基于改进集成学习算法的在线空气质量预测
2019-01-09张晓龙
夏 润,张晓龙
(1.武汉科技大学计算机科学与技术学院,湖北 武汉,430065;2.武汉科技大学智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉,430065;3.武汉科技大学大数据科学与工程研究院,湖北 武汉,430065)
随着工业化和城镇化进程的迅速发展,人类生活质量日益提高,但能源大量消耗和污染物排放造成的空气污染问题也日趋严重,因此空气质量预测对指导人们的生活和工作具有重要意义,国内外研究人员对此也极为关注。
常用的分析及预测方法有统计分析、主成分分析(PCA)、BP神经网络、支持向量机(SVM)等。Yeganeh等[1]建立PLS-SVM混合模型来预测空气中的CO浓度,需要的计算时间要少于采用单一SVM方法进行预测。李远林[2]运用连续隐马尔可夫模型对兰州市未来24 h的PM10浓度进行预报。Byun等[3]研究的CMAQ模型和Grell等[4]研究的WRF/Chem模型能对大气污染物传输过程进行离线或在线模拟,但其工程应用较为复杂。Feng等[5]采用结合气团轨迹分析和小波变换的人工神经网络模型进行PM2.5浓度的日均值预测,但选取的特征变量较为单一,模型缺乏泛化能力。田静毅[6]、刘笃晋[7]等均运用BP神经网络方法进行空气质量预测,但 BP神经网络收敛时间较长,得到的属性特征量较少并且解释性不强。
目前针对空气质量预测的研究大多集中于离线、短时预报,参与建模的属性特征单一,并且数据量较少,有些方法又过于复杂,不便于工程应用。空气质量变化具有规律性弱、不稳定、易突变的特点,例如PM2.5浓度值变化范围大,低时可小于10 μg/m3,高时可超过300 μg/m3,并且在数小时内就有可能产生剧烈变化。这些特点为空气质量预测带来很大难度,需要不断研究新方法来应对。
XGBoost是基于Gradient Boosting算法的一个优化版本,其将多个回归树模型集成在一起,形成一个强分类器,具有训练速度快、可并行处理和泛化能力强等优势,已成功应用于路况预测、文本分类、电量预测、DDoS异常检测等领域[8-9]。然而通过对XGBoost模型进行评估和诊断后发现,它能较好地解决空气质量预测中的非线性问题且满足在线预测的性能要求,但有时也会出现性能不稳定的现象。为此,本文提出一种基于改进XGBoost算法的空气质量在线预测新方法。首先,针对收集到的空气质量数据集,采用数据融合工具对时间序列数据进行预处理,构造出含更多空气质量相关特征的数据集,同时采用Boruta算法[10]进行特征选择。然后,对XGBoost算法进行一阶导数和二阶导数优化,采用时间滑动窗口和模型权重衰减机制,不断训练新模型并且减少时间久远的学习模型的投票权重,最后通过Bagging集成学习方法[11-12]构成OPGBoost组合模型,用于离线-在线空气质量异常情况预测。
1 数据准备
1.1 数据格式
空气质量原始数据是通过传感器实时收集的,数据样本的格式如下:
(1)
式中:xi(t)为t时刻影响空气质量的第i个因素;y(t)={y1(t),y2(t)}为t时刻表征空气质量的指标,包括最受人关注的两个指标,即PM2.5浓度值(y1(t))和空气质量指数AQI (y2(t)),并且在影响这两个指标的因素集中可以存在k≠l,p≠n。
1.2 数据源
原始实验数据一共有3组,分别为实验室自采数据(采集时间:2016年9月~2018年2月,每小时采集一次)、武汉市和北京市的空气质量历史数据(2014年1月~2017年12月)。3组数据集大致都包括AQI、主要空气污染物(PM2.5、PM10、O3、CO、SO2、NO2、NOx、NMHC、CH4等)的浓度值以及重要气象数据(温度、湿度、风速和风向等)。
预测变量为PM2.5浓度和AQI。根据《环境空气质量指数(AQI)技术规定(试行)》(HJ 633—2012),按PM2.5浓度和AQI划分的空气质量等级如表1所示。
表1按PM2.5浓度和AQI划分的空气质量等级
Table1AirqualitygradedbyPM2.5concentrationandAQI

空气质量等级PM2.5浓度/μg·m-3AQI优0~350~50良35~7551~100轻度污染75~115101~150中度污染115~150151~200 重度污染150~250201~300严重污染>250>300
本文根据表1将PM2.5浓度和AQI的取值范围划分为两类:优和良划为一类,标记为反类;轻度污染、中度污染、重度污染和严重污染划为另一类,标记为正类。正类的PM2.5浓度值和AQI值属于空气质量异常范畴,需要通过预报以提请人们注意和重点防范。
1.3 数据预处理
由于数据采集过程中出现的非人为原因,导致原始数据集存在不完整、极少量数据异常等情况,会影响数据挖掘与分析的结果,因此需要进行数据预处理。
一般来说,处理缺失数据可以采用两种方法:一种是直接删除缺失样本,另一种是填写缺失值。由于本文中的时间序列数据具有时间连续性特点,故对缺失值和异常值采用最近邻插补法进行填充。
1.4 有效数据集的构造
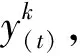
为了选出合适的样本属性集以及具体的属性特征,就需要确定上述样本结构中m的取值。本文采用的方法是:首先将m设置为一较大值(如m=72),然后构造出相应的样本数据集,再采用相关的数据降维技术逐步选出优质的特征子集。
常用的降维方法分为两类:特征提取和特征选择。特征提取会将多个数据特征融合为线性组合特征,但得到的特征不便于解释,无法阐述其具体含义,而本研究不仅旨在建立准确的空气质量预测模型,更希望能够找到与空气质量密切相关的特征集,获取能够解释的特征子集,因此本文采用特征选择方法。
Boruta算法是一种树的集成特征选择算法[10],主要是输出特征的重要度排序,特征越重要,其重要度系数就越大。本文针对上述3个不同区域的数据集,先重构出符合各自原有时间序列特性的扩展数据集,然后采用Boruta算法将所有特征按照重要度系数进行排序,最后通过交叉验证筛选出最优的特征子集。
表2所示为北京市的空气质量历史数据经过特征选择后得到的针对不同预测量的前14个重要特征。
从选出的重要特征子集来看,其不仅包括原始数据集中的17个属性值,还包括一些新构造的特征;不仅与过去1、2、3、…、24 h的空气污染物特征和气象属性特征相关,还与过去1、2、3 d同时段空气质量和气象数据的均值、最大值、最小值等统计量相关。最终,对于PM2.5浓度和AQI这两个预测量,从北京市数据集中选取参与算法建模的属性特征量均为212个,模型的训练和预测都是基于这212个属性进行的。
表2北京市空气质量数据的部分重要特征
Table2PartialimportantfeaturesextractedfromairqualitydataofBeijing

序号预测量PM2.5AQI1PM2.5(t-1)AQI(t-1)2PM2.5(t-2)PM2.5(t-1)3PM10(t-1)PM2.5(t-2)4PM10_24hAQI(t-1)5SO2PM2.5_24h6SO2(t-1)PM107NO2PM10_24h8COSO29CO_24hSO2(t-2)10NOSO2_24h11NO(t-1)NO212NO(t-2)NO2_24h13NO_24hCO14SO2(t-2)O3
注:PM10表示当前时刻的PM10浓度,PM10(t-1)表示上一个时刻的PM10浓度,PM10_24 h表示24 h的PM10平均浓度,其余以此类推。
2 OPGBoost算法
2.1 XGBoost算法简介
XGBoost算法可以在不选定损失函数具体形式的情况下, 仅仅依靠输入数据的值就可以进行叶子节点分裂优化计算。它的目标函数Obj(t)经过泰勒展开后,最终化简为[8]:
(2)
式中:γ为学习率;T为回归树的叶子数量;Gj为一阶导数;Hj为二阶导数;λ为正则化参数。
Obj(t)的大小与Gj和Hj的值有很大关系,Obj(t)值越小,XGBoost模型的预测和泛化能力就越强。
2.2 OPGBoost算法实现
实验研究发现,采用XGBoost算法进行空气质量预测时,生成的模型性能不稳定,预测精度有时很高,有时又较低。时间较久远的XGBoost模型无法较准确地预测当前的样本数据,是由于其内部的某些单棵树没有起到拟合作用。如果能够筛选掉或者降低这些树的权重,添加新的树模型,那么模型的预测精度就有可能得到很大提高。
针对上述问题,本文基于XGBoost算法进行优化,提出一种改进的集成学习算法OPGBoost对空气质量异常情况进行预测,其结构如图1所示。OPGBoost模型中包含多个XGBoost模型,为了减少组合模型的训练时间,加快其收敛速度,采用一阶导数和二阶导数优化的方式,减少单个XGBoost模型的训练时间以及单个XGBoost模型中树的棵数,将一个大的模型分解成几个小的模型,便于更好地进行在线模型的交替更新及预测。
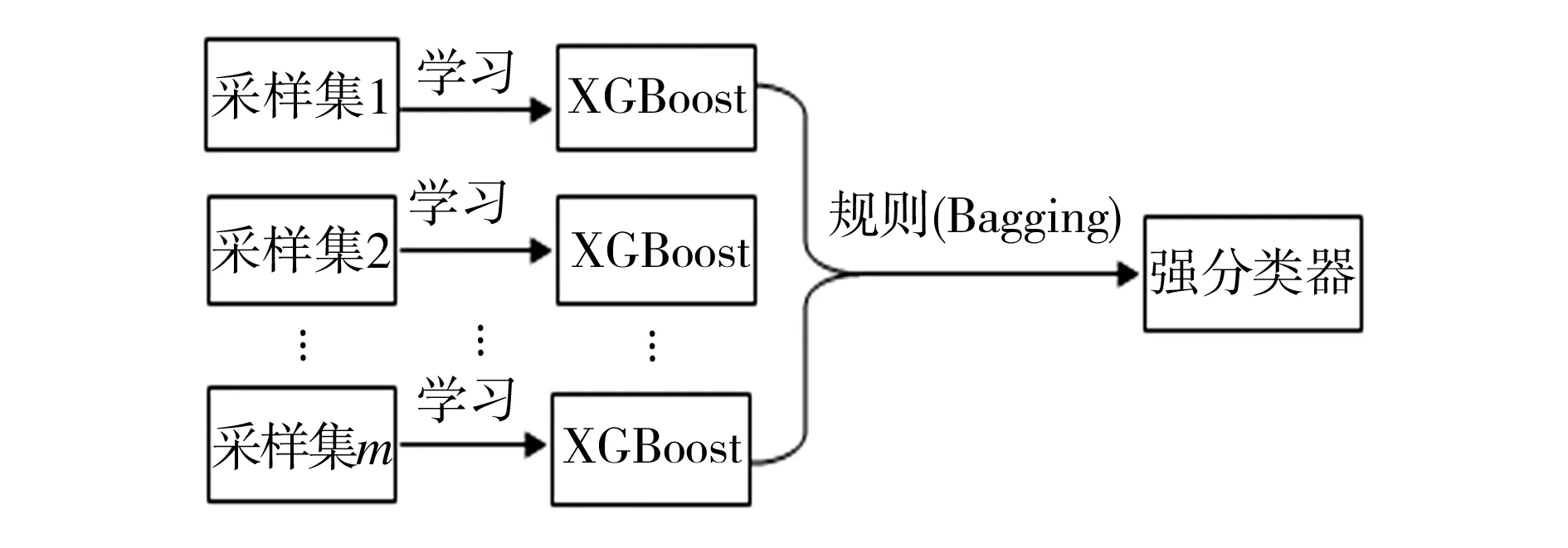
图1 OPGBoost 算法结构Fig.1 Structure of OPGBoost algorithm
OPGBoost算法的特性如下:
(1)自定义损失函数。对一阶导数和二阶导数的取值进行优化时,为每个样本提供了一种动态取值策略,进而使每个XGBoost模型有不同的假设学习空间,并且具有较好的预测精度和泛化能力。
(2)采用Bagging 集成学习思想,将多个不同且性能不稳定的基分类器XGBoost进行组合,构成集成模型OPGBoost。
下面给出一阶导数和二阶导数的优化方法:

上述伪代码中预测值predss的取值范围为(0,1),则(1-predss)N随着N的增大而减小,且二阶导数Hj也随之减小。经过多次实验比较,当N的取值为3或4、C的取值为2时,模型的预测效果最好。
3 实验平台搭建
3.1 实时数据库系统介绍

首先对PI系统进行二次开发,添加RDotNet.dll、RDotNet.Native.dll、R.NET等工具包,引入数据挖掘分析的功能模块,使PI系统能支持调用R 语言机器学习模型,并且能进行预测,即开发了一套能实现在线预测的系统化数据挖掘与分析平台,使其更适合于大数据流的实时处理。然后在此基础上构建离线-在线空气质量预测模型,并将实时预测结果通过用户界面展示出来。
3.2 预测模型的组合权重
预测模型离线训练完成后,需要将其架构到在线服务系统中。本文利用Bagging集成的思想实现模型的离线-在线服务,但考虑到距离当前时间序列越久远的模型,其数据相关性会降低,对当前空气质量的影响程度会减小,模型预测精度的可信度会下降,模型权重自然也要降低,因此采用滑动窗口和衰减函数机制来训练模型,降低时间较久远模型的权重,然后再进行模型的投票组合。
3.2.1 非线性衰减函数
假设初始数据X进入系统的时刻为t1,经过一段时间到达时刻t2,将该批数据X在当前时刻t2的权重系数定义为ft i,其中i表示第i个预测模型,则衰减函数为
ft i|t=t2=2-λ(t -t1)(λ>0)
(3)
式中:λ为衰减因子,λ∈(0,1)。
非线性衰减函数ft i的取值就是模型的权重系数,它与时间间隔和衰减因子有关,即时间间隔和衰减因子的值越大,相应的模型权重系数ft i的值就越小。
3.2.2 滑动窗口设置
组合模型的集成预测函数为
(4)
式中:fi(1≤i≤n)表示当前数据流的第i个分类模型。本文取n=3,即时间滑动窗口设为3个,预测结果由靠近当前预测数据流的3个分类模型以及由衰减函数得到的模型权重系数进行投票组合而成。
3.3 系统处理流程
采用PI系统自身的数据融合功能,将3组原始数据分别整合成多维数据集合,按照(时间标签,属性名,属性值)三元组格式存取,通过自带时间属性的函数读取相应时段内的数据,动态控制滑动窗口的数据流量大小,避免数据流不稳定、忽快忽慢等情况,最终整合成可使用的数据格式。然后调用机器学习算法进行离线训练,通过衰减函数调节模型权重,并投票组合成集成模型,以实时预测空气质量异常状况。具体步骤如下:
(1)实时数据的读取和预处理
根据所要读取数据的起始时间和终止时间以及相应的属性字段来决定滑动窗口的大小,然后调用PI系统内相应函数来读取滑动窗口内的数据流,融合成多维数据结构。最后经过数据预处理和特征选择形成概要数据结构。
(2)模型离线训练和反复调优
模型的训练主要是在R-Studio软件环境中进行。首先,采用上面得到的概要数据结构,调用相应机器学习算法,进行模型训练(设置相应的种子,便于复现实验过程),然后对模型进行评估,不断进行诊断和优化,对每个滑动窗口内的数据都训练一个算法模型以供调用。
(3)模型融合
采用非线性衰减函数,保留之前生成的模型,但减少其投票权重系数,并赋予新模型。经交叉验证后,确定衰减因子λ的优化值为1/2900。考虑到时间间隔越大,衰减函数值就越小,模型的权重系数也越小(接近于0),经过实验研究,基学习模型XGBoost的个数确定为3。最后,经过加权投票集成为组合模型OPGBoost。
(4)模型线上调用
模型的线上调用主要在PI系统中进行。首先,将上述训练好的学习模型通过相应接口移植到PI系统上,用于线上模型的更替以及空气质量预测。模型在线运行效果和稳定性如果不满足要求,则转到步骤(2)中重新训练和调优。当用户通过前端界面发送预测某时段内空气质量的请求时,通过相应时段的组合模型实现在线预测,并将预测结果按照(时间标签,属性名,属性值)的格式保存到PI系统里,通过用户界面显示。
4 实验结果分析
4.1 训练集和测试集的选取
实验室自采数据的时间范围是2016年9月~2018年2月,分别用2016年9月~2017年1月、2016年11月~2017年3月、2017年1月~2017年5月的数据训练出3个模型,每个模型的训练集样本均为3600个,确保数据时间序列能体现出季节性和长期趋势性。类似,武汉市和北京市的空气质量历史数据的时间范围是2014年1月~2017年12月,分别用2014年1月~2014年5月、2014年3月~2014年7月、2014年5月~2014年9月的数据训练出3个模型。
将训练好的3个模型通过加权投票生成组合模型进行空气质量预测。剩余时段的数据依次向后滑动,进行模型训练和测试,用与滑动窗口最接近的未来3个月的数据作为测试集,计算模型的总体预测精度。
4.2 模型评价方法
收集的原始数据中,正类(空气污染)样本数量较少。为了精确识别PM2.5浓度和AQI的类别,只专注于正类样本的准确率是不够的,因此本文采用3种评估指标,分别是准确率P、召回率R和调和平均数F1值,其中F1是衡量模型对正类样本整体预测性能的评估指标。评估指标计算公式如下:
P=TP/(TP+FP)
(5)
R=TP/(TP+FN)
(6)
F1=2PR/(P+R)
(7)
式中:TP表示正确预测的正样本数量;FP表示将负样本错误预测为正样本的数量;FN表示将正样本错误预测为负样本的数量。
4.3 实验结果
本实验分别建立单步预测(1 h)和直接多步预测(12、24 h)两类模型,针对3组原始数据构造有效数据集,并采用随机森林(RF)、支持向量机(SVM)、BP神经网络、XGBoost和OPGBoost这5种算法进行空气质量预测对比实验。每种情况下进行30次实验,预测性能评估指标取平均值,相关结果如表3~表5所示。
从表3中可以看出,针对3个数据集的单步预测,5种算法都获得了较高的预测精度,验证了所提出的有效数据集构造方法和重要特征选择方法的有效性。同时,OPGBoost算法具有最高的预测精度,也验证了本文采用的一阶和二阶导数值调优以及模型权重系数衰减的Bagging集成学习策略的有效性,表明OPGBoost模型具有较好的学习能力和泛化能力。
基于时间序列的直接多步预测具有一定的难道,这是由于步长和时间间隔的增大,导致时间序列之间的关联程度和数据相关性降低,使得模型预测能力和精度下降。从表4和表5中可以看出,在直接多步预测中,OPGBoost算法的预测性能仍优于其他4种算法,预测精度提高了2~5个百分点。这是因为OPGBoost兼有XGBoost和Bagging方法的优势,产生了良好的融合增益效果,可以更好地拟合空气质量预测中的非线性问题。
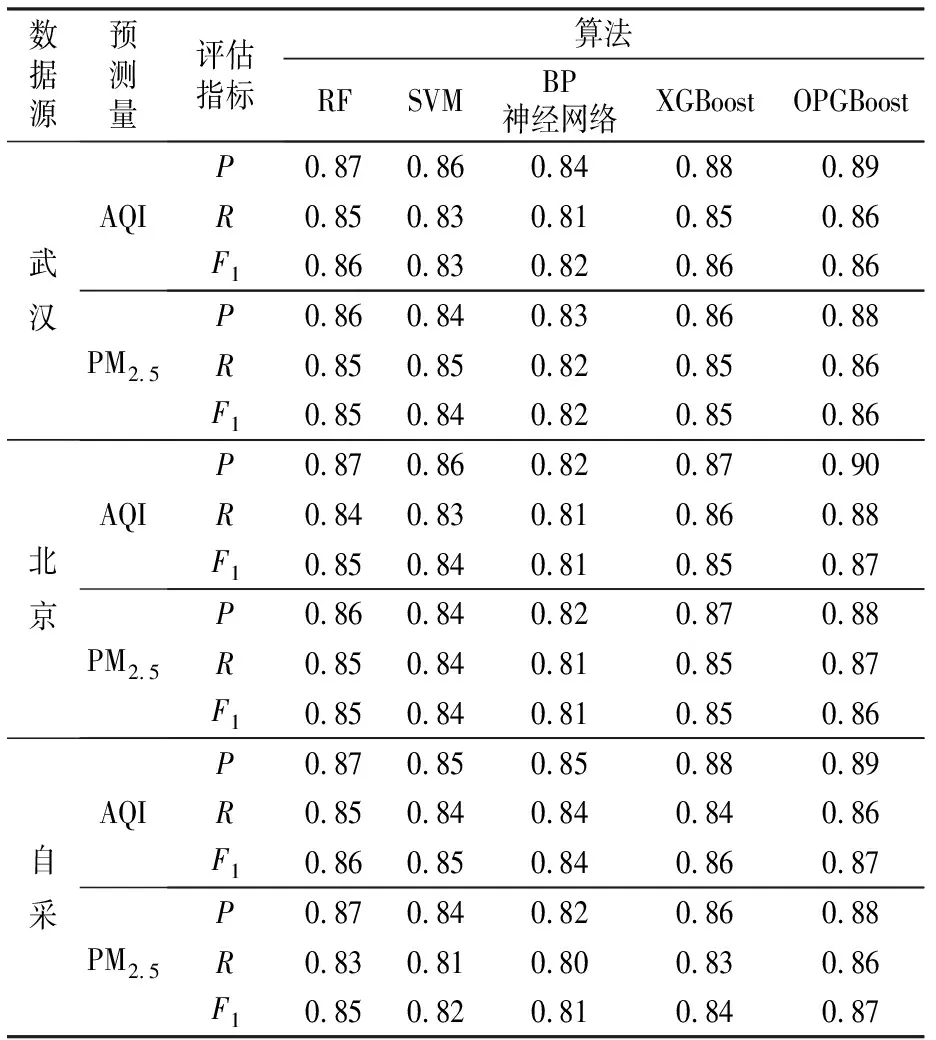
表3 未来1 h空气质量预测结果Table 3 Prediction results of air quality in the next hour

表4 未来12 h空气质量预测结果Table 4 Prediction results of air quality in the next 12 hours

表5 未来24 h空气质量预测结果Table 5 Prediction results of air quality in the next 24 hours
5 结语
本文首先采用时间序列分析方法,构造出新的样本数据集,并采用Boruta算法选择出重要的属性特征,然后结合XGBoost算法、一阶和二阶导数优化、Bagging集成学习策略,提出了一种空气质量在线预测的新方法。同时,整合PI系统开发出一个满足应用需求的系统化大数据挖掘与分析平台,采用时间滑动窗口和模型权重衰减机制,构建了基于时间序列的OPGBoost组合模型,通过离线模型训练以及模型线上调用,可对空气中PM2.5浓度和AQI的异常值进行在线预测。与其他几种已有算法相比,本文方法在准确性和实用性方面具有明显优势,对于空气污染情况的出现具有较好的预测能力。所开发的数据挖掘与分析平台更加适合于大数据流的实时处理且具有较快的响应速度,便于人们及时了解空气质量状况。
