基于神经网络算法的新闻分类研究
2019-02-14宋文浩
宋文浩
(诸城市实验中学,山东潍坊,261000)
1 概述
神经网络的研究在机器学习中具有重要的意义。人工神经网络以其特有的优越性,成为研究的热点。神经网络的特点可以从三个方面来介绍:第一,人工神经网络的自学习能力。对于图像识别问题,只需要将图片及其对应类别输入神经网络,不需要构造复杂的组合特征,神经网络可以通过强大的自学习能力捕捉特征之间的关联,实现图像识别功能。第二,人工神经网络的联想存储功能。第三,人工神经网络的高速优化能力。对于机器学习问题来说,复杂度越高的问题,寻找优化解的计算量往往会越大。而设计好的反馈型人工神经网络,则能够充分利用计算机高速运算的能力,能够大大缩短寻找优化解的时间。
娱乐文章按体裁能分成七类:资讯热点,电影电视剧报道评论,人物深扒,组图盘点,明星写真,行业报道,机场图。本文根据娱乐文章的文本信息构建神经网络,将文章进行多分类。
■1.1 数据集特征
娱乐新闻数据集包含了7个特征:
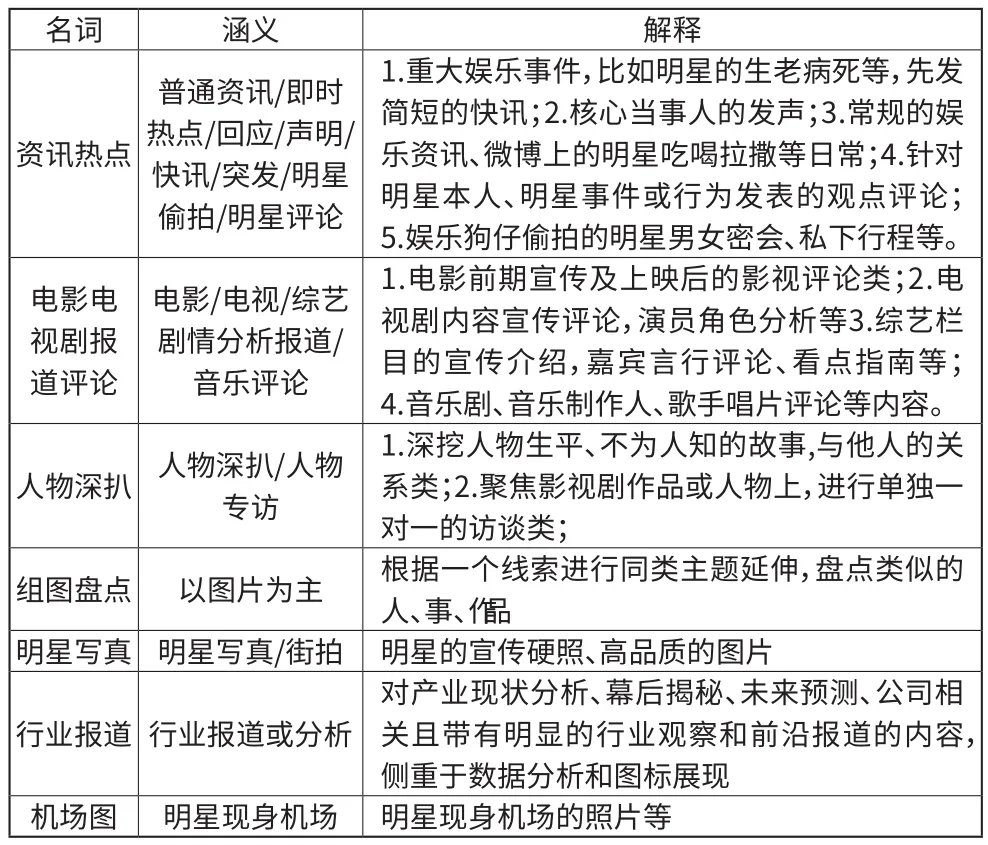
名词 涵义 解释资讯热点普通资讯/即时热点/回应/声明/快讯/突发/明星偷拍/明星评论1.重大娱乐事件,比如明星的生老病死等,先发简短的快讯;2.核心当事人的发声;3.常规的娱乐资讯、微博上的明星吃喝拉撒等日常;4.针对明星本人、明星事件或行为发表的观点评论;5.娱乐狗仔偷拍的明星男女密会、私下行程等。1.电影前期宣传及上映后的影视评论类;2.电视剧内容宣传评论,演员角色分析等3.综艺栏目的宣传介绍,嘉宾言行评论、看点指南等;4.音乐剧、音乐制作人、歌手唱片评论等内容。人物深扒 人物深扒/人物专访电影电视剧报道评论电影/电视/综艺剧情分析报道/音乐评论1.深挖人物生平、不为人知的故事,与他人的关系类;2.聚焦影视剧作品或人物上,进行单独一对一的访谈类;组图盘点 以图片为主 根据一个线索进行同类主题延伸,盘点类似的人、事、作品明星写真 明星写真/街拍 明星的宣传硬照、高品质的图片行业报道 行业报道或分析对产业现状分析、幕后揭秘、未来预测、公司相关且带有明显的行业观察和前沿报道的内容,侧重于数据分析和图标展现机场图 明星现身机场 明星现身机场的照片等
■1.2 数据集预处理
通常,在工程实践中,拿到的实际数据往往存在以下问题:数据缺失、数据重复、数据冗余等。这就要求我们在将数据喂入模型开始训练之前,针对现有数据存在的问题进行特定的处理,即数据预处理。数据预处理要具有针对性,对于不同类型的数据以及不同类型的数据问题,采取的预处理方式也不同。我们的娱乐新闻数据集的预处理一共包含分词,去停用词和计算TF-IDF三个步骤。对训练数据进行整体分析,抽取出正文和标签部分作为输入。对测试数据做相同处理,抽取出测试数据的真实标签和正文内容。
1.2.1 去停用词
停用词包括标点、数字、单字等对于分析文本内容贡献很小的词语以及其它一些无意义的词。这些词(如“你我他”)往往无法表示文本的特征,对于模型的训练帮助不大,应当从文本中清除掉。本文用到的是哈工大的停用词表。将文章中的词与停用词表中的词作比较,如果在表中出现该词,就将其删除,如果没有出现,就跳过。
1.2.2 分词
文本分词是文档处理中的一个必不可少的操作,因为后续的操作需要用文档中的词来表征这篇文档的内容。本文中对文本进行分词步骤如下:
(1)构造词典
(2)分词操作
目前主要用来构造词典的方法是字典树。分词主要采用的有正/反/双向最大匹配以及语言模型和最短路径等算法。
我们使用的是结巴分词程序包。
1.2.3 tf-idf指标
tf-idf(term frequency-inverse document frequency)又称之逆文档频率,是一种统计学上对词出现的频繁程度的一种量化指标。用于衡量一个单词在一篇文章中或者在一个大型的语料库中的重要程度,词语的重要性和词语在一篇文档中出现的次数有着正相关关系,但和整个语料库中该次出现的频率有着负相关关系。通俗地说,就是一个词在某篇文章中出现的次数越高,而在这一堆文章中的其他文章中出现越少,它就更能表征这篇文章的内容。
词频(TF)指的是一个给定的词语在某篇文章中出现的次数,为了防止文章过长导致频率偏向长文章,这个出现的次数一般会采用某种算法进行归一化操作(通常采用该次出现的频数/该篇文档的总词数)。TF(W)=在某一类中词条W出现的次数除以该类中所有的词条数目。
IDF的计算方法是由语料库中文档的总数除上出现该词语的文档数,将结果再取对数。IDF=log(语料库的文档总数除以包含词条w的文档数+1),分母之所以要加1,是为了避免分母为0 IDF=log(语料库的文档总数包含词条w的文档数+1),分母之所以要加1,是为了避免分母为0。
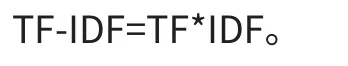
最终输入模型的即每篇文章的TF-IDF值。
■1.3 数据集划分
为了模型的训练与模型的性能检验,我们需要把数据集分为训练集和测试集两部分。数据集共包含9000+训练数据,2000+测试数据。
2 构建神经网络模型
■2.1 构建神经网络模型
2.1.1 基本原理
神经网络结构:一个经典的神经网络包含三个层次。红色的是输入层,绿色的是输出层,紫色的是中间层(也叫隐藏层)。输入层有3个输入单元,隐藏层有4个单元,输出层有2个单元。如图1所示。

图1
神经元结构如图2所示。
一个神经元一般由输入z和输出a两个函数组成。每个神经元和其他的每个神经元都具有一个连接权重,它们各自的权重通常是一些随机值。对于一个神经元,将所有对应的权重和上一层的输出a相乘,然后,把这些值相加。然后运用激活函数对这个值进行非线性变换,这个激活函数的输出成为这个神经元的最后的输出。Z=n0*w0+n1w1+n2w2+b.激活函数常用sigmoid函数:sigmoid函数的输出介于0~1之间,它是人工神经网络中比较常用的一种激活函数。
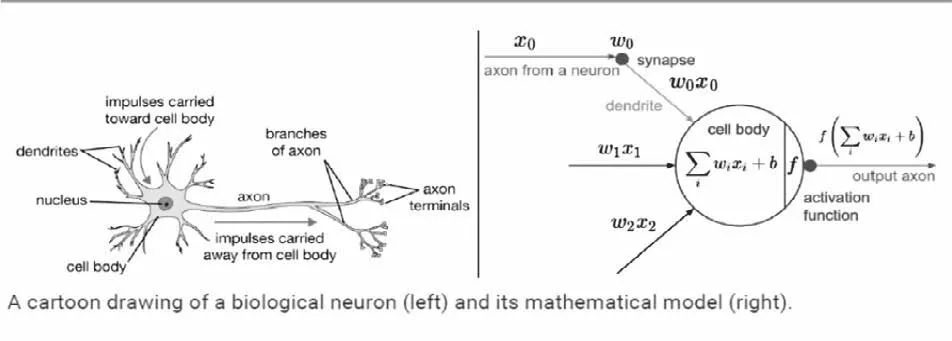
图2
神经网络(感知机)算法:训练的目的是求出最适权重(即W)与最适b。为描述预测模型的准确度,在此引入了损失函数。求最优解的的过程就是求损失函数最小的过程。公式如下:
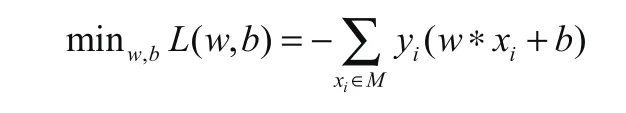
2.1.2 前向传播算法
神经网络的前向传播算法,在神经网络中,下一层的输入是通过上一层结点进行卷积运算(加权运算),并且加上bias偏置项,最后再通过一个非线性函数进行非线性变换而得到。这里的非线性函数也就是激活函数,常见的激活函数包括ReLu, sigmoid等。这里得到的结果就是本层结点的输出,也是下一层的输入。重复以上过程,进行一层层的运算,直到网络最后一层,得到输出层结果。
不管维度多高,前向传播每层进行的计算过程都可以用如下公式表示:
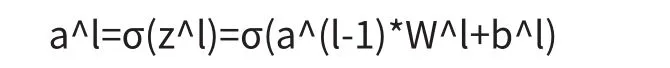
上述公式中,l表示网络层数,*表示向量运算,W为权重,b为偏置,σ表示激活函数。本文采取ReLu作为激活函数。
2.1.3 反向传播算法
网络初始训练时采用的随机初始权重得到的输出结果和实际值之间肯定存在很大的偏差,因此,需要更新网络中每一层的权重值,优化网络的预测准确率,此时需要使用反向传播算法。
假设前向传播算法计算得到的输出值为yk,yk表示输出层输出的对第k个结果的预测,而第k个结果的真实值记为tk,定义损失函数如下:
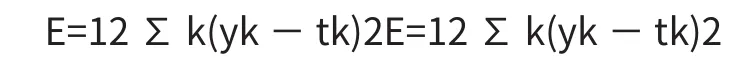
反向传播算法也就是采用梯度下降的方法对参数W和偏置b进行迭代优化,再梯度下降过程中需要计算误差函数分别对网络中每一层的参数W和b的偏导数。从而找到梯度下降最快的方向(即损失函数下降最快的方向),从而优化算法模型。
神经网络是根据网络深度进行划分,工作原理主要包括前向传播和反向传播。通常的神经网络包括输入层,隐藏层,和输出层。隐藏层的深度往往远远大于1。我们通过输入特征,进行前向传播,然后计算出输出误差(真实值和计算值之间的误差)。反向传播算法的目的即通过得到的输出误差,不断的迭代,从而更新网络的权重,不断的减小训练误差,达到最小化模型误差的目的。从而提高网络预测的准确率和泛化能力。
2.1.4 过拟合问题
过拟合,就是拟合函数需要顾忌每一个点,对训练模型的一些噪音或者离群点也做出了拟合,最终形成的拟合函数对测试集数据拟合的有所欠缺,导致预测结果波动很大。可以很明显地看到,模型在训练集上效果很好,但是在测试集上效果很差。这会导致模型泛化能力弱,达不到预期的结果。针对神经网络的过拟合问题,通常采用随机失活部分神经元(dropout)的方法进行解决。即,简化了神经网络的模型,避免模型过于复杂而导致过拟合问题。本文中的模型也采用了dropout方法来降低过拟合。
■2.2 模型的特点分析
构建了结构为:64个神经元的Dense层->0.2Dropout层->7个神经元的Dense层的神经网络,采用SGD算法,设置了10个epoch,batch size为128。在训练集上达到80.89%的准确率,在测试集上达到了73.27%的准确率,如图3所示。
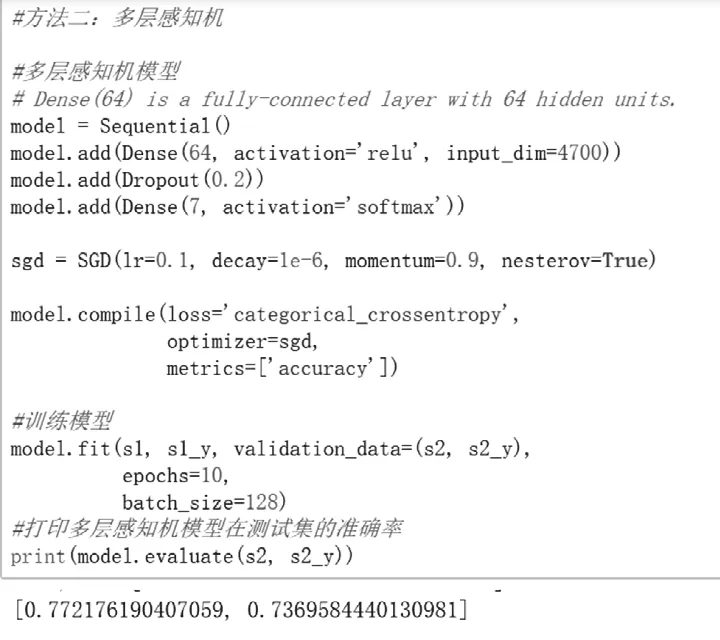
图3
3 结语
本项目根据具体的娱乐新闻分类数据,在该数据上探索了神经网络算法。构建了结构为:64个神经元的Dense层->0.2Dropout层->7个神经元的Dense层的神经网络,采用SGD算法,设置了10个epoch,batch size为128。在训练集上达到80.89%的准确率,在测试集上达到了73.27%的准确率。表现出了神经网络学习方法的优异性。
