基于神经网络的出版选题预测模型
2018-12-25康宝中林海
康宝中 林海
近年来,随着图书销售数据管理的规范化、信息化,图书选题策划人员面对书城近期销售排行榜、销售月报以及《开卷图书调查报告》等众多报表,对其进行深度研究与定量分析,获得的结果无疑极有价值,也是未来图书市场调查研究的趋势。图书选题作为图书出版的最初环节,历来被出版单位所重视。图书选题策划的基本流程包括信息筛选、选题设计、选題论证、选题优化等,图书销售数据能够直观反应市场规律与用户消费倾向,对选题策划有着重要的影响。但出版单位对于确定图书选题类别以及确定印刷量显得力不从心。
鉴于图书市场具有短期的波动性与中长期的周期性、销售数量巨大与销售品种繁多并存等特点,给出版单位选题策划带来很大困难。根据图书市场短期波动性特点,提出了使用改进神经网络模型预测图书印刷量,可为出版单位确定各地域的指定图书选题印刷量提供参考。
一、基于神经网络模型的销售预测分析
人工神经网络的思想源自仿效生物学神经网络,当今地球上所有生命体的大脑均由神经网络组成。现代神经网络项目通常有几千个到几百万个神经单位和上百万个连接,这几个数量级虽然远不如人脑复杂,但已经接近蠕虫的计算能力。
(一)神经网络算法简介
反向传播BP(Back Propagation)学习算法的前馈型神经网络简称BP神经网络(BPNN)。BP神经网络主要特点是信号从输入层通过隐含层直至输出层整个过程保持前向传递,依次经过隐含层,其中隐含层可能有多层,通过逐层神经元后,最后从输出层输出神经网络处理结果。其中,上一层神经元的结果只影响下一层神经元的操作。如果输出层的输出值达不到预期目标,则神经网络转入误差的反向传播过程,根据预测误差不断调整神经网络的权值,再进行信号的前向传递,反复迭代,使神经网络的输出值不断逼近目标输出值。神经网络的拓扑结构如图1-1所示:
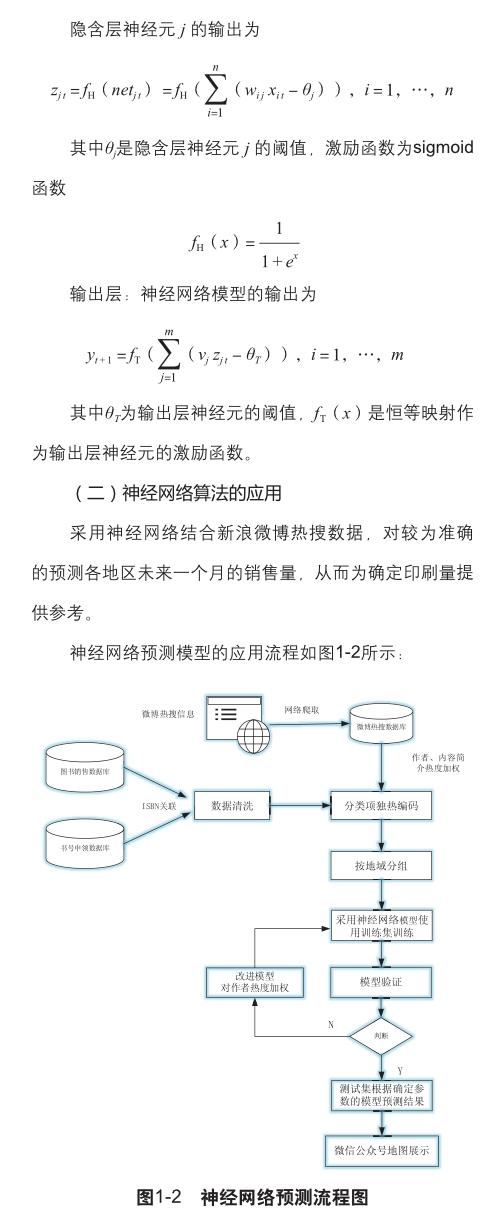
由图1-2可知,整个神经网络预测流程分为三个主要部分:第一部分为数据的清洗准备阶段;第二部分为训练集训练阶段,通过验证增加作者与内容热度模型较普通模型获得更好的热点事件预测效果,当RMSE基本不变时,最终确定预测模型;第三部分为测试集预测阶段,将测试集数据装载入预测模型进行预测。
1. 数据准备阶段
首先,将图书销售数据与书号实名申领系统数据通过ISBN码进行关联,解决图书销售数据、作者信息残缺等问题,然后按地域进行分组。其中对分类项采用独热编码处理,将离散特征取值按一定的映射规则,扩展至欧式空间,在欧式空间中离散特征的某个取值就对应一个点。在机器学习算法中,会比较频繁的计算特征之间距离或相似度,在具体的过程中常用的距离或相似度计算正是基于欧式空间。完成以上步骤即完成数据准备阶段。
2. 确定预测模型
通过预测模型反复的训练,直至RMSE趋于稳定值。通过比对预测值与实际值,提出了采用微博热搜数据对作者加权的改进方案,通过网络爬取热搜信息,引入作者热度因子,进而改进预测模型。通过对改进模型进行反复迭代,经对比分析后,改进后的模型对热门事件预测能力显著提高,进而最终确定基于神经网络的图书选题预测模型。
3. 预测短期内图书销量
通过改进的预测模型,按地域划分对选题印刷量进行预测,利于出版单位工作人员合理确定各地域印刷量,最终将预测结果持久化至数据库。
(三)数据清洗
以《开卷图书销售报告》(2013-2016)为例,该数据覆盖全国2000余家实体书店门市,20余家独立网店及天猫书城,具有良好的连续性、代表性和完整性。采用2012-2013连续2年的图书零售市场逐月观测数据作为训练集,2014-2015年为测试集。同时,分数据采用书号实名申领数据,书号实名申领系统作为中国图书出版的基础性建设,涵盖全国范围内发行的图书选题所有数据,具有权威性。
首先,将图书销售数据与书号实名申领系统数据通过ISBN码进行关联,采用书号系统数据填补等措施,解决如销售数据、作者信息残缺等数据问题;手动清洗部分出版方式、地域等填写不规范或数据残缺问题;保留规范和有效的数据,如书名、作者、售价、时间、销量、中图分类1级、中图分类2级、中图分类3级、选题类型、语言类别、装订类型(平装、精装等)、页数、字数、内容简介、内容类型(新书、重印、再版)、版次、印次、读者对象、地区、出版方式(常规出版、合作出版、引进出版等)、作者产量频度、出版单位产量频度等字段;然后按地域分组,采用独热编码来处理离散型特征。
(四)确定预测模型及改进
模型通过8000次训练,RMSE基本趋于稳定值,测试集预测结果均已输出,如图1-3所示:
预测样例的预测值与实际值如图1-4所示,可以看出预测误差范围基本在可接受范围之内。
通过分析可知上述模型对于类似“诺奖事件”的热门、热点事件无法做到准确预测,原因在于图书销售数据与书号实名申领系统数据无法关联热点时事,同时不存在反应作者的热门指标。综上所述,模型改进上需增加对于作者热度的权值信息与选题内容的权值信息,通过比对是否含有热搜、作者信息加权,而对于选题内容加权来说,通过对选题内容分词后,判断否包含热搜词语来对选题内容加权。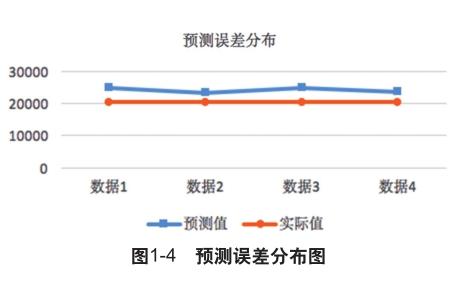
对于新浪微博热搜词与热搜名人信息的搜集,通过采用网络爬取的形式,通过Jsoup框架将两部分数据中的排名、关键词、搜索指数等信息按一定频率进行爬取,解析处理后保存至数据库中,为销售数据的作者加权及选题内容加权作为数据支撑。
增加作者热度与内容热度两个维度,模拟热搜数据通过将一条数据修改为热搜作者或将图书选题内容简介中增加微博热搜词信息。
对模型进行改进后,以固定频率爬取新浪微博热搜数据,采用模拟方式以及对比历史数据的方式可以明显提高预测准确度。如图1-5所示: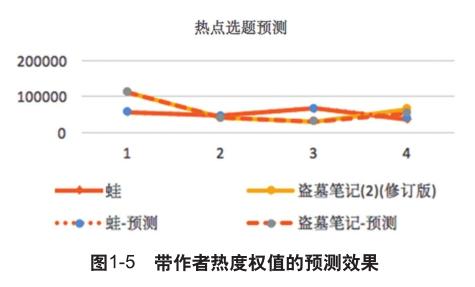
随着“诺贝尔奖颁奖”揭晓时刻的远去,虚构类榜单的“莫言热”也逐渐降温,不过在2013年1月的榜单中莫言依然是入榜品种数最多的作者,《蛙》再次蝉联榜单首位;同样随着网络连续剧《盗墓笔记》的热播和同名电影《盗墓笔记》的上映,南派三叔的《盗墓笔记》和《藏海花》等均表现出强势的销售热潮,本次选取莫言的代表作品《蛙》以及南派三叔代表作品《盗墓笔记》作为预测样例。
首先,我们以前三个月的数据为基础,预测下一个月的销售数量,并与实际销售数量进行比较。从上图看出,预测偏差基本在可控范围之内,表明增加了作者热度与选题热度的神经网络预测方法,对热点事件带来的图书印刷量激增的情形具有较好的预测拟合效果。
二、实验结果及应用
根据预测数据,用户可通过在选题预测公众号中输入“map”,将各选题的预测结果以各省、自治区、直辖市、特别行政区的形式展示。本次预测选题选定中图分类法儿童类,包含二级分类卡通/漫画/绘本、少儿英语、少儿国学经典、少儿艺术、少儿文学、少儿科普百科、低幼启蒙、幼儿园教材、卡片挂图、游戏益智、青少年心理自助11个子类,三级分类少儿卡通、少儿英语、少儿国学经典、少儿美术、少儿艺术综合、少儿游戏、少儿绘本、幼儿园教师用书、少儿卡片、少儿小说、少儿漫画、少儿科普百科、少儿挂图、连环画、少儿文学名著、低幼启蒙、青春漫画、少儿文学其他、少儿手工、少儿音乐、少儿故事、幼儿教材、青少年心理自助共23个子类。
预测的图书销量按各省、自治区、直辖市、特别行政区以颜色深浅区分,颜色越深表示销售量越大;通过左下角标尺可以调节印量单位值,给出更为直观的展示,合理安排不同地域的图书印刷量,可以减少不必要的人、财、物的消耗,同样在减少运输成本与库存积压及销售供给方面具有巨大优势。
通过双击地图中的省、自治区、直辖市、特别行政区,可以进入选题预测详情页面,展示该地域下一个月的印量预测信息,为出版单位工作人员指定下一个月的销售计划提供决策参考。
通过以上分析,从数据层面保障了选题预测的可靠性,对印刷数量给出直观展示,并在地域上给予出版单位较为准确的印刷量预测,为出版单位印刷量确定与地域投放提供了科学依据。由此,使用以上方法可以建立一整套以图书销售数据整合当前热门、热点信息为基础的图书选题预测应用系统,为图书出版行业进行更大规模的数据分析应用奠定基礎。
以上运用神经网络的方法,基于图书销售数据、书号实名申领系统数据及新浪微博热搜数据,采用数据挖掘的分析方法,预测出各地域下图书的印刷量信息,进而为出版单位提供各地域的选题销售分派等工作奠定了良好的基础,为实现出版单位收益最大化提供了良好的保障。
