基于级联极限学习机的基站空调在线监测系统
2019-01-07罗方芳陶求华
罗方芳,陶求华
(1.集美大学计算机工程学院,福建 厦门 361021;2.集美大学机械与能源工程学院,福建 厦门 361021)
0 引言
由于通信基站设备需要在相对恒温的条件下才能正常工作,所以需要配备专用的基站空调,为基站内各种设备正常稳定的运行提供必要的条件。为确保基站空调稳定运行,有必要对基站空调进行实时的在线监测,了解相关设备的运行状况,并且对异常状态及时报警,以便尽早排查故障。因此,高效、实时的在线基站空调故障监测和诊断系统的研究有其实际意义。目前的空调故障诊断系统主要有两种设计思路[1]。一种是基于模型的故障诊断,将实测值和模型预测值之间的残差作为故障判断的依据。代表算法有:基于能量守恒的残差计算方法[2]、基于残差特征和数理统计相结合的计算方法[3],等等。基于模型的故障诊断方法应用很广泛,但其准确度依赖于所建模型的精度,故而对建模要求很高。另一种是基于数据的故障诊断,利用人工智能技术,通过教计算机如何学习、推理和决策来实现故障诊断。代表算法有:决策树算法[4]、主成分分析法[5]、神经网络算法[6],等等。由于此类方法的参数选择较复杂以及训练速度较慢,故限制了其在故障诊断中的进一步使用。
某基站空调公司提供的数据集存在着样本类别不平衡的问题,正常样本数据高达62%,而某些故障的样本占数据集比例仅为1%。这种不平衡性会使得一些少量样本的故障类型在单个的多类分类器的训练过程中被视为噪声而遭“吞噬”。相较于决策树处理方法,这种小类样本识别率低的问题在神经网络类型的故障诊断处理中更为严重。借鉴于极限学习机参数选择简单、学习速度快的特点,本文设计了一个基于级联极限学习机的基站空调故障监测与诊断系统。针对每一种故障类型单独训练一个原子极限学习机,再将其级联组合,以此来解决训练集类别不平衡的问题。
1 空调系统模型
实验对象是目前应用最为广泛的移动基站空调系统,基站空调有内机和外机两部分,中间采用制冷剂管道连接。基站空调在线监测系统的构建分为离线学习阶段与在线实时监测分析阶段两部分。在离线训练阶段收集大量故障样本和无故障样本数据,预处理后导入级联极限学习机进行训练,获得稳定的检测分析模型。在线实时监测分析阶段,系统接收基站空调传感器的数据(温度、湿度、压力等),对数据进行归一化预处理后,输入基于级联极限学习机的在线监测分析系统,实时分析当前空调运行状态,若诊断显示故障,则及时预警排除故障以提高空调系统的制冷效率及维护通信基站的稳定运行。


表1 故障模式样本分布表
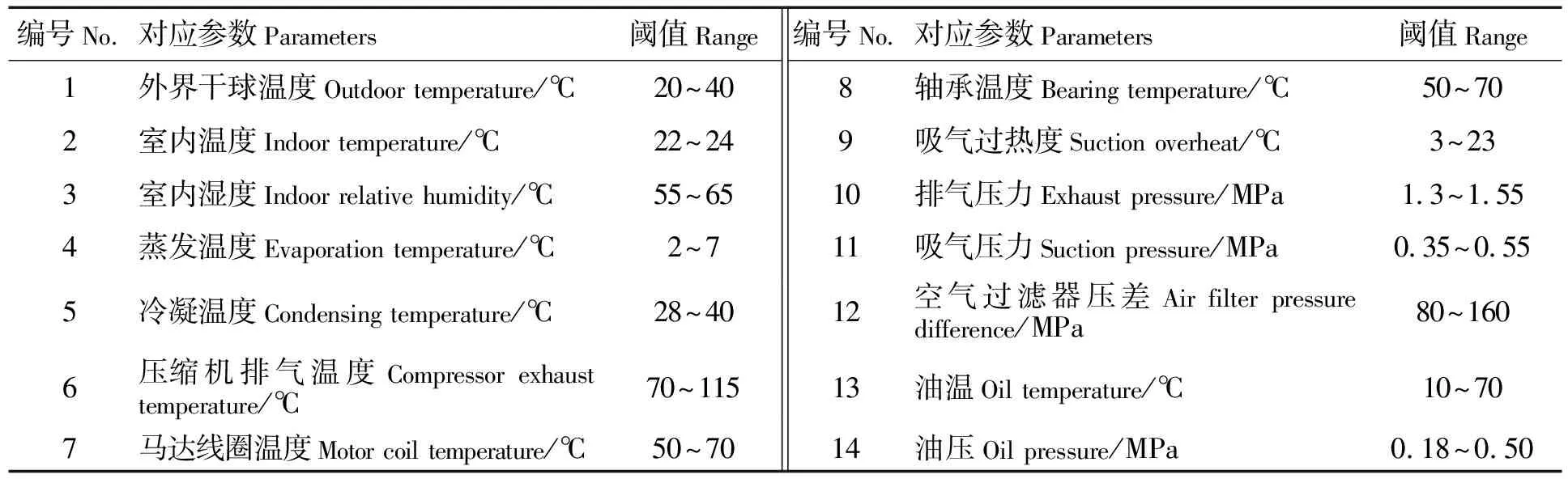
表2 系统接收参数及其含义
2 算法模型
2.1 训练原子ELM分类器
即使在深度学习盛行的机器学习领域,单隐层前馈神经网络(single hidden layer feed-ward neural network)以其强大的非线性逼近能力仍广泛应用于故障诊断中。新兴的极限学习机(extreme learning machine ELM)[7-8]是单隐层前馈神经网络的代表。

Ti-ξi,1≤i≤m,其中,β=[β1,…,βL]T为隐层输出权值向量,C为代价参数,ξi为理论输出Ti与实际输出f(xi)的误差,h(xi)为第i个实例xi的隐层输出向量。
根据Lagrange对偶理论,采用Moore-Penrose广义逆计算方法即可解析求出网络的隐层输出权值,由此可见,ELM算法避免了繁琐的迭代寻优的计算过程,也不易陷入局部极值。

然而在面对“训练样本集故障类别不平衡”的问题时,ELM也遇到了与其他神经网络算法相同的困境,即,少量特殊样本会被单个的分类器在训练过程中视为噪声而遭“吞噬”,进而导致小类样本识别率低、泛化能力弱的情形。为此,本文为每一种故障类型(包括“正常-无故障”类型)单独设计一个原子ELM分类器,再将各分类器级联组合用于新样本的故障诊断。
原子ELM分类器的结构如图1所示。由于是针对具体的某一种故障类型训练原子ELM分类器,所以ELM的输出层只有一个神经元。实验阶段训练集的样本数为100,所以需要对规模m=100的训练集针对具体故障模式进行数据预处理,即,该故障模式对应样本的输出值为1,其余样本的输出值为-1。
原子ELM分类器的理想输出公式为:Hβ=T,其中,
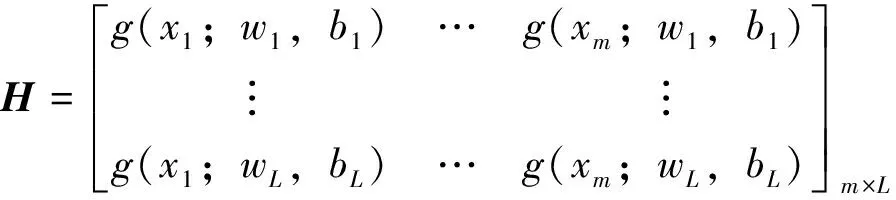
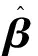

/C+HTH)-1HTT
(1)
在测试阶段,对于一个实例x,将其导入原子ELM分类器,对应的输出可由公式(2)计算获得。
(2)
原子ELM分类器的具体训练算法流程如下:
1)输入归一化预处理后的训练集D;
2)初始化隐层神经元数L,激励函数g,代价参数C=1;
3)随机设定输入点与隐层之间的权值w和隐层偏置向量b;
4)计算隐层的输出矩阵H=g(x;w,b);
2.2 级联ELM
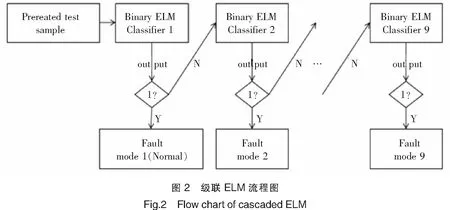
在所有的原子ELM分类器(包括“正常-无故障”类型)均训练完成后,每一个原子ELM分类器相当于界定了某种故障模式与其他故障模式的分界线。将各原子ELM分类器按图2方式级联组合[9]。由于在绝大多数情况下基站空调都处于正常运行模式,所以将“正常-无故障模式”的原子ELM分类器放在级联串中的第一个。
在对未知样本故障诊断时,将归一化预处理后的样本导入级联ELM系统。若第一个原子ELM分类器的输出为-1,它将继续进入下一个原子ELM分类器,直到在第j个原子ELM分类器的输出为1时停止向下传输,最终的诊断结果为第j个原子ELM分类器所对应的故障模式,j=1,…,9。
3 实验结果分析
为了更好地测试级联ELM算法的性能,从训练时间和故障诊断精度两方面进行考量。对比算法有:单独的多类ELM[7]、单独的支持向量机(SVM)[10]、级联的SVM、反向传输神经网络(BP)[11]、C4.5决策树算法[12]。其中SVM的级联组合方式与ELM的级联组合方式相同;单独的ELM代码来源为http://www.ntu.edu.sg/home/egbhuang/elm_random_hidden_nodes.html,激励函数为sigmoid函数;SVM算法的代码来源为https://www.csie.ntu.edu.tw/~cjlin/libsvm/,采用径向基函数作为核函数;C4.5决策树算法根据参考文献[12],采用“后剪枝”策略编写;BP神经网络采用Matlab工具箱实现,隐层神经元数设为20。各程序均在Matlab2012b上部署运行,训练集的样本数为100,测试集的样本数为60。
和大多数的机器学习算法相类似,ELM算法也存在参数(隐层神经元数)选择问题。原子ELM分类器的训练过程中,采用增量生长法来确定,将隐层神经元数从5开始递增测试学习误差,若误差的变化低于阈值δ(δ=0.01),则停止增长。经多次实验后,选择如表3所示的各原子ELM分类器隐层神经元数目。不可否认,选择合适的隐层神经元数这一过程较为耗时,在今后的工作中,可以对隐层神经元个数的优化进行更深入的研究。但隐层神经元数确定后,原子ELM分类器的训练过程是迅速的、稳定的。

表3 各原子ELM分类器隐层神经元数
表4罗列了各算法的训练时间、测试时间和故障诊断精度。从表4可以看出,与SVM算法、BP算法、C4.5算法相比,单独的多类ELM算法和级联ELM算法的训练速度极快,时间优势十分明显。由于级联ELM算法需训练多个原子ELM分类器,故训练时间比单独的多类ELM算法略长一些,但级联ELM的故障诊断精度明显高于其他几种算法,并且,在线故障诊断时间达到毫秒级别,满足实时监测的需求。
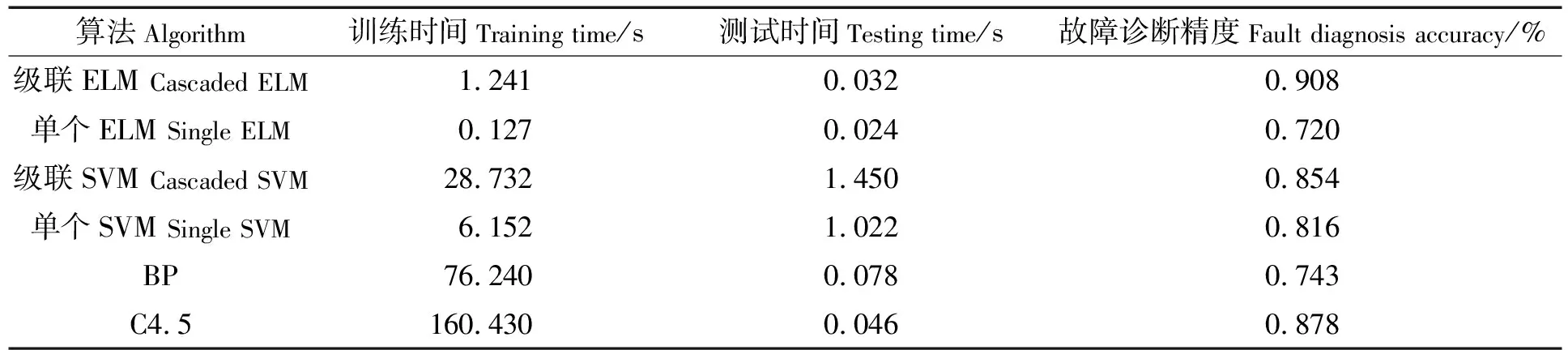
表4 各算法性能对比

表4的对比数据显示单个ELM、单个SVM的故障诊断精度均明显低于C4.5决策树算法,这是由于训练集中故障模式的样本数不平衡造成的。特别地,图3展示了训练集中小样本的故障模式,如“制冷系统内有空气(模式3)”、“内机过滤器堵塞(模式5)”、“电子膨胀阀开启过大(模式8)”,及其在20次测试中被正确识别的比率。样本数的不平衡在单个的多类分类器的训练过程中会吞噬掉小样本数的故障模式,相比于决策树分类算法,“吞噬”情况在神经网络结构的分类器中更为明显。采用级联ELM的方式能大幅度地提高小样本的故障识别率,虽然C4.5算法对故障模式8的识别率高于级联ELM算法,但在树的构造过程中,需要对数据集进行多次的顺序扫描和排序,因而训练时间长。总体而言,级联ELM算法在训练时间和故障诊断精度方面的综合性能更优。
4 结论
本文提出一种级联ELM的基站空调在线故障诊断算法。实验结果表明该算法与单独的多类ELM算法、SVM算法、BP算法、C4.5决策树算法相比都能获得更高的分类精度。与SVM算法、BP算法相比,级联ELM算法的训练时间也大大缩短。通过训练针对各个故障模式的原子ELM分类器来消除训练集中样本不平衡而产生的小类样本故障模式被吞噬问题,提高了小类样本的故障识别率,进一步通过级联原子ELM分类器来提高系统的泛化性能。测试数据的故障诊断时间达到毫秒级别,达到实时预警的需求,并输出可能的故障源,为基站空调维护人员提供相应的技术支持。但在真实复杂的野外基站空调运行环境中还有一些问题需要进一步考虑完善,如各基站传感器通信的有效距离,数据丢包率等问题。
