基于泰坦尼克之灾问题的机器学习传统算法和神经网络算法对比分析
2019-02-14王可晴
王可晴
(浙江省萧山中学,浙江杭州,310000)
1 概述
泰坦尼克号的沉没是历史上具有广泛影响的沉船事件之一,1912年4月15日,在首次航行期间,泰坦尼克号撞上冰山后沉没,2224名乘客和机组人员中有1502人遇难。这场轰动的悲剧震撼了国际社会。虽然幸存下来的人存在一些运气方面的因素,但有一些人比其他人更有可能生存,比如妇女,儿童和上层阶级。我们的目标便是根据每位乘客的性别,年龄,舱位等相关特征,来预测该乘客是否会在该次乘船事故中存活下来。
■1.1 训练集以及测试集
我们总共有900名左右的乘客数据,每位乘客包括10个 特 征, 包 括 Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarke。 我 们 将 拿 出600名乘客数据作为我们的训练集,剩下的数据作为我们的测试集,用来检验我们构建模型的性能好坏。
■1.2 数据预处理
通过对数据集的观察发现,有些乘客的部分属性存在着一定的缺失值NaN,比如Age,Fare等相关属性。我们需要对这些数据进行填充,对于连续型属性数据缺失的情况,我们通过在未缺失数据上构建一个随机森林回归模型,来对缺失的数据属性进行拟合,然后填充该部分缺失的数据。对于离散型数据缺失的情况,我们将删除该乘客对应的记录。
对于Ticket,Cabin,Embarke等类目型变量,我们将把它们转化为one-hot独热编码。采用one-hot编码后,一方面可以使样本之间能够直接进行距离的计算,另一方面能够扩充样本特征的数目。在一定的程度上,提高模型的性能。
经过预处理后,我们的待训练样本,从原始的10个特征增加到15个特征。增加的特征主要是由于类目型特征经过了one-hot编码的转换。15个特征中不包括乘客姓名特征Name,因为通过对数据分析,乘客的姓名应该和该乘客是否能够存活下来无关。
2 分类模型构建
■2.1 kNN模型
2.1.1 kNN模型原理
KNN(K Nearest Neighbor)算法,又称之为K领近算法,是数据挖掘与机器学习中最简单的分类方法之一。K领近指的是待分类样本点最近的K个邻居。kNN 模型最初由Cover和Hart于1968 年提出, 是一个在理论上比较成熟的方法[1]。
KNN模型的主要思想是,将训练集绘制在特征空间中,然后将待分类样本,通过特定的距离计算公式,得到该样本在该特征空间最近的K个邻居,然后采取投票原则,将K个邻居中得票最多的类别作为待分类样本的类别。
在我们要解决的实例问题中,我们的训练样本包括600个乘客的特征数据,将它们绘制在特征空间里。在测试集的300个数据中,我们计算每一个乘客与训练集中600个乘客的距离远近,挑选出最近的k个距离,然后采取投票原则,k个样本中所属类别最多的类别就是测试样本的类别。
2.1.2 结果分析
我们采用了sklearn机器学习库中kNN模型算法,对我们的数据进行了训练。并且尝试了不同的k取值,在该问题上的正确率。我们分别测试了当k 取5,10,15,20时模型的结果。测试的结果显示,在上述4种k的取值下,在测试集上的正确率分别为79.3%,81.7%,83.1%,82.4%。由此可见,在泰坦尼克号这个问题上经过验证,当k取值在15左右时,模型的结果较好。
关于kNN模型中k值的不同选择:当k值较小时,预测结果对近邻的实例点非常敏感,容易发生过拟合;如果k值过大模型会倾向大类,容易欠拟合;通常k是不大于20的整数。kNN算法的优点是精度高,对异常值不敏感。但是缺点是对k的取值相对比较敏感,不同的k取值对模型产生的结果可能差异性非常的明显。
另一方面,由于我们的训练集的大小仅仅为600个样本,而对于其他的一些机器学习应用,我们可能有上百万训练样本,这个时候kNN算法的局限性就暴露出来了,每预测一个新的样本的类别,我们都需要计算该样本与上百万样本的距离,会造成算法运行速度非常缓慢,效率低下,这时候需要采用其他速度更快的分类模型来解决该问题。
■2.2 逻辑回归模型
2.2.1 逻辑回归模型原理
逻辑回归是机器学习中一种常见的分类模型,其对于简单的分类问题具有良好的效果。其基本原理是采用sigmoid函数作为我们的预测函数,来预测条件概率P(y = 1 | x)。在我们的问题中,sigmoid函数的输出就是乘客存活下来的概率,范围在[0,1]之间。模型在训练的过程中,通过不断最小化极大似然代价函数,来提高模型预测的准确率。在训练的过程中,加入正则化项,可在一定程度上减轻模型过拟合。
2.2.2 逻辑回归的假设函数
假设函数采用sigmoid函数,函数形式为如1式,取值范围为[0,1]。代表了每位乘客存活下来的概率。其中z =θTxX,θ是模型需要学习的参数,X在该问题中对应每个乘客的特征向量。即z是每位乘客所有特征的线性组合。

2.2.3 逻辑回归的代价函数
代价函数是我们优化的目标函数,用来衡量模型在训练集上的拟合程度,在训练集上拟合的越好,代价函数就越小,在训练集上拟合的不好,那么代价函数就越大。所谓的学习过程,实质是就是不断的通过更新模型的参数值,来降低代价函数值的过程。
常见的代价函数有MSE代价,交叉熵代价。其中前者常常应用于回归问题中,交叉熵代价常用于分类问题中。对于我们的问题而言,由于是一个二分类问题,所以采用交叉熵代价函数。交叉熵代价函数的表达形式如2式。其中g(θ)代表了逻辑回归函数的输出,log代表以10为底的对数,yi代表样本的真实分布。
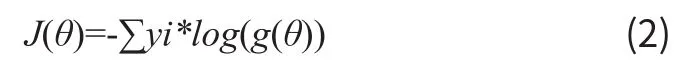
2.2.4 逻辑回归的潜在问题
理论上来说,算法在经过多次迭代的过程中。代价函数的值可以不断的降低,直到达到一个比较小的值后,基本保持不变。但是这样存在的一个问题是,模型会过度的拟合训练集的数据,从而陷入过拟合的风险。一旦模型陷入了过拟合,即使模型在训练集上的准确率很高,但是模型没有足够的泛化能力,将模型推广到未知的数据[2],造成在测试集上的效果不好。
2.2.5 逻辑回归的正则化
为了解决上述提到的模型可能陷入过拟合的问题,需要采取一定的措施。常见的缓解过拟合的措施,可以增加训练集的数目,或者采取正则化手段。由于我们不太容易去增加训练集的数目,因此可以采用正则化手段。常见的正则化有L1,L2正则化。在我们的问题中采用L1正则化,加入正则化项的代价函数如3式,其中C为正则化参数。
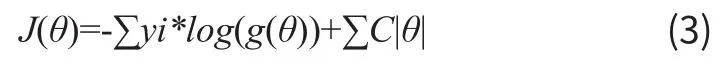
2.2.6 结果分析通过在训练的过程中加入的L1正则化项,我们的模型基本没有发生过拟合,在训练集上的准确率达到了79.8%,在测试集上达到了81.7%的正确率,取得了良好的性能。逻辑回归的优点是在于简单,训练速度相对于KNN模型快很多。但是其一般更适合用于线性可分的问题当中,而对于一些线性不可分的问题中,采用更复杂的非线性模型可能会取得更好的效果。
■2.3 SVM模型
2.3.1 SVM模型原理
支持向量机(support vector machine,SVM),它最初于20世纪90年代由Vapnik提出,是机器学习中一种十分强大的分类模型。与数据挖掘中的其他分类模型相比,具有较好的泛化能力。而且针对非线性可分数据,拥有一套先进的理论方法来处理。SVM(Support Vector Machine)指的是支持向量机,是常见的一种判别方法。在逻辑回归建立超平面的基础上寻找唯一且最合理的分界。对于线性可分情况,具体方法是寻找离各邻近点距离之和最大的线来进行分隔;对于线性不可分情况,则需要核函数的帮助。由于其优秀的分类性能,在机器学习领域成为了研究的热点。在学术界,不断的有新的理论被提出。近年来,与SVM相关的方法,在人脸识别,手写识别,文本分类中得到了广泛的应用,并且取得了很好的效果[2]。
SVM可以理解为是逻辑回归的改进,对于逻辑回归模型来讲,由于存在无数个可能的解,解不唯一。即存在无数个超平面将数据分割开来,因此算法得到的解可能不一定是最优的。而SVM算法能从这无数个超平面中,选取一个最大间隔的超平面,使模型的泛化能力更强。
SVM主要适用于两种情况。第一类是线性可分数据,第二类是线性不可分数据。对于线性可分数据,采用了核技巧,将数据从低维空间映射到高维空间,再通过松弛变量等技术使数据变的线性可分。
2.3.2 SVM模型的核函数
对于线性可分的数据,普通的SVM可以取得很好的效果。但在现实世界里,存在着很多非线性可分的数据。这个时候,普通的SVM就不太适用。核函数本质上是一种建立从一维到多维空间的映射。当线性不可分的情况通过核函数映射到多维,就可能成为线性可分,即可以通过方法一加以分隔。此时,线性不可分数据就可能变成线性可分数据,核函数用来计算两个低维空间的向量在高维空间的内积,只要满足Mercer 条件的函数,都可以作为核函数。常见的核函数有线性核函数,高斯核函数,多项式核函数等[3]。
2.3.3 结果分析
当训练集数目比较小时,SVM算法一般能够取得很好的效果。但是当训练集数目比较多时,SVM比较容易陷入过拟合,所以需要采用一定的正则化措施来缓解过拟合。
因此我们使用了sklearn中带有核函数的SVM,在包含有600个样本的训练集上经过一段时间的训练后,最终得到的支持向量个数为298个。可以看到大概有50%的训练样本为支持向量。
我们采用了不同的核函数来检验模型的效果,实验结果表明,不同的核函数在该问题上的差异性不显著。最终我们采用了带有高斯核函数的SVM,在训练集上的正确率为81.8%,在测试集中进行测试时,得到了83.5%的正确率。从训练集和测试集上的正确率来看,模型基本上没有发生过拟合。SVM也是在包含上述一系列的分类模型中,所达到的正确率比较高的模型,因此可见,SVM模型是效果非常好的一个分类模型。
■2.4 神经网络模型
2.4.1 神经网络模型原理
神经网络是基于生物学中神经网络的基本原理,对人类大脑工作过程的一个简单的模拟。它能够通过一定的学习算法,学到一个非常复杂的非线性模型。当数据量比较大时,具有十分强大的泛化能力。
神经网络通过将多个神经元通过一定的联结方式连接在一起,构成一个运算模型。每个神经元节点的输入是上一层神经元输入的线性组合,然后加上激活函数后,作为该个神经元的输出。常用的激活函数有sigmoid,tanh,Relu等。每两个神经元之间,具有一个权重值w。神经网络就是通过激活函数,权重,联结方式来模拟人类大脑的学习记忆功能。
神经网络在工作时,首先通过前向传播计算代价函数值,然后通过反向传播算法计算代价函数的梯度值,最后通过一定的优化算法,更新神经网络的每一层的权重矩阵W。
在我们的泰坦尼克号乘客遇难问题中,每个乘客在经过预处理后,有14个特征,所以我们的神经网络的输入层一共含有14个神经元,第二层网络具有32个神经元,第三层网络具有64个神经元,输出层含有一个神经元。在这个问题上,我们建立了一个具有多层感知机的神经网络来进行预测,并且添加了相应的正则化项来防止模型的过拟合[4]。
2.4.2 神经网络模型dropout正则化
dropout(随机失活神经元)是在训练神经网络过程中,避免模型过拟合常用的技巧。在标准的神经网络中,由于层次可能较深,神经元的个数可能较多。因此模型很容易陷入过拟合。如果引入了dropout技术,在每轮训练的过程中随机断开部分神经元,只更新部分神经网络权重值。可以在一定程度上,缓解神经网络训练过程中模型的过拟合问题。从另一个角度讲,由于每次只训练部分神经元,也可以提高训练的速度,加速训练的过程。
2.4.3 结果分析
我们通过构建了一个三层的感知机神经网络,对600个训练集数据进行训练,最终在训练集上取得了85.8%的正确率,在测试集上取得了83.5%的正确率,基本和SVM得到的结果不相上下。实质上,神经网络更适合处理特征数目很多,训练集数目很大的情况,而在泰坦尼克号这个问题上,由于我们只有几百个训练样本,每个样本只有十几个特征。因此,虽然结果表现不错,但是没有真正体现出神经网络强大的泛化能力,没有体现出多层神经网络的主要优势。
3 结语
本项目通过Kaggle上具体的实例“泰坦尼克号乘客遇难预测分析”,对该问题分别采用了KNN模型,逻辑回归模型,SVM模型以及神经网络模型。在该问题的同一测试集上,最优模型分别取得了79%,81.7%,83.5%,83.5的正确率。比较了机器学习中不同的分类模型在该问题上的优缺点。通过对该问题的研究,掌握了不同分类模型的差异性。
