(2017年度“华苏杯”获奖论文三等奖)运营商客服通话信息的文本自动分类
2019-01-18胡波
胡 波
中国电信股份有限公司江苏分公司
0 背景问题
电信运营商客户服务热线承担着业务咨询、投诉、办理、障碍申告等职责。随着计算机语音识别能力的提升,目前各运营商陆续开展了语音录音文件向文本数据的转换工作,形成了大量的客服文本信息库,成为运营商大数据的一部分。目前,部分运营商在对客服拨打的客服电话进行大数据分析,挖掘潜在的内容价值,比如:发现热点投诉问题、客户业务咨询中的商机捕获、客户情绪评价等。但是,目前客服信息分类是通话结束后,由客服人员人为在系统页面中操作指定,主观性和随意性较大,从抽检来看,准确度不高。本文介绍如何利用文本分类技术,实现对运营商客户服务文本信息的分词、关键字评价,并实现自动分类模型;同时引入了深度学习的相关框架,对客服文本信息进行了分类尝试。
1 文本分类模型介绍
近些年来,随着大数据的相关技术发展,越来越多的非结构化信息得到存储和分析,文本分类是一个重要研究和实践方向。所谓文本分类是根据文本的内容,由计算机对未知类别的文字文档进行自动处理,判别它们所属预定义类别集中的一个或多个类别。近些年来,文本分类在舆情识别、商品评价、新闻分类等方面得到了应用。
传统文本分类一般采用“词袋”(bag-of-words)假设。所谓“词袋”假设是在自然语言处理和信息检索中的一种简单假设:在这种模型中,文本(段落或者文档)被看作是无序的词汇集合,忽略语法甚至是单词的顺序。
在“词袋”假设下,采用“有监督学习”的方法,主要思路是:从已打上分类标签的文档中提取特征,在特征的预处理的基础上,引入有监督模型进行特征值与分类标签的训练和模型迭代,在模型的准确性满足后投入实际的分类应用。与英文等文字不一样,中文的文本分类首先需要进行“分词”处理,在此基础上再进行特征提取等后续工作。以下是中文文本分类的一般建模过程:

图1 基于统计学习的中文文本分类一般性过程
1.1 中文分词
分词是从中文自然语言句子中划分出有独立意义词的过程。众所周知,英文是以词为单位的,词和词之间是靠空格隔开,而中文是以字为单位,不能天然形成“词”。计算机进行分词的基础是需要建立一个词库,将整理形成的中文词纳入到词库中。现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于统计的分词方法和基于理解的分词方法等。分词技术是做中文文本分析的基础,应用非常广泛。
1.2 特征提取
过高的特征维度是文本分类的一个显著特点,因为一个不重复的分词都可以视为一个单独的特征。为了兼顾运算时间和分类精度两个方面,不得不进行特征选择,力求在不损伤分类性能的同时达到降维的目的。常用的特征选择方法有文档频率方法(DF)、信息增益方法(IG)、互信息方法(MI)、CHI方法,以及期望交叉熵、文本证据权、优势率等方法。
1.3 分类建模
在分类算法的选择上,目前存在各种各样的文本分类算法,如朴素贝叶斯、文本相似度法(也称向量空间法)、支持向量机、K-最近邻、SVM等算法。其中朴素贝叶斯和支持向量机方法应用比较广泛,它们具有分类机制简单、处理速度快的优点。近些年来,随着深度学习的兴起,相关学习框架也陆续应用到文本分类中。
1.4 模型评价
数据挖掘中的模型评价有很多种,这里我们不考虑差异化的误分代价,误分情况采用混淆矩阵来刻画,总体用“召回率”“准确率”来评价模型。以下是混淆矩阵{An×n}的示意图表示:

图2 混淆矩阵示例
对文本分类结果,类别i 的“准确率”(也称“查准率”)定义为“预测类别i的集合中,实际为类别i的比例”:类别i 的“召回率”(也称“查全率”)定义为“实际类别i的集合中,被预测分类为类别i的比例”:模型的“整体准确率”定义为“被正确分类的样本数量占全体样本的比例”:(N为全体验证样本数量)。
2 建模实验分析
2.1 样本说明
建模实例为某个运营商大区呼叫中心,经智能语音识别工具识别,一段时间内总共有83500个客服沟通文本文件,每个文件为一次语音通话的识别内容。为了进行文本分类学习,先随机抽取出3000个文本文件,安排人员对其内容进行人工识别,打上分类标签,作为训练和验证的样本集。分类标签分为以下几类:

表1 文本样本集中各分类情况说明
2.2 建模环境
本文建模采用python(版本3.5.2)编写脚本,中文分词包采用jieba(版本0.18),文本挖掘采用通用挖掘工具包sckit-learn包(版本0.18.1),深度学习框架采用谷歌tensor fl ow(GPU版本1.2.0),软件均在Windows 10环境下运行。
2.3 建模操作
(1)步骤1:分词处理
分词之前涉及到两个方面的工作,一个是自定义词库的设置,一个是停用词的设置。自定义词库主要是将强化一些运营商产品和服务的相关术语、常用口头语,保证分词处理能够被识别为词,避免通用词库不能识别的风险,或者没有必要进行进一步划分。我们在样本生成的过程中,由业务资深人员确认了相关术语,加载到自定义库中,比如:“光猫”“网口”“翼支付”“移机费”“信用开机”“国际漫游”“10000号”“增值业务”等35个自定义分词。
为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。但是,并没有一个明确的停用词表能够适用于所有的工具。因此我们根据分词结果进行统计,将出现频率较高但无实际价值的分词,加入到停用词库中,比如:“坐席”“为您服务”“谢谢”等。该步骤的进一步完善与下面“步骤2”的特征提取操作结合在一起。
(2)步骤2:特征提取
基于上一步骤的分词处理结果,我们提取出6354个特征维度(即不同分词),我们通过文档频率方法(DF)进行特征筛选,具体做法是将分词在全部文档中,进行最高、最低频率排名,通过业务甄别将频率过多、过少,且对文档分类价值不大的通用沟通词语,比如“请稍等”“如果”“那么”等进行剔除。
我们剔除了文档频率超过3000的分词,大多数是通用语气词、过渡词,以及文档频率不足10的分词,大多数是未正确语音识别的词语。通过筛选,最终我们将参与建模的特征值数量控制在2000左右。
为了后续模型训练处理,将特征信息(分词)和文档标签放置到一个矩阵中去,以下是矩阵的表现形式,其中wij是权重参数:

图3 文档-特征权重表达式
wij权重的表示、计算常用以下方式:
(1)BOOL(布尔)权重,bij值为0或者1,表示特征i与文档j是否有联系;
(2)TF(词频)权重,TFij表示特征i在文档j的出现次数;
(3)TF-IDF(词频-逆文档频率)权重,wij=TFij×log(N/DFi),N表示文档数量,DFi表示特征i出现文档的次数。
(3)步骤3:分类建模
我们分别采用上述3种权重表达方式参与分类建模。我们采用Naive Bayes(朴素贝叶斯)、SVM(支持向量机)以及DNN(深度神经网络)三类算法进行文本分类的建模。其中,朴素贝叶斯和SVM在文本分类场景中已经得到广泛的使用。我们尝试采用深度学习框架应用到本文本分类场景中。
在深度学习算法中,DBN(深度信念网络)应用于文本分类中,CNN(卷积神经网络)和RNN(循环神经网络)考虑到上下文因素,更多应用到短文本/语句的分类识别,从实践来看,很少应用在文章长文本分类场景。DBN算法的核心是采用无监督的算法对模型进行预训练,使得预训练参数在正式训练中得到较好的收敛效果。不过,近年来GPU计算能力得到较大提升,Relu、Dropout等建模技巧对模型参数初始化要求减低。因此,这里提出采用DNN(深度神经网络)作为深度学习的算法,综合采用Relu、Dropout等学习技巧。DNN的模型结构示意图如下:

图4 DNN建模示意图
说明:第1层是特征输入层,根据特征提取步骤的处理,输入变量为2052个;第n层(输出层,softmax层)节点数量为12个,即每个分类为一个输出节点。
(4)步骤4:模型评价
3000个打好标签的样本集中,随机抽取2000个样本参与建模,剩下1000个样本进行验证,以下是建模效果比较:

表2 三种模型的建模效果
我们发现,采用DNN网络在训练集上的效果非常好,但在验证样本集上验证有所降低。不过从验证样本集效果来看,DNN效果还是最优。由于DNN模型的TF特征选取在测试集中达到了最优,我们确定采用它进行建模迭代。为了进一步检查模型误分的情况,对混淆矩阵进行了进一步的分析(标号对应含义请参考表1):
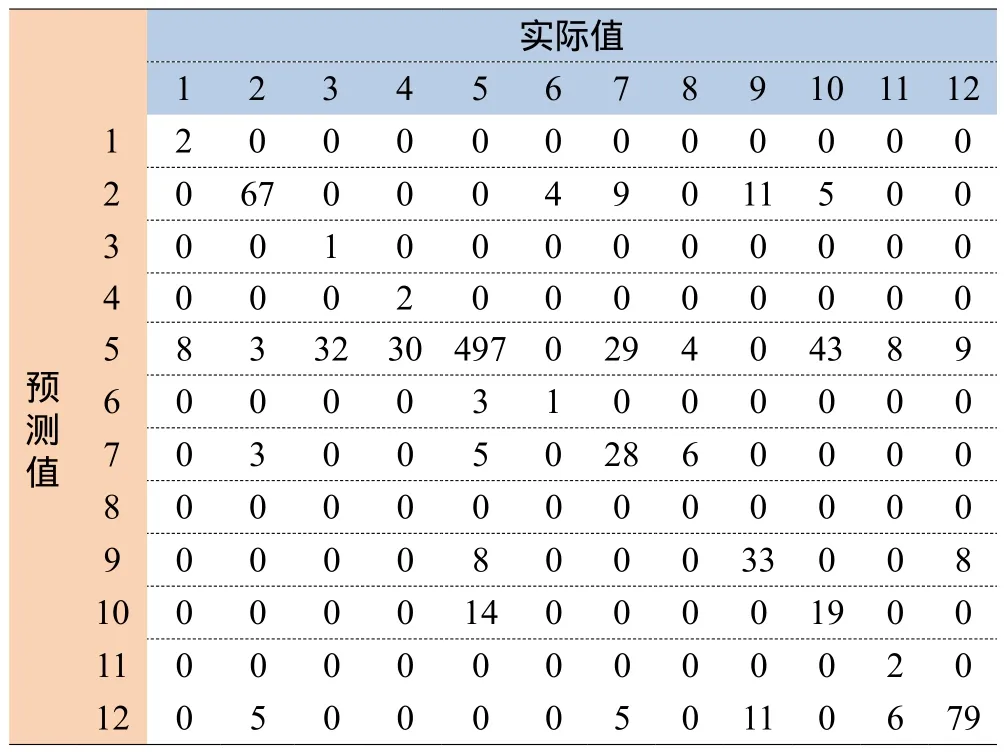
表3 基于验证样本集分类的混淆矩阵
针对表3的混淆矩阵分析,我们发现预测主要问题集中在标号5(即“宽带报障”类别)的误分上。原因是部分分类占比太低,使得一些算法模型难以进行识别,我们在数据挖掘中称之为“薄靶”,比如运营商客户流失的预测(流失客户占比在2%左右)。在这种情况下,我们可以参考其它建模领域中的“分层抽样”,人为加大一些标签的分布占比,来处理“薄靶”的数据分布。
分层抽样采用的具体方法,就是分别从不同的分类中、采用不同的抽样比值。我们将标号5的抽样比例从66%降低到22%,以提高其他分类的比例。通过分层抽样,误分为“标号5”的数量大大减少,验证样本集的准确率提升到88.3%。准确率进一步提升,模型算法的优化是一个方向,但主要还是要依靠“语音识别成文本”准确率的提升,我们发现目前在非标准普通话的识别中还存在较大差错率。
结合客服的日常管理要求,我们认为准确性具有一定可用性。目前已经在客服部门布署了该模型,每月自动分类处理180多万文本文件,主要用来:(1)分析各个分类的趋势,发现异常情况;(2)同时对人工指定不一致的通话分类进行抽样检查,对话务员的错误分类进行纠偏和考核,提升了质检效率。
3 结语
我们尝试采用机器学习算法对语音转换文本进行自动分类,并达到了预期效果。在建模过程中,我们在传统方法的基础上引入了深度学习算法,通过比较发现在运营商客服的沟通场景下,采用“词频权重(TF)”结合深度学习DNN算法是最佳算法实践。同时进一步针对部分小比例分类进行分层抽样操作,通过分层抽样的方式,有效解决“薄靶”问题,整体达到较高的文本识别准确率,满足了对运营商客服大数据进行分类管理的需求。
