基于修辞结构理论的多模态语料库研究
2019-01-15张培佳冯德正
张培佳 冯德正
(香港理工大学英文系,香港)
提 要 多模态语篇分析发展到今天,面临的主要挑战是缺乏基于大量语料的实证研究,尤其是对平面媒体图文语篇的语料库研究。究其原因是图文语篇的多维特性导致多模态语料库的标注难度极大。而以修辞结构理论为重要基础的GeM模型是现有标注图文语料最系统的理论框架。本文以流程图的方式展示了GeM模型的应用步骤,以公共卫生海报语料库为例演示了修辞结构的XML标注,并介绍借助计算工具gem-tools实现自动生成修辞结构图、统计语料库数据、检索修辞关系等多模态语料库研究的基本方法,以期为国内学者进行多模态语料库建设与实证研究提供有效的理论与方法。
一、 引 言
多模态语篇分析自20世纪90年代兴起以来,研究者们已从社会符号学、互动分析、会话分析、语用学等不同角度出发构建理论框架和探索分析方法,但在理论建设和研究方法上仍有诸多局限,其面临的主要挑战是缺乏实证研究(Bateman 2014b;Batemanetal. 2017)。多模态语篇分析沿袭了语篇分析、会话分析等学科的理论驱动的阐释性方法(hermeneutic method),而非语料驱动的分析方法。研究者们通常是提出一个理论框架,然后选取几个典型例子证明理论的可操作性,语料起辅助作用。但一方面理论需要在真实的语料中验证,另一方面质性文本分析中语料的代表性与分析结论的普适性受到局限(Bateman 2014b:238)。Bateman(2014b:238)进一步指出,在多模态理论创始阶段,用个别例子演示分析框架是非常必要的。然而,随着多模态研究的发展,研究者亟需通过大量真实的语料来验证、评估多模态理论是否具有普适性。从语用学的角度,黄立鹤(2017:27)同样指出,多模态语料库的方法可以为语用研究增加定量分析的客观性,从较大程度上弥补传统语用研究的不足。因此,只有更广泛地引入语料库方法,更充分地利用数据科学,才能对日趋复杂的多模态语篇进行全面而深入的分析,保证多模态研究不断向纵深发展。
多模态语料是指包含文字、图像、副语言特征、表情、手势等复杂表意的资源(詹姆斯·马丁、米歇尔·扎帕维尼娅2018),大致可分为实时性和非实时性(real-time/non-real-time)两类(Matthiessen 2009)。国内外多模态领域已认识到系统化语料库建设与研究的重要性,但很多研究只是解释标注方法,真正意义上的多模态语料库标注与研究寥寥无几。同时,大部分研究关注的是视频形式的实时性语料(自然会话/即席话语),从会话分析或语用学视角基于时间轴对语言、副语言特征、肢体语言等进行标注(Adolphs & Carter 2013;Allwoodetal. 2003),而很少有对广告、漫画等具有明显修辞设计的非实时性平面媒体语篇的实证分析。究其原因是实时性语料沿用了会话分析等学科对副语言特征、手势等比较成熟的标注方法(Goodwin 1981;Schegloff 1984),而平面媒体的语篇特征,如语义关系、表达方式等,则没有系统的标注框架可以综合分析。这方面,体裁与多模态(Genre and Multimodality,GeM)模型(Bateman 2008)作为第一个多层描述分析多模态语篇的框架,为标注平面媒体语篇提供了有效工具。然而,该框架尚未被广泛应用于多模态语料库研究。目前已建成的GeM标注语料库只有三例,即Thomas(2009)标注的英国和中国台湾的牙膏、洗发水等日用品包装,Hiippala(2015b)标注的赫尔辛基旅游宣传册与Zhang(2017)标注的纽约和中国香港的公共卫生海报。本文首先介绍GeM模型并讨论为何修辞结构的分析是多模态语料库建设的重要层次,着重阐述如何将修辞结构理论(Rhetorical Structure Theory,RST)(Mann et al. 1992;Mann & Thompson 1988)扩展应用于非实时性多模态语篇分析。随后,本文以公共卫生海报语料库(Zhang 2017)为例,演示如何使用可扩展标记语言(eXtensible Markup Language,XML)标注平面图文语篇的修辞结构、如何利用计算工具gem-tools(Hiippala 2015a)进行GeM标注语料库研究。最后,本文在展示基于GeM模型应用RST构建多模态语料库的基础上,讨论此类标注语料库对多模态研究的优势以及未来发展的挑战。
二、 多模态语料库建设:GeM模型与RST
John Bateman等人于1999至2002年期间在斯特灵大学和不莱梅大学成立GeM项目组,开发一个旨在从多模态体裁的角度来解释多模态语篇视觉风格(包括版式、排印等)上的一致性与多样性的框架,即GeM模型。项目组假定体裁在多模态语篇的版式结构、印刷式样和空间布局等的选择上有一定的制约,以及对语篇的修辞结构和布局结构之间的转化有一定的影响(Bateman 2014a:32)。为论证这一假设,项目组采用语料库驱动的方法来设计GeM模型以支持实证研究。他们以插图书籍、说明书、印刷版和网络版报纸作为研究对象,探讨这些非实时性语料的物质载体(纸张或电脑屏幕)及所使用的符号资源(文字、照片、插图 、图表、表格、地图等)等,并以此确定模型的必要分析层。
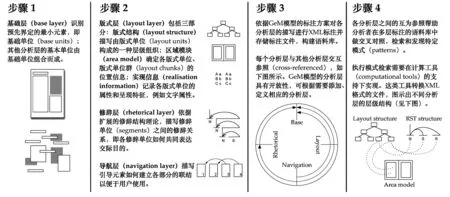
图1 GeM模型应用步骤(译自Hiippala 2017:278)
鉴于符号模态(semiotic mode)种类繁多难以作出清晰的界定,Bateman(2008)区分了三类主要的模态:文本流(text-flow)、图像流(image-flow)、页面流(page-flow)。文本流以线性展开逻辑文本实体;图像流以序列(sequence)连接相关元素,如由多个元素构成的一个图表、一幅漫画等;页面流以空间距离、元素群组(spatial proximity,grouping of elements)等统筹更多具有修辞功能的单位实现语篇的交际目的。根据这些定义,项目组选取的任何一个多模态页面(如动物图鉴、电话机使用说明书等),都可以视作是多种符号模态(如文本流、插图、图表等)相互协调与整合的多模态修辞结构体。因此,与交际目的的实现紧密相关的修辞结构、修辞潜势的研究是多模态语篇分析的关键一环,也是GeM模型描述多模态语篇的重要组成部分。除此之外,该模型还涵盖内容层中各符号系统的体现形式如文字特征等。项目组共设置了四个必要分析层:基础层、版式层、修辞层、导航层(详细介绍见图1),并开发了第一套使用XML多层标注非实时性语料的方案(Henschel 2003)。
其中,修辞层借助RST分析多模态语料的修辞结构。以描写语篇结构为出发点旨在实现自然语篇的计算机生成,William C. Mann、Sandra A. Thompson和Christian M.I.M. Matthiessen于20世纪80年代初在南加州大学创立了RST。该理论从功能的角度解读各小句、句子、段落等语篇单位,通过对各单位之间修辞关系的分析来解释语篇的整体性、连贯性和层级性。RST一诞生就为语篇分析提供了可行的理论框架(Delin & Bateman 2002;Matthiessen & Thompson 1988),也为语篇的自动生成带来了建模上的灵活性(Hovy 1993;Moore & Paris 1993)。尽管RST在语篇分析、生成等不同学科领域有相当的影响力及广泛的适用性(Taboada & Mann 2006),但也有学者质疑理论本身及其应用,主要包括语篇单位的切分、核心单位的确定等(Fritz 2014;Stede 2008)。当RST被扩展应用于多模态研究领域时,这两个问题就显得尤为突出。Bateman(2008:157-159)详细阐释了将RST应用于多模态语篇分析时四项特别值得注意的问题:修辞单位的界定、修辞关系核心性(nuclearity)的确定、修辞单位间的空间邻接性以及同一修辞单位的重用现象(the reuse of a span/segment)。
第一,RST的研究始于小句,逐步过渡到句子、段落和语篇;但在多模态研究领域,这一分析模式将被打破。多模态语篇的最小修辞单位可以是比小句更小的元素。GeM项目组界定了可满足项目研究要求的基础单位(Bateman 2008:111)。例如图表或列表中的基础单位包括图、图表标题、图表中的文字、列表起始句、列表条目。这其中不少基础单位往往由小于小句的名词短语甚至单词构成,但都是修辞单位并通过一定的关系被连接起来:图表中的图与标题可构成详述(elaboration)、多核心重述(multi-nuclear restatement)、识别(identification)等关系;列表中的起始句与条目可构成类别从属(class-ascription)、属性识别(property-ascription)等关系(Bateman 2008:160-163)。识别等关系是GeM项目组为处理多模态修辞现象而进行的扩展(冯德正等 2016:50)。RST最初定义了24种修辞关系(Mann & Thompson 1988),但修辞关系集具有开放性。在多模态、多语种等研究领域,分析者可根据研究目的细化和补充关系集,例如Carlson等(2003)的树库团队设计了78种修辞关系。
第二,修辞关系核心性的确定。多模态语篇中的图像往往极富视觉冲击力,这也加大了判断核心性的难度。例如当图像与文字构成详述关系时,很难判定哪一个是核心。在此类情况下,我们可以选择多核心关系来避免判定的任意性(Bateman 2008:159;Matthiessen待发表)。图2展示了两个常见的标志牌及多核心关系的RST图式。图2a提醒大众在此区域禁止吸烟,禁烟图标和文字“no smoking”表达的意义一致,构成多核心重述关系。图2b提示道路使用者右侧为公共入口,文字“public access”和右箭头图标表达的意义相互叠加,共同预告入口设施及方位,构成多核心增添关系(addition)。Matthiessen(1995、待发表)系统化重构RST,对判断修辞关系的核心性提出了核心性连续体(nuclearity cline)的概念。例如在漫画、新闻等体裁中常见的投射关系(projection),对于说话人(projecting)与说的话(projected)之间是否构成单核心或多核心关系,构成单核心关系的情况下哪个语篇单位为核心,Matthiessen(待发表)指出判断核心性应根据作者想要表达的交际效果,即不同的取向性(orientation)而定:若对说话人的表达更具主题性,说话人为核心(若更强调主题,即以说话人为核心);若对说的话的表达更具表述性,则说的话为核心(若更强调话语表述的内容,则以所说的话为核心)(可参阅Matthiessen & Teruya 2015)。

图2 多核心修辞关系的示例(Matthiessen待发表)
第三,修辞单位间的非线性排列。传统上,RST分析呈线性排列的句子及更高层次的语篇单位。但是,多模态语篇具有“多角度、多起点的特点,能够从左到右、从上到下、从中心到边沿组织信息,甚至是三种角度的结合,或者是相反的过程”(张德禄2012:126)。因此,修辞单位间的相互毗连,呈现二维甚至三维的空间排列,例如漫画中的元素覆盖(overlay)现象。Bateman(2008:158)认为分析者可以遵循多方位邻接原则(adjacent in any direction)来处理这一问题。
第四,同一修辞单位的重用现象。例如使用说明书中的插图往往既可以呈现产品的某一特定部分来帮助使用者识别,又可以展示某一具体操作动作。举例来说,在iPhone使用手册的“开始使用”部分,手机侧边的SIM卡托盘及回纹针这一图例让iPhone用户一方面清楚该部分所在位置,另一方面了解如何安装、取出或更换手机中的SIM卡。这一图例因此可与多个修辞单位形成修辞关系。但在具体分析中,为维持修辞结构的树形层级性,Bateman(2008:159)不建议重复使用同一修辞单位。
三、 多模态语料库建设:标注、图示及分析
1. 语料库简介
本节以基于GeM模型多层标注建立的CPHP(Corpus of Public Health Posters)(Zhang 2017)为例,演示基础层和修辞层的标注、图示,并介绍基于CPHP的多模态修辞研究。CPHP分为两个子语料库,即CPHP-NYC和CPHP-HK,涵盖选自纽约和中国香港的公共卫生海报各30张。语料涉及健康饮食、体能活动、非传染病、传染病、口腔卫生、健康保险、器官捐赠、吸烟、吸毒、饮酒等20多个健康主题。本节选取CPHP-NYC中的一例海报NYC-2(见图3)来作具体演示。NYC-2是Read’em Before You Eat’em公众教育运动的海报之一,展示于纽约地铁站等公共场所。2008年,纽约成为美国第一个强制要求连锁餐厅在菜单上标示卡路里的城市,并出台了标准的菜单标示法。该宣导活动随之产生,提醒消费者用餐时查看卡路里含量并作出健康的选择。

图3 健康教育海报示例NYC-2
2. 语料库标注
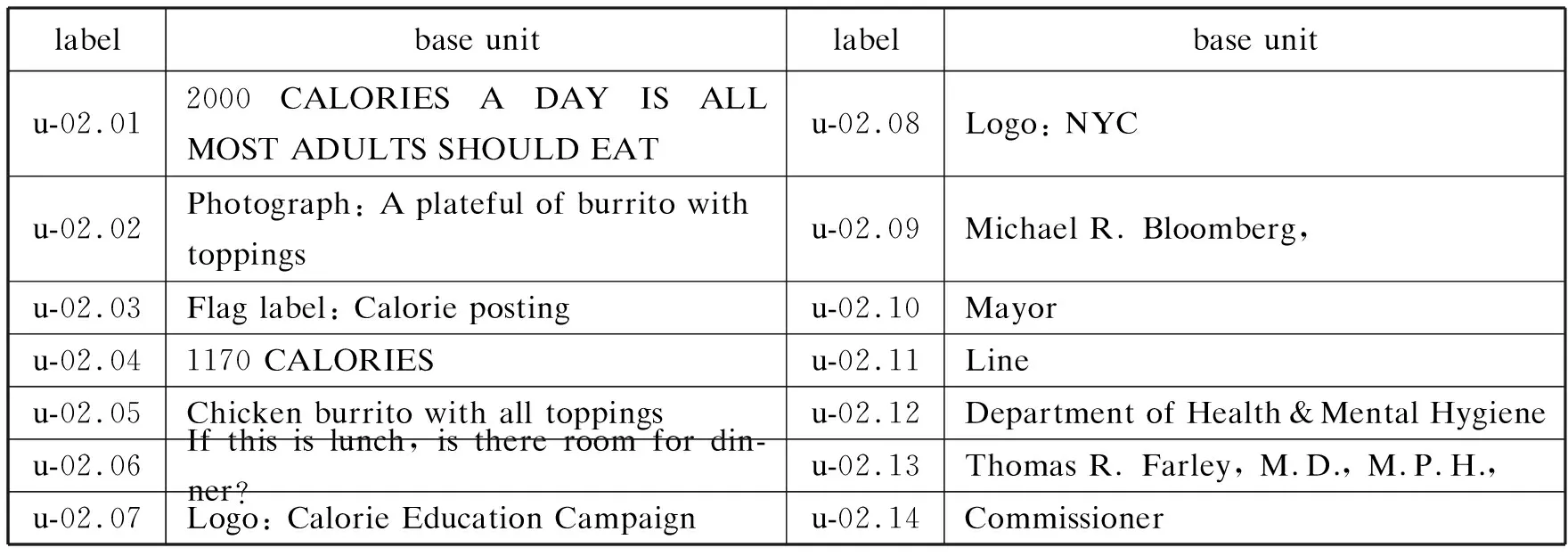
语料库标注的第一步是确定、识别基础单位(见图1),基本原则是相对最小性与客观全面性。基础单位的最小性(atomicity)是相对于其他分析层的基本单位而言的,基础单位是修辞单位等的组成基础(Bateman 2008:111)。所有文字元素甚至可以以单词为基础单位进行标注,再在其他分析层进行组合,但为了避免基础层的代码爆炸,一般研究都无须把单词界定为最小元素。此外,利用功能、体裁等特征可方便辨认及标识基础单位,但识别的客观全面性要求分析者保持独立判断,免受任何影响(如视觉感知特性、与研究的相关程度),不能过早组合或遗漏任何元素。所以NYC-2共包括14个基础单位,并使用id属性(u-02.01,u-02.02等)标识每个基础单位(见表1)。
labelbase unitlabel base unitu-02.012000 CALORIES A DAY IS ALL MOST ADULTS SHOULD EATu-02.08Logo: NYCu-02.02Photograph: A plateful of burrito with toppingsu-02.09Michael R. Bloomberg,u-02.03Flag label: Calorie postingu-02.10Mayoru-02.041170 CALORIESu-02.11Lineu-02.05Chicken burrito with all toppingsu-02.12Department of Health & Mental Hygieneu-02.06If this is lunch, is there room for din-ner?u-02.13Thomas R. Farley, M.D., M.P.H.,u-02.07Logo: Calorie Education Campaignu-02.14Commissioner
表1 NYC-2的基础单位
那么,如何标注这些复杂的基础单位、修辞结构呢?如何实现基础单位在其他分析层的可重复性以保证各分析层的交互式参照?如何使数据的处理能力(如统计、可视化、检索等)更强?如何使数据的修改、不同语料库之间数据的交换等更方便?GeM项目组使用可扩展标记语言XML来满足各类要求。限于篇幅,本文对XML的基础知识、特点等不作具体介绍。XML允许用户自行定义描述性的标签(tag)来标识数据,项目组因此设计了一系列标签,例如基础单位的标签为

图4 NYC-2的基础层标注
修辞层的标注包括两部分:修辞单位及修辞关系。不是所有的基础单位都是修辞单位。嵌入式基础单位、引导元素、某些图案元素如分隔线等不视作修辞单位(Henschel 2003:17-18);体裁的一些固定元素(如书信的称呼和信尾敬辞等)也不计作修辞元素。因此,除去海报出版机构的标志组合(logo lockup)等元素,NYC-2共包括6个修辞单位:海报标题、墨西哥卷饼图片、热量标示、图片小标题、公众教育运动标志、反问句。如图5所示,修辞单位的标签为

图5 NYC-2的修辞层标注
3. 语料库图示与分析
标注完成、验证后,利用计算工具gem-tools实现标注的可视化(如图6的修辞结构图)、统计语料库数据(如修辞关系出现次数、不同模态的使用比重)、检索模式(如RST图式)等。这套gem-tools针对GeM标注语料库开发,用程式语言Python编写代码,在交互式笔记本Jupyter Notebook中运行。Zhang(2017)在使用gem-tools过程中,发现、报告其缺陷,并协助Hiippala进行修正和改善;对不同体裁的语料进行反复测试后,gem-tools在体裁适用性、图示高清度等方面已得到了显著提高。运行命令启动Notebook,在Jupyter界面导入NYC-2的基础层、修辞层XML 文件,即刻输出图6。图示修辞结构可再次判定修辞关系分析的准确性、验证代码的有效性。相比之下,手动绘图费时耗力,只适合个案研究(如冯德正等 2016),RST绘图软件(如O’Donnell 1997的RST-Tool)既不如gem-tools快速便捷,也不具备合并不同层次结构图(如修辞结构和版式结构)等功能。
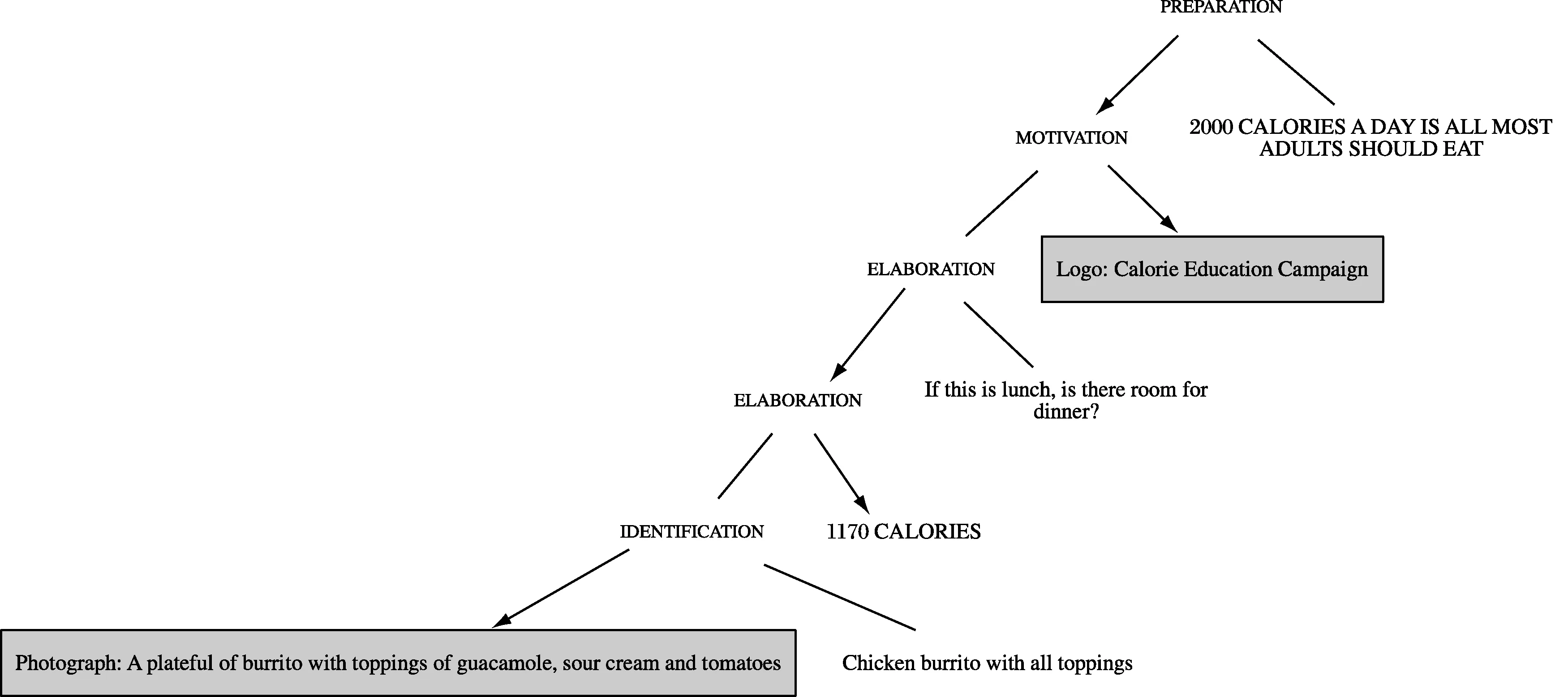
图6 NYC-2的修辞结构图
多层标注60张海报后,利用gem-tools统计与修辞结构分析相关的数据:29种修辞关系在CPHP中共出现了454次(见图7)。其中,详述、使能(enablement)、动机(motivation)、多核心重述、准备(preparation)等关系的出现频率较高。运用gem-tools搜索特定修辞关系,对比所选定关系RST图式中的核心、卫星单位,可以分析修辞关系在CPHP中的构成特征。例如,在Jupyter界面中输入“preparation”,准备关系的RST图式被突出显示,搜索数据显示其卫星单位往往是醒目的海报标题或/和视觉冲击力强的图像,这些卫星单位单独或共同在较短时间内吸引观赏者的注意力,并为整张海报的理解起准备作用。因此,以标注语料库实证分析的统计、检索信息为依据,结合对各符号资源的定性分析,可实现对不同修辞关系在检索范围内的使用情况的全面研究。接下来我们通过检索在CPHP中高频出现的几种修辞关系,简单讨论公共卫生海报的意义配置以及子语料库中海报的构意特征。
动机与使能这一对修辞关系在公益海报中的高频出现是可以预见的,但如何出现需要实证考察。输入“motivation”,搜索发现CPHP中所有海报的call-to-action(CTA),即动机关系RST图式的核心单位,几乎一律使用祈使语气,直接明确。例如NYC-1中的“CUT YOUR PORTIONS. CUT YOUR RISK.”和HK-17中的“记得醒目防晒!Be SunSmart!”。在子语料库中分别输入“enablement”,对比显示在CPHP-NYC中仍大量以祈使语气呈现相关资源,与CTA紧密呼应且数量适中,例如NYC-1中的“Call 311 for your Healthy Eating Packet”。在CPHP-HK中相关信息却几乎以名词短语的形式呈现,例如HK-17中的“免费热线 3656 0800 更多防晒贴士:www.cancer-fund.org/sunsmart”。CPHP-HK中的有些海报甚至逐条列出专题网站、健康教育热线等相关资源。输入“elaboration”,对比显示详述关系在CPHP-NYC中主要出现在文本流中,通过补充细节、提供实例等来进一步阐释与某一健康主题相关的知识及态度;在CPHP-HK中却分别大比例地出现在图像流、文本流中,或由海报标题与最明显的图像流构成。而CPHP-NYC中的海报标题与相关图像流往往构成多核心重述关系,图像本身易读性也高,使得共同表达的含义更加清晰明了。此外,CPHP-HK中象征性图像使用较频繁,比CPHP-NYC中同类图像的出现次数高出一倍多。因此初步分析表明,CPHP-NYC中的海报使人一目了然,CPHP-HK中的海报整体构意不够明确。这是否与海报设计者对公众视觉能力(visual competence)、文化背景等要素的不同预设相关,还需结合社会心理学、传播学、文化研究等理论进一步实证分析。虽然已经超出本文关注的范围,但我们需要强调将文本分析置于社会文化背景中进行阐释的重要性。
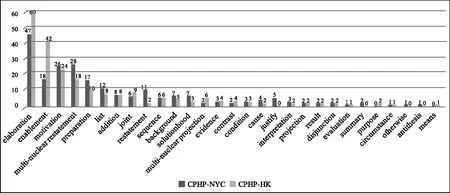
图7 CPHP的修辞关系统计图
最后需要说明的是,GeM模型的设计初衷并非是分析修辞结构,而是将多模态语篇视为多层次符号制品(multi-layered semiotic artefact)进行多层描述分析(Bateman 2008:108),如图1所示。此外,根据系统功能语法(Halliday & Matthiessen 2014:26),语言为四层次系统,即内容层的语义层、词汇语法层和表达层的音系、语音层或字系、字体层,而表达层的层次性对于多模态研究更为重要,因为人们需要知道表达资源是如何与其他各层的系统相关联及互动的。所以,虽然修辞层是GeM模型的重要部分,但建库分析更大的优势是依据各分析层的互相参照而全面、准确阐释多模态语篇的意义构建。例如,修辞结构与版式结构之间的关系被认为是对等的:修辞结构中的特定构型(configuration)会影响版式结构的设计,反之亦然。CPHP也包括各海报版式层的标注文件。通过对比修辞和版式结构、对照修辞单位在版式层的区域模块等,可以揭示不同语篇单位在设计、排印等方面的资源选择,有助于进一步分析多模态修辞潜势。多层标注的多模态语料库也是进一步研究多模态体裁、进行跨文化或跨媒介对比研究的理想工具。虽然有诸多优势,GeM模型的标注方案还需完善。版式层的标注方案主要针对格状基础的设计(grid-based design),如GeM项目组所选取的各类语料。对于不同设计的多模态语篇,我们无法依据现有的标注方案确定各版式单位及版式单位群的空间位置信息。以polygon的方式进行更灵活更精准的三维定位可以解决这一问题(Zhang 2017)。此外,标注方式的发展趋势是从人工标注到自动标注,应尽快开发基于Web的自动标注工具以提高标注的效率和精确度。
四、 结 语
作为语篇分析和生成的工具,RST已广泛应用于语言学、计算语言学、计量语言学、人工智能等领域及其交叉研究,但都只是对单一模态语篇的语篇结构等进行标注的语料库(Carlsonetal. 2002;Dasetal. 2015)。GeM模型则是唯一扩展RST建设多模态语料库的框架。本文展示了应用GeM模型建库的基本步骤,并演示了多模态语料库的修辞结构标注、图示及分析。总之,借鉴RST的GeM模型为多模态语料库建设提出了可操作的理论与标注方案,发展了多模态实证研究的技术方法;而基于此模型的标注语料库为更加系统、深入理解复杂多模态语篇的意义建构、模态关系以及多模态体裁空间(genre space)等概念提供了有力的分析框架与实证基础。事实上,从20世纪90年代多模态语篇的自动生成(Batemanetal. 2001;Matthiessenetal. 1995)到本世纪初多模态语料库的标注构建(Bateman 2008),RST一直起着关键性的作用,在多模态研究领域具有不可替代的优势。作为语言学者,一方面,我们应进一步发展多模态修辞结构理论、完善应用此理论构建多模态语料库的模型,通过大量的实证分析,研究多模态语篇的内容层、表达层等各个层次的特征、层次之间的关系,对比更多不同体裁的多模态语篇,据以加强多模态领域的理论建设。另一方面,我们应通过完善实证分析的研究方法增进与人工智能等领域的交流合作。例如为人工智能领域提供我们的语义标注数据并探讨各类数据的结合应用。鉴于此,语言学领域自身也应更广泛地布局人工智能,研究者可以了解人工智能诸多流派的研究现状、难题以及趋势,解决语言学与多模态研究的新问题并为人工智能研究提供新的思路。
