浅谈Spark 云平台的性能优化
2018-12-28俞华锋
俞华锋
(浙江经济职业技术学院,浙江 杭州 310018)
0 引言
在大数据处理领域中,Spark 云平台越来越受到欢迎, 现在已经演变成一个高速发展应用广泛的计算平台,在各大电子商务网站都有使用。 Spark 云平台适用于大数据处理的各个场合,与Hadoop 平台有相似的地方, 但优于它的是,Spark 计算的中间结果可以保存在内存中, 从而不再需要读写HDFS, 因此Spark 能更好地适用于大数据领域的离线批处理、 数据挖掘、 机器学习、SQL 类处理、流式/实时计算、图计算等各种不同类型的需要迭代计算的地方。
通过Spark 云平台可以使得处理大数据的任务执行的很快, 处理性能和效率很高。 当然如果我们要使用Spark 开发出高效率和高性能的云计算平台, 就必须对其各个方面进行合理的设置和优化, 否则Spark平台的执行效率可能会很低。 因此,如果要发挥Spark本身的优势, 就必须对其各个方面进行综合分析,并进行合理的设置和优化, 才能提高其性能。 本文主要探讨如何设置和优化Spark 平台,来提高其性能,从而来提高大数据计算作业的执行速度和执行效率。
1 Spark 运行基本原理
Spark 云平台是处理Stream 数据的框架, 它是将数据分割成很小的时间片断,以batch 批量处理的方式来处理Stream 数据。 这种批量处理的方式使得它可以同时兼顾实时和批量数据处理的逻辑和算法, 方便了需要将历史和实时数据进行挖掘和分析的应用场合。Spark 云平台通过序列化及类加载机制, 运行在JAVA虚拟机上, 采用分布式方式执行各个任务。 执行任务的流程如图1 所示。
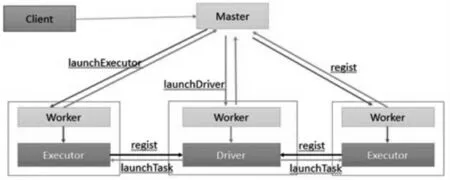
图1 执行任务的流程图
在Client 端机子上通过spark-submit 命令提交任务给 Master 机子后, 就会启动一个属于该任务的Driver进程。 Driver 进程根据部署模式,可能在本地机子上启动,也可能在分布式集群中的某个Worker 工作节点上启动。 Driver 进程启动以后,它向集群管理器申请执行Spark 任务所需的资源Executor 进程。 集群管理器收到Driver 进程的申请后, 会根据申请的参数, 在不同的Worker 节点上,启动相应数量的Executor 进程。
Driver 进程申请到了所需的资源之后,便开始调度和执行任务代码。 Driver 进程首先将Spark 的任务代码拆分成很多部分,每一部分称之为stage,即每个stage对应一部分代码。 同时每个stage 新建一批子任务,然后由各个Worker 节点上的Executor 进程来执行这些子任务。 第一个stage 的所有子任务执行完毕之后,就将中间计算结果存储到Worker 节点的本地磁盘中。 一个stag 执行完以后,Driver 进程就会执行下一个stage,一直执行到全部任务执行完毕, 并且计算完所有的数据才停止。
2 优化方法探讨
Spark 的性能优化, 需要我们根据不同的大数据应用场景,对Spark 的各项任务进行综合的考虑,并提供多方面的技术解决方案来进行优化, 才能获得最佳性能。 本文主要从开发Spark 任务时的优化、资源调度时的优化设置和数据倾斜时的优化处理这三个方面进行探讨。
2.1 开发时优化处理
在开发Spark 任务时,应根据具体的业务以及实际的应用场景, 将一些性能优化的基本原则灵活地运用到Spark 任务中,例如,避免RDD 的重复设计,合理的配置Spark 的各个参数以及一些特殊操作的优化等等。
在开发一个Spark 任务时,首先根据任务相对应的数据源创建一个初始的弹性分布式数据集RDD,然后对创建的这个RDD 执行映射或归约的操作,得到下一个中间的弹性分布式数据集RDD,然后对中间的RDD再执行映射或归约的操作, 直到计算出最终的结果。在上述的循环往复的操作过程中,不同的 RDD 会通过映射或归约操作得到一系列的RDD 串。对于同一份数据源一般只应该创建一个RDD, 如果创建了多个RDD, Spark 云平台会对不同的RDD 分别进行计算,得到的结果相似,失去了参考价值,因此增加了Spark 任务的资源开销。
在设计RDD 时, 除了上述原则外, 还要在对不同的数据执行映射或归约的操作时, 尽量地复用同一个已经存在的RDD。 例如,已经创建了一个
2.2 资源优化处理
根据具体的业务开发好Spark 任务代码后,就应该为相应的任务配置相应的资源。 我们可以通过sparksubmit 命令来设置特定任务的资源参数。 如果资源参数设置不合理, 就会导致集群的资源没有发挥应有的性能, 任务执行会比较缓慢。 如果设置的资源参数过大,超过了集群能够提供的极限,就会出现各种异常。总之言之,资源参数要设置合理,否则就会导致Spark任务的执行效率低下, 无法达到预期的性能。 因此我们需要对资源参数进行设置和优化处理。
怎么样对Spark 的资源参数进行优化配置呢?主要是通过调节和优化num-executors 和executor-memory 等参数,来提高资源使用的效率,发挥集群的优势,从而提升Spark 任务的执行性能。
num-executors 参数的作用是,设置Spark 执行一个任务时需要执行多少个Executor 进程。 Driver 进程在向Spark 云平台申请资源时,系统会按照num-executors 参数设置的数量,在各个worker 工作节点上,启动numexecutors 个Executor 进程。 这个参数如果不设置的话,系统只会启动很少量的Executor 进程, 这样就会导致运行效率非常低,速度非常慢。num-executors 参数一般设置50~100 比较合适,执行任务时集群管理器会启动50~100 个左右的Executor 进程, 大部分队列可以得到充分的资源,达到性能最优化。 当然如果设置的太少,就发挥不了集群资源的优势,造成资源浪费。
executor-memory 参数用于设置Executor 进程的内存。 Executor 内存的大小很大程度上影响着Spark 任务执行的速度。 我们可以把Executor 进程的内存大小设置为4-8G, 具体设置多少还得根据资源队列的最大内存限制是多少。 num-executors 和executor-memory 的积就是某个Spark 任务执行的总内存量, 如果超过了队列的最大内存量,性能也会下降。
2.3 数据倾斜时的优化处理
在大数据业务处理中经常会遇到的问题是数据倾斜。 例如, 在进行shuffle 操作时, 可能会出现这种情况,大部分key 对应几条数据,系统很快就处理完了,但是个别key 可能对应了百万级别的数据, 系统可能需要花费很长时间来处理。 而最长的task 花费的时间决定了整个Spark 任务的执行时间,此时的Spark 任务的执行时间会很长。 数据倾斜的优化处理就是使用各种解决方案来解决数据倾斜的问题, 以缩短任务的执行时间,从而保证Spark 的执行效率和性能。
由于大数据计算业务的需要, 经常会对Hive 数据源执行分析操作。 由于Hive 数据源中的数据不均匀,出现数据倾斜的几率非常大, 在这种情况下, 我们可以先对数据根据key 进行聚合操作, 即所谓的ETL 预处理, 然后,Spark 再对ETL 预处理之后的数据进行处理。 由于Spark 处理的数据是聚合后的数据,它就不需要使用原先的shuffle 操作了,也不会发生数据倾斜了。
如果在shuffle 操作时, 就少数几个键值会造成数据倾斜, 当然这少数几个键值对任务本身的影响不大的话, 我们可以过滤掉这几个键值。 因为这些键值被丢弃了,就不参加运算了,也就不会产生数据倾斜。 例如, 我们可以使用where 子句过滤掉上述的键值,在Spark Core 中对RDD 也执行相同的过滤操作, 过滤掉产生数据倾斜的键值。
3 结束语
本文首先阐述了Spark 云平台性能优化的意义,然后阐述了Spark 运行的基本原理,最后探讨了Spark 云平台性能的优化方法。 希望能对Spark 云平台的研究提供一定的参考。 当然本文只是简单的提出了性能优化的一些方法, 具体的实现和优化处理的方法有待进一步的研究与完善。
