基于SBAS和混沌理论的内排土场沉降监测及预测
2019-02-11雷少刚卞正富
田 雨,雷少刚,卞正富
(1.中国矿业大学 国土资源研究所,江苏 徐州 221116; 2.矿山生态修复教育部工程研究中心,江苏 徐州 221116)
排土场是露天矿存放废弃石材土料的地方,是露天矿整个生产周期中不可或缺的一项永久性工程建筑,排土场可分为内排土场和外排土场,其中,内排土场是采矿过程中将剥离的岩土直接排弃到采空区进而形成的堆积体。内排土技术运距短,可以极大地降低排土成本,相比于外排土场压占面积更小,同时内排土场经平整恢复,可为复垦和工程建设提供可观的土地,成为矿区实现可持续发展的关键区域之一。但排土场因其填方土石的自重作用、降雨径流等因素影响,堆积成形后随时间推移不可避免的发生变形。目前学者们对于排土场的研究主要集中在边坡稳定性上[1-3],对于排土场主体的变形沉降研究较少,而内排土场土层沉降压实过程中,土壤质地和渗透性发生变化,有效水分和养分随之改变,不利于植被及微生物生长[4-5],工程建设更是对其主体变形的速率、累积量等都提出了严格要求,本文旨在通过时序SAR数据高精度监测内排土场沉降,探究其沉降规律,并依据监测数据采用混沌时间序列相空间重构理论结合二阶Volterra自适应滤波建立预测模型,进行内排土场沉降动态预计,为内排土场的充填复垦[6],工程利用等提供一定参考。
1 研究区概况
胜利露天煤矿隶属于神华北电胜利能源有限公司,其中胜利一号露天矿位于胜利煤田的中西部,锡林浩特市北郊5 km,本煤田位于内蒙古高原中部,气候干燥,丘陵地形,地形标高970~1 326 m,露天矿共有4个排土场,其中3个外排土场:南排土场、北排土场、沿帮排土场。矿区至2013年实现全部内排,内排土场覆盖范围约2.3 km×1.1 km,其上植被较少,适宜利用SAR数据进行沉降监测,如图1所示。

图1 研究区示意Fig.1 Schematic map of the study area
2 沉降监测
2.1 SBAS算法
小基线集(SBAS)技术由BERARDINO等于2002年提出[7],其基本原理是将获得的同一个区域的SAR数据按照空间基线组成多个集合,利用最小二乘方法分别得到每个集合的沉降时间序列,然后利用奇异值分解法(SVD)将多个集合联合求解从而得到整个观测时间周期的沉降时间序列[8],经众多国内外学者验证,它可以有效抑制由于时间、空间造成的失相干和大气效应,尤其在低植被覆盖区域可得到高精度的沉降时序数据。
2.2 数据准备
Sentine-1 A于2014-04-03发射,搭载了C波段SAR传感器,时间分辨率为12 d,共有4种数据获取模式:SM(Stripmap Model),IW(Interferometric Wide Swath),EW(Extra-Wide Swath)和WM(Wave Model)[9]。本文选用Sentine-1 A IW模式下的单视复数据(SLC),极化方式为VV和VH,其空间分辨率为5 m×20 m,数据时间跨度为2016-09-29—2018-02-03,除缺失2017-06-20一期数据外,其余数据时间间隔均为12 d,共计41期。
本文选取时间基线阈值为60 d,时空基线如图2所示。

图2 干涉图的时空基线Fig.2 Spatial-temporal baselines of the interfergrams
2.3 沉降结果及分析
通过生成的干涉图,经相位解缠、轨道精炼和重去平、时间高通滤波、空间低通滤波等得到只含形变信息的差分干涉图,进而SVD求解得到时间形变序列[10]。
图3为处理获得的2016-09-29—2018-02-03地面累积沉降量,由图3可以看出,胜利一号露天矿内排土场的累积沉降量和沉降面积随时间推移不断增大,总体呈现西部累积沉降大,东部累积沉降小的规律,截至2018-02-03(参考2016-09-29),最大累积沉降量达394 mm。

图3 沉降量Fig.3 Maps of settlement
为进一步研究内排土场沉降的时空分布规律,将2018-02-03累积沉降量按照50 mm等间隔划分为Ⅰ~Ⅷ共8个区域,并从累积沉降量最大区域向外延伸两条直线A和B,每个区域内均在直线上随机取一点,如图4所示。
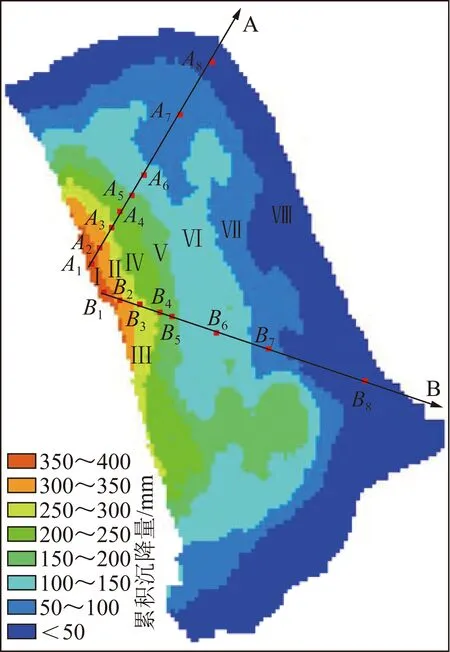
图4 线和点位置Fig.4 Location of lines and points
分别统计沿直线A,B的累积沉降量和A1~A8点,B1~B8点处的沉降时间序列。
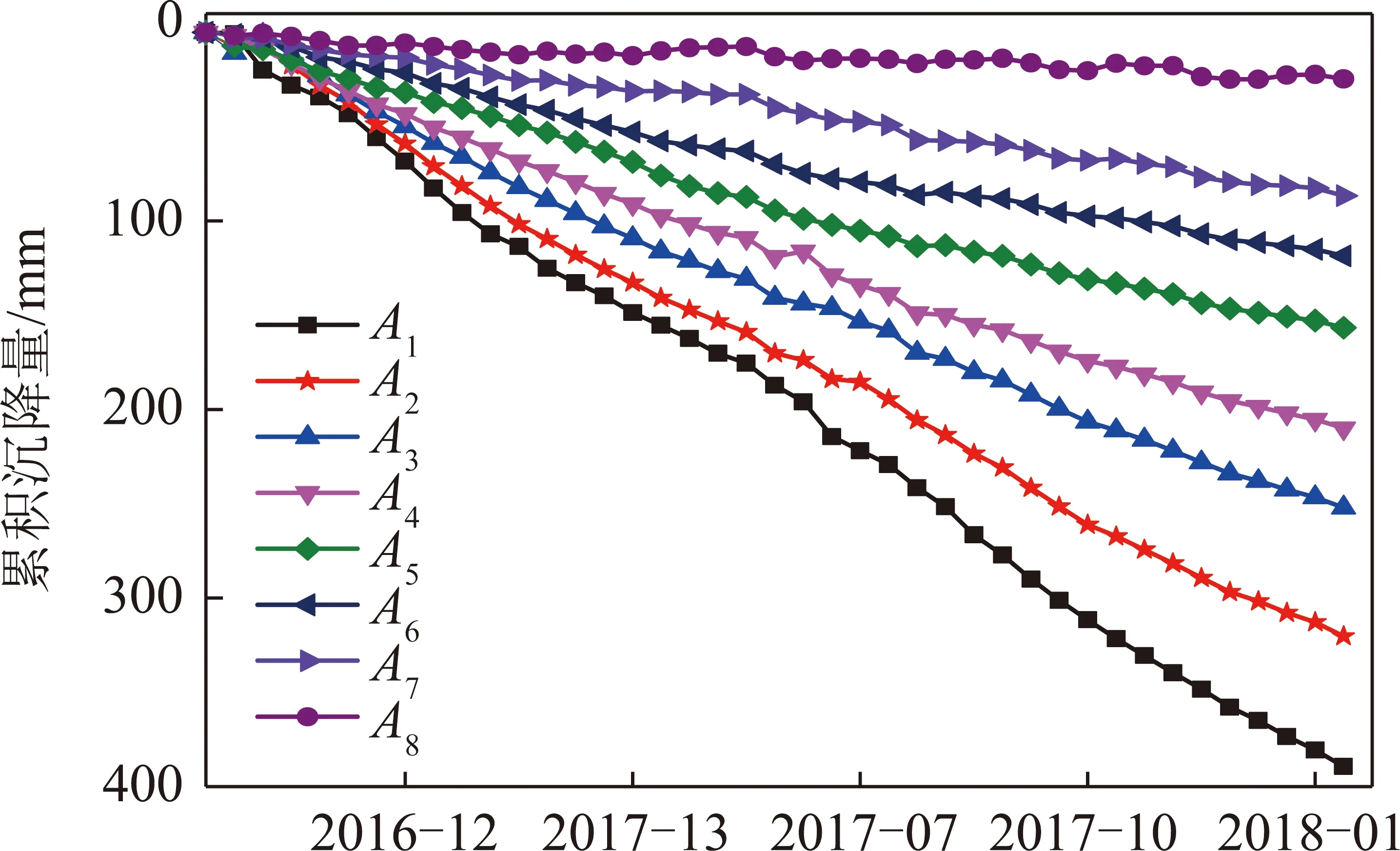
图6 A1~A8沉降时间序列Fig.6 Settlement time series of A1-A8
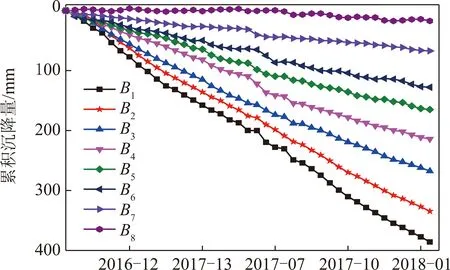
图7 B1~B8沉降时间序列Fig.7 Settlement time series of B1-B8
图5为观测时间周期内累积沉降量沿直线A和B的剖面图,可以看出A,B两条曲线相似度很高,内排土场累积沉降量空间上呈现明显的半漏斗状,总体上累积沉降量与到矿坑距离成反比,符合内排土场排弃规律。图6,7分别代表直线A和B在每个区域取的随机点随时间的沉降规律,可看出同一个区域内两点的累积沉降量-日期曲线近乎相同,两图均反映出在Ⅷ区域,沉降速率最后趋近于0,表明已达稳定状态,可初步判断Ⅷ区域已基本满足了土地复垦及建设简单构筑物的基本要求,Ⅲ~Ⅶ区域随时间推移沉降速率有所减缓,但仍未稳定,还需一定时间的固结压实才可以考虑工程利用,Ⅰ,Ⅱ区域观测周期内沉降速率大且基本保持不变,沉降剧烈,处于沉降活跃期,主要是由于其为观测周期起始时覆土,比其他区域较晚,且临近矿坑,受施工、雨水冲刷等影响边坡部分土壤松动滑落所致,存在滑坡、泥石流风险,是后期沉降监测的重点区域。
2.4 下沉系数估计
矿区传统的下沉系数是井工矿开采沉陷和建筑物下采煤进行地表移动变形预计时的一个重要参数。但露天矿内排土场覆土工后物料也会在自重等作用下逐渐压实沉降,期间地表难免发生移动变形,而内排土场的再利用如工程建设和土地复垦等都对土体稳定性提出了严格要求,因此露天矿内排土场主体稳定性必须考虑下沉系数,本文定义内排土场下沉系数为排土工后最终沉降量与初始覆土高度的比值:

(1)
式中,q为内排土场下沉系数;H0为内排土场原始覆土高度,m;Hcm为内排土场最终沉降量,cm。
依据内排土场排土时序图,得A1~A8,B1~B8覆土时间见表1。
表1A1~A8,B1~B8覆土日期
Table 1 Covering soil times ofA1-A8andB1-B8

点号覆土日期(年-月)点号覆土日期(年-月)A12016-10B12016-09A22016-08B22016-06A32016-05B32016-05A42016-04B42016-04A52016-03B52016-03A62015-03B62015-03A72014-09B72013-12A82013-07B82013-07
因内排土场覆土层力学性质相近,覆土高度几乎相同,所以可近似认为A1~A8,B1~B8为内排土场覆土工后不同时期的沉降状态,其中A1接近为监测周期开始时最新的覆土点,选择A1~A8累积沉降量依据时间关系进行曲线拟合,估计A1点累积下沉量,结果如图8所示。

图8 A1点累积下沉拟合曲线Fig.8 Cumulative settlement fitting curve of A1
由图8可知,累积下沉量随时间呈现指数分布,R2高达0.991,A1最终下沉量约为662 mm,下沉量达到相对稳定约需要110期监测,即1 320 d。A1点排土场原始覆土高度为103.58 m,因此可求得观测周期内,内排土场下沉系数约为0.639 cm/m。值得注意的是,A1点沉降监测时间受限于原始数据,略晚于真实覆土时间,而覆土初期是沉降剧烈期,因此本文求出的下沉系数小于实际下沉系数,只能作为后续研究的参考。
3 沉降预测
3.1 混沌系统的识别
混沌运动可认为是确定性非线性动力系统中独特的重复性运动,具有不同于一般确定性运动的几何和统计特征[11]。混沌系统与高维随机运动的主要区别在于:混沌系统通过相位重构,其轨迹可预测,而随机运动则不能[12]。
时间序列可分为周期性序列、准周期性序列和混沌序列[13]。对于指定的时间序列需要进行性质鉴别。混沌时间序列的判定方法有很多,目前为止使用最为广泛的Lyapunov指数法[14-15]。Lyapunov指数反映了混沌动力学系统对初始条件的敏感性,最大的Lyapunov指数是否大于0可作为判定动力学系统混沌性的一个依据。现有的Lyapunov指数计算方法有定义法、Wolf方法、P-范数方法、小数据量法以及奇异值分解方法等[14-15]。
3.2 相空间重构
根据荷兰数学家TANKENS[16]提出的延迟嵌入定理,即只要将采集到的时间序列嵌入到延迟时间为τ的m维相空间中,则所重构的m维状态空间与原混沌动力系统的几何特征等价,它们具有相同的拓扑结构。因此,选取合适的嵌入维数m和延迟时间τ是相空间重构的关键步骤。
本文选取互信息量法求延迟时间τ。Swinny和Frasert[17]提出的互信息法是一种通过度量2个变量之间的随机关联程度来判断系统非线性相关性的方法,计算较为准确,在相空间重构延迟时间的确定中应用较为广泛。
对于时间序列{x(t1),x(t2),…,x(tn)},当延迟时间为τ时,序列变为{xi+τ,i=1,2,…,n},则互信息函数为

(2)
其中,P(xk)为xk在时间序列{xi+τ,i=1,2,…,n}中出现的概率;P(xkτ)为xk+τ出现的概率;P(xk,xk+τ)为xk和xk+τ共同出现的概率,在使用互信息量法计算最佳时间延迟时一般采用互信息函数I(τ)的第1个极小值点作为最优时间延迟。
选取A1,B3,A5,B7各点的相邻两期累积沉降量差值构成4组长度为40的时间序列,因缺失一景SAR数据无法组成等时间间隔序列,经研究采用3次样条插值对数据进行加密,从而得到4组以1 d为间隔,长度为492的时间序列数据。图9是4组时间序列数据的互信息,由图9可以看出A1,B3,A5,B7的时间延迟分别为4,3,3,3。

图9 互信息法选择时延Fig.9 Determine delay time through mutual information method
对于嵌入维数m的选取利用Cao Liangyue[18]提出的改进虚假临近点法,即Cao方法,定义:
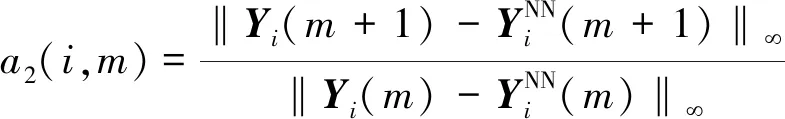
(3)

定义E(m)为所有i对应a2(i,m)的均值,即
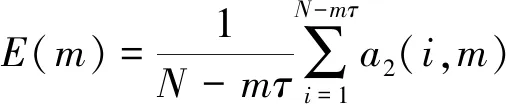
(4)
为了进一步研究E(m)随m的变化情况,定义
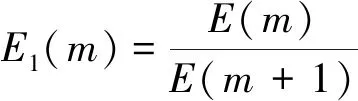
(5)
若时间序列存在混沌吸引子,则当嵌入维m大于某个值m0时,E1(m)逐渐稳定,那么m0+1可以作为系统的最佳嵌入维数。但在实际生活中,时间序列数据长度有限,有时难以准确判断E1(m)为否已达到收敛状态,因此,额外定义

(6)
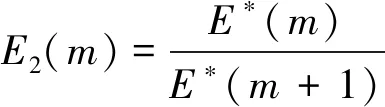
(7)
若E2(m)的值恒为1,则表明所选时间序列为随机时间序列,数据间无相关性;若其不恒为1,则表明时间序列数据间的相关性受嵌入维数m影响[19],因此可以依据E1(m)和E2(m)的值共同确定出最佳嵌入维数。
图10为4组时间序列数据的E1(m)和E2(m)值,由图10可以确定A1,B3,A5,B7的最佳嵌入维数分别为6,5,6,6。

图10 Cao方法选择嵌入维Fig.10 Determine embedding dimension through Cao method
得到A1,B3,A5,B7四组时间序列的最佳延迟时间τ和嵌入维数m后,采用小数据量法分别计算其最大Lyapunov指数,结果见表2。由表2可以看出,4组时间序列的最大Lyapunov指数均大于0,所以可以判断A1,B3,A5,B7四组时间序列均具有混沌特征。
表2 最大Lyapunov指数
Table 2 Largest Lyapunov exponent

时间序列A1B3A5B7最大Lyapunov指数0.020 90.024 10.015 70.032 6
3.3 Volterra自适应滤波预测
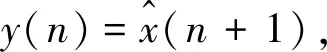

(8)
式中,hp(m1,m2,…,mp)为p阶Volterra核;m为滤波器的输入维数;N1=N2=m≥2D+1。
文献[20]指出,要实现一个混沌时间序列完全描述出原动力系统的动力特征,至少需要m≥2D+1个变量,所以可取N1=N2=m≥2D+1。
定义U(n)和H(n)分别为滤波器的输入矢量和系数矢量:
U(n)=[1,x(n),x(n-1),…,x(n-m+1),
x2(n),x(n)x(n-1),…,x2(n-m+1)]T
(9)
H(n)=[h0,h(0),h(1),…,h(m-1),h2(0,0),
h2(0,1),…,h2(m-1,m-1)]T
(10)
因此,式(7)可表示为

(11)
对于二阶Volterra自适应滤波器,可采用的自适应算法为时间正交自适应算法。
本文分别使用A1,B3,A5,B7四组时间序列的前472个数据为训练样本,后20个样本为测试样本,Volterra模型沉降预测结果如图11所示。
由图11可以看出,二阶Volterra自适应滤波预测结果在短期内可以很好地反映出真实值的变化规律,预测绝对误差在可接受范围内波动,预测精度较高,但随预测步数的增加,预测效果逐渐下降。
为进一步评价沉降预测结果的优劣,采用下述3个指标进行度量:
(1)平均绝对误差
(12)
(2)平均相对误差

(13)
(3)均方根误差

(14)
其中,n为预测样本数;xd(i)和x(i)分别为i时刻对应的预测沉降值和真实沉降值。经计算,预测模型各指标见表3。
表3 Volterra自适应预测预测误差
Table 3 Error of Volterra self-adaptive prediction%

时间序列前10步MAEMAPERMSE后10步MAEMAPERMSEA10.590.060.7616.471.7020.86B34.651.005.7722.123.8529.64A51.590.672.2054.0714.1063.69B73.572.223.9141.5811.7953.14
基于表3的统计结果,得出二阶Volterra自适应滤波对4组时间序列的前10步预测结果精度都很高,平均绝对误差(MAE)、平均相对误差(MAPE)和均方根误差(RMSE)均在6%以下,实现了沉降时间序列的高精度预测,分析其原因在于二阶Volterra自适应滤波避免引入其他干扰因素数据,仅从沉降数据本身出发,综合利用了训练样本中的线性与非线性因素。而随着预测步数的增加,如后10步的预测,其MAE,MAPE和RMSE相比于前10步大幅上升,表明预测结果精度的大幅下降。这证明二阶Volterra自适应滤波仅适用于沉降时间序列的短期预测,将其应用于长期沉降预测结果不可靠。
4 结 论
(1)引入小基线集(SBAS)技术利用sentinel-1 A数据监测内排土场沉降,因内排土场植被覆盖度极低,sentinel-1 A数据时间分辨率高,多余观测多,所得沉降数据精度和可信度高,为露天矿内排土场沉降监测提供了新思路。
(2)内排土场沉降剖面呈现明显的半漏斗状,总体上累积沉降量与到矿坑的距离成反比,通过累积沉降量将内排土场划分为了8个区域,通过对8个区域上随机两点的沉降速率分析可得,Ⅰ,Ⅱ区域处于沉降活跃期,存在滑坡、泥石流风险,是后期沉降监测的重点区域,Ⅲ~Ⅶ区域步入稳定过渡期,Ⅷ区域已基本稳定,初步判断该区已基本满足了土地复垦及建设简单构筑物的基本要求。
(3)依据A1~A8的覆土时间差,对A1累积沉降量进行曲线拟合,得A1最终下沉量约为662 mm,下沉量达到相对稳定约需1 320 d,定义内排土场下沉系数为地表最终沉降量与初始覆土高度的比值,求得观测周期内,内排土场下沉系数约为0.639 cm/m。值得注意的是,A1点沉降监测时间受限于原始数据,略晚于真实覆土时间,而覆土初期是沉降剧烈期,因此本文求出的下沉系数小于实际下沉系数,只能作为后续研究的参考。
(4)针对SBAS技术得到的沉降量时间序列,从中任选4点,分别求取其最佳延迟时间τ和嵌入维数m,经检验4组序列数据均具有混沌特征。
(5)运用混沌理论中的相空间重构理论结合二阶Volterra自适应滤波对沉降量进行预测,预测结果在短期内与真实值吻合较好,但随预测步数增加,预测误差逐步增加。表明二阶Volterra自适应滤波可对SBAS获取的一维沉降观测数据进行有效地短期预测,而其对沉降的长期预测结果不可靠。
