基于中文宾州树库的依存句法分析器的比较
2019-01-21杨振鹏
杨振鹏
(南京财经大学红山学院,江苏 南京 210003)
近年来,依存句法分析发展迅速,已经成为自然语言处理方面的热点问题。国际上著名的自然语言处理会议CoNLL曾多次在会议的shared task中涉及依存句法分析问题。目前,针对依存句法分析的研究越来越多,技术也日趋成熟,依存句法分析器也得到了快速发展。基于汉语的依存句法分析起步较晚,2012年Che等人对汉语句法分析器进行了分析和研究,而此次研究是在斯坦福依存规则下开展的。虽然汉语依存句法分析起步较晚,但发展迅速,已经有多种依存句法分析器产生,而且大部分都适用于汉语依存分析的研究。目前,常用的、技术较为成熟的依存句法分析器主要有:斯坦福依存句法分析器、复旦大学依存句法分析器、哈工大依存句法分析器和最大生成树依存句法分析器。
本文首先介绍了语料的预处理方法及结果的评测标准;然后对四类依存句法分析器进行了详细介绍,重点对各分析器所采用的模型和算法进行了分析和对比;最后,总结了现有依存句法分析存在的问题,并对未来依存句法分析的发展进行了展望。
一、语料的预处理及评测标准
(一)语料的预处理
就目前而言,还没有比较成熟的依存树库的存在,尽管2002年Rambow等人曾做过早期的努力。由于句法分析发展较早,句法分析技术更为成熟,而且英语一直是研究的主流,因此英语的句法分析树库已经存在,并且日趋成熟。目前,英语中最大的树库是宾州树库,树库在句法分析中也引入了依存分析器,从而实现了依存句法分析。汉语的研究起步晚,汉语句法分析中,应用最广的是中文宾州树库(Chinese Treebank,CTB)。随着汉语应用的推广扩大,针对汉语的依存句法研究也成为研究的热点问题。Cheng等人曾在2003年就开展了汉语依存分析的研究,分别在CKIP树库和CTB树库上进行了依存分析的实验。实验时,将普通的句法分析结构转换为依存分析结构,并根据树形结构中的依存关系进行依存分析,实验取得了良好的效果。
目前,大部分的基于汉语的依存分析都采用了CTB,但CTB中的数据资源采用的是传统的句法分析结构也就是短语结构,不能够直接得到相应的依存分析结构。因此,对汉语进行依存分析之前,应先进行结构转换,即将短语结构转换为依存结构。结构转换的思想最早应用于英语的依存句法分析之中,Richard等人提出了利用中心词映射规则进行结构转换,这种转换方式被后续研究者所广泛采用。党政法和周强在2005年进行了汉语的依存研究,采用了中心词映射规则实现了短语树到依存树的自动转换。李正华、车万翔、刘挺等人在2008年也做过汉语依存分析的转换研究,提高了短语结构树库向依存结构树库转换的正确率。
实验采用的语料为CTB5.0,基于中心词映射规则对语料进行规范化处理,然后利用Penn2Malt工具进行依存结构的转换。转换结果如下图所示:

图1 CTB短语结构

图2转换后的依存结构
(二)依存句法分析的评测方法
性能评测是判断一个分析器好坏的重要标准,目前句法分析中最常用的评测方法是PARSEVAL。该评测体系有两个基本的评测指标:句法分析的精确率和召回率。具体表示如下:

对基于语料的依存句法分析系统,不再使用召回率,而是根据标记情况的不同,提出了两种正确率:无标记依存精确率(unlabeledattachmentscore,UAS)和带标记依存精确率(labeledattachmentscore,LAS)。具体表示如下:

二、目前主流的依存句法分析器
目前,技术较成熟、应用较为广泛的依存句法分析器有四个:斯坦福依存句法分析器(StanfordParser)、复旦大学依存句法分析器(CTBParser)、哈工大依存句法分析器(GParser)和最大生成树依存句法分析器(MSTParser)。
(一)斯坦福依存句法分析器
斯坦福大学拥有知名度较高的自然语言处理小组,其研究具有前瞻性,而且技术成熟,斯坦福依存句法分析器就由其设计完成。分析器是基于概率上下文无关文法(Probabilistic Context Free Grammar,PCFG)模型设计的,加入了词汇化依赖。此分析器不仅包含了短语结构的分析结果,也包含了依存结构的分析结果。网址为:http://nlp.stanford.edu/software/lex-parser.shtml。
PCFG是在上下文无关语法(Context-free grammer,CFG)基础上演化而来的,在CFG基础上增加了概率因素,对分析的规则设置一个概率值。PCFG常被用于语法解析问题,而语法解析通常采用树形结构,即将一个句子用语法解析树的形式显示,PCFG就是求取概率最大的语法树(也称最优树Tbest)。因此,基于PCFG的生成式句法分析模型成为当前应用最广泛的分析模型,最优树Tbest计算如式(1)所示:
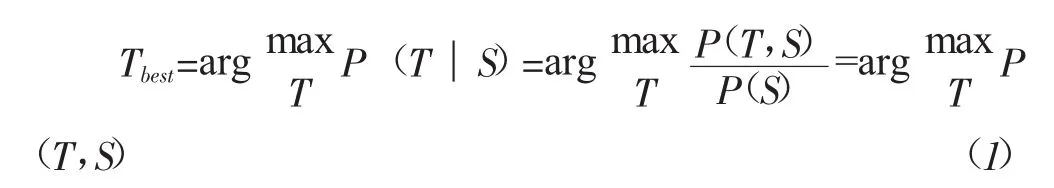
其中,代表联合概率,其采用了规则概率乘积的求解方式,如式(2)所示:
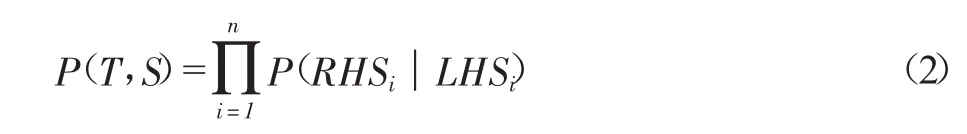
PCFG虽然应用广泛,但也容易造成数据稀疏的问题。为解决这一问题,分析器中还引入了马尔科夫模型(MarkovModel,MM),利用MM模型对规则进行优化。对分析中的规则对应于MM过程,利用先生成根结点,然后生成左结点,最后生成右结点的顺序进行优化。这种方式的处理很大程度地缓解了数据稀疏的问题。
斯坦福依存句法分析器为后续的科学研究提供了便利,Roger Levy和Christopher Manning曾在PCFG中引入最大似然估计因子,并在CTB上进行实验,实验取得了良好效果,F1值提高了1.9%,达到了82.6%。Pichuan Chang等人也利用斯坦福依存句法分析器进行了实验,在处理汉语的语法关系特征时引入了重排序(reranking)的方法,使得F1值提高到82.9%。
(二)复旦大学依存句法分析器
复旦大学也是开展自然语言处理研究较早的高校,其建立了一支高水平的自然语言处理小组,依存句法分析器由其设计完成。分析器是基于条件随机场模型(Conditional Random Field,CRF)设计的,不仅在句法分析中采用了CRF模型,而且在分词以及词性标注中均采用了CRF模型。用户使用的灵活度更高,可以自行编辑相关词条,扩展了分析器的适用性,可以对繁体中文作处理。网址为:http://code.google.com/p/ctbparser/。
CRF模型与PCFG模型相比优势明显,主要有两方面的优势:一是CRF模型对于特征的处理更加灵活,有效解决了特种处理中的标记偏置问题;二是CRF模型作为典型的判别式模型,将最大熵模型(MaxEnt)和隐马尔可夫模型(Hidden Markov Model,HMM)进行了融合,取长补短,特征融合、处理能力强。CRF模型在进行句法分析时,也引入了概率模式,采用了归一化的方式对概率进行了优化。模型最优树采用了条件似然值进行估算,候选句法树的概率估算形式如下:
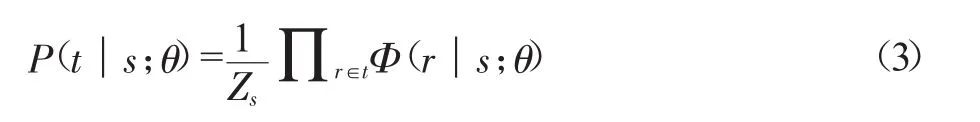
采用指数形式来求解团势函数:

训练数据的log似然值为:

特征和模型之间期望的差值是似然值对的θi偏导数:

复旦大学依存句法分析器在树形结构查询中优势明显,采用了二维查找树(2D Trie)来降低分析器的运行时间,与传统查找方法相比,运行速度提高了4.3倍。
(三)哈工大依存句法分析器
哈尔滨工业大学设立了语言技术平台LTP(Language Technology Platform),主要开展自然语言处理领域的研究工作,哈工大依存句法分析器则是LTP平台的一项研究成果。分析器采用了多种模型进行语料的分析和处理,采用CRF模型处理分词模块,采用支持向量机模型(Support Vector Machine,SVM)处理词性标注模块,采用最大熵模型来完成命名实体识别(Named Entity Recognition,NER)。哈工大设计的依存句法分析器(Graph-Based Parser,GParser)是基于图模型实现的,采用最大熵模型实现了语义角色标注(Semantic Role Labeling,SRL)。网址为:http://ir.hit.edu.cn/ltp/。
McDonald将依存分析问题转化为在有向图中寻找最大生成树(Maximum Spanning Tree,MST)的问题,这是首次提出基于图的依存分析方法。其原理为:针对图中可能输出的每一种结果树,都给定一个评分,然后利用动态规划思想,找到评分最大的那棵树。
基于图的依存分析方法实际为求解弧的最大评分的过程:
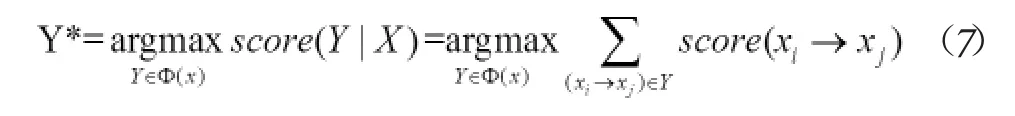
其中,X代表句子输入,Y代表候选依存树,xi→xj代表词i到词j的依存弧,Φ(x)代表输入X对应的可能依存树的集合。
(四)最大生成树依存句法分析器
最大生成树依存句法分析器也是基于图模型实现的,分析器是由Ryan McDonald和Jason Baldrige设计完成,分析器采用最大边缘的决策式训练模型,是一种非投射性的判别式依存句法分析器。网址为:http://www.seas.upenn.edu/~strctlrn/MSTParser/MSTParser.html。
MSTParser是采用条件概率模型,为图中每一条边设置一个得分,这样将寻找最优依存树的过程转化为求解得分最高生成树的过程。得分的设置通过特征向量以及权重向量之间的点规则来实现,具体表示如下:
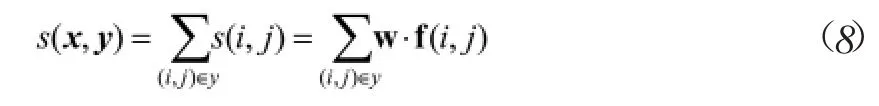
其中,x为输入的句子,y为输出中的依存树,s表示得分,(i,j)是依存关系中的结点对。f(i,j)是值为1或者0的二元特征向量,表示结点xi和xj之间的是否存在依存关系,1代表存在依存关系,0代表不存在依存关系。例如:“开”和“门”,则 f(i,j)=1,否则,f(i,j)=0。
最大生成树算法已经被广泛使用,成为研究的热点问题。其中,经典的Chu-Liu-Edmonds算法成为最常用、最高效的最大生成树算法。周惠巍、黄德根等人将最大生成树算法与决策式解析算法相结合,采用优势互补的原理进行中文依存句法分析研究。研究利用Nivre模型进行依存分析,并根据依存度对最大生成树有向边进行重新打分,再重复最大生成树的求解过程,结果作为最后的依存树。实验采用十折交叉测试的方法,对CTB中的4500句中文进行分析,F1精确率达到了86.49%。
为了便于比较分析,本文采用CTB5.0作为语料,对四种依存句法分析器进行性能测试,表1列出了各种句法分析方法在CTB5.0上的句法分析性能。

表1依存句法分析器性能比较
最大生成树依存分析器效果最好,复旦大学依存句法分析器效果次之,斯坦福依存句法分析器和哈尔滨工业大学依存句法分析器效果较差。最大生成树作为经典的算法,研究较多,技术较为成熟;利用弧的评分来计算最后输出结果的评分,准确率较高,但当搜索空间较大时,耗时较多。CTBParser利用CRF模型进行依存句法分析,对特征的融合能力比较强,可以结合多种特征方面的优势,识别效果较好。StanfordParser所用的PCFG方法,易于长距离句子的分析,对于短距离句子的分析,则效果较差。哈工大依存句法分析器虽然也是采用最大生成树算法,但是其分词和词性标注正确率较低。
三、总结与展望
近年来,依存句法分析发展迅速,依存句法分析技术也日趋成熟,现有的依存句法分析的研究仍存在一些问题亟待解决。
(1)结构转换:句法结构和依存结构之间需要进行转换。目前而言,转换的准确率还不是很高,主要是因为句子的结构通常较为复杂,如动词和动名词结构、同位结构等,算法处理准确率不高,进而影响转换的准确率。
(2)训练算法的改进:目前的训练算法比较单一,应考虑多种算法和模型进行多重训练,以提高算法的准确率。
(3)完善语料库信息:语料库是依存句法分析的基础条件,目前语料库的信息相对比较陈旧,应扩充语料库,增加一些新型结构的语料,同时针对新型结构语料进行对应的分析处理。
由于英语的依存句法分析研究较早,相关技术已经比较成熟,因此汉语研究中,许多研究都借鉴了英语的研究方法甚至是研究成果,虽然提高了汉语演技的速度,但也造成了一些适应性的问题。由于汉语和英语存在语法、语义等方面的问题,因此原样的生搬硬套不会取得实质性的进展。虽然中文依存句法分析近几年发展迅速,国内外学者也进行了很多研究和探索,但发展之路任重而道远。对于目前汉语依存的发展,笔者有几点看法:
(1)研究要结合汉语自身的特点。就目前而言,大部分的研究都是基于英语的,英语的研究也相对成熟。虽然汉语研究中借鉴了很多英语的研究方法,比如统计模型和解码算法等,但汉语本身结构、句式较为复杂,应结合汉语的自身特点开展研究,例如汉语中特殊语法结构(倒装句、叠词等)的处理。
(2)提高分析算法的正确率和效率。算法的正确率是计算机各类问题研究中普遍存在的问题,而依存句法分析算法的性能也直接影响最终的结果。目前常用的算法(CRF、PCFG、MST等)虽然相对比较成熟,但仍有可以改进和提升的空间,应加以研究以提升其算法的性能。
(3)利用语法、语义等方面知识构建联合模型来提高依存分析的正确率。最近几年许多国内外学者开始尝试使用联合模型来进行依存分析。李正华等人建立汉语词性标注和依存分析的联合模型;在2012年,Jun Hatori等人又提出将词义也加入到依存的分析当中,构建的词义、词性标注和依存分析的联合模型。联合模型开辟了一种新的思路,可以成为我们研究的一种方向。
