lling onfollowed by the re fi nement network to correct certain errors.ThenMt+1is iteratively propagated to the next framet+2 using the same procedure until we reach the next keyframe.
Although this mask propagation approach is useful,several artifacts may occur when objects cross each other:the propagation algorithm may lose track of an occluded object or it could mistake one object for another.To avoid such errors,mask propagation is performed in both forwards and backwards directions between keyframes.This gives for each object two candidate masks at each framet:i.e.,the one that has been forward-propagated from a previous keyframet′<tandi.e.,the one that has been backward-propagated from an upcoming keyframet′>t.In order to circumvent both lost and mistaken objects we consider for each object two additional candidate masks:
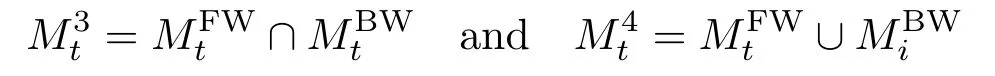
The decision between these four mask candidates for each frame and each object is deferred to the next step,which makes that decision based on global optimization.
Mask linking.After backward and forward propagation,each object has 4 mask proposals(except for keyframes where it has a single mask proposal).In order to decide which mask to pick for each object in each frame,we use a graph-based data association technique(GMMCP)[80]that is specially well-suited to video tracking problems. This technique not only allows selection among the 4 candidates for a given object on a given frame,it is also capable of correcting erroneous object-mask assignments on a given frame,based on global similarity computations between mask proposals along the whole sequence.The underlying generalized maximum multi-cliques problem is clearly NP-hard,but the problem itself is of sufficiently small size to be handled effectively by a fast binary-integer program as in Ref.[80].
Formally,we de fi ne a complete undirected graphG=(V,E)where each vertex inVcorresponds to a mask proposal.Vertices in the same frame are grouped together to form a cluster.Eis the set of edges connecting any two different vertices.Each edgee∈Eis weighted by a score measuring the similarity between the two masks it connects,as detailed in the next paragraph.All vertices in different clusters are connected together.The objective is to pick a set ofKcliques①A clique is a subgraph in which every pair of distinct vertices is connected.that maximize the total similarity score,with the restriction that each clique contains exactly one vertex from each cluster.Each selected clique represents the most coherent tracking of an object across all frames.
Regionsimilarityformasklinking.In our graph-based technique,a score needs to be speci fi ed to measure the similarity between the two masks,and the associated image data.This similarity must be robust to illumination changes,shape deformation,and occlusion.Many previous approaches in multiple object tracking[80,81]have focused on global information of the appearance model,typically the global histogram,or motion information(given by optical fl ow or a simple constant velocity assumption).However,when dealing with large displacements and with an unstable camera,the constant velocity assumption is invalid and optical fl ow estimation is hard to apply.Furthermore,using only global information is insufficient,since our object regions already have similar global appearance.To overcome this challenge,we de fi ne our similarity score as a combination of global and local features.More precisely,each regionRis described by the corresponding maskM,its global HSV histogramsH,a setPof SURF keypoints[82],and a setEof vectors which connect each keypoint with the centroid of the mask.Each region is determined by four elements:R:=(M,H,P,E),wherepiis theith keypoint,whereCis the barycenter ofM.
Then the similarity between two regions is de fi ned as:
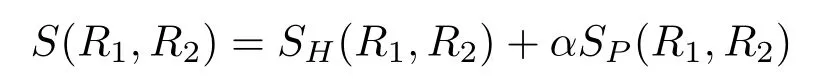
In this expression,SH(R1,R2)=exp(-dc(H1,H2))wheredcis the cosine distance between two HSV histograms which encode global color information,SPis the local similarity computed based on keypoint matching,andαis a balance coefficient to specify the contribution of each component.SPis computed by
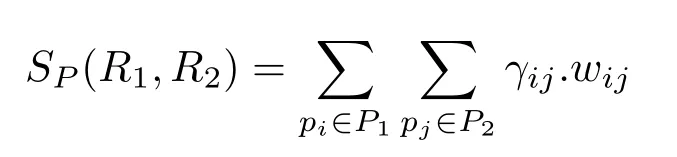
whereγijis the indicator function set to 1 if two keypointspiandpjmatch,and 0 otherwise.This function is weighted bywijbased on the position of the matching keypoints with respect to the centroid of the region:

wheredcis the cosine distance between two vectors andσis a constant.
Post-processing.At this time,we already haveKmasks forKobjects for all frames of the video.Now we perform a post-processing step to ensure that our fi nal mask covers all details of the objects.This is very important in video object removal since any missing detail can cause perceptually annoying artifacts in the object removal result.This postprocessing includes two main steps.
The fi rst step is to give a label for each region in the global foreground mask(the union of all object masks produced by multi-OSVOS for framet)which does not yet have any label.To this end,we proceed as follows.First,we compute the connected componentsCof all masksand try to assign a label to all pixels in each connected component.To do so,we consider the masksthat were obtained for the same framet(and possibly another object classjby the mask linking method).A connected component is considered as isolated ifis empty for allj.For non-isolated components,a label is assigned by a voting scheme based on the ratioi.e.,the assigned label for regionCisthe one with the highest ratio.Ifrj(C)>80%then regionCis also assigned labeljregardless of the voting result,which may lead to multiple labels per pixel.
In the second step,we do a series of morphological operations,namely opening and hole fi lling.Finally we dilate each object mask again with size 9×9,this time allowing overlap between objects.
3.3 Object removal
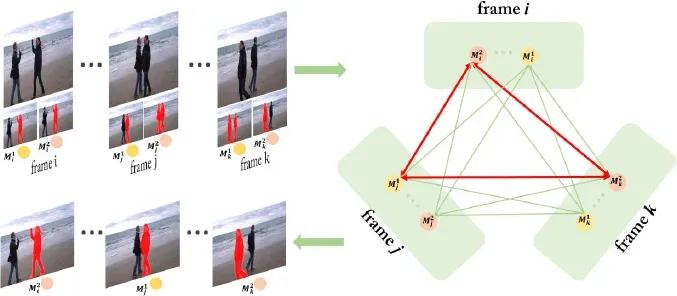
Fig.4 Mask proposals are linked across frames to form a graph.The goal is then to select a clique from this graph minimizing the overall cost.As a result,a best candidate is picked for each frame to ensure that the same physical object is tracked.

Fig.5 Region description.Each region is described by a global histogram,a set of SURF keypoints(yellow points),and a set of vectors which connects each keypoint and the centroid of the region.
After using the method in the previous section,all selected objects have been segmented throughout the complete video sequence.From the corresponding masks,the user can then decide which objects are to be removed.This last step is performed using video inpainting techniques that we now detail.First,we present a simple inpainting method that is used when the background is static(or can be stabilized)and revealed at some point in the sequence.This fi rst method is fast and relies on the reconstruction of a motion fi eld.Then we present a more involved method for the case where the background is moving,with possibly some complex motion as in the case of dynamic textures.
3.3.1Static background
We assume for this fi rst inpainting method that the background is visible at least in some frames(for instance because the object to be removed is moving over a large enough distance).We also assume that the background is rigid and that its motion is only due to camera motion.In this case,the best option for performing inpainting is to copy the visible parts of the background into the missing regions,from either past or future frames.For this,the idea is to rely on a simple optical- fl ow pixel propagation technique.Motion information is used to track the missing pixels and establish a trajectory from the missing region toward the source region.
Overview.Our optical fl ow-based pixel propagation approach is composed of three main steps,as illustrated in Fig.6.After stabilizing the video to compensate for camera movement,we use FlowNet 2.0 to estimate forward and backward optical fl ow fi elds.These optical fl ow fi elds are then inpainted using a classical image inpainting method to fi ll in the missing information.Next,these inpainted motion fi elds are concatenated to create a correspondence map between pixels in the inpainting region and known pixels.Lastly,missing pixels are reconstructed by a copy-paste scheme followed by Poisson blending to reduce artifacts.
Motion fi eld reconstruction.A possible approach to optical fl ow inpainting is smooth interpolation,for instance,in the framework of a variational approach,by ignoring the data term and using only the smoothness term in the missing regions,as proposed in Refs.[56,57]. However,this approach leads to over-smoothed and unreliable optical fl ow.Therefore,we choose to reconstruct the optical fl ow using more sophisticated image inpainting techniques. More speci fi cally we fi rst compute,outside the missing region,forward and backward optical fl ow fi elds between pairs of consecutive frames using the FlowNet approach from Refs.[83].We then rely on the image inpainting method from Ref.[76]to interpolate these motion fi elds.

Fig.6 Global pipeline of the optical fl ow-based propagation approach for reconstructing a static background.From input video(a),forward/backward optical fl ow fi elds are estimated by FlowNet 2.0(b),and then are inpainted by an image inpainting algorithm(c).From these optical fl ow fi elds,pixels from the source region are propagated into the missing region(d).
Optical fl ow-based pixelreconstruction.Once the motion fi eld inside the missing region is fi lled,it is used to propagate pixel values from the fi rst use the image inpainting method from Ref.[76]to complete one keyframe,which is chosen to be the middle frame of the video,and then propagate information from this frame to other frames in the video using forward and backward maps.
Poisson blending.Videos in real life often contain illumination changes,especially if recorded outdoors. This is problematic for our approach that simply copies and pastes pixel values.When illumination ofthe sources differs from the illumination of the restored frame,visible artifacts across the border of the occlusion may appear.A common way to resolve this is to apply a blending technique,e.g.,Poisson blending[77],which fuses source toward the missing regions.For this to be done,we map each pixel in the missing region to a pixel in the source region.This map is obtained by accumulating the optical fl ow fi eld from frame to frame(with bilinear interpolation).We compute both forward and backward optical fl ow,which leads us to two correspondence maps:a forward map and a backward map.From either map,we can reconstruct missing pixels with a simple copy-paste method,using known values outside the missing region.
We perform two passes: fi rst a forward pass using the forward map to reconstruct occlusion,then a backward pass using the backward map. After these two passes,the remaining missing information corresponds to parts that have never been revealed in the video.To reconstruct this information,we a source image and a target image in the gradient domain. However,performing Poisson blending frame-by-frame may affect temporal consistency.To maintain it,we adopt the recent method of Bokov and Vatolin[57]which takes into account information from the previous frame.In this method,a regularizer penalizes discrepancies between the reconstructed colors and corresponding colors in the optical fl owaligned previous frame.More speci fi cally,given the colors of the current and previous inpainted framesIt(p),It-1(p),respectively,the re fi ned Poissonblended imageI(p)can be obtained by minimizing the discretized energy functional[57]:
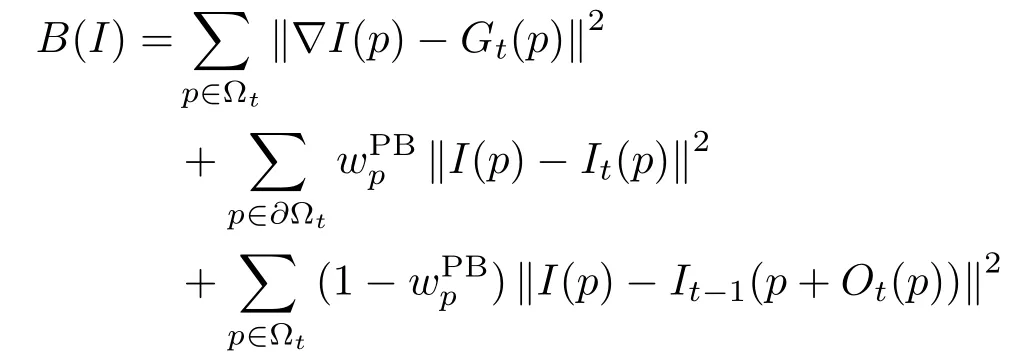
Here,∂Ωtdenotes the outer-boundary pixels of the missing region Ωt,Gt(p)is the target gradient fi eld andOt(p)is the optical fl ow at positionpbetween framest-1 andt.The termsare de fi ned as
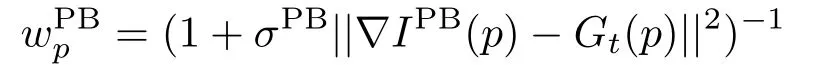
whereIPBis the usual Poisson blended image.They are used to weight the reconstruction results from the previous frameIt-1in the boundary conditions.In this de fi nition,σPBis a constant controling the strength of temporal-consistency enforcement.These weights allow to better handling of global illumination changes while enforcing temporal stability.This Poisson blending technique is applied at every pixel propagation step to support the copy-paste framework.
3.3.2Dynamic background
The simple optical fl ow-based pixel propagation method proposed in Section 3.3.1 can produce plausible results if the video contains only a static background and simple camera motion. More involved methods are needed to deal with large pixel displacements and complex camera movements.They are typically based on joint estimation of optical fl ow and color information inside the occlusion:see for instance Refs.[61,84]. However,when the background is dynamic or contains moving objects,these latter methods often fail to capture oscillatory patterns in the background.In such situations,global patch-based methods are preferred.They rely on minimization of a global energy computed over spacetime patches.This idea was fi rst proposed in Ref.[58],later improved in Ref.[59],and recently improved further in Le et al.[62].
We describe brie fl y the method in Ref.[62].A prior stabilization process is applied to compensate for instabilities due to camera movement(see below for the improvement proposed in the current work).Then a multiscale coarse-to- fi ne scheme is used to compute a solution to the inpainting problem.The general structure of this scheme is that,at each scale of a multiscale pyramid,we alternate until convergence(i)computation of an optimal shift map between pixels in the inpainting domain and pixels outside(using a metric between patches which involves image colors,texture features,and optical fl ow),and(ii)update of image colors inside the inpainting domain(using a weighted average of the values provided by the shift map).A key to the quality of the fi nal result is the coarse initialization of this scheme;it is obtained by progressively fi lling in the inpainting domain(at the coarsest scale)using patch matching and(mapped)neighbors averaged together with a priority term based on optical fl ow.The heavy use of optical fl ow at each scale greatly helps to enforce temporal consistency even in difficult cases such as dynamic backgrounds or complex motions.In particular,the method can reconstruct moving objects even when they interact.The whole method is computationally heavy but the speed is signi fi cantly boosted when all steps are parallelized.
We have recently brought several improvements to this method of Ref.[62]:
Video stabilization.In general,patch-based video inpainting techniques require good video stabilization as a pre-processing step to compensate for patch deformations due to camera motions[85,86].This video stabilization is usually done by calculating a homography between pairs of consecutive frames using keypoint matching followed by an RANSAC algorithm to remove outliers[87].However,large moving objects appearing in the video may reduce the performance of such an approach as too many keypoints may be selected on these objects and prevent the homography from being estimated accurately from the background.This problem can be solved by simply neglecting all segmented objects when computing the homography.This is easy to do:since we already have masks of the selected objects,we just have to remove all keypoints which are covered by masks.This is an advantage of our approach in which both segmentation and inpainting are addressed.
Background and foreground inpainting.In addition to stabilization improvement,multiple segmentation masks are also helpful for inpainting separately the background and the foreground.More precisely,we fi rst inpaint the background neglecting all pixels contained in segmented objects. After that,we inpaint in priority order the segmented objects that we want to keep and which are partially occluded.This increases the quality of the reconstruction,both for the background and for the objects.Furthermore,it reduces the risk of blending segmented objects which are partially occluded because segmented objects have separate labels.In particular,it is extremely helpful when several objects overlap.
We fi nally mention another advantage of our joint tracking/inpainting method:objects are better segmented and thus easier to inpaint,as it is a wellknown fact that the inpainting of a missing domain may be of lower quality if the boundary values are unsuitable.In our case,time continuity of segmented objects and the fact of using different labels for different objects have a huge impact on the quality of the inpainting.
4 Results
We fi rst evaluate our results for the segmentation step of the proposed method.We provide quantitative and visual results,and comparisons with state-of-the-art methods.We then provide several visual results for the complete object removal process,again comparing with the most efficient methods.These visual comparisons are given as isolated frames in the paper;it is of course more informative to see the complete videos in the supplementary material at https://object-removal.telecom-paristech.fr/.We consider various datasets:we use sequences from the DAVIS-2016[7]challenge,and from the MOViC[88]and ObMIC[89]datasets;we also consider classical sequences from Refs.[49]and[59].Finally,we provide several new challenging sequences containing strong appearance changes,motion blur,objects with similar appearance and at times crossing,as well as complex dynamic textures.
Unless otherwise stated,only thefi rstframe is annotated by the user in all experiments.In some examples(e.g.,Camel)not all objects are visible in the fi rst frame and we use another frame for annotation.In a few examples we annotate more than one frame(e.g.,the fi rst and last frame inTeddy bear- fi re and Jumping girl- fi re)in order to illustrate the fl exibility of the system in correcting errors.
4.1 Implementation details
For segmentation,we use the Deeplab v2[74]architecture for the multi-OSVOS and re fi ning networks.We initialize the network using the pretrained model provided by Ref.[74]and then adapt it to video using the training set of DAVIS-2016[69]and thetrain-valset in DAVIS-2017[19](we exclude the validation set of DAVIS-2016).For the data augmentation procedure,we generate 100 pairs of images and ground truth from the fi rst frame annotation,following the same protocol as in Ref.[21].For the patch-based mask propagation and mask linking,we evolved from the implementations of Refs.[71]and[80],respectively.
For the video inpainting step,we use the default parameters from our previous work[62].In particular,the patch size is set to 5,and the number of levels in the multi-scale pyramid is 4.
For a typical sequence with resolution(854×480)and 100 frames,the full computational time is of the order of 45 minutes for segmentation plus 40 minutes for inpainting on an Intel Core i7 CPU with 32 GB of RAM and a GTX 1080 GPU.While this is a limitation of the approach,complete object removal is about one order of magnitude faster than a single completion step from state-of-the-art methods[59,61].While interactive editing is out of reach for now,the computational time allows offline post-processing of sequences.
4.2 Object segmentation
For the proposed object removal system,and as explained in detail above,the most crucial point is that the segmentation masks must completely cover the considered objects,including motion and transition blur.Otherwise,unacceptable artifacts remain after the full object removal procedure(see Fig.13 for an example).In terms of performance evaluation,this means that we favorrecallover
precision,as de fi ned below. This also means that the ground truth provided with classical datasets may not be fully adequate to evaluate segmentation in the context of object removal,because they do not include transition zones induced by,e.g.,motion blur. For this reason,recent video inpainting methods that make use of these databases to avoid the tedious manual selection of objects usually start from adilationof the ground truth. In our case,a dilation is learned by our architecture(smart dilation)during the segmentation step,as explained above.For these reasons,we compare our method with state-of-the-art object segmentation methods,after various dilations and on the dilated versions of the ground truth.We also provide visual results in our supplementary website at https://object-removal.telecom-paristech.fr/.
Evaluation metrics.We brie fl y recall here the evaluation metrics that we use in this work:some of them are the same as in the DAVIS-2016 challenge[7]and we also add other metrics specialized for our task.The goal is to compare the computed segmentation mask(SM)to the ground truth mask(GT).The
recallmetric is de fi ned as the ratio between the area of the intersection between SM and GT,and the area of GT.Theprecisionis the ratio between the area of the intersection and the area of the SM.Finally,the
IoU(intersection over union),or Jaccard index,is de fi ned as the ratio between intersection and union.
Single object segmentation.We use the DAVIS-2016[7]validation set and compare our approach to recent semi-supervised state-of-the-art techniques(SeamSeg[71],ObjectFlow[72],MSK[69],OSVOS[8],and onAVOS[20])using pre-computed segmentation masks provided by the authors.As explained above,we consider a dilated version of the ground truth(using a 15×15 structuring element,as in Refs.[61,62]).Therefore,we apply a dilation of the same size to the masks from all methods.In our case,this dilation has both been learned(size 7×7)and applied as a post-processing step(size 9×9).Since the composition of two dilations with such sizes yields a dilation with size 15×15,the comparison is fair.
Table 1 shows a comparison using the three abovementioned metrics.Our method has the best recall score overall,therefore achieving its objective.The precision score remains very competitive.Besides,our method outperforms OSVOS[8]and MSK[69],those having a similar neural network backbone architecture(VGG16),on all metrics.The precision andIoUscores compare favorably with onAVOS[20]which uses a deeper and more advanced network.Table 2 provides a comparison between OSVOS[8]and our approach on two sequences from Ref.[60].These sequences have been manually segmented by the authors of Ref.[60]for video inpainting purposes.On such extremely conservative segmentation masks(in the sense that they over-detect the object),the advantage of our method is particularly strong.
As a further experiment,we investigate the ability of dilations of various sizes to improve recall without degrading precision too much.For this,we plot precision-recall curves as a function of the structuring element size(ranging from 1 to 30).To include ourmethod on this graph,we start from our original method(highlighted with a green square)and apply to it either erosions with a radius ranging from 1 to 15,or dilation with a radius ranging from 1 to 15.Again this makes sense since our method has learned a dilation whose equivalent radius is 15.Results are displayed in Fig.8.As can be seen,our method is the best in terms of recall,and recall increases signi fi cantly with dilation size.With the sophisticated onAVOS method,on the other hand,recall increases slowly,while precision drops drastically,as dilation size increases.Basically,these experiments show that the performance achieved by our system for the full coverage of a single object(that is,with as few missed pixels as possible)cannot be obtained from state-of-the-art object segmentation methods by using simple dilation techniques.
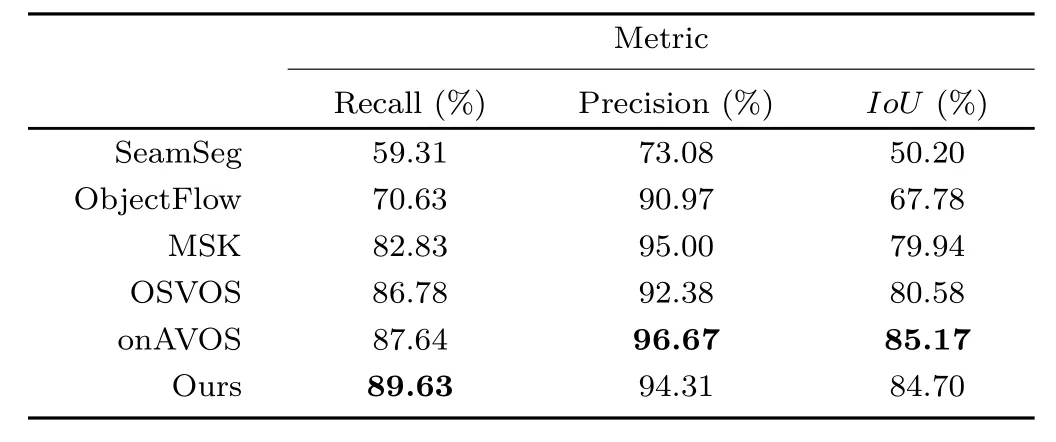
Table 1 Quantitative comparison of our object segmentation method to other state-of-the-art methods,on the single object DAVIS-2016[7]validation set.The main objective when performing object removal is to achieve high recall scores

Table 2 Quantitative comparison of our object segmentation method and the OSVOS segmentation method[8],on two sequences manually segmented for inpainting purposes[60]
Multiple object segmentation.Next,we perform the same experiments for datasets containing videos with multiple objects.Since thetestground truth was not yet available(at the time of writing)for the DAVIS-2017 dataset and since our network was trained on thetrain-valset of this dataset,we consider two other datasets:MOViCs[88]and ObMIC[89].They include multiple objects,but only have one label per sequence. To evaluate multiple object situations,we only kept sequences containing more than one object,and then manually re-annotated the ground truth giving different labels for different instances.Observe that these datasets contain several major difficulties such as large camera displacements,motion blur,similar appearances,and crossing objects.Results are summarized in Table 3.Roughly the same conclusions can be drawn as inthe single object case,namely the superiority of our method in term of recall,without much sacri fi ce of precision.
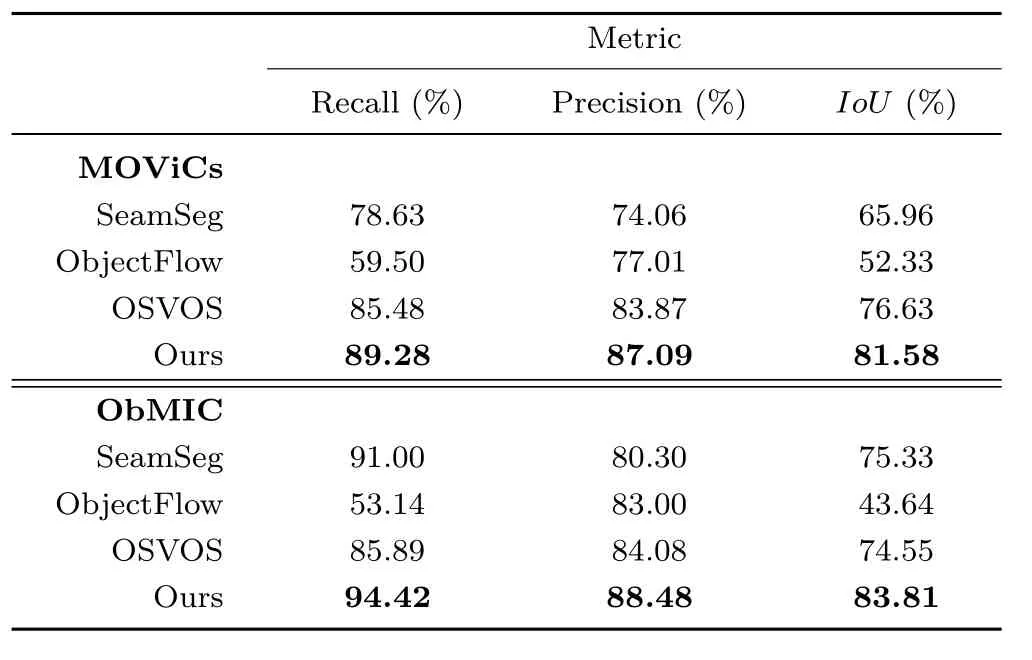
Table 3 Quantitative comparison of our object segmentation method and other state-of-the-art methods,on two multiple objects datasets(MOVICs[88]and ObMIC[89])
Some qualitative results of our video segmentation technique are shown in Fig.7.In the fi rst two rows,we show some frames corresponding to the single object case,on the DAVIS-2016 dataset[7].The last three rows show multiple object segmentation results on MOViCs[88],ObMIC[89],and Granados’s sequences[49]respectively. On these examples,our approach yields full object coverage,even with complex motion and motion blur.This is particularly noticeable on the sequencesKite-surfandParaglidinglaunch.In the multiple object cases,the examples illustrate the capacity of our method to deal with complex occlusions.This cannot be achieved with mask tracking methods such as objectFlow[72]or SeamSeg[71].The OSVOS method[8]leads to some confusion of objects,probably because temporal continuity is not taken into account by this approach.
4.3 Object removal
Next,we evaluate the complete object removal pipeline.We consider both inpainting versions that we have introduced.We use the simple,optical lf ow-based method introduced in Section 3.3.1 for sequences having static backgrounds.We refer to this fast method as thestatic version.We use the more complex method derived from Ref.[62]and detailed in Section 3.3.2 for more involved sequences,exhibiting challenging situations such as dynamic backgrounds,camera instability,complex motions,and crossing objects.We refer to this second slower version as thedynamic version.
In Fig.9,we display examples of both single and multipleobjectremoval,through several representative frames. The video results can be fully viewed in the supplementary website.The fi rst sequenceBlackswan(DAVIS-2016)shows that our method(dynamic version)can plausibly reproduce dynamic textures.In the second sequenceCows(DAVIS-2016),the method yields good results,with a stable background and continuity of the geometrical structures,despite a large occlusion implying that some regions are covered throughout the sequence.We then turn to the case of multiple object removal.In the sequenceCamel(DAVIS-2017),we show the removal of one static object,a challenging case since the background information is missing in places.In this example,the direct use of the inpainting method from Ref.[62]results in some undesired artifacts when the second camel enters the occlusion.By using multiple object segmentation masks to separate background and foreground,we can create a much more stable background.The last two examples are from an original video.This sequence again highlights that our method can deal with dynamic textures and hand-held cameras.

Fig.7 Visual comparison of different segmentation approaches.Left to right:original,SeamSeg[71],ObjectFlow[72],OSVOS[8],ours.
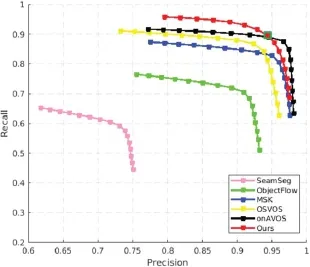
Fig.8 Precision-recall curves for different methods with different dilation sizes.
Comparison with state-of-the-art inpainting methods.In these experiments,we compare our results with two state-of-the-art video inpainting methods[59,61].

Fig.9 Results from our object removal system.
First,we provide a visual comparison between our optical fl ow-based pixel propagation method(the static approach)with the method of Huang et al.[61]using a video with a static background.Figure 10 shows some representative frames of the sequenceHorse-jump-high.In this sequence,we achieve a comparable result using our simple optical fl ow-based pixel propagation approach.Our advantage is the considerable reduction of computational time.With an unoptimized version of the code,our method takes approximately 30 minutes to fi nish while the method in Ref.[61]takes about 3 hours to complete this sequence.
Next,we qualitatively compare our method with Ref.[61]when reconstructing dynamic backgrounds.We use the code released by the author on several sequences using the default parameters.In general,Huang et al.[61]fail to generate convincing dynamic textures.This can be explained by the fact that their algorithm relies on dense fl ow fi elds to guide completion,and these fi elds are often unreliable for dynamic texture.Moreover,they fi ll the hole by sampling only 2D patches from the source regions and therefore the periodic repetition of the background is not captured.Our method,on the other hand,fills the missing dynamic textures in a plausible way.Figure 11 shows representative frames of the reconstructed sequenceTeddy-bear,which is recorded indoors.This sequence is especially challenging because of the presence of both dynamic and static textures,as well as illumination changes.Our method yields a convincing reconstruction of the fi re,unlike the one in Ref.[61].The complete video can be seen in the supplemental material website.

Fig.10 Qualitative comparison with Huang et al.’s method[61].Top to bottom:our segmentation mask,result from Ref.[61]using a manually segmented mask,our inpainting results using our mask.

Fig.11 Qualitative comparison with Huang et al.’s method[61]on video with a dynamic background.Left to right:our segmentation mask,result from Ref.[61],our inpainting result performed on our mask.

Fig.12 Qualitative comparison with Newson et al.’s method[59].Top:our segmentation masks;red and green masks denote different objects,and yellow shows the overlap region between two objects.Middle:results from Ref.[59]performed on our segmentation masks.Bottom:our inpainting results performed on the same masks.
We also compare our results with the video inpainting technique from Ref.[59].Figure 12 shows some representative frames of the sequenceParkcomplex,which is taken from Ref.[60]and modi fi ed to focus on the moment when objects occlude each other.In this example,the method of Ref.[59]cannot reconstruct the moving man on the right which is occluded by the man on the left.This is because the background behind this man changes over time(from tree to wall).Since Newson et al.’s method[59]treats the background and the foreground similarly,the algorithm can not reconstruct the situation “man in front of the wall”because it has never seen this situation before.Our method,by making use of the optical fl ow and thanks to the object segmentation map,can reconstruct the “man”and the “wall”independently,yielding a plausible reconstruction.
Impact of segmentation masks on inpainting performances.In these experiments,we highlight the advantages of using the segmentation masks of multiple objects to improve the video inpainting results.
First,we emphasize the need for masks which fully cover the objects to be removed.Figure 13(top)demonstrates the situation in which some object details(the waving hand in this case)are not covered by the mask(here using the state-of-the-art OSVOS method)[8].This situation leads to a very unpleasant artifact when video inpainting is performed.Thanks to the smart dilation,introduced in the previous sections,our segmentation mask fully covers the object to be removed,yielding a more plausible video after inpainting.
Object segmentation masks can also be helpful for the video stabilization step. Indeed,in the case of large foregrounds,these can have a strong effect on the stabilization procedure,yielding a bad stabilization of the background,which in turn yields bad inpainting results.In contrast,if stabilization is applied only to the background,the fi nal object removal results are much better.This situation is illustrated in the supplementary material.
To further investigate the advantage of using multiple segmentation masks to separate background and foreground in the video completion algorithm,we compare our method with direct application of the inpainting method from Ref.[62],without separating objectsand background.Representativeframes ofboth approaches are shown in Fig.14.Clearly,the method in Ref.[62]produces artifacts when the moving objects(the two characters)overlap the occlusion,due to patches from these moving objects being propagated within the occlusion in the nearest neighbor search step.Our method,on the other hand,does not suffer from this problem because we reconstruct background and moving objects separately.This way,the background is more stable,and the moving objects are well reconstructed.
5 Conclusions,limitations,and discussion

Fig.13 Results of object removal using masks computed by OSVOS(top)and our method(bottom).Left to right:segmentation mask,resulting object removal in one frame,zooms.When the segmentation masks do not fully cover the object(OSVOS),the resulting video contains visible artifacts(the hand of the man remains after object removal).

Fig.14 Advantage of using segmentation masks to separate background and foreground.Left:without separation,the result has many artifacts.Right:the background and foreground are well reconstructed when reconstructed independently.
In this paper,we have provided a full system for performing object removal from video.The input of the system comprises a few strokes provided by the user to indicate the objects to be removed.To the best of our knowledge,this is the fi rst system of this kind,even though the Adobe company has recently announced it is developing such a tool,under the nameCloak.The approach can deal with multiple,possibly crossing objects,and can reproduce complex motions and dynamic textures.
Although our method achieves good visual results on different datasets,it still suffers from a few limitations.First,parts of objects to be edited may be ignored by the segmentation masks.In such cases,as already emphasized,the inpainting step of the algorithm will amplify the remaining parts,creating strong artifacts.This is an intrinsic problem of the semi-supervised object removal approach and room remains for further improvement.Further,the system is still relatively slow,and in any case far from real time.Accelerating the system could allow for interactive scenarios where the user can gradually correct the segmentation-inpainting loop.
The segmentation of shadows is still not fl awlessly performed by our system,especially when the shadows lack contrast.It is a desirable property of the system to be able to deal with such cases.This problem can be seen in several examples provided in the supplementary material.
Concerning the inpainting module,the user has to currently choose between the fast motion-based version(which works better for static backgrounds)and the slower patch-based version which is required in the presence of complex dynamic backgrounds.An integrated method that reunites the advantages of both would be preferable.Huang et al.’s method[61]makes a nice attempt in this direction,but its use of 2D patches is insufficient to correctly inpaint complex dynamic textures,which are more plausibly inpainted by our 3D patch-based method.
Another limitation occurs in some cases where the background is not revealed,speci fi cally when semantic information should be used.Such difficult cases are gradually being solved for single images by using CNN-based inpainting schemes[64].While the training step of such methods is still out of reach for videos as of today,developing an object removal scheme fully relying on neural networks is an exciting research direction.
Acknowledgements
We gratefully acknowledge the support of NVIDIA who donated a Titan Xp GPU used for this research.This work was funded by the French Research Agency(ANR)under Grant No.ANR-14-CE27-001(MIRIAM).
Open AccessThis article is licensed under a Creative Commons Attribution 4.0 International License,which permits use,sharing,adaptation,distribution and reproduction in any medium or format,as long as you give appropriate credit to the original author(s)and the source,provide a link to the Creative Commons licence,and indicate if changes were made.
The images or other third party material in this article are included in the article’s Creative Commons licence,unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use,you will need to obtain permission directly from the copyright holder.
To view a copy ofthis licence, visit http://creativecommons.org/licenses/by/4.0/.
Other papers from this open access journal are available free of charge from http://www.springer.com/journal/41095.To submit a manuscript,please go to https://www.editorialmanager.com/cvmj.
杂志排行

Computational Visual Media的其它文章
- Single image shadow removal by optimization using non-shadow anchor values
- Automatic route planning for GPS art generation
- Manufacturable pattern collage along a boundary
- Fast raycasting using a compound deep image for virtual point light range determination
- Deep residual learning for denoising Monte Carlo renderings
- Unsupervised natural image patch learning