Pedestrian Attributes Recognition in Surveillance Scenarios with Hierarchical Multi-Task CNN Models
2018-12-26WenhuaFangJunChenRuiminHu
Wenhua Fang, Jun Chen,*, Ruimin Hu
1 National Engineering Research Center for Multimedia Software, Computer School of Wuhan University, Wuhan 430072, China
2 Hubei Key Laboratory of Multimedia and Network Communication Engineering, Wuhan University, Wuhan 430072, China
3 Collaborative Innovation Center of Geospatial Technology, Wuhan 430079, China
Abstract: Pedestrian attributes recognition is a very important problem in video surveillance and video forensics. Traditional methods assume the pedestrian attributes are independent and design handcraft features for each one.In this paper, we propose a joint hierarchical multi-task learning algorithm to learn the relationships among attributes for better recognizing the pedestrian attributes in still images using convolutional neural networks (CNN). We divide the attributes into local and global ones according to spatial and semantic relations,and then consider learning semantic attributes through a hierarchical multi-task CNN model where each CNN in the first layer will predict each group of such local attributes and CNN in the second layer will predict the global attributes. Our multi-task learning framework allows each CNN model to simultaneously share visual knowledge among different groups of attribute categories. Extensive experiments are conducted on two popular and challenging benchmarks in surveillance scenarios, namely, the PETA and RAP pedestrian attributes datasets. On both benchmarks, our framework achieves superior results over the state-of-theart methods by 88.2% on PETA and 83.25%on RAP, respectively.
Keywords: attributes recognition; CNN;multi-task learning
I. INTRODUCTION
Visual recognition of pedestrian attributes,such as the estimation of gender, age and clothes colors or styles, is an emerging and important research topic in computer vision community, due to its great potential in the real surveillance system. For example, pedestrian attributes recognition has been used to assists pedestrian re-identification [1-6] and pedestrian detection [7-9]. And it has been proved to greatly improve other vision related tasks [11, 12]. As a middle-level representation, pedestrian attributes may shorten the semantic gap between low-level features and human description [12, 13]. In addition, they may play a critical role for the specific person search in practical applications for public security, such as the retrieval of the suspects in London underground bombing event.
Recognizing pedestrian attributes remains a challenging problem in video surveillance environments. In the surveillance scenes, the viewpoints of the two different cameras will change largely. For example, from Figure 1(a),the same pedestrian appears in two different cameras. The trousers of the pedestrian can be seen clearly in the left scene but in the right scene, they are truncated. The variable poses of the pedestrian also affect the attributes recognition in the surveillance scene. For example, in Figure 1(b) the attribute “with a phone” appears in the right but when the person changes the pose in the left, it disappears.In addition, in the large time range of the surveillance scenes, the appearance of the person will change a lot and affect the attribute recognition, such as attribute “with attachment”in Figure 1(c). Obviously, the low quality of the image, orientation and the partial occlusion will suffer the attributes recognition, seen from Figure 1(d), 1(e) and 1(f). Besides, there are many other factors to affect the pedestrian recognition, such as illumination variant and scale variant. All these factors make the pedestrian attributes recognition in the surveillance scenes more difficult.
In this paper, the author proposed a novel group based hierarchical multi-task CNN framework for pedestrian attributes recognition.
Pedestrian attributes recognition approaches can be divided into two categories according to feature representation: hand-crafted features and deep learning features. The former is artificially designed based on the statistical properties of the frame pixels. Early work was done on relatively small pedestrian attributes datasets. Daniel et al [13] proposed a part based feature representation for human attributes including facial hair, eyewear, and clothing color in video surveillance. Lubomir et al [15] tried to recognize 9 binary human attributes in personal photo album images by a poselet based approach [16]. To recognize more pedestrian attributes in surveillance environment, Zhu et al [17] constructed the Attributed Pedestrians in Surveillance (APiS)database including 11 binary and 2 multi-class attribute annotations. Moreover, they proposed two baseline methods with color and texture features to predict the attributes. Deng et al[12] extended the above work and released the first large scale pedestrian dataset including 19, 000 images with 61 annotated attributes.And they adopted multiple low-level color and texture features to present the attributes. However, the main drawback of such hand-crafted descriptors is that they lack enough discriminative capacity for pedestrian attributes recognition in surveillance scenarios [18].
On the other hand, deep learning features,such as deep Convolutional Neural Networks(CNN), has demonstrated superior performance in many computer vision tasks [19-21]. And it has also been shown that CNN can generate robust and generic features [22].CNN learns discriminative hierachical features from raw pixels by several convolution and fully connected layers which construct a complicated, non-linear mapping between the input and the output [19]. Encouraged by the ability of feature learning of CNN, recently researchers have exploited the CNN features for pedestrian attributes recognition. Li et al [18]proposed two CNN based models to recognize pedestrian attributes. On the one hand, they treated each attribute as an independent component and trained single attribute recognition model to recognize each attribute one by one.On the other hand, they treated the pedestrian attributes recognition as classic multiple classification task to exploit the relationship among attributes. Zhu et al [9, 24] proposed a multi-label convolutional neural network to predict multiple attributes together in a unified framework, in which a pedestrian image was roughly divided into multiple overlapping body parts, which were simultaneously integrated in the multi-label CNN model. Kai Yu et al [25] formulated pedestrian attribute rec-ognition in an attribute localization framework and proposed a weakly-supervised pedestrian attribute localization network to predict the attribute labels.

Fig. 1. Examples of some attributes in surveillance scenes.
Compared to the typical single label object classification, two additional issues are introduced into pedestrian attributes recognition:multi-labeling and correlation-based learning.Most of the existing methods usually assume that the pedestrian attributes are independent each other and transform the pedestrian attributes recognition into multiple single classification problems [18, 24, 25]. However,obviously the correlations between pedestrian attributes are important to infer the attributes.Take gender and clothes style for example.‘wearing dress’ indicates the gender of the pedestrian is probably ‘female’.
Multi-task learning (MTL) is an effective method for such feature sharing for related tasks, as well as competition among classifiers[23]. In the work [18], an interesting observation was found that although the average accuracy of DeepMAR (the MTL model with sharing the whole CNN for pedestrian attributes recognition) was higher than DeepSAR (without MTL) in PETA dataset [14] in most attributes. It indicated that the MTL was indeed effective in the pedestrian attributes recognition.Recently, some related work had been done in this field. Emily et al [26] proposed a multitask deep convolutional neural network model with sharing the lower two convolutional layers for facial attributes recognition. In addition, they added another fully-connected layer at the top of such model to take advantage of attribute relationships. However, this simple method to model the relationships between attributes failed to boost the performance in all facial attributes. Abrar et al [27] also proposed a multi-task deep convolutional neural network for binary attributes recognition. They assumed that there existed a latent shared task matrix in the multi-task network. Firstly, they divided the attributes into several groups, such as texture, shape, colors and character. And then they designed the convolutional neural network for each attribute recognition in the same group. And they substituted fully-connected layers with the joint MTL object loss.They regarded the output of the last convolutional layer in the CNN as the weight vector and aggregate them to a weight matrix. At last, they split the weight matrix into the latent shared matrix and the combination matrix. The vector of the combination matrix indicated appearance of the binary attributes. The method was suitable for binary attributes recognition but maybe it was not suitable for some multiple-value attributes recognition in our task. In addition, the assumption of the latent shared task matrix was not proved in the pedestrian attributes recognition task. And the high resource consumption was not suitable for this task.
Given the aforementioned issues, in this paper we propose a CNN based hierarchical multi-task framework for the large scale pedestrian attributes recognition in the surveillance scenes, as shown in Figure 2. The motivation is that there are inherent relationships among the pedestrian attributes which can benefit the recognition of each attribute. We explicitly model such relationships by splitting the attributes into local and global ones according to their location and semantics. In the first layer, each multi-task CNN is constructed for local attributes in each local group. The notation L_i_attr_j indicates the i−th attribute in the i−th local group. In the second layer, the auxiliary network on the top of last convolutional layers from all local multitask CNNs is proposed for learning global attributes. The notation G_attr_k indicates the k−th attribute in the global group. Unlike the work in [26], we introduce the spatial and semantic based grouping. We adopt body part detection to locate the head, upper body and lower body for local attributes recognition.For each attribute in the same local group,they share the lower layers in the network to learn the common information. In [26], they hypothesized all the attributes in the face were related and shared the same lower convolutional layers. Maybe that hypothesis was suit-able for the facial attributes recognition. We find that such hypothesis is not suitable for our task, because the classification of some attributes in a local group will suffer from that in another local group. In addition, in [26], they didn’t use part alignment for facial attributes recognition because there were not scale and pose variants in the datasets. However, there are lots of scale and pose variants in the pedestrian attributes recognition. We find that the part alignment can improve the performance.The another significant difference between our method and that in [26] is that we consider the imbalance of the attributes and introduce the weighted cross entropy loss function. In[26], each attribute was treated as equals. Obviously, the attributes appear in the datasets at different frequencies. The last main difference is that we divide the attributes into local ones in different local groups and global ones in one group. And we assume that the attributes in the same local group are highly related and the attributes in the different local groups complete with each other. In addition, the attributes in the global attributes are related with all local attributes. We find that this hypothesis is suitable for our task. In [26], they assumed that all attributes were related explicitly and implicitly. They divided the facial attributes into nine groups. They shared the lower two convolutional layers for all attributes and then in nine subsequent convolutional layers, each one was prepared for each attribute recognition in the same group. For modelling the relationships among the attributes, they added two fully-connected layers on the top of the last layer of each network. They considered the semantic relationships implicitly. But we consider that more explicitly by designing a new hierarchical network. The first layer of our framework is the convolutional neural networks for local attributes recognition and the second layer of our framework is the auxiliary network on the top of the above convolutional neural networks for global attributes recognition.
All in all, the contributions of this paper are summarized as follows:
1) We consider both the semantic relationships and the spatial relationships in pedestrian attributes recognition in the surveillance scenes.
2) We propose a novel CNN based hierarchical multi-task learning framework for the pedestrian attributes recognition according to the semantic and spatial relationships in the surveillance scenes.
3) We conduct sufficient experiments on two challenging large scale pedestrian attributes databases and achieve the state-of-theart performance.

Fig. 2. CNN based hierarchical multi-task learning framework for pedestrian attributes recognition.
The rest of this paper is organized as fol-lows. In Section II, we present the proposed CNN based multi-task learning framework in detail. We conduct the experiments on PETA[14] and RAP [17] pedestrian attributes recognition databases in Section III. Finally, we conclude this paper in Section IV.
II. PROPOSED APPROACH
In this section, we will explain the details of the proposed approach of the multi-task CNN model. Figure 2 shows the overall structure of the proposed method, starting from raw images input and ending with attribute classification output. We start with the presentation of pedestrian attributes grouping strategy, then introduce the CNN based multi-task learning model for local attributes recognition in each group. Based on the learned local CNN features in each group, we discuss the global attributes recognition in detail.
2.1 Pedestrian attributes grouping
Pedestrian attributes can be naturally split into different groups according to spatial location and semantic relation. For spatial location,pedestrian attributes can be divided into global and local. As the name implies, local attributes describe the head (‘glasses’, ‘long hair’), upper body (‘T-shirt’) and lower body(‘long pants’) and global attributes describe the whole body (‘age’, ‘gender’). For semantic relation, pedestrian attributes can be divided into correlated and non-correlated. For example, ‘Long hair’ and ‘red dresses’ may indicate that the gender of the pedestrian is ‘female’.So ‘female’ is correlated with ‘long hair’ and‘red dressed’.
Attributes grouping is considered in many attributes recognition task [26,27]. But they only consider the semantic relationship such as texture, color, shape and son. In our work,we consider both the semantic relationship and the spatial relationship. We split the pedestrian attributes into the global and local ones.Because the number of the global attributes is relatively small, usually less than 10, we aggregate them into only one group. For the local attributes, according to the different locations, we split them into three categories: the head-shoulder, the upper body and the lower body. Moreover, according to the correlation among the local attributes, we divide them into different groups, such as color, texture,shape and action. Detailed attributes grouping tables are listed in section III.
2.2 Multi-task learning for local attributes
In this section, we will explain the details of the proposed approach of the multi-task CNN model for local attributes. And the global attributes recognition will be discussed in the next section.
The local attributes recognition is described as illustrated in Figure 3. Firstly, the images of training dataset are divided into M different groups according to the attributes grouping mentioned above. And then Images from each group are fed into a multi-task CNN model for learning semantic attributes. Due to multiple attributes labels of each image, an image will belong to different groups. Emily et al [26]proposed a multi-task model based on Alexnet [19] for facial attributes recognition with two lower convolutional layers shared by all attributes, ignoring the semantics and spatial relationship. Unlike that, we use and modify the popular network structure VGG-16 [20] to learn more discriminative features.
In our multi-task framework, the four lower convolutional layers with two max pooling layers are shared for all attributes in the same group. This allows for learning of implicit relationships among attributes at a lower level.After that, feature maps are fed into different convolutional layers, max pooling layers,global average pooling layer and subsequent softmax layer for each attribute recognition.Different from standard VGG model, we not only remove the last two fully connected layers and add a 1×1 convolutional layer with global average pooling layer [21], but also replace some 3×3 convolutional layers with the 1×1 convolutional layers, as shown in Figure 3. This can not only reduce the parameters by a large margin, and accelerate convergence in the training, but also lose the performance.This improvement can boost the performance by ~ 1.2% in mean Accuracy (mA). Moreover,we use a weighted sigmoid cross-entropy loss for all attribute scores to facilitate training to solve the imbalance distribution of attributes.This can improve the performance by ~ 0.9%in mean Accuracy (mA). As preprocessing steps, the training mean is subtracted from the images. This helps the network to be robust to shifts in the input. Unlike other attributes classification methods, we do not perform any manual alignment or part extraction in the preprocessing stage. Our method is more applicable to real-world imagery for which alignment may be challenging.
In order to make our model to predict multiple attributes together, the cross entropy loss function is usually used as the cost function as follows:

where K is the total number of attributes in a group; piis the ground truth probability of the i−th attribute; pˆiis the predicted probability of the i−th attribute.
However, in the pedestrian attribute datasets (e.g., the PETA dataset [14] and the RAP dataset [17]), the distributions of positive and negative samples in most attributes are usually imbalanced. Many attributes, such as ‘wearing a V-neck or not’, are seldom labeled positive in the training data. Using the objective function in Equation 1 may cause these attributes to be constantly predicted as negative. To address this problem, we follow the work of [25]and introduce a weighted cross entropy loss function as follows:

where w is a weight vector indicating the proportion of positive samples over all attribute categories in the training set. The aim function can be optimized by stochastic gradient descent method iteratively.
2.3 Multi-task learning for global attributes
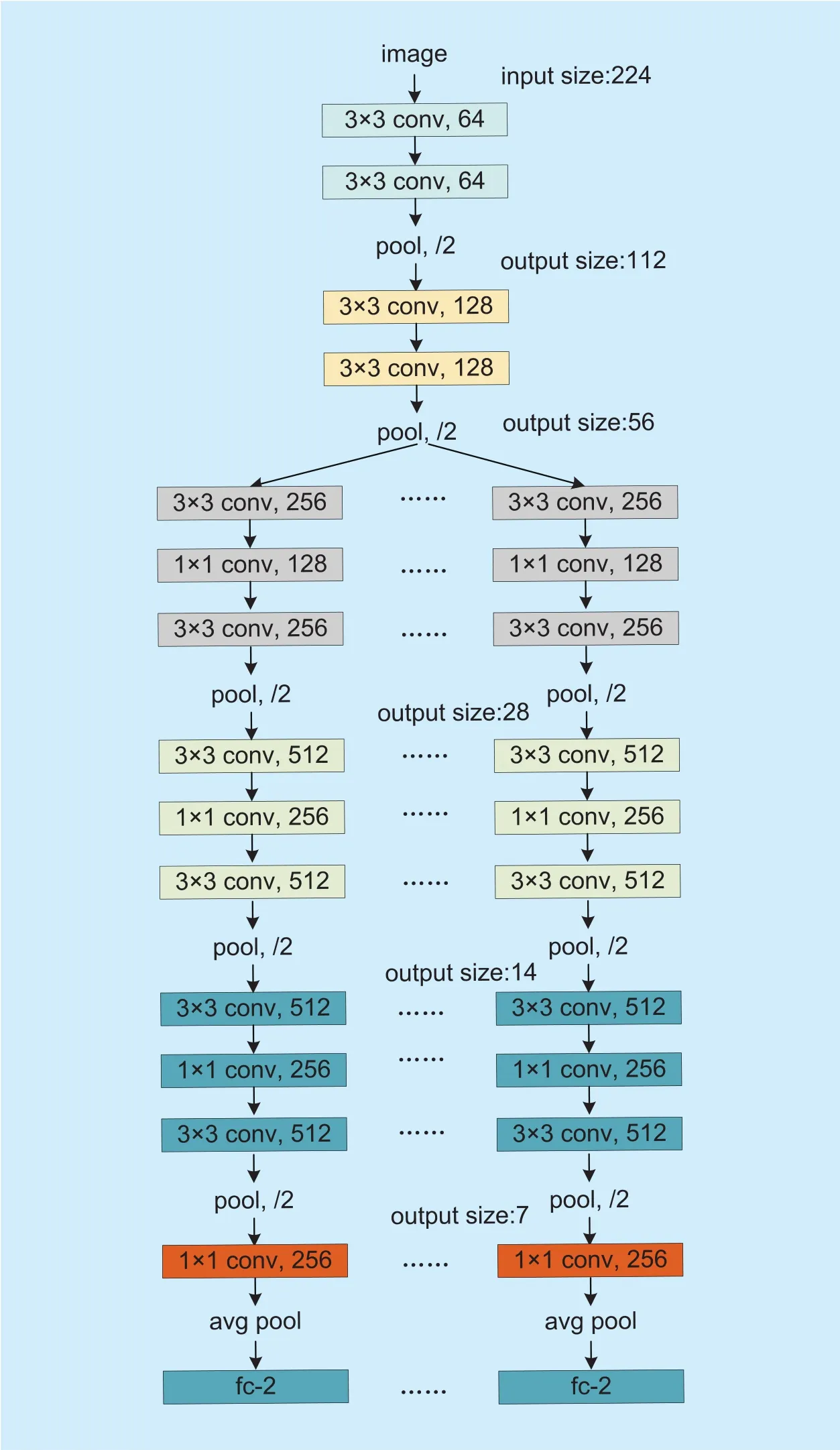
Fig. 3. Multi-task learning for local attributes recognition.
Since the global attributes are related to the multiple local attributes of the pedestrian, the local CNN features are shared for all global attributes. Inspired by AUX architecture [26],we also design a novel AUX architecture. In our AUX architecture, we add a 1×1 convolu-tional layer and global average pooling on the top of the last convolutional layer of the multitask CNN for local attributes. We also use the sigmoid cross-entropy loss for all global attribute scores to facilitate training like local attributes learning. This can boost the performance about 1%.
In Figure 4, the purple dashed line shows the connection between multi-task CNN for local attributes learning and global attributes prediction. And the orange dashed lines show the multi-task CNN for local attributes learning. In AUX architecture [26], two fully connected layers are added on the output of the multi-task CNN to predict the global facial attributes. However, this may result in the risk of over-fitting (five fully connected layers for global attribute recognition). From the perspective of CNN based object classification,the convolutional layers and the fully connected layers are regarded as feature extraction and classifier respectively. Our model is quite different from AUX architecture. We use the all convolutional features as the input of our model to share the features directly, not the predicted vectors.
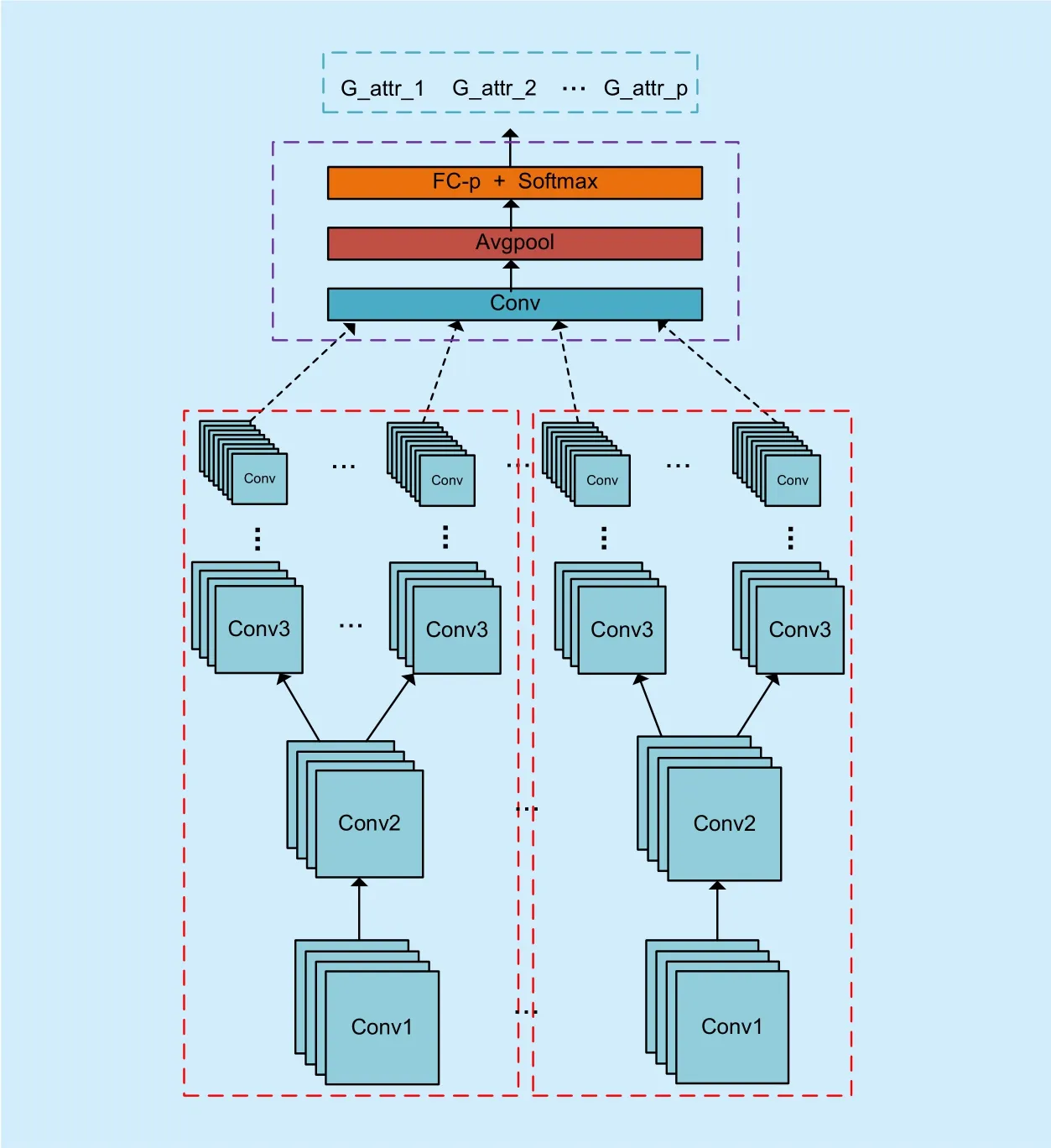
Fig. 4. Multi-task learning for global attributes recognition.
2.4 Body part detection
Body part detection can improve the performance of pedestrian attributes recognition[17]. And some public benchmarks provide the bounding boxes of the body parts directly,such as RAP dataset [17]. In our work, the body part detection is used to locate the head,upper body and lower body for local attributes recognition. We use the famous method, Poselet [16], to detect the body parts for the datasets without any annotations of body parts, such as PETA [14]. By the way, we will design the novel multi-task network to learn the location of the bod parts and the attribute recognition jointly in end-to-end manner.
2.5 Implementation
In this section, we cover the detailed implementation of our model to enable other researchers to easily build upon our results.We preprocess all examples by warping the input image to 256 × 256 pixels. In order to learn robust features from CNNs, during training, we make use of several data augmentation strategies [26]. We resize the images of training database to 227×227, and randomly crop a 224×224 patch from them. Secondly,the cropped patches are horizontally flipped by random. Finally, we use a scale jittering strategy to help CNN to learn robust features[28]. Furthermore, we crop a patch on three scales (1, 0.875, and 0.75), which yield the scaled patches of size 224×224, 196×196, and 168×168. The scaled patches are then resized to 224×224. In testing phase, we disuse the data augmentation strategy and just crop one 224×224 patch from the center of testing image.
Multi-task CNN is pre-trained on ImageNet dataset [19] and then the model parameters are finely tuned on pedestrian attributes recognition datasets. In the process of CNN training,the learning rate is set to 10-3, decreases to its 1/10 every 10K iterations, and stops at 50K iterations [17].
III. EXPERIMENTS AND RESULTS
In this section, we show the pedestrian attributes recognition performance of the proposed method. We firstly introduce the datasets,evaluation criterion and baselines for evaluating our proposed approach. Then we give the grouping lists on the datasets based on the grouping strategy. Finally, the proposed method is compared with the state-of-the-art methods.
3.1 Datasets
We evaluate the proposed approach on two popular large scale pedestrian attributes recognition datasets in surveillance scenarios: PETA[14] and RAP [17].
The PETA dataset is one of large pedestrian attributes datasets in surveillance scenarios,collected from existing person re-identification datasets (such as 3DPES [30], VIPeR [31],etc.). And it consists of 19,000 images with resolution ranging from 17×17 to 169×365 pixels. Each image in PETA is labeled with 61 binary and 4 multi-class attributes. The detailed information of such attributes can be found in reference [14].
The RAP dataset is the largest collection of realistic multi-camera surveillance scenarios with long term collection. The dataset is composed of 41,585 images, with 72 annotated binary attributes as well as viewpoints, occlusions, body parts information. We use the default training/testing splits in our experiment.We also train our CNN model in image classification task from ImageNet [19] to initiate our model and fine-tune it in our target databases.
3.2 Benchmarks
To evaluate the effectiveness of the proposed method, we choose four recent state-of-the-art approaches as the benchmarks. One approach is based on low-level feature and the others are based on CNN features. The first one is Ensemble of Localized Features (ELF) feature,which is proposed by Gray et al. [31], and has been successfully used in human attribute recognition [32]. It consists of 8 color channels(RGB, HS, and YCbCr) and 21 texture filters derived from the luminance channel. As the same with existing work [31], we divided the human image into six equal strips and extracted a 474-d ELF feature for each strip. So the final ELF feature is a 2784-d low-level feature vector to represent the image.
Recently, CNN has been successfully used in vision related areas, such as object classification [19, 20], object detection [21]. The CNN features trained for large-scale object classification have also shown a good generalization ability among general object recognition tasks [22, 24]. Besides the ELF feature,the recent CNN based methods are also adopted as baselines in this paper. We select three CNN based approaches with top performance,which are ACN [32], DeepMAR [17] and WPAL [25] respectively. In addition, we adopt the mean accuracy (mA), accuracy (Acc),precision (Prec), recall (Rec) and F1 score which are usually used in object recognition task [18,25,32] as our evaluation criterions for better evaluating our approach. The detailed information of such evaluation criterions can be seen in reference [17].
3.3 Attributes grouping
In this section, we will give the attributes groups in our experiments according to the grouping strategy discussed in section 2.1.Firstly, the pedestrian attributes are divided into two parts: the global and local. The global attributes usually describe the features of the whole body, such as gender, age, body shape,viewpoint and role, etc. Because of the relatively small volume, we aggregate them into one group. Secondly, the local attributes are divided into three parts (head, upper body and lower body). Finally, each local part is split into two groups according to semantic appearance (style and color) and action. For example, in the head part, one group involves the semantic appearance, such as hair style, hair color, hat, glasses, etc. And the other group in-volves the action, such as telephoning, talking,etc. Detailed attributes groups are listed in Table I.
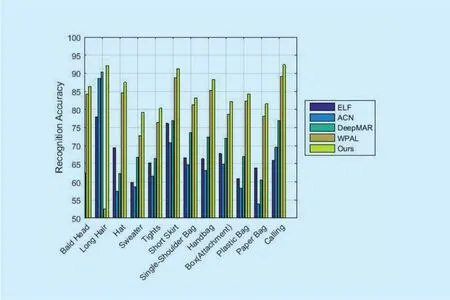
Fig. 5. Attributes recognition result on PETA dataset.

Table I. Pedestrian attributes groups in PETA and RAP.
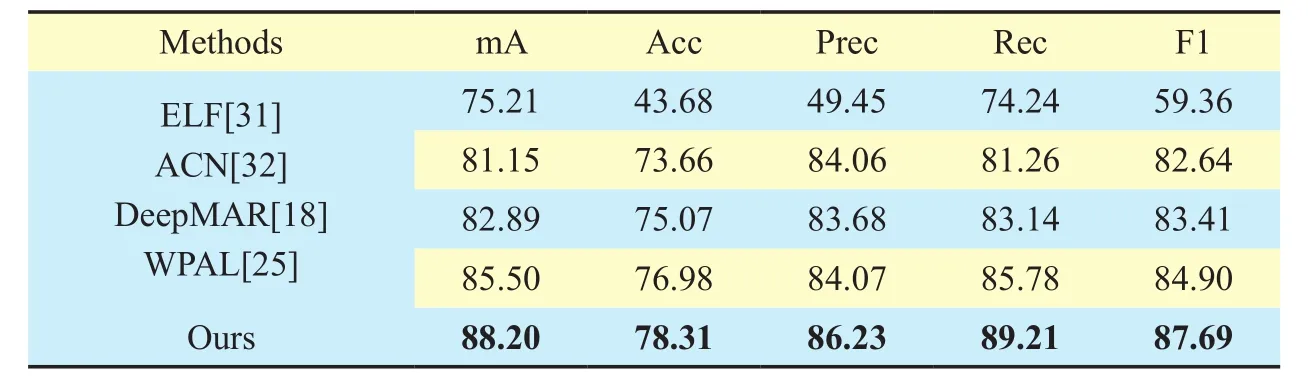
Table II. Pedestrian attributes evaluation on PETA.
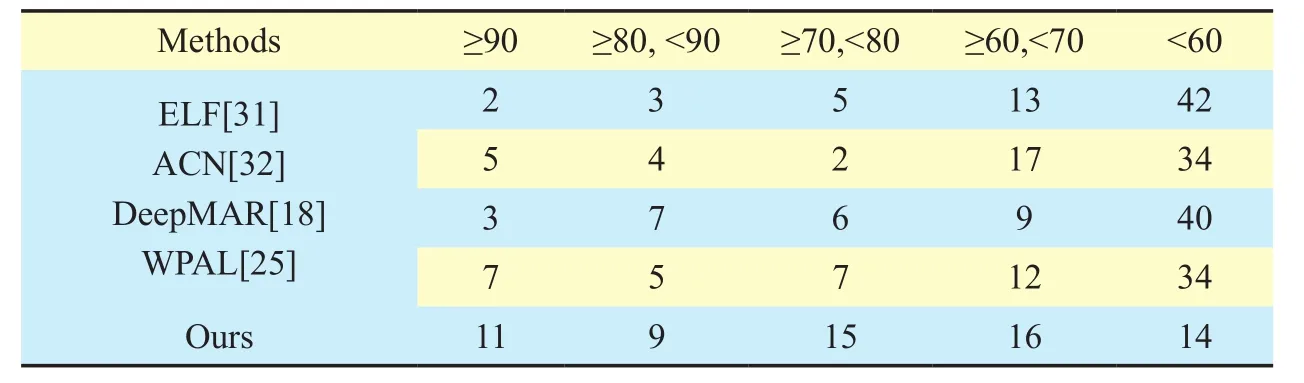
Table III. Attributes accuracy distribution on PETA.
Recently, some research work focuses on the relationship strength among attributes.According to the semantic attribute grouping idea proposed in [23], group details are used as discriminative side information. It helps to promote which attribute classifiers are encouraged to share more visual knowledge, due to the group membership privileges. So we will focus on these progressive grouping strategy in our work in the future.
3.4 Performance Evaluation on PETA
In this section, we compare our method with four baselines on PETA dataset. The performance of the benchmarks are listed in [18]and [25]. As shown in Table II, our multi-task CNN framework obtains the highest performance on two datasets in all four evaluation criterions. According to Table II, we can learn that the mean accuracy (mA), accuracy (Acc),precision (Prec), recall (Rec) and F1 of our method are 88.20%, 78.31%, 86.23%, 89.21%and 87.69%, which are 2.7%, 1.33%, 2.16%,3.43% and 2.79% higher than that of the stateof-the-art approaches respectively. Besides,the average improvement of the proposed method over the second best method is 3.5%.
In addition, for evaluating our methods, we give the attributes recognition distribution in different intervals of accuracy. From Table III,we see that our model can learn more discriminative features. In our model, there are 11, 20,35 and 51 attributes, accuracies of which are higher than 90%, 80%, 70% and 60%, respectively. Our model outperforms WPAL [25] by a large margin.
In Figure 5, we give some attributes recognition results, in which the accuracy of each attribute is higher than the state-of-the-art by at least 3%.
In general, the proposed multi-task CNN framework obviously improves the recognition accuracy of pedestrian attributes.
3.5 Performance Evaluation on RAP
Finally, we compare our method with the state-of-the-art on RAP. As shown in Table IV,For RAP dataset, according to Table II, we can learn that the mean accuracy, accuracy, precision, recall and F1 of our method are 83.25%,63.13%, 82.52%, 81.65% and 82.08%, which are 2.0%, 0.53%, 2.30%, 3.26% and 6.1%higher than that of the state-of-the-art approaches.
We also give the attributes recognition distribution in different intervals of accuracy, as shown in Table V. We can see that our model has achieved the best results in most of 72 attributes in RAP dataset. And there are 15,33, 53, 64 attributes in which the accuracies are higher than 90%, 80%, 70%, 60%, respectively. In every accuracy interval except lower than 60%, we have achieved the state-of-theart performance.
We also give the concrete attribute recognition result on RAP. Because there are 72 attributes in all, due to the limitations of length,we just list the attributes whose accuracy is higher than the best by 5%, as illustrated in Figure 6.
Our multi-task deep learning framework produces the highest performance on the two datasets. Both on the PETA and RAP datasets,some work with competitive results is based on multi-task learning CNN feature. Compared with the result of the original multi-task method in [33] (mA: 69.66%), our framework(83.25%) is much better with the additional multi-task learning and attributes grouping to explore the discriminative information. The recent multi-task CNN works [25] adopted different multi-task framework, so the results are not directly comparable. Our deep learning framework is similar to [25], but our results improved 2.7% and 2% in mA compared to[25] in PETA and RAP respectively. And in other performance evaluation criterions, we also outperformed the baselines by a large margin.
IV. CONCLUSIONS
In this paper, we have proposed a novel group based hierarchical multi-task CNN framework for pedestrian attributes recognition. The main idea is splitting the pedestrian attributes into different groups according to the spatial and semantic relationship and building the novel hierarchical multi-task CNN framework for local attributes and global attributes recognition by global sharing and competition between groups through learning deep discriminative features. The proposed method can significantly improve the performance of pedestrian attributes recognition. Experimental results on two public benchmark databases have demonstrated its superiority over the state-of-the-art methods. In our future work, the relationships among local and global attributes are considered to model by graphical models explicitly.
V. ACKNOWLEDGEMENT
This research is based upon work supported by National Key R&D Program of China(-NO.2017YFC0803700), National Nature Science Foundation of China(No.U1736206),National Nature Science Foundation of China(61671336), National Nature Science Foundation of China(61671332), Technology Research Program of Ministry of Public Security(No. 2016JSYJA12), Hubei Province Technological Innovation Major Project(-No.2016AAA015),Hubei Province Technological Innovation Major Projec(2017AAA123),The National Key Research and Development Program of China (No.2016YFB0100901) and Nature Science Foundation of Jiangsu Province(No. BK20160386).
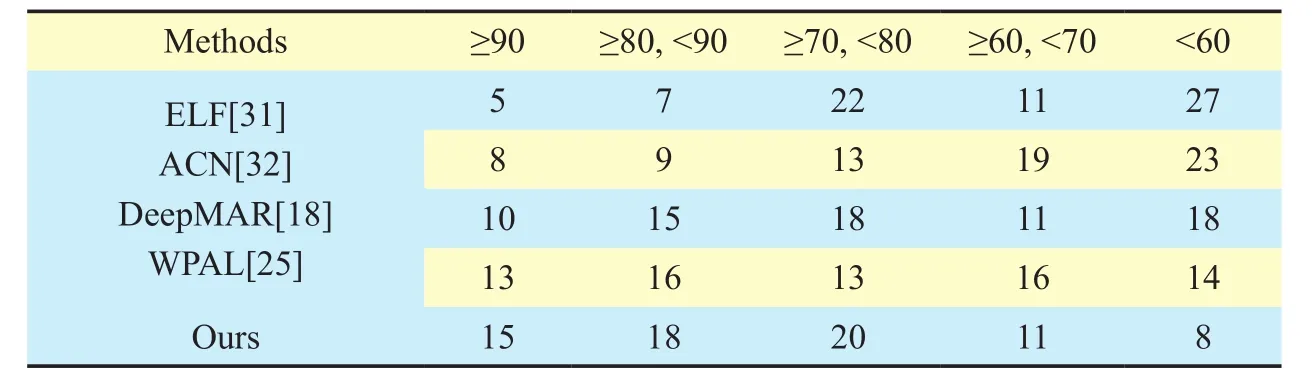
Table V. Attributes accuracy distribution on RAP.
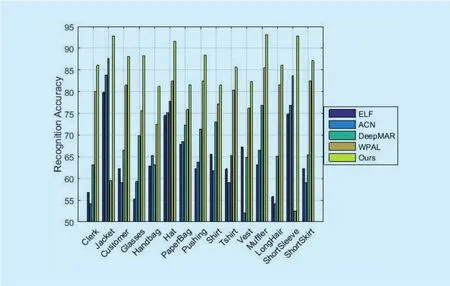
Fig. 6. Attributes recognition result on RAP dataset.
杂志排行

China Communications的其它文章
- Cost-Aware Multi-Domain Virtual Data Center Embedding
- Statistical Analysis of a Class of Secure Relay Assisted Cognitive Radio Networks
- Moving Personal-Cell Network: Characteristics and Performance Evaluation
- A Novel 3D Non-Stationary UAV-MIMO Channel Model and Its Statistical Properties
- Mode Selection for CoMP Transmission with Nonideal Synchronization
- Illegal Radio Station Localization with UAV-Based Q-Learning