移动群智感知中基于深度强化学习的位置隐私保护策略
2019-02-15胡煜家白光伟顾一鸣
胡煜家,白光伟,沈 航,3,顾一鸣
1(南京工业大学 计算机科学与技术学院,南京 211816) 2(南京大学 计算机软件新技术国家重点实验室,南京 210093) 3(南京邮电大学 通信与网络技术国家工程研究中心,南京 210003)
1 引 言
随着物联网的发展,智能手机、平板电脑、可穿戴设备、车载感知设备等移动终端集成了越来越多的传感器,公众拥有越来越强大的计算、感知、存储和通信能力.通过一些激励措施合理利用这些能力,可以廉价、高效的解决许多环境感知问题,这种思想被称为群智感知(Crowd Sensing)[1].
群智感知应用通过发布感知任务,激励用户感知数据,再对这些数据进行分析和使用.然而,这种新的数据采集方式也带来了新的隐私问题.一旦用户完成了某个感知任务,群智感知服务商就可以推测出该任务采集时段用户出现在这个任务的数据采集范围内,从而利用用户完成任务的轨迹掌握用户的行为模式.而当用户的隐私受到威胁时,用户会失去参与群智感知应用的积极主动性.
传统的位置隐私保护技术包括空间隐匿[2,3]、位置偏移和模糊[4,5]、伪造虚假位置[6]等,但是这些技术需要伪造或者修改数据采集位置或时间,会影响群智感知任务数据的可用性.现有的群智感知环境下的隐私保护技术主要依赖k-匿名等方式泛化采集数据的用户,然而群智感知激励机制需要奖励任务的完成者,用户被泛化后会影响激励机制的运作.
针对群智感知环境,本文设计了一种泛化任务的隐私保护策略,避免了隐私保护机制对激励机制的影响.为了保证数据的可用性,混淆任务采用其他用户完成的真实任务,当没有足够的用户参与泛化时,系统不能满足k-匿名的隐私保护需求,则采取抑制法放弃该任务.用户连续提交感知任务时,不同的泛化任务集合会影响下一次任务被抑制的可能性.为了降低抑制率,本文提出使用一种深度强化学习算法,不断尝试不同的混淆任务组合,训练一个可以输出最低抑制率的混淆任务选择方案的深度Q网络,利用这个网络对混淆任务选择进行决策.实验结果表明本文的隐私保护策略在不破坏感知任务有效性的前提下,以较低的抑制率保护了用户的位置隐私.
文章结构安排如下:第2节介绍了本文的研究问题和现有研究的不足;第3节描述了群智感知任务的特性,并针对这些特性提出了本文隐私保护策略的系统模型;第4节分析了最小化抑制率的任务决策问题;第5节提出将该问题转化为一个MDP模型,并使用DQN算法求解;第6节是实验和结果分析;最后,总结全文并展望下一步工作.
2 相关工作
通常群智感知服务器发布的任务对时间和位置都是敏感的.如:现有一个群智感知任务,需要感知某居住区晚上10点的噪声数据.用户上传该地区9点的噪声数据或者邻近地区的噪声数据都是无效的.而传统的隐私保护技术常常通过扭曲时间或者泛化位置来保护用户的隐私,在群智感知环境下这些方法将破坏数据的有效性.因此面对群智感知任务的时间敏感性和位置敏感性,如何在不破坏任务数据的可用性的前提下保护用户的隐私是一个亟待解决的问题.
常见的针对群智感知环境的隐私保护技术主要包括混淆区技术、第三方匿名技术、k-匿名技术和抑制技术等.
文献[7]让用户可以个性化的设置隐私需求,然后通过混淆算法根据用户的隐私需求随机扩展一个混淆区发送感知数据.该方法在用户连续提交感知数据时容易遭到位置推断攻击,并且由于感知任务的位置敏感性,发送一个混淆区的感知数据会造成数据失效.
文献[8]通过第三方匿名服务器对任务和自己的特征数据进行随机数匿名绑定,服务器对上传的感知数据做相似度计算并反馈信誉值.使得服务器无法同时获取用户的特征信息和感知信息,又通过信誉限定了用户的行为.但是增加了通信的开销和第三方服务器泄漏隐私的风险.
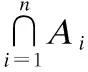
文献[10]采用抑制法,切断用户位置和时间的关联性来保护用户的轨迹隐私.该方法从用户完成的n个任务中选择k个,以乱序组合的方式上传给服务器.虽然保护了用户的轨迹隐私,但是感知数据和时间失去了关联性,数据也就没有了意义.并且该方法无论什么情况都需要抑制n-k份感知数据,也会造成了服务质量的下降.
以上策略虽然保护了用户在群智感知环境下的位置隐私,但是没有兼顾群智感知任务数据的可用性和激励机制的运作.针对相关缺陷,本文提出了一种基于深度强化学习算法的隐私保护策略.
3 任务特性和系统模型
本节详细介绍了群智感知任务的特性,以及针对这些特性提出的隐私保护策略的系统模型.
3.1 任务特性
群智感知任务具有真实性、位置敏感性、时间敏感性和延迟容忍性4个特性.
·真实性:群智感知任务采集的数据必须是真实有效的.
·位置敏感性:数据的产生位置是其重要属性,用户只能在群智感知任务要求的位置附近感知数据.位置敏感性越强的任务采集范围越小.
·时间敏感性:数据和其产生时间是紧密相连的,不同的任务对数据的时间敏感性不同.群智感知任务要求用户在一定的感知时段内完成,这个感知时段的粒度就是根据时间敏感性设置的.
·延迟容忍性:大部分群智感知任务只对数据的产生时间敏感,对数据的使用时间不敏感,即群智感知任务是允许延迟提交的.不同类型的任务有不同的延迟容忍性,允许延迟提交的时长不同.
3.2 系统模型
本文的总体系统模型主要包括3个交互主题:移动用户、匿名服务器和群智感知服务器.如图1所示.
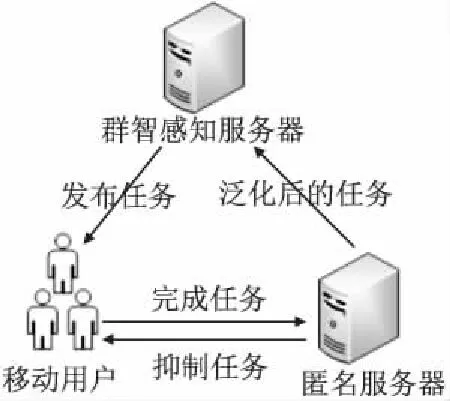
图1 系统整体框架Fig.1 System framework
·移动用户:移动用户u是群智感知任务的完成者.他们接受群智感知服务器发布的任务,在规定的感知时段t1内前往任务位置l,感知数据任务数据d后,将任务Task={u,d,l,t1}发送给匿名服务器.
·匿名服务器:匿名服务器是用户隐私的保护者.当接受到移动用户完成的任务后,匿名服务器将任务数据存储至任务提交时限前的最后一个感知时段tn(即tn时段结束后t1时段采集的数据将可能失效).选择t1时段内其他k-1个用户完成的任务组成匿名数据集合S={〈d1,l1〉,〈d2,l2〉,…,〈dn,ln〉},将用户u完成的任务数据Task′={u,d,l,t1}泛化为Task′={u,S,t1},转发给群智感知服务器,如果该任务的感知时段t1没有足够的候选混淆任务,则抑制此任务并通知用户.匿名服务器通过泛化任务,使群智感知服务器无法分辨用户u完成了k个任务中的哪一个,实现了k-匿名隐私保护要求.
·群智感知服务器:群智感知服务器是感知数据的消费者,负责发布任务给移动用户.其发布的每个任务包括如下数据:数据类型Type(如:温度、气压、速度等);数据感知范围l,范围的大小根据位置敏感性定义;数据感知时段t1,时段的长度根据时间敏感性定义;提交时限tn,该时段是根据延迟容忍性定义的.群智感知服务器只需要在tn+1时段之前将{d,l,t1}从泛化后的任务数据集S提取出来,并根据激励机制奖励用户u,不需要关注具体哪个任务数据是由哪个用户采集的,也不需要用户完成任务后立即提交数据.
4 最小化抑制率的任务决策问题
在本文的隐私保护机制中如果没有足够的候选混淆任务,目标任务将会被抑制,过高的抑制率会降低用户参与群智感知应用的积极性,也会影响群智感知服务器收集数据的效率.如何在k-匿名的隐私保护要求下,尽量降低抑制率是一个核心问题.
4.1 任务抑制分析
想要降低化抑制率,首先要明确什么情况下需要对任务的提交进行抑制,本节总结了3种需要抑制任务的情况:
1) 任务的感知时段少于k-1个其他用户感知数据.此时完成任务的用户太少,没有足够的用户协作来泛化任务,需要群智感知服务器利用适当的激励机制[12-14]提高用户的参与率.
2) 由于用户连续完成任务时,具有背景知识的攻击者可以结合用户上一次和下一次完成的任务进行分析,利用最大移动速度攻击模型[15],排除大量混淆任务,从而破坏k-匿名.因此并不是相同感知时段的所有其他任务都是有效混淆任务,当有效混淆任务不足k-1个时任务应该被抑制.
3) 有效的混淆任务不少于k-1个,根据最大移动速度攻击分析用户的泛化任务集合可知每一次任务的提交和混淆任务的选择都会影响下一次任务的有效混淆任务数量.所以如果提交某个任务,可能导致之后多次任务的混淆任务数变少,从而整体抑制率大大提高,也应该抑制此任务.
4.2 匿名集和候选集
上一节看出任务是否需要抑制与有效混淆任务和泛化后的任务集合息息相关.我们将有效混淆任务的集合定义为候选集,泛化后的任务集合定义为候选集.为了方便计算,下文用任务位置l表示对应的任务,具体的定义如下:
定义1. (候选集)对于任意li∈Ci,与用户u在ti时段完成的任务lu,i无法区分,则称Ci为用户u在ti时段的候选集.
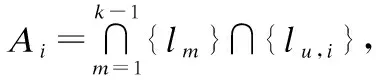
当候选集Ci中的任务位置少于k-1个时,匿名集Ai无法包含k-1个混淆任务位置,则抑制任务.我们将抑制率、候选集和匿名集之间的关系表示为:
Minimize:μ=P(|Ci|≤k-1)
(1)
Subject to: |Ai|=k
(2)
匿名集的选取会影响下一时段的候选集,最小化抑制率的问题就转化为:选择一个匿名集A1.使得可能的候选集序列C1,C2,…,Cn中小于k-1个混淆任务的候选集最少.本节详细介绍了候选集和匿名集的关系和计算方法.
4.2.1 候选集
因为群智感知任务具有真实性、时间敏感性、位置敏感性,所以候选集中的混淆任务不能使用假数据或者历史数据,只能采用其他用户在同一感知时段ti采集的真实数据.考虑到最大移动速度攻击等攻击模型,要让候选集中的任务与目标用户u0完成的任务无法区分,并不是所有ti完成的任务都能够起到混淆的效果,所以有效的候选集Ci的计算需要考虑上一时段的匿名集Ai-1,和用户u0下一时段ti+1完成的任务的任务位置lu,i+1.
tn是用户u0在t1时段完成的任务的提交时限.
当n=1时,说明在任务提交时限前用户只完成了一个任务,不需要考虑用户连续提交任务时的轨迹隐私.因此除了目标用户自己完成的任务外,所有t1时段完成的任务都可以作为混淆任务加入候选集.公式(3)计算了n=1情况的候选集,其中L1表示t1时段所有用户的任务位置集合,候选集中不能包括目标用户u0的任务.
C1=L1/{lu0,1}
(3)
n≥2时,需要保护用户的轨迹隐私.候选集Ci根据i的不同计算公式不同.
当i=1时,说明用户刚刚开始提交任务,只需要保证候选集内的任务都可以抵达该用户t2时段用户u0完成的真实任务位置即可.这种情况的候选集通过公式(4)计算,其中函数L(l,r,t)表示以位置l为圆心,r为半径的圆形区域内所有用户在t时段的任务集合.公式(4)中,圆心位置是用户u0在t2时段完成的真实任务的位置,半径是用户在t1到t2期间移动的最大距离,混淆任务的时段是t1.
C1=L(lu0,2,vm×(t2-t1),t1)/{Iu0,1}
(4)
当i=2,3,…,n-1时,合理的候选集Ci必须保证ti-1时段的匿名集Ai-1内的所有任务从ti-1时段开始以用户的最大移动速度Vm移动,可以在ti时段内到达Ci内任意混淆任务位置.还要保证以Ci内的混淆任务位置为起点,可以在ti+1时段内到达用户该时段完成的真实任务的位置lu,i+1.公式(5)计算了这种情况下的候选集,其中luj,i-1∈Ai-1.
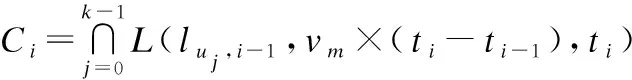
(5)
当i=n时,没有ti+1时段的任务需要保证可达性了,所以只需要考虑匿名集Ai-1内的混淆任务与候选集Cn的可达性即可.公式(6)计算了这种情况的候选集,其中luj,n-1∈An-1.
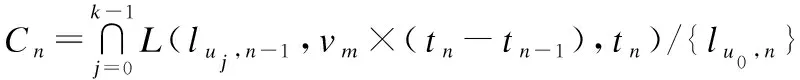
(6)
4.2.2 匿名集
用户u0在ti时段的匿名集Ai是在Ci中选择k-1个混淆任务位置再加上该用户自己的任务位置组成,如公式(7)所示,其中lm∈Ci.
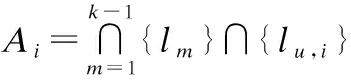
(7)
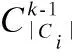
4.3 复杂度分析
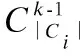
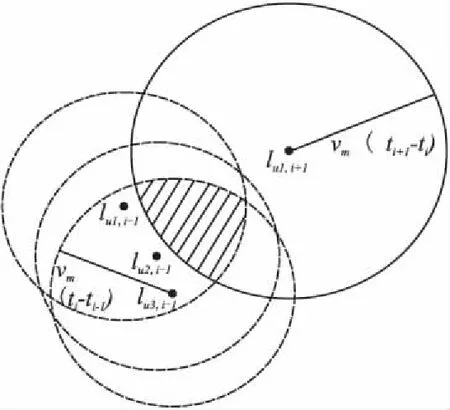
图2 候选集范围Fig.2 Candidate set range
5 基于深度强化学习的任务决策方案
本文采用了一种深度强化学习[11]的方法来解决最小化抑制率的任务决策问题.深度强化学习是一种将深度学习与强化学习结合起来的机器学习方法,其思想是通过智能体不断重复访问任意状态,尝试不同的动作来更新一个神经网络,最终神经网络可以拟合一个动作-回报函数,根据智能体的当前状态输出一个逼近最优回报的动作.深度强化学习的基本框架如图3所示.
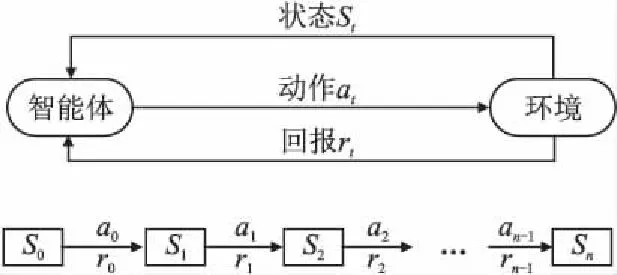
图3 深度强化学习基本框架Fig.3 The basic framework of deep reinforcement learning
5.1 任务决策问题的MDP化
马尔可夫决策过程是指导智能体在随机系统需要同时考虑系统的确定性(系统当前的各种状态)与不确定性(系统未来可能的状态)时做出最优化决策.匿名服务器选取匿名集的过程可以看作是一个马尔科夫决策过程.马尔科夫决策过程是一个五元组M=(S,A,P,R,γ),其中S为状态、A为动作、P为状态转移函数、R为回报、γ为折扣因子.
本文的模型中匿名服务器是智能体,所有群智感知任务的集合就是环境.
每一个候选集Ci为一个状态si.
在候选集Ci中选取匿名集就是可以对si产生的动作ai.
系统从某状态si下执行动作ai,m将转移到未来状态si+1,m.因为候选集可以通过匿名集计算,所以我们的状态转移不是随机产生的,只是在选择之前是不确定的,满足公式(8),具有马尔科夫性,即系统的下一个状态只和当前状态与当前采取的动作有关,与之前的状态无关.
P(Ci+1|C1,A1,C2,A2,…,Ci,Ai)=P(Ci+1|Ci,Ai)
(8)
回报函数R表示当前选择的回报.公式(9)计算了用户u在当前状态si下,经过某个动作ai到达状态si+1的回报值.
R=(1-μ)+δ|sn|
(9)
其中μ是用户u从t1到tn的最小抑制率,μ越小回报越高.由于系统无法在选择ti时段的匿名集时知道ti到tn的时段的任务是否被抑制,所以公式(9)只能计算任务时段为tn的状态的回报值,其余状态的回报都设为0.δ是常数,|sn|表示最后一个状态表示的候选集|Cn|的大小,一般来说当前状态候选集越大,下一状态的选择余地也就越大,系统执行下一次动作时被抑制的可能性也越低,当两种选择抑制率相同时,未来被抑制的概率低的选择价值更高.本文中应该优先比较的是抑制率μ,所以δ是一个很小的值,保证只有当μ相等时比较|sn|才有意义.
折扣因子γ∈[0,1]表示当前回报和未来回报之间的差异.在本文的研究中当前回报指当前任务是否抑制,未来回报指整体抑制率,显然整体抑制率更加重要.
将匿名集的选择过程转化为MDP模型后,选择最低抑制率的匿名集的问题就形式化为:求从当前状态抵达最大回报值的状态转移方案了.问题形式化如下:
Maximize:R=(1-μ)+δ|sn,j|
(10)
(11)
(12)
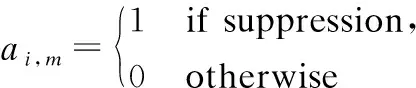
(13)
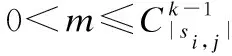
(14)
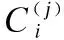
5.2 基于DQN的抑制率优化算法
Q学习(Q-learning)算法[17]是求解马尔科夫决策问题的一种有效的强化学习方法.它通过状态到动作的映射学习,使得智能体采取最优的策略获得最大回报值.
智能体首先根据回报值,创建一个回报矩阵R,其列为状态,行为动作,值为回报值.tn时段的状态的回报值可以通过公式(9)计算,其他可达状态之间的回报值为0,不可达状态的回报值为-1.随后智能体构建一个和回报矩阵R同阶的决策矩阵Q,作为决策表.刚开始智能体对外界一无所知,所以决策矩阵Q初始化为一个零矩阵,Q-learning算法通过如下公式不断更新Q矩阵:
(15)
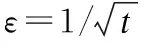
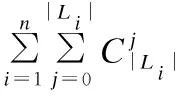
Q(s,a;θ)≈Q*(s,a)
(16)
Q-Network的训练就是最优化一个损失函数.损失函数就是标签和网络输出的偏差,目标是让损失函数最小化.通过大量的标签数据,再使用梯度下降的方法反向传播(BackPropagation)来更新Q-Network的参数.我们的目标是让Q-Network的Q值趋近于最优Q值,因此使用Q值作为标签,Q值的均方差作为损失函数.
L(θ)=E[(yi-Q(s,a;θi))2]
(17)
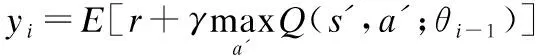
令损失函数沿梯度方向下降,通过下式计算参数θ关于损失函数的梯度.
(18)
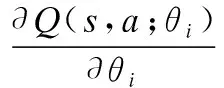
由于本文的(st,at,rt,st+1)是一个时间相关的序列,样本具有连续性,如果每次得到样本就更新Q值会受样本分布影响,效果不好.因此本文使用DQN训练时采取经验回放(Experience replay)技术,将Agent得到的数据存储起来,然后随机采样,来打破数据之间的关联.采用经验回放的基于DQN的抑制率优化算法描述如下:
输入:L1,L2,…,Ln
输出:A1
Begin
Step1.设置神经网络的各项参数
Step3.初始化用户u在t1时段的候选集C1为状态s1
Step4.forepisode←1 to M
Step5. 根据策略选择一个动作ai
Step6. 执行该动作ai,获得回报r.
Step7. 保存(st,at,rt,st+1)到经验回放池D
Step8.iflen(D)>OBSERVERthen
Step9. 从D中抽取一部分数据作为训练样本
Step10. 利用训练样本获得目标Q值
Step11. 使用目标Q值和当前Q值更新Q网络
endif
endfor
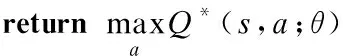
End
该算法输入t1到tn时段内所有用户完成的任务集合.输出目标用户u在t1时段的预期抑制率最低的匿名集A1.
步骤1中,初始化了Q网络的参数向量θ,回报矩阵R,折扣因子γ,学习率α,训练次数M,观察值OBSERVER,抽取样本数minibatch,并声明一个经验回放池D.
步骤2中,初始化了一个参数向量为θ的状态-动作对应回报的函数作为Q网络,在训练开始之前所有状态-动作的回报为0.
步骤3中,根据第3章介绍的公式计算出候选集,作为DQN算法中的状态.计算候选集需要计算用户真实任务位置和该时段所有的混淆任务位置之间的距离,其时间复杂度为O(n).
步骤4-11是一个循环体,循环次数为训练次数M.在循环体中,步骤5根据ε-greedy policy策略选择动作;步骤6,模拟执行选择的动作,获得回报;步骤7,将当前状态,选中的动作,执行该动作产生的回报保存到经验回放池中;步骤8,判断经验回放池中的数据是否达观察者,如果到达观察只则开始训练Q网络;步骤9-10,随机从经验回放池中抽取minibatch个数据记录每个样本的回报作为目标Q值.步骤11,计算了Q网络的输出值和目标Q值之间的损失函数,并使用SGD算法更新Q网络的参数向量θ,使其毕竟目标Q值.整个循环的时间复杂度为O(M×minibatch).
步骤12中,返回Q网络中当前状态为目标用户t1时段完成的任务的候选集的情况下回报值最大的动作,该动作就是匿名服务器选择的任务匿名集A1.选出最大回报值的动作需要遍历Q网络中s1状态的所有回报值,所以其时间复杂度为O(n).
综上所述,因为步骤3中的n一般不会超过20,所以步骤3的复杂度无需考虑,本文提出的基于DQN的抑制率优化算法的总体时间复杂度为O(M×minibatch×n).
6 实验与结果分析
我们采用公开的GeoLife GPS Trajectories进行实验,这个GPS轨迹数据集由微软亚洲研究院的Geolife项目采集,记录了182个用户3年的轨迹信息.下面将介绍实验环境和参数设置,然后针对实验结果进行分析.
我们在一台配置为Intel Core i7 4790处理器,4核8线程,主频为3.6GHz;1080Ti显卡,显存为11GB,显存频率为11100MHz;16GB RAM;128GB固态硬盘(SSD)的主机上运行Ubuntu16.04系统,使用python语言,借助tensorflow和numpy等库进行编程.首先对数据进行了处理,选择了100个用户在特定范围内的数据,并随机分配了一些群智感知任务.群智感知任务均匀分布在正方形区域内,假设用户在任务时间段内移动到任务位置附近,以一定概率完成任务.为了提高实验数据的参考价值,我们每个实验重复运行五次,取平均值,保证实验结果具有一般性.为了体现本文方案的优越性,当需要对照实验时,我们采用了最常见的泛化用户的隐私保护方案选取用户的方式来选取任务作为Baseline与本文的DQN算法进行对照.
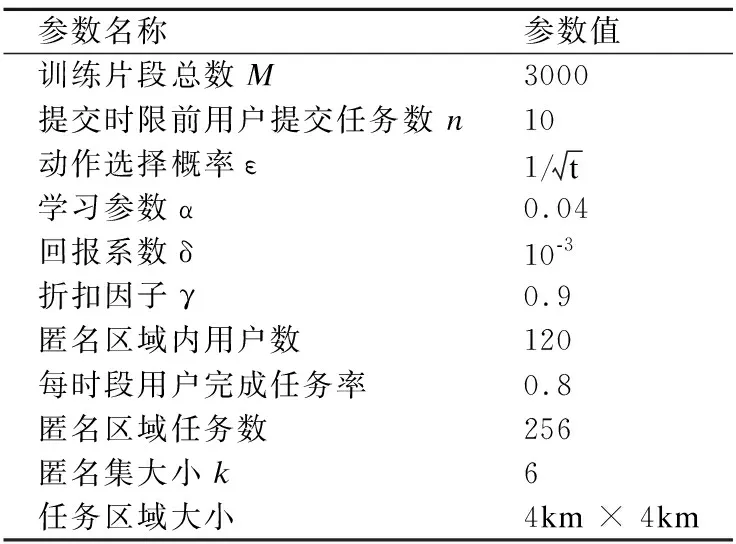
表1 实验参数设置Table 1 Experimental parameters
6.1 Q网络参数调试实验
本文采用的DQN算法降低抑制率需要创建一个神经网络,并使用该网络来替换掉传统Q-learning中的Q值表.我们采用tensorflow库创建了一个三层的神经网络.下面介绍Q网络的参数调试实验.
图4(a)是不同学习率下任务抑制率的箱形图.可以看出当学习率大于0.04时不能稳定收敛于较低的抑制率,并且异常值较多.分析原因是当学习率过高时,算法过多依赖于过往的经验,探索未选择过的匿名集的概率大大降低,容易进入局部收敛.因此根据实验结果,为了使抑制率不陷入局部收敛的前提下减少训练次数,提高计算速度,我们选择了0.04作为本文环境下的学习率.
图4(b)表示在学习率为0.04的条件下,训练次数对平均回报值的影响.其中OPT values是通过暴力穷举得出的最优决策下的抑制率,实际情况中穷举法时间复杂度过高计算速度过慢是无法获得的.根据回报值的公式可知,平均回报值越高,最终抑制率越低,服务质量越好.实验结果表明,样本数据训练次数达到3000次后回报值趋于收敛,并非常接近最优解.因此学习率为0.04时训练约3000次可以计算出接近最优抑制率的匿名集.

图4 Q网络相关参数间关系Fig.4 Parameters relationships on Q-network
6.2 用户数量对抑制率的影响
用户数量是影响群智感知应用运作的基础,同时也是群体协作类的隐私保护机制能否成功的重要因素.本节在k=6的隐私保护要求下,对用户数量和抑制率的关系进行了实验.实验对比了本文提出的算法的抑制率DQN value,传统的泛化用户的选取算法的抑制率Baseline和最优抑制率OPT value.图5描述了用户数量对抑制率的影响,可以看出当用户数量非常少时,Baseline和DQN value都非常高.因为用户数量稀少时,无论什么方案都很难找到足够的用户参与泛化,任务将大量抑制,所以需要激励机制配合.两种方案在用户数量提高后都降低了抑制率,而采用DQN算法降低抑制率的速度明显高于Baseline,并且最终非常趋近于最优值.
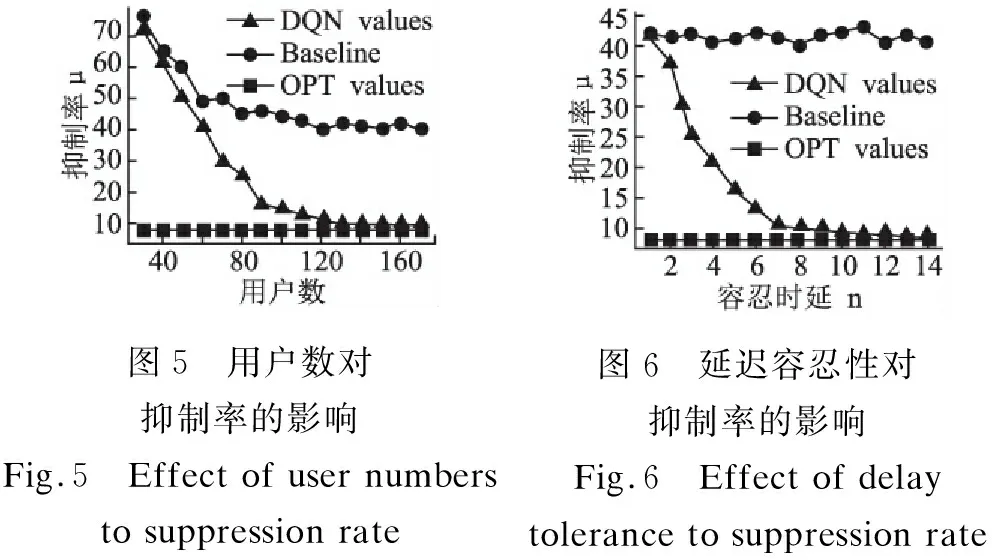
图5 用户数对抑制率的影响Fig.5 Effect of user numbers to suppression rate图6 延迟容忍性对抑制率的影响Fig.6 Effect of delay tolerance to suppression rate
6.3 任务的延迟容忍性对抑制率的影响
延迟容忍性影响着任务提交前DQN算法对抑制率的优化空间.我们选取了100个用户在特定范围内完成任务的情况对延迟容忍性和抑制率的关系做了实验.实验结果如图6所示,其中横坐标容忍延时n表示任务失效前用户完成的任务数.可以看出当延迟容忍性为0或者1时,任务实时性要求非常高,Baseline和DQN value都在42左右.原因是没有延迟容忍性,DQN算法就没有优化抑制率的空间.当延迟容忍性提高后,Baseline的抑制率始终在40-45左右波动.因为传统的选取方式的抑制率与任务的容忍延时无关,没有合理利用群智感知任务的特性.而DQN算法的抑制率随着延迟容忍性的提高快速下降,当延迟容忍性达到7以上时抑制率趋于平稳并非常接近最优值.因此本文的算法能够利用群智感知环境的特点,在感知任务具有一定延迟容忍性的条件下表现出了良好的效果.
7 结束语
本文提出一种移动群智感知中基于深度强化学习的隐私保护策略.其核心思想是:
1) 保证群智感知数据的可用性.
2) 抑制会破坏用户隐私的任务.
3) 降低任务的抑制率.
实验结果表明,本文的策略在任务具有足够延迟容忍性,并有较多用户参与的群智感知应用下表现出良好的效果.后续的工作包括:
1)当任务的延迟容忍性非常差时DQN算法降低抑制率的效果不好,研究如何结合激励机制,进一步降低抑制率;
2)根据用户对隐私的重视程度,提供定制化的隐私保护机制.
