基于改进型决策树SVM的图像识别方法
2019-01-27潘燕
潘 燕
(福建农业职业技术学院 信息技术学院,福建 福州350007)
决策树技术的核心用途主要有两个:分类和预测。该技术着眼的分类规则是由一组无规则的事例推理出决策树表达形式,它采用自顶向下的方式,在决策树的内部节点对属性值进行比较,根据不同属性判断从某节点向下的分支,并在决策树的叶节点处得到结论。整组事例中的每一条规则都在决策树上的根节点到叶节点上体现出来,整棵决策树对应着整组规则的排布。以决策树算法为基础的分类模型有一个极为突出的优势:不需要任何领域知识和参数的假设,就可以生成可以理解的规则[1]。
以决策树算法为基础的分类模型有如下特征:1)分类原理简单,通俗易懂;2)分类效率高,被广泛应用于大数据分类;3)运用决策树进行分类时,不需要对训练集数据以外的知识进行学习;4)工作精度高,分类准确[2]。
作为决策树核心分类方法之一的SVM(support vector machine)有三大优势:1)构造的分类器少;2)不存在分类盲区;3)分类时,不必应用所有分类器。由于具有这些优势,SVM算法多用于解决多分类问 题[3]。
下面将研究一种改进型决策树SVM分类方法,并将其应用于图像识别中,以检测该算法的分类性能。
1 支持向量机
支持向量机是一种用于机器学习的方法,它以统计学习理论为基础,通过寻找结构化风险最小的途径来增强学习能力,达到经验风险和置信范围最小的目的。该算法可以实现从数量较少的样本中获得最优的统计规律,即寻求出正、负分类的最大间隔[4-5]。
假设用于支持向量机训练的样本为 {(xi,yi),i=1,2,…,l},其中l为训练样本数。当训练样本集线性可分时,最优的分类超平面为

式(1)中:w为分类超平面的法向量,决定了分类平面的方向;b为位移量,决定了分类平面与原点的距离。最优的分类平面是将支持向量机样本分开的线性函数。
可以将问题理解为对优化问题

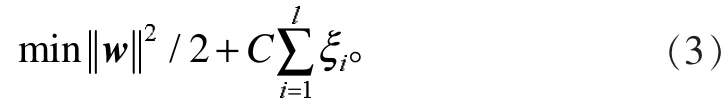
通过拉格朗日算子对上面优化问题进行求解,得
到最优决策函数为
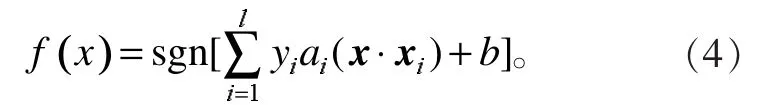
支持向量的ai通常在全体样本中所占的比例很小[6-7],因此,可以用较少的支持向量完成对整组样本的分类。在解决非线性分类问题时,SVM通过运用核函数把样本转化到某个特定的高维空间H,并在空间H中对事例进行划分[8],运用Mercer条件,将对应的最优决策函数处理为

2 决策树支持向量机
决策树支持向量机工作时会首先将整组事例划分为两组子类,再对两组子类继续划分为4个次子类,以此类推,直至划分到每个节点只包含一个单独类,最终生成叶子节点,形成决策树。决策点采用SVM对其进行划分。
相比于其他两种传统分类方法 (1-a-1方法和1-a-r方法),决策树SVM具有如下优点:
1)决策树SVM不存在划分盲区,分类精度高、分类准确;
2)决策树SVM构造分类器数量少,对于N个分类事例,只需构造N-1个分类器;
3)随着分类层次的递增,训练样本数量和支持向量数量都在减少,大大减少了训练时间;
4)采用决策树进行分类时,单一训练样本不需要通过所有分类器,减少了分类时间。
采用决策树SVM进行分类时存在误差积累问题。假如在某一节点上发生分类错误,则该错误在后续节点划分时会延续,导致分类结果与真实结果相差较大。如图1所示,事例样本在决策节点SVM0处分类发生错误,导致最终的分类结果发生错误[9]。可见,决策树的分类结构与分类结果的准确性息息相关。为此,本文以解决多分类支持向量机的问题为核心任务,来构造一个可避免累计误差问题的改进型决策树结构。

图1 决策树SVM分类模型
3 改进型决策树SVM分类方法
SVM分类方法的优点是不需要海量的训练样本来对训练模型进行训练,而缺点是其惩罚因子(C和ε等)需要依靠建模人员的经验来选取,因此其分类性能具有较大的随机性。本文使用文献[10]中的模拟退火算法对支持向量机的参数进行优化选择,以提高决策树SVM分类方法的分类性能。
模拟退火算法在本质上是随机寻优算法的一种,它是以蒙特卡罗迭代求解方法为基础发展而来的。其根本原理与金属退火原理较为相似。运用该算法对SVM参数优化的详细过程如下:
1)定义初始参数,确定支持向量机中ε、C和σ等参数的取值范围:定义计数变量m和i,并赋初值为0。
2)以模拟退火算法为基础,对支持向量机进行参数优化。
校企合作课题研究师资培训活动从2012至2016年,持续开办了5年,总体来说取得了任何培训都无法达到的成果,成果最突出的要算和顺德职业技术学院的合作,通过创客式产品研发为合作契机,加上培训后期的持续合作,最终真正达到了校企合赢的目标,科研成果也是硕果累累,如获得了实用新型专利、获得了软件著作权证书、公开发表了教学改革论文、公开出版了教材、获得科技成果鉴定、获得了政府部门颁发科学技术进步奖、获得了行业协会颁发的科技进步奖、获得了科技厅产学研项目的资助等。
3)求解最优解。 如果 f(Xi+1)<fopt,则使 Xi+1=Xopt,f(Xi+1)=fopt,m=0;否则使 m=m+1。其中,f(Xi+1)表示函数取Xi+1时刻的值,fopt表示当前最优解。
4)判断随机抽样的稳定性。设检验抽样稳定性的阈值为 Nr,如果 m<Nr,则使 i=i+1,并重新进行 2);否则使m=0。
5)判断停止退火条件。 如果 fopt<k 时,温度为 Tk,则使j=j+1;否则使j=0。设j的阈值为I,检验精度为ε,如果 j≥I或 fopt<ε,则停止退火过程;否则进行 6)。
运用SA算法对支持向量机SVM进行参数优化时,可以对存储的数据进行提取,也可以对优化后的数据进行实时更新,确保可以凭借记忆来记录参数选择过程,同时SA算法也可对参数进行调整,减小结果误差。SA算法在提高逼近系统的精度和提高参数优化的速度方面具有显著效果。
需要特别说明的是,使用模拟退火算法对支持向量机的参数进行优化选择,会增加SVM算法训练运算的时间,但在实际操作中,运用决策树进行结构优化和训练学习过程一般都是一个离线过程,而以延长离线计算过程时间为代价换取决策树分类的准确性的做法是可取的。
4 图像识别应用实例分析
4.1 手势图像识别实例
(1)图像预处理
运用深度摄像采集手势图像作为分析样本。采集了10种共500张分辨率为640×480的手势图像用于样本训练和样本测试,随机选取其中的300张用于模型训练,其余用于分类性能测试。
处理过程是:先运用深度摄像机设备获取手势场景的深度图像;再运用深度信息对手势图像进行二值化处理,对无用部分和待识别手势部分分别进行0、1定值处理;最后将标志为1的区域,即待识别的图像放到一个特定区域内,采用膨胀、腐蚀和中值滤波方法等对图像进行去噪处理[11]。
常用的图像数据纹理特征分析度量算子有SURF、傅里叶描述子、几何矩。其中几何矩由于具有旋转、平移、尺度等特性的不变特征,又被称为不变矩。不变矩一般用来识别图像中较大的物体,对于物体的形状描述得比较好。在图像处理中,不变矩可以作为一个重要的特征来表示物体,可以根据此特征对图像进行分类等操作。因不变矩在笛卡尔坐标系下,由2、3阶归一化中心矩所构造的7个矩特征向量,不仅具有对灰度图像缩放及扭曲过程中所引起的变化特征描述值不变的特点,而且计算量更小,故在下面实验中将运用不变矩进行特征的提取,这样可以不计较手势和镜头间的距离变化,具有鲁棒性强的优势。手势图像识别流程如图2所示。

图2 手势图像识别流程
(2)识别精度分析
在图像分析中,图像质量的好坏直接影响识别算法的设计与结果的精度。因此在图像分析前,需要进行预处理。图像预处理的主要目的是消除图像中无关的信息,恢复有用的信息,增强信息的可检测性,最大限度地简化数据,从而改进特征提取、图像分割、匹配和识别的可靠性。一般的预处理流程为灰度化→几何变换→图像增强。
使用预处理方法对待识别的手势图像进行预处理,以提高识别效率。预处理后的10种手势图像如图3所示。

图3 预处理后的10种手势图像
使用常规的决策树SVM分类方法对手势图像进行识别,并和本文研究的改进型决策树SVM分类方法进行识别准确率对比。实验结果如图4所示。
实验结果表明:常规分类方法对10种手势的识别准确率均值为90.038%,改进型决策树SVM分类方法对10种手势的识别准确率均值为94.955%。改进型决策树SVM分类方法在进行手势图像识别时具有更高的识别精度。

图4 手势识别准确率的实验结果
4.2 交通标志识别实例
为使用交通标志图像识别实例对改进型决策树SVM分类方法的性能进行的验证,共采集了500个交通标志的图像。对交通标志图像进行预处理结果如图 5 所示[12]。
使用改进型决策树SVM分类方法对交通标志图像进行识别时,错误识别数为31个,分类精度为95.4%;使用常规的决策树SVM分类模型对交通标志图像进行识别时,错误识别数为52个,分类精度为89.6%。使用改进型决策树SVM分类方法相比常规的分类模型在进行交通标志图像分类时具有更高的识别精度。分类器性能指标的对比如表1所示。
从表1可以看出,改进型决策树SVM分类方法在训练时间上长于常规分类器,但是识别时间短于常规分类器,而识别精度要高于常规分类器。训练过程是离线进行的,属于离线过程,消耗较长的离线训练时间来提高分类器的在线识别精度是合理的。

图5 图像预处理

表1 分类器性能指标对比
5 结论
研究了一种改进型决策树SVM分类方法,并在图像识别中检测该算法的分类性能。实验结果表明:1)改进型决策树SVM分类方法与常规的分类模型相比,在进行手势图像识别和交通标志图像分类时均具有更高的识别精度;2)改进型决策树SVM分类方法的训练时间比常规分类器长,但是识别时间比常规分类短。
