Foundation Study on Wireless Big Data: Concept, Mining,Learning and Practices
2018-12-26JinkangZhuChenGongSihaiZhangMingZhaoWuyangZhou
Jinkang Zhu*, Chen Gong, Sihai Zhang, Ming Zhao,Wuyang Zhou
Key Laboratory of Wireless-Optical Communications, Chinese Academy of Sciences, School of Information Science and Technology, University of Science and Technology of China, Hefei 230022, China
Abstract: Facing the development of future 5G, the emerging technologies such as Internet of things, big data, cloud computing, and artificial intelligence is enhancing an explosive growth in data traffic. Radical changes in communication theory and implement technologies, the wireless communications and wireless networks have entered a new era.Among them, wireless big data (WBD) has tremendous value, and artificial intelligence(AI) gives unthinkable possibilities. However, in the big data development and artificial intelligence application groups, the lack of a sound theoretical foundation and mathematical methods is regarded as a real challenge that needs to be solved. From the basic problem of wireless communication, the interrelationship of demand, environment and ability, this paper intends to investigate the concept and data model of WBD, the wireless data mining, the wireless knowledge and wireless knowledge learning (WKL), and typical practices examples, to facilitate and open up more opportunities of WBD research and developments. Such research is beneficial for creating new theoretical foundation and emerging technologies of future wireless communications.
Keywords: wireless big data; data model;data mining; wireless knowledge; knowledge learning; future wireless communications
I. INTRODUCTION
1.1 Motivation
The rapidly growing of wireless data puts great challenges to the communication network service. As all known, to address the influx of massive users, meeting the high traffic growth and demand for high connectivity is very difficult. The users access density will be more than 1062km; the density of wireless base stations (BSs) will be higher than 1042
km; and the capacity per area will be greater than 1032Gbpskm. Such demands far exceed not only the capacity limit of existing technologies, but also the existing theoretical limit [1].
According to Shannon theorem, if the probability of occurrence of event xmis p(xm), the information amount of M users isFor frequency bandwidth B, cell density NF, the num-ber of MIMO channels λcell, and SINR as the ratio of signal to interference/noise, the capacity of existing wireless networks is CA=log2(1 +SINR ),and is difficult to meet the unlimited demands [2]. Assume that SINR can achieve 8bps/Hz transmission,NF=4(cell radius = 282m),λcell=32, the demanding frequency bandwidth for meeting 103Gbpskm2will be B = 976.56MHz. Currently, getting such bandwidth is almost impossible. These are several most prominent in ability challenges for wireless communications and networks, for example, how to achieve all things connection and greatly exceed direct transmit and access capabilities of the existing network, and how to achieve an ultra dense network with much more than the capacity of existing network.
This paper investigated the data models of WBD, the wireless data mining, the wireless knowledge and the wireless knowledge learning (WKL), and proposed a basic mode of WKL including the user grouping unit and the task calculation unit.
Nowadays, the importance of big data is recognized by almost all industries, where data can be used to drive various industrial development, and the innovations of digital technology stem from data become essential. Recent research on big data emerges in the wireless field, which has brought exciting aspiration for the most prominent challenges for wireless communications and wireless networks. Reference [3] reviewed typical applications and specific cases for wireless big data (WBD),with many mature applications in the fields of wireless operation and service, network planning/optimization/ operation and maintenance.
In recent years, the re-emergence of AI based on big data, especially, the application of machine learning, deep learning, and reinforcement learning, has provided new opportunities and possibilities for wireless communications and wireless networks based on WBD [4].
The intelligent transmission technologies of physical layer and the optimization technologies of intelligent network design have attracted extensive interests from research and development. However, the fundamental topic of WBD has not been addressed yet, which is particular important with many challenges and thus deserves study and discussion.
1.2 Related work
As all know, the data that computers have collected and processed grows exponentially in volume, variety and velocity. Right now,big data has become a major research topic in the computer world, which has been deeply worked on. While the computer ability is growing dramatically, the data size could be unlimited. Thus, the deep investigation on mathematical foundation of big data is required, to avoid the failure to solve problems efficiently. However, the heterogeneity, largescale, timeliness, complexity, and privacy problems with big data impede progress at all phases of the pipeline that can create value from data, on what data to keep and what to discard, and how to store what we keep reliably with the right data. All need the basic results from fundamental study of big data [5].
Ref. [6] considers big data as an important field of data science, and summaries the opportunities, challenges and potential future strategies for mathematics and statistics, and the added value that big data can bring to industry.In Ref. [7], after offering a broader definition of big data, it focuses on the analytic methods used for big data, whose distinguishing feature is on the analytic methods related to unstructured big data and structured big data,to capture other unique characteristics. A concept on the adjective “big” as a mathematical operator is proposed in Ref. [8], which fits the concept of being “linguistics variable” as per fuzzy logic, to give a possible mathematical theory as a foundation for big data research.The heterogeneity, scale, timeliness, complexity, and privacy problems with big data impede progress at all phases of the pipeline that can create value from data, about what data to keep and what to discard, and how to store what we keep reliably with the right data, all need the support from foundation study of big data [5]. Therefore, Ref. [9] points out that we only know little on the big data paradigm yet.One wonder if new mathematical foundation is emerging for todays and futures challenges.
Artificial intelligence (AI) makes it possible for a slow and tiny brain electronic system to perceive, understand, predict, and manipulate a world far larger and more complicated than itself. Theoretically, workers in AI can choose to apply their methods to any area of human intellectual endeavor [10]. The most important of AI methods is learning, machine learning,deep learning, and reinforcement learning, all of which are based on the trial and selection of artificial neural network structures, and is breathing new life into artificial intelligence research [4].
Against these research progress, the study on the fundamental problems of big data and learning mechanism has been very helpful for the understanding and application of WBD.However, we also know little on the mathematical models and fundamental theory of big data, not to mention wireless big data yet.Study this issue is a great challenge for future wireless.
1.3 Contributions
In wireless communications and wireless networks, the most fundamental task is to solve the matching issues of the demand, ability and environment. We can count on making full advantage of WBD and wireless knowledge learning (WKL) to solve such important problem.
Demand, denoted as S(t), is user service request from outside, including transmission requirements, deployment requirements, service requirements and so on. In general, S(t)is a huge amount of data, cluttered, dynamic and of low value density from a wide variety of users. It is needed to investigate the value mining and the data rearranging or combining(data modeling) for different wireless applications.
Capacity, denoted as C(t), is the achievable capabilities of wireless communications and networks, including transmission capacities,access capabilities, quality of service, and so on. We can make full use of the existing knowledge of wireless communication and wireless networks, including formulas, algorithms and models, to build effective, dynamic, data and model integrated, intelligent knowledge entities, for matching and meeting the massive service demands.
Environment, denoted as Y(t), is the impact of the external environment of the wireless communications, including interference and change such as transmission environment, access environment and service environment. To facilitate mathematical fundamental research on WBD and wireless knowledge, we assume that environmental disturbance and change are given at time and area. Unless otherwise specified, such impact will be temporarily ignored.
Therefore, this paper attempts to explore the fundamental theory and mathematical expression of WBD and WKL, in order to achieve the optimal matching of the demand,the ability and the environment. This means that we need to answer two basic questions:How do we represent the values of data set and the knowledge measure, and how to make mathematic description of these data sets and knowledge volume to solve the optimal results for meeting the massive demands.
The contributions of this article can be outlined as follows,
● Based on the data model of WBD, basic modes of wireless data mining and the mining method are proposed, i.e., selecting the appropriate feature variable (knowledge variable) and establishing the corresponding user grouping, to optimize the wireless communications.
● The concepts of wireless knowledge and the knowledge entropy are addressed,which provides mathematical expression and measurement of wireless knowledge based on WBD.
● The basic mode of data mining using knowledge variable is also the base mode of knowledge learning for wireless communications and wireless networks, to reduce the optimization complexity.
● Two examples are given to illustrate that the proposed model of WBD, data mining,and WKL can not only apply in the high rate transmission of a large number of users, but also optimize the joint design of
wireless networks.
The rest of this paper is organized as follows. Section II discuss the fundamental problem of wireless communication based on WBD. Section III addresses the data mode of WBD and the wireless data mining. Section IV proposes the wireless knowledge and wireless knowledge learning (WKL). Section V shows practice examples using the data mining and the knowledge learning. The conclusion is in Section VI.
II. BASIC CONCEPTS OF WBD
2.1 Fundamental problem on wireless communications
For future wireless communications and wireless networks, the most fundamental problem is to solve the tradeoff issues of the demands,abilities and environments. The service demands from a large number of users are a very big data, whose transmission and receiving are the dual problem of being both wireless and big data. Full advantage of wireless big data (WBD) and wireless knowledge learning(WKL) must be taken to analyze and solve.
Assume the data set of service demands from M users (u1,… ,u2,… ,uM) per km2is S(s1,… ,sm,… ,sM) (Mbps/km2), then, the total service demands can be expressed as follows,
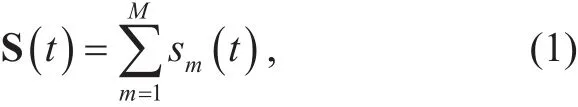
where sm(t) :( sm,1,… ,sm,t,… ,sm,T) is the service demand of m-th user at T time slots (a signal frame). If M >> 1, the service demands S(t) may be very large, and even can be close to infinity theoretically.
The service demands from users may also be the media requirements, delay features,transmitting traffic, etc. These are all called as the service demands, only their data unit is different due to the problem.
The capability achieved by wireless communications and wireless networks is denoted as C(t) (Mbps/km2), is a function of the resources consumption (Q), the condition parameters (X) the environmental parameters (Y). Then the capability of wireless communications and wireless networks can be expressed as
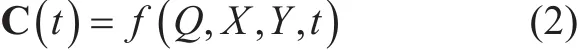
where the data volume of Q and X may be also large. In general, the environment parameter (Y) is constant at a given time and region. No matter how to choose the resources consumption (Q), the capabilities of wireless communications are always limited.
For M >> 1, the capability C(t) of wireless communications using existing methods will be not possible to meet the huge service demands S(t), as following.

Obviously, the most fundamental target of future wireless communications is to guarantee that the huge service demands and the limited communication capacity will tend to the same.These are only two possible ways: group the service demands and reduce its dimension;and greatly improve the communication ability using new way. It is the main objective of this article.
2.2 Definition on WBD
The wireless service demands coming from a large number of users and the transmission data from wireless communications and wireless networks are the very huge data, which belong to the big data [11]. In truth, we have to give a specific definition of these big data with wide range and particularity of wireless applications, which are called as wireless big data (WBD).
In 2011, the McKinsey Global Institute has published the definition of big data in [12]: “the scale of data exceeds the capability of acquisition, storage, management and analysis for conventional data-base software, which can be characterized by the massive amount of data,fast data flow, diversified data type, and low data value density.” Thus, the wireless big data(WBD) are defined a data set that can be used to greatly improve, optimize, innovate, and reform the existing wireless communication technologies and wireless networks.
In order to fully use the currently occurring demand data and the demand data that have been stored in WBD database before, effective and robust data sets need to be obtained.
Assume, the currently occurring data scenario is denoted as ω0, the past data scenarios stored in the database before are denoted as ω1,… ,ωd,… ,ωD. Then, the data space of all data scenarios of the huge demands can be expressed as ΩS, ΩS= (ω0,ω1, … ,ωD), for D >> 1.
According to data mining and deterministic equivalent (DE) [13], the huge service demands S(t) shown in (1) can be transformed into G user groups with small amount of data and lower complexity, via selecting on suitable wireless feature variable, given by

where (*)|ΩSdenotes the (*) value in data scenario ΩS.
Based on the above considerations, wireless transmission capacity can approached by the achievable deployment, which transforms the total capability requirement C(t) into the combination of G groups, i.e.,

Then, to satisfy the demands in different cells, we have

Therefore, to solve the matching problem between the demands and abilities in wireless communications, the first step is to solve user grouping of huge service demands based on the suitable data model of WBD, which will be discussed in next section.
2.3 Achieving goal of WBD
According to above analysis, the achieving goal of WBD is that the huge service demand S(t) can be transformed into Sg(t) ( g = 1,… ,G ), with the small data amount and the low complexity. Then, the formula (6) can be re-expressed as,

Thus, the first step is to solve user grouping of huge service demands, which is to complete the analysis and calculation for achieving goal shown in formula (7).
III. WIRELESS DATA MINING
Wireless data mining is a process of extracting useful information from very large amount of data or stream of data according to the wireless problem using feature variables, to reflect and achieve the applying capability of WBD.It is a challenge due to big data’s volume, variability and velocity [14].
A big data processing model has been proposed in [15] from the data mining perspective. Such data-driven model involves demand-driven aggregation of information sources, mining and analysis, user modeling,and security and privacy considerations.
Due to big data’s volume, variability and velocity [14], there are great differences among the industries, technologies, applications and services in wireless communications and wireless networks. More requirements introduce more complicated the issues and the more difficulties to reconcile and optimize.
Therefore, we analyze and build data mode of WBD using wireless data mining based on feature variables, which can be used to build the user grouping by extracting, or sorting out,or reorganizing the wireless big data as the valuable data set or data model came.
3.1 Data model of WBD
Note that WBD have the heterogeneity, largescale, timeliness, and complexity problems,which greatly impede progress at all aspects of wireless communications that can create value from data. It is a great challenge to reorganize the data set from very huge and messy WBD according to the wireless purpose. Thus,it is necessary to organize, reconstruct, and standardize the data structure of WBD, which is the important basis for the effective use of WBD.
Recall that in formula (1), the huge service demands of M users are S:( s1,… ,sm,… ,sM),M >> 1. Assume a feature variable selected for resolving wireless problem is V :( v1,… ,vg,…vG), for G < M, which is also called as 1stvariable. Then, to divide M users and their service demands into G groups, the corresponding relationship among feature variable, users, and demands is given by

where M :( u1,… ,um,… ,uM).
1) Vector Data Model: Based on formula (8), the vector data model of WBD is a grouped data set sorted out from WBD by feature variable (grouping variable)V :( v1,… ,vg,…vG) given by

where g =1,2,…,G.The vector data model is very facilitation of the vector calculations.
2) Polynomial Data Model: When we choose high-order polynomial to express the data model of WBD [16], the grouped data set shown in Eq. (8), S:( S1,… ,Sg,… ,SG) can be expressed as

which is called as Polynomial Data Model of WBD, is a function of the grouping variable v. The complexity of the original data set is reduced to be the suitable for the algebraic calculation.
3) Matrix Data Model: In order to satisfy the increasing throughput and various performance demands, future wireless communications and networks needs to adopt new approaches of matrix design, which ultimately results in very large random matrix.For the transmission demand of m-th user sm(t) :( sm,1,… ,sm,t,… ,sm,T), the total service demand of M users is
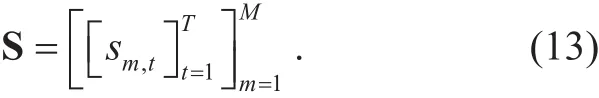
When T >> 1, M >> 1, S is a large scale random matrix. Therefore, the grouped data set of WBD can be expressed as a matrix, matrix data model of WBD, that is

where SGdenotes the demand data set reorganized by feature variable V, and also is a lower level matrix than S shown in (13). Therefore,the matrix data model is particularly suitable for the matrix calculations.
In short, these data models all are different representations of data set of WBD reorganized by the feature variable (1stvariable), to fit different computing requirements.
3.2 User grouping
User grouping is to divide the huge service demands of a large number of users into different groupings. Firstly, the feature variable(1stvariable) needs to be selected to reduce effectively the dimensionality, [17].
For the 1stvariable denoted as X :( x1,… ,xg,…xG), it may picked out from sm(m =1,2,… M) as the grouping variable to divide the massive users into G groups, which depends entirely on the wireless problem to be solved. Then the original demand matrix can be expressed as G user groups, given by
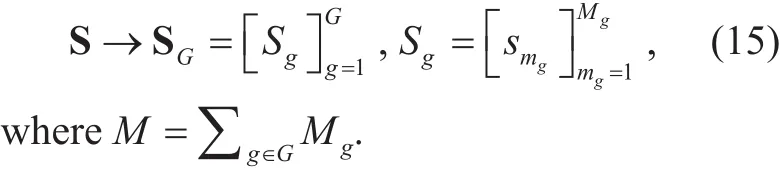
For the optimization of g-th user grouping,the selected 1stvariable is xg= sig∈Sg, to structure the grouping demand matrix of g-th group, i.e.,

For this reason, we propose to full use of the currently occurring demand data and the very big data of demands that have been stored before, to perform WBD mining and deterministic equivalent (DE) analyzing [13],to obtain robust and reliable grouping results.
Letting ω0denote the currently occurring scenario of demand data, ω1, …,ωDdenote the data scenarios of demands used and stored before, the data space of all usable scenarios of demand data is given by ΩG=(ω0,ω1, …,ωD).
Assuming ∆Sm/gis the objective function ofΩGwhere varies the different ωdthe necessary and sufficient condition of optimal selecting m∈Mgis
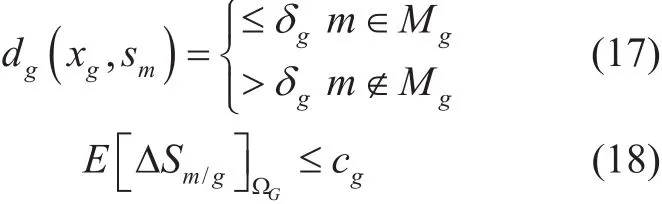
which is the decision condition achieving optimal grouping when δgand cgall are very small amount.
According to the above condition, selecting m-th user among the M users admitted to user grouping can be achieved. Via the same processing, after selecting m ∈ M1,… ,m ∈Mg,… ,until m∈Mg, there are G user groups and M1+ M2+ … + MG=M.
IV. WIRELESS KNOWLEDGE AND KNOWLEDGE LEARNING
4.1 Concept of wireless knowledge
1) Definition on Wireless Knowledge: The word of knowledge is nothing special in a variety of application situations, while the word on study knowledge has also been used even more. In Ref. [18] published in 2007 by WILEY Inter Science, the formulation of systematic conceptions of data, information, and knowledge are listed in the “Knowledge Map of Information Science”, whose are defined as: data are unprocessed, unrelated raw facts or artifacts; Information is meaningful data, or data arranged or interpreted in a way to provide meaning; while Knowledge is the most complex, the product of a synthesis in our enriched information by a persons or a systems own experience.
Regarding the creation and measurement of knowledge, Ref.[19] reviewed the current measurement methods from samples of 63 empirical papers, and proposed a measure on different attributes for knowledge creation. It facilitates knowledge creation operationalization in a way that allows assessment against existing comparable definitions. But there is no specific discussion of wireless knowledge.While discussing how to link creation, usage,and transfer of knowledge to an expected performance, increasing competitiveness has not been fully discussed yet, as shown in Ref.[20].
Thus, it is crucial to investigate wireless knowledge in the specific field of wireless communications.
This article defines that the wireless knowledge is the general term of the description,understanding, and cognition for all issues involved in a wide variety of wireless communications and wireless networks. In other words,wireless knowledge includes the description,understanding and cognition for wireless users, transmission, system, networks, services,and so on. Based on definition of wireless knowledge, the data mining of WBD is from the feature variables and data models of WBD.
Then, the feature variables selected in value mining of WBD, first and second variables,are a kind of wireless knowledge.
2) Wireless Knowledge Measure: Given the importance of wireless knowledge for future wireless communications, we define a measure of wireless knowledge: knowledge volume and knowledge entropy.
Wireless knowledge volume: If the knowledge of wireless event A is known, via study-ing a wireless event B, one can obtain how much new and avail knowledge, which is defined as knowledge volume of event B relative to event A. That is, how much knowledge of event B is learned based on event A, which is denoted as “KB/A”.
Consider the similarity degree of event B to event A, denotes as SB/A. The knowledge volume of event B relative to event A is given by

If the difference degree between event B and event A is denoted as DB/A,DB/A=1− SB/A, the knowledge volume of event B relative to event A can also be expressed as
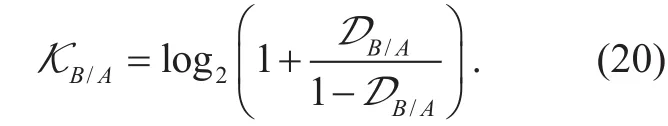
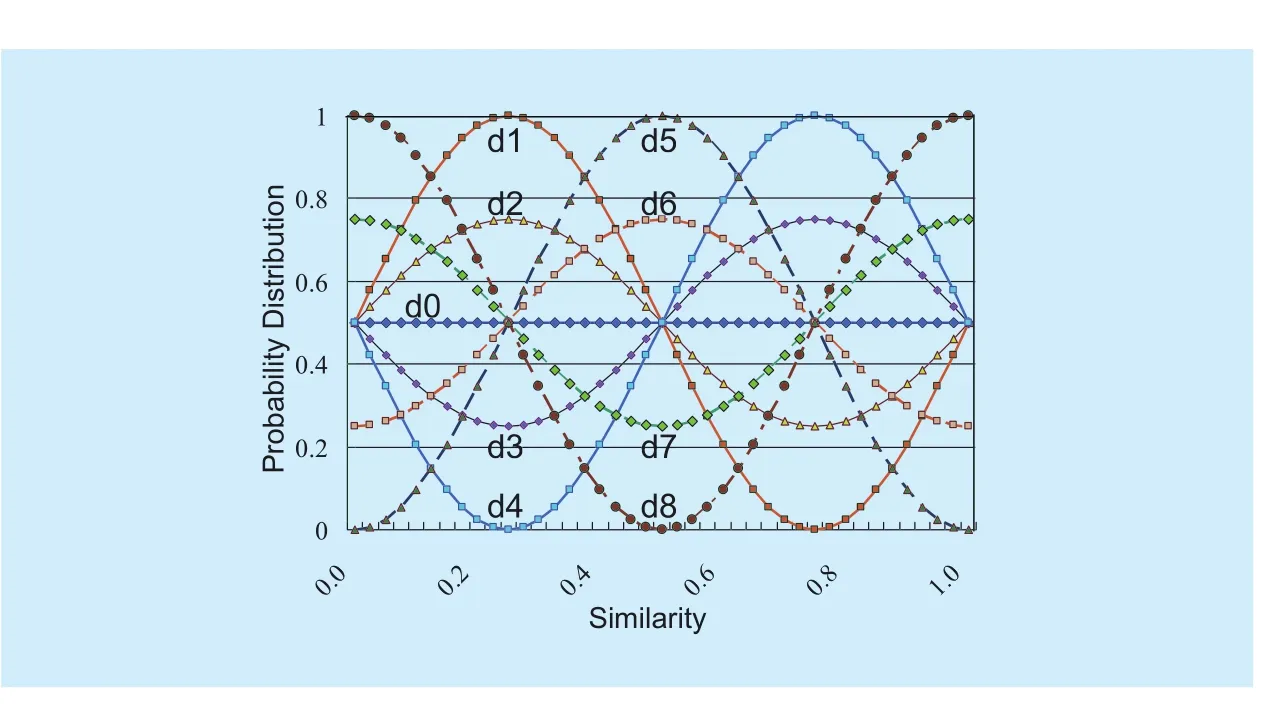
Fig. 1. Probability distribution of event B to event A.

Fig. 2. Knowledge entropy for different distributions.
For DB/A= SB/A=0.5, a half is the same and a half is different. Then, the knowledge volume of B relative to A is equal to(KB/A=1). For DB/A>0.5, we have KB/A>1 and vice versa.
Wireless knowledge entropy: From the definition and analysis on information theory,if event B is composed of a very large number of small events b with different probabilities p(b), the expected value of knowledge volume of event B relative to event A is defined as the knowledge entropy of B relative to A,HKB/A,given by

When event B is a discrete random variable with N values, i.e., B :( b1,b2,… bk,…bN), the knowledge entropy of event B relative to event A is given by
Based on the definition and analysis, we can derive the following important characteristics of knowledge entropy:
Uniqueness: According to Eq. (20, 21), as long as the similarity of event B relative to event A is a given value for given probability distributions, the knowledge entropy is a determined amount without ambiguity.
Zero Knowledge Entropy: If the similarity degree of event B relative to event A is 1,i.e., the two events are exactly the same, the knowledge entropy of each other equals zero,i.e., HKB/A=0, if B≡A.
Dependence of knowledge entropy: According to Eqs. (20, 22), the size of knowledge entropy, which depends on the similarity degree of B with respect to A, also depends on the probability distribution of similarity.
Figure 1 shows the different probability distributions, uniform (d0), SIN types (d1, d2,d3, d4), and COS types (d5, d6, d7, d8). figure 2 shows the knowledge entropy of different distributions.
The results illustrate that if there is a high probability of occurrence in an interval with a low degree of similarity, the knowledge entropy is large. And if there is a high probability of appearing in an interval with a high degree of similarity, the knowledge entropy is small.This is the theoretical basis for the user grouping.
4.2 Basic mode of WKL
Wireless knowledge learning (WKL) is a process to minimize the knowledge entropy of the certain event or the given task in wireless communication and wireless networks,through the processing and using of known knowledge and specific variables.
A basic mode of WKL is proposed to achieve the given wireless task, which consists of two units supported by relative feature variables, i.e. the grouping unit and the task unit,as figure 3.
In the user grouping unit of basic mode of WKL, first the huge service demands of M users are clustered into data models with G user groups according to the grouping variable (1stvariable). Then, the task calculation unit (task execution unit) of basic mode of WKL will implement the given task through the analysis and calculation using the selected task variable(2ndvariable). The grouping variable and task variable are called as the knowledge variables.
Furthermore, the outputs of task calculation unit are compared with the inputs of service demands to evaluate the calculating result. The selected two knowledge variables and the relating parameters are adjusted until the output of task execution unit is optimal.
The basic mode of WKL is that the user grouping unit uses WBD to realize perception and prediction, and the task calculation unit is based on knowledge variables to realize the decision and the optimization. It is a typical AI learning structure.
1) Learning of User Grouping: As the analysis on user grouping in Section III,transmission demands S:( s1,s2,… ,sm,…sM)with M user occur at the same time, and then the probabilities of appearance of sm,p(sm)=1 (m =1,2,… M), are the same.
When s1is selected as first knowledge variable, the similarity degree between sm(m ∈ M)and s1is denoted as Ssm/s1, and the total of knowledge volume of the demand data set S before learning is
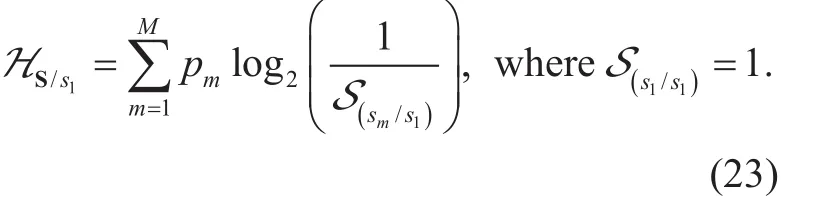
The first knowledge variable X :( sx1,… sxg,…sxG) is picked out from sm(m =1,2,… M) as the grouping variable, to divide the M users into G groups SG≜(S1,… Sg,… SG) as shown in (16).We need to select the optimal variables,such that the amount of knowledge after the group learning is minimized, i.e.
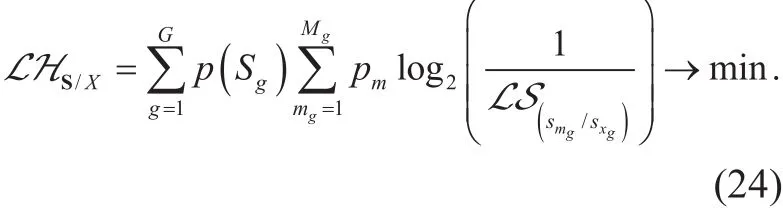
If LHS/X=0, it is full learning. As long as> S(sm/s1), the knowledge entropy after learning must be LHS/X< HS/X. Therefore, the group knowledge learning can reduce the total of knowledge entropy.
2) Learning of Task Execution: After performing user grouping, the next step is to finish the task calculation for each grouping, to minimize the resource overhead, as shown in formula (5).
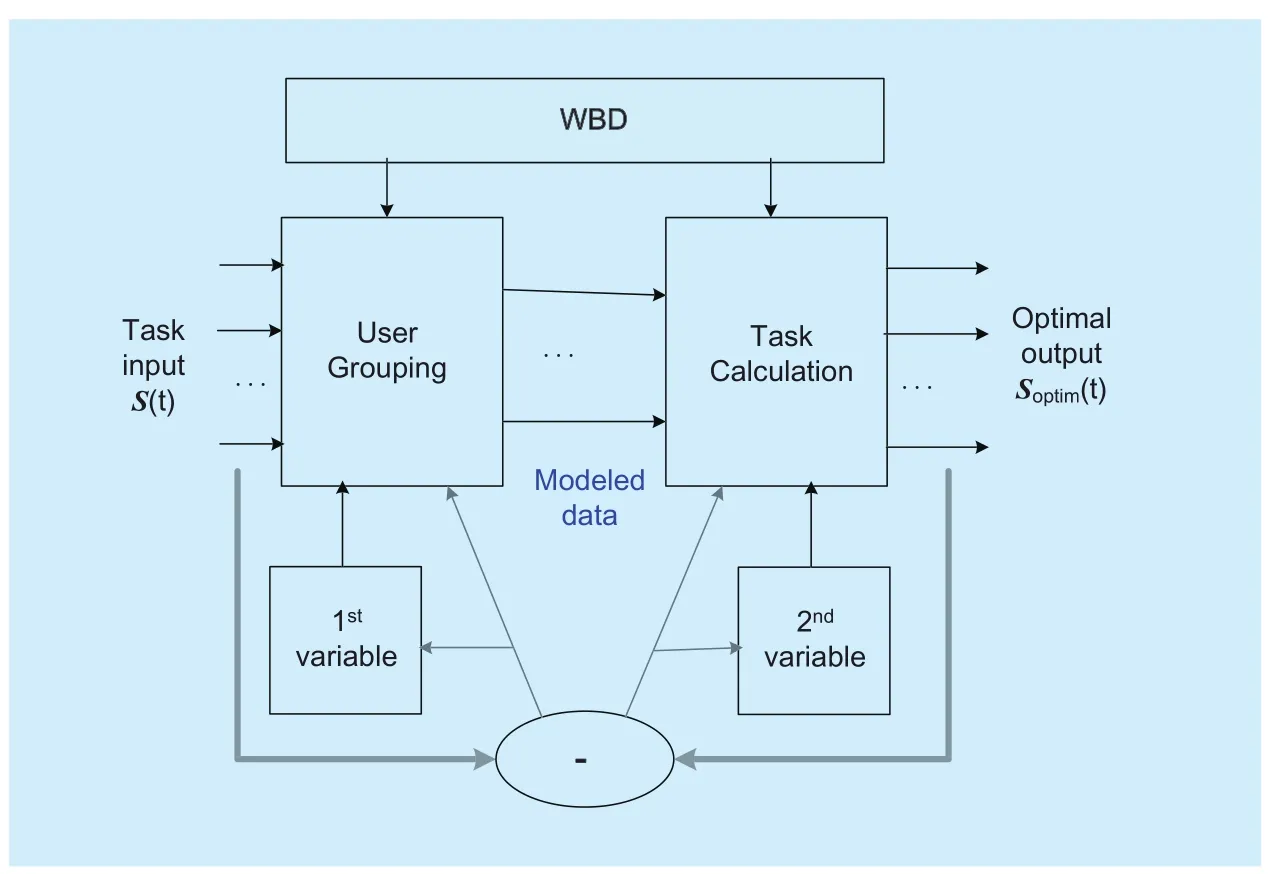
Fig. 3. Basic mode of wireless knowledge learning.
The 2ndknowledge variable is denotes as A :(a1,...ae,...aE), which may be various information content, channel fading, access capability of different cell, etc.
Let Sg,aeis the new description of Sgafter chosen 2ndknowledge variable ae, i.e,

Assume that the resource cost is denoted as Q(Sae,g) shown in (5). Then, based on ΩEdata scenarios of WBD, the best choice of 2ndknowledge variable, i.e., the decision criterion of minimum resource cost, is given by

where Q(·) is the amount of resource cost of a variable (·);denotes the expected value of the resource cost amount of the variable (·) based on WBD set Ω. The description of task execution of WKL can be given as follows. Suppose that A :(a1,...ae,...aE) is selected as the 2ndknowledge variable. Let Sae,gbe new description after Sgchoosing variable ae, i.e.,Sg→Sae,g.
When a1is known, the knowledge entropy of different Sgrelated to a1is,

Therefore, the task calculation unit is performing computation from a2to aEsequentially, where based on ΩEdata scenarios of WBD the smallest knowledge entropy is selected from different ae(ae∈A; ≠ a1). Then, it can be found that the expected value of the resource overhead can reach the minimum, i.e.,

4.3 Learning efficiency
The efficiency of WKL can be defined as the ratio of the reduced knowledge volume after learning over that before learning, expressed as follows,
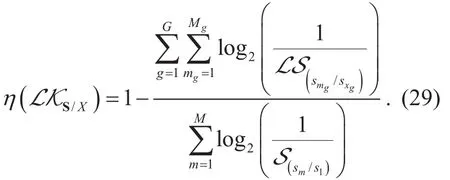
Obviously, the learning efficiency is 1 for full learning. In general, it is less than 1.
V. PRACTICES OF WBD AND WKL
5.1 Data compression of massive users
As shown in formula (1), the service demands S(t) of M users need to be transmitted.If the transmission demand of i-th user is si(si= ( si,1,… ,si,t,… si,T), i =1,2,… M ), then the M users and their demands are M:respectively, where t is the number of time slots for 1≤t≤T.
Assume the transmission content of i-th user Si=(si,1,...,si,t,...,si,T), is known as the grouping variable. Then, we can compute the difference vectors (∆Smi) between Smand Sifor m=1,2,3,… M and m≠i, which is first step of knowledge learning shown in Eq. (16). Thus the service demand matrix of M users after the grouping learning can be expressed as

Set a label β of the difference degree of m-th user and i-th user at t-th slot. Then we have where δ is infinitesimal.
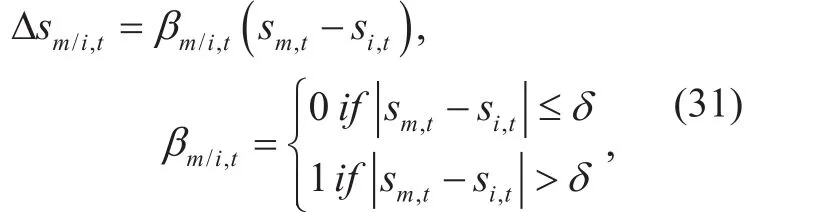
Therefore, the number of difference elements in ∆Smiis the number of nonzero elements, i.e.,

where the difference degree between the grouping variable and m-th user vector is expressed asand the similarity degree of the grouping variable relating to m-th vector is given by
If T >>Tm/i, the difference degree between the grouping variable and m-th user will be very small, and the knowledge volume after learning also is very small. In other words, the amount of transmitting data is also very few.
According to Eq. (29), the efficiency of knowledge learning between i-th and m-th users is
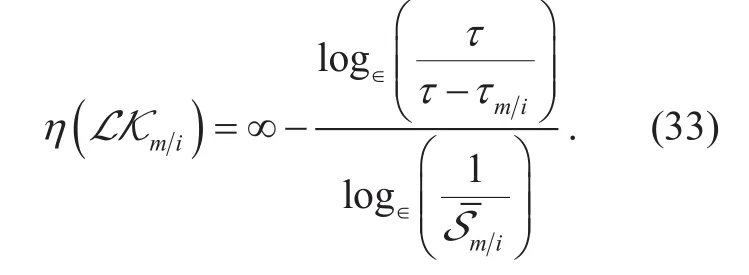
Example 1:
We give an example with 70 similar active users, the users are grouped into one group in Case 1 and the users are grouped into 6 groups in Case 2.
Case 1: figure 4 shows the difference degree between M =70 users and x1=s1, only a user group, where the difference degree is higher. The average of difference degree between (M − 1) users and x1=s1in G=1,g=1is 0.356. Based on Eq.(21,22), for only a user grouping (G = 1), the knowledge entropy of Case 1 is 1.559 for the evenly distributed, given by
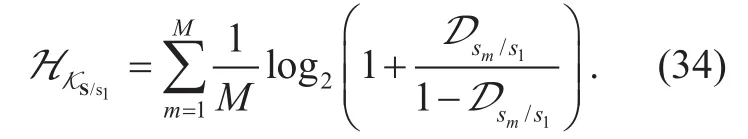
Case 2: figure 5 shows the scenario where M = 70 users are divided into 6 groups. The number of users in all group Mgare different,M1=10, M2=23, M3=18, M4=5, M5=5, and M6=9, but the difference degree within the group is lower than 17%. Thus, the average of difference degree are cg={0.034, 0.0734,0.0803, 0.0201, 0.0112, and 0.0626}, the knowledge entropy of Case 2 is 0.429 for the evenly distributed, given by
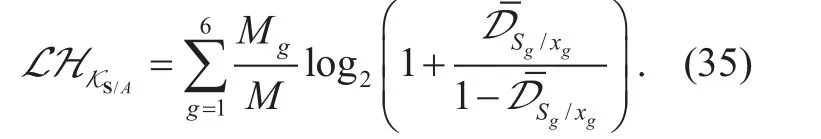
Thus, the compression efficiency is

Fig. 4. The different degree relating to s1.
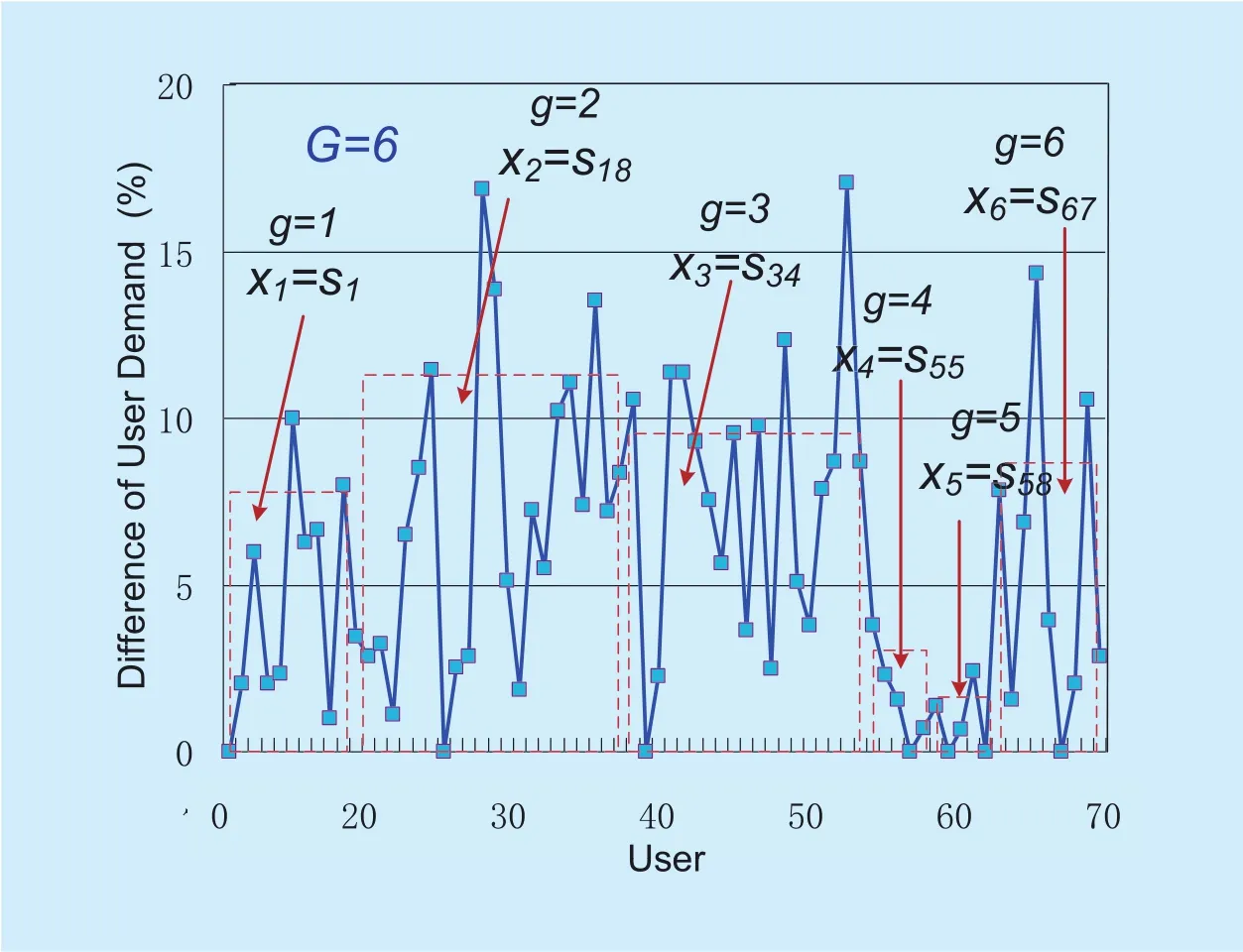
Fig. 5. The different degree within grouping for 6 groups.
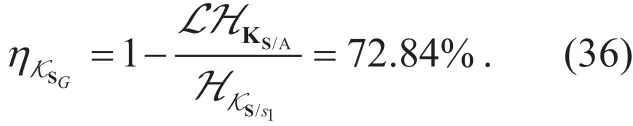
The further, simplifying the description of grouped user demands is depending to the specific content of the user’s needs, such as data,characters, words, phrases, etc. Their comparison and selection are not difficult, are omitted here.
5.2 Cell coverage of ultra dense networks
We study how to deploy different sub-networks (subnets) to meet the huge service demands of M users, to build an ultra-dense network (UDN) with the minimum resource cost. In addition to M users and M service requests, a new variable is added, the speed of user movement, which is directly related to the radius of network cell. The three types of parameters are given as follows,

For supporting different moving speeds of users, based on the corresponding relationship between the cell radiuses of subnets and the moving speeds of users, we must select different radiuses of cell corresponding the different moving speeds, i.e.,
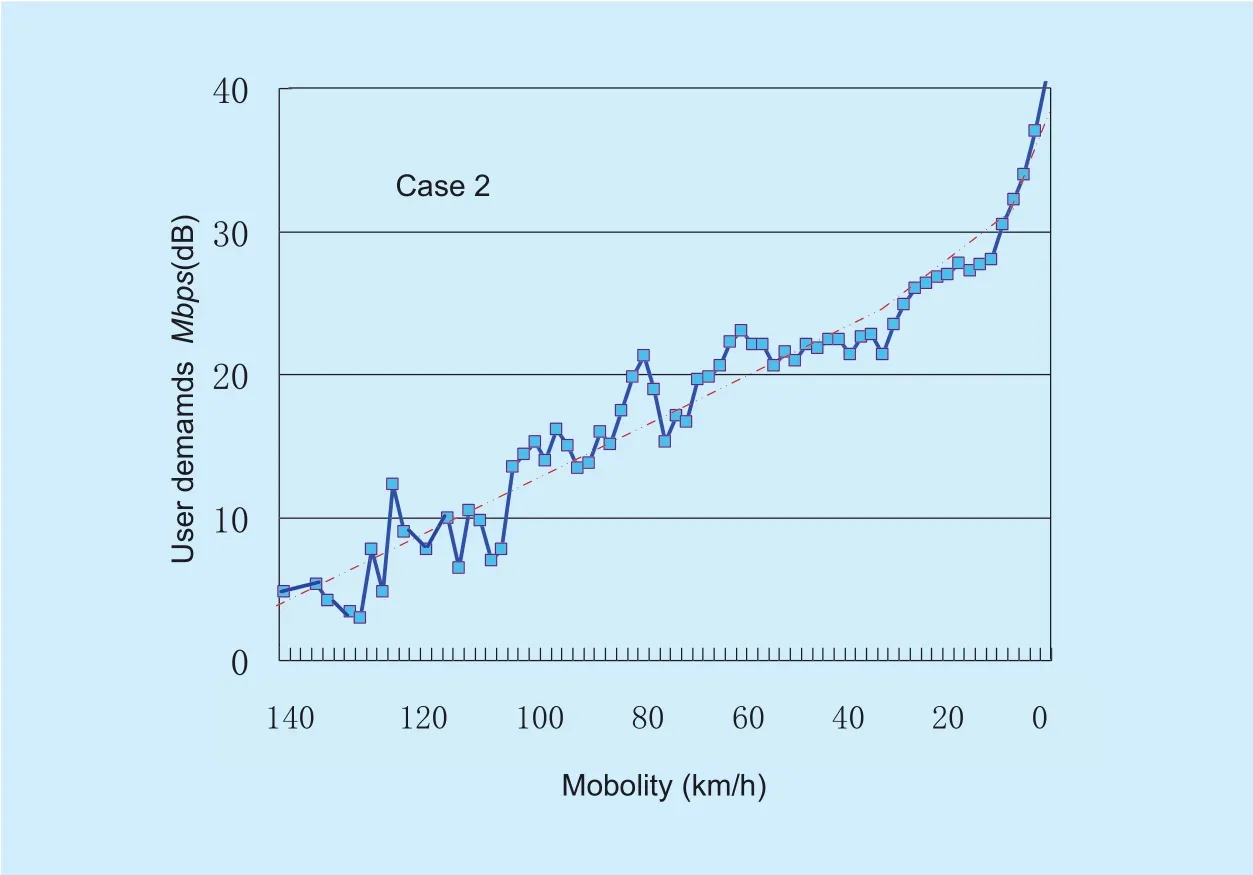
Fig. 6. User demands of different moving speeds.

where the highest moving speed corresponds to the maximum radius of cell.
Conventionally, cell coverage can be completed by selecting a macro cell network that supports the highest mobile speed. Assuming that the total of service demands per unit area of M users is S(t), the capacity per unit area of macro cell network is

where bmacis the overhead of frequency bandwidth and σmacis the spectral capacity per unit area of macro cell network. If M >> 1, bmacwill become big, which will not be realistic.
Now, the user grouping selects the speed intervals of user movement as the 1stknowledge variable using WBD sets stored in database(Ωnet), which are divided into G groups. Thus,the corresponding relationship between the speed intervals of users and the transmission capacity of subnets is given by

where [Vg,Vg+1) is the g-th speed interval supported by Csubgsubnet, and
According to Eq. (38), the transmission capability that can be achieved by UDN composed of G subnets is given by

where bgis the required bandwidth of g-th subnet, and BG=is the total bandwidth.
Let subnet 1 be the macro cell as basic cell of UDN, whose area spectrum efficiency is σ1= σmac. Then, the area spectrum efficiencies of other subnets are higher, i.e.,
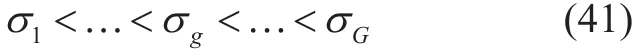
According to the above formula (41), the resource consumption of UDN is BG, the consumption of macro cell network is bmacas reference, bmac> BG, the knowledge volume of resource consumption after building an UDN is

As the actual demands of M users and the results of big data prediction will always be different to some extent, further adjustment for optimization needs to be performed in the task execution module.
When the deployed capacity by the basic subnet is known, the achievable capacity of other subnets must be learned from the underlying subnet, for minimum resource overhead.The learning result of optimal coverage of UDN can expressed as
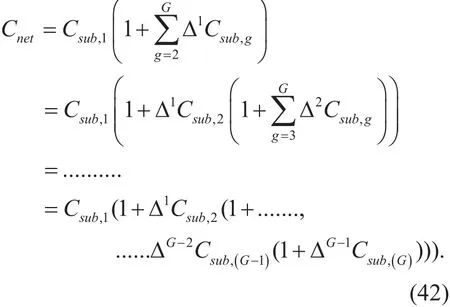
where “Δ” denotes the difference between the actual value and the prediction, and CNetis the actual capacity after adjusted.
Among them, the difference of each learning is Dg/g,1. We have proved that the knowledge entropy after learning process, HNet, will be minimized if the condition is satisfied, i.e.,

where ”Δ” denotes the difference between the actual value and prediction.
Example 2:
Now, we provide a data set of service requirements, as shown in figure 6, where the services demands (Mbps) of 200 users are organized based on the moving speed (140km/h -0km/h) using a 2km/h of quantization interval.
At the same time, we adopt four subnets.Subnet 1 is a typical macro cell cellular subnet; Subnet 2 is a micro cell subnet with fractional frequency reuse, which can also adopt cooperative or antenna active system techniques; Subnet 3 has a small cell structure for outdoor coverage; and Subnet 4 deploys pico/femto cells for indoor applications.
Assume there is flexibility to choose G subnets to serve the service demand, where 1 ≤ G ≤ 4. Simultaneously, we select three intervals of moving speed: 1) Evenly split, 2)Multiplied dropping and 3) Optimal interval,where the total bandwidth consumption for different strategies are summarized in figure 7. When G = 1, only Subnet 1 (macro cell) is selected to support high moving speed, and the resource cost (frequency bandwidth) is Btotal= 542.9 MHz. For G = 2, there are three configurations: (1; 2), (1; 3), and (1; 4). For G = 3, there are also three configurations: (1;2; 3), (1; 2; 4), and (1; 3; 4). For G = 4, all the four subnets are used, the minimum frequency bandwidth using proposed optimization method can be reduced to Btotal=53.0 MHz, which is a 10x reduction than coverage cost using only Subnet 1.
VI. CONCLUSION

Fig. 7. The total bandwidth consumption for different strategies.
Facing the fundamental problem of matching the service demands, the wireless abilities and the environments, this paper investigated the data models of WBD, the wireless data mining, the wireless knowledge and the wireless knowledge learning (WKL), and proposed a basic mode of WKL including the user grouping unit and the task calculation unit, to achieve the optimal matching of demand, ability and environment, as the R&D fundamental of future wireless communications and wireless networks.
The analysis results illustrated that we can make full advantage of WBD and knowledge learning to solve the fundamental problems based on data model of WBD, data mining and learning.
The key ideas of this paper is:
● The computable data model of WBD is a basis for big data used in solve wireless problems.
● The establishment of the data model relies on mining valuable and regular data for user grouping and simply describing.
● The basic mode of knowledge learning is a useful module that solves different wireless problems driven by the relative knowledge variables.
● The definition of knowledge and knowledge entropy, as well as the establishment of the corresponding relationship between learning mode and knowledge learning, can be used to quantitatively describe and solve the optimal solution for wireless problem.The analysis results and practice examples illustrated that the limited communication capacities may achieve massive transmission demands using data mining and knowledge learning.
ACKNOWLEDGMENT
This work was supported by Key Program of NFSC (61631018).
杂志排行

China Communications的其它文章
- Pedestrian Attributes Recognition in Surveillance Scenarios with Hierarchical Multi-Task CNN Models
- Cost-Aware Multi-Domain Virtual Data Center Embedding
- Statistical Analysis of a Class of Secure Relay Assisted Cognitive Radio Networks
- Moving Personal-Cell Network: Characteristics and Performance Evaluation
- A Novel 3D Non-Stationary UAV-MIMO Channel Model and Its Statistical Properties
- Mode Selection for CoMP Transmission with Nonideal Synchronization